Modo de alto desempenho de servidor único
Alto desempenho é a busca de todo programador. Quer estejamos construindo um sistema ou escrevendo uma linha de código, esperamos alcançar alto desempenho, e alto desempenho é a parte mais complicada. O sistema operacional, CPU, memória, disco, Cache, rede, linguagem de programação, arquitetura, etc., cada um tem o potencial de afetar o sistema para alcançar alto desempenho.
Uma linha de logs de depuração inadequados pode reduzir o desempenho do servidor de TPS 30000 para 8000;
Um parâmetro tcp_nodelay, é possível estender o tempo de resposta de 2 milissegundos para 40 milissegundos.
Portanto, alcançar a computação de alto desempenho é uma tarefa muito complexa e desafiadora. Diferentes estágios no processo de desenvolvimento do sistema de software estão relacionados a se o alto desempenho pode ser alcançado no final.
Da perspectiva de um arquiteto, é claro, atenção especial deve ser dada ao projeto de uma arquitetura de alto desempenho. O design de arquitetura de alto desempenho se concentra principalmente em dois aspectos:
-
1. Tente melhorar o desempenho de um único servidor e maximize o desempenho de um único servidor.
-
2. Se um único servidor não puder oferecer suporte ao desempenho, crie uma solução de cluster de servidor.
Além dos dois pontos acima, se o sistema final pode alcançar alto desempenho também está relacionado à implementação e codificação específicas.
No entanto, o projeto de arquitetura é a base do alto desempenho.Se o projeto de arquitetura não atingir alto desempenho, o espaço para melhorias na implementação e codificação específicas subsequentes é limitado. Visualmente falando, o design da arquitetura determina o limite superior do desempenho do sistema e os detalhes de implementação determinam o limite inferior do desempenho do sistema.
Uma das chaves para o alto desempenho de um único servidor é o modelo de simultaneidade adotado pelo servidor. O modelo de simultaneidade tem os dois pontos principais de design a seguir:
-
1. Como o servidor gerencia as conexões.
-
2. Como o servidor lida com a solicitação.
Os dois pontos de design acima estão relacionados ao modelo de E/S e ao modelo de processo do sistema operacional.
-
Modelo de E/S: bloqueante, não bloqueante, síncrono, assíncrono.
-
Modelo de processo: processo único, multiprocesso, multithread.
Os pontos de conhecimento básico acima serão usados ao introduzir o modelo de simultaneidade em detalhes abaixo, então sugiro que você primeiro verifique o domínio desses conhecimentos básicos. Para obter mais informações, consulte os três volumes de "Programação de Rede UNIX".
PPC (processo por conexão)
Seu significado significa que toda vez que há uma nova conexão, um novo processo é criado para atender especificamente a requisição de conexão, modelo adotado pelos servidores de rede UNIX tradicionais.
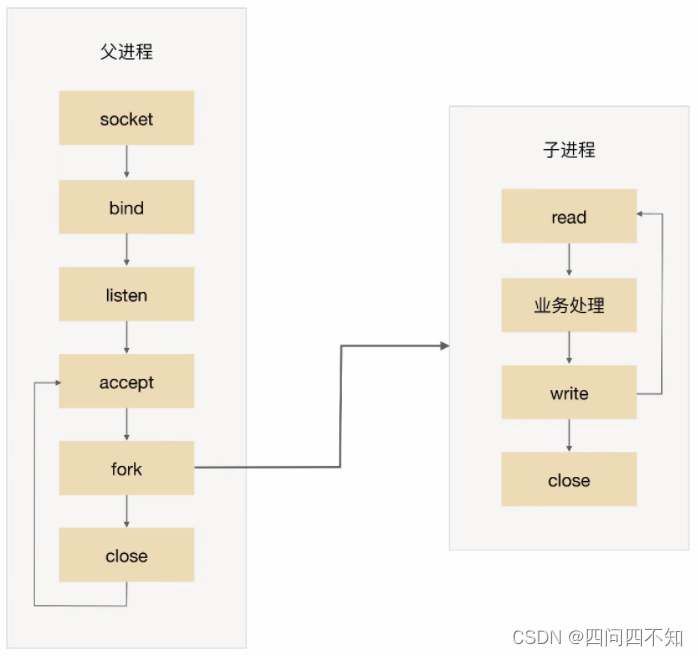
O fluxograma básico é:
-
O processo pai aceita a conexão (aceite na figura).
-
O processo pai "bifurca" o processo filho (bifurcação na figura).
-
O processo filho manipula as solicitações de leitura e gravação da conexão (o processo filho lê, processa negócios e grava na figura).
-
O processo filho fecha a conexão (fecha no processo filho na figura).
Observe que há um pequeno detalhe na figura. Após o processo pai "bifurcar" o processo filho, ele chama diretamente close, o que parece fechar a conexão. Na verdade, apenas reduz a contagem de referência do descritor de arquivo da conexão por um. O fechamento real da conexão é esperar Depois que o processo filho também chama close e a contagem de referência do descritor de arquivo fd (Descritor de arquivo) correspondente à conexão torna-se 0, o sistema operacional realmente fecha a conexão. detalhes, consulte "Programação de Rede UNIX: Volume 1".
O modo PPC é simples de implementar, sendo mais indicado para situações onde o número de conexões com o servidor não é tão grande, como um servidor de banco de dados.
Para servidores de negócios comuns, antes do surgimento da Internet, esse modelo realmente funcionava bem porque as visitas e simultaneidade do servidor não eram tão grandes. O CERN httpd, o primeiro servidor da web do mundo, adotou esse modelo (para obter detalhes, consulte https: //en.wikipedia.org/wiki/CERN_httpd).
Após o surgimento da Internet, o número de simultaneidade e visitas de servidores aumentou de dezenas para dezenas de milhares, destacando-se as desvantagens desse modelo, principalmente nos seguintes aspectos:
-
O fork é caro: do ponto de vista do sistema operacional, o custo de criação de um processo é muito alto. Ele precisa alocar muitos recursos do kernel e copiar a imagem da memória do processo pai para o processo filho. Mesmo que o sistema operacional atual use a tecnologia Copy on Write (cópia na gravação) ao copiar a imagem da memória, o custo geral da criação de um processo ainda é muito alto.
-
A comunicação entre os processos pai e filho é complicada: quando o processo pai "bifurca" o processo filho, o descritor de arquivo pode ser copiado do processo pai para o processo filho através da cópia da imagem de memória, mas depois que a "bifurcação" é concluída, o a comunicação entre os processos pai e filho é mais problemática, e IPC (Interprocess Communication) e outros esquemas de comunicação de processo. Por exemplo, o processo filho precisa informar ao processo pai quantas solicitações ele processou antes de fechar para oferecer suporte ao processo pai para estatísticas globais, então o processo filho e o processo pai devem usar o esquema IPC para transferir informações.
-
O número de conexões simultâneas suportadas é limitado: se cada conexão sobreviver por muito tempo e novas conexões surgirem continuamente, o número de processos aumentará e a frequência de agendamento e comutação de processos do sistema operacional também aumentará. A pressão também aumentará . Portanto, em circunstâncias normais, o número máximo de conexões simultâneas que uma solução PPC pode manipular é de várias centenas.
Modo Apache Prefork
No modo PPC, ao entrar uma conexão, um novo processo é bifurcado para processar a requisição de conexão. Devido ao alto custo do processo fork, o usuário pode se sentir mais lento ao acessar. O surgimento do modo prefork vem para resolver isso problema.
Como o nome indica, prefork é criar um processo com antecedência (pre-fork). O sistema pré-cria um processo ao iniciar, para então começar a aceitar as requisições dos usuários, quando uma nova conexão chega, a operação do fork process pode ser omitida, permitindo aos usuários acesso mais rápido e melhor experiência. O diagrama básico do prefork é:
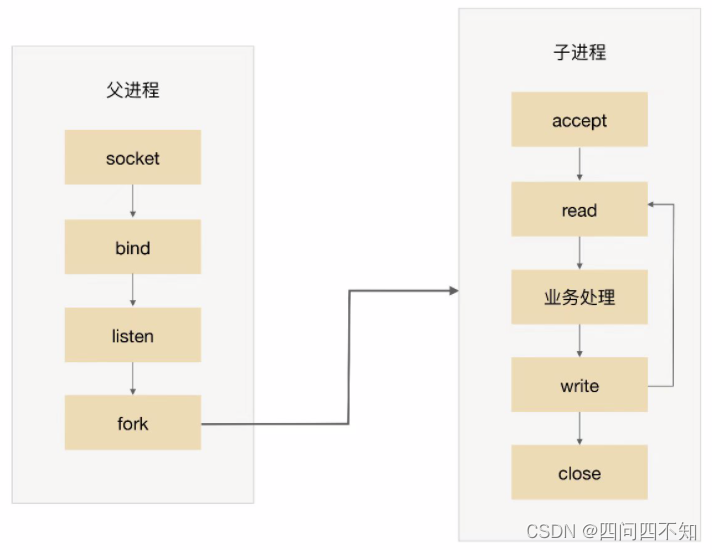
A chave para a realização do prefork é que vários processos filhos aceitam o mesmo socket.Quando uma nova conexão entra, o sistema operacional garante que apenas um processo pode finalmente aceitar com sucesso. Mas também há um pequeno problema aqui: o fenômeno do "grupo chocante" significa que, embora apenas um processo filho possa aceitar com sucesso, todos os processos filho bloqueados na aceitação serão despertados, o que leva a agendamento de processo desnecessário e troca de contexto. Felizmente, o sistema operacional pode resolver esse problema.Por exemplo, o kernel após a versão 2.6 do Linux resolveu o problema de aceitar o rebanho trovejante.
O modo prefork, como o PPC, ainda tem o problema de comunicação complexa entre os processos pai e filho e o número limitado de conexões simultâneas suportadas, portanto, não há muitas aplicações práticas no momento. O servidor Apache fornece o modo MPM prefork, que é recomendado para sites que requerem confiabilidade ou compatibilidade com software antigo. Por padrão, um máximo de 256 conexões simultâneas são suportadas.
Além do modo Prefork, o Apache também possui os modos Worker e Event. Em comparação com o modo prefork, o worker usa um modo misto de multiprocesso e multithread. O modo worker também pré-bifurca alguns subprocessos primeiro e depois cria alguns threads para cada subprocesso, incluindo um thread de escuta Cada solicitação será processada Atribuída a um segmento para atender. As threads são mais leves que os processos, porque as threads compartilham o espaço de memória do processo pai, portanto, o uso de memória será reduzido. Em cenários de alta simultaneidade, haverá mais threads disponíveis do que o prefork e o desempenho será melhor. ; Além disso, se houver um problema com um encadeamento, isso também causará problemas com encadeamentos no mesmo processo.Se houver problemas com vários encadeamentos, isso afetará apenas parte do Apache, não todos. Devido ao uso de multi-processo e multi-thread, é necessário considerar a segurança dos threads. Ao usar conexão longa keep-alive, um determinado thread sempre estará ocupado, mesmo que não haja solicitação no meio, precisa esperar até que o timeout seja liberado (esse problema também existe no modo prefork). O modo de evento é o modo de trabalho mais recente do Apache. É muito semelhante ao modo de trabalho. A diferença é que ele resolve o problema de desperdício de recursos de encadeamento durante conexões longas de manutenção de atividade. No modo de trabalho de evento, haverá alguns dedicados threads É usado para gerenciar esses threads do tipo keep-alive.Quando chega uma requisição real, a thread que passa a requisição para o servidor, e permite que ela seja liberada após a conclusão da execução. Isso aprimora a manipulação de solicitações em cenários de alta simultaneidade.
TPC (Thread por conexão)
Seu significado significa que toda vez que há uma nova conexão, um novo thread é criado para processar especificamente a solicitação de conexão.
Em comparação com os processos, os encadeamentos são mais leves e o consumo de criação de encadeamentos é muito menor que o dos processos; ao mesmo tempo, os multiencadeamentos compartilham o espaço de memória do processo e a comunicação do encadeamento é mais simples do que a comunicação do processo. Portanto, o TPC realmente resolve ou enfraquece o problema do alto custo do fork do PPC e o problema da comunicação complicada entre os processos pai e filho.
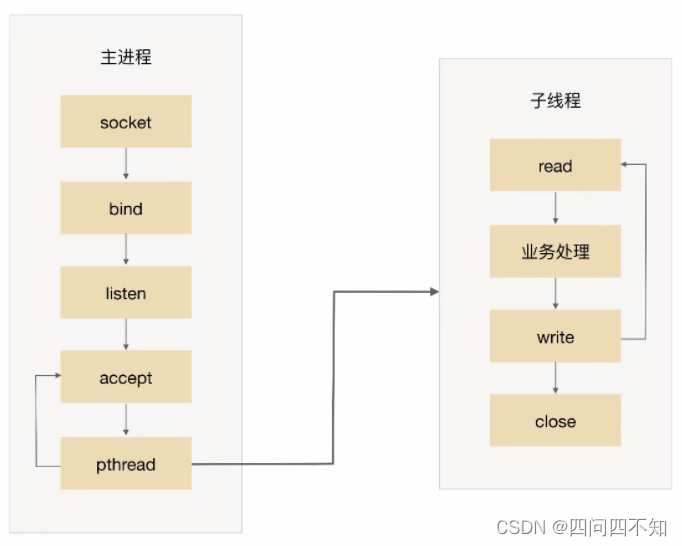
O processo básico do TPC é:
-
O processo pai aceita a conexão (aceite na figura).
-
O processo pai cria um thread filho (pthread na figura).
-
O subencadeamento lida com as solicitações de leitura e gravação da conexão (leitura do subencadeamento, processamento de negócios e gravação na figura).
-
A thread filha fecha a conexão (feche na thread filha na figura).
Observe que, em comparação com o PPC, o processo principal não usa conexões "fechadas". O motivo é que os subthreads compartilham o espaço do processo principal e os descritores de arquivo conectados não são copiados, portanto, apenas um fechamento é necessário.
Embora o TPC resolva os problemas de alto custo de fork e comunicação de processo complexo, ele também apresenta novos problemas, especificamente:
-
Embora o custo de criar um thread seja menor do que o de criar um processo, ele não é isento de custos.Ainda há problemas de desempenho quando há alta simultaneidade (como dezenas de milhares de conexões por segundo).
-
Não há necessidade de comunicação entre processos, mas a exclusão mútua e o compartilhamento entre threads introduzem complexidade, o que pode levar a problemas de impasse se você não for cuidadoso.
-
Multi-threads afetarão uns aos outros. Quando um thread é anormal, pode causar a saída de todo o processo (por exemplo, a memória está fora dos limites).
Além de introduzir novos problemas, o TPC ainda tem o problema de escalonamento de threads de CPU e custos de comutação. Portanto, o esquema TPC é basicamente semelhante ao esquema PPC em essência.No cenário de centenas de conexões simultâneas, o esquema PPC é mais usado, porque o esquema PPC não tem risco de impasse e não afeta uns aos outros entre vários processos Maior estabilidade.
pré-encadear
No modo TPC, um novo thread é criado para processar a solicitação de conexão quando uma conexão chega. Embora criar um thread seja mais leve do que criar um processo, ainda tem um certo custo, e o modo prethread é para resolver esse problema.
Semelhante ao prefork, o modo prethread cria threads com antecedência e começa a aceitar as solicitações do usuário. Quando uma nova conexão chega, a operação de criação de threads pode ser omitida, fazendo com que os usuários se sintam mais rápidos e tenham uma experiência melhor.
Como o compartilhamento de dados e a comunicação entre várias threads são mais convenientes, a implementação de prethread é, na verdade, mais flexível do que a de prefork. Os métodos de implementação comuns são os seguintes:
O processo principal aceita e, em seguida, entrega a conexão a um thread para processamento.
Todos os sub-threads tentam aceitar e, finalmente, apenas um thread aceita com sucesso.O diagrama básico do esquema é o seguinte: O
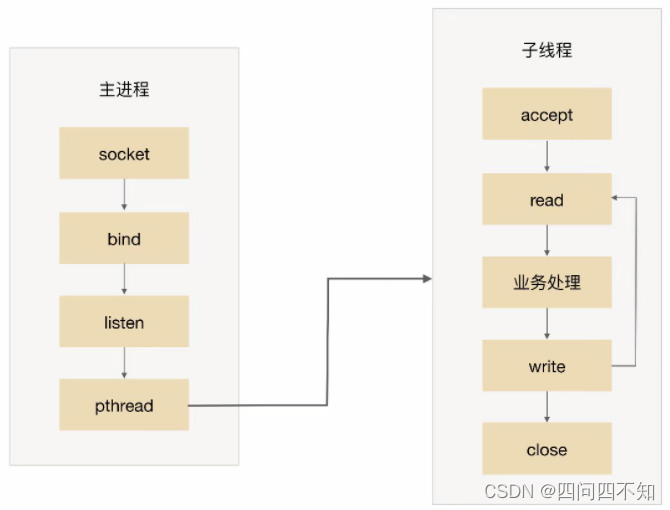
modo de trabalho MPM do servidor Apache é essencialmente um esquema de pré-thread , mas foi ligeiramente melhorado. O servidor Apache primeiro criará vários processos e, em seguida, criará vários encadeamentos em cada processo. O processo filho continua a fornecer serviços sem fazer com que todo o servidor desligue.
Prethread pode, teoricamente, suportar mais conexões simultâneas do que prefork, e o modo de trabalho MPM do servidor Apache suporta 16 × 25 = 400 threads de processamento simultâneos por padrão.
reator
O principal problema do modo PPC é que cada conexão precisa criar um processo (para resumir, usamos apenas PPC e processo como exemplo, na verdade, ele é substituído por TPC e thread, o princípio é o mesmo) , e o processo é destruído após o término da conexão. Fazer isso é realmente um grande desperdício. Para resolver esse problema, uma ideia natural é a reutilização de recursos, ou seja, ao invés de criar um processo separado para cada conexão, um pool de processos é criado para atribuir conexões aos processos, e um processo pode cuidar do negócio de várias conexões.
Depois de introduzir o método de processamento de pool de recursos, uma nova questão surgirá: como um processo pode lidar com eficiência com vários serviços conectados? Quando uma conexão é feita a um processo, o processo pode adotar o fluxo de processamento de "leitura -> processamento de negócios -> gravação" Se a conexão atual não tiver dados para ler, o processo será bloqueado na operação de leitura. Este método de bloqueio não tem problema no cenário de uma conexão e um processo, mas se um processo lida com várias conexões, o processo é bloqueado na operação de leitura de uma determinada conexão. Neste momento, mesmo que outras conexões tenham dados para ler, o processo não pode ler Processing, é óbvio que alto desempenho não pode ser alcançado dessa maneira.
A maneira mais fácil de resolver esse problema é alterar a operação de leitura para non-blocking e, em seguida, o processo pesquisa continuamente várias conexões. Este método pode resolver o problema de bloqueio, mas a solução não é elegante. Em primeiro lugar, o polling consome CPU; em segundo lugar, se um processo lida com dezenas de milhares de conexões, a eficiência do polling é muito baixa.
Para melhor resolver os problemas acima, é fácil pensar que o processo só processa quando há dados na conexão, que é a fonte da tecnologia de multiplexação de E/S.
A tecnologia de multiplexação de E/S pode ser resumida em dois pontos principais de implementação:
-
Quando várias conexões compartilham um objeto de bloqueio, o processo só precisa esperar em um objeto de bloqueio sem consultar todas as conexões. Métodos de implementação comuns incluem select, epoll, kqueue, etc.
-
Quando uma determinada conexão possui novos dados que podem ser processados, o sistema operacional notificará o processo e o processo retornará do estado bloqueado para iniciar o processamento de negócios.
A multiplexação de E/S combinada com pool de threads resolve perfeitamente os problemas de PPC e TPC, e os "grandes deuses" deram a ela um nome muito bom: Reactor, que significa "reator" em chinês. Pensando em "reator nuclear", parece assustador. Na verdade, a "reação" aqui não significa reação de fusão ou fissão, mas "resposta de evento ", que pode ser entendida como " quando vier um evento, eu responderei Resposta ", o "I" aqui é o Reactor, a resposta específica é o código que escrevemos, o Reactor chamará o código correspondente de acordo com o tipo de evento a ser processado. O modo Reactor também é chamado de modo Dispatcher (você verá uma classe com esse nome em muitos sistemas de código aberto, que na verdade implementa o modo Reactor), que está mais próximo do significado do modo em si, ou seja, o I/O evento de monitoramento unificado de multiplexação, Atribuição (Despacho) recebida a um processo após o evento.
Os principais componentes do modo Reactor incluem o Reactor e o pool de recursos de processamento (pool de processos ou pool de threads), no qual o Reactor é responsável por monitorar e distribuir eventos e o pool de recursos de processamento é responsável pelo processamento de eventos. À primeira vista, a implementação do Reactor é relativamente simples, mas na verdade, combinado com diferentes cenários de negócios, o esquema de implementação específico do modo Reactor é flexível e mutável, principalmente refletido em:
O número de Reatores pode variar: pode ser um Reator ou vários Reatores.
O número de pools de recursos pode variar: tomando um processo como exemplo, pode ser um único processo ou vários processos (semelhante a threads).
Combinando os dois fatores acima, existem teoricamente 4 opções. No entanto, em comparação com o esquema de implementação de "processo único de reator único", a solução de "processo único de reator múltiplo" é complexa e não tem vantagens de desempenho. Portanto, "processo único de reator múltiplo" "O plano é apenas um plano teórico e não tem aplicação real.
O padrão final do Reactor tem estas três implementações típicas:
-
Processo/thread único de reator único.
-
Multithreading de reator único.
-
Múltiplos processos/threads do Reator.
A escolha específica de processo ou thread no esquema acima está mais relacionada à linguagem de programação e à plataforma. Por exemplo, a linguagem Java geralmente usa threads (por exemplo, Netty) e a linguagem C pode usar processos e threads. Por exemplo, o Nginx usa processos e o Memcache usa threads.
Processo/thread único de reator único
O diagrama esquemático do esquema de processo único/encadeamento de reator único é o seguinte (tomando o processo como exemplo):
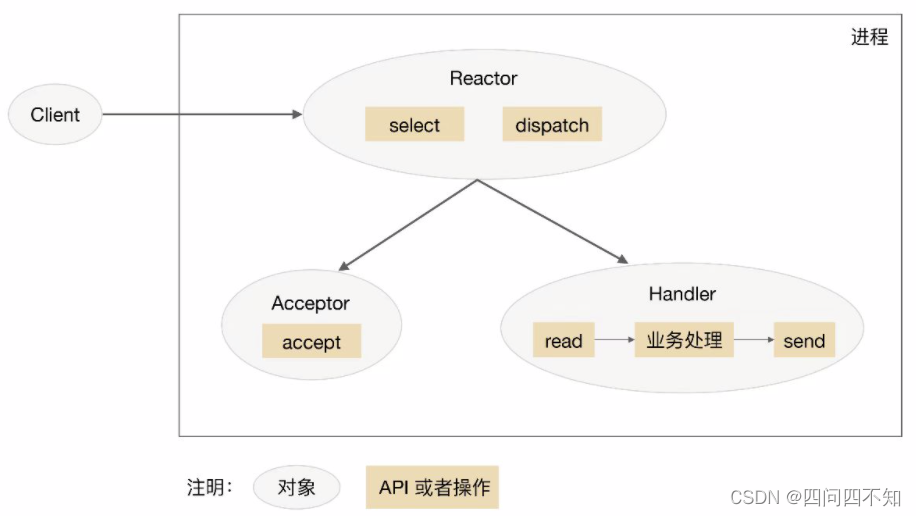
Observe que selecionar, aceitar, ler e enviar são APIs de programação de rede padrão, e expedição e "processamento de negócios" são operações que precisam ser completados. Os diagramas esquemáticos de outros esquemas são semelhantes.
Para detalhar este esquema:
-
1. O objeto Reactor monitora o evento de conexão por meio de select e o distribui por dispatch após receber o evento.
-
2. Se for um evento de estabelecimento de conexão, será processado pelo Acceptor, que aceita a conexão através de accept e cria um Handler para tratar diversos eventos subseqüentes da conexão.
-
3. Caso não seja um evento de estabelecimento de conexão, o Reactor chamará o Handler correspondente à conexão (o Handler criado no passo 2) para responder.
-
4. O manipulador concluirá o processo de negócios completo de ler->processamento de negócios->enviar.
A vantagem do modo de processo único de reator único é que ele é muito simples, não há comunicação entre processos, nem competição de processos e tudo é concluído no mesmo processo. Mas suas deficiências também são muito óbvias, as manifestações específicas são:
-
Existe apenas um processo e o desempenho de CPUs multi-core não pode ser utilizado; apenas vários sistemas podem ser implantados para utilizar CPUs multi-core, mas isso trará complexidade para operação e manutenção. Originalmente, apenas um sistema precisa ser mantido , mas esse método precisa ser mantido em uma máquina. Vários sistemas.
-
Quando o Handler está processando o negócio em uma determinada conexão, todo o processo não pode manipular eventos de outras conexões, o que pode facilmente levar a gargalos de desempenho.
Portanto, a solução de processo único de reator único tem poucos cenários de aplicação na prática e é adequada apenas para cenários com processamento de negócios muito rápido . Atualmente, o conhecido software de código aberto que usa processo único de reator único é o Redis.
Cabe ressaltar que os sistemas escritos em linguagem C geralmente utilizam um único reator e um único processo, pois não há necessidade de criar threads no processo; enquanto os sistemas escritos em Java geralmente utilizam um único reator e um único thread, pois a máquina virtual Java é um processo e a máquina virtual Existem muitos encadeamentos, e o encadeamento de negócios é apenas um deles.
Multithreading de reator único
Para superar as deficiências da solução de processo único/thread de reator único, é óbvio introduzir multiprocesso/thread múltiplo, o que leva à segunda solução: multithread de reator único.
O diagrama esquemático do esquema multi-threading do Reactor único é:
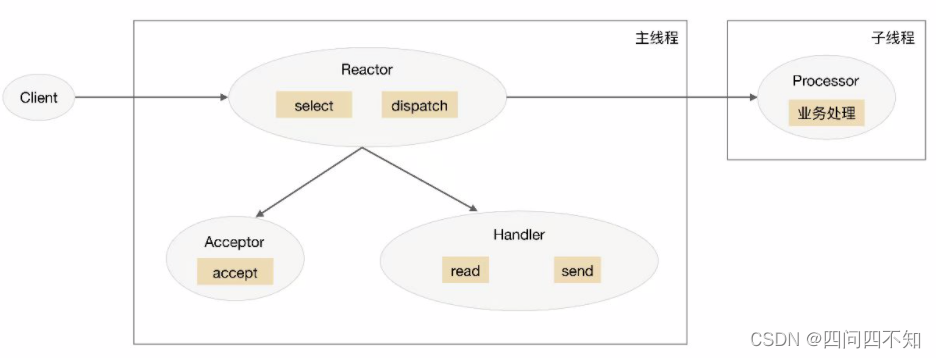
introduza este esquema:
-
1. Na thread principal, o objeto Reactor monitora o evento de conexão por meio de select e o distribui por dispatch após receber o evento.
-
2. Se for um evento de estabelecimento de conexão, será processado pelo Acceptor, que aceita a conexão através de accept e cria um Handler para tratar diversos eventos subseqüentes da conexão.
-
3. Caso não seja um evento de estabelecimento de conexão, o Reactor chamará o Handler correspondente à conexão (o Handler criado no passo 2) para responder.
-
4. O Handler é responsável apenas por responder a eventos e não realiza processamento de negócios, após o Handler ler os dados por meio de leitura, ele os enviará ao Processador para processamento de negócios.
-
5. O Processador concluirá o processamento do negócio real em um sub-thread independente e, em seguida, enviará o resultado da resposta ao Handler do processo principal para processamento, o Handler retornará o resultado da resposta ao cliente por meio de envio após receber a resposta.
A solução multithreading única do Reator pode fazer pleno uso dos recursos de processamento de multi-core e multi-CPU, mas também apresenta os seguintes problemas:
O acesso e o compartilhamento de dados multithread são mais complicados . Por exemplo, depois que o thread filho conclui o processamento de negócios, ele precisa passar o resultado para o reator do thread principal para envio, o que envolve o mecanismo de exclusão mútua e proteção de dados compartilhados. Tomando o NIO de Java como exemplo, Selector é thread-safe, mas o conjunto de chaves retornado por Selector.selectKeys() não é thread-safe, e o processamento de chaves selecionadas deve ser de thread único ou protegido por medidas de sincronização.
O Reactor é responsável por monitorar e responder a todos os eventos, e roda apenas na thread principal, tornando-se um gargalo de performance quando a alta simultaneidade instantânea é alta.
Você pode achar que apenas a solução " single Reactor multi-thread " está listada aqui , e a solução " single Reactor multi-process " não está listada . Qual é o motivo? O principal motivo é que, se vários processos forem usados, depois que o processo filho concluir o processamento de negócios, ele retornará o resultado ao processo pai e notificará o processo pai para qual cliente enviá-lo, o que é muito problemático. Como o processo pai apenas escuta os eventos em cada conexão por meio do Reactor e depois os distribui, o processo filho não é uma conexão ao se comunicar com o processo pai. Se você quiser simular a comunicação entre o processo pai e o processo filho como uma conexão e adicionar o Reactor para escutar, é mais complicado. Quando multi-threading é usado, porque multi-threading compartilha dados, a comunicação entre threads é muito conveniente. Embora o problema de sincronização ao compartilhar dados entre threads precise ser considerado adicionalmente, essa complexidade é muito menor do que a complexidade da comunicação entre processos.
Multi-reator multi-processo/thread
Para resolver o problema de multithreading de um único reator, a maneira mais intuitiva é alterar um reator único para um reator múltiplo, o que leva à terceira solução: multiprocesso/thread multi-reator.
O diagrama esquemático do esquema multi-processo/thread multi-reator é (tome o processo como exemplo):
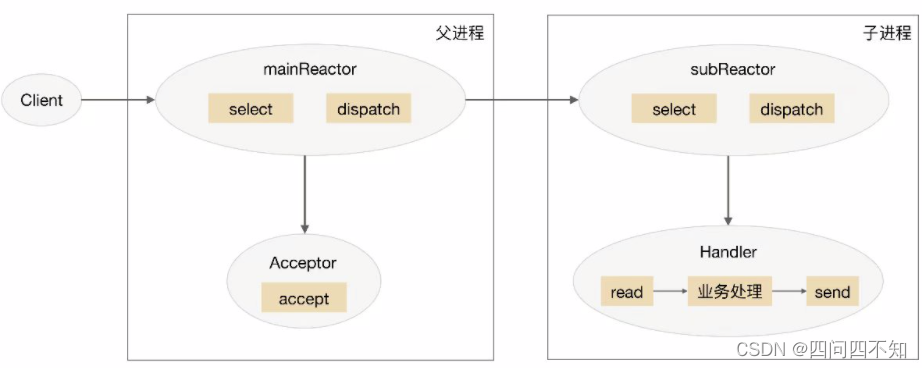
o esquema detalhado é o seguinte:
-
1. O objeto mainReactor no processo pai monitora o evento de estabelecimento de conexão por meio de select, recebe o evento por meio do Acceptor e atribui a nova conexão a um processo filho.
-
2. O subReactor do subprocess adiciona a conexão atribuída pelo mainReactor à fila de conexão para monitoramento e cria um Handler para manipular vários eventos da conexão.
-
3. Quando um novo evento ocorrer, o subReactor chamará o Handler correspondente à conexão (ou seja, o Handler criado na etapa 2) para responder.
-
4. O manipulador conclui o processo de negócios completo de ler→processamento de negócios→enviar.
A solução multi-processo/thread multi-reator parece mais complicada do que a solução multi-thread de reator único, mas é mais simples na implementação real. Os principais motivos são:
-
As responsabilidades do processo pai e do processo filho são muito claras: o processo pai é responsável apenas por receber novas conexões e o processo filho é responsável por concluir o processamento de negócios subseqüente.
-
A interação entre o processo pai e o processo filho é muito simples, o processo pai só precisa passar a nova conexão para o processo filho, e o processo filho não precisa retornar dados.
-
Os subprocessos são independentes uns dos outros e não há necessidade de compartilhamento síncrono e outros processamentos (isso é limitado a selecionar, ler, enviar, etc. relacionados ao modelo de rede sem compartilhamento síncrono, e o "processamento de negócios" ainda pode precisa de compartilhamento síncrono).
Atualmente, o conhecido sistema de código aberto Nginx usa multirreator e multiprocesso , e a implementação de multirreator e multithread inclui Memcache e Netty .
O Nginx adota o modo multiprocesso multirreator, mas a solução é diferente do modo multiprocesso multirreator padrão. A diferença específica é que apenas a porta de escuta é criada no processo principal, e o mainReactor não é criado para "aceitar" a conexão, mas o Reactor do processo filho é usado para "aceitar" a conexão e apenas um processo filho "aceita" de cada vez através do bloqueio. Após o processo "aceitar" uma nova conexão, ela será colocada em seu próprio reator para processamento e não será atribuída a outros processos filhos. Para mais detalhes, consulte as informações relevantes ou leia o código-fonte do Nginx.
git clone https://gitclone.com/github.com/nginx/nginx
Proator
O Reactor é um modelo de rede síncrona sem bloqueio, porque as operações reais de leitura e envio requerem sincronização do processo do usuário. O "síncrono" aqui significa que o processo do usuário é síncrono ao executar operações de E/S, como ler e enviar. Se a operação de E/S for alterada para assíncrona, o desempenho pode ser melhorado ainda mais. Este é o modelo de rede assíncrona Proactor.
A tradução chinesa de Proactor como "dispositivo proativo" é difícil de entender. A palavra semelhante a ela é proativa, que significa "ativo", por isso traduzimos como "dispositivo proativo" para melhor compreensão. O Reactor pode ser entendido como "Eu o notificarei quando um evento ocorrer e você o tratará", enquanto o Proactor pode ser entendido como " Irei lidar com um evento quando ele ocorrer e notificarei você quando ele terminar ". "I" aqui é o kernel do sistema operacional, "eventos" são eventos de E/S que possuem novas conexões, dados para ler e dados para gravar, e "você" é o código do nosso programa.
O diagrama esquemático do modelo Proactor é:
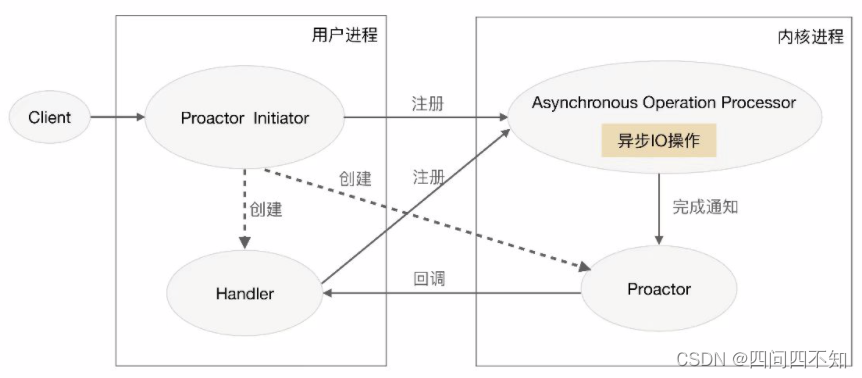
apresentar a solução Proactor em detalhes:
-
1. O Proactor Initiator é responsável por criar o Proactor e o Handler e registrar o Proactor e o Handler no kernel por meio do Processador de operação assíncrona.
-
2. O processador de operação assíncrona é responsável por processar as solicitações de registro e concluir as operações de E/S.
-
3. O processador de operação assíncrona notifica o Proactor após concluir a operação de E/S.
-
4. O Proactor chama de volta diferentes Handlers para processamento de negócios de acordo com diferentes tipos de eventos.
-
5. O Handler conclui o processamento de negócios e também pode registrar um novo Handler no processo do kernel.
Em teoria, o Proactor é mais eficiente que o Reactor. A E/S assíncrona pode fazer uso total do recurso DMA, permitindo que as operações de E/S se sobreponham aos cálculos. muito trabalho. Atualmente, a E/S assíncrona real é realizada por meio do IOCP no Windows, mas o AIO no sistema Linux não é perfeito, portanto, o modo Reactor é a principal maneira de realizar a programação de rede de alta simultaneidade no Linux. Portanto, embora o Boost.Asio afirme implementar o modelo Proactor, ele na verdade usa IOCP no Windows, enquanto no Linux é um modelo assíncrono simulado com o modo Reactor (usando epoll).