Resumo: Este artigo foi compilado a partir do compartilhamento de Yuan Kui, um engenheiro de pesquisa e desenvolvimento de motores em tempo real, na sessão de integração de dados Flink Forward Asia 2022. O conteúdo deste artigo está dividido basicamente em quatro partes:
- O serviço em tempo real da Xiaohongshu reduz os custos e aumenta o histórico de eficiência
- Flink e prática híbrida offline
- Problemas encontrados na prática e soluções
- perspectiva futura
Clique para ver o vídeo original e PPT de fala
1. O pano de fundo da redução de custo de serviço em tempo real de Xiaohongshu e aumento de eficiência
1.1 Recursos dos cenários de uso do Xiaohongshu Flink

Os recursos Flink de Xiaohongshu incluem os três itens a seguir:
-
Primeiro, arquitetura nativa de nuvem, multinuvem complexa, doméstica e estrangeira. Desde a sua criação, Xiaohongshu construiu todos os seus sistemas técnicos na nuvem pública e é um nativo da nuvem no verdadeiro sentido.
Cooperamos com muitos fornecedores de nuvem, como AWS, Tencent Cloud, Huawei Cloud, Alibaba Cloud e assim por diante. Após anos de desenvolvimento, os dados de negócios também foram distribuídos para diferentes fornecedores de nuvem. A própria nuvem nativa trará benefícios naturais, como isolamento de recursos e expansão são muito fáceis.
-
Em segundo lugar, o link de integração de dados é longo e há um fenômeno em que os recursos são desviados uns dos outros durante os horários de pico. Tomemos a integração de dados como exemplo: na arquitetura multinuvem, os dados geralmente são transmitidos entre nuvens, portanto, as tarefas de integração de dados são importantes e indispensáveis. Construímos um cluster exclusivo para integração de dados do Flink no passado, mas com o aumento das tarefas de integração de dados, ocorreu cada vez mais preempção de recursos.
Como as tarefas de integração do Flink são todas tarefas em lote, a maioria delas será executada intensivamente ao mesmo tempo no início da manhã, e algumas tarefas falharão porque não podem aproveitar os recursos. Ao mesmo tempo, a taxa de utilização geral de todo o pool de recursos também é relativamente baixa, porque há relativamente poucas tarefas em lote em execução durante o dia e os recursos estão ociosos neste momento.
-
Em terceiro lugar, os trabalhos de integração de dados de alta e baixa qualidade são executados pelo mecanismo de modo de fluxo Flink. Existem algumas razões históricas, uma é que o mecanismo de modo de lote da versão inicial do Flink não está maduro e o outro é que o modo de fluxo é relativamente simples, é rápido e não há necessidade de considerar o problema de dados intermediários armazenar. É uma escolha melhor quando os recursos são abundantes.
1.2 Serviço de integração de dados Xiaohongshu Flink

Existem muitos tipos de integração de dados típicos em Xiaohongshu, como Hive para Clickhouse, Hive para Doris, Hive para MySQL, Mongo para Hive, etc.
O lado direito da figura acima é uma imagem superior. Uma fonte de dados executa uma junção de pesquisa Mongo, que é dividida em dois fluxos e gravada no downstream. Essa é uma tarefa típica de integração de dados do Flink.
1.3 Requisitos Ambientais Gerais para Redução de Custos e Aumento de Eficiência

Com o desenvolvimento de Xiaohongshu, a infraestrutura tornou-se cada vez mais perfeita e o uso de recursos tornou-se mais padronizado. A era da aplicação bárbara de recursos no passado acabou e agora estamos prestando cada vez mais atenção à utilização da CPU do cluster.
Neste contexto, vejamos os clusters de recursos do Flink. Por um lado, nosso atual cluster de recursos Flink adota principalmente o modo exclusivo, e alguns pools de recursos pequenos têm menos tarefas, que são propensas à fragmentação e desperdício de recursos. Por outro lado, o cluster de tarefas de integração do Flink tem preempção de recursos à noite, mas não pode ser usado durante o dia porque os recursos estão ociosos, o que fará com que a taxa geral de utilização de recursos seja baixa.

Para os dois problemas acima, quais são as soluções para melhorar a utilização geral dos recursos? Pode ser dividido em dois pontos a seguir:
- Primeiro, como evitar clusters de pequena escala. Podemos mesclar clusters de pequena escala e, em seguida, cooperar com K8s Resource Quota para isolamento de recursos. Além disso, temos uma solução melhor, que é usar o cluster misto off-line fornecido pela equipe de contêineres. Migre as tarefas do cluster de pequena escala para o cluster híbrido offline e libere os recursos do cluster de pequena escala.
- Em segundo lugar, como reduzir a preempção de recursos durante os períodos de pico. Do ponto de vista da plataforma, podemos otimizar o agendamento de recursos e refinar a prioridade das tarefas. Do ponto de vista do mecanismo Flink, podemos promover o mecanismo de modo de lote do Flink, porque o mecanismo de modo de lote tem menos requisitos de recursos. Mas nosso ponto de entrada é diferente, nós o consideramos do ponto de vista dos recursos.
1.4 Comparação do modo de fluxo/batch do Flink sob a perspectiva de redução de custos e aumento de eficiência

Em seguida, vamos comparar o modo de fluxo e o modo de lote do Flink da perspectiva dos recursos.
O mecanismo de modo de fluxo do Flink não tem conceito de estágios quando está em execução e os dados fluem na forma de pipelines. Isso requer que todos os operadores e recursos simultâneos estejam prontos em tempo real para que o programa possa ser executado normalmente. Para o mecanismo de modo em lote, as tarefas são divididas em vários estágios, e o próximo estágio só pode ser executado após a conclusão do estágio anterior, e apenas alguns operadores e recursos obtidos simultaneamente podem ser executados.
De outro ponto de vista, algumas tarefas em lote do tipo agregação inevitavelmente apresentarão estado e marca d'água ao executar no modo de fluxo, o que requer mais recursos de CPU e memória. No mecanismo do modo de lote, o estado e a marca d'água não são necessários, apenas os dados intermediários do Shuffle, que também têm altos requisitos de disco, mas o disco é mais barato que a CPU e a memória.
Esta é a comparação entre o modo de fluxo e o modo de lote da perspectiva dos recursos e também algumas considerações para alternar tarefas de lote do modo de fluxo para o modo de lote para execução.
2. Flink e prática híbrida offline
Cluster K8s 2.1 em implantação mista off-line

Vamos primeiro ver o que é mixagem off-line. Geralmente, as empresas terão dois tipos de serviços. Um deles é o serviço online, caracterizado por longo tempo de execução e natureza de maré do tráfego de serviço e utilização de recursos. Ou seja, quando houver muitos usuários durante o dia, a taxa de utilização dos recursos será alta e o tráfego será alto, e quando o número de usuários diminuir à noite, a taxa de utilização dos recursos também cairá. O outro é o trabalho offline. Ele será executado apenas por um período de tempo e a taxa de utilização de recursos é muito alta durante o período de execução e geralmente não é sensível a atrasos. Desde que a execução termine antes de um determinado ponto de tempo, os recursos ficarão ociosos.
A chamada mixagem off-line refere-se ao uso de recursos ociosos em serviços on-line para operações off-line para melhorar a utilização geral dos recursos. Para negócios off-line, pode reduzir bastante o custo de uso de recursos. Durante a execução mista de tarefas off-line, os serviços on-line precisam ser protegidos e operações como supressão de recursos podem ser executadas na operação de serviços off-line.
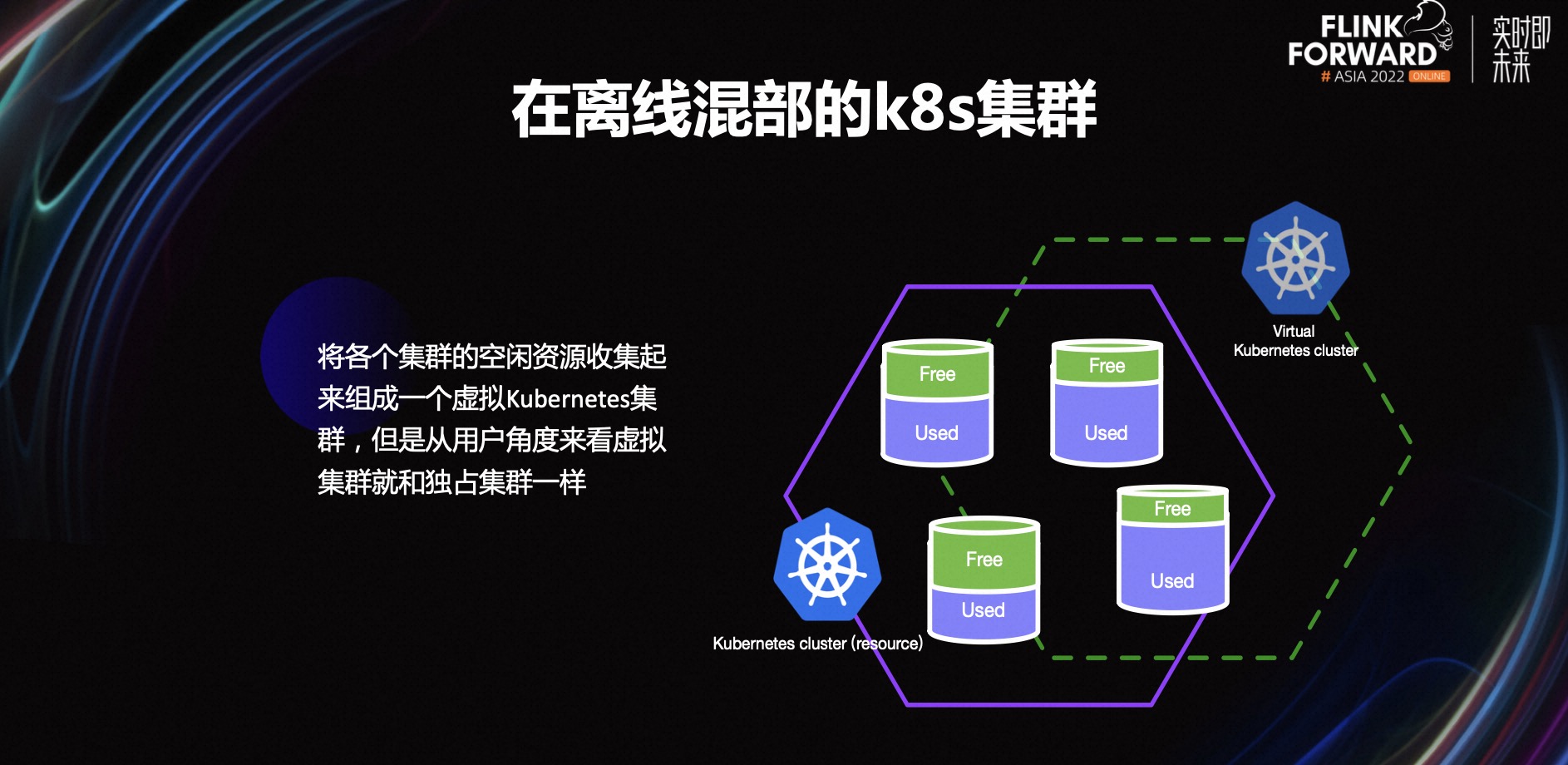
A figura acima é um diagrama esquemático de um cluster híbrido offline. A equipe do contêiner coleta os recursos ociosos de cada cluster de serviço online para formar um cluster de recursos. Do ponto de vista do usuário, apenas alguns nós virtuais podem ser vistos, mas na verdade cada nó virtual corresponde a um ou mais nós de recursos reais. Para os usuários, a utilização dos clusters virtuais é a mesma dos clusters exclusivos reais, a única diferença é que os recursos dos nós virtuais podem estar em constante mudança. A equipe de contêineres forneceu um cluster híbrido offline e, por acaso, tínhamos tarefas offline e pressão sobre a utilização de recursos, então deu certo.
2.2 Recursos de tarefas off-line adequadas para mixagem off-line

Quais tarefas são adequadas para migração, as principais considerações são as três características a seguir:
-
A primeira é que as tarefas migradas não devem ser sensíveis a atrasos, porque os recursos off-line serão compactados no cluster misto off-line e o tempo de execução das tarefas off-line pode ser maior.
-
A segunda é que as tarefas devem ter características de marés, sendo necessário selecionar tarefas off-line que rodam em grande número apenas quando os recursos estão ociosos e migrar para elas. De um modo geral, os serviços online possuem recursos relativamente ociosos à noite, enquanto as tarefas offline são concentradas e rodam mais à noite, o que é mais adequado.
-
A terceira é ter tolerância a falhas, porque os recursos das tarefas off-line podem ser compactados e os pods podem ser removidos durante a mixagem off-line, portanto, as tarefas precisam ter certa tolerância a falhas.
2.3 Tarefas do Flink adequadas para mixagem offline

Para tarefas em lote, como o Pod pode ser removido, quando removido, pode consumir novamente os dados quando é puxado para outros nós, resultando em duplicação de dados, portanto, temos que escolher o lado Sink para suportar a inserção idempotente ou não care Migração de tarefas em lote de dados duplicados. Para o mecanismo do modo de lote, precisamos encadear todos os operadores o máximo possível e selecionar essa parte da migração da tarefa. Porque se os operadores não estiverem encadeados, os dados intermediários serão colocados no disco, que terá requisitos maiores nos nós de recursos. Tente escolher a migração de tarefa em lote que é executada em grande número à noite, porque os recursos do cluster misto off-line ficam relativamente ociosos à noite. Geralmente, um cluster misto off-line não é adequado para tarefas de upstream, mas como ele possui alguns recursos ociosos durante o dia que podem suportar parte das tarefas de streaming, também optamos por migrar algumas tarefas de streaming de baixa qualidade e essas tarefas de streaming precisam ser capaz de tolerar Fail Over, um atraso é permitido por um período de tempo.
2.4 Flink e co-construção offline
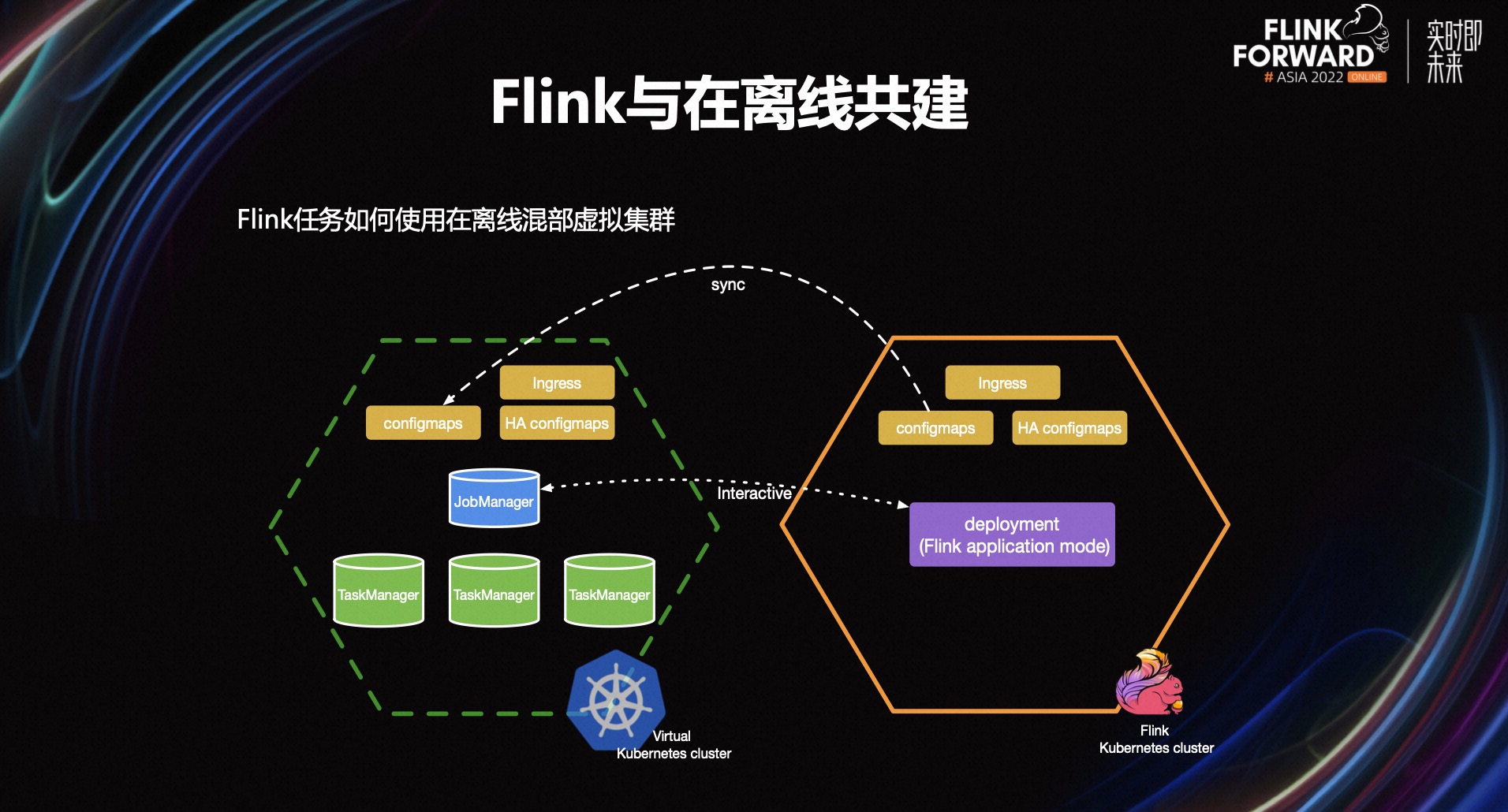
Primeiro, implantaremos um cluster exclusivo do Flink sem nós exclusivos e, em seguida, a equipe de contêineres implantará os nós virtuais em nosso cluster exclusivo. Atrás do nó virtual está um controlador e um nó de recurso real. Quando enviamos uma tarefa, precisamos apenas enviar a tarefa para o nó virtual, e a implantação puxará o JobManager Pod no nó virtual. Finalmente, o processo de criação será enviado pelo controlador do nó virtual para o nó de recurso real atrás dele para execução.
Usamos o método Flink Native K8s, então o TaskManager é puxado pelo JobManager. Este processo de criação é o mesmo da implantação, e também será enviado pelo nodo virtual ao nodo de recurso real para execução. Ou seja, no final, todos os pods de JobManager e TaskManager são executados nos nós de recursos atrás deles e há apenas uma imagem espelhada dos pods nos nós virtuais. Para recursos do K8s, como Configmaps, Service e Ingress, seus dados de origem são armazenados no ETCD e apenas uma parte deles precisa ser sincronizada.
Dessa forma, podemos enviar tarefas normalmente no cluster exclusivo do Flink e operar o Pod por meio do comando kubectl normalmente. Para nós, usar um cluster virtual offline é o mesmo que usar um cluster exclusivo do Flink normal. Claro, existem alguns problemas no processo de implementação. Por exemplo, JobManager e TaskManager pertencem a dois clusters, como se comunicar entre eles, como coletar logs e indicadores de monitoramento, etc. não entre em detalhes aqui.
3. Problemas encontrados na prática e soluções
A última parte é sobre alguns problemas que encontramos na prática. Como nativos da nuvem, as perguntas aqui também se concentram em alguns problemas e soluções que encontramos na nuvem nativa.
3.1 Evite a permanência de arquivos de dados temporários no host
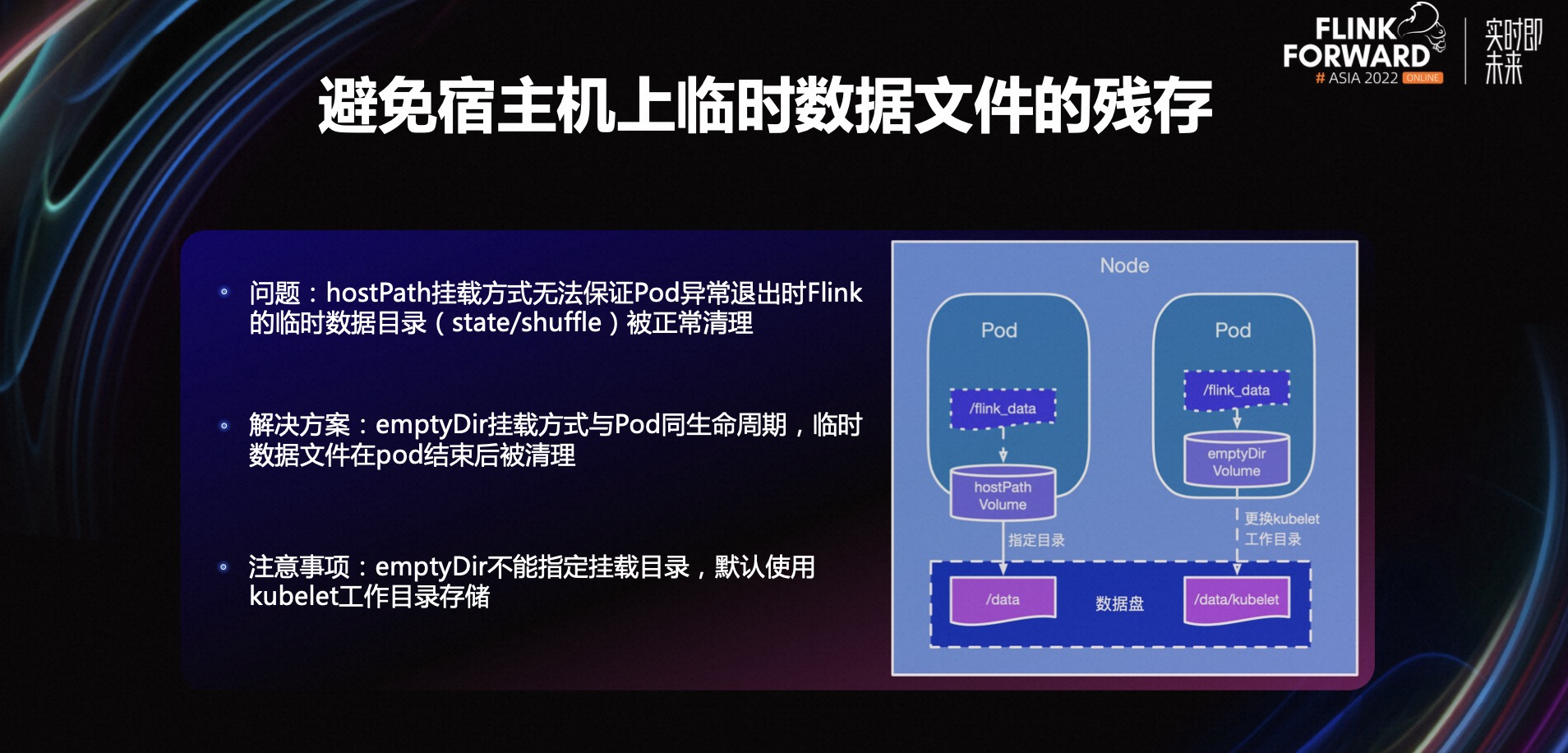
A primeira questão é como evitar os restos de arquivos de dados temporários na máquina host. Qualquer pessoa que tenha usado a tecnologia de contêiner K8s encontrará esse problema.Por padrão, um contêiner é iniciado e os arquivos de dados temporários no contêiner são armazenados no disco do docker. Se o arquivo de dados temporário for muito grande, isso afetará a estabilidade de execução do docker. Neste momento, podemos montar outro disco de dados no contêiner e permitir que o arquivo de dados temporário seja gravado neste disco de dados, para que não afete a estabilidade de funcionamento do sexo do docker.
Em K8s, os discos de dados geralmente são montados por meio do método de montagem de volume hostPath. A vantagem desse método é que o diretório de montagem de um host pode ser especificado. O método de montagem é simples, mas o método de montagem hostPath depende da limpeza dos arquivos temporários de o próprio programa.lógica. Se o Pod sair de forma anormal, por exemplo, quando encontrar OOM e for eliminado por K8s, a lógica de limpeza do arquivo de dados temporário não teve tempo de ser executada e o Pod foi encerrado, então o arquivo de dados temporário permanecerá na máquina host. Quando houver mais e mais arquivos restantes, ocupando todo o disco de dados, isso afetará a estabilidade da operação da tarefa. Então, como resolvemos isso?
O K8s possui um método de montagem chamado emptyDir, que tem o mesmo ciclo de vida do Pod. Portanto, independentemente de o Pod terminar normalmente ou anormalmente, os arquivos de dados temporários no diretório de montagem emptyDir serão limpos após o término, o que reduz a dependência da lógica de limpeza do programa.
Uma coisa a observar aqui é que emptyDir não pode especificar o diretório de montagem e o diretório de trabalho do kubelet é usado por padrão para armazenamento. Geralmente, este diretório está no disco do sistema. Se nenhum processamento for feito, a gravação de arquivos temporários no disco do sistema pode afetar a estabilidade da operação do sistema. Portanto, geralmente precisamos alterar o diretório de trabalho do kubelet para outro disco de dados durante a inicialização .
3.2 Problema OOM do modo batch no cenário nativo da nuvem
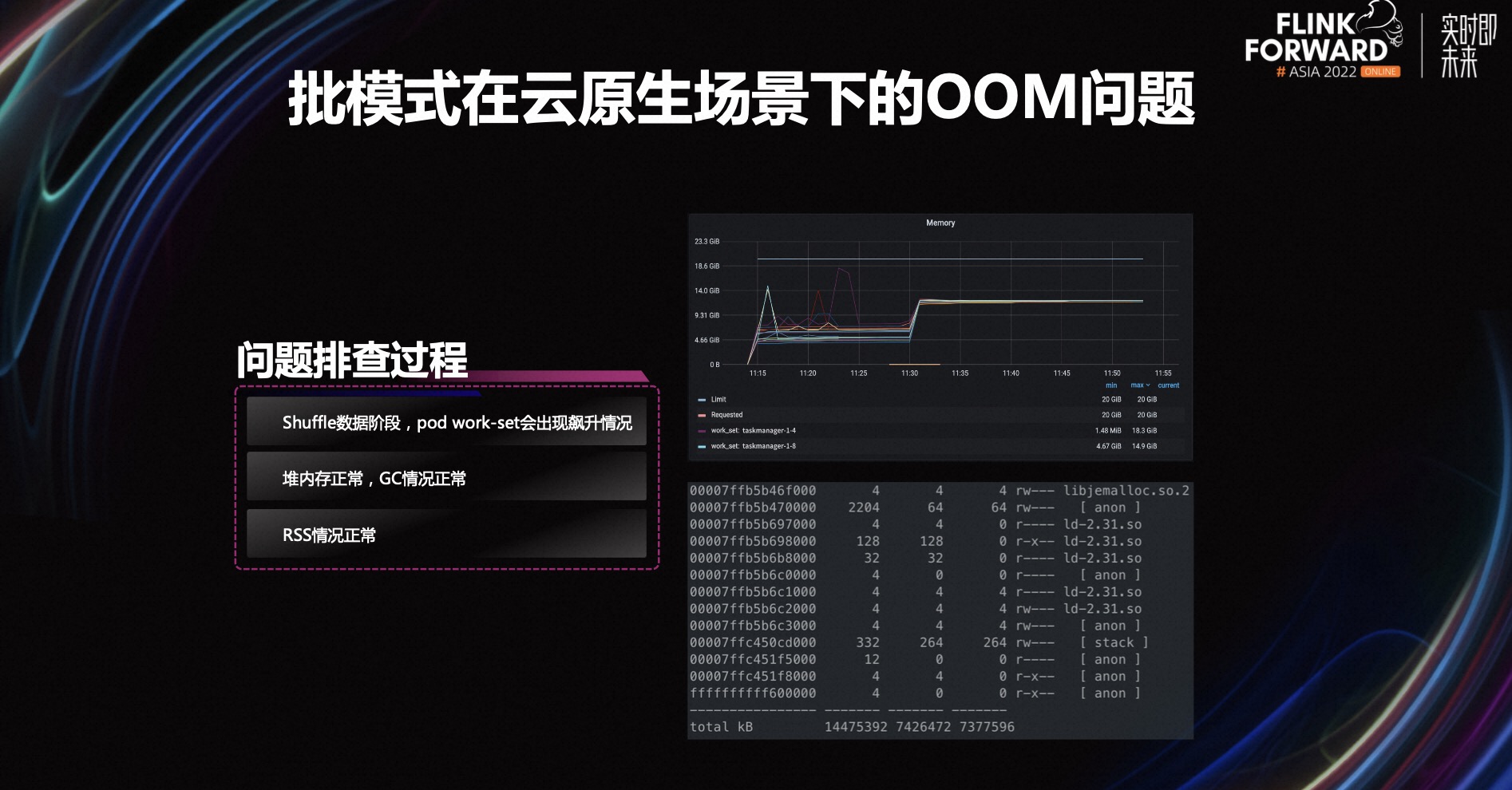
A segunda questão é o problema OOM do modo batch em cenários nativos da nuvem. Essa tarefa é executada sem problemas no mecanismo de modo de fluxo, mas os problemas OOM ocorrem com frequência após alternar para a execução do mecanismo de modo de lote.
Esta tarefa ainda possui dois operadores após a cadeia, ou seja, um embaralhamento de dados será realizado no meio, e o OOM ocorre nesta etapa de gravação dos dados embaralhados. No diagrama de monitoramento no canto superior direito da figura acima, você pode ver claramente dois estágios. O primeiro estágio é o estágio de gravação de dados aleatórios. Em alguns casos, o conjunto de trabalho sobe. Uma vez que o limite do contêiner é excedido, OOM Kill será acionado.
Quando isso acontece, primeiro observamos o uso da memória heap do webui do Flink. Atualmente, o uso da memória heap é normal. Da interface de monitoramento do GC, também podemos ver que a situação do GC é normal. Então suspeitamos que pode haver um vazamento na memória off-heap, então entramos no Pod e verificamos o uso de RSS através do comando pmap. Ou seja, na imagem no canto inferior direito, você pode ver que o RSS também está normal, e o RSS é apenas cerca de 7G, o que não atinge o limite de 20G, o que significa que não é causado por um out- vazamento de memória de heap.
A resposta já está aqui. O indicador do conjunto de trabalho pode ser entendido simplesmente como RSS+Page Cache. RSS é normal, mas o conjunto de trabalho disparou novamente, então podemos suspeitar que OOM é causado pelo Cache de página.

Seguindo essa linha de pensamento, efetuamos login no nó da máquina para verificar o log da máquina. Conforme mostrado na figura acima, encontramos uma pilha de chamadas e podemos ver que o OOM é causado pela solicitação de cache de página. Na verdade, o desempenho do disco na nuvem é insuficiente. Quando os dados do Shuffle são gravados em grande quantidade no cache da página em um instante, os dados não podem ser liberados no disco a tempo, resultando em uso excessivo de memória e acionando o OOM Kill.
Temos uma solução temporária. Aumente o número de Pods, reduza a quantidade de dados processados por um único Pod e tente distribuir os Pods para diferentes nós de máquina para reduzir a pressão sobre os nós de máquina. Ou atualize o kernel da máquina e limite a corrente ajustando os parâmetros do kernel. Além disso, também podemos iniciar a partir do próprio mecanismo Flink e limitar diretamente a corrente no estágio de dados Shuffle.
4. Perspectivas Futuras

A direção que Xiaohongshu explorará no futuro inclui principalmente as três partes a seguir.
- Primeiro, o modo de lote aplica escavação profunda. Esperamos aprofundar os usuários, explorar mais cenários de uso de mecanismos de modo de lote e realmente promover a integração de fluxo de lote do Flink.
- Em segundo lugar, use a função Resource Quota do K8s para mesclar vários pequenos clusters do lado comercial para reduzir o problema de fragmentação de recursos da máquina.
- Em terceiro lugar, sem servidor é uma meta importante para a implantação de mecanismos de modo de lote em ambientes nativos de nuvem, mas a implantação forçada como sem servidor significa que, se o pod for encerrado, os dados intermediários serão limpos, o que afetará a recuperação de falhas da tarefa .Neste momento, serviço aleatório remoto O valor do shuffle é refletido.Usar o serviço aleatório remoto pode efetivamente reduzir a dependência parcial de discos locais, melhorar a utilização de recursos e ajudar a arquitetura nativa da nuvem.