
Com base nas perguntas comuns do Apache Doris sobre o processo de leitura e escrita, mecanismo de consistência de cópia, mecanismo de armazenamento, mecanismo de alta disponibilidade, etc., ele é classificado e respondido na forma de perguntas e respostas. Antes de começar, vamos primeiro explicar os termos relacionados a este artigo:
-
FE : Frontend, o nó front-end de Doris. Principalmente responsável por receber e retornar solicitações de clientes, metadados, gerenciamento de cluster, geração de plano de consulta, etc.
-
BE : Backend, o nó backend de Doris. Principalmente responsável pelo armazenamento e gerenciamento de dados, execução do plano de consulta, etc.
-
BDBJE : Oracle Berkeley DB Java Edition.Em Doris, BDBJE é usado para completar a persistência de logs de operação de metadados, alta disponibilidade FE e outras funções.
-
Tablet : Tablet é a unidade de armazenamento físico real de uma tabela. Uma tabela é armazenada em unidades de tablets na camada de armazenamento distribuída formada pelo BE de acordo com partições e buckets. Cada tablet inclui meta informações e vários RowSets consecutivos.
-
RowSet : RowSet é uma coleção de dados de uma alteração de dados no Tablet. As alterações de dados incluem importação, exclusão, atualização de dados, etc. Registros RowSet por informações de versão. Cada mudança gerará uma versão.
-
Versão : consiste em dois atributos: Início e Fim, e mantém informações de registro de alterações de dados. Geralmente usado para representar o intervalo de versões do RowSet. Após uma nova importação, é gerado um RowSet com início e fim iguais. Após a compactação, é gerada uma versão do RowSet com intervalo.
-
Segmento : representa segmentos de dados em RowSet. Vários segmentos constituem um RowSet.
-
Compactação : O processo de mesclagem de versões consecutivas do RowSet é chamado de Compactação e os dados serão compactados durante o processo de mesclagem.
-
Coluna chave, coluna Valor : Em Doris, os dados são descritos logicamente na forma de uma tabela. Uma tabela inclui linhas (Linha) e colunas (Coluna).Linha é uma linha de dados do usuário e Coluna é usada para descrever diferentes campos em uma linha de dados. A coluna pode ser dividida em duas categorias: Chave e Valor. Do ponto de vista comercial, Chave e Valor podem corresponder a colunas de dimensão e colunas de indicador, respectivamente. A coluna Chave de Doris é a coluna especificada na instrução de criação da tabela. A coluna após a palavra-chave chave exclusiva ou chave agregada ou chave duplicada na instrução de criação da tabela é a coluna Chave. Além da coluna Chave, o restante é o Valor coluna.
-
Modelo de dados : o modelo de dados de Doris é dividido principalmente em três categorias: Agregado, Único e Duplicado.
-
Tabela base : em Doris, chamamos a tabela criada pelo usuário por meio da instrução de criação de tabela de Tabela Base.A tabela base armazena os dados básicos armazenados da maneira especificada pela instrução de criação de tabela do usuário.
-
Tabela ROLLUP : No topo da tabela Base, os usuários podem criar qualquer número de tabelas ROLLUP. Esses dados ROLLUP são gerados com base na tabela Base e são armazenados fisicamente de forma independente. A função básica da tabela ROLLUP é obter dados agregados de granulação mais grossa com base na tabela Base, semelhante a uma visão materializada.
Q1: Qual é a diferença entre particionamento e bucket Doris?
Doris oferece suporte a dois níveis de particionamento de dados:
-
A primeira camada é Partition, que suporta métodos de divisão Range e List (semelhante ao conceito de tabela de partição do MySQL). Várias partições formam uma tabela e a partição pode ser considerada a menor unidade lógica de gerenciamento. Os dados podem ser importados e excluídos apenas para uma partição.
-
A segunda camada é Bucket (Tablet também é chamado de bucketing), que suporta métodos de divisão Hash e Random. Cada Tablet contém várias linhas de dados, e os dados entre Tablets não têm interseção e são armazenados fisicamente de forma independente. Tablet é a menor unidade de armazenamento físico para operações como movimentação e cópia de dados.
Você também pode usar apenas um nível de particionamento. Se você não escrever uma instrução de particionamento ao criar uma tabela, Doris irá gerar uma partição padrão, que é transparente para o usuário.
A indicação é a seguinte:
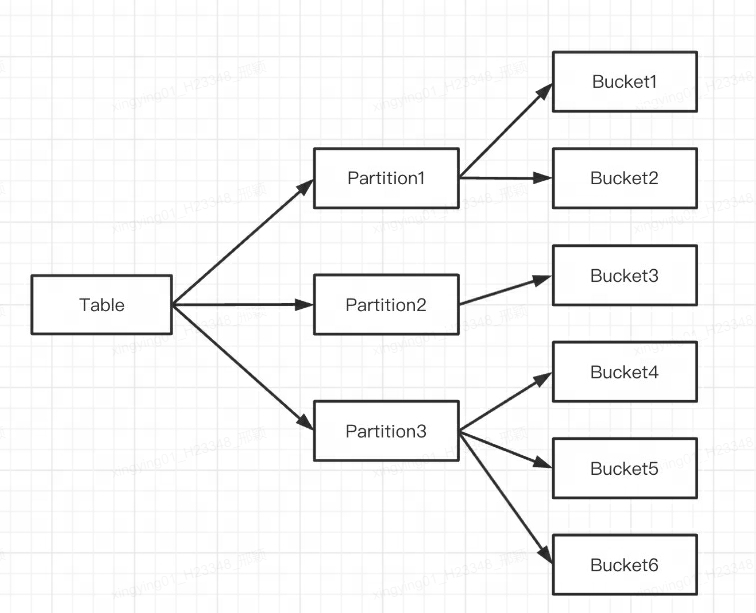
Vários Tablets pertencem logicamente a diferentes partições (Partição).Um Tablet pertence apenas a uma Partição e uma Partição contém vários Tablets. Como o Tablet é fisicamente armazenado de forma independente, pode-se considerar que a Partição também é fisicamente independente.
Falando logicamente, a maior diferença entre particionamento e bucket é que o bucket divide o banco de dados aleatoriamente, enquanto o particionamento divide o banco de dados de forma não aleatória.
Como garantir múltiplas cópias de dados?
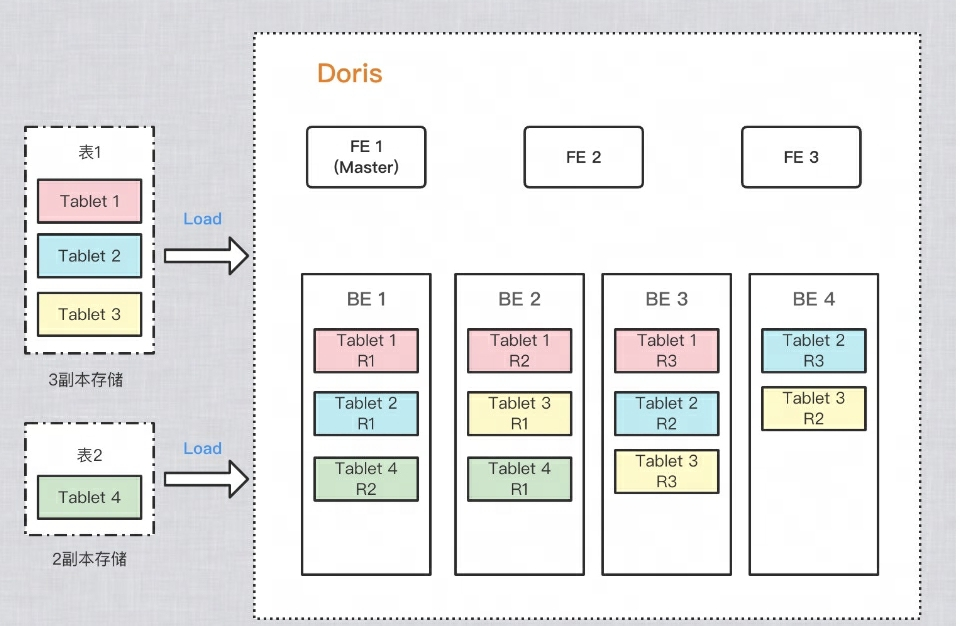
Para melhorar a confiabilidade do armazenamento de dados e o desempenho dos cálculos, Doris faz várias cópias de cada tabela para armazenamento. Cada cópia de dados é chamada de cópia. Doris usa o Tablet como unidade básica para armazenar cópias de dados. Por padrão, um fragmento possui 3 cópias. Ao criar uma tabela, você pode PROPERTIESdefinir o número de cópias em:
PROPERTIES
(
"replication_num" = "3"
);
Como exemplo na figura abaixo, duas tabelas são importadas para o Doris respectivamente: a tabela 1 é armazenada em 3 cópias após a importação e a tabela 2 é armazenada em 2 cópias após a importação. A distribuição dos dados é a seguinte:
Q2: Por que você precisa de buckets?
A fim de reduzir os intervalos e evitar a distorção de dados, dispersar a leitura de IO e melhorar o desempenho da consulta, diferentes cópias do Tablet podem ser dispersas em diferentes máquinas, para que o desempenho de IO de diferentes máquinas possa ser totalmente utilizado durante as consultas.
Q3: Qual é a estrutura de armazenamento e formato dos arquivos físicos?
Cada importação de Doris pode ser considerada uma transação e um RowSet será gerado. E RowSet inclui vários segmentos, ou seja Tablet-->Rowset-->Segment. Então, como o BE armazena esses arquivos?
Estrutura de armazenamento de Doris
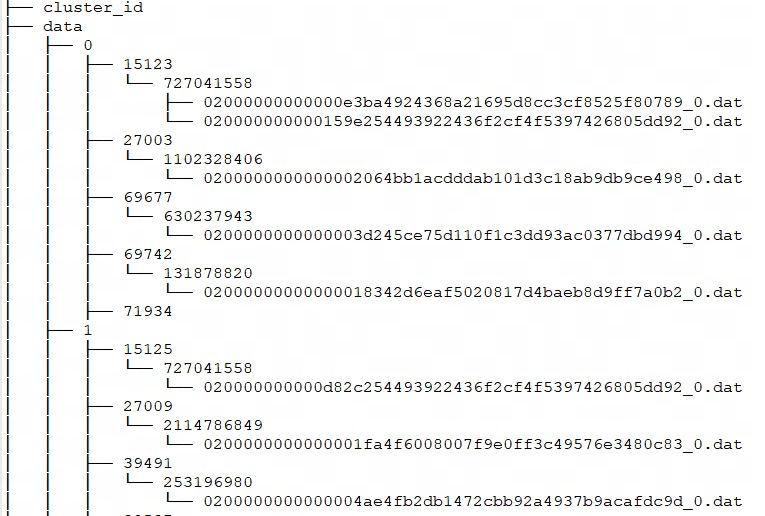
Doris storage_root_pathconfigura o caminho de armazenamento por meio e os arquivos de segmento são armazenados no tablet_iddiretório e gerenciados pelo SchemaHash. Pode haver vários arquivos de segmento, que geralmente são divididos de acordo com o tamanho. O padrão é 256 MB. O diretório de armazenamento e as regras de nomenclatura do arquivo de segmento são:
${storage_root_path}/data/${shard}/${tablet_id}/${schema_hash}/${rowset_id}_${segment_id}.dat
Entre storage_root_pathno diretório e você poderá ver a seguinte estrutura de armazenamento:
-
${shard}: Isso é 0, 1 na figura acima. Ele é criado automaticamente pelo BE no diretório de armazenamento e é aleatório. Aumentará com o aumento dos dados. -
${tablet_id}: Ou seja, 15123, 27003, etc. na figura acima, que é o ID do Bucket mencionado acima. -
${schema_hash}: Ou seja, 727041558, 1102328406, etc. na imagem acima. Como a estrutura de uma tabela pode ser alterada, uma é gerada para cada versão do esquemaSchemaHashpara identificar os dados dessa versão. -
${segment_id}.dat: O primeiro érowset_id, ou seja, 02000000000000e3ba4924368a21695d8cc3cf8525f80789 na figura acima;${segment_id}é o RowSet atualsegment_id, começando em 0 e aumentando.
Formato de armazenamento de arquivo de segmento
O formato geral do arquivo do Segmento é dividido em três partes: área de dados, área de índice e rodapé, conforme mostrado na figura a seguir:

-
Região de dados: usada para armazenar as informações de dados de cada coluna. Os dados aqui são carregados em páginas sob demanda. As páginas contêm os dados da coluna e cada página tem 64k.
-
Região de índice: Doris armazena os dados de índice de cada coluna na região de índice. Os dados aqui serão carregados de acordo com a granularidade da coluna, portanto, serão armazenados separadamente das informações dos dados da coluna.
-
Informações de rodapé: contém informações de metadados do arquivo, soma de verificação do conteúdo, etc.
Q4: Quais são as limitações DML dos diferentes modelos de tabela de Doris?
-
Atualização: a instrução Update atualmente oferece suporte apenas ao modelo UNIQUE KEY e apenas à atualização da coluna Valor.
-
Excluir: 1) Se o modelo de tabela utilizar uma classe agregada (AGGREGATE, UNIQUE), a operação Delete poderá especificar apenas as condições da coluna Key; 2) Esta operação também excluirá os dados do Índice Rollup relacionado a este Índice Base.
-
Inserir: Todos os modelos de dados podem ser Inseridos.
Como implementar a inserção? Como os dados podem ser consultados após serem inseridos?
-
Modelo AGGREGATE : Na fase Inserir, os dados incrementais são gravados no RowSet no método Append e, na fase de consulta, o método Merge on Read é usado para mesclar. Ou seja, os dados são gravados primeiro em um novo RowSet durante a importação e a desduplicação não será executada após a gravação. A classificação simultânea multidirecional só será executada quando uma consulta for iniciada. Ao executar a classificação de mesclagem multidirecional, duplique os dados serão classificados. As chaves são organizadas juntas e agregadas. A chave da versão superior substituirá a chave da versão inferior e, em última análise, apenas o registro com a versão mais recente será retornado ao usuário.
-
Modelo DUPLICADO : Este modelo é escrito de forma semelhante ao anterior e não haverá operações de agregação na fase de leitura.
-
Modelo UNIQUE : Antes da versão 1.2, este modelo era essencialmente um caso especial do modelo agregado, com comportamento consistente com o modelo AGGREGATE. Como o modelo de agregação é implementado por Merge on Read , o desempenho em algumas consultas de agregação é ruim. Doris introduziu uma nova implementação do modelo Unique após a versão 1.2, Merge on Write , que marca e exclui dados substituídos e atualizados durante a gravação. Durante a consulta, todos os dados marcados e excluídos são excluídos. Os dados serão filtrados no nível do arquivo, e os dados lidos serão os dados mais recentes, eliminando o processo de agregação de dados na fusão em tempo de leitura e podem suportar o pushdown de vários predicados em muitos casos.
Simplificando, o fluxo de processamento de Merge on Write é:
-
Para cada chave, encontre sua posição nos dados base (RowSetid + Segmentid + número da linha) [A árvore de intervalo de chave primária em nível de segmento é mantida na memória para acelerar as consultas]
-
Se a chave existir, marque a linha de dados para exclusão. As informações marcadas para exclusão são registradas no Delete Bitmap, onde cada Segmento possui um Delete Bitmap correspondente.
-
Escreva os dados atualizados no novo RowSet, conclua a transação e torne os novos dados visíveis, ou seja, podem ser consultados pelo usuário.
-
Ao consultar, leia o Bitmap de exclusão, filtre as linhas marcadas para exclusão e retorne apenas dados válidos [Para todos os segmentos de ocorrências, consulte de acordo com a versão de cima para baixo]
O seguinte apresenta a implementação do processo de escrita e do processo de leitura.
Processo de gravação : Ao gravar dados, o índice de chave primária de cada segmento será criado primeiro e, em seguida, o Delete Bitmap será atualizado.
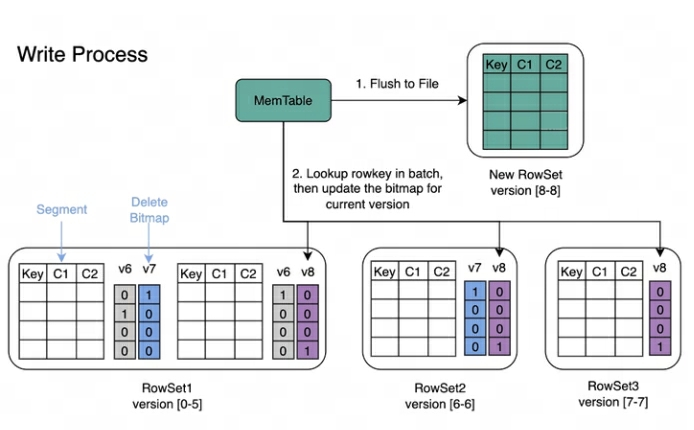
Processo de leitura : O processo de leitura do Bitmap é mostrado na figura abaixo. Pela imagem podemos saber:
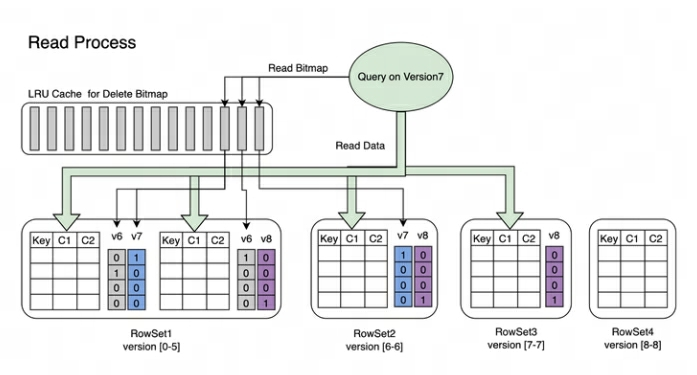
-
Uma consulta que solicita a versão 7 verá apenas os dados correspondentes à versão 7.
-
Ao ler os dados do RowSet5, os Bitmaps gerados pelas modificações V6 e V7 serão mesclados para obter o DeleteBitmap completo correspondente à Versão7, que é usado para filtrar os dados.
-
No exemplo acima, a importação da versão 8 cobre um dado no Segment2 do RowSet1, mas a Consulta que solicita a versão 7 ainda pode ler os dados.
Como a atualização é implementada?
O processo de atualização do modelo UNIQUE é essencialmente Select+Insert.
-
Update usa a lógica de filtragem Where do próprio mecanismo de consulta para filtrar as linhas que precisam ser atualizadas da tabela a ser atualizada e, com base nisso, manter o Delete Bitmap e gerar os dados recém-inseridos.
-
Em seguida, execute a lógica Insert, o processo específico é semelhante à lógica de escrita do modelo UNIQUE mencionada acima.
P5: Como o Doris' Delete é implementado? Um RowSet também será gerado? Como deletar os dados correspondentes?
-
Delete de Doris também gerará um RowSet.No modo DELETE, os dados não são realmente excluídos, mas as condições de exclusão dos dados são registradas. Armazenado em informações Meta. Ao executar a Compactação Base, as condições de exclusão serão mescladas na versão Base.
-
Doris também oferece suporte a LOAD_DELETE no modelo UNIQUE KEY, que permite a exclusão de dados por meio da importação em lote das chaves a serem excluídas e pode oferecer suporte a recursos de exclusão de dados em grande escala. A ideia geral é adicionar um identificador de status de exclusão ao registro de dados, e a chave excluída será compactada durante o processo de compactação. A compactação é principalmente responsável por mesclar várias versões do RowSet.
Q6: Quais índices Doris possui?
Atualmente, Doris oferece suporte principalmente a dois tipos de índices:
-
Índices inteligentes integrados, incluindo índices de prefixo e índices ZoneMap.
-
Os índices secundários criados manualmente pelos usuários incluem índices invertidos, índices Bloomfilter, índices Ngram Bloomfilter e índices Bitmap.
O índice ZoneMap é uma informação de índice mantida automaticamente para cada coluna no formato de armazenamento de coluna, incluindo Min/Max, o número de valores nulos, etc. Essa indexação é transparente para o usuário.
Qual é o nível do índice?
-
Agora, todos os índices em Doris são locais de nível BE, como índice invertido, índice Bloomfilter, índice Ngram Bloomfilter e índice Bitmap, índice de prefixo e índice ZoneMap, etc.
-
Doris não possui um Índice Global. Em um sentido amplo, partições + chaves de bucket também podem ser consideradas globais, mas são relativamente granulares.
Qual é o formato de armazenamento do índice?
No Doris, os dados do índice de cada coluna são armazenados uniformemente na região do índice do arquivo de segmento.Os dados aqui são carregados de acordo com a granularidade da coluna, portanto, são armazenados separadamente das informações dos dados da coluna. Aqui tomamos o índice de prefixo Short Key Index como exemplo.
O índice de prefixo Short Key Index é um método de índice baseado na classificação de chave (AGGREGATE KEY, UNIQ KEY e DUPLICATE KEY) para consultar dados rapidamente com base em uma determinada coluna de prefixo. O índice Short Key Index aqui também adota uma estrutura de índice esparsa.Durante o processo de gravação de dados, um item de índice será gerado a cada determinado número de linhas. Esse número de linhas é a granularidade do índice, cujo padrão é 1.024 linhas e é configurável. O processo é mostrado abaixo:
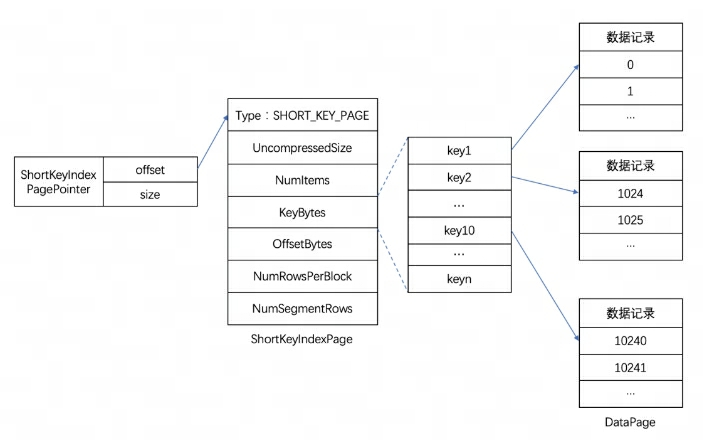
Entre eles, KeyBytes armazena os dados do item de índice e OffsetBytes armazena o deslocamento do item de índice em KeyBytes.
O Short Key Index usa os primeiros 36 bytes como índice de prefixo desta linha de dados. Quando um tipo VARCHAR é encontrado, o índice de prefixo é truncado diretamente. O Short Key Index usa os primeiros 36 bytes como índice de prefixo desta linha de dados. Quando um tipo VARCHAR é encontrado, o índice de prefixo é truncado diretamente.
Como o processo de leitura atinge o índice?
Ao consultar os dados em um Segmento, de acordo com as condições da consulta executada, os dados serão primeiramente filtrados com base no índice do campo. Em seguida, leia os dados, o processo geral de consulta é o seguinte:
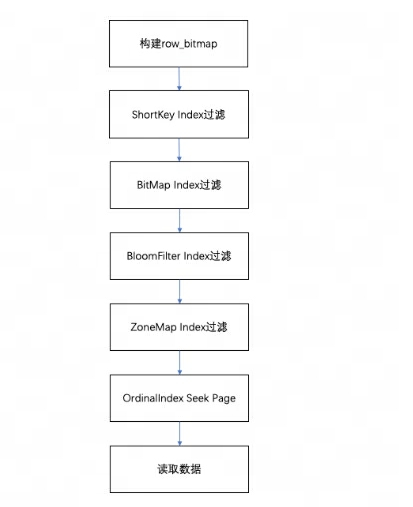
-
Primeiro, será construído um de acordo com o número de linhas do Segmento
row_bitmappara indicar quais dados precisam ser lidos. Todos os dados precisam ser lidos sem usar nenhum índice. -
Quando a chave é usada nas condições de consulta de acordo com a regra do índice de prefixo, o índice ShortKey será filtrado primeiro e o intervalo de números de linha ordinal que pode ser correspondido no índice ShortKey será combinado em
row_bitmap. -
Quando houver um índice de índice BitMap no campo da coluna na condição de consulta, o número da linha ordinal que atende às condições será descoberto diretamente de acordo com o índice BitMap e intersectado com o row_bitmap para filtragem. A filtragem aqui é precisa. Se a condição de consulta for removida posteriormente, este campo não será filtrado para índices subsequentes.
-
Quando o campo da coluna na condição de consulta tiver um índice BloomFilter e a condição for equivalente (eq,in,is),ele será filtrado de acordo com o índice BloomFilter. Aqui serão percorridos todos os índices,o BloomFilter de cada página será ser filtrado e as condições da consulta poderão ser encontradas. Todas as páginas.
row_bitmapFiltre a interseção do intervalo de números da linha ordinal nas informações do índice e . -
Quando houver um índice ZoneMap no campo da coluna na condição de consulta, ele será filtrado de acordo com o índice ZoneMap. Aqui, todos os índices também serão percorridos para encontrar todas as páginas que a condição de consulta pode cruzar com o ZoneMap.
row_bitmapFiltre a interseção do intervalo de números da linha ordinal nas informações do índice e . -
Após gerar
row_bitmap, encontre a página de dados específica através do OrdinalIndex de cada coluna em lotes. -
Leia os dados da página de dados da coluna de cada coluna em lotes. Ao ler, para páginas com valores nulos, determine se a linha atual é nula com base no bitmap do valor nulo. Se for nulo, preencha-o diretamente.
Q7: Como Doris realiza a compactação?
Doris usa Compactação para agregar incrementalmente arquivos RowSet para melhorar o desempenho.As informações de versão do RowSet são projetadas com dois campos,Início e Fim,para representar o intervalo de versões do Rowset mesclado. As versões inicial e final de um RowSet cumulativo não mesclado são iguais. Durante a compactação, RowSets adjacentes serão mesclados para gerar um novo RowSet, e as informações de início e fim da versão também serão mescladas para formar uma versão maior. Por outro lado, o processo de compactação reduz bastante o número de arquivos RowSet e melhora a eficiência da consulta.
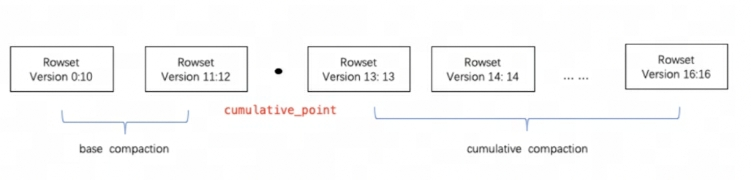
Conforme mostrado na figura acima, as tarefas de Compactação são divididas em dois tipos, Compactação Base e Compactação Cumulativa. cumulative_pointÉ a chave para separar as duas estratégias.
Pode ser entendido assim:
-
cumulative_pointÀ direita está um RowSet incremental que nunca foi mesclado e as versões inicial e final de cada RowSet são iguais; -
cumulative_pointÀ esquerda está o RowSet mesclado, a versão inicial e a versão final são diferentes. -
Os processos de tarefas de Compactação Base e Compactação Cumulativa são basicamente os mesmos, a única diferença está na lógica de seleção do InputRowSet a ser mesclado.
Em que chave se baseia a compactação?
-
Em um Segmento, os dados são sempre armazenados na ordem de classificação da Chave (AGGREGATE KEY, UNIQ KEY e DUPLICATE KEY), ou seja, a classificação da Chave determina a estrutura física de armazenamento dos dados e determina a ordem da estrutura física dos dados da coluna.
-
Portanto, o processo de compactação Doris é baseado em AGGREGATE KEY, UNIQ KEY e DUPLICATE KEY.
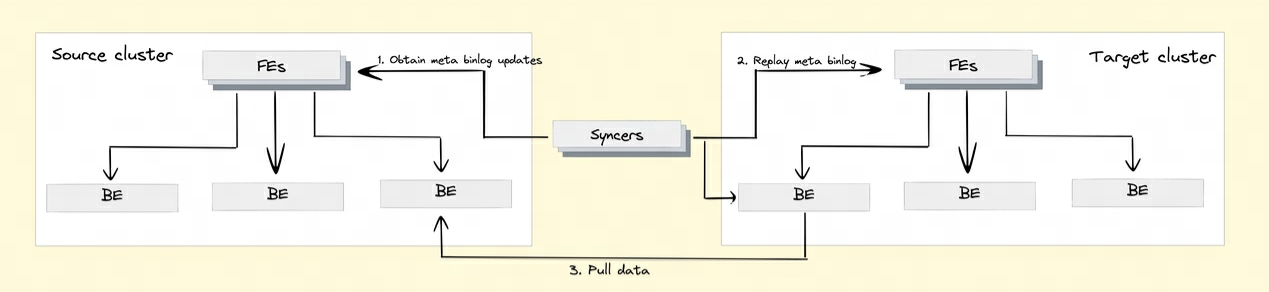
P8: Como Doris implementa a replicação de dados entre clusters?
Para realizar a função de replicação de dados entre clusters, Doris introduziu o mecanismo Binlog. Os registros e operações de modificação de dados são registrados automaticamente por meio do mecanismo Binlog para obter rastreabilidade dos dados. A reprodução e recuperação de dados também podem ser obtidas com base no mecanismo de reprodução do Binlog.
Como o Binlog é registrado?
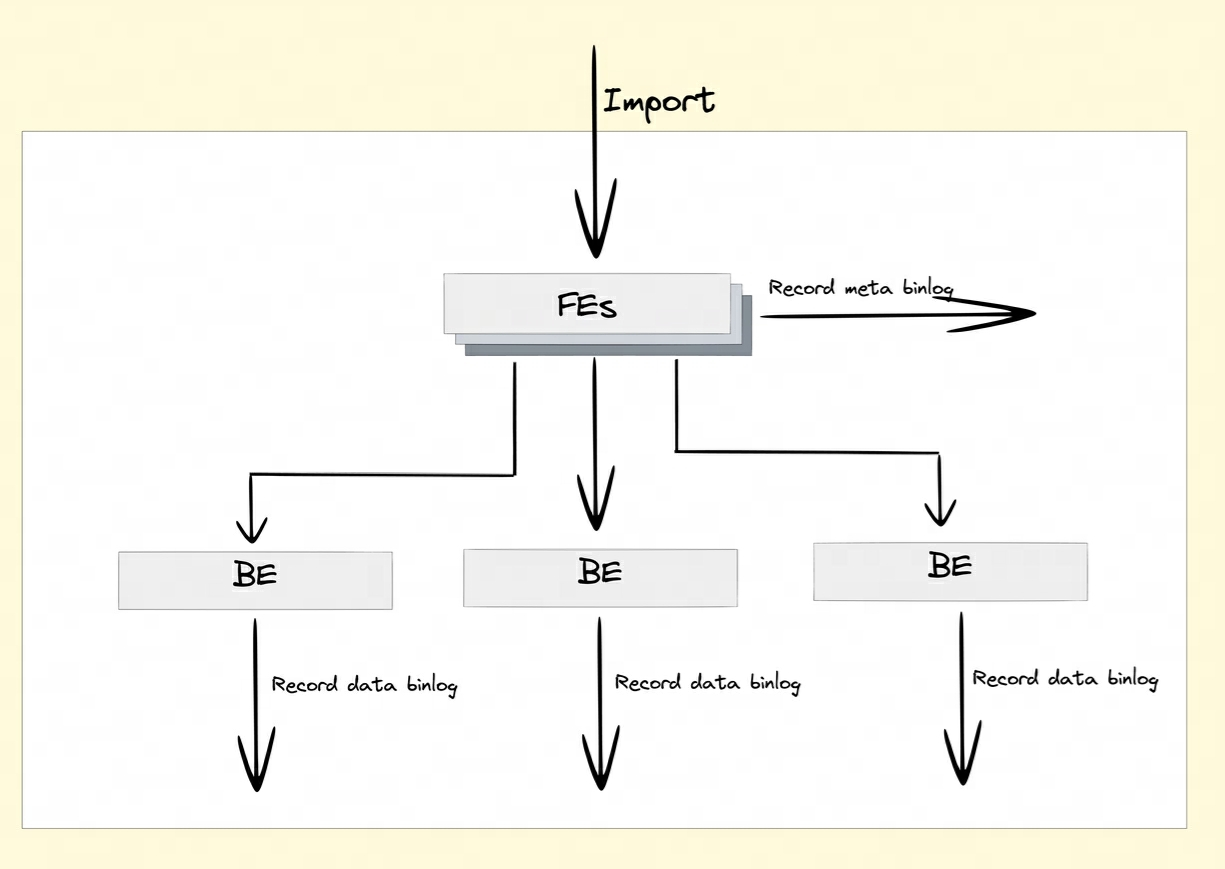
Após ativar o atributo Binlog, FE e BE persistirão os registros de modificação das operações DDL/DML em Meta Binlog e Data Binlog.
-
Meta Binlog: Doris aprimorou a implementação do EditLog para garantir a ordem do log. Ao construir uma sequência crescente de LogIDs, cada operação é registrada com precisão e persistida em ordem. Este mecanismo de persistência ordenado ajuda a garantir a consistência dos dados.
-
Binlog de dados: Quando FE inicia uma transação de publicação, o BE executará a operação de publicação correspondente. O BE gravará as informações de metadados desta transação envolvendo RowSet no KV prefixado
rowset_metacom e persistirá no armazenamento Meta. Após o envio, os arquivos de segmento importados serão vinculado à pasta Binlog.
Geração de binlog:
Reprodução de dados BInlog:
Q9: A tabela de Doris tem múltiplas cópias. Como garantir múltiplas cópias durante a fase de escrita? Existe um conceito mestre-escravo? É necessário retornar o sucesso da gravação após Maioria?
-
As 3 cópias de Doris BE não possuem o conceito de master-slave e utilizam o algoritmo Quorum para garantir a escrita multicópia.
-
Durante o processo de gravação, FE determinará se o número de cópias de cada tablet que grava dados com sucesso excede metade do número total de cópias do tablet. Se o número de cópias de cada tablet que grava dados com sucesso excede metade do número total de tablets cópias (mais sucesso), então a transação de confirmação será bem-sucedida e o status da transação será definido como COMMITTED; o status COMMITTED indica que os dados foram gravados com sucesso, mas os dados ainda não estão visíveis e a tarefa Publicar versão precisa ser continuada Depois disso, a transação não poderá ser revertida.
-
FE terá um thread separado para executar a versão de publicação para a transação de confirmação bem-sucedida. Quando o FE executa a versão de publicação, ele enviará solicitações de versão de publicação para todos os nós do Executor BE relacionados à transação por meio do RPC Thrift. A tarefa de publicação da versão é executada de forma assíncrona em cada Nó executor BE. Importe os dados para o RowSet gerado e torne-os uma versão de dados visível.
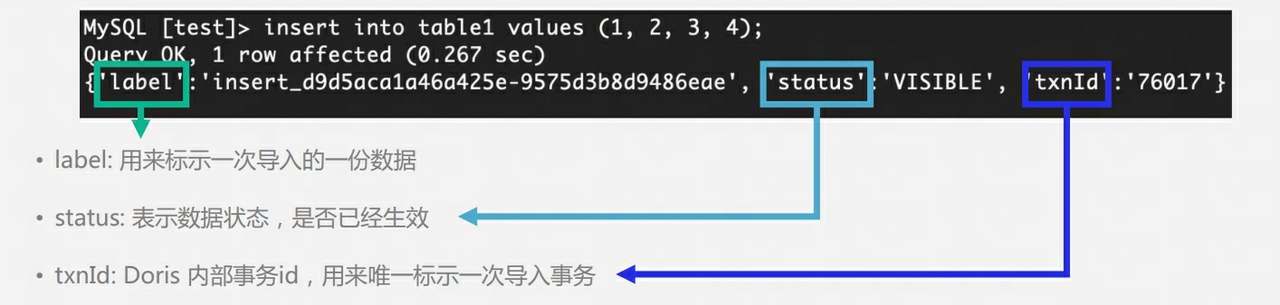
Por que existe um mecanismo de publicação : semelhante ao MVCC, se não houver um mecanismo de publicação, os usuários poderão ler dados que ainda não foram enviados.
O que acontecerá se a tabela tiver 3 cópias e apenas 1 cópia for escrita com sucesso : Neste momento, a transação será ABORTADA
O que acontecerá se a tabela tiver 3 cópias e apenas 2 cópias forem escritas com sucesso : Neste momento, a transação será COMPROMETIDA e Doris FE realizará monitoramento e inspeções regulares do tablet. Se for encontrada uma anormalidade na cópia do tablet, um Clone será gerada uma tarefa para clonar uma nova cópia.
Por que o usuário executa a consulta imediatamente após executar Insert Into e o resultado pode estar vazio ? O motivo é que a transação ainda não foi publicada.
Q10: Como o FE de Doris garante alta disponibilidade?
No nível de metadados, Doris utiliza o protocolo Paxos e o mecanismo Memory + Checkpoint + Journal para garantir alto desempenho e alta confiabilidade dos metadados.
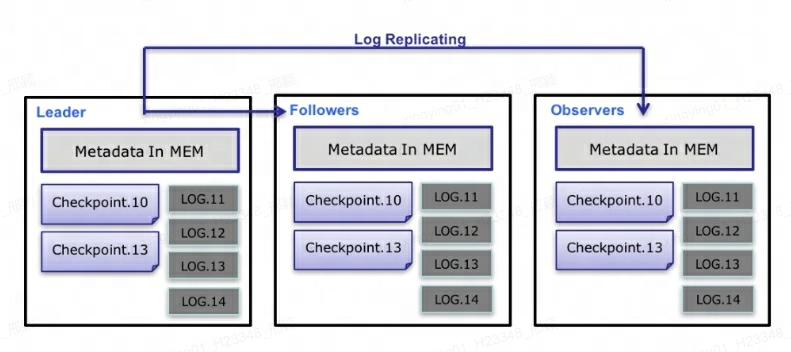
O processo específico de fluxo de dados de metadados é o seguinte :
-
Somente Leader FE pode escrever metadados. Após a operação de gravação modificar a memória do Líder, ela será serializada em um Log e
key-valuegravada em BDBJE na forma de . A chave é um número inteiro contínuo elog ido valor é o log de operação serializado. -
Depois que o log for gravado no BDBJE, o BDBJE copiará o log para outros nós FE não líderes de acordo com a política (gravação majoritária/gravação total). O nó FE Não Líder modifica sua própria imagem de memória de metadados reproduzindo logs para completar a sincronização de metadados com o nó Líder.
-
O número de logs no nó Líder atinge o limite (100.000 por padrão) e atende ao ciclo de execução do thread Checkpoint (60 segundos por padrão). O Checkpoint lerá o arquivo de imagem existente e os logs subsequentes e reproduzirá uma nova cópia da imagem de metadados na memória. A cópia é então gravada no disco para formar uma nova imagem. A razão para regenerar uma cópia da imagem em vez de gravar a imagem existente como uma imagem é principalmente porque gravar na imagem e adicionar um bloqueio de leitura bloqueará a operação de gravação. Portanto, cada Checkpoint ocupará o dobro do espaço de memória.
-
Após a geração do arquivo de imagem, o nó Líder notificará outros nós não líderes de que a nova imagem foi gerada. O Non-Leader extrai ativamente o arquivo de imagem mais recente por meio de HTTP para substituir o arquivo local antigo.
-
Para logs no BDBJE, os logs antigos serão excluídos regularmente após a conclusão da imagem.
explicar :
-
Cada atualização de metadados é primeiro gravada no arquivo de log do disco, depois gravada na memória e, finalmente, periodicamente verificada no disco local.
-
É equivalente a uma estrutura de memória pura, o que significa que todos os metadados serão armazenados em cache na memória, garantindo assim que o FE possa restaurar rapidamente os metadados após uma falha sem perder metadados.
-
Os três Líder, Seguidor e Observador constituem um serviço confiável. Quando um único nó falha, três são basicamente suficientes, porque afinal, o nó FE armazena apenas uma cópia dos metadados e sua pressão não é grande, então se Quando houver muitos FEs consumirão recursos da máquina; portanto, na maioria dos casos, três são suficientes para obter um serviço de metadados altamente disponível.
-
Os usuários podem usar o MySQL para se conectar a qualquer nó FE para acesso de leitura e gravação aos metadados. Se a conexão for para um nó Não Líder, o nó encaminhará a operação de gravação para o nó Líder.
Sobre o autor
Invisible (Xing Ying) é engenheira sênior de kernel de banco de dados da NetEase. Ela está envolvida no desenvolvimento de kernel de banco de dados desde a formatura. Atualmente, ela está envolvida principalmente no desenvolvimento, manutenção e suporte comercial de MySQL e Apache Doris. Como contribuidor do kernel do MySQL, ele relatou mais de 50 bugs e itens de otimização para o MySQL, e vários envios foram incorporados à versão 8.0 do MySQL. Juntando-se à comunidade Apache Doris desde 2023, Apache Doris Active Contributor, enviou e mesclou dezenas de Commits para a comunidade.
Uma escola secundária comprou um "dispositivo de catarse interativo inteligente" - que na verdade é um caso para o Nintendo Wii. Linguagem de programação do ano TIOBE 2023: C # Kingsoft WPS travou O experimento Rust do Linux foi bem-sucedido, o Firefox pode aproveitar a oportunidade... 10 previsões sobre código aberto Acompanhamento do incidente de executivas demitindo funcionários: O presidente da empresa chamou os funcionários de "infratores reincidentes" e questionou "currículos acadêmicos falsos". O artefato de código aberto LSPosed anunciou que iria parar de atualizar. O autor disse que sofreu um grande número de ataques maliciosos. 2024 "A Batalha do Ano" no círculo front-end: React não consegue cavar buracos. Você precisa preenchê-lo com documentos? O Linux Kernel 6.7 é lançado oficialmente. A era do "pós-código aberto" chegou: a licença é inválida e não pode atender ao público em geral. Mulheres executivas foram demitidas ilegalmente. Funcionários se manifestaram e foram alvo de oposição ao uso de ferramentas EDA piratas para chips de design.