
Este artigo é baseado em um discurso proferido por Shao Wei, engenheiro sênior de P&D da Volcano Engine, na QCon Global Software Development Conference. Palestrante|Discurso de Shao Wei|QCon Guangzhou em maio de 2023
PPT | Katalyst: Prática de otimização de custos nativa da ByteDance Cloud
1. Fundo
A Byte começou a transformar seus serviços em serviços nativos da nuvem desde 2016. A partir de hoje, o sistema de serviços da Byte inclui principalmente quatro categorias: microsserviços tradicionais são principalmente serviços Web RPC baseados em Golang, o serviço de pesquisa de promoção é um serviço C++ tradicional com maior desempenho; requisitos; além disso, há também aprendizado de máquina, big data e vários serviços de armazenamento .
A questão central que precisa ser resolvida após a nativa da nuvem é como melhorar a eficiência de utilização de recursos do cluster, tomando como exemplo o uso de recursos de um serviço online típico, a parte azul escura é a quantidade de recursos realmente utilizados pelo negócio; , e a parte azul claro é o buffer de segurança fornecido pela área de negócios, mesmo que a área de buffer seja aumentada, ainda existem muitos recursos que foram solicitados, mas não utilizados pelo negócio. Portanto, o foco da otimização é utilizar esses recursos não utilizados tanto quanto possível do ponto de vista arquitetônico.
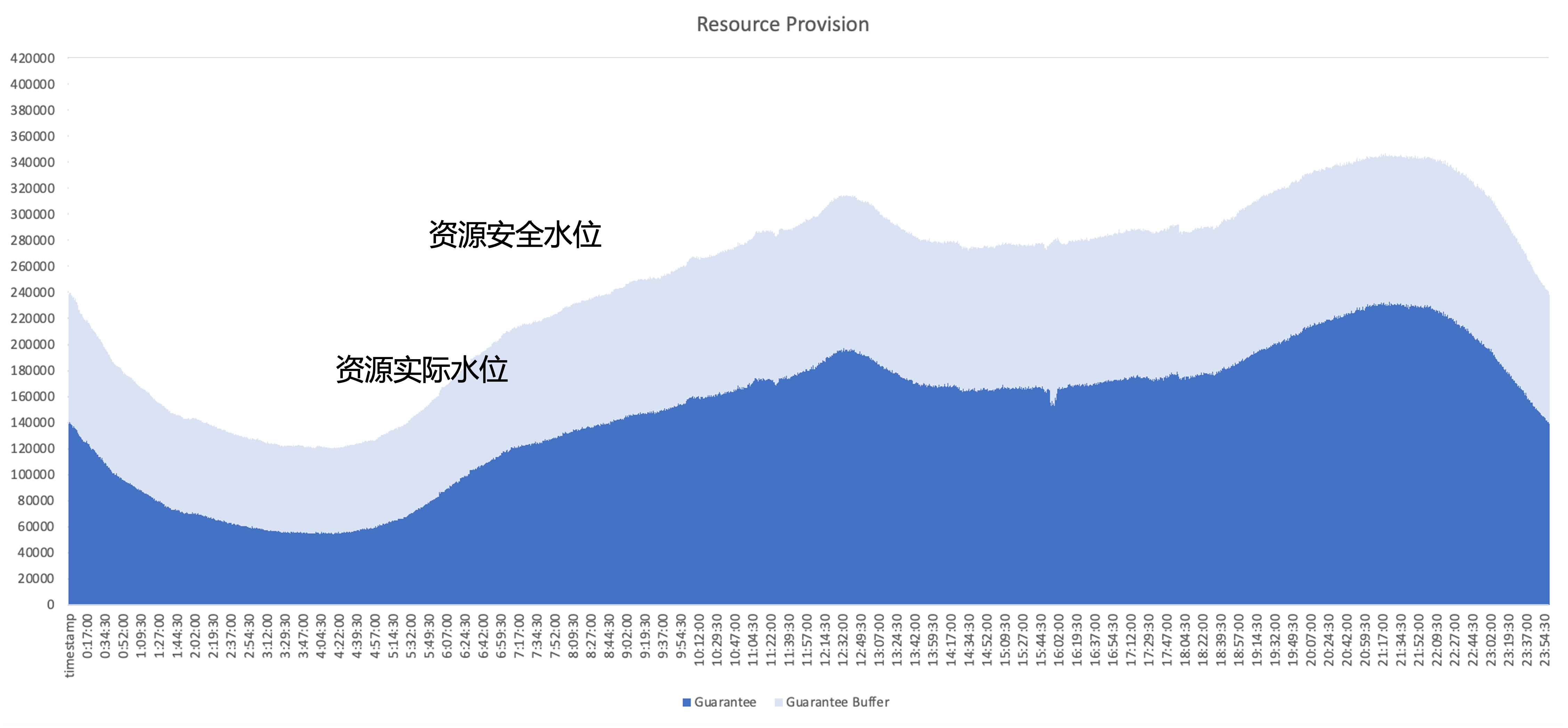
plano de gerenciamento de recursos
A Byte tentou vários tipos diferentes de soluções de gerenciamento de recursos internamente, incluindo
- Operação de recursos: ajude regularmente a empresa a administrar o status de utilização de recursos e promova o gerenciamento de aplicativos de recursos. O problema é que a carga de operação e manutenção é pesada e o problema de utilização não pode ser resolvido.
- Overbooking dinâmico: Avalie a quantidade de recursos de negócios no lado do sistema e reduza proativamente a cota. O problema é que a estratégia de overbooking não é necessariamente precisa e pode levar a um risco de execução.
- Escalabilidade dinâmica: O problema é que se você direcionar apenas os serviços online para escalabilidade, uma vez que os altos e baixos do tráfego nos serviços online são semelhantes, não será possível melhorar totalmente a utilização ao longo do dia.
Portanto, no final, Byte adota implantação híbrida, rodando online e offline no mesmo nó ao mesmo tempo, fazendo pleno uso das características complementares entre recursos online e offline para alcançar uma melhor utilização de recursos, em última análise, esperamos alcançar o seguinte efeito; , ou seja, as vendas secundárias são on-line. Os recursos não utilizados podem ser bem preenchidos com cargas de trabalho off-line para manter a eficiência da utilização de recursos em alto nível ao longo do dia.
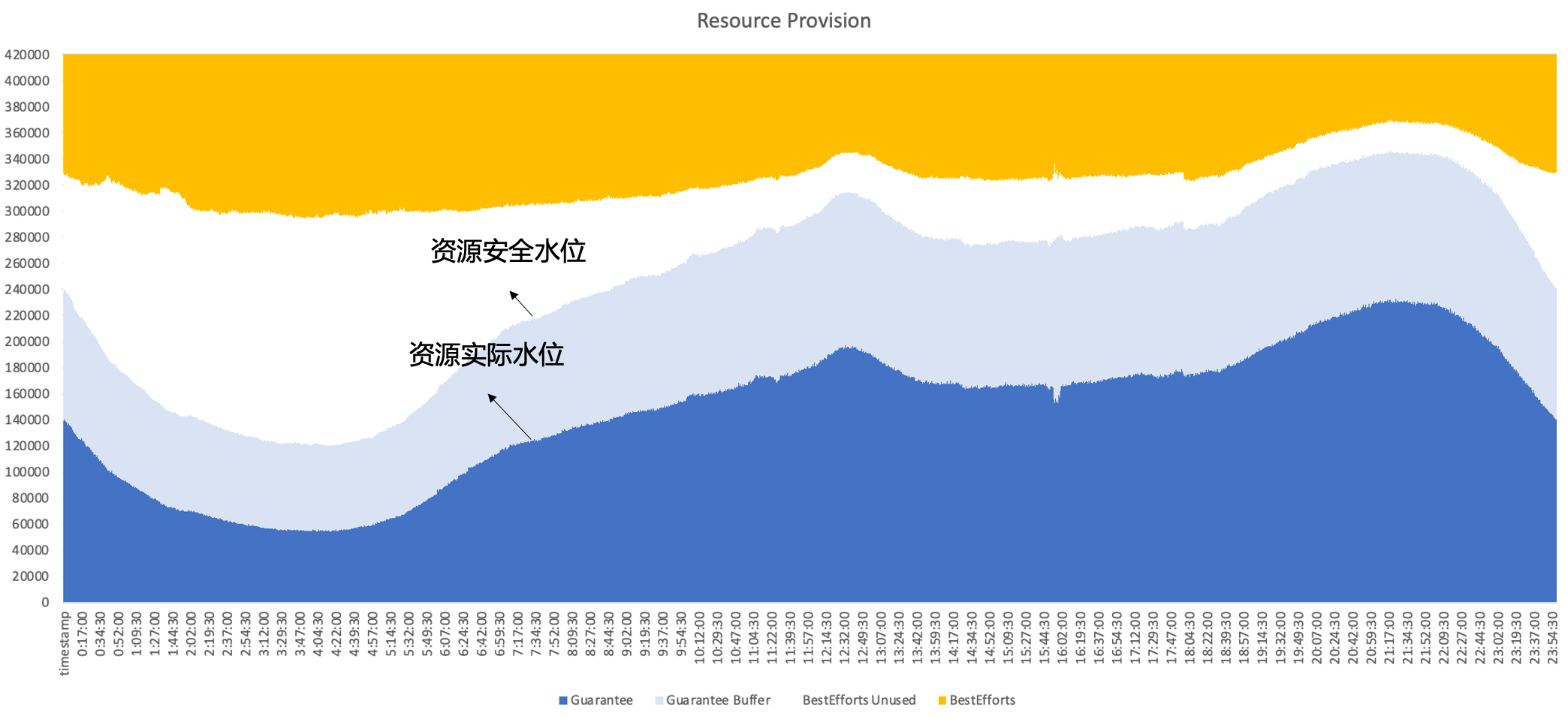
2. Histórico de desenvolvimento de implantação híbrida de bytes
À medida que o Byte Cloud se torna nativo, escolhemos soluções de implantação híbrida apropriadas com base nas necessidades de negócios e características técnicas em diferentes estágios e continuamos a iterar nosso sistema híbrido no processo.
2.1 Fase 1: Mixagem de tempo compartilhado offline
A primeira etapa envolve principalmente a implantação híbrida de compartilhamento de tempo online e offline.
- Online: nesta fase, construímos uma plataforma de elasticidade de serviço online. Os usuários podem configurar regras de escala horizontal com base em indicadores de negócios, por exemplo, se o tráfego comercial diminuir no início da manhã e o negócio reduzir proativamente algumas instâncias, o sistema executará recursos; bing embalagem com base no encolhimento da instância Isso libera toda a máquina;
- Para offline: Nesta fase, os serviços offline podem obter um grande número de recursos do tipo spot e, como o seu fornecimento é instável, podem usufruir de um certo desconto no custo, ao mesmo tempo, para online, a venda de recursos não utilizados para offline pode; obter um certo desconto no custo.
A vantagem desta solução é que ela não requer um mecanismo complexo de isolamento lateral de máquina única e a implementação técnica é relativamente baixa, mas também existem alguns problemas, como;
- A eficiência de conversão não é alta e problemas como fragmentação podem ocorrer durante o processo de empacotamento;
- A experiência offline também pode não ser boa. Quando o tráfego online flutua ocasionalmente, o usuário offline pode ser morto à força, resultando em fortes flutuações de recursos.
- Isso causará alterações de instância no negócio. Nas operações reais, o negócio geralmente configura uma política elástica relativamente conservadora, resultando em um limite superior baixo para melhoria de recursos.
2.2 Fase 2: Implantação conjunta Kubernetes/YARN
Para resolver os problemas acima, entramos no segundo estágio e tentamos rodar offline e online em um nó.
Como a parte online foi transformada nativamente com base no Kubernetes anteriormente, a maioria dos trabalhos offline ainda são executados com base no YARN. Para promover a implantação híbrida, introduzimos componentes de terceiros em uma única máquina para determinar a quantidade de recursos coordenados online e offline e os conectamos com componentes independentes, como Kubelet ou Node Manager ao mesmo tempo; cargas de trabalho online e offline são agendadas para nós, elas também são coordenadas por O componente de coordenação atualiza de forma assíncrona as alocações de recursos para ambas as cargas de trabalho.
Este plano permite-nos completar a acumulação de reservas de capacidades de co-localização e verificar a viabilidade, mas ainda existem alguns problemas
- Os dois sistemas são executados de forma assíncrona, de modo que o contêiner offline só pode ignorar o gerenciamento e o controle, e há uma corrida e muita perda de recursos nos links intermediários;
- A simples abstração de cargas de trabalho offline nos impede de descrever requisitos complexos de QoS
- A fragmentação dos metadados offline dificulta a otimização extrema e não consegue alcançar a otimização do agendamento global.
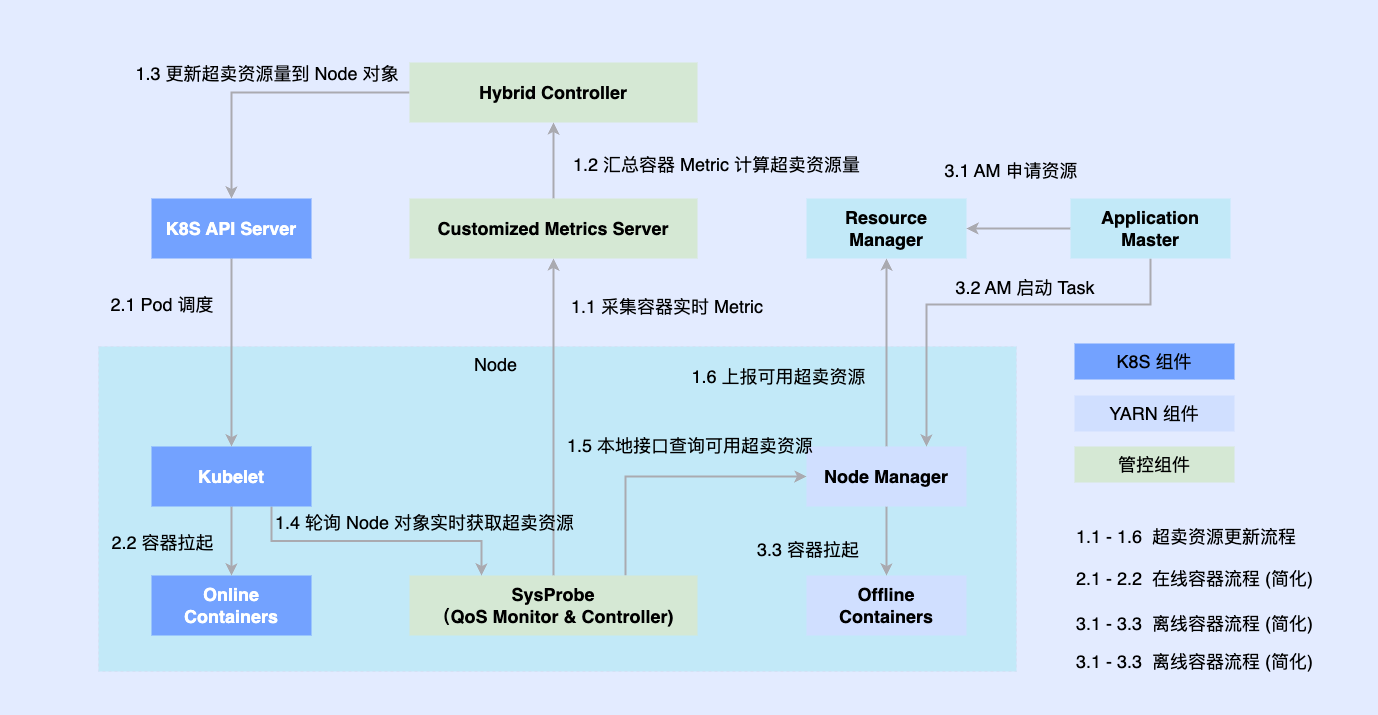
2.3 Fase 3: Agendamento unificado e implantação mista off-line
Para resolver os problemas do segundo estágio, no terceiro estágio realizamos completamente a implantação híbrida offline unificada.
Ao tornar os trabalhos off-line nativos da nuvem, permitimos que eles sejam agendados e os recursos gerenciados na mesma infraestrutura. Neste sistema, a camada superior é uma federação de recursos unificada para realizar o gerenciamento de recursos de vários clusters. Em um único cluster, há um agendador central unificado e um gerenciador de recursos unificado independente. Eles trabalham juntos para obter recursos de gerenciamento de recursos integrados offline. .
Nesta arquitetura, o Katalyst atua como camada central de gerenciamento e controle de recursos e é responsável por realizar a alocação e estimativa de recursos em tempo real no lado da máquina única.
- Padronização de abstração: abra metadados offline, torne a abstração de QoS mais complexa e rica e atenda melhor aos requisitos de desempenho de negócios;
- Sincronização de gerenciamento e controle: A política de gerenciamento e controle é emitida quando o contêiner é iniciado para evitar correção assíncrona de ajustes de recursos após a inicialização, ao mesmo tempo em que oferece suporte à expansão livre da política;
- Estratégia inteligente: Ao criar retratos de serviços, você pode detectar antecipadamente as demandas de recursos e implementar estratégias mais inteligentes de gerenciamento e controle de recursos;
- Automação de operação e manutenção: Através da entrega integrada, a automação e a padronização da operação e manutenção são alcançadas.
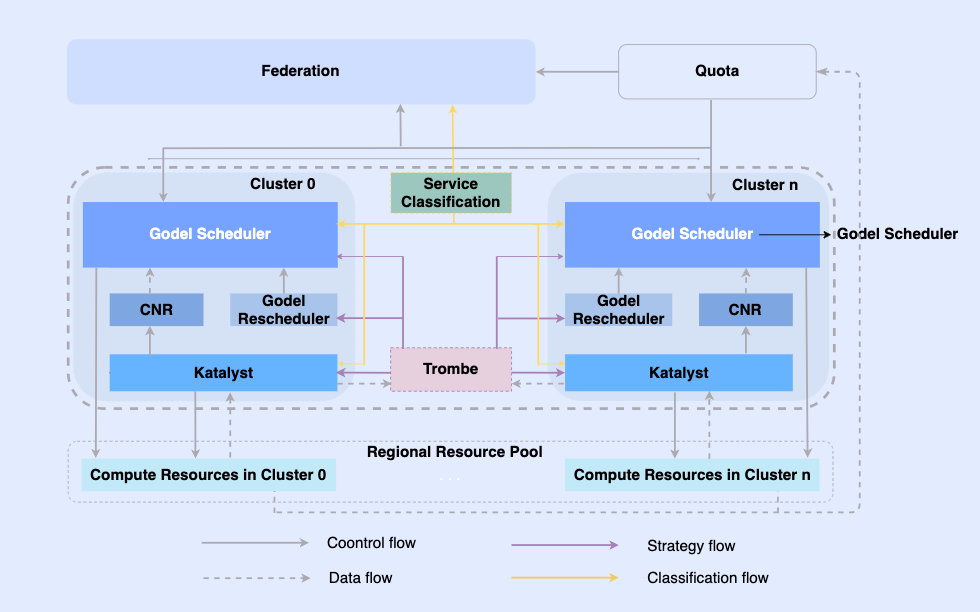
3. Introdução ao sistema Katalyst
Katalyst é derivado da palavra inglesa catalisador, que originalmente significa catalisador. A primeira letra foi alterada para K, o que significa que o sistema pode fornecer recursos de gerenciamento automatizado de recursos mais poderosos para todas as cargas em execução no sistema Kubernetes.
3.1 Visão geral do sistema Katalyst
O sistema Katalyst é dividido em quatro camadas, incluindo
- A API padrão de nível superior abstrai diferentes níveis de QoS para os usuários e fornece recursos avançados de expressão de recursos;
- A camada central é responsável por recursos básicos, como agendamento unificado, recomendação de recursos e construção de retratos de serviço;
- A camada autônoma inclui um sistema de monitoramento de dados autodesenvolvido e um alocador de recursos responsável pela alocação em tempo real e ajuste dinâmico de recursos;
- A camada inferior é um kernel personalizado em bytes, que resolve o problema de desempenho de uma única máquina quando executado off-line, aprimorando o patch do kernel e o mecanismo de isolamento subjacente.
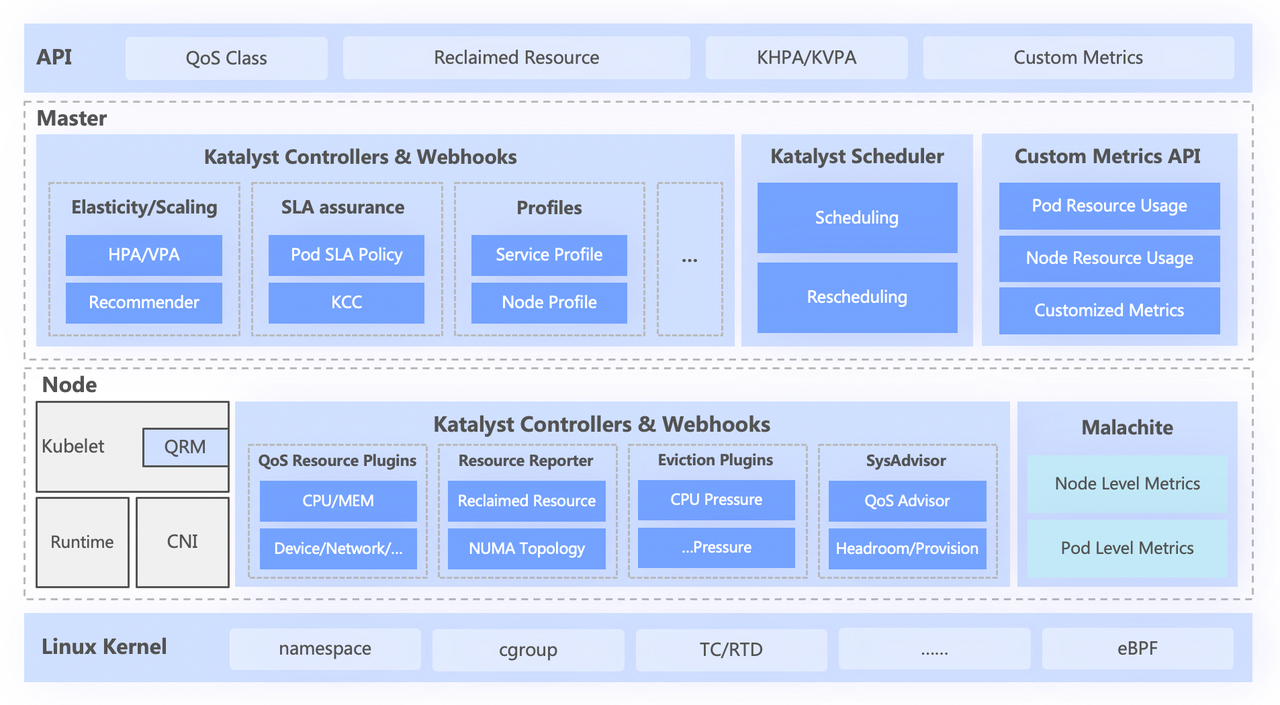
3.2 Padronização abstrata: Classe QoS
O Katalyst QoS pode ser interpretado de perspectivas macro e micro
- Em um nível macro, o Katalyst define níveis de QoS padrão com base na dimensão principal da CPU especificamente, dividimos a QoS em quatro categorias: exclusivo, compartilhado, reciclagem e tipo de sistema reservado para componentes principais do sistema;
- De uma perspectiva micro, a expectativa final do Katalyst é que, independentemente do tipo de carga de trabalho, ele possa ser executado em um pool no mesmo nó sem a necessidade de isolar o cluster por meio de cortes rígidos, alcançando assim melhor eficiência de tráfego e utilização de recursos. eficiência.
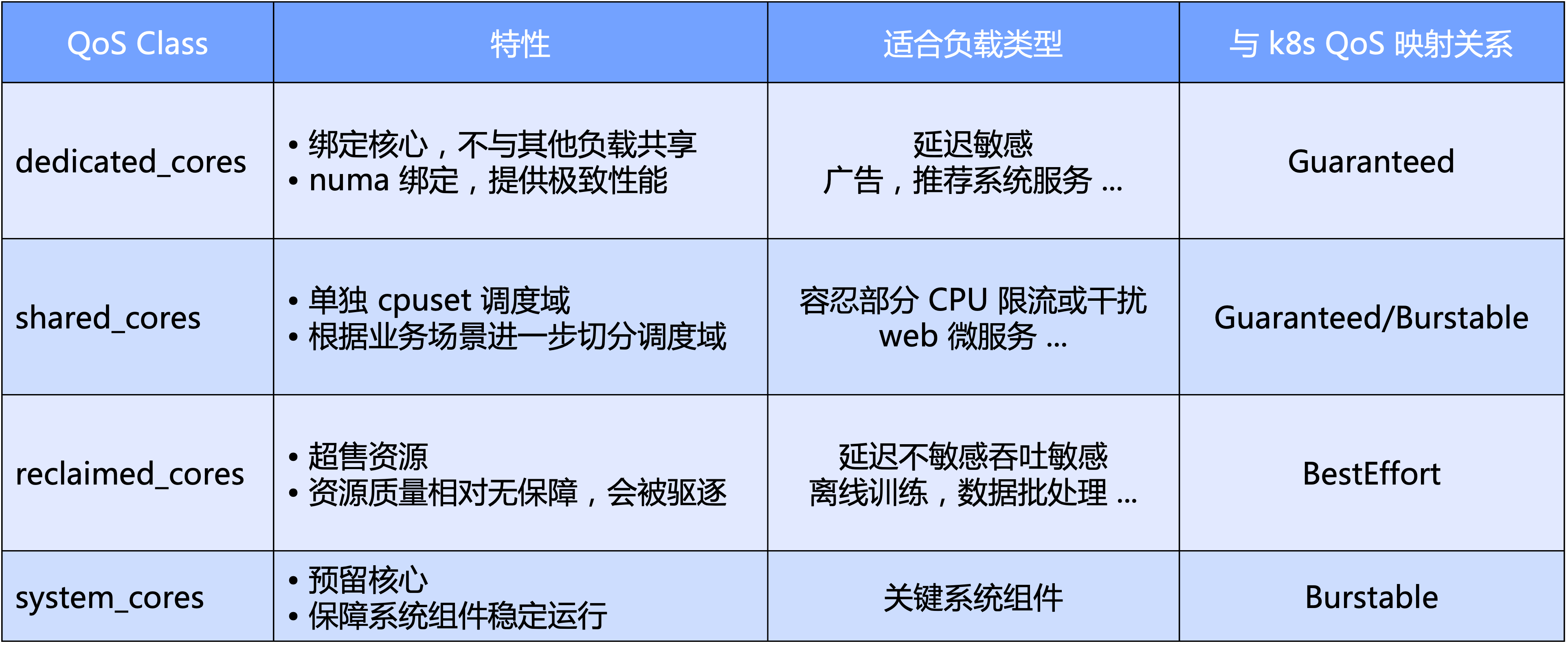
Com base na QoS, o Katalyst também oferece diversas melhorias de extensão para expressar outros requisitos de recursos além dos núcleos da CPU.
- Aprimoramento de QoS: Expressão estendida de requisitos de negócios para recursos multidimensionais, como ligação NUMA/placa de rede, alocação de largura de banda de placa de rede, peso IO, etc.
- Aprimoramento de pod: estende a expressão da sensibilidade do negócio a vários indicadores do sistema, como o impacto do atraso no agendamento da CPU no desempenho do negócio
- Aprimoramento de nós: Expresse as demandas combinadas de microtopologia entre múltiplas dimensões de recursos, estendendo a TopologyPolicy nativa
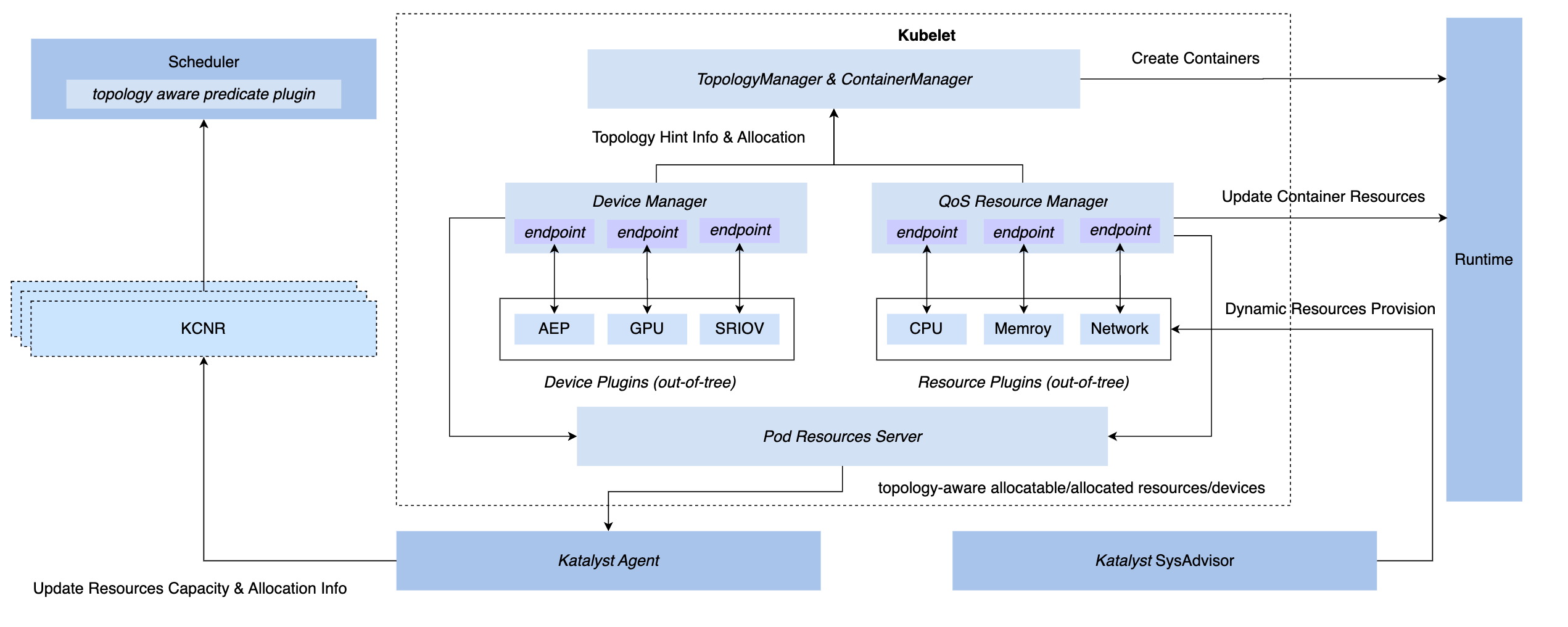
3.3 Sincronização de gerenciamento e controle: QoS Resource Manager
Para obter recursos de gerenciamento e controle síncronos no sistema K8s, temos três métodos de gancho: inserção da camada CRI, camada OCI e camada Kubelet. No final, o Katalyst optou por implementar o gerenciamento e o controle no lado Kubelet, ou seja, implementar um QoS Resource Manager no mesmo nível do Device Manager nativo. As vantagens deste programa incluem.
- Implemente a interceptação durante a fase de admissão, eliminando a necessidade de depender de medidas secretas para obter controle nas etapas subsequentes.
- Conecte metadados com Kubelet, relate informações de microtopologia de máquina única para o nó CRD por meio de interface padrão e realize o acoplamento com o agendador
- Com base nesta estrutura, plug-ins conectáveis podem ser implementados de forma flexível para atender às necessidades personalizadas de gerenciamento e controle.
3.4 Estratégia inteligente: retrato do serviço e estimativa de recursos
Normalmente, é mais intuitivo optar por usar indicadores de negócios para construir um retrato de serviço, como atraso do serviço P99 ou taxa de erro downstream. Mas também existem alguns problemas. Por exemplo, em comparação com os indicadores do sistema, é geralmente mais difícil obter indicadores de negócios. As empresas geralmente integram vários quadros e os significados dos indicadores de negócios que produzem não são exatamente os mesmos; forte dependência destes indicadores, todo A implementação do controle se tornará muito complicada.
Portanto, esperamos que o controle final de recursos ou retrato de serviço seja baseado em indicadores de sistema e não em indicadores de negócios. O mais crítico é como encontrar os indicadores de sistema que mais preocupam o negócio. Nossa abordagem é usar um conjunto de indicadores off-line; pipelines para descobrir indicadores de negócios e indicadores de sistema. Por exemplo, para o serviço na figura, o indicador de negócio principal é o atraso P99. Através da análise, verifica-se que o indicador do sistema com a maior correlação é o atraso de agendamento da CPU. Continuaremos a ajustar o fornecimento de recursos do serviço para se aproximar. seu objetivo tanto quanto possível.
Com base em retratos de serviço, o Katalyst fornece mecanismos de isolamento avançados para CPU, memória, disco e rede, e personaliza o kernel quando necessário para fornecer requisitos de desempenho mais fortes, no entanto, para diferentes cenários e tipos de negócios. Esses meios não são necessariamente aplicáveis; é preciso enfatizar que o isolamento é mais um meio do que um fim. No processo de realização de negócios, precisamos escolher diferentes soluções de isolamento com base em necessidades e cenários específicos.
3.5 Automação de operação e manutenção: gerenciamento de configuração dinâmica multidimensional
Embora esperemos que todos os recursos estejam sob um sistema de pool de recursos, em um ambiente de produção em larga escala, é impossível colocar todos os nós em um cluster. Além disso, um cluster pode ter máquinas CPU e GPU, embora o plano de controle possa; ser compartilhado, mas é necessário certo isolamento no plano de dados no nível do nó, muitas vezes precisamos modificar a configuração da dimensão do nó para verificação em escala de cinza, resultando em diferenças nos SLOs de diferentes serviços em execução no mesmo nó.
Para resolver esses problemas, precisamos considerar o impacto das diferentes configurações de nós nos serviços durante a implantação do negócio. Para isso, o Katalyst fornece recursos de gerenciamento dinâmico de configuração para entrega padrão, avaliando o desempenho e a configuração de diferentes nós por meio de métodos automatizados e selecionando o nó mais adequado para o serviço com base nesses resultados.
4. Aplicação de co-localização Katalyst e análise de caso
Nesta seção, compartilharemos algumas práticas recomendadas baseadas em casos internos da Byte.
4.1 Efeito de utilização
Em termos dos efeitos da implementação do Katalyst, com base nas práticas comerciais internas da Byte, nossos recursos podem ser mantidos em um estado relativamente alto durante o ciclo trimestral em um único cluster, a utilização de recursos também mostra um nível relativamente alto em vários períodos de cada dia; Distribuição estável ao mesmo tempo, a utilização da maioria das máquinas no cluster também é relativamente concentrada e nosso sistema de implantação híbrido funciona de forma relativamente estável em todos os nós.
| Algoritmo de previsão de recursos | Proporção de recursos recuperados | Utilização média da CPU no nível do dia | Utilização máxima da CPU no nível do dia |
|---|---|---|---|
| Buffer fixo de utilização | 0,26 | 0,33 | 0,58 |
| algoritmo de agrupamento k-means | 0,35 | 0,48 | 0,6 |
| Algoritmo PID do indicador do sistema | 0,39 | 0,54 | 0,66 |
| Estimativa do modelo de indicador do sistema + algoritmo PID | 0,42 | 0,57 | 0,67 |
4.2 Prática: acesso off-line sem sentido
Depois de entrar no terceiro estágio, precisamos realizar a transformação offline da nuvem nativa. Existem dois métodos principais de transformação. Um é para serviços já no sistema K8s. Conectaremos diretamente o pool de recursos baseado no Virtual Kubelet. , Uma transformação completa da estrutura será muito dispendiosa para as empresas e, teoricamente, levará a atualizações contínuas para todas as empresas. Obviamente, este não é um estado ideal.
Para resolver esse problema, Byte se refere à camada adesiva do Yodel, ou seja, o acesso comercial ainda usa a API Yarn padrão, mas nesta camada adesiva faremos a interface com a semântica K8s subjacente e abstrairemos a solicitação de recursos do usuário; algo como Pod ou Descrição do contêiner. Este método nos permite usar tecnologia K8s mais madura no nível inferior para gerenciar recursos, alcançar a transformação off-line nativa da nuvem e, ao mesmo tempo, garantir a estabilidade do negócio.
4.3 Prática: Governança de Operações de Recursos
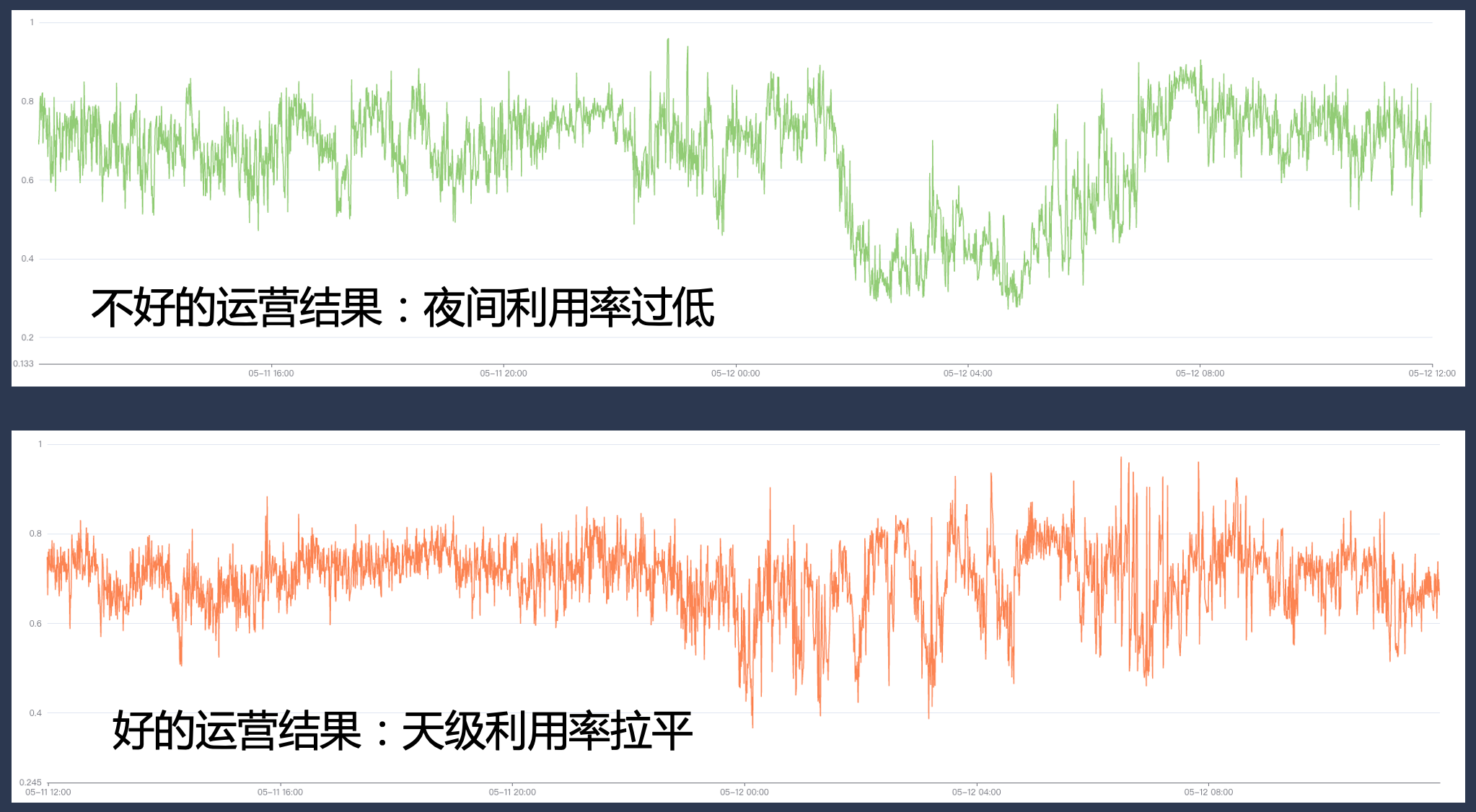
Durante o processo de co-localização, precisamos adaptar e transformar o big data e a estrutura de treinamento, e fazer várias novas tentativas, pontos de verificação e classificações para garantir que, depois de cortarmos esses big data e trabalhos de treinamento para todo o conjunto de recursos de co-localização, A experiência de usá-los não é tão ruim.
Ao mesmo tempo, precisamos de ter capacidades básicas completas em matérias-primas, classificação de negócios, governação operacional e gestão de quotas no sistema. Se a operação não for bem executada, a taxa de utilização pode ser muito elevada durante determinados períodos de pico, mas pode haver uma grande lacuna de recursos durante outros períodos, fazendo com que a taxa de utilização não atenda às expectativas.
4.4 Prática: Maximizando a Melhoria da Eficiência de Recursos
Ao construir retratos de serviço, utilizamos indicadores de sistema para gerenciamento e controle. No entanto, indicadores de sistema estáticos baseados em análise offline não conseguem acompanhar as mudanças no lado do negócio em tempo real. tempo para ajustar os valores estáticos.
Para esse fim, o Katalyst apresenta modelos para ajustar as métricas do sistema. Por exemplo, se pensarmos que o atraso de agendamento da CPU pode ser de x milissegundos, e após um período de tempo, calcularmos através do modelo que o atraso da meta de negócios pode ser de y milissegundos, podemos ajustar dinamicamente o valor da meta para melhor avaliar desempenho dos negócios.
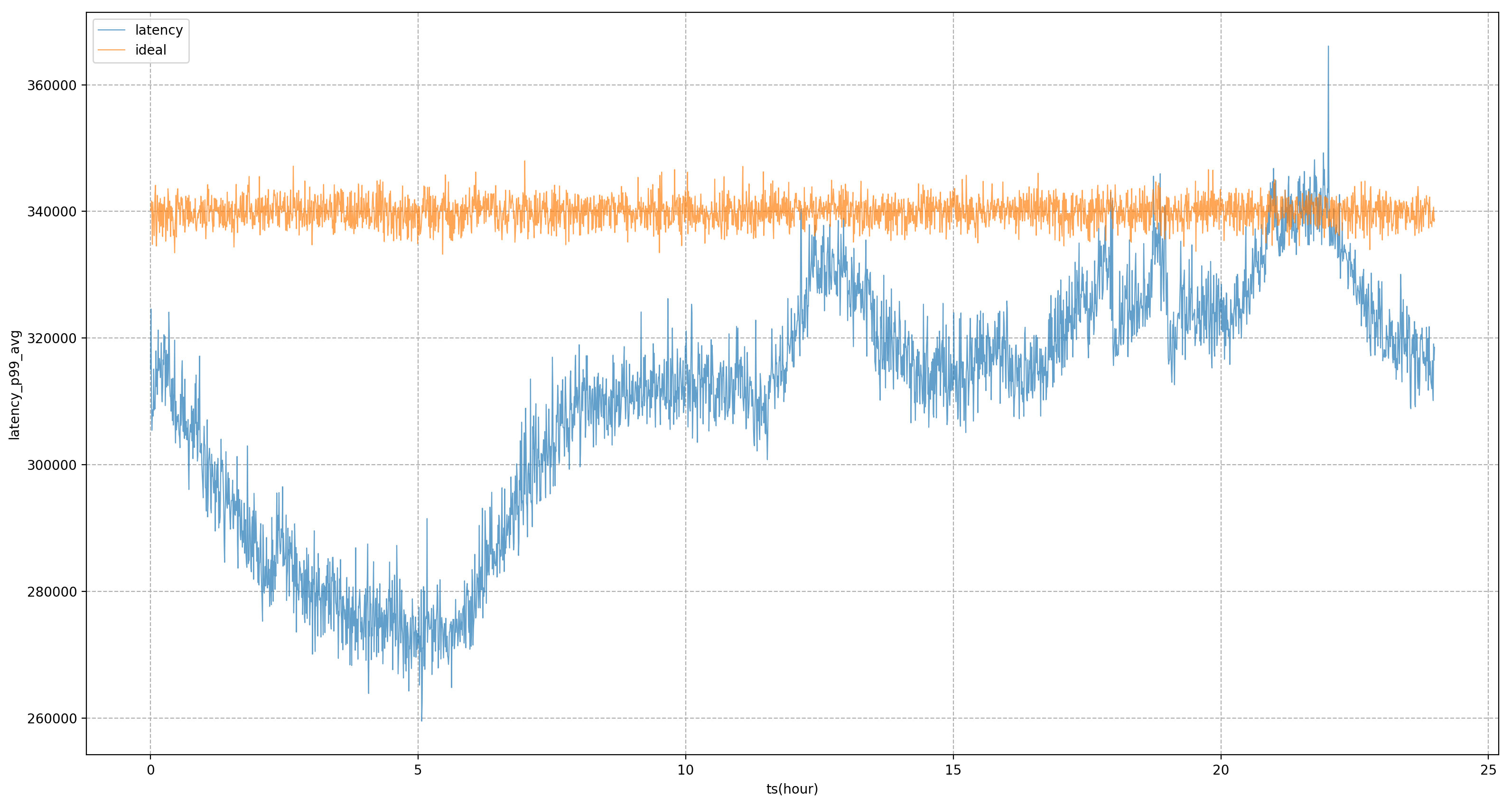
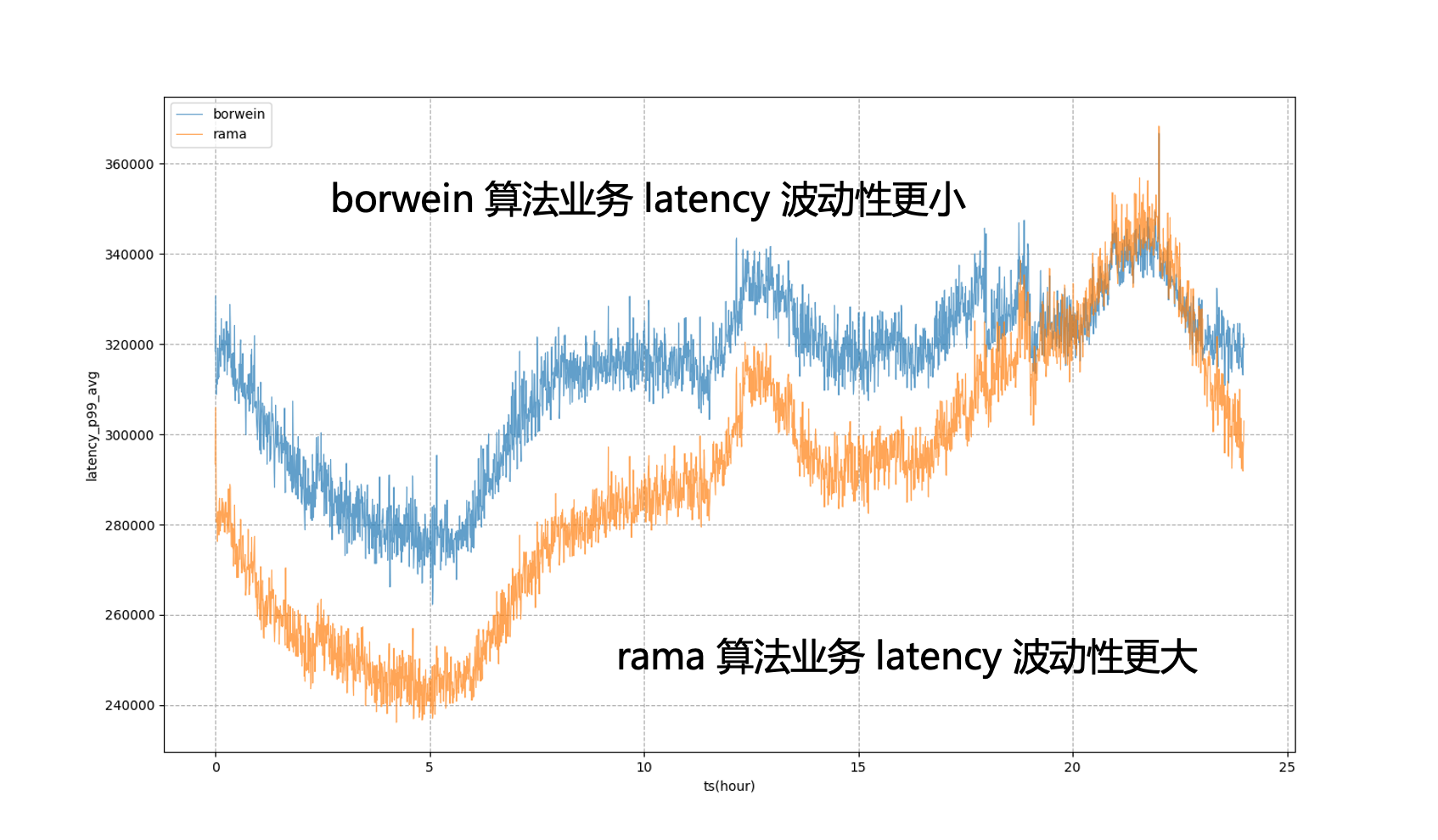
Por exemplo, na figura abaixo, se as metas estáticas do sistema forem completamente utilizadas para regulação, o negócio P99 estará em um estado de flutuação severa, o que significa que durante os horários de pico fora da noite, não podemos reduzir o uso de recursos de negócios a um nível mais alto. estado extremo para torná-lo mais próximo do negócio A quantidade que pode ser tolerada durante o horário de pico noturno após a introdução do modelo, podemos ver que o atraso do negócio será mais estável, permitindo-nos nivelar o desempenho do negócio a um nível relativamente estável; ao longo do dia e obter benefícios de recursos.
4.5 Prática: Resolva problemas de máquina única
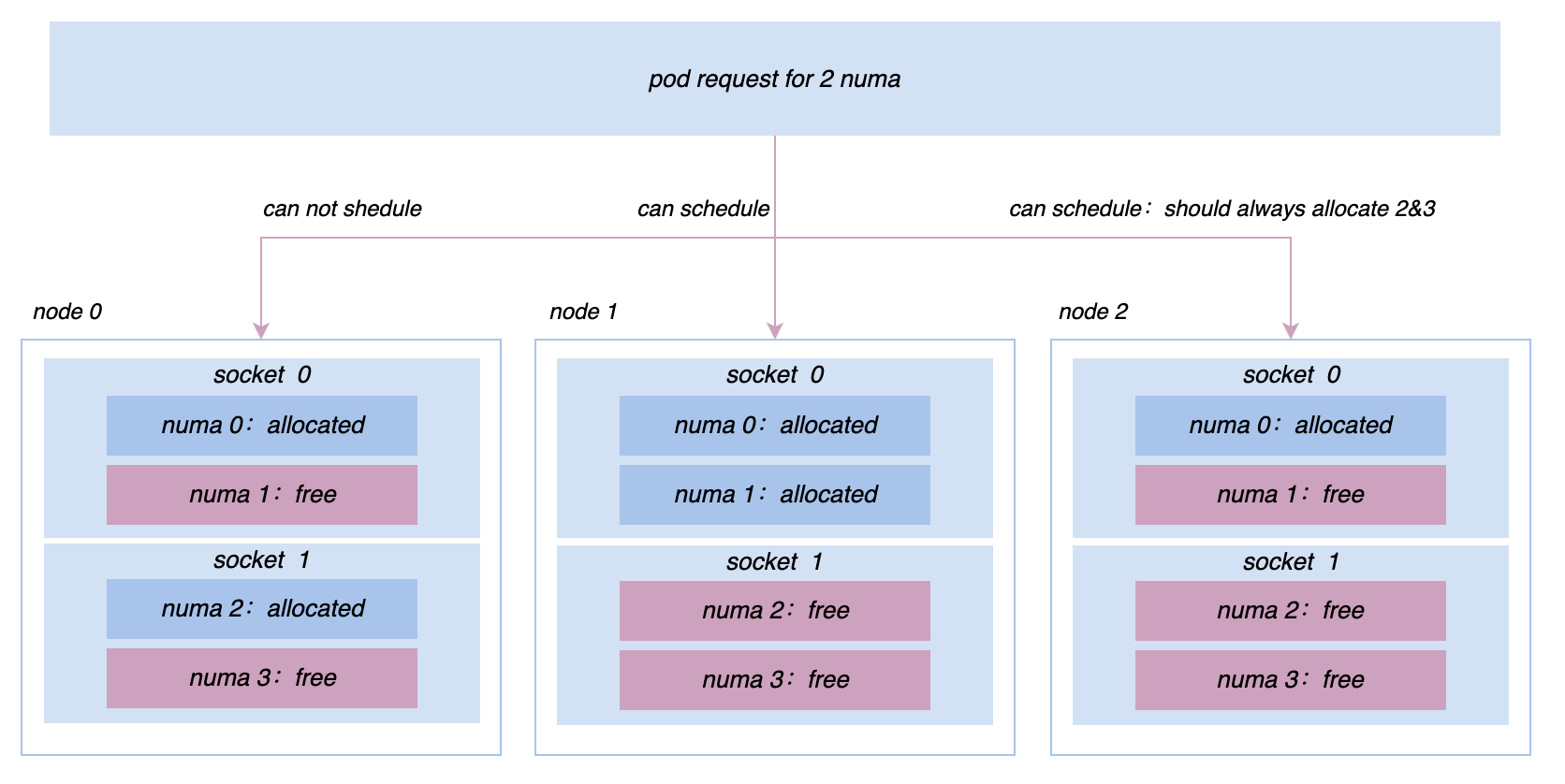
No processo de promoção da co-localização, continuaremos a encontrar vários problemas de desempenho online e offline e demandas para gerenciamento de microtopologia. Por exemplo, inicialmente todas as máquinas eram gerenciadas e controladas com base no cgroup V1. No entanto, devido à estrutura do V1, o sistema precisa percorrer uma árvore de diretórios muito profunda e consumir muita CPU no modo kernel para resolver este problema. , estamos mudando os nós de todo o cluster para cgroup V1. A arquitetura cgroup V2 nos permite isolar e monitorar recursos de forma mais eficiente para serviços como busca de promoção, para buscar um desempenho mais extremo, precisamos implementar afinidades mais complexas; e estratégias anti-afinidade no nível Socket/NUMA, etc. Etc., esses requisitos de gerenciamento de recursos mais avançados podem ser melhor realizados no Katalyst.
5 Resumo e Perspectivas
Katalyst foi oficialmente de código aberto e lançou a versão v0.3.0 e continuará a investir mais energia na iteração; a comunidade construirá recursos e melhorias de sistema em isolamento de recursos, perfil de tráfego, estratégias de agendamento, estratégias elásticas, gerenciamento de dispositivos heterogêneos, etc. , todos são bem-vindos para prestar atenção, participar deste projeto e fornecer feedback.
Companheiro de frango, deepin-IDE de "código aberto" e finalmente conseguiu a inicialização! Bom cara, a Tencent realmente transformou o Switch em uma "máquina de aprendizagem pensante" Revisão de falhas e explicação da situação da Tencent Cloud em 8 de abril Reconstrução de inicialização de desktop remoto RustDesk Cliente Web Banco de dados de terminal de código aberto do WeChat baseado em SQLite WCDB inaugurou uma grande atualização Lista de abril TIOBE: PHP caiu para o nível mais baixo, Fabrice Bellard, o pai do FFmpeg, lançou a ferramenta de compressão de áudio TSAC , o Google lançou um grande modelo de código, CodeGemma , isso vai te matar? É tão bom que é de código aberto - ferramenta de edição de imagens e pôsteres de código abertoVídeo do discurso da conferência: Katalyst: Bytedance Cloud Native Cost Optimization Practice |