Capítulo 2: Hadoop serialização
2.1 Serialization Overview
2.1.1 O que é serializado
- É a sequência de objectos em memória é convertida numa sequência de bytes (ou outro protocolo de transferência de dados) para o armazenamento de disco (persistente) e a rede.
- Desserialização é para receber uma sequência de bytes (ou outro protocolo de transferência de dados) ou um disco de dados persistente, ele é convertido em objectos em memória.
2.1.2 Por que devem serializar
- Em geral, os objetos "ao vivo" sobrevivem apenas na memória, não há falta de energia desligado. E objetos "ao vivo" só pode ser usado por um processo local que não pode ser enviado para outro computador na rede. No entanto, a serialização podem ser armazenados objectos "ao vivo", pode ser objeto "ao vivo" é enviado para o computador remoto.
2.1.3 Por que não usar a serialização Java
- serialização Java é uma seqüência de pesos pesados quadro (a Serializable), um objeto é serializado, navio com um monte de informações adicionais (várias informações de verificação, Cabeçalho, sistema de herança, etc.), não facilitam a transmissão eficiente na rede. Assim, o Hadoop tem desenvolvido o seu próprio conjunto de mecanismo de serialização (gravável).
Hadoop sequência de características:
(1) compacto: uma utilização eficiente do espaço de armazenamento.
(2) Rápido: pequena leitura sobrecarga e gravação de dados.
(3) pode ser estendido: um protocolo de comunicação com a actualização e pode actualizar
(4) interoperarem: multilingue interacção apoio
2.2 feijão objeto implementa personalizados interfaces seriais (gravável)
- No desenvolvimento empresa é muitas vezes tipos de serialização básicos comuns não pode atender a todos os requisitos, como passar um objetos de feijão no âmbito Hadoop, em seguida, o objeto seria necessário para implementar interfaces seriais.
Feijão de sequências-alvo passos de aplicação específica são como se segue Passo 7.
(1) deve implementar a interface gravável
deserialização (2), o que reflecte a necessidade de chamar um construtor argumento vazio, os parâmetros de configuração devem ser livres
public FlowBean() {
super();
}
(3) Método de sequência reescrevendo
@Override
public void write(DataOutput out) throws IOException {
out.writeLong(upFlow);
out.writeLong(downFlow);
out.writeLong(sumFlow);
}
(4) O método de reescrever deserialização
@Override
public void readFields(DataInput in) throws IOException {
upFlow = in.readLong();
downFlow = in.readLong();
sumFlow = in.readLong();
}
(5) Note-se que a ordem de desserialização e serialização ordem exatamente
(6), a fim de exibir os resultados em um arquivo, precisa ser reescrito toString (), pode ser usado "\ t" à parte, para facilitar a posterior utilização.
(7) Se você precisa de personalizar o feijão na transmissão de chave, a necessidade de implementar a interface Comparable, porque o processo Aleatório MapReduce caixa requisitos fundamentais devem ser classificado. Veja a parte traseira de triagem dos casos.
@Override
public int compareTo(FlowBean o) {
// 倒序排列,从大到小
return this.sumFlow > o.getSumFlow() ? -1 : 1;
}
2.3 Processo de sequência de operação prático
1. demanda
- número de telefone estatística do custo total de tráfego a montante, a jusante de tráfego, um caudal total por
(1) dados de entrada do
formato de dados (2) de entrada:
| Eu iria | número de telefone | rede IP | tráfego upstream | tráfego downstream | código de status da rede |
|---|---|---|---|---|---|
| 7 | 13560436666 | 120.196.100.99 | 1116 | 954 | 200 |
o formato dos dados de saída desejado (3)
| número de telefone | tráfego upstream | tráfego downstream | fluxo total |
|---|---|---|---|
| 7 | 13560436666 | 1116 | 954 |
2. Análise de Requisitos
- Os dados são como se segue
1 13631579850 120.196.100.82 2481 24681 200
2 13631579950 120.197.40.4 264 0 200
3 13631579930 120.196.100.99 132 1512 200
4 13631544000 120.197.40.4 240 0 200
5 13631579930 120.196.100.99 1527 2106 200
6 13631579930 120.197.40.4 4116 1432 200
7 13631579930 120.196.100.99 1116 954 200
8 13631579950 120.197.40.4 3156 2936 200
9 13631579830 120.196.100.82 240 0 200
10 13631544000 120.197.40.4 6960 690 200
11 13631579730 120.197.40.4 3659 3538 200
12 13631579930 120.196.100.99 1938 180 200
13 13631544000 120.196.100.99 918 4938 200
14 13631579930 120.197.40.4 180 180 200
15 13631579840 120.197.40.4 1938 2910 200
16 13631579950 120.196.100.82 3008 3720 200
17 13631544000 120.196.100.99 7335 110349 200
18 13631579930 120.196.100.99 9531 2412 200
19 13631579900 120.196.100.55 11058 48243 200
20 13631579930 120.196.100.82 120 120 200
21 13631579850 120.196.100.82 2481 24681 200
22 13631579930 120.196.100.99 1116 954 200
- Estatísticas para cada número de telefone (endereço IP) do fluxo de tráfego total a montante ea jusante:
3. O programa em MapReduce
- Feijão objeto para as estatísticas de tráfego de escrita
package com.zhangyong.serialize;
import java.io.DataInput;
import java.io.DataOutput;
import java.io.IOException;
import org.apache.hadoop.io.Writable;
/**
* @Author zhangyong
* @Date 2020/3/4 16:35
* @Version 1.0
* 编写流量统计的Bean对象
*/
public class FlowBean implements Writable {
private String phoneNumber; //电话号码
private long upFlow; //上行流量
private long downFlow; //下行流量
private long sumFlow; //总流量
public String getPhoneNumber() {
return phoneNumber;
}
public void setPhoneNumber(String phoneNumber) {
this.phoneNumber = phoneNumber;
}
public long getUpFlow() {
return upFlow;
}
public void setUpFlow(long upFlow) {
this.upFlow = upFlow;
}
public long getDownFlow() {
return downFlow;
}
public void setDownFlow(long downFlow) {
this.downFlow = downFlow;
}
public long getSumFlow() {
return sumFlow;
}
public void setSumFlow(long sumFlow) {
this.sumFlow = sumFlow;
}
@Override
public String toString() {
return "FlowBean{" +
"phoneNumber='" + phoneNumber + '\'' +
", upFlow=" + upFlow +
", downFlow=" + downFlow +
", sumFlow=" + sumFlow +
'}';
}
/**
* 在反序列化时候,反射机制需要调用空参的构造方法
*/
public FlowBean() {
}
/**
* 为了对象数据的初始化方便,提供一个带参的构造方法
* @param phoneNumber
* @param upFlow
* @param downFlow
*/
public FlowBean(String phoneNumber, long upFlow, long downFlow) {
this.phoneNumber = phoneNumber;
this.upFlow = upFlow;
this.downFlow = downFlow;
this.sumFlow = upFlow + downFlow;
}
/**
* 从数据流中反序列出对象的数据。从数据流中读取字段时必须和序列化的顺序保持一致
* @param in
* @throws IOException
*/
public void readFields(DataInput in) throws IOException {
phoneNumber = in.readUTF();
upFlow = in.readLong();
downFlow = in.readLong();
sumFlow = in.readLong();
}
public void write(DataOutput out) throws IOException { //将对象数据序列化到流中
out.writeUTF(phoneNumber);
out.writeLong(upFlow);
out.writeLong(downFlow);
out.writeLong(sumFlow);
}
}
- Escrever classe Mapper
package com.zhangyong.serialize;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import java.io.IOException;
/**
* @Author zhangyong
* @Date 2020/3/4 16:35
* @Version 1.0
* 定义Mapper类
*/
public class FlowMapper extends Mapper<LongWritable, Text, Text, FlowBean> {
@Override
protected void map(LongWritable key, Text value, Context context)
throws IOException, InterruptedException {
String line = value.toString (); //拿到一行数据
String[] fields = line.split ("\\s+"); //切分成各个字段
String phoneNumber = fields[1]; //手机号
// 取出上行流量和下行流量
long upFlow = Long.parseLong(fields[fields.length - 3]);//上行流量
long downFlow = Long.parseLong(fields[fields.length - 2]);//下行流量
//封装数据为key-value进行输出
context.write (new Text (phoneNumber), new FlowBean (phoneNumber, upFlow, downFlow));
}
}
- Redutor de aula de redação
package com.zhangyong.serialize;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
import java.io.IOException;
/**
* @Author zhangyong
* @Date 2020/3/4 16:35
* @Version 1.0
* 定义Reducer类
*/
public class FlowReducer extends Reducer<Text, FlowBean, Text, FlowBean> {
@Override
protected void reduce(Text key, Iterable<FlowBean> values, Context context) throws InterruptedException, IOException {
long upFlowSum = 0; //上行流量计数器
long downFlowSum = 0; //下行流量计数器
for (FlowBean bean : values) {//上行流量和下行流量累加求和
upFlowSum += bean.getUpFlow ();
downFlowSum += bean.getDownFlow ();
}
//将结果输出
context.write (key, new FlowBean (key.toString (), upFlowSum, downFlowSum));
}
}
- Motorista classe Write motorista
package com.zhangyong.serialize;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.input.TextInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.mapreduce.lib.output.TextOutputFormat;
/**
* @Author zhangyong
* @Date 2020/3/4 16:35
* @Version 1.0
* 编写Driver驱动类
*/
public class FlowDriver {
public static void main(String[] args) throws Exception {
// 数据输入路径和输出路径
args = new String[2];
args[0] = "src/main/resources/flowi";
args[1] = "src/main/resources/flowo";
Configuration cfg = new Configuration ();// 读取配置文件
//设置本地模式运行(即使项目类路径下core-site.xml文件,依然采用本地模式)
cfg.set ("mapreduce.framework.name", "local");
cfg.set ("fs.defaultFS", "file:///");
Job job = Job.getInstance (cfg);// 新建一个任务
job.setJarByClass (FlowDriver.class); // 设置主类
job.setInputFormatClass (TextInputFormat.class);//设置输入格式
job.setOutputFormatClass (TextOutputFormat.class);
//本job使用的mapper和reducer
job.setMapperClass (FlowMapper.class); // Mapper
job.setReducerClass (FlowReducer.class); // Reducer
//指定mapper输出数据的key-value类型
job.setMapOutputKeyClass (Text.class);
job.setMapOutputValueClass (FlowBean.class);
//指定最终输出数据的key-value类型
job.setOutputKeyClass (Text.class);
job.setOutputValueClass (FlowBean.class);
FileInputFormat.addInputPath (job, new Path (args[0])); // 输入路径
FileOutputFormat.setOutputPath (job, new Path (args[1])); // 输出路径
// 提交任务
int res = job.waitForCompletion (true) ? 0 : 1;
System.exit (res);
}
}
4. Execute os resultados do programa em Hadoop locais
- Executar para conclusão sem erro e gerar meios flowo o sucesso de

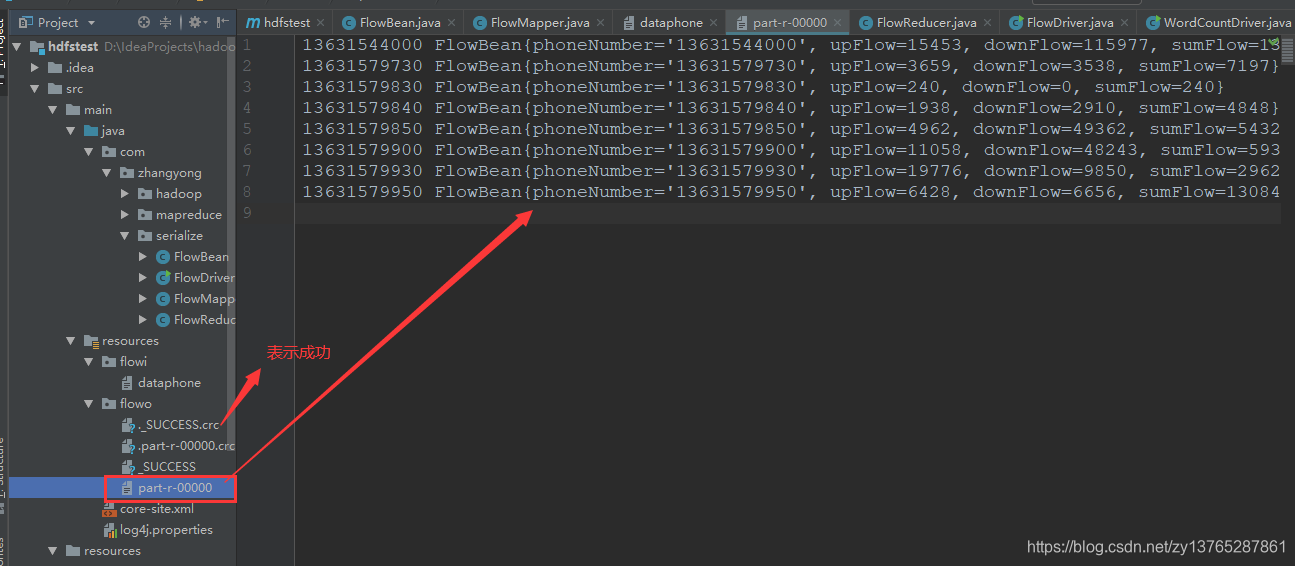
- Os resultados são como se segue
13631544000 FlowBean{phoneNumber='13631544000', upFlow=15453, downFlow=115977, sumFlow=131430}
13631579730 FlowBean{phoneNumber='13631579730', upFlow=3659, downFlow=3538, sumFlow=7197}
13631579830 FlowBean{phoneNumber='13631579830', upFlow=240, downFlow=0, sumFlow=240}
13631579840 FlowBean{phoneNumber='13631579840', upFlow=1938, downFlow=2910, sumFlow=4848}
13631579850 FlowBean{phoneNumber='13631579850', upFlow=4962, downFlow=49362, sumFlow=54324}
13631579900 FlowBean{phoneNumber='13631579900', upFlow=11058, downFlow=48243, sumFlow=59301}
13631579930 FlowBean{phoneNumber='13631579930', upFlow=19776, downFlow=9850, sumFlow=29626}
13631579950 FlowBean{phoneNumber='13631579950', upFlow=6428, downFlow=6656, sumFlow=13084}
