

À medida que a indústria de SaaS cresce rapidamente, são necessárias arquiteturas dinâmicas e adaptáveis para lidar com o fluxo de dados em tempo real. Veja como construí-los.
Traduzido de Como construir uma arquitetura de plataforma escalável para dados em tempo real , da autora Christina Lin.
A indústria de software como serviço (SaaS) está mostrando um crescimento imparável, com o tamanho do mercado previsto para atingir US$ 317,555 bilhões em 2024 e quase triplicar para US$ 1,22887 bilhão até 2032 . Este crescimento destaca a necessidade crescente de estratégias de dados robustas e aprimoradas. Esta tendência é impulsionada pelo crescente volume, velocidade e diversidade dos dados gerados pelas empresas e pela integração da inteligência artificial.
No entanto, este cenário crescente traz vários desafios importantes, como a gestão de picos de tráfego, a transição do processamento de transações online (OLTP) para o processamento analítico online (OLAP) em tempo real, a garantia de autoatendimento e dissociação, e a tornar-se agnóstica e multi-cloud. implantação regional. Enfrentar esses desafios requer uma estrutura arquitetônica sofisticada que garanta alta disponibilidade e mecanismos robustos de failover sem comprometer o desempenho do sistema.
A arquitetura de referência neste artigo detalha como construir uma plataforma de dados escalonável, automatizada e flexível para dar suporte ao crescente setor de SaaS. Essa arquitetura dá suporte às necessidades técnicas de processamento de dados em grande escala , ao mesmo tempo que se alinha às necessidades comerciais de agilidade, economia e conformidade regulatória.
Desafios técnicos de serviços SaaS com uso intensivo de dados
À medida que a procura por serviços e volumes de dados continua a crescer, surgem vários desafios comuns na indústria de SaaS.
Lidar com picos e explosões de tráfego é fundamental para alocar recursos de maneira eficiente para lidar com padrões de tráfego variáveis. Isso requer o isolamento de cargas de trabalho, o escalonamento durante os picos de carga de trabalho e a redução dos recursos de computação fora dos horários de pico, evitando a perda de dados.
Manter o OLTP em tempo real para OLAP significa oferecer suporte contínuo ao OLTP, que gerencia grandes volumes de transações rápidas com foco na integridade dos dados, e sistemas OLAP que suportam insights analíticos rápidos. Esse suporte duplo é fundamental para dar suporte a consultas analíticas complexas e manter o desempenho máximo. Ele também desempenha um papel fundamental na preparação de conjuntos de dados para aprendizado de máquina (ML).
Habilitar o autoatendimento e a dissociação exige capacitar as equipes com recursos de autoatendimento para criar e gerenciar tópicos e clusters sem depender muito de uma equipe central de TI. Isso acelera o desenvolvimento e permite que aplicativos e serviços sejam desacoplados e alcancem escalabilidade independente.
Promover o agnosticismo e a estabilidade da nuvem permite agilidade e capacidade de operar em diferentes ambientes de nuvem, como AWS , Microsoft Azure ou
Como construir uma arquitetura compatível com SaaS
Para enfrentar esses desafios, as grandes empresas de SaaS geralmente adotam uma estrutura arquitetônica que envolve a execução de vários clusters abrangendo diversas regiões e gerenciados por um plano de controle desenvolvido de forma personalizada. O design do plano de controle aumenta a flexibilidade da infraestrutura subjacente, ao mesmo tempo que simplifica a complexidade dos aplicativos conectados a ela.
Embora esta estratégia seja crítica para a alta disponibilidade e um mecanismo de failover robusto, ela também pode se tornar muito complexa para manter o desempenho uniforme e a integridade dos dados em um cluster distribuído geograficamente, e muito menos sem afetar o desempenho ou introduzir latência. Os desafios de aumentar ou diminuir recursos. surgir.
Além disso, determinados cenários podem exigir que os dados sejam isolados em um cluster específico por motivos de conformidade ou segurança. Para ajudá-lo a construir uma arquitetura robusta e flexível que evite essas complexidades, apresentarei algumas sugestões.
1. Estabeleça uma base estável
Um grande desafio para os serviços SaaS é alocar recursos para lidar com vários padrões de tráfego, incluindo consultas on-line de alta frequência e alto volume, inserção de dados e troca interna de dados.
A conversão do tráfego em processos assíncronos é uma solução comum que permite um escalonamento mais eficiente e uma alocação rápida de recursos computacionais. Plataformas de streaming de dados como Apache Kafka são ideais para gerenciar com eficiência grandes quantidades de dados. Mas gerenciar uma plataforma de dados distribuída como o Kafka traz seu próprio conjunto de desafios. O sistema de Kafka é conhecido por sua complexidade técnica, pois requer o gerenciamento de coordenação, sincronização e escalonamento de cluster, bem como protocolos adicionais de segurança e recuperação. Desafios em Kafka
A Java Virtual Machine (JVM) no Kafka também pode causar picos de latência imprevisíveis, principalmente devido ao processo de coleta de lixo da JVM. Gerenciar a alocação de memória da JVM e ajustar os requisitos de alto rendimento do Kafka é notoriamente tedioso e pode impactar a estabilidade geral do corretor Kafka.
Outro obstáculo é a gestão da política de dados de Kafka. Isso inclui o gerenciamento de políticas de retenção de dados, compactação de log e exclusão de dados, ao mesmo tempo em que equilibra custos de armazenamento, desempenho e conformidade até certo ponto.
Resumindo, gerenciar com eficácia sistemas baseados em Kafka em um ambiente SaaS é complicado. Como resultado, muitas empresas de SaaS estão recorrendo a alternativas Kafka que fornecem streaming de dados altamente escalável sem a necessidade de dependências externas, como JVM ou ZooKeeper.
2. Habilite dados de streaming de autoatendimento
Há uma demanda crescente por soluções de autoatendimento que permitam aos desenvolvedores criar temas desde o desenvolvimento até a produção. A infraestrutura ou serviço de plataforma deve fornecer uma solução com controle centralizado, fornecer detalhes de login e automatizar a rápida criação e implantação de recursos em diversas plataformas e estágios.
Isto levanta a necessidade de um plano de controle, que vem em muitas formas. Alguns planos de controle são usados apenas para gerenciar o ciclo de vida de um cluster ou tópico e atribuir permissões na plataforma de streaming. Outros planos de controle adicionam uma camada de abstração ao virtualizar alvos e ocultar detalhes da infraestrutura de usuários e clientes.
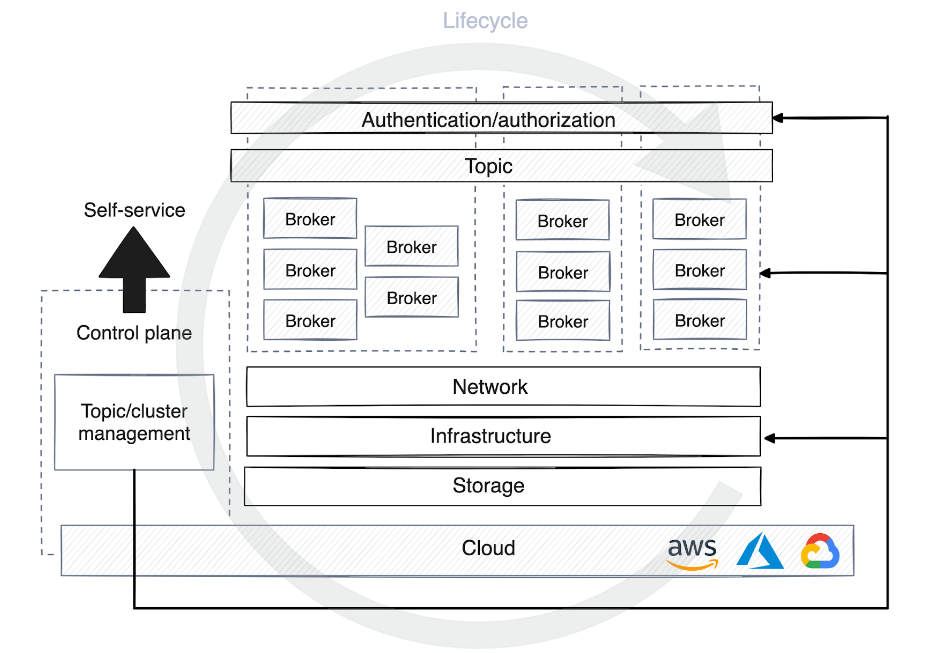
Quando um tópico é cadastrado no plano de controle da plataforma de dados de autoatendimento, diferentes estratégias de otimização de recursos computacionais são aplicadas dependendo do estágio do ambiente. No desenvolvimento, os tópicos geralmente compartilham clusters com outros processos, a retenção de dados é menos enfatizada e a maioria dos dados é descartada em poucos dias.
Contudo, na produção, a alocação de recursos deve ser cuidadosamente planejada com base no volume de tráfego. Esse planejamento inclui determinar o número de partições para consumidores, definir políticas de retenção de dados, decidir sobre a localização dos dados e considerar se você precisa de um cluster dedicado para casos de uso específicos.
Para o plano de controle, é muito útil automatizar o processo de gerenciamento do ciclo de vida da plataforma de streaming. Isso permite que o plano de controle depure agentes de forma autônoma, monitore métricas de desempenho e inicie ou pare o rebalanceamento de partições para manter a disponibilidade e estabilidade da plataforma em escala.
3. Suporte em tempo real para OLTP e OLAP
A mudança do processamento em lote para a análise em tempo real torna crítica a integração de sistemas OLAP na infraestrutura existente. No entanto, estes sistemas normalmente lidam com grandes quantidades de dados e requerem modelos de dados complexos para análises multidimensionais aprofundadas.
O OLAP depende de múltiplas fontes de dados e, dependendo da maturidade da empresa, geralmente há um data warehouse ou data lake para armazenar os dados, bem como pipelines de processamento em lote que são executados periodicamente (geralmente todas as noites) para mover dados das fontes de dados. . Este processo mescla dados de vários sistemas OLTP e outras fontes – um processo que pode se tornar complexo na manutenção da qualidade e consistência dos dados.
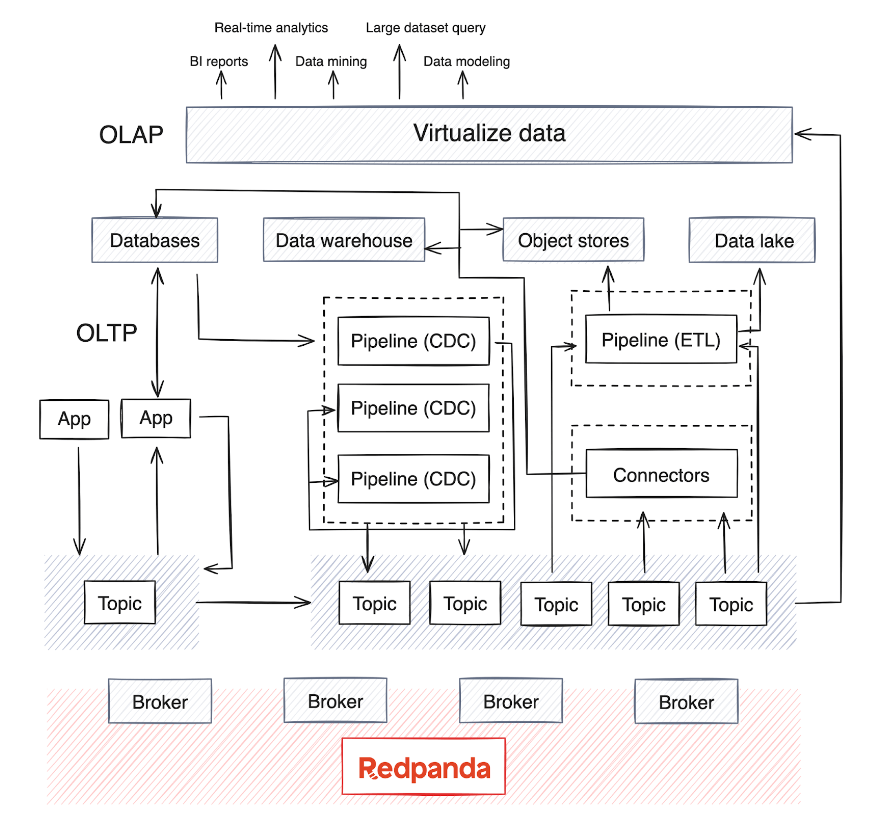
Hoje, o OLAP também integra modelos de IA com grandes conjuntos de dados. A maioria dos mecanismos de processamento de dados distribuídos e bancos de dados de streaming agora suportam consumo, agregação, resumo e análise em tempo real de dados de streaming de fontes como Kafka ou Redpanda. Essa tendência levou ao surgimento de pipelines de extração, transformação, carregamento (ETL) e extração, carregamento, transformação (ELT) para dados em tempo real, bem como pipelines de captura de dados de alteração (CDC) que transmitem logs de eventos de bancos de dados.
Pipelines em tempo real, normalmente implementados em Java , Python ou Golang, exigem um planejamento cuidadoso. Para otimizar o ciclo de vida desses pipelines, as empresas de SaaS estão incorporando o gerenciamento do ciclo de vida dos pipelines em seus planos de controle para otimizar o monitoramento e o alinhamento de recursos.
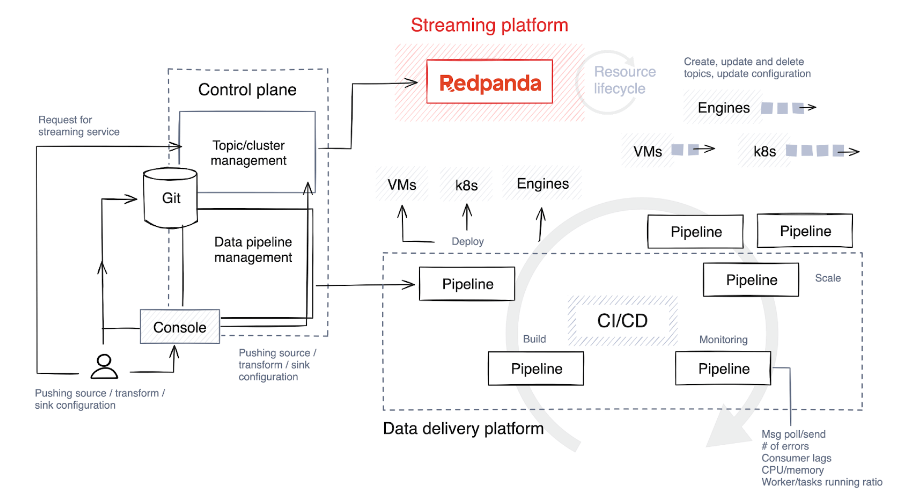
4. Compreenda (e otimize) o ciclo de vida do pipeline de dados
A primeira etapa é escolher uma pilha de tecnologia e determinar o nível de liberdade e personalização que os usuários que criam pipelines irão desfrutar. O ideal é permitir que eles selecionem diversas tecnologias para diferentes tarefas e implementem guarda-corpos para limitar a construção e expansão de tubulações.
A seguir está uma breve visão geral dos estágios envolvidos no ciclo de vida do pipeline.
Construir e testar
O código-fonte é enviado para um repositório Git, diretamente pelos desenvolvedores do pipeline ou por meio de ferramentas personalizadas no plano de controle. Esse código é então compilado em código binário ou em um programa executável usando uma linguagem como C++, Java ou C#. Após a compilação, o código é empacotado em um artefato, um processo que também pode envolver o agrupamento de dependências autorizadas e arquivos de configuração.
O sistema então executa testes automatizados para verificar o código. Durante o teste, o plano de controle cria tópicos temporários especificamente para essa finalidade, e esses tópicos são destruídos assim que o teste é concluído.
implantar
Os artefatos são implantados em máquinas virtuais (como Kubernetes ) ou bancos de dados de streaming, dependendo da pilha de tecnologia. Algumas plataformas oferecem abordagens mais criativas para estratégias de lançamento, como implantações azul/verde, que permitem reversão rápida e minimizam o tempo de inatividade. Outra estratégia é o lançamento canário, onde uma nova versão é aplicada apenas a uma pequena parte dos dados, reduzindo assim o impacto de possíveis problemas.
As desvantagens dessas estratégias são que as reversões podem ser desafiadoras e pode ser difícil isolar os dados afetados pela nova versão. Às vezes é mais simples realizar uma versão completa e reverter todo o conjunto de dados.
Expandir
Muitas plataformas oferecem suporte ao escalonamento automático, como o ajuste do número de instâncias em execução com base no uso da CPU, mas o nível de automação varia. Algumas plataformas fornecem esta funcionalidade de forma nativa, enquanto outras requerem configuração manual, como definir o número máximo de tarefas paralelas ou processos de trabalho por trabalho.
Durante a implantação, o plano de controle fornece configurações padrão com base na demanda prevista, mas continua monitorando as métricas de perto. Em seguida, aloca recursos adicionais ao tópico, dimensionando o número de processos de trabalho, tarefas ou instâncias conforme necessário.
monitor
Monitorar as métricas corretas em seu pipeline e manter a observabilidade são as principais formas de detectar problemas antecipadamente. Aqui estão algumas métricas importantes que você deve monitorar proativamente para garantir a eficiência e a confiabilidade do seu pipeline de processamento de dados.
Indicadores de recursos
- O uso de CPU e memória é fundamental para entender como os recursos estão sendo consumidos.
- A E/S de disco é importante para avaliar a eficiência das operações de armazenamento e recuperação de dados.
Taxa de transferência e latência
- Os registros de entrada/saída medem a taxa de processamento de dados por segundo.
- Os registros processados por segundo representam o poder de processamento do sistema.
- A latência ponta a ponta é o tempo total necessário entre a entrada e a saída dos dados, o que é fundamental para o desempenho do processamento em tempo real.
Contrapressão e histerese
- Isso ajuda a identificar gargalos no processamento de dados e a evitar possíveis lentidão.
Taxa de erro
- O rastreamento das taxas de erro ajuda a manter a integridade dos dados e a confiabilidade do sistema
5. Melhore a confiabilidade, redundância e resiliência
As empresas priorizam alta disponibilidade, recuperação de desastres e resiliência para manter operações contínuas durante interrupções. A maioria das plataformas de streaming de dados já possui fortes proteções e estratégias de implantação integradas, principalmente através da extensão de clusters em diversas partições, data centers e zonas de disponibilidade independentes de nuvem.
No entanto, envolve compensações, como aumento da latência, potencial duplicação de dados e custos mais elevados. Aqui estão algumas sugestões ao planejar alta disponibilidade, recuperação de desastres e resiliência.
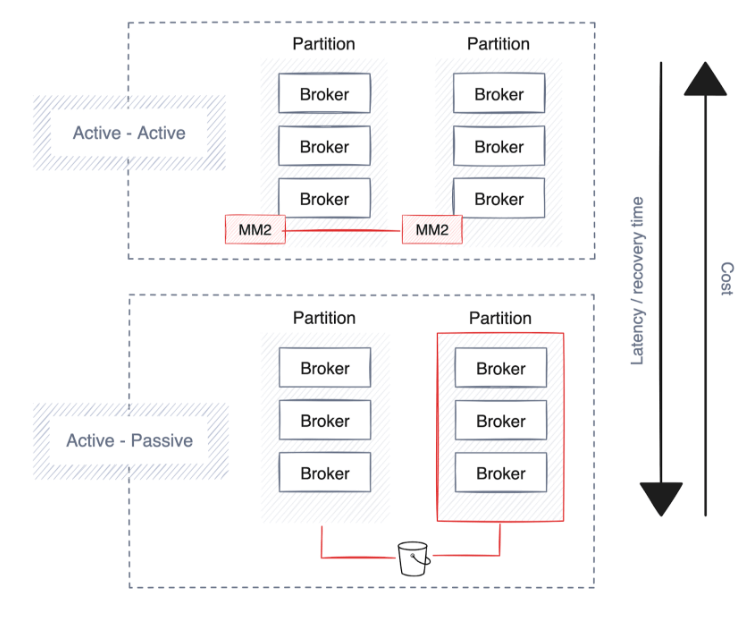
Alta disponibilidade
Um processo de implantação automatizado gerenciado pelo plano de controle desempenha um papel fundamental no estabelecimento de uma estratégia robusta de alta disponibilidade . Essa estratégia garante que pipelines, conectores e plataformas de streaming sejam distribuídos estrategicamente entre zonas de disponibilidade ou partições com base no provedor de nuvem ou no data center.

É fundamental que as plataformas de dados distribuam todos os pipelines de dados em diversas zonas de disponibilidade (AZs) para reduzir o risco. A continuidade é suportada pela execução de cópias redundantes de pipelines em diferentes AZs para manter o processamento de dados ininterrupto em caso de falha da partição.
As plataformas de streaming subjacentes à arquitetura de dados devem seguir o exemplo e replicar automaticamente os dados em várias AZs para melhorar a resiliência. Soluções como o Redpanda podem automatizar a distribuição de dados entre partições, melhorando a confiabilidade e a tolerância a falhas da plataforma.
No entanto, considere os potenciais custos de largura de banda de rede associados, tendo em conta a localização das suas aplicações e serviços. Por exemplo, manter os pipelines próximos aos armazenamentos de dados pode reduzir a latência e a sobrecarga da rede, ao mesmo tempo que reduz os custos.
recuperação de desastres
A recuperação mais rápida de falhas acarreta custos mais elevados devido ao aumento da replicação de dados, resultando em maior sobrecarga de largura de banda e requer uma configuração sempre ativa (ativo-ativo), duplicando o uso de hardware. Nem todas as tecnologias de streaming oferecem essa funcionalidade, mas plataformas de nível empresarial como Redpanda suportam backup de dados e metadados de cluster para armazenamento de objetos em nuvem.
elasticidade
Além da alta disponibilidade e da recuperação de desastres, algumas empresas globais exigem estratégias de implantação regional para garantir que o armazenamento e o processamento de dados cumpram regulamentações geográficas específicas. Em vez disso, as empresas que desejam compartilhar dados em tempo real entre diferentes regiões com gerenciamento mínimo geralmente criam um cluster compartilhado que permite aos agentes replicar e distribuir dados entre regiões.
No entanto, esta abordagem incorre em custos de rede e latência significativos, uma vez que os dados são continuamente transferidos para as partições seguintes. Para aliviar o tráfego de dados, a busca do seguidor instrui o consumidor de dados a ler os dados da partição seguidora geograficamente mais próxima.
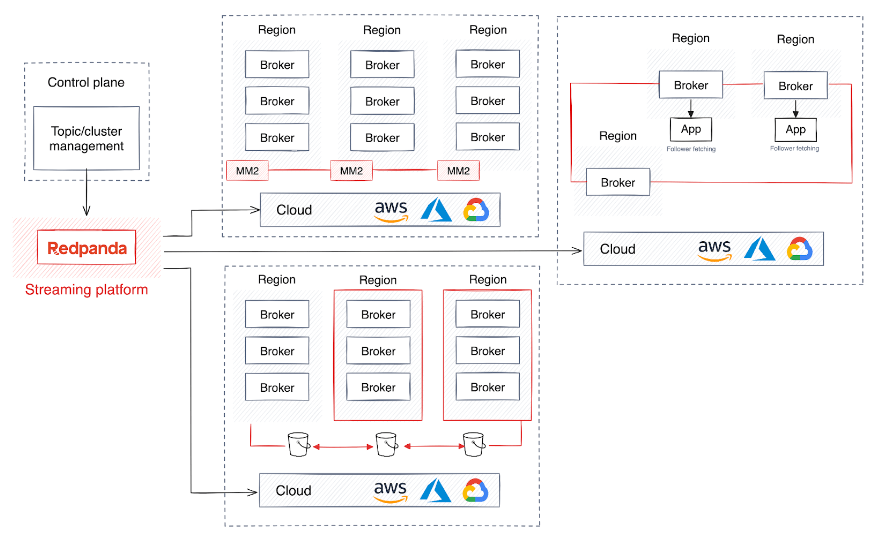
Além disso, o dimensionamento de clusters para preenchimento de dados melhora o balanceamento de carga entre data centers. Essa escalabilidade é crítica para gerenciar volumes crescentes de dados e tráfego de rede, ajudando as empresas a escalar sem sacrificar o desempenho ou a confiabilidade.
para concluir
À medida que as empresas se transformam através da transformação digital, os dados em tempo real tornam-se cada vez mais críticos para orientar a tomada de decisões. Isto envolve extrair insights mais profundos de enormes conjuntos de dados , permitindo previsões mais precisas, simplificando processos automatizados de tomada de decisão e fornecendo serviços mais personalizados – tudo isso otimizando custos e operações.
Uma opção é adotar uma arquitetura de referência que inclua uma plataforma escalonável de streaming de dados, como Redpanda , um substituto plug-and-play do Kafka implementado em C++. Ele permite que as empresas evitem o tempo real, facilitando o escalonamento contínuo, uma API de gerenciamento que oferece suporte à automação do ciclo de vida , armazenamento em camadas para reduzir os custos de armazenamento , réplicas de leitura remota para simplificar a configuração de clusters somente leitura econômicos e distribuição geográfica contínua de dados. complexidade de processamento.
Com a tecnologia certa, os fornecedores de SaaS podem melhorar os seus serviços, melhorar a experiência do cliente e aumentar a sua vantagem competitiva no mercado digital. As estratégias futuras devem continuar a otimizar estes sistemas para uma maior eficiência e adaptabilidade, para que as plataformas SaaS possam prosperar num mundo orientado por dados.
Um programador nascido na década de 1990 desenvolveu um software de portabilidade de vídeo e faturou mais de 7 milhões em menos de um ano. O final foi muito punitivo! Alunos do ensino médio criam sua própria linguagem de programação de código aberto como uma cerimônia de maioridade - comentários contundentes de internautas: Contando com RustDesk devido a fraude desenfreada, serviço doméstico Taobao (taobao.com) suspendeu serviços domésticos e reiniciou o trabalho de otimização de versão web Java 17 é a versão Java LTS mais comumente usada no mercado do Windows 10 Atingindo 70%, o Windows 11 continua a diminuir Open Source Daily | Google apoia Hongmeng para assumir o controle de telefones Android de código aberto apoiados pela ansiedade e ambição da Microsoft; Electric desliga a plataforma aberta Apple lança chip M4 Google exclui kernel universal do Android (ACK) Suporte para arquitetura RISC-V Yunfeng renunciou ao Alibaba e planeja produzir jogos independentes para plataformas Windows no futuroEste artigo foi publicado pela primeira vez em Yunyunzhongsheng ( https://yylives.cc/ ), todos são bem-vindos para visitar.