机器学习中的Bias,Error,Variance的区别
@(Machine Learning)
名词解释
- Error | 误差
- Bias | 偏差 – 衡量准确性
- Variance | 方差 – 衡量稳定性
这三个概念的关系是我当前不太理解的。
详细阅读参考网页。
首先,三者的关系是:
Error反映的是整个模型的准确度,Bias反映的是模型在样本上的输出与真实值之间的误差,即模型本身的精准度。Variance反映的是模型每一次输出结果与模型输出期望值之间的误差,即模型的稳定性。
引入过拟合的思路来看,我们通过样本上训练模型来估计真实数据。即:通过有限的训练样本来估计无限的真实数据。当我们更加相信这些样本数据的真实性的时候,会尽量保证模型在训练样本上的准确度,从而去减少了模型的Bias。这样的模型很可能就会失去一定的泛化能力,导致过拟合问题。而我们为了防止过拟合,通过降低模型在真实数据上的表现时,增加了模型的稳定性,即减小Variance。这样会使模型的Bias增大。
所以,在机器学习里,Bias和Variance的取舍,平衡是一个基本主题。
模型的Bias是可以建模的:只需要保证模型在训练样本上误差最小就可以保证Bias较小。为了达到这个目的,必须用所有数据一起训练才可以达到这个目的,得到模型的最优解。
通过准 v.s. 确 的角度思考
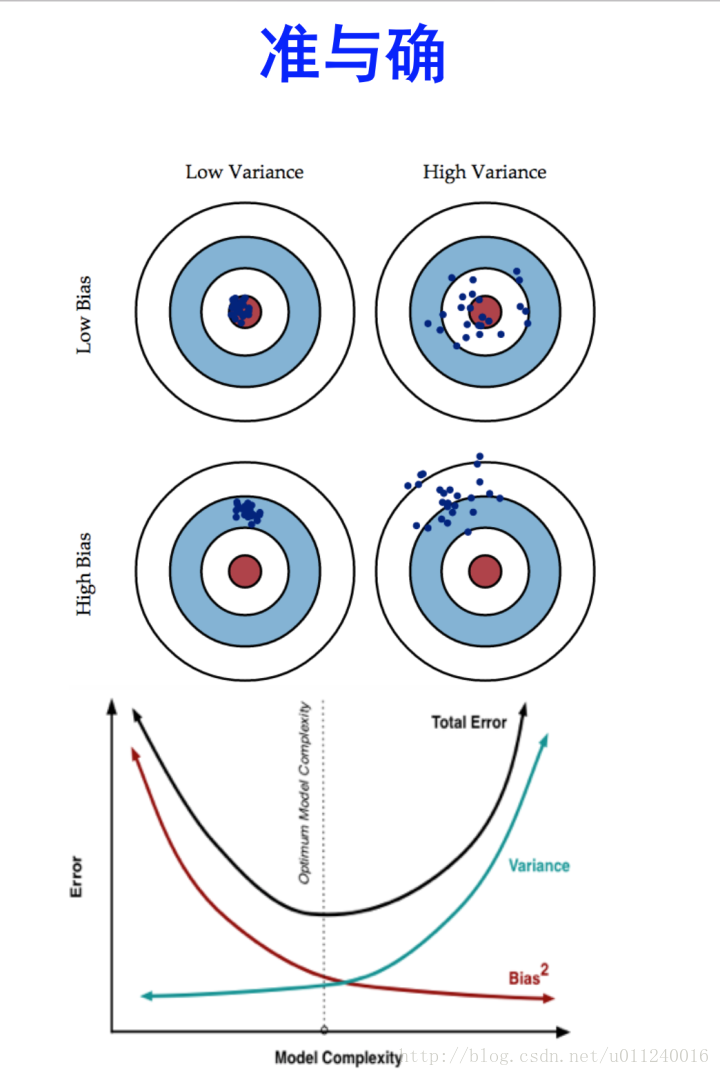
方差和偏差均较小时,是最期待的结果,但是事情没有这么好,二者往往鱼与熊掌难以兼得,因此需要平衡。
高偏差(样本训练出来模型)+ 低方差,模型表现出来的是在远离靶心的地方稳定出现。注意稳定这个词。
低偏差 + 高方差,模型围绕着中心散列得比较开,因为低偏差的量化计算一般是通过估计整体的偏差期望,所以围绕着中心比较均匀分布时,可以得到较小的偏差,但是计算方差时,每一项都是正数(可以为0),那么方差就是偏离的累计。
高偏差 + 高方差,模型在远离中心的地方且散列较开,是最差的情形。
下面的线图,体现的是为何以及如何在Bias和Variance之间取得平衡。一般考虑Bias时用的是平方值。
模型越复杂,Bias越小,体现的是随着模型复杂度变高,在训练样本上效果越好,也无可避免得出现过拟合现象。也即,在测试样本上,方差就会越来越大。而总体误差是二者之和,得到的总体结果是U形线。所以,可见,最佳的解决思路是在该U形线最低点处取值。