Artigos da série de design arquitetônico
- Projeto Arquitetônico Série 1: O que é Projeto Arquitetônico
- Série 2 de Design de Arquitetura: Vários Princípios Comuns de Design de Arquitetura
- Série 3 de Design de Arquitetura: Como Projetar uma Arquitetura Escalável
Na série Architecture Design 1: What is Architecture Design , falamos sobre o objetivo principal do projeto de arquitetura, que é resolver os problemas causados pela complexidade dos sistemas de software. Hoje falaremos sobre alto desempenho, uma das fontes do sistema de software complexidade.
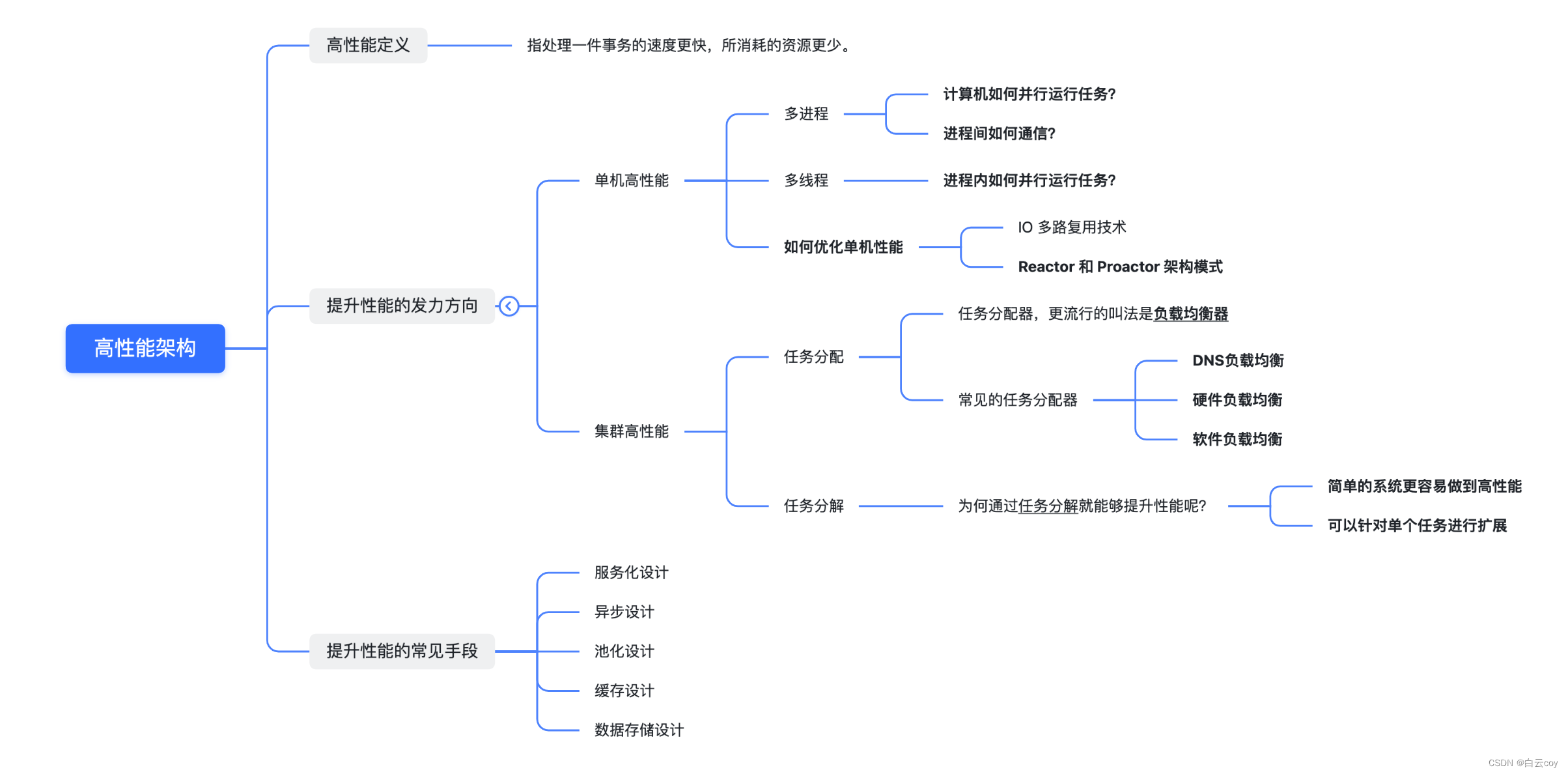
1. O que é arquitetura de alto desempenho?
Para entender o que é arquitetura de alto desempenho , precisamos primeiro entender o que é alto desempenho .
Definição de alto desempenho
Primeiro, o que é desempenho e como entendê-lo?
Simplificando, o desempenho refere-se à capacidade de processamento de uma transação.
Então, o que é alto desempenho?
Alto desempenho refere-se ao processamento de uma transação mais rapidamente e ao consumo de menos recursos.
Arquitetura de Alto Desempenho
Então, o que é uma arquitetura de alto desempenho?
Arquitetura de alto desempenho refere-se ao uso de tecnologias e estratégias apropriadas para alcançar excelente desempenho do sistema com investimento limitado de recursos.
Para os técnicos, como melhorar o desempenho do sistema com investimento limitado de recursos é ao mesmo tempo um desafio e uma oportunidade.
Você pode imaginar que se você é arquiteto e a arquitetura que você constrói tem o mesmo desempenho, o custo é menor. Essa é a sua vantagem?
2. Por que a arquitetura de alto desempenho é importante
Depois de entrar na era da Internet, a velocidade de desenvolvimento dos negócios está muito além da sua imaginação. Por exemplo:
- Em 2016, o número máximo de pagamentos por segundo do Alipay atingiu 120.000 durante o Double 11 .
- Em 2017, o número de envelopes vermelhos enviados e recebidos no WeChat durante o Festival da Primavera atingiu 760 mil por segundo .
Extraímos as principais informações: 120.000 pagamentos são feitos por segundo e 760.000 envelopes vermelhos são enviados e recebidos por segundo . Esses dois números significam que existem dezenas de milhares, ou mesmo centenas de milhões, de usuários utilizando o sistema ao mesmo tempo.
Com um número tão grande de usuários, você pode imaginar quanta pressão o sistema sofre, principalmente para serviços complexos como pagamentos e envelopes vermelhos, que exigem alto desempenho em todo o link. Os links de um sistema complexo são muitas vezes muito longos.É uma tarefa complexa e desafiadora garantir que cada link do link coopere para alcançar um alto desempenho.
Dessa forma, a arquitetura de alto desempenho é útil.
Podemos maximizar a velocidade de processamento, o rendimento e a eficiência do sistema por meio do projeto de arquitetura de alto desempenho, fornecendo assim serviços de sistema estáveis e confiáveis para atender às necessidades de negócios complexas, de grande escala e de alta simultaneidade.
Os sistemas de alto desempenho geralmente apresentam as seguintes características:
- Resposta rápida
- Alto rendimento
- baixa latência
- Alta simultaneidade
- Escalabilidade
3. Como projetar uma arquitetura de alto desempenho
A complexidade trazida pelo alto desempenho em sistemas de software se reflete principalmente em dois aspectos: por um lado, é a complexidade trazida por um único computador para alto desempenho ; por outro lado, é a complexidade trazida por vários clusters de computadores para alto desempenho. desempenho .
Portanto, podemos entender o alto desempenho dos sistemas de software sob dois aspectos: alto desempenho autônomo e alto desempenho de cluster .
A seguir, vamos discutir quais tecnologias comuns podem melhorar o desempenho independente e o desempenho do cluster.
1. Direcionamento dos esforços para melhorar o desempenho
1.1 Alto desempenho de máquina única
O aspecto mais crítico do alto desempenho independente é o sistema operacional .
O desenvolvimento do desempenho do computador é essencialmente impulsionado pelo desenvolvimento de hardware, especialmente o desenvolvimento do desempenho das CPUs. A famosa “Lei de Moore” mostra que o poder de processamento da CPU dobra a cada 18 meses; e a chave para utilizar totalmente o desempenho do hardware é o sistema operacional.
Portanto, o próprio sistema operacional realmente se desenvolve com o desenvolvimento do hardware. O sistema operacional é o ambiente de execução do sistema de software. A complexidade do sistema operacional determina diretamente a complexidade do sistema de software.
As coisas mais relevantes entre sistemas operacionais e desempenho são processos e threads .
1. Multiprocesso
Como um computador executa tarefas em paralelo?
Nos primeiros dias, os computadores só podiam executar uma tarefa por vez. Se uma tarefa exigisse a leitura de uma grande quantidade de dados de um dispositivo de E/S (como uma fita), a CPU ficava realmente ociosa durante a operação de E/S, e esse tempo ocioso teria sido. Outros cálculos são possíveis.
Para melhorar o desempenho, utiliza-se um processo que corresponde a uma tarefa. Cada tarefa possui seu próprio espaço de memória independente. Os processos não estão relacionados entre si e são agendados pelo sistema operacional. Para atingir o objetivo de operação paralela de múltiplos processos, é adotado um método de compartilhamento de tempo, ou seja, o tempo da CPU é dividido em vários segmentos, e cada segmento só pode executar instruções em um determinado processo.
Embora ainda seja processado serialmente do ponto de vista do sistema operacional e da CPU, devido à rápida velocidade de processamento da CPU, do ponto de vista do usuário, parece que vários processos estão sendo processados em paralelo.
Como se comunicar entre processos?
Embora o multiprocesso exija que cada tarefa tenha um espaço de memória independente e os processos não estejam relacionados entre si, do ponto de vista do usuário, se duas tarefas puderem se comunicar durante o processo em execução, o design da tarefa se tornará mais flexível e eficiente.
Caso contrário, se as duas tarefas não puderem se comunicar durante a operação, a tarefa A só poderá gravar os resultados no armazenamento e a tarefa B poderá então ler do armazenamento para processamento. Isso não é apenas ineficiente, mas também torna o design da tarefa mais complexo.
Para resolver este problema, vários métodos de comunicação entre processos foram projetados, incluindo pipes, filas de mensagens, semáforos, armazenamento compartilhado, etc.
2. Multiencadeamento
Como executar tarefas em paralelo dentro de um processo?
O multiprocesso permite que múltiplas tarefas sejam processadas em paralelo, mas tem suas próprias deficiências. Um único processo só pode ser processado em série. Na verdade, muitas subtarefas dentro de um processo não precisam ser executadas estritamente em ordem cronológica e também precisam ser processados em paralelo.
Para resolver esse problema, as pessoas inventaram threads. Threads são subtarefas dentro do processo, mas todas essas subtarefas compartilham os mesmos dados do processo. Para garantir a exatidão dos dados, foi inventado um mecanismo de bloqueio mutex.
Com o multithreading, a menor unidade de agendamento do sistema operacional torna-se um thread e um processo se torna a menor unidade de alocação de recursos do sistema operacional.
3. Como otimizar o desempenho independente durante a codificação?
Para melhorar o desempenho de uma única máquina, um dos pontos-chave é o modelo de simultaneidade adotado pelo servidor, que envolve modelos de IO multiprocessos, multithread e assíncronos sem bloqueio e síncronos sem bloqueio.
Multiplexação IO Existem
dois pontos-chave na tecnologia de multiplexação IO:
- Quando múltiplas ligações partilham um objecto de bloqueio,o processo só precisa de esperar num objecto de bloqueio sem sondar todas as ligações.Os métodos de implementação comuns incluem select,epoll,kqueue,etc.
- Quando uma determinada conexão possui novos dados que podem ser processados, o sistema operacional notificará o processo, e o processo retornará do estado de bloqueio e iniciará o processamento de negócios.
Padrões de arquitetura Reactor e Proactor
No design do sistema back-end, se quisermos alcançar alto desempenho em uma única máquina, com base na multiplexação IO, toda a nossa estrutura de rede também precisa cooperar com a tecnologia de pooling para melhorar nosso desempenho.
Portanto, a indústria geralmente usa multiplexação de E/S + pool de threads para melhorar o desempenho. Da mesma forma, os dois padrões de arquitetura de alto desempenho de máquina única comumente usados na indústria são os padrões Reactor e Proactor. O modo Reactor é um modelo de rede síncrona sem bloqueio e o modo Proactor é um modelo de rede assíncrona sem bloqueio .
Entre os softwares de código aberto da indústria, o Redis adota um único Reactor e uma abordagem de processo único, o Memcache adota uma abordagem multi-Reator e multi-thread, e o Nginx adota uma abordagem multi-Reator e multi-processo.
4. Resumo
Se quisermos completar um sistema de software de alto desempenho, precisamos considerar pontos técnicos como multiprocessos, multithread, comunicação entre processos e simultaneidade multithread.
Embora multiprocessos e multithreading melhorem muito o desempenho do processamento paralelo multitarefa, eles ainda são essencialmente sistemas de compartilhamento de tempo e não podem alcançar o verdadeiro paralelismo ao mesmo tempo. A maneira de resolver este problema é permitir que múltiplas CPUs executem tarefas de computação ao mesmo tempo, alcançando assim um verdadeiro paralelismo multitarefa.
Atualmente, o processador multi-core mais comum é a solução SMP. SMP, nome completo Symmetric Multi-Processor, estrutura simétrica de multiprocessador.
1.2 Cluster de alto desempenho
Embora o desempenho do hardware do computador tenha se desenvolvido rapidamente, ele ainda é insignificante em comparação com a velocidade de desenvolvimento dos negócios. Especialmente depois de entrar na era da Internet, a velocidade de desenvolvimento dos negócios excede em muito a velocidade de desenvolvimento do hardware.
Como mencionado anteriormente, para dois negócios complexos, pagamento e envelopes vermelhos, o desempenho de uma única máquina não pode ser suportado de qualquer maneira, e um cluster deve ser usado para alcançar alto desempenho. Por exemplo, para sistemas de negócios da escala de Alipay e WeChat, o número de máquinas do sistema backend está na casa das dezenas de milhares.
Melhorar o desempenho através de um grande número de máquinas não é tão simples quanto adicionar máquinas, é uma tarefa complexa cooperar com múltiplas máquinas para alcançar alto desempenho. As formas comuns são:
1. Alocação de tarefas
A distribuição de tarefas significa que cada máquina pode lidar com tarefas de negócios completas e diferentes tarefas são atribuídas a diferentes máquinas para execução.
A complexidade do design de cluster de alto desempenho se reflete principalmente na necessidade de adicionar um alocador de tarefas e selecionar um algoritmo de alocação de tarefas apropriado.
Para alocadores de tarefas, o nome mais popular é load balancer . Mas esse nome faz as pessoas pensarem inconscientemente que o objetivo da alocação de tarefas é manter a carga de cada unidade de computação em um estado equilibrado. Na verdade, a alocação de tarefas não se limita a considerar o balanceamento de carga das unidades de computação. Diferentes algoritmos de alocação de tarefas têm objetivos diferentes. Alguns são baseados em considerações de carga, alguns são baseados em considerações de desempenho (taxa de transferência, tempo de resposta) e alguns são baseados em considerações de negócios.
A escolha de um alocador de tarefas adequado também é uma questão complexa e requer consideração abrangente de vários fatores, como desempenho, custo, facilidade de manutenção e disponibilidade.
As classificações comuns de alocadores de tarefas são:
Balanceamento de carga DNS
Este é o método de balanceamento de carga mais simples e comum e é frequentemente usado para obter balanceamento em nível geográfico.
A essência do balanceamento de carga do DNS é que quando usuários de diferentes localizações geográficas acessam o mesmo nome de domínio, o DNS pode retornar endereços IP diferentes. Por exemplo, os usuários do norte visitam a sala de informática em Pequim, enquanto os usuários do sul visitam a sala de informática em Shenzhen. Tomando como exemplo www.baidu.com, o endereço obtido pelos usuários do norte é 61.135.165.224, e o endereço obtido pelos usuários do sul é 14.215.177.38.
- Vantagens: implementação simples, baixo custo, sem necessidade de desenvolvimento ou manutenção, acesso próximo, velocidade de acesso rápida
- Desvantagens: Atualizações intempestivas, escalonabilidade deficiente, estratégia de alocação simples
O balanceamento de carga de hardware
implementa a função de balanceamento de carga por meio de um dispositivo de hardware separado. Este tipo de dispositivo é semelhante a roteadores e switches e pode ser entendido como um dispositivo de rede básico para balanceamento de carga. Atualmente existem dois modelos típicos: F5 e A10.
- Vantagens: Forte desempenho (suporta mais de 1 milhão de simultaneidades), funções poderosas (suporta balanceamento de carga em todos os níveis, suporta algoritmos de balanceamento abrangentes)
- Desvantagens: caro, baixa escalabilidade
O balanceamento de carga de software
implementa a função de balanceamento de carga fornecendo software de balanceamento de carga. Os mais comuns são LVS e Nginx. LVS é o balanceamento de carga de 4 camadas do kernel Linux e Nginx é o balanceamento de carga de 7 camadas do software.
Além de utilizar sistemas de código aberto para balanceamento de carga, se o negócio for relativamente especial, também é possível customizar com base em sistemas de código aberto (por exemplo, plug-ins Nginx), ou mesmo realizar autopesquisa.
- Vantagens: simples, barato, flexível, o balanceamento de carga da camada 4 e da camada 7 pode ser selecionado e expandido de acordo com as necessidades do negócio
- Desvantagens: Comparado ao balanceamento de carga de hardware, o desempenho é médio e a função não é tão poderosa.
A principal diferença entre o balanceamento de carga de software e o balanceamento de carga de hardware está no desempenho. O desempenho do balanceamento de carga de hardware é muito superior ao do software. Por exemplo, o desempenho do Nginx é de 10.000 níveis e, após instalar o Nginx em um servidor Linux geral, pode atingir cerca de 50.000/segundo; o desempenho do LVS é de 100.000 níveis e diz-se que pode atingir 800.000/segundo; e o desempenho do F5 é de um milhão de níveis, começando em 200. Disponível de 10.000/segundo a 8 milhões/segundo.
Arquitetura típica de balanceamento de carga
Geralmente, usamos uma combinação de três métodos de balanceamento de carga com base em suas respectivas vantagens e desvantagens. Os princípios básicos da combinação são: o balanceamento de carga de DNS realiza o balanceamento de carga em nível geográfico; o balanceamento de carga de hardware realiza o balanceamento de carga em nível de cluster; o balanceamento de carga de software realiza o balanceamento de carga em nível de máquina.
2. Divisão de tarefas
Através da alocação de tarefas , podemos romper o gargalo do desempenho de processamento de uma única máquina e adicionar mais máquinas para atender às necessidades de desempenho do negócio.No entanto, se o próprio negócio se tornar cada vez mais complexo, o desempenho só poderá ser expandido através da alocação de tarefas . , a renda ficará cada vez menor.
Por exemplo, quando o negócio é simples, se uma máquina for expandida para 10 máquinas, o desempenho pode ser aumentado em 8 vezes (parte da perda de desempenho causada pelo grupo de máquinas precisa ser deduzida, portanto não pode atingir os 10 vezes teóricos ), mas se o negócio se tornar cada vez mais complexo, se uma máquina for expandida para 10, o desempenho só poderá ser melhorado em 5 vezes.
A principal razão para esse fenômeno é que o negócio está se tornando cada vez mais complexo e o desempenho de processamento de uma única máquina será cada vez menor. Para continuar melhorando o desempenho, precisamos adotar uma nova abordagem: decomposição de tarefas .
A arquitetura de microsserviços adota essa ideia: por meio desse método de decomposição de tarefas , o sistema de negócios original unificado, mas complexo, pode ser dividido em sistemas de negócios pequenos e simples que exigem a cooperação de vários sistemas.
Do ponto de vista comercial, a decomposição de tarefas não reduzirá a funcionalidade nem a quantidade de código (na verdade, a quantidade de código pode aumentar porque as chamadas são alteradas de dentro do código para chamadas através da interface entre servidores), então por que passar pode decomposição de tarefas melhora o desempenho? Existem principalmente os seguintes fatores:
-
É mais fácil para um sistema simples alcançar alto desempenho:
quanto mais simples for a função do sistema, menos pontos afetarão o desempenho e será mais fácil realizar a otimização direcionada. -
Ele pode ser expandido para uma única tarefa.
Quando cada tarefa lógica é decomposta em subsistemas independentes, o gargalo de desempenho de todo o sistema é mais fácil de encontrar. Após a descoberta, apenas o desempenho do subsistema com o gargalo precisa ser otimizado ou melhorado, sem alterar todo o sistema. O risco será muito menor.
Como a decomposição de um sistema unificado em vários subsistemas pode melhorar o desempenho, é melhor dividi-lo em partes mais detalhadas?
Na verdade, caso contrário, o desempenho não só não será melhorado, mas também será reduzido.A principal razão é que se o sistema for dividido muito finamente, para concluir um determinado negócio, o número de chamadas entre sistemas aumentará exponencialmente, e o número de chamadas entre sistemas aumentará exponencialmente.Os canais de chamadas são atualmente transmitidos através da rede e o desempenho é muito inferior ao das chamadas de função dentro do sistema.
Portanto, os benefícios de desempenho trazidos pela decomposição de tarefas têm um certo grau. Não é que quanto mais detalhada for a decomposição de tarefas, melhor. Para o projeto de arquitetura, como compreender essa granularidade é muito crítico.
Para obter instruções específicas sobre como decompor tarefas, você pode consultar o capítulo sobre divisão em Architecture Design Series 3: How to Design a Scalable Architecture .
2. Métodos comuns para melhorar o desempenho
A seguir, vamos analisar brevemente vários métodos comuns para melhorar o desempenho.
2.1 Design orientado a serviços
1. O quê: O que é servitização?
A servitização refere-se à divisão de um sistema empresarial complexo em vários sistemas empresariais pequenos e simples que precisam cooperar entre si por meio da decomposição de tarefas .
O resultado inevitável da servitização de sistemas grandes e complexos é a centralização dos negócios. Além disso, uma arquitetura monolítica não é necessariamente uma arquitetura ruim, dependendo da complexidade da aplicação. Por exemplo, se uma empresa iniciante deseja realizar negócios na Internet, uma vez que a escala do negócio é pequena, a complexidade do negócio é limitada e a quantidade de pesquisa e desenvolvimento não é grande, uma arquitetura monolítica é mais adequada neste momento .
2. Porquê: Porquê a servitização?
O objetivo da servitização é combinar de forma flexível serviços reutilizáveis para responder rapidamente às mudanças nas necessidades dos negócios e apoiar tentativas e erros rápidos nos negócios.
Como avaliar se um sistema precisa de servitização? Normalmente precisamos considerar principalmente os seguintes fatores:
- É um sistema grande e complexo?
- Há duplicação de construção?
- O negócio é incerto?
- A tecnologia restringe o desenvolvimento empresarial?
- Existem gargalos de desempenho no sistema?
Se um sistema apresentar os problemas acima, então é a melhor maneira de realizar a atualização técnica geral e a reconstrução comercial do sistema por meio da servitização.
3. Como: Como implementar a servitização?
A estrutura organizacional é ajustada
. Para melhor implementar a servitização do sistema, o ajuste da estrutura organizacional é uma etapa muito crítica.
Porque depois que o sistema for orientado a serviços, alguns problemas da equipe serão estendidos, como divisão de trabalho da equipe, colaboração, etc. Portanto, só ajustando a estrutura organizacional existente é que os benefícios da servitização podem ser maximizados.
Depois que a infraestrutura orientada a serviços
é orientada a serviços, sua ênfase principal está na comunicação entre diferentes serviços , o que dará origem a uma série de problemas complexos que precisam ser resolvidos, como registro de serviço, publicação de serviço, invocação de serviço, balanceamento de carga e monitoramento. Espere, isso requer uma solução completa de governança de serviços.
Portanto, a condição necessária para a servitização é ter um quadro orientado para os serviços.Este quadro orientado para os serviços deve ser capaz de resolver estes problemas complexos, e o desempenho do quadro orientado para os serviços é particularmente importante.
Existem atualmente duas estruturas orientadas a serviços convencionais: SpringCloud e Dubbo .
Meios importantes de servitização
- Design sem estado: A ausência de estado facilita o aumento e a redução rápida dos serviços.
- Design dividido: simplifique o complexo, reduza a dificuldade, divida e conquiste.
4. Resumo
Em uma frase: dissociação de negócios, reutilização de capacidades e entrega eficiente .
2.2 Projeto assíncrono
1. O quê: O que é assíncrono?
Assíncrono é um conceito de design relativo à sincronização.
Sincronização significa que quando uma chamada é emitida, o chamador deve esperar que a chamada retorne o resultado antes de continuar a execução.
Assíncrono significa que quando uma chamada é emitida, o chamador não obterá o resultado imediatamente, mas poderá continuar a realizar operações subsequentes até que o chamador conclua o processamento, e o chamador será notificado por meio de status, notificação ou retorno de chamada.
2. Por quê: Por que assíncrono?
Por meio do assíncrono, a latência pode ser reduzida, o desempenho geral do sistema pode ser melhorado e a experiência do usuário pode ser melhorada.
3. Como: Como implementar de forma assíncrona?
1) Assíncronas no nível de E/S
Chamadas assíncronas no nível de E/S são o que costumamos chamar de modelo de E/S, que inclui bloqueio, não bloqueio, síncrono e assíncrono.
No kernel do sistema operacional Linux, existem cinco modos de interação de IO diferentes integrados, ou seja, IO de bloqueio, IO sem bloqueio, IO multiplexado, IO acionado por sinal e IO assíncrono . Em relação ao modelo de IO de rede, no Linux, o modelo mais utilizado e com melhor desempenho é o modelo síncrono sem bloqueio.
Técnicas comuns para chamadas assíncronas
- Comunicação assíncrona: NIO, Netty
2) Processo assíncrono no nível da lógica de negócios
O processo assíncrono no nível da lógica de negócios significa que nosso aplicativo pode ser executado de forma assíncrona na lógica de negócios.
Normalmente, negócios mais complexos terão processos com muitas etapas. Se todas as etapas estiverem sincronizadas, quando uma dessas etapas travar, todo o processo ficará travado. Obviamente, o desempenho de tal processo não será muito alto.
Por isso, na indústria, se quisermos melhorar o desempenho e a simultaneidade, utilizaremos basicamente processos assíncronos.
Técnicas comuns para processos assíncronos
- Fila de mensagens: desacoplamento assíncrono, redução de pico de tráfego
- Programação assíncrona: multithreading, pool de threads
- Orientado a eventos: padrão publicar-assinar (padrão observador)
- Driver de trabalho: tarefas agendadas, XXL-JOB
4. Resumo
Resumo de uma frase: Embora a eficiência da execução assíncrona seja alta, a complexidade e a dificuldade de programação também são altas, portanto, não abuse dela .
2.3 Projeto de agrupamento
1. O quê: O que é tecnologia de pooling?
A tecnologia de pooling é uma tecnologia comum para melhorar o desempenho. Ela mantém recursos "caros" e "demorados" em um "pool" específico para reduzir a criação e destruição repetida de recursos e facilitar o gerenciamento e a reutilização unificados, melhorando assim o desempenho do sistema.
2. Porquê: Por que é necessária a tecnologia de pooling?
A tecnologia de pooling é usada para reduzir a sobrecarga do sistema causada pela criação e destruição repetidas e melhorar o desempenho do sistema.
3. Como: Como implementar tecnologia de pooling?
Grupo de discussão
- ForkJoinPool
- Os parâmetros principais do pool de threads ThreadPoolExecutor
precisam ser definidos com base no cenário de negócios. Por exemplo, o número de threads pode ser definido com base no fato de a tarefa ser intensiva em IO ou CPU.
conjunto de conexões
- Conjunto de conexões de banco de dados
- Conjunto de conexões Redis
- Conjunto de conexões HttpClient
4. Resumo
Numa frase: gestão unificada e reutilização de recursos para melhorar o desempenho e a utilização de recursos .
2.4 Projeto de cache
1. O quê: O que é cache?
O cache é uma tecnologia que melhora a velocidade de acesso aos recursos . Suas características são: escrever uma vez, ler inúmeras vezes.
A essência do cache é trocar espaço por tempo. Ele sacrifica a natureza dos dados em tempo real e usa dados armazenados em cache na memória em vez de ler os dados mais recentes do servidor de destino (como banco de dados), o que pode reduzir a pressão do servidor e a latência da rede.
2. Por quê: Por que usar o cache?
O objetivo do uso do cache é obviamente melhorar o desempenho do sistema (alto desempenho, alta simultaneidade).
Quais são as vantagens e desvantagens de usar cache?
vantagem
- Otimize o desempenho e reduza o tempo de resposta
- Reduza o estresse e evite sobrecarga do servidor
- Economize largura de banda e alivie gargalos de rede
deficiência
- consome espaço extra
- Pode haver problemas de consistência de dados
3. Como: Como usar o cache?
1) Como melhorar a velocidade de acesso aos recursos?
Coloque os recursos mais próximos dos usuários ou em sistemas que possam ser acessados mais rapidamente .
2) Onde o cache pode ser usado?
| Classificação de cache | dimensões de cache | descrever |
|---|---|---|
| cache do cliente | cache do navegador | 1. O ponto de cache mais próximo do usuário usa o dispositivo terminal do usuário para armazenar recursos de rede, o que é mais econômico. 2. Geralmente usado para armazenar imagens em cache, JS, CSS, etc., que podem ser controlados por meio dos atributos Expires e Cache-Control no cabeçalho da mensagem. |
| Cache do servidor | Cache CDN | 1. Armazene recursos estáticos como HTML, CSS, JS, etc. 2. Atuar como um desvio para reduzir a carga no servidor de origem. |
| Cache do servidor | cache de proxy reverso | 1. Separação de recursos dinâmicos e estáticos. Geralmente, os recursos estáticos são armazenados em cache e os recursos dinâmicos são encaminhados ao servidor de aplicativos para processamento. |
| Cache do servidor | cache local | 1. Cache de memória, velocidade de acesso rápida, adequado para cenários onde pequenas quantidades de dados são armazenadas em cache. 2. Cache de disco rígido, cache de dados em arquivos, velocidade de acesso é mais rápida do que obter dados pela rede, adequado para cenários onde grandes quantidades de dados são armazenadas em cache. |
| Cache do servidor | Cache distribuído | 1. Elementos arquitetônicos necessários na arquitetura de sites em grande escala. 2. Armazene em cache os dados do ponto de acesso para reduzir a pressão do banco de dados. |
3) Que tipo de cache é mais dispendioso de introduzir? Por que é mais caro introduzir?
O custo de introdução do cache local e do cache distribuído será maior. Como os recursos desses dois tipos de cache estão relacionados aos negócios e precisam ser calculados pela lógica de negócios, os requisitos de consistência de dados entre o cache e os dados originais são maiores.
4) 1 indicador principal: taxa de acerto do cache.
Quanto maior a taxa de acerto do cache, melhor será o desempenho. A fórmula de cálculo é: taxa de acertos do cache = número de acertos/(número de acertos + número de erros).
Como melhorar a taxa de acerto do cache? As estratégias comuns são as seguintes:
- Duração do cache: nas mesmas condições, quanto maior a duração do cache, maior será a taxa de acertos do cache.
- Atualização de cache: quando os dados são alterados, a atualização direta do valor do cache tem uma taxa de acerto mais alta do que a remoção do cache.
- Capacidade do cache: quanto maior a capacidade do cache, mais dados serão armazenados em cache e maior será a taxa de acertos do cache.
- Granularidade do cache: quanto menor a granularidade do cache, menores serão as alterações nos dados e maior será a taxa de acertos do cache (reduz o risco de chaves grandes)
- Pré-aquecimento do cache: os dados do ponto de acesso são armazenados em cache antecipadamente para melhorar a taxa de acertos do cache
Resumo em uma frase: Como melhorar a taxa de acertos do cache? Isso permite que os dados residam no cache por um longo período de tempo .
5) 1 questão central: consistência do cache.
A consistência do cache refere-se à consistência entre o cache e os dados de origem. Para garantir a consistência do cache, as coisas ficarão complicadas.
Como conseguir consistência de cache? As estratégias de cache comumente usadas são as seguintes:
Na arquitetura Cache/DB, a estratégia de cache é como ler e gravar dados do cache e do banco de dados.
1. Modo de cache de expiração: padrão de expiração de cache
- Recursos: A maneira mais simples de obter consistência de cache, definir o tempo de expiração do cache para obter consistência eventual
- Desvantagens: Necessidade de tolerar inconsistências de dados no tempo de expiração definido
2. Padrão Cache Aside: Padrão Cache Aside
- Leitura: Cache Hit, retorna diretamente dados armazenados em cache, Cache Miss, carrega dados do banco de dados para cache e retorna
- Gravar: escreva primeiro no banco de dados e depois exclua os dados correspondentes no cache
- Desvantagens: Este modo pode causar inconsistências de gravação dupla entre o cache e o banco de dados. Você pode usar o modo de exclusão dupla atrasada para minimizar essa inconsistência.
3. Modo de escrita assíncrona: Write Behind Pattern
- Leia: Cache Hit, retorna diretamente dados em cache, Cache Miss, retorna diretamente vazio
- Gravação: primeiro grave no banco de dados, entregue os novos dados gravados ao MQ por meio do banco de dados, depois consuma o MQ pelo processo assíncrono e, finalmente, grave os dados no cache.
Resumo em uma frase: Como conseguir consistência de cache? Isso permite que cada operação de leitura obtenha os dados mais recentes da operação de gravação .
4. Resumo
Resumo de uma frase: O cache é o rei em lidar com alta simultaneidade (o cache é o rei) .
2.5 Projeto de armazenamento de dados
1. O quê: O que é armazenamento de dados?
O armazenamento de dados geralmente se refere a dados gravados em algum formato em um meio de armazenamento interno ou externo de computador.
As mídias de armazenamento comuns incluem: fitas, discos, etc. A forma como os dados são armazenados varia dependendo do meio de armazenamento. Os dados na fita são acessados apenas no modo de arquivo sequencial; no disco, o acesso sequencial ou o acesso direto podem ser usados de acordo com os requisitos de uso. O método de armazenamento de dados está intimamente relacionado à organização do arquivo de dados, a chave é estabelecer a correspondência entre a ordem lógica e física dos registros e determinar o endereço de armazenamento para melhorar a velocidade de acesso aos dados.
Os sistemas comuns de gerenciamento de armazenamento de dados incluem: banco de dados (MySQL), mecanismo de pesquisa (Elasticserach), sistema de cache (Redis), fila de mensagens (Kafka), etc. Este também é o foco da nossa próxima discussão.
2. Por quê: Por que o design do armazenamento de dados é importante?
Na era da Internet, quando a simultaneidade do sistema atinge um determinado estágio, o armazenamento de dados muitas vezes se torna um gargalo de desempenho. Se você não realizar um bom design no início, encontrará dificuldades na expansão horizontal posterior e no subbanco de dados e subtabela.
Por que o gargalo de desempenho geralmente está no armazenamento de dados e não no serviço de aplicativo?
Como os serviços de aplicativos são basicamente sem estado e podem ser facilmente expandidos horizontalmente, o alto desempenho dos serviços de aplicativos será relativamente simples. Mas para alto desempenho de armazenamento de dados, é relativamente mais complicado porque os dados têm estado.
3. Como: Como projetar o armazenamento de dados?
As soluções comuns para resolver o alto desempenho do armazenamento incluem o seguinte: A maior parte da indústria é construída em torno disso ou cria derivados e extensões relacionados.
1) Separação entre leitura e escrita
Os sistemas da Internet tendem a ler mais e escrever menos, portanto, o primeiro passo na otimização do desempenho é separar a leitura e a escrita.
A separação de leitura e gravação é um método de otimização que separa as operações de leitura das operações de gravação. Podemos usar essa tecnologia para resolver o problema de gargalo de desempenho do armazenamento de dados.
Atualmente, a solução de separação leitura-gravação popular na indústria é geralmente baseada na arquitetura do modelo mestre-escravo , que implementa a separação leitura-gravação das ações de acesso, introduzindo uma camada proxy de acesso a dados. Especificamente, existem duas maneiras:
Implementando a separação de leitura e gravação por meio de proxy independente
A vantagem de introduzir um proxy de acesso a dados é que o programa de origem pode obter a separação de leitura e gravação sem quaisquer alterações. A desvantagem é que, devido à adição de uma camada extra de middleware como proxy de transferência, o desempenho será reduzido e os agentes de acesso a dados também podem facilmente se tornar gargalos de desempenho e há certos custos de manutenção. Os produtos típicos incluem MyCAT, agente de banco de dados Alibaba Cloud-RDS, etc.
Outra maneira de obter a separação de leitura e gravação por meio do SDK incorporado é carregar a camada proxy de acesso a dados no lado do aplicativo e integrá-la ao aplicativo por meio do SDK, o que pode evitar a perda de desempenho e os custos de manutenção causados por uma camada independente . problema alto. No entanto, este método possui certos requisitos para a linguagem de desenvolvimento e apresenta problemas de aplicabilidade. Produtos típicos incluem ShardingSphere, etc.
2) Partição de dados
"Particionamento" refere-se ao processo de divisão física de dados em partes separadas de dados para armazenamento. Divida os dados em partições que possam ser gerenciadas e acessadas de forma independente. O particionamento pode melhorar a escalabilidade, reduzir a contenção e otimizar o desempenho. Além disso, fornece um mecanismo para segmentar dados por padrões de uso.
Por que particionar os dados?
- Melhore a escalabilidade . A expansão de um único sistema de banco de dados acabará atingindo os limites do hardware físico. Se os dados forem divididos em diversas partições, cada partição será hospedada em um servidor separado, permitindo que o sistema seja ampliado quase infinitamente.
- Melhorar o desempenho . As operações de acesso a dados em cada partição são executadas através de volumes de dados menores. Quando feito corretamente, o particionamento pode melhorar a eficiência do seu sistema.
- Fornece flexibilidade operacional . O uso de partições pode otimizar operações, maximizar a eficiência do gerenciamento e reduzir custos de diversas maneiras.
- Melhore a usabilidade . O isolamento de dados em vários servidores evita pontos únicos de falha. Se uma instância falhar, apenas os dados dessa partição ficarão indisponíveis. As operações em outras partições podem continuar.
Como projetar partições?
Três estratégias típicas para particionamento de dados:
- Particionamento horizontal (ou seja, fragmentação) . Nesta estratégia, cada partição é um armazenamento de dados independente, mas todas as partições possuem o mesmo esquema. Cada partição, chamada de fragmento, contém um subconjunto específico de dados, como todos os pedidos de um conjunto específico de clientes. O fator mais importante é a escolha da chave de fragmento. A fragmentação distribui a carga por várias máquinas, reduzindo a contenção e melhorando o desempenho.
- Particionamento vertical . Nesta estratégia, cada partição contém um subconjunto de campos do item no armazenamento de dados. Os campos foram segmentados com base em seus padrões de uso. Por exemplo, coloque os campos acessados com frequência em uma partição vertical e os campos acessados com menos frequência em outra partição vertical. O uso mais comum do particionamento vertical é reduzir os custos de E/S e de desempenho associados à busca de itens acessados com frequência.
- Partição funcional . Nesta estratégia, os dados foram agregados com base em como são usados por cada contexto limitado no sistema. Por exemplo, um sistema de comércio eletrônico pode armazenar dados de faturas em uma partição e dados de inventário de produtos em outra partição. Melhore o desempenho do isolamento e do acesso a dados por meio do particionamento funcional.
3) Subbanco de dados e subtabela
Todos devem estar familiarizados com o conceito de subbanco de dados e subtabela, que pode ser dividido em dois métodos: subbanco de dados e subtabela:
- Divisão de tabela: refere-se à divisão dos dados de uma tabela em várias tabelas de acordo com certas regras para reduzir o tamanho dos dados da tabela e melhorar a eficiência da consulta.
- Divisão de banco de dados: refere-se à divisão dos dados em um banco de dados em vários bancos de dados de acordo com certas regras para reduzir a pressão em um único servidor e melhorar o desempenho de leitura e gravação (como: CPU, memória, disco, IO).
Duas soluções típicas para fragmentação de bancos de dados e tabelas:
dividir verticalmente
- Divisão vertical da tabela : ou seja, uma tabela grande é dividida em tabelas pequenas e diferentes "campos" em uma tabela são divididos em várias tabelas. Por exemplo, uma biblioteca de produtos divide informações básicas do produto, inventário de produtos, informações do vendedor, etc. diferentes tabelas de banco de dados.
- Decomposição vertical : Divida diferentes áreas de negócios em um sistema em várias bibliotecas de negócios. Por exemplo: biblioteca de produtos, biblioteca de pedidos, biblioteca de usuários, etc.
dividir horizontalmente
- Divisão horizontal da tabela : Divida os dados em várias tabelas de acordo com determinadas dimensões.No entanto, como várias tabelas ainda pertencem a um banco de dados, a granularidade do bloqueio é reduzida, o que melhora o desempenho da consulta até certo ponto, mas ainda há um gargalo no desempenho de IO.
- Divisão horizontal de banco de dados : Divida os dados em vários bancos de dados de acordo com determinadas dimensões, reduzindo a pressão em uma única máquina e banco de dados e melhorando o desempenho de leitura e gravação.
Métodos comuns de divisão horizontal
- Subbanco de dados e tabela de intervalo : use o método range para dividir a chave de fragmentação de acordo com o intervalo. Por exemplo: divida o banco de dados em tabelas de acordo com o intervalo de tempo.
- Fragmentação de banco de dados hash e fragmentação de tabela : use o módulo hash para fragmentação de chaves por meio de hash. Por exemplo: subbanco de dados e tabela baseada no ID do usuário.
Para mais informações sobre subbanco de dados e subtabela, consulte o artigo: Prática de Desenvolvimento e Design: Plano de Implementação de Subbanco de Dados e Subtabela , que não será descrito aqui.
4) Separação de quente e frio
A separação quente e fria refere-se ao armazenamento separado de dados frios históricos e dados quentes atuais. O armazenamento frio armazena apenas os dados que atingem o estado final. O armazenamento quente também armazena dados que precisam modificar os campos. Isso pode reduzir o volume de armazenamento do dados quentes atuais. Melhore o desempenho.
Como determinar se os dados são dados frios ou dados quentes? Em outras palavras, em que circunstâncias a separação a quente e a frio pode ser usada?
- Dimensão de tempo : os usuários podem aceitar dados novos e antigos para serem consultados separadamente. Por exemplo, para dados de pedidos, podemos usar os dados de três meses atrás como dados frios e os dados de três meses como dados quentes.
- Dimensão de estado : depois que os dados atingem o estado final, há apenas requisitos de leitura e nenhum requisito de escrita. Por exemplo, para dados de pedidos, podemos usar pedidos concluídos como dados frios e outros como dados quentes.
4. Resumo
Em uma frase: através da divisão, a pressão de leitura e escrita é dispersa e a pressão de armazenamento é dispersa, melhorando assim o desempenho .
4. Finalmente
Ao buscar o alto desempenho do sistema, não ignore o fator custo. Porque alto desempenho geralmente significa alto custo.
Portanto, ao projetar sistemas de alto desempenho, deve-se prestar atenção especial à minimização de custos e à maximização de benefícios.
Por fim, como técnicos, devemos ter uma busca técnica: aprender a fazer mais trabalhos com os mesmos recursos.