

Autor | Wunan
Introdução
O nível de PV do log transmitido diariamente pelo centro de log pode chegar a centenas de bilhões.Dados de log redundantes podem ser reduzidos durante o processo de relatório, o que pode reduzir a dificuldade e o custo do processamento de dados downstream, melhorar a precisão e a qualidade dos dados e melhor suporte Operação e otimização de sistemas empresariais. Este artigo apresenta a prática de otimização do UBC SDK para empacotamento de duplicação de log. Ao otimizar o banco de dados, o processo e o mecanismo de gerenciamento, ele reduz efetivamente a taxa de duplicação no nível de log de três milésimos para dez milésimos.
O texto completo tem 8.525 palavras e o tempo estimado de leitura é de 22 minutos.
01 Introdução
O artigo primeiro apresenta o histórico de desduplicação da plataforma de log e o mecanismo de gerenciamento do UBC SDK, depois explica as dificuldades e métodos de localização de problemas duplicados e, finalmente, concentra-se na análise e prática de solução de problemas duplicados.
1.1 Histórico da desduplicação de log
O centro de log se concentra na capacitação de todo o ciclo de vida dos logs finais, incluindo funções como coleta, transmissão, gerenciamento, consulta e análise de dados de log, etc., para realizar o gerenciamento completo do ciclo de vida dos dados, resolver problemas como como padronização de logs e unificação de produtos novos e antigos e melhoria da utilização de recursos da plataforma para maximizar o valor do aplicativo de logs.
Para garantir que os dados downstream recebam dados de forma eficiente e precisa, o centro de registro fez otimizações de longo prazo na pontualidade e confiabilidade da transmissão de dados de ponta a ponta e alcançou resultados notáveis. No entanto, essas otimizações também destacaram gradualmente o problema de duplicação de dados.
Problemas duplicados significam que o mesmo log é relatado ao servidor pelo SDK mais de uma vez. Para reduzir o QPS do servidor, o SDK irá empacotar e reportar vários logs, de modo que problemas repetidos podem ser divididos em duas categorias:
1. Duplicação de pacote: O SDK enviou os dados, mas não recebeu o resultado. O servidor foi colocado no disco, mas o pacote no final não foi excluído. Todo o log do pacote é relatado repetidamente.
2. Duplicação de log: Um único log é inserido em vários pacotes e reportado ao servidor com cada pacote.
O servidor do centro de log lançou uma solução de desduplicação de streaming para garantir que não haja duplicação granular de pacotes nos dados downstream. O servidor realiza a desduplicação através do pacote md5, mas o mesmo log sendo inserido em pacotes diferentes resultará em md5s diferentes. Neste caso, o servidor não consegue identificá-lo. Portanto, o pré-requisito para a desduplicação no lado do servidor é que o SDK garanta que os logs relatados não sejam empacotados repetidamente.
1.2 Introdução ao UBC SDK
O SDK UBC (User Behavior Collection), ou seja, o SDK de coleta de comportamento do usuário, é responsável pela coleta, empacotamento, geração de relatórios e outras funções dos logs de gerenciamento de terminal. Ele registra os dados de comportamento do usuário e os carrega no servidor do centro de log. É o fonte do link de transmissão de dados do centro de log.
1.2.1 Tipo de ponto
De acordo com o conteúdo expresso pela gestão, pode ser dividido em gestão de eventos e gestão de fluxo, que registram comportamento único e comportamento de permanência respectivamente.
Diferentes partes de negócios têm requisitos diferentes para a pontualidade dos relatórios pontuais. Do lento ao rápido, ele pode ser dividido em: relatórios não em tempo real, relatórios em tempo real, relatórios diretos e relatórios reais. Existem diferenças nos processos de execução de diferentes tipos de relatórios.
1.2.2 Mecanismo de gestão
O UBC SDK realiza a gravação e transmissão da maioria dos dados na fábrica. Ambas as extremidades podem relatar centenas de bilhões de logs em um único dia. Ele precisa ser relatado com rapidez e precisão, sem afetar a execução do thread principal. Para atingir este objetivo, a UBC tomou as seguintes medidas:
1. Processamento assíncrono em fases : Para garantir a eficiência e estabilidade dos relatórios, o SDK divide internamente todo o processo em vários estágios e os entrega aos threads de tarefas e envia threads para agendamento e execução assíncrona.
2. Armazenamento persistente de logs e pacotes : para garantir que os logs não sejam perdidos, o SDK persistirá os logs no SQLite, persistirá os logs nos arquivos durante o envio e tentará enviar repetidamente até obter sucesso.
3. Vários horários de acionamento de relatórios : para levar em consideração o rendimento e a pontualidade dos relatórios, o SDK acionará relatórios de log em diferentes momentos, como acionamento imediato quando ocorre o gerenciamento em tempo real, acionamento quando o gerenciamento não em tempo real atinge o relatório ciclo, relatando dados de backlog ao alternar entre front e backend ou quando a rede se recupera, etc.
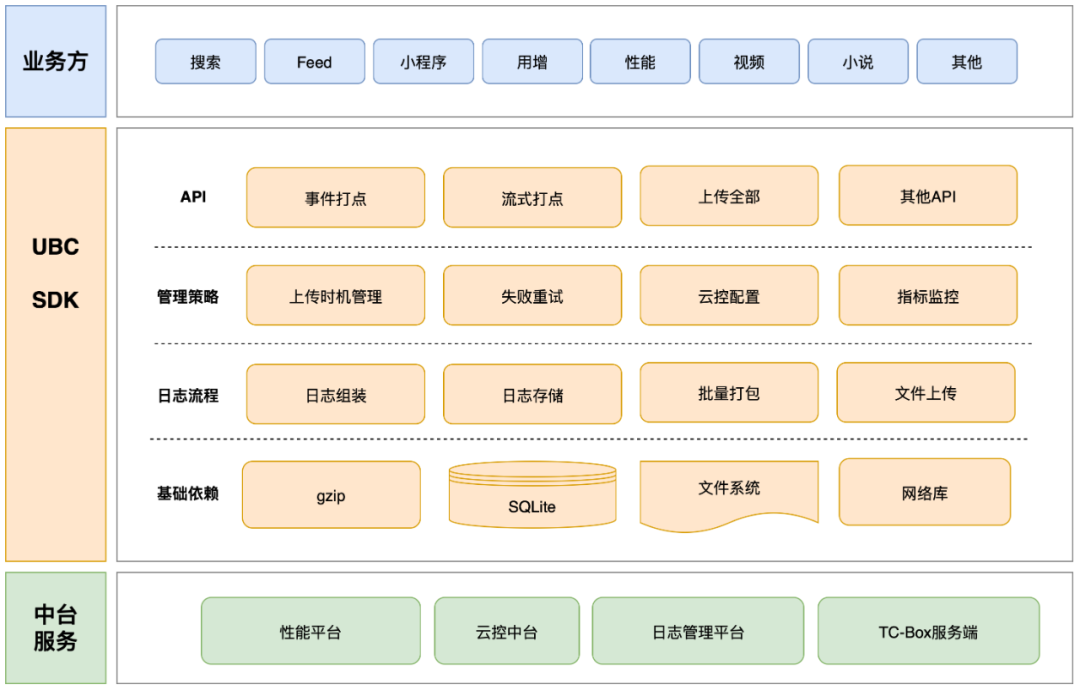
A arquitetura do módulo principal do UBC SDK é mostrada na figura abaixo:
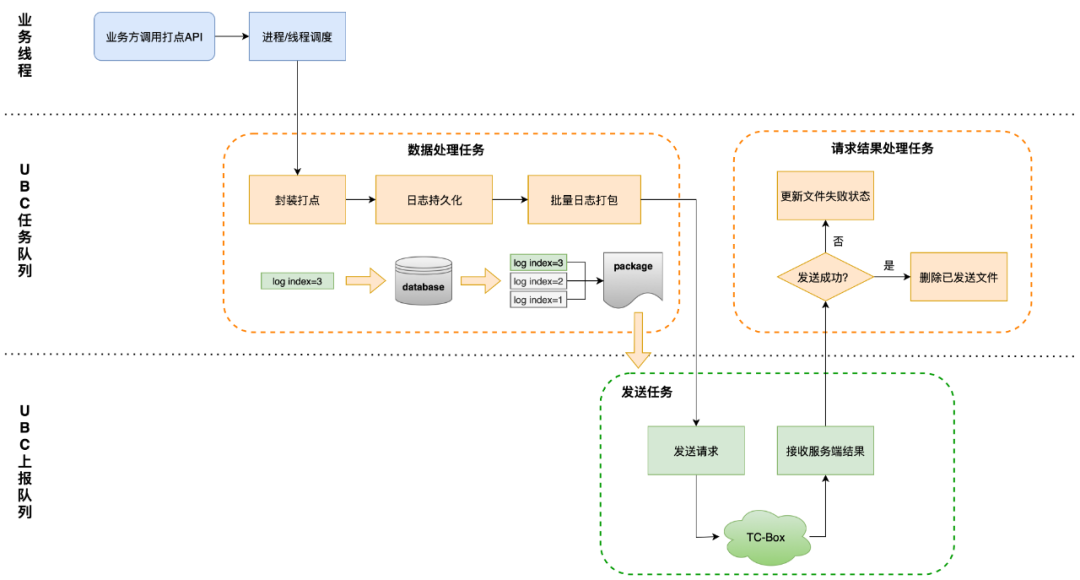
O processo básico de gerenciamento, armazenamento e envio de logs UBC é mostrado na figura abaixo:
02 Meios de posicionamento
2.1 Dificuldades de posicionamento e metodologia
Existem as seguintes dificuldades na solução de problemas de duplicação de log final:
1. Existem muitas partes comerciais que usam o UBC. Diferentes cenários de acionamento são diferentes em diferentes pontos, e os problemas que surgem também são diferentes. É impossível entender os métodos de chamada de todos os serviços.
2. A duplicação de log é causada principalmente por eventos anormais subjacentes de baixa probabilidade, que estão intimamente relacionados ao ambiente local do usuário, à versão do sistema e ao fabricante, e o problema é difícil de reproduzir.
3. UBC SDK é a entrada de dados e afeta todo o sistema. Qualquer modificação no processo de relatório pode causar flutuações nos dados existentes e afetar as estatísticas do negócio.
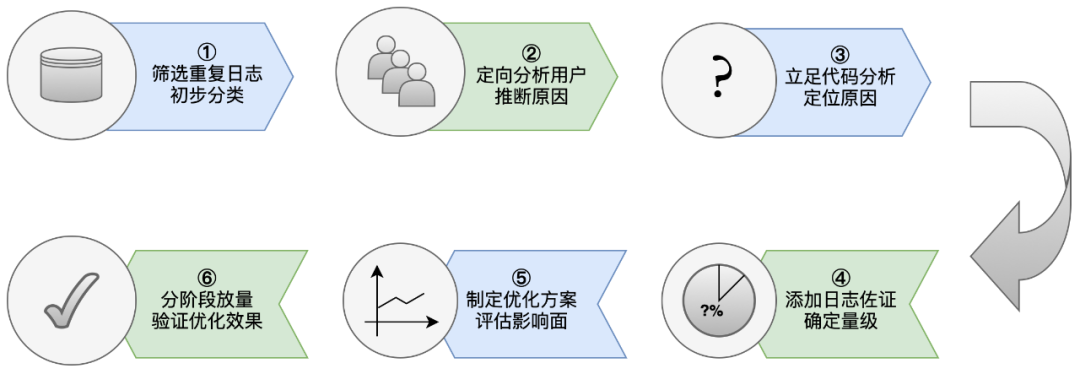
Portanto, este tipo de problema é difícil de solucionar e otimizar através de meios comuns.A UBC formou gradualmente um conjunto de metodologia no processo de tratamento:
2.2 Ferramentas de posicionamento
2.2.1 Identificação de log on-line
Os registos online são a forma mais direta de monitorizar indicadores, incluindo taxas de duplicação. No entanto, encontrar registos duplicados entre centenas de milhares de milhões de dados é como encontrar uma agulha num palheiro.
Portanto, ao localizar problemas duplicados, vários tipos de sinalizadores são cruciais. Eles podem ser usados para identificar e correlacionar diferentes entradas de log para ajudar a determinar quais problemas são duplicados. Através de estatísticas de dados e monitoramento de alarmes, os problemas podem ser descobertos dentro do limite de tempo T+1, e os problemas podem ser analisados diretamente através dos dados brutos que participam das estatísticas.
Para encontrar logs duplicados, primeiro você precisa identificar um log exclusivamente.
Log uuid : UUID (Universally Unique Identifier) é uma string de 128 bits que pode garantir que um objeto ou evento seja identificado de forma exclusiva globalmente, ou seja, um log pode ser identificado de forma exclusiva no mesmo dispositivo para registro e rastreamento. As alterações podem causar flutuações nos dados existentes e afetar as estatísticas comerciais.
Os logs relatados repetidamente ao TC-Box podem ser encontrados através do log uuid. No entanto, para determinar se é um pacote duplicado ou um log duplicado, ele precisa ser julgado com base nas informações da embalagem. Existem duas informações principais de identificação do pacote :
1. Pacote md5 : MD5 (Message Digest Algorithm 5) é uma função hash criptográfica amplamente usada que pode receber dados de qualquer comprimento e gerar um valor hash de comprimento fixo. O UBC calcula o valor md5 através do conteúdo do pacote como identificador do pacote.
2. Tempo de criação do pacote : carimbo de data/hora da embalagem em nível de milissegundos. Como o valor md5 é o mesmo quando o conteúdo do pacote é o mesmo, se o mesmo lote de dados for empacotado várias vezes, ele não poderá ser identificado pelo md5, portanto, md5+createtime precisa ser usado como identificador de identificação para empacotamento repetido.
Além das informações de identificação, outras informações também são necessárias para auxiliar na tomada de decisões, tais como:
1. carimbo de data/hora : o carimbo de data/hora no momento do gerenciamento, que pode ser combinado com logs repetidos antes e depois do gerenciamento para inferir as operações do usuário.
2.appv : O número da versão do aplicativo durante o gerenciamento. Ao avaliar o efeito de otimização, é necessário reduzir a interferência de relatórios atrasados de versões antigas.
3.processo : Execute o ID do processo empacotado e o nome do processo.Quando existem vários processos na instância UBC ao mesmo tempo, a duplicação pode ocorrer devido à insegurança do processo.
4.trigger : Tempo de disparo de empacotamento. Em circunstâncias normais, diferentes tempos de relatório têm frequências diferentes. Frequência anormal de tempo de relatório também pode ajudar a localizar problemas.
5.db_sync : modo de sincronização SQLite, que pode ser usado para auxiliar na verificação de exceções causadas por métodos de write-back do banco de dados do usuário.
2.2.2 Monitoramento anormal
Várias anomalias podem ocorrer durante a execução da CUE. Para detectar essas anomalias em tempo hábil, a CUE precisa ser monitorada através de relatórios e gestão.
Diferentes tipos de monitoramento e gerenciamento de anormalidades carregarão o status de execução de links especiais, pilhas de exceções e outros conteúdos para auxiliar na solução de problemas repetidos, estatísticas de magnitude de exceção e análise de efeito de reparo.
Para evitar situações anormais que impossibilitem a execução do processo normal de UBC, o monitoramento ignorará o armazenamento UBC e armazenará e reportará por meio de desvio.
2.2.3 Gestão empresarial
Como um SDK na camada de serviço, o UBC está desacoplado do negócio, portanto, ele só pode monitorar o comportamento do próprio SDK e não pode obter diretamente o caminho de operação do usuário e as informações do dispositivo.
O gerenciamento do lado comercial ocorre em vários cenários de operações do usuário e pode ajudar a restaurar o comportamento do usuário. Por exemplo, podemos determinar os comportamentos de comutação front-end e back-end e inicialização a frio do usuário por meio da ativação manual de pontos relevantes; exibir os pontos por meio da tela inicial e obter o poder do usuário para determinar se o dispositivo do usuário foi desligado e reiniciado; registre vários status de rede, disco, etc. através de outros pontos. e outras informações.
03 Atribuição e resolução de problemas repetidos
3.1 Problemas relacionados ao banco de dados
Com base no processo de execução de gerenciamento, para solucionar o problema de empacotamento repetido de logs únicos, a primeira coisa que vem à mente é solucionar o estágio de empacotamento de logs em lote.

Existem muitas ramificações lógicas neste link, e as estratégias de execução de gerenciamento em tempo real e não em tempo real são diferentes:
-
Depois que o RBI não em tempo real é acionado, o cache é gravado primeiro e depois o banco de dados é gravado.Depois que o tempo de relatório é atingido, o banco de dados é consultado em lotes e o relatório é acionado;
-
O gerenciamento em tempo real é primeiro gravado no arquivo para acionar o relatório. Se a gravação do arquivo falhar, ele será gravado no banco de dados. Ao gravar o arquivo, o banco de dados será consultado para adicionar um lote de gerenciamento não em tempo real.
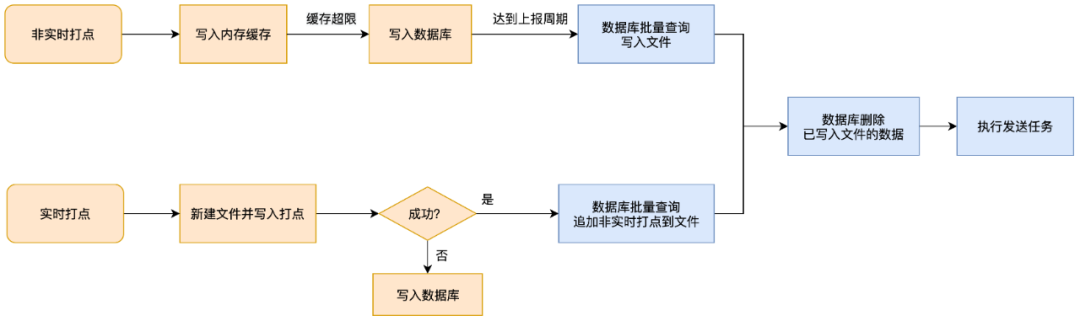
Na análise inicial dos dados repetidos, havia poucos pontos de gerenciamento em tempo real, e a maioria deles eram gerenciamento não em tempo real e gerenciamento de streaming que precisavam ser armazenados no banco de dados. Portanto, no primeiro estágio de solução de problemas duplicados, nos concentramos na solução de problemas relacionados ao banco de dados.
O processo de empacotamento é o processo de “transferência de logs do banco de dados para arquivos em lotes”, os detalhes das etapas mostradas na caixa azul são mostrados na figura abaixo.
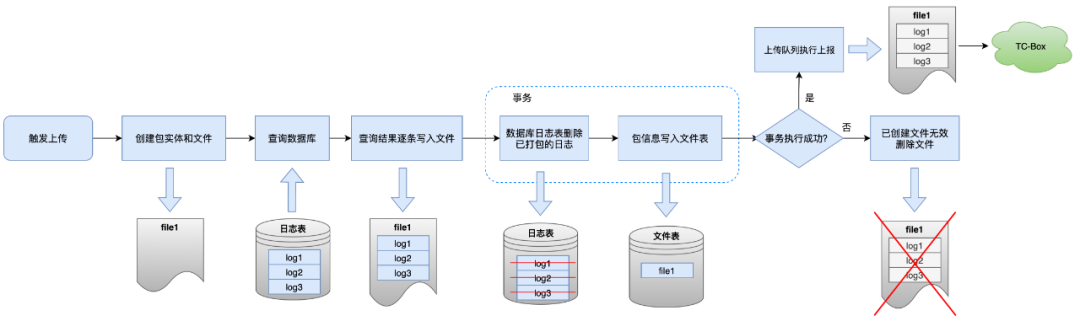
Em circunstâncias normais, se a exclusão do log empacotado no banco de dados falhar após a gravação do arquivo, o SDK encerrará o processo de relatório e excluirá o arquivo gerado, interrompendo o processo de envio para evitar empacotamento repetido.
A intenção original deste link é resolver o problema de envio repetido causado pela leitura direta do banco de dados durante o relatório.No entanto, se houver exceções que o SDK não tenha conhecimento durante o processo, isso fará com que o arquivo atual seja enviado diretamente com sucesso, mas o log não foi excluído. Este lote de logs é o seguinte: Quando for relatado pela primeira vez, será consultado e empacotado novamente, resultando em duplicação.
3.1.1 Corrupção do banco de dados
De acordo com a metodologia de localização de problemas mencionada na Seção 2.1, os usuários duplicados são classificados de acordo com as características dos dados, as causas da duplicação são atribuídas uma a uma e os problemas duplicados em grande parte são localizados como corrupção de banco de dados.
(1) Atribuição de problema
Características dos dados
-
O PV reportado pelos utilizadores num único dia é enorme, com casos graves a atingir milhões (o número médio de PV reportado por um único utilizador num único dia é de cerca de 2.000).
-
A maioria dos logs relatados pelos usuários são logs duplicados e o mesmo log será empacotado várias vezes.
-
O intervalo entre embalagens múltiplas é muito curto e não ocorre partida a frio.
-
A maioria dos pacotes duplicados tem o mesmo md5, mas tempos de criação diferentes, e a condição de acionamento é que o número de itens exceda o limite.
Razão especulação
A exclusão da transação de log empacotada retorna um resultado bem-sucedido e o relata, mas o resultado real da exclusão é uma falha.
análise mais aprofundada
Revisamos o código para exclusão de dados relatados e inicialmente descartamos alguns fatores de influência:
-
Toda a lógica é adicionada com um bloqueio de sincronização para eliminar a influência de outros threads.
-
Exceções de execução SQL serão detectadas e uma falha será retornada. O arquivo atual será excluído e não relatado.
-
Monitoramos a situação em que o número de itens excluídos pelo método delete não era o esperado, mas a magnitude do problema era pequena e tinha pouco impacto na taxa de repetição.
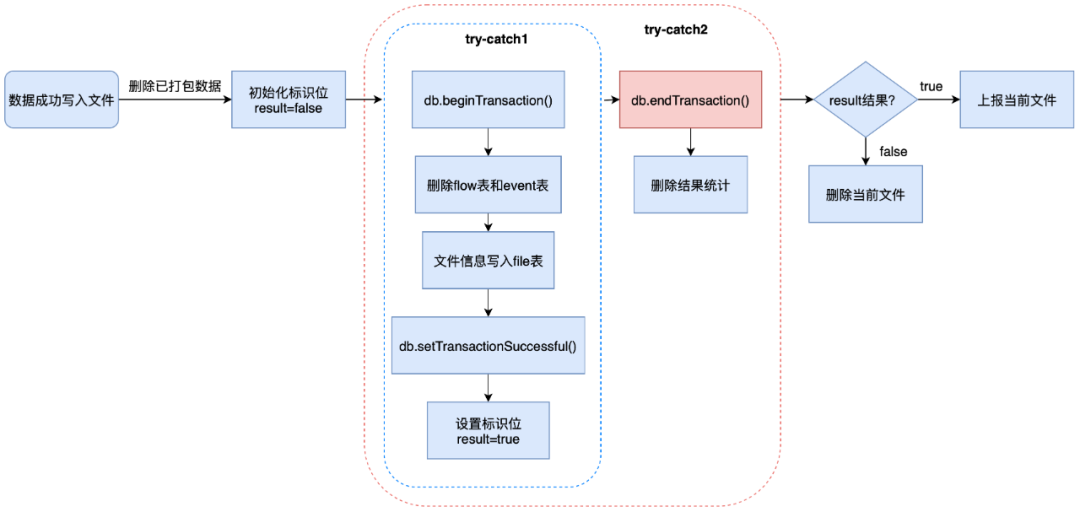
Uma análise mais aprofundada das duas camadas de try-catch no código revelou o problema:
-
Try-catch da camada interna: execute vários SQLs, defina o sinalizador de sucesso da transação após o sucesso e defina o sinalizador de resultado como verdadeiro.
-
Try-catch da camada externa: envia a transação e conta os resultados da exclusão.
Ao entrar na camada externa, o bit de sinalização foi definido como verdadeiro, mas o resultado da transação enviada não foi processado.Infere-se que ocorreu uma exceção não tratada neste link e fez com que a transação fosse revertida.
atribuição de apoio
-
Para determinar a causa da exceção, o monitoramento da exceção SQL é refinado e todas as pilhas de exceções capturadas na classe DatabaseHelper são registradas.
-
Obteve os dados de monitoramento anormais de usuários duplicados e descobriu que havia um grande número de exceções SQL. A pilha é a seguinte: Ocorreu uma exceção de corrupção de banco de dados SQLiteDatabaseCorruptException durante db.endTransaction, o que corrobora os resultados da análise de código.
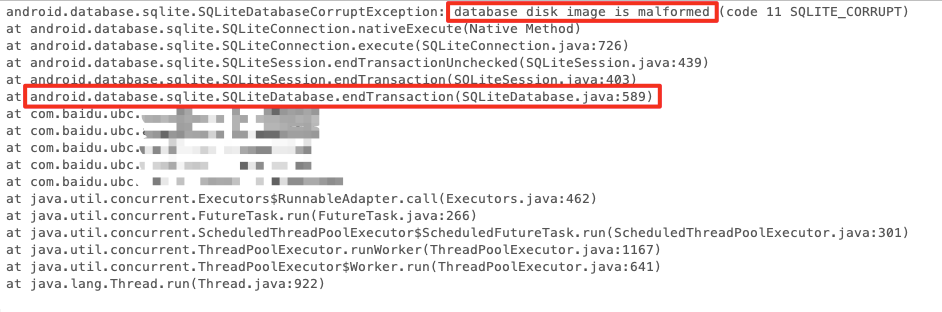
pilha de falhas
-
O site oficial do SQLite também explica o problema de danos ao banco de dados: falha no fsync do arquivo, danos ao disco, gravação anormal de dados e outros problemas durante o processo de leitura e gravação do banco de dados podem causar danos ao banco de dados.

atribuição final
-
A corrupção do banco de dados pode resultar em partes do log legíveis, mas não graváveis.
-
O resultado da execução da exclusão dos dados foi atualizado antes da transação ser confirmada e o relatório foi processado de acordo com o resultado bem-sucedido.No entanto, a transação foi revertida devido a danos no banco de dados e os dados não foram excluídos com sucesso.
-
Depois que cada upload for bem-sucedido, o número de entradas do banco de dados será verificado. Se o limite for excedido, o upload será acionado novamente. A gravação será interrompida depois que um único pacote exceder o limite, resultando em um grande número de relatórios em um curto período de tempo com o mesmo md5 dos pacotes.
(2)Plano de otimização
Para resolver esse problema, é necessária uma otimização em duas etapas em ambas as extremidades:
1. Corrija os resultados da execução da transação do banco de dados e redefina os resultados se ocorrer uma exceção durante o envio da transação;
2. Reconstrua o banco de dados quando ele estiver danificado. Exclua o arquivo do banco de dados e seus arquivos anexados -journal, -shm, -wal. O arquivo do banco de dados será recriado quando o banco de dados for aberto novamente.
avaliação de risco
1. O UBC tem uma alta pontualidade de relatórios. A maioria dos dados pode ser relatada e apagada do banco de dados em 1 minuto. Portanto, apenas alguns dados são geralmente retidos no banco de dados. A exclusão direta de dados perdidos está dentro de um intervalo aceitável.
2. As operações de exclusão e reconstrução de arquivos não devem ser realizadas com frequência. A frequência dos reparos do banco de dados precisa ser limitada e as estatísticas devem ser coletadas para cada operação e resultado de reparo.
3. O risco de reconstrução da base de dados é relativamente elevado, pelo que o método experimental de distribuição direccionada AB é utilizado para confirmar que é eficaz e não tem outros efeitos antes de aumentar gradualmente o volume.
Efeito de otimização
1. No estágio inicial do experimento, a troca experimental foi direcionada a usuários com um grande número de relatórios repetidos, e todos foram reparados com sucesso e a taxa de repetição retornou a 0 após o reparo.
2. Após a implementação completa do experimento, de acordo com estatísticas de monitoramento, mais de 40 desses danos ao banco de dados podem ser reparados com sucesso todos os dias, e não haverá mais um grande número de problemas repetidos.
3. Após a optimização do problema de corrupção da base de dados, a taxa de duplicação do mercado caiu para menos de dois milésimos, uma diminuição de cerca de 0,07 pontos percentuais, representando cerca de 35% do nível antes da optimização.
3.1.2 Falha na gravação do arquivo WAL
(1) Atribuição de problema
Características dos dados
-
Se houver usuários duplicados, um lote de pacotes será empacotado duas vezes.
-
Há partida a frio nas duas embalagens e o intervalo é longo.
-
O último pacote é o primeiro pacote após a inicialização a frio, e a condição de gatilho para o empacotamento é o relatório em tempo real ou o relatório de recuperação de rede.
Razão especulação
Uma falha no nível do sistema no dispositivo do usuário fez com que a operação do banco de dados fosse bem-sucedida, mas o write-back falhou.
análise mais aprofundada
-
A partir do Android 9.0, o modo WAL (Write-Ahead Logging) do SQLite está habilitado por padrão. No modo WAL, o SQLite registrará as operações de modificação no arquivo WAL.Quando o sistema estiver ocioso ou quando a transação for confirmada, uma operação de ponto de verificação será executada e, em seguida, o arquivo WAL será gravado de volta no arquivo de banco de dados no disco . SQLite usa esse mecanismo para evitar operações frequentes de gravação em disco e melhorar o desempenho de gravação e a simultaneidade do banco de dados.
-
Quando a operação de modificação é gravada no arquivo WAL e o arquivo WAL é gravado de volta no arquivo de banco de dados, ele passará pelo processo de primeiro gravar no buffer do disco e, em seguida, executar a operação fsync para liberar o disco. A chave para saber se as transações podem ser recuperadas após uma exceção do sistema está em saber se o arquivo WAL executa o fsync com êxito.
-
Existem dois modos principais de sincronização WAL comumente usados: PRAGMA schema.synchronous = NORMAL | FULL. A diferença entre os dois é que NORMAL retornará o resultado do commit antes que o fsync seja executado ao gravar o arquivo WAL, enquanto o modo FULL irá realmente gravar o WAL para o disco. O resultado é retornado posteriormente.
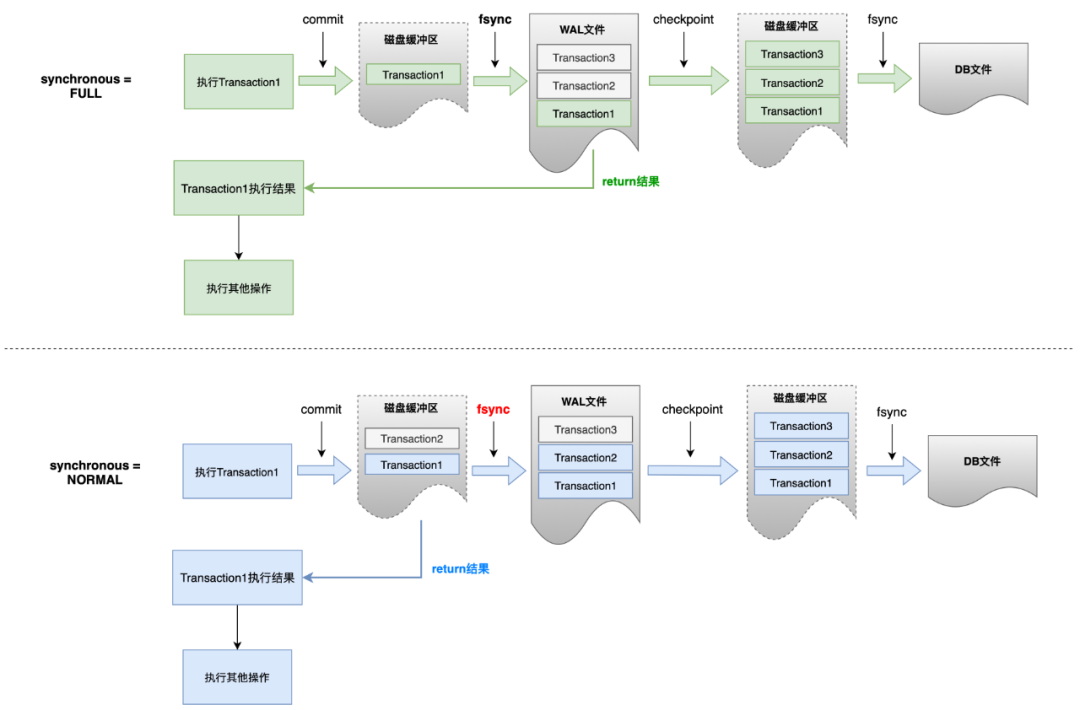
- A documentação oficial do SQLite menciona: No modo NORMAL, o envio da transação pode ser revertido quando há falta de energia ou o sistema trava.

atribuição de apoio
1. Inicie o gerenciamento relacionado para registrar a energia do usuário. Para alguns usuários, a energia foi inferior a 10% durante o pacote anterior. Porém, a energia foi recuperada durante o segundo pacote, indicando que houve um problema de falta de energia durante o período.
2. Traga e relate as informações do modo de sincronização do banco de dados. Foi verificado que os modos de banco de dados dos usuários com problemas tão repetidos são todos NORMAIS.
atribuição final
1. O SQLite do dispositivo do usuário usa o modo NORMAL do WAL.Depois que a transação de exclusão é gravada no buffer do disco WAL e antes que o buffer seja sincronizado com o disco, ocorre uma queda de energia ou falha do sistema.
2. A transação foi considerada bem-sucedida e relatada, mas o arquivo WAL não foi gravado. Portanto, os dados no arquivo do disco não foram excluídos e a exclusão não pode ser executada novamente após a restauração do sistema. Os dados relatados ainda existem.
(2)Plano de otimização
De acordo com o motivo da duplicação, pode-se deduzir a solução para este problema, ou seja, garantir que a operação seja gravada no disco o mais rápido possível após a conclusão da operação do banco de dados.Existem três métodos de execução: (1) Turn desligar o modo WAL; (2) Definir o modo de sincronização para FULL; (3) Executar manualmente o ponto de verificação.
Depois de comparar e testar várias soluções, o lado Android finalmente encontrou uma solução de compromisso: apenas a confiabilidade da transação do banco de dados "Excluir dados empacotados" é garantida. Quando o modo de sincronização é NORMAL, o ponto de verificação é acionado manualmente após a exclusão dos dados, acionando Gravação do arquivo WAL. Insira o arquivo DB e certifique-se de que o SQLite tenha pelo menos concluído a operação fsync do arquivo WAL. O tempo necessário para executar um ponto de verificação é basicamente igual ao tempo necessário para executar uma transação, e a degradação do desempenho está dentro de uma faixa aceitável.
Para garantir que as transações sejam totalmente gravadas no modo WAL no iOS, além de definir o modo de sincronização como NORMAL, você também precisa habilitar a opção fullfsync para garantir estritamente que a ordem de gravação seja consistente com a ordem de envio. Após testes e avaliação, a degradação do desempenho foi maior que o benefício da otimização da taxa de repetição e finalmente optamos por não realizar essa otimização.
Efeito de otimização
-
A falha de gravação do WAL é responsável por cerca de 70% dos problemas de duplicação de cauda longa na nova versão.
-
De acordo com dados experimentais do Android, em uma única hora, o grupo experimental reduziu o empacotamento repetido em mais de 200 vezes em comparação com o grupo de controle.
3.2 Relacionado ao processo
Depois de otimizar o problema de empacotamento repetido causado por danos ao banco de dados, consultamos os dados de mercado e descobrimos que ainda há um problema no lado do Android, onde os logs são inseridos repetidamente em dois pacotes com um intervalo curto e o usuário não tem informações de exceção do banco de dados .
Esse problema de acionar o empacotamento ao mesmo tempo em um curto período de tempo leva naturalmente a outra questão: se o segmento UBC é seguro. No entanto, como mostrado na Seção 1.2.2, existem apenas duas filas dentro do UBC. A leitura do banco de dados e o empacotamento são operações de thread único. Em teoria, não haverá problemas de simultaneidade de thread.
Portanto, voltamos nossa atenção para as questões de segurança de processos no lado do Android:
1. Além do processo principal, o Baidu APP também possui vários subprocessos, como pequenos programas e mídia, diferentes processos chamarão a API de gerenciamento.
2. Para garantir a velocidade de inicialização, o UBC adota um método de inicialização de carregamento lento.Um singleton UBC será inicializado somente quando o processo atual não tiver uma instância UBC.
3. Se a parte comercial chamar a API em um processo não principal, o UBC irá IPC para o thread principal para execução para garantir que apenas o processo principal tenha um singleton UBC no ciclo de vida. Se houver um problema com esse processo, poderá fazer com que outra instância UBC seja inicializada no processo filho.
Quando dois processos possuem singletons UBC ao mesmo tempo, pode ocorrer insegurança no processo, conforme mostrado na figura abaixo.
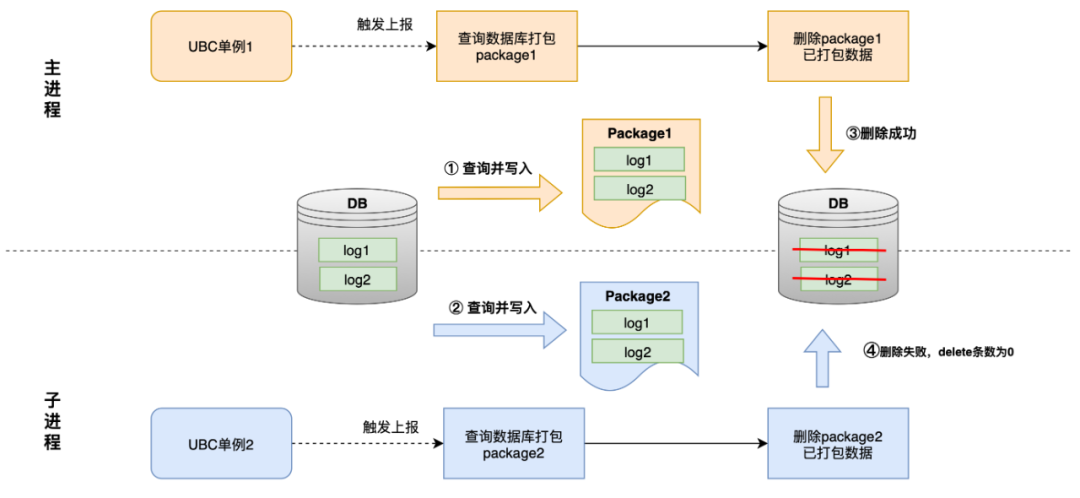
1. Dois processos empacotam e operam o banco de dados simultaneamente. Se um processo executar uma consulta antes que o outro processo exclua os dados, o mesmo lote de dados será gravado em dois arquivos.
2. A sequência de execução das operações de exclusão fará com que a operação de exclusão subsequente retorne um número de exclusão 0 porque os dados não existem, mas o relatório não será encerrado com o lançamento de uma exceção.
Existem dois tipos de razões pelas quais problemas de múltiplos processos levam à inicialização de dois singletons UBC: falha de IPC e falha de julgamento de processo. Os dois problemas têm diferentes manifestações e razões para empacotamento repetido. Eles são apresentados um por um abaixo.
3.2.1 Falha do IPC leva a múltiplas instâncias UBC
(1) Atribuição de problema
Características dos dados
-
Se houver usuários duplicados, um lote de pontos será empacotado duas vezes.
-
O tempo entre dois pacotes é curto (menos de 1s).
-
Entre as condições de acionamento do empacotamento, a recuperação da rede e a comutação em segundo plano ocorrem com frequência.
-
Quando dois dados duplicados são empacotados, o ID e o nome do processo são diferentes.
Razão especulação
Os dois processos possuem instâncias UBC respectivamente, monitoram eventos do sistema simultaneamente e leem o empacotamento do banco de dados.
atribuição adicional
Depois de nos comunicarmos com o lado comercial da estrutura multiprocessos, resolvemos os motivos para a ocorrência de dois casos únicos de UBC e embalagens repetidas:
1. Se ocorrer um erro quando os IPCs da estrutura multiprocessos passarem do processo filho para o processo principal, o gerenciamento de falhas do IPC será acionado no processo filho.
2. Este gerenciamento chama a interface antiga de gerenciamento de multiprocessos abandonada do UBC.A interface antiga permite inicializar um singleton UBC no processo filho e adiciona monitoramento da comutação front-end e back-end e do status da rede.
3. Monitoramento do gatilho de comutação de front-end e back-end e recuperação de rede, fazendo com que duas instâncias UBC executem empacotamento ao mesmo tempo.
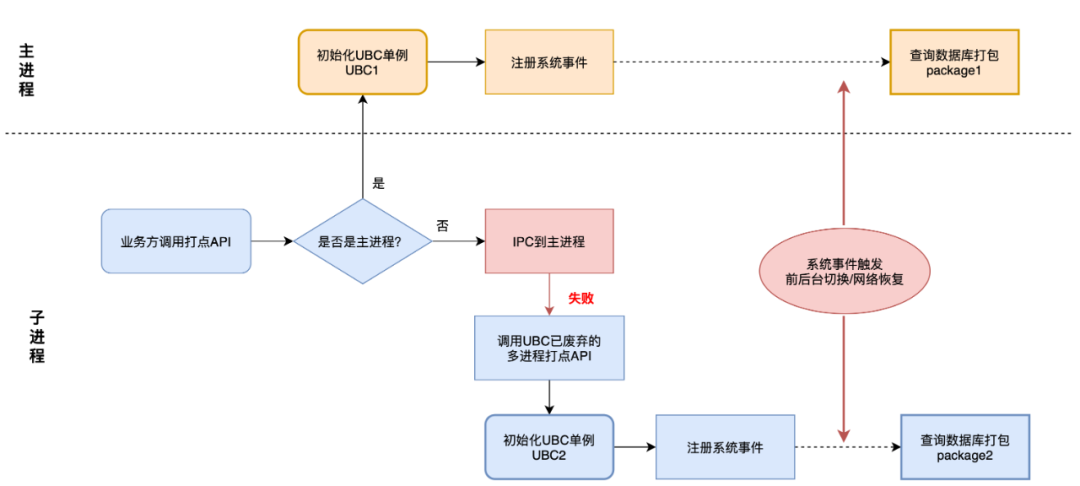
atribuição de apoio
Um dos dois pacotes com problemas repetidos apresenta um ponto de falha do IPC, o que é consistente com a conclusão da análise.
(2)Plano de otimização
Em resposta a este problema, após avaliação de impacto, foi finalmente realizada uma otimização em duas etapas:
1. Quando o subprocesso restringe o empacotamento, a comutação front-end e a recuperação da rede são acionadas, o processo não principal não executa o processo de empacotamento;
2. Otimize a interface de gerenciamento de vários processos, ignore a lógica de agendamento UBC em processos não principais, evite inicializar instâncias e grave pontos de gerenciamento diretamente em arquivos para geração de relatórios.
Efeito de otimização
Após a otimização deste problema, a taxa de duplicação de mercado caiu para menos de um milésimo, uma diminuição de cerca de 0,04 pontos percentuais, representando cerca de 33% da taxa de pré-otimização.
3.2.3 A falha no julgamento do processo leva a múltiplas instâncias de UBC
(1) Atribuição de problema
Características dos dados
-
Se houver usuários duplicados, um lote de pontos será empacotado duas vezes.
-
O tempo entre dois pacotes é curto (menos de 1s).
-
Os gatilhos em tempo real são responsáveis pela maioria das condições de gatilho de embalagem, mas há casos em que ambos são gatilhos não em tempo real. Em circunstâncias normais, o empacotamento que não é em tempo real deve ser separado por pelo menos 1 minuto.
-
Um dos dois pacotes tem gerenciamento acionado pelo subprocesso (como visualizações de páginas do miniprograma), mas não há gerenciamento de falhas de IPC.
Razão especulação
Existem duas instâncias UBC, e os RBIs A e B entram e acionam o empacotamento ao mesmo tempo.As duas instâncias UBC são simultâneas e ambos os RBIs C no banco de dados são consultados e empacotados para geração de relatórios.
atribuição adicional
- Combinando o desempenho dos dados e os resultados de otimização do problema de falha do IPC, o problema não é o relatório simultâneo de dados do backlog causado pela falha do IPC, mas a simultaneidade de múltiplos processos desencadeados pelo RBI.Portanto, o principal ponto de suspeita é o julgamento do processo.
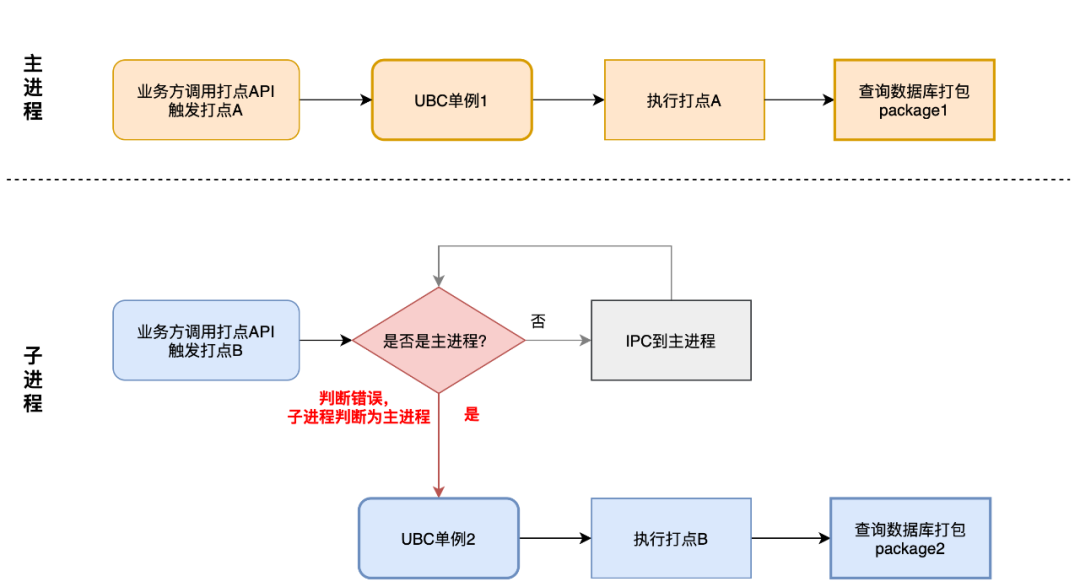
-
O método fornecido pela estrutura multiprocesso é usado para determinar o processo principal.A lógica para determinar se o nome do processo atual é igual ao nome do pacote é o processo principal e obter o nome do processo atual:
-
Ler registros de memória → Obter do arquivo do sistema /proc/self/cmdline → Obter do ActivityManager
-
Se os métodos anteriores não conseguirem obtê-lo, use o nome do pacote como nome do processo.
-
O nome do pacote geralmente é o mesmo do processo principal. Se o nome do pacote for usado como nome do processo no processo filho, isso levará a um erro de julgamento, inicializando outro singleton UBC no processo filho, causando repetidos problemas de empacotamento.
atribuição de apoio
O usuário empacotou o processo duas vezes com o mesmo nome, mas IDs de processo diferentes, o que é consistente com a conclusão da análise do código.
(2)Plano de otimização
Como um SDK de gerenciamento, o UBC não deve prestar muita atenção à lógica de julgamento do processo, portanto, é necessário promover a atualização da estrutura multiprocessos e aumentar a forma de obtenção do nome do processo:
A API 28 do Android adiciona um novo método para obter nomes de processos, Application.getProcessName(), que não requer reflexão e IPC e pode ser usado como um método de julgamento redundante para nomes de processos.
Efeito de otimização
-
Problemas de duplicação causados por falhas de julgamento de processos são responsáveis por cerca de 20% dos problemas de cauda longa de embalagens duplicadas em novas versões.
-
Depois de otimizar o método de julgamento do processo, o número de pacotes repetidos duas vezes em um segundo foi reduzido em cerca de metade.O problema de duplicação de logs de novas versões é causado apenas por dispositivos de versão inferior que não suportam esta API.
3.3 Relacionado ao mecanismo de gestão
3.3.1 registro real
(1) Atribuição de problema
Reallog é um tipo especial de gerenciamento. Ele não armazena em cache após o gerenciamento. Ele apenas executa uma operação de E/S de consulta. Ele carrega dados históricos de falha e os reporta diretamente para a memória. Depois que o relatório falha, ele é gravado no banco de dados .
Este mecanismo é configurado para garantir a pontualidade final do relatório de dados, mas sob circunstâncias anormais causará o empacotamento repetido do reallog: o log foi relatado com sucesso e colocado no disco, mas o resultado do servidor não foi retornado a tempo, e o UBC armazena o log de acordo com a lógica de falha.Entre no banco de dados e seja consultado e informado quando o próximo gerenciamento de reallog for acionado.
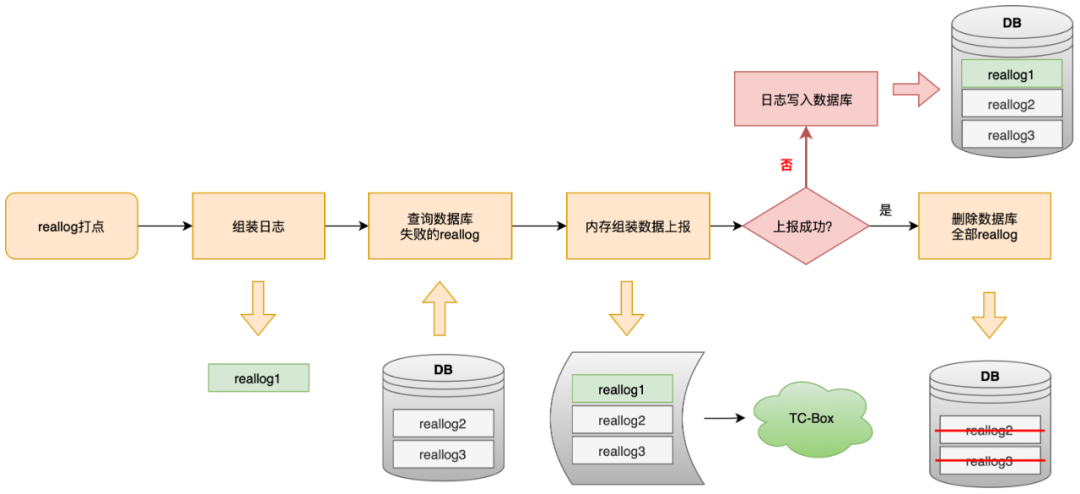
Conforme mostrado na figura acima, o gerenciamento do tipo reallog será empacotado e relatado de forma independente, e o sinalizador reallog=1 será carregado na URL. Use este identificador para verificar dados duplicados, o que comprova o problema de duplicação causado pelo reallog.
(2) Plano de otimização
Para otimizar o problema do reallog, duas soluções podem ser adotadas: a duplicação de logs é convertida em duplicação de pacotes ou o gerenciamento de reallogs é degradado para gerenciamento em tempo real.

Avaliação do caso:
-
Por ser um tipo especial de gerenciamento, o reallog não pode ser configurado através da central de logs, é utilizado apenas por poucos empresários, é uma gestão que não atende aos padrões da central.
-
Após várias rodadas de otimização de pontualidade, o atual percentil 97 de pontualidade do gerenciamento comum em tempo real é de cerca de 0,5 minutos, o que é suficiente para atender às necessidades das partes comerciais.
Depois de avaliar os custos e benefícios das duas opções e confirmá-los com as partes comerciais relevantes, foi finalmente decidido otimizar através de reallog off-line gradual por meio de experimentos e, ao mesmo tempo, alcançar a convergência do tipo de ponto UBC.
Efeito de otimização
-
Cerca de 10% dos problemas de duplicação de cauda longa em novas versões são causados pelo reallog.
-
Depois que o reallog estiver offline, não haverá mais duplicação desse tipo em ambas as extremidades e não terá impacto no uso de partes comerciais relacionadas.
04 Resumo e Perspectivas
Relatar logs com precisão e eficiência é a intenção e o objetivo original do UBC SDK como fonte de dados de log. Após esforços de longo prazo, a UBC melhorou muito sua pontualidade e taxa de chegada. Desta vez, exploramos e otimizamos os problemas que foram relatados repetidamente, descobrimos e resolvemos vários problemas e perigos ocultos no processo de gerenciamento do SDK, e iremos A taxa de duplicação de log é reduzido de três milésimos para menos de um milésimo, fornecendo dados mais confiáveis para dados downstream.
Ao mesmo tempo, acumulamos uma experiência valiosa na solução de vários problemas de gerenciamento final, otimizamos logs locais e construímos um monitoramento mais detalhado do processo de execução do SDK, estabelecendo uma base sólida de dados para descobrir e localizar rapidamente problemas no futuro.
--FIM--
Leitura recomendada
Baidu pesquisa modelo de aprendizagem profunda prática de negócios e otimização
Prática de aplicação de grandes modelos na área de detecção de defeitos de código
Fale com o InfoQ sobre o mecanismo de busca de alto desempenho de código aberto do Baidu, Puck
O Alibaba Cloud sofreu uma falha grave e todos os produtos foram afetados (restaurados). O Tumblr esfriou o sistema operacional russo Aurora OS 5.0. Nova UI revelada Delphi 12 e C++ Builder 12, RAD Studio 12. Muitas empresas de Internet recrutam urgentemente programadores Hongmeng. Hora do UNIX . está prestes a entrar na era de 1,7 bilhão (já entrou). Meituan recruta tropas e planeja desenvolver o aplicativo do sistema Hongmeng. Amazon desenvolve um sistema operacional baseado em Linux para se livrar da dependência do Android do .NET 8 no Linux. O tamanho independente é reduzido em 50%.O FFmpeg 6.1 "Heaviside" é lançado