Link: https://zhuanlan.zhihu.com/p/655272123
O surgimento do ChatGPT nos permite ver as capacidades do Large Language Model (LLM) na compreensão de linguagem e código, seguimento de instruções humanas, raciocínio básico, etc., mas o o problema da alucinação [ 1] ainda é um desafio importante enfrentado pelos atuais grandes modelos de linguagem. Simplificando, o problema da alucinação ocorre quando o LLM gera resultados incorretos, absurdos ou inconsistentes com os fatos. Além disso, a atualização dos dados (Data Freshness) é outro problema que ocorre quando o LLM gera resultados, ou seja, o LLM pode não ser capaz de dar ou dar respostas desatualizadas a algumas questões urgentes. Melhorar os resultados gerados pelo LLM recuperando informações externas relevantes é atualmente uma solução popular para os problemas acima, chamada Retrieval Augmented LLM (Retrieval Augmented LLM). Este longo artigo fornecerá uma introdução relativamente abrangente à solução de LLM com recuperação aprimorada. Os principais conteúdos incluem:
- Recuperar a introdução do conceito, importância e problemas resolvidos pelo LLM aprimorado
- Recuperar os principais módulos do LLM aprimorado e seus métodos de implementação
- Recuperar alguns estudos de caso e aplicações de LLM aprimorado
Este artigo pode ser considerado um resumo do meu estudo nesta área. Pode não ser muito profissional e aprofundado e inevitavelmente haverá algumas imprecisões. Discussões são bem-vindas (meu ID do WeChat: companheiro de longa data). Para facilitar atualizações posteriores, também criei um repositório no Github A Guide to Retrieval Augmented LLM [2] . Ao mesmo tempo, seja bem-vindo a seguir minha conta pública do WeChat "AI Thinking Bicycle"
A recuperação aprimora o LLM, o LLM nos capacita.
O que é LLM aprimorado para pesquisa
Recuperação Aumentada LLM (Retrieval Augmented LLM), simplesmente, é fornecer um banco de dados externo para LLM. Para perguntas do usuário (Consulta), por meio de alguma tecnologia de recuperação de informações (Recuperação de Informações, IR), primeiro recupere as perguntas do usuário do banco de dados externo Relevante informações e, em seguida, deixe o LLM combinar essas informações relevantes para gerar resultados. Este modo às vezes é chamado de Geração Aumentada de Recuperação (RAG). A figura abaixo é um diagrama simples de LLM com recuperação aprimorada.
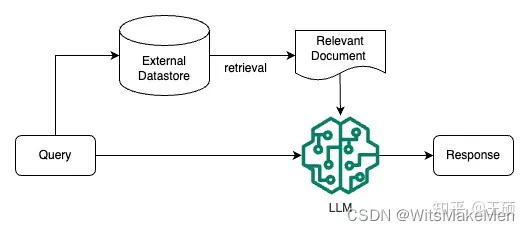
O cientista pesquisador da OpenAI Andrej Karpathy fez uma apresentação sobre o status atual do modelo GPT na conferência Microsoft Build 2023 há algum tempo, State of GPT [3] A primeira metade da apresentação compartilhou como modelos como ChatGPT são treinados passo a passo A segunda metade Esta parte compartilha principalmente algumas instruções de aplicação do modelo LLM, incluindo uma breve introdução à direção de aplicação do LLM com recuperação aprimorada. A foto abaixo é a introdução a essa direção compartilhada por Andrej.
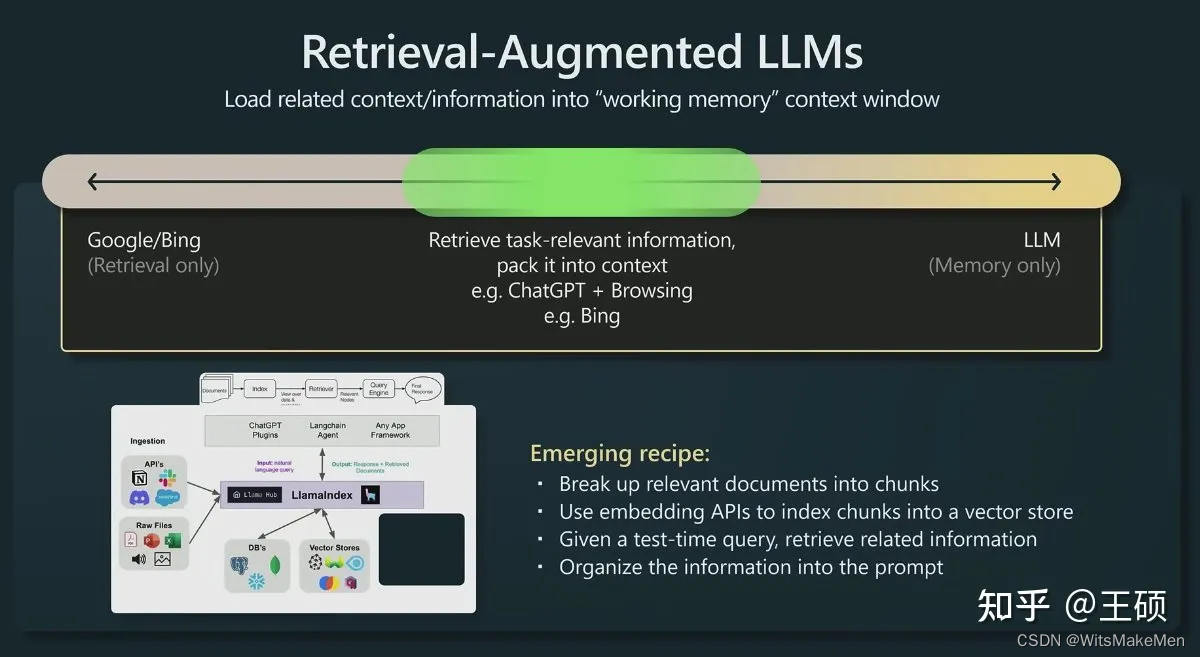
Ferramentas tradicionais de recuperação de informações, como mecanismos de pesquisa como Google/Bing, possuem apenas recursos de recuperação ( Somente recuperação ) Agora o LLM incorpora dados e conhecimento massivos em seus enormes parâmetros de modelo por meio do processo de pré-treinamento e possui recursos de memória ( Memória - apenas ). Nessa perspectiva, o LLM aprimorado por recuperação está no meio, combinando o LLM com a recuperação tradicional de informações e carregando informações relevantes na memória de trabalho do LLM (Memória de Trabalho ) por meio de algumas técnicas de recuperação de informações , ou seja, a janela de contexto do LLM (Janela de Contexto ), que é a entrada máxima de texto que o LLM pode aceitar durante uma única geração.
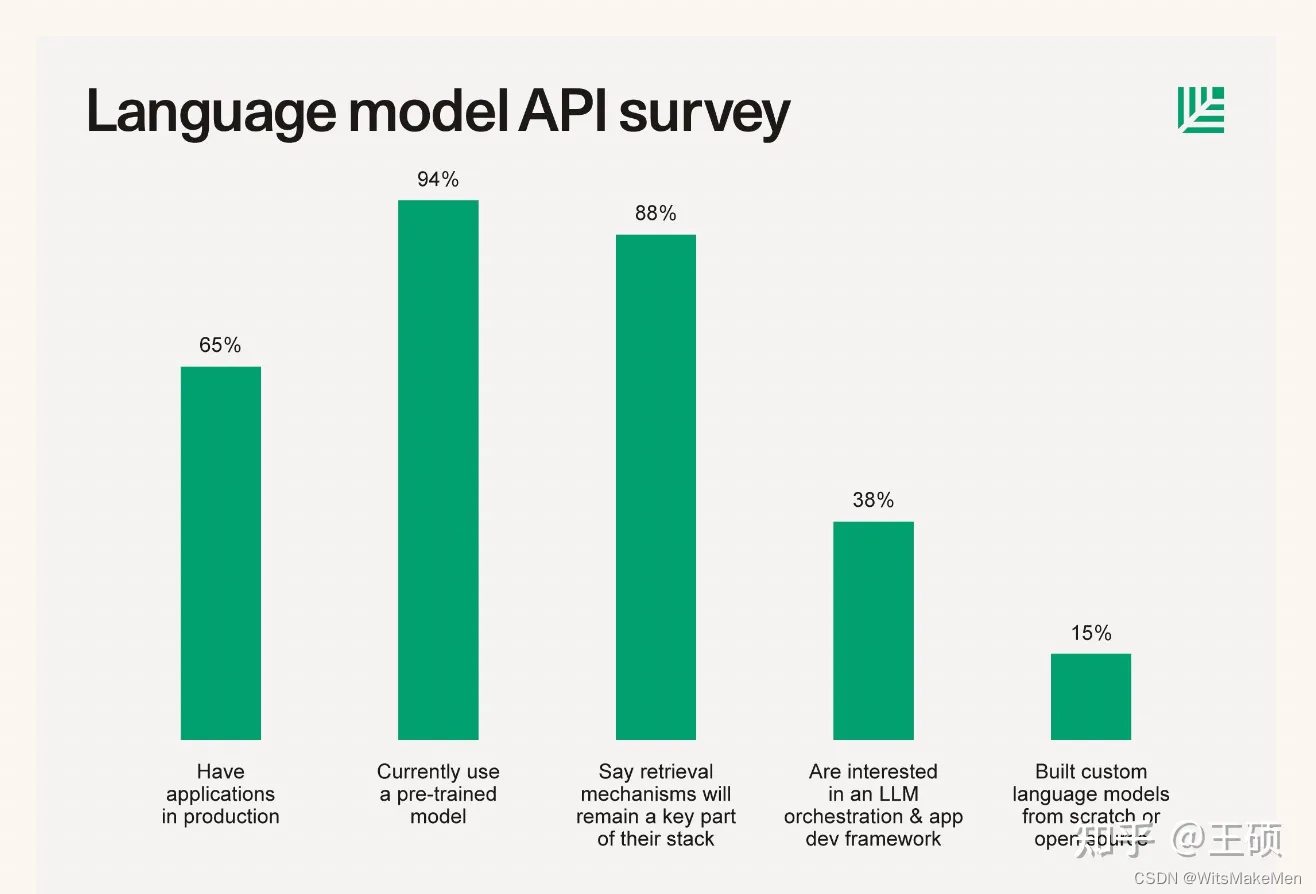
O compartilhamento de Andrej não apenas mencionou o método de aplicação para aprimorar o LLM com base na recuperação, mas também a partir da pesquisa e do resumo da pilha de tecnologia de start-ups de IA por algumas instituições de investimento conhecidas, também podemos ver a ampla aplicação da tecnologia LLM com base na recuperação. Por exemplo, em junho deste ano, a Sequoia Capital publicou um artigo sobre a grande pilha de tecnologia de modelo de linguagem, The New Language Model Stack [4] , que forneceu os resultados de uma pesquisa por questionário de 33 start-ups de IA nas quais investiu. os resultados na figura abaixo mostram que cerca de 88% dos empreendedores afirmaram ter usado tecnologia LLM aprimorada baseada em pesquisa em seus produtos.
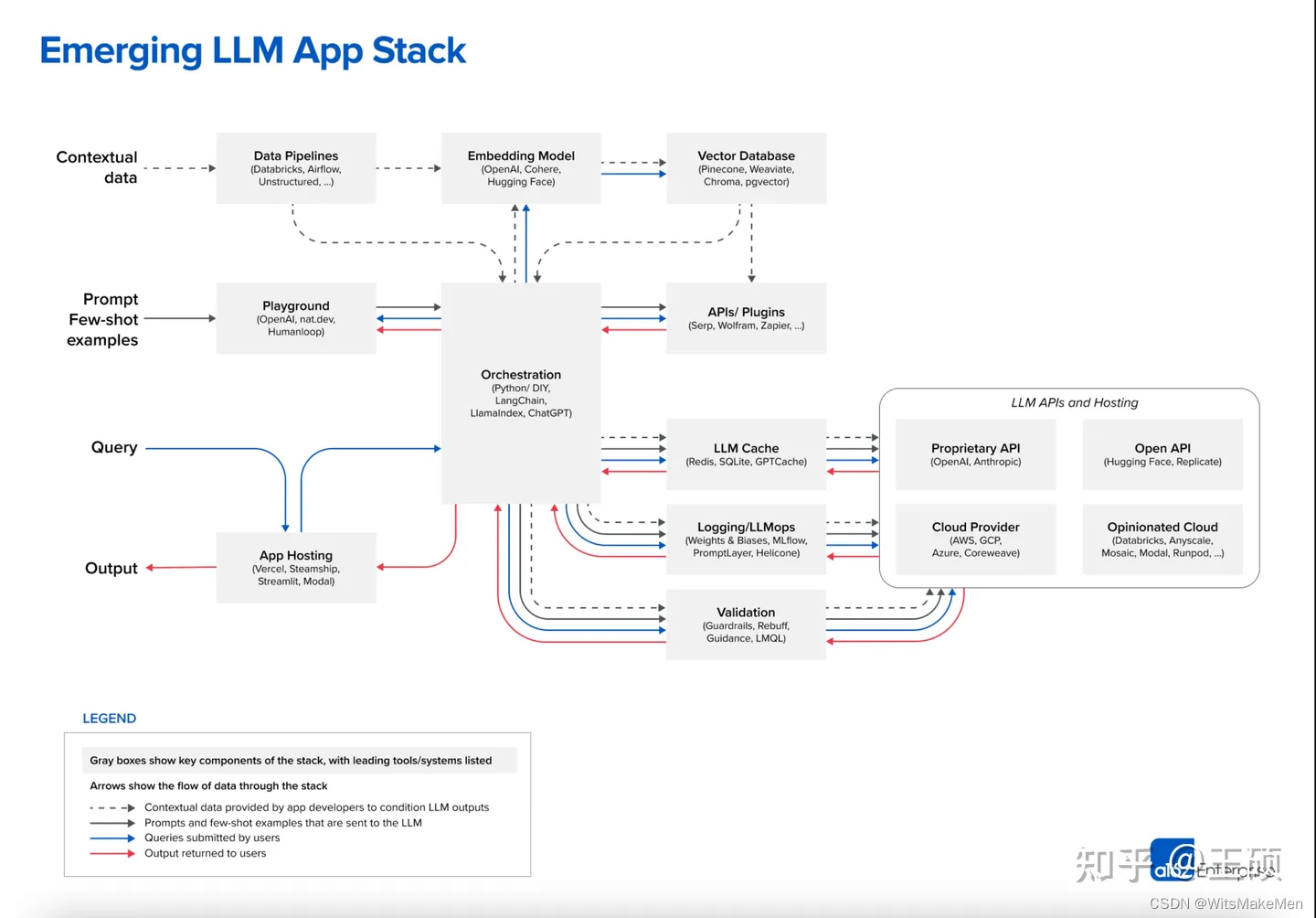
Coincidentemente, a famosa instituição americana de capital de risco A16Z também publicou um artigo resumido Emerging Architectures for LLM Applications [5] em junho deste ano apresentando a arquitetura de aplicativo LLM atual . A figura a seguir é a arquitetura típica do aplicativo LLM atual resumida no artigo, entre os quais o mais A maneira como os dados contextuais é uma ideia para aprimorar o LLM por meio da recuperação.
Recuperar problemas resolvidos pelo LLM aprimorado
Por que combinar sistemas tradicionais de recuperação de informações para aprimorar o LLM? Em outras palavras, quais são os principais problemas resolvidos pelo LLM com base no aprimoramento da recuperação? Esta parte do conteúdo é baseada no que o grupo Chen Danqi da Universidade de Princeton compartilhou anteriormente sobre modelos de linguagem baseados em recuperação na conferência ACL 2023. Tutorial ACL 2023: Modelos e aplicativos de linguagem baseados em recuperação [6]
Conhecimento de cauda longa
Embora a quantidade atual de dados de treinamento LLM já seja muito grande, muitas vezes centenas de gigabytes de dados e trilhões de marcadores (Tokens).Por exemplo, os dados de pré-treinamento do GPT-3 usam 300 bilhões de marcadores e o LLaMA usa 1,4 trilhão de marcadores. . As fontes de dados de treinamento também são muito ricas, como Wikipedia, livros, fóruns, códigos, etc. O número de parâmetros do modelo LLM também é muito grande, variando de bilhões, dezenas de bilhões a centenas de bilhões. No entanto, o LLM pode registrar em parâmetros limitados. Não é realista ter todo o conhecimento ou informação, e a cobertura dos dados de treinamento também é limitada. Sempre haverá algum conhecimento de cauda longa que não pode ser coberto nos dados de treinamento.
Para alguns conhecimentos relativamente gerais e populares, o LLM geralmente pode gerar resultados mais precisos, mas para alguns conhecimentos de cauda longa, as respostas geradas pelo LLM geralmente não são confiáveis. Este artigo na conferência ICML, Large Language Models Struggle to Learn Long-Tail Knowledge [7] , estudou a relação entre a precisão do LLM para respostas a perguntas baseadas em fatos e o número de documentos em campos relacionados nos dados de pré-treinamento, e constatou que existe uma forte Relevância, ou seja, quanto maior o número de documentos relevantes nos dados pré-treinamento, maior será a precisão da resposta do LLM às perguntas e respostas factuais. Uma conclusão simples pode ser tirada deste estudo: o LLM tem uma capacidade de aprendizagem relativamente fraca para conhecimento de cauda longa. A imagem abaixo é a curva de correlação desenhada no artigo.
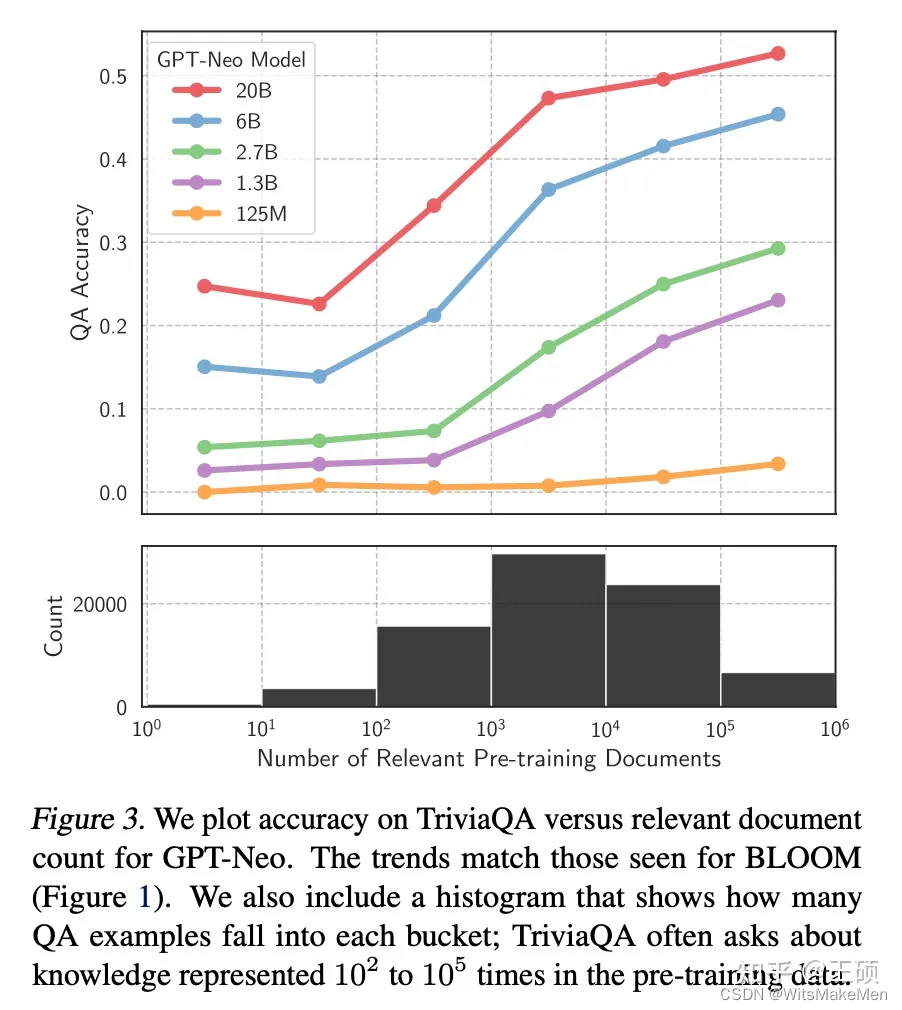
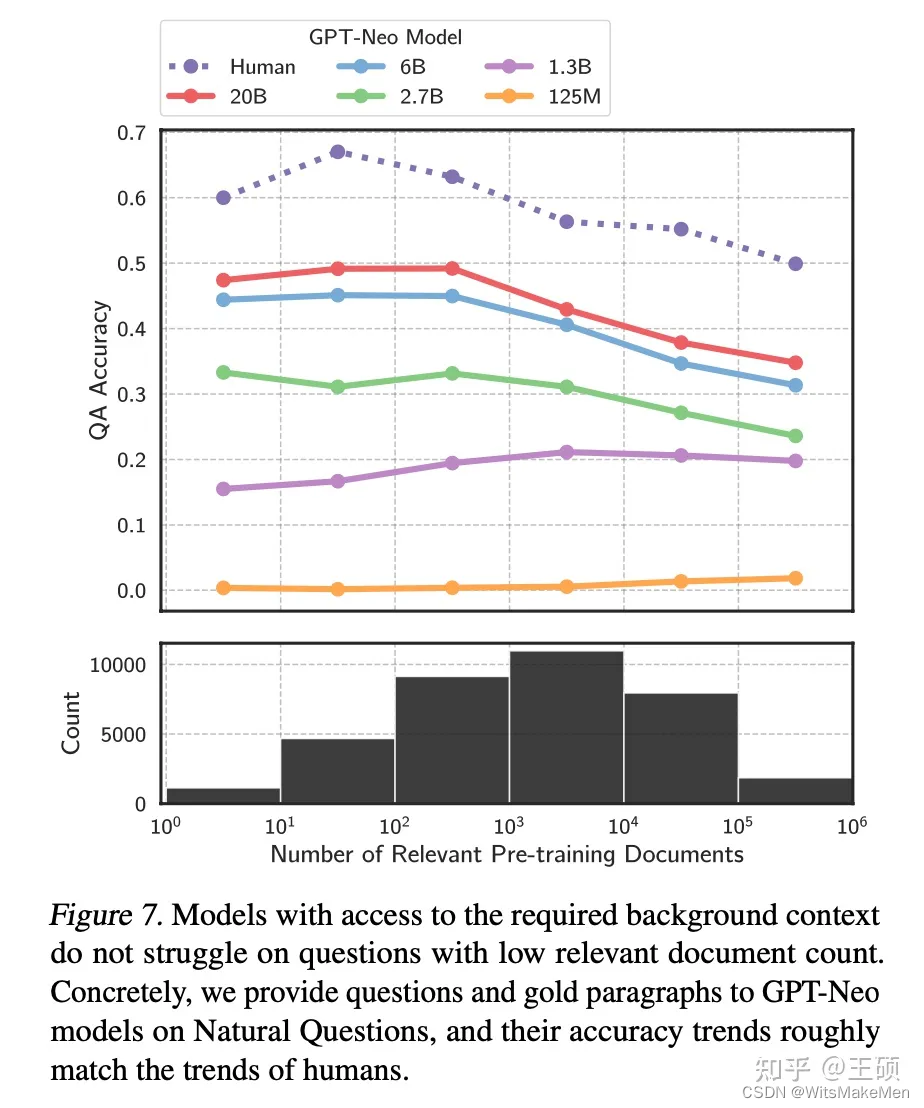
A fim de melhorar a capacidade do LLM de aprender conhecimento de cauda longa, é fácil pensar em adicionar conhecimento de cauda longa mais relevante aos dados de treinamento ou aumentar o número de parâmetros do modelo. Embora ambos os métodos tenham certos efeitos, como mencionado acima Há também suporte de dados experimentais no artigo, mas esses dois métodos não são econômicos, ou seja, uma grande quantidade de dados de treinamento e parâmetros de modelo são necessários para melhorar significativamente a precisão da resposta do LLM ao conhecimento de cauda longa. O método de recuperação fornece informações relevantes como contexto (Contexto) durante a inferência LLM, o que pode não apenas alcançar uma melhor precisão de resposta, mas também ser uma forma mais econômica. A imagem abaixo mostra a precisão da resposta de modelos de diferentes tamanhos quando informações relevantes são fornecidas. Comparando a imagem anterior, podemos ver que para modelos da mesma magnitude de parâmetro, quando uma pequena quantidade de documentos relevantes é fornecida para participação no pré-treinamento , deixe O modelo utilizar informações relevantes durante a fase de inferência e sua precisão de resposta for bastante melhorada.
dados privados
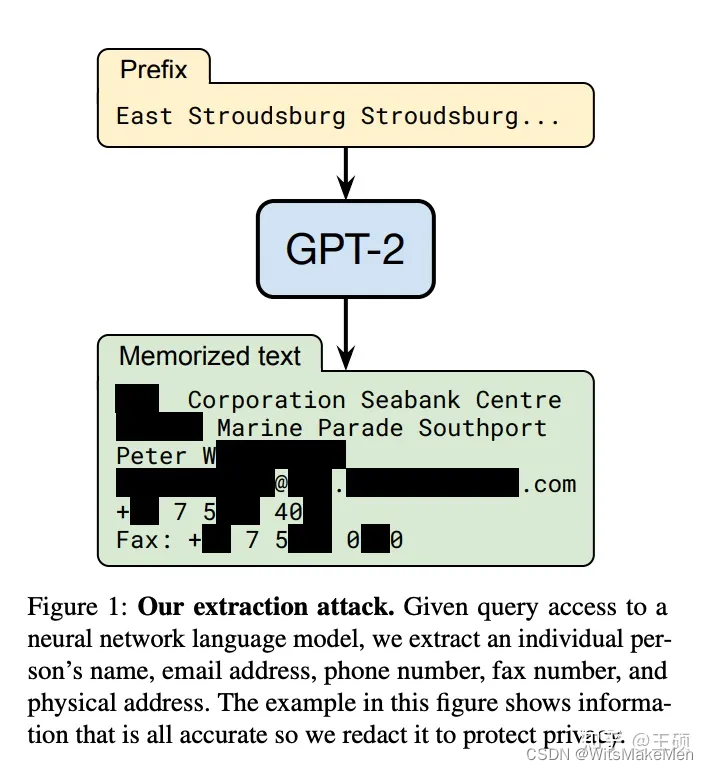
A maioria dos estágios de pré-treinamento de LLMs de uso geral, como ChatGPT, usam dados públicos e não incluem dados privados, portanto, falta algum conhecimento de domínio privado. Por exemplo, se você perguntar ao ChatGPT sobre o conhecimento interno de uma determinada empresa, o ChatGPT provavelmente não saberá ou inventará aleatoriamente. Embora os dados privados possam ser adicionados na fase de pré-treinamento ou usados para ajuste fino, os custos de treinamento e iteração são elevados. Além disso, a pesquisa e a prática mostraram que o LLM pode vazar dados de treinamento por meio de alguns métodos de ataque específicos.Se os dados de treinamento contiverem alguma informação privada, é provável que ocorra vazamento de informações de privacidade. Por exemplo, os pesquisadores neste artigo Extraindo dados de treinamento de modelos de linguagem grande [8] usaram a consulta construída para extrair nomes públicos pessoais, endereços de e-mail, números de telefone e informações de endereço do modelo GPT-2 O artigo também descobriu que os modelos de maior escala são mais vulneráveis a ataques do que os de menor escala.
Se dados privados forem usados como um banco de dados externo, o LLM pode recuperar diretamente informações relevantes do banco de dados externo ao responder perguntas com base em dados privados e, em seguida, combinar as informações relevantes recuperadas para responder. Isto elimina a necessidade de o LLM lembrar o conhecimento privado em parâmetros através de pré-treinamento ou ajuste fino, o que não só economiza custos de treinamento ou ajuste fino, mas também evita o risco de vazamento de dados privados até certo ponto.
Atualização de dados
Como o conhecimento aprendido no LLM vem de dados de treinamento, embora o ciclo de atualização da maior parte do conhecimento não seja muito rápido, ainda haverá algum conhecimento ou informação que será atualizado com muita frequência. As informações que o LLM aprende com os dados de pré-treinamento podem facilmente se tornar obsoletas. Por exemplo, o modelo GPT-4 utiliza dados de pré-treinamento a partir de 2021-09, portanto, quando se trata de eventos ou informações após esta data, ele se recusará a responder ou dará respostas desatualizadas ou imprecisas. O exemplo a seguir pergunta ao GPT-4 quem é o atual CEO do Twitter. A resposta dada pelo GPT-4 ainda é Jack Dorsey, e lembrará que a resposta pode estar desatualizada.

Se o conhecimento frequentemente atualizado for usado como um banco de dados externo para o LLM recuperar quando necessário, o conhecimento do LLM pode ser atualizado e expandido sem retreinar o LLM, resolvendo assim o problema da atualização dos dados do LLM.
Verificação da fonte e explicabilidade
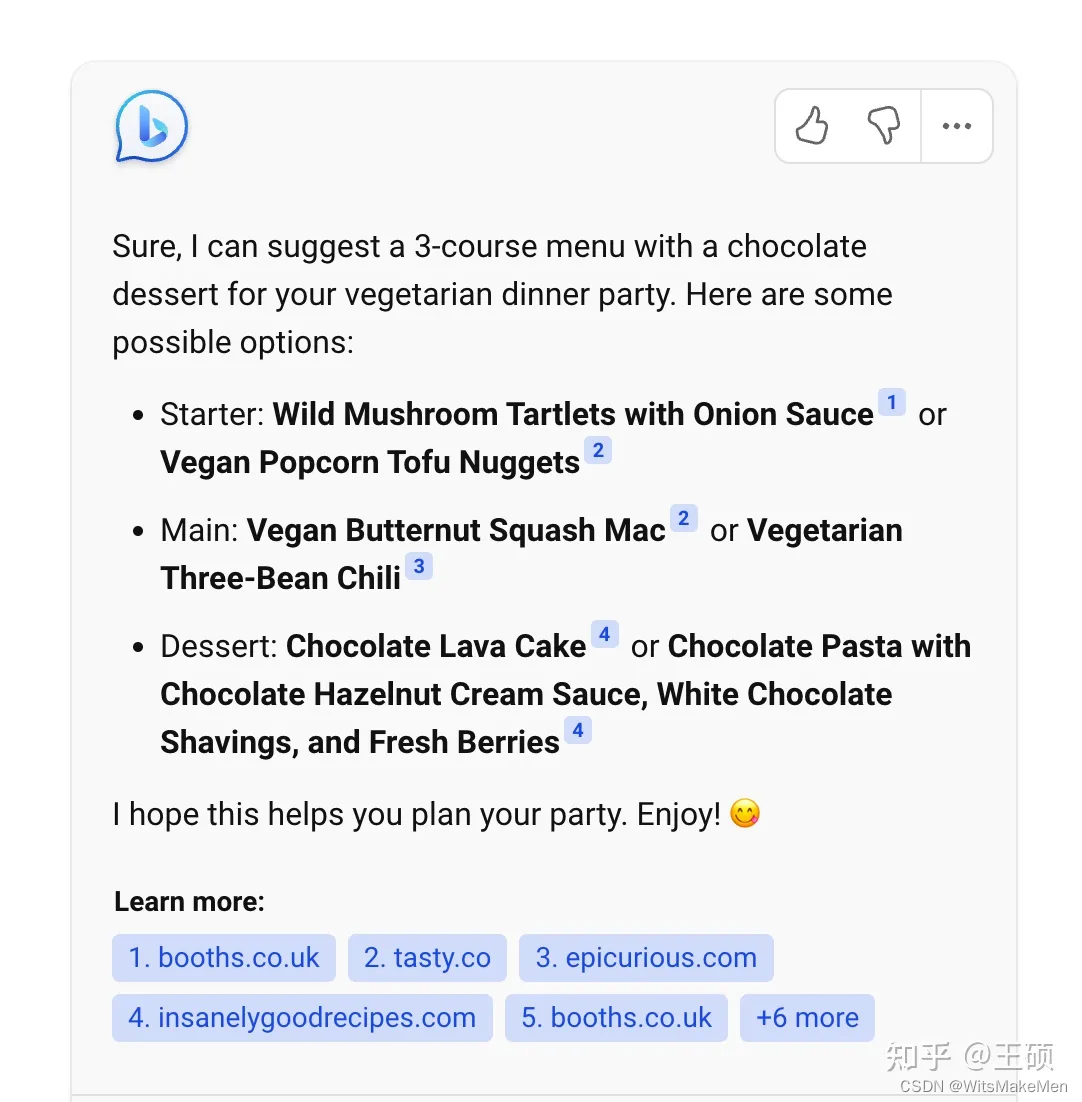
Normalmente, o resultado gerado pelo LLM não fornece sua fonte, tornando difícil explicar por que ele é gerado tal como é. Ao fornecer fontes de dados externas ao LLM e permitir que ele seja gerado com base nas informações relevantes recuperadas, é estabelecida uma correlação entre os resultados gerados e a fonte de informação, de modo que os resultados gerados possam ser rastreados até a fonte de referência, tornando-os interpretáveis e controláveis O sexo é grandemente melhorado. Ou seja, você pode saber em quais informações relevantes o LLM se baseia para gerar a resposta. O Bing Chat é um produto típico que usa recuperação para aprimorar a saída do LLM. A figura a seguir mostra uma captura de tela do produto Bing Chat. Você pode ver que links para informações relevantes são fornecidos nas respostas geradas.
Usando a recuperação para aprimorar o resultado do LLM, uma etapa muito importante é encontrar fragmentos de informações relevantes de dados externos por meio de algumas técnicas relacionadas à recuperação e, em seguida, usar os fragmentos de informações relevantes como contexto para o LLM se referir ao gerar respostas. Algumas pessoas podem dizer que à medida que a janela de contexto do LLM se torna cada vez mais longa, a etapa de recuperação de informações relevantes não é necessária e o máximo de informação possível é fornecido diretamente no contexto. Por exemplo, o comprimento máximo de contexto atualmente recebido pelo modelo GPT-4 é 32K, e o modelo Claude permite um comprimento máximo de contexto de 100K [9] .
Embora a janela de contexto do LLM seja cada vez maior, a etapa de recuperação de informações relevantes ainda é importante e necessária. Por um lado, a atual arquitetura de rede do LLM determina que o comprimento da sua janela de contexto tem um limite superior e não crescerá infinitamente. Além disso, a janela de contexto aparentemente grande contém, na verdade, informações relativamente limitadas. Por exemplo, o comprimento de 32K pode ser equivalente apenas ao comprimento de uma tese de graduação universitária. Por outro lado, estudos demonstraram que fornecer uma pequena quantidade de informações mais relevantes leva a uma maior precisão nas respostas do LLM do que fornecer uma grande quantidade de informações não filtradas. Por exemplo, este artigo da Universidade de Stanford, Lost in the Middle [10] , apresenta os seguintes resultados experimentais: pode-se observar que a precisão da resposta do LLM diminui à medida que o número de documentos fornecidos na janela de contexto aumenta.
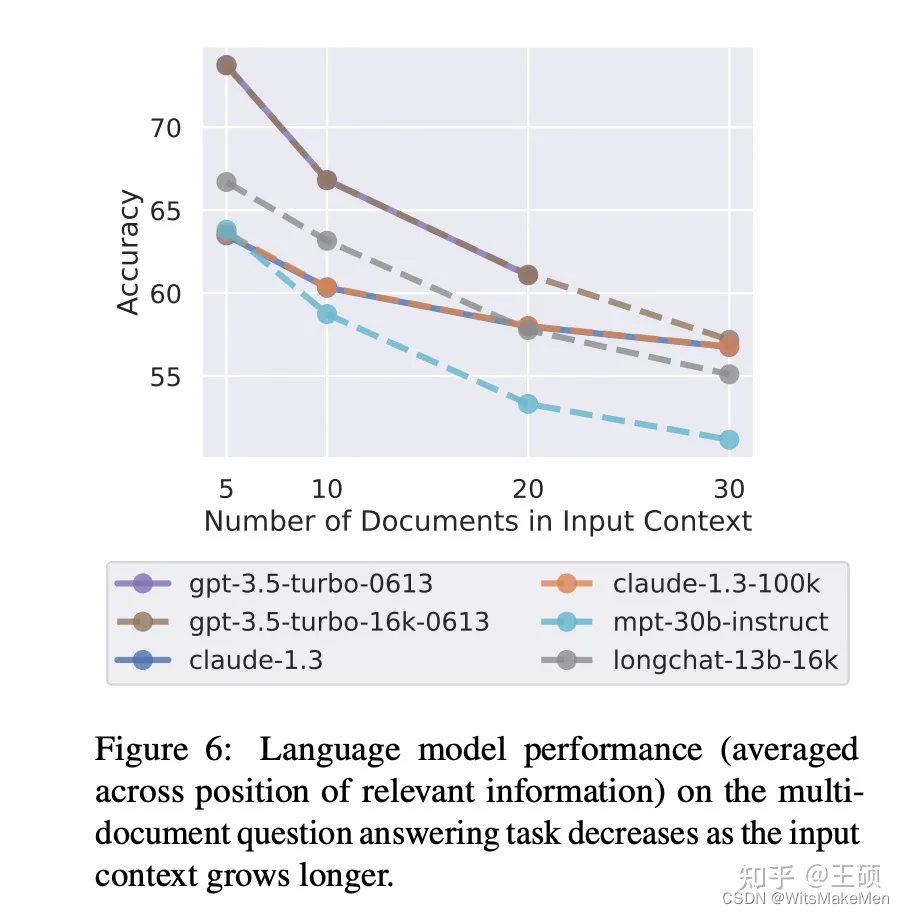
A tecnologia de recuperação é usada para encontrar os fragmentos de informação mais relevantes para a questão de entrada a partir de uma grande quantidade de dados externos. Ao mesmo tempo que fornece uma referência para o LLM gerar respostas, também filtra a interferência de algumas informações irrelevantes até certo ponto para melhorar o precisão das respostas geradas. Além disso, quanto maior a janela de contexto, maior será o custo de inferência. Portanto, a introdução de etapas relevantes de recuperação de informações também pode reduzir custos desnecessários de raciocínio.
Módulos principais
Para construir um sistema LLM aprimorado por recuperação, os principais módulos que precisam ser implementados e os problemas que precisam ser resolvidos incluem:
- Módulo de dados e indexação : como lidar com dados externos e construir índices
- Módulo de consulta e recuperação : como recuperar informações relevantes com precisão e eficiência
- Módulo de Geração de Resposta : Como usar informações relevantes recuperadas para melhorar o resultado do LLM
Módulo de dados e índice
coleção de dados
A função do módulo de aquisição de dados é geralmente converter dados externos de múltiplas fontes, tipos e formatos em um objeto de documento unificado (Objeto de Documento) para facilitar o processamento e uso subsequente. Além de conter o conteúdo do texto original, o objeto documento geralmente também carrega as metainformações do documento (Metadados), que podem ser utilizadas para posterior recuperação e filtragem. As metainformações incluem, mas não estão limitadas a:
- Informações de tempo, como tempos de criação e modificação de documentos
- Título, palavras-chave, entidades (pessoas, lugares, etc.), categorias de texto e outras informações
- Resumos e resumos de texto
Algumas metainformações podem ser obtidas diretamente e outras com a ajuda da tecnologia PNL, como extração de palavras-chave, reconhecimento de entidades, classificação de texto, resumo de texto, etc. Podem ser usados modelos e estruturas tradicionais de PNL ou podem ser implementados com base em LLM.
As fontes de dados externos podem ser diversas, como
- Vários documentos do Doc, planilhas, apresentações do Slides, programações do calendário, arquivos do Drive, etc. no pacote do Google
- Dados de comunidades de bate-papo como Slack e Discord
- Arquivos de código hospedados no Github, Gitlab
- Vários documentos sobre o Confluence
- Dados da página da web
- Dados retornados pela API
- ficheiros locais
Os tipos e formatos de arquivo de dados externos também podem ser diversos, como
- Do ponto de vista do tipo de dados, incluindo texto simples, tabelas, documentos de apresentação, código, etc.
- Do ponto de vista do formato de armazenamento de arquivos, incluindo txt, csv, pdf, markdown, json e outros formatos
Os dados externos podem ser multilíngues, como chinês, inglês, alemão, japonês, etc. Além disso, também pode ser multimodal, além da modalidade de texto discutida acima, inclui também imagens, áudio, vídeo e outras modalidades. Contudo, os dados externos discutidos neste artigo serão limitados à modalidade texto.
Ao construir um módulo de aquisição de dados, dados de diferentes fontes, tipos, formatos e idiomas podem exigir diferentes métodos de leitura.
fragmentação de texto
A fragmentação de texto é o processo de cortar texto longo em pedaços menores, como cortar um artigo longo em parágrafos relativamente curtos. Então, por que fragmentar texto? Por um lado, o comprimento de contexto atual do LLM é limitado. Colocar diretamente todo um artigo longo como informação relevante na janela de contexto do LLM pode exceder o limite de comprimento. Por outro lado, para textos longos, mesmo que estejam relacionados com a questão de consulta, geralmente não são completamente relevantes. O chunking pode eliminar até certo ponto conteúdo irrelevante e filtrar alguns para posterior geração de resposta. Ruído desnecessário.
A qualidade da segmentação do texto afetará muito o efeito da geração de respostas subsequentes. Se a segmentação não for boa, a correlação entre o conteúdo será cortada. Portanto, é importante projetar uma boa estratégia de chunking. As estratégias de chunking incluem métodos de segmentação específicos (como segmentar por frases ou parágrafos), o tamanho apropriado dos blocos, se a sobreposição entre diferentes blocos é permitida, etc. O blog da Pinecone Chunking Strategies for LLM Applications [11] fornece alguns fatores que precisam ser considerados ao projetar estratégias de chunking.
- Características do conteúdo original : O conteúdo original é longo (postagens de blogs, livros, etc.) ou curto (tweets, mensagens instantâneas, etc.) e qual é o formato (HTML, Markdown, Code ou LaTeX, etc.) • Diferentes características de conteúdo podem ser aplicadas de maneira diferente.estratégia de chunking;
- Métodos de indexação subsequentes : Atualmente, o índice mais comumente usado é a indexação vetorial de conteúdo em pedaços. Diferentes modelos de incorporação de vetores podem ter seus próprios tamanhos de pedaços aplicáveis. Por exemplo, o modelo de transformador de frase é mais adequado para conteúdo em nível de frase. Para incorporação, o tamanho de bloco adequado do modelo text-embedding-ada-002 da OpenAI está entre 256 e 512 tags;
- Comprimento da pergunta : O comprimento da pergunta precisa ser considerado porque fragmentos de texto relevantes precisam ser recuperados com base na pergunta;
- Como usar o conteúdo relevante recuperado no estágio de geração de resposta : Se o conteúdo relevante recuperado for fornecido diretamente ao LLM como parte do Prompt, então o limite de comprimento de entrada do LLM precisa ser considerado ao projetar o tamanho do bloco.
Método de implementação de bloco
Então, como implementar o bloqueio de texto? De modo geral, o processo geral de implementação da fragmentação de texto é o seguinte:
- Corte o texto longo original em pequenas unidades semânticas, onde as unidades semânticas geralmente estão no nível da frase ou do parágrafo;
- Funda essas pequenas unidades semânticas em pedaços maiores até que o tamanho do pedaço definido (Tamanho do pedaço) seja alcançado e, em seguida, trate o pedaço como um fragmento de texto independente;
- O próximo fragmento de texto é construído iterativamente e a sobreposição geralmente é definida entre fragmentos de texto adjacentes para manter a coerência semântica.
Então, como dividir o texto longo original em pequenas unidades semânticas? O método mais comumente usado é dividir com base em delimitadores, como pontos (.), novas linhas (\n), espaços, etc. Além de usar um único separador para segmentação simples, você também pode definir um conjunto de separadores para segmentação iterativa. Por exemplo, ao definir ["\n\n", "\n", " ", ""]tal conjunto de separadores, ao segmentar, primeiro use o primeiro separador para segmentar (implementando algo semelhante aos parágrafos). (O efeito da segmentação) Após a conclusão da primeira segmentação, os blocos que excederem o tamanho predefinido continuarão a ser segmentados usando separadores subsequentes e assim por diante. Este método de segmentação pode manter melhor a estrutura hierárquica do texto original.
Para alguns textos estruturados, como código, Markdown, LaTeX e outros textos, pode ser necessário considerá-los separadamente ao segmentar:
\nclassPor exemplo, em arquivos de código Python, pode ser necessário adicionar algo semelhante ao delimitador\ndefpara garantir a integridade dos blocos de código de classe e função;- Por exemplo, os arquivos Markdown são organizados por meio de diferentes níveis de cabeçalhos, ou seja, diferentes números de símbolos #. Essa estrutura hierárquica pode ser mantida usando separadores específicos durante a divisão.
A configuração do tamanho do bloco de texto também é um fator importante a considerar na estratégia de agrupamento. Se for muito grande ou muito pequeno, afetará o efeito da geração da resposta final. O método de cálculo mais comumente usado para o tamanho do bloco de texto pode ser baseado diretamente no número de caracteres (nível de caractere) ou no número de tokens (nível de token). Quanto à forma de determinar o tamanho adequado do bloco, isso varia de cenário para cena, sendo difícil ter um padrão unificado. A escolha pode ser feita avaliando os efeitos dos diferentes tamanhos de bloco.
Alguns dos métodos de bloqueio mencionados acima possuem implementações correspondentes em LangChain [12] . Por exemplo, o exemplo de código a seguir
from langchain.text_splitter import CharacterTextSplitter
from langchain.text_splitter import RecursiveCharacterTextSplitter, Language
# text split
text_splitter = RecursiveCharacterTextSplitter(
# Set a really small chunk size, just to show.
chunk_size = 100,
chunk_overlap = 20,
length_function = len,
add_start_index = True,
)
# code split
python_splitter = RecursiveCharacterTextSplitter.from_language(
language=Language.PYTHON,
chunk_size=50,
chunk_overlap=0
)
# markdown split
md_splitter = RecursiveCharacterTextSplitter.from_language(
language=Language.MARKDOWN,
chunk_size=60,
chunk_overlap=0
)
Índice de dados
Após as operações anteriores de leitura de dados e segmentação de texto, os dados processados precisam ser indexados. Um índice é uma estrutura de dados usada para recuperar rapidamente o conteúdo de texto relevante para a consulta de um usuário. É um dos principais componentes básicos do LLM aprimorado por recuperação.
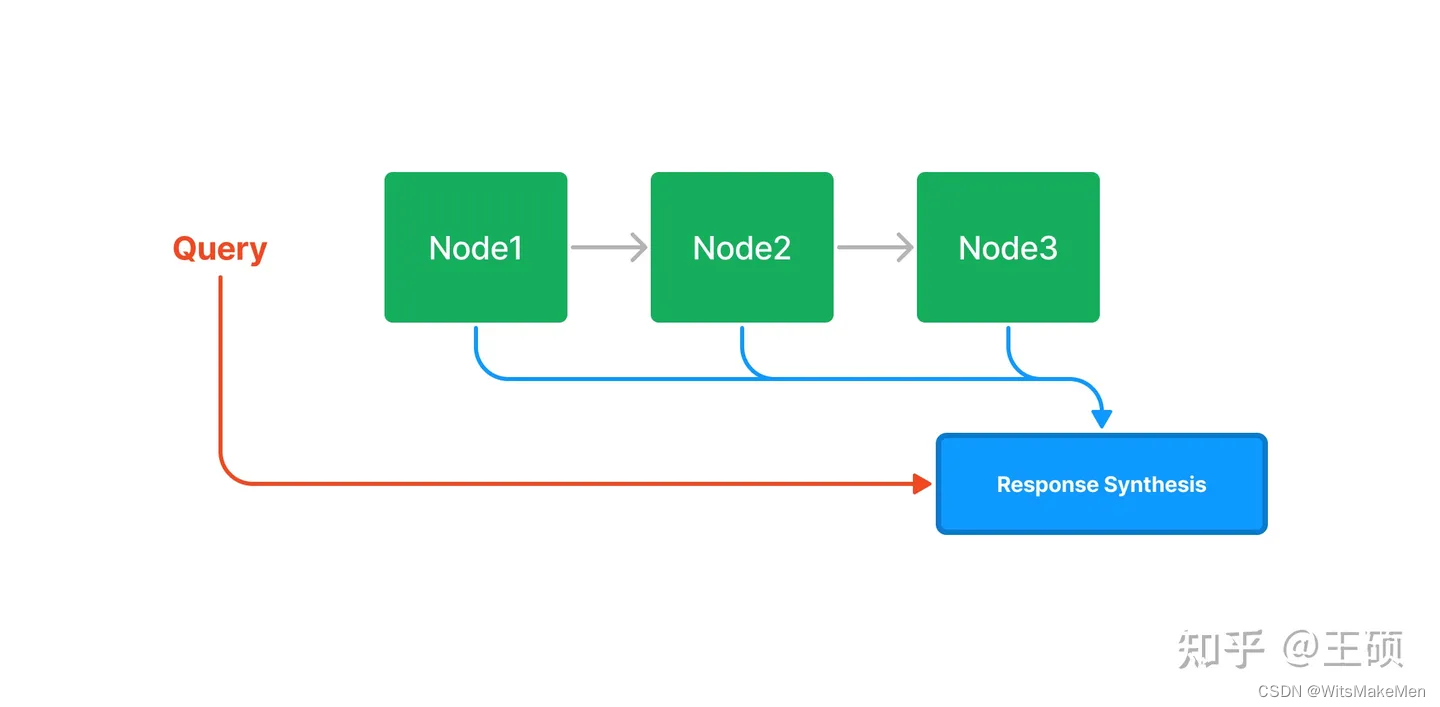
Aqui estão algumas estruturas de índice comuns. Para ilustrar diferentes estruturas de índices, é introduzido o conceito de nó (Nó). Aqui, os nós são os pedaços de texto (Chunks) gerados após a segmentação do documento na etapa anterior. O diagrama de estrutura de índice a seguir vem do documento How Each Index Works do LlamaIndex [13] .
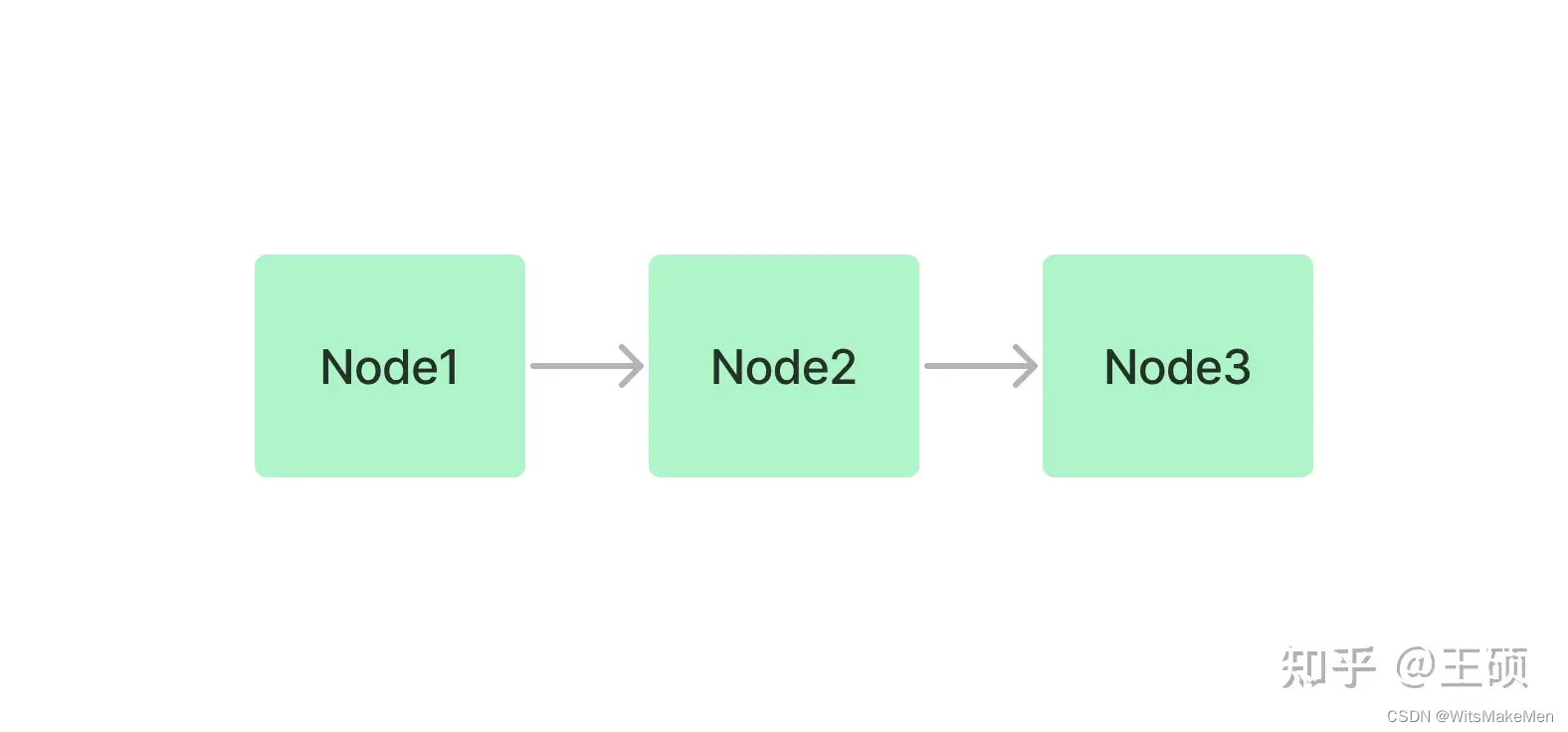
Índice encadeado
Índices encadeados indexam blocos de texto sequencialmente por meio da estrutura de uma lista vinculada. Nas fases subsequentes de recuperação e geração, todos os nós podem simplesmente ser percorridos sequencialmente ou a filtragem pode ser realizada com base em palavras-chave.
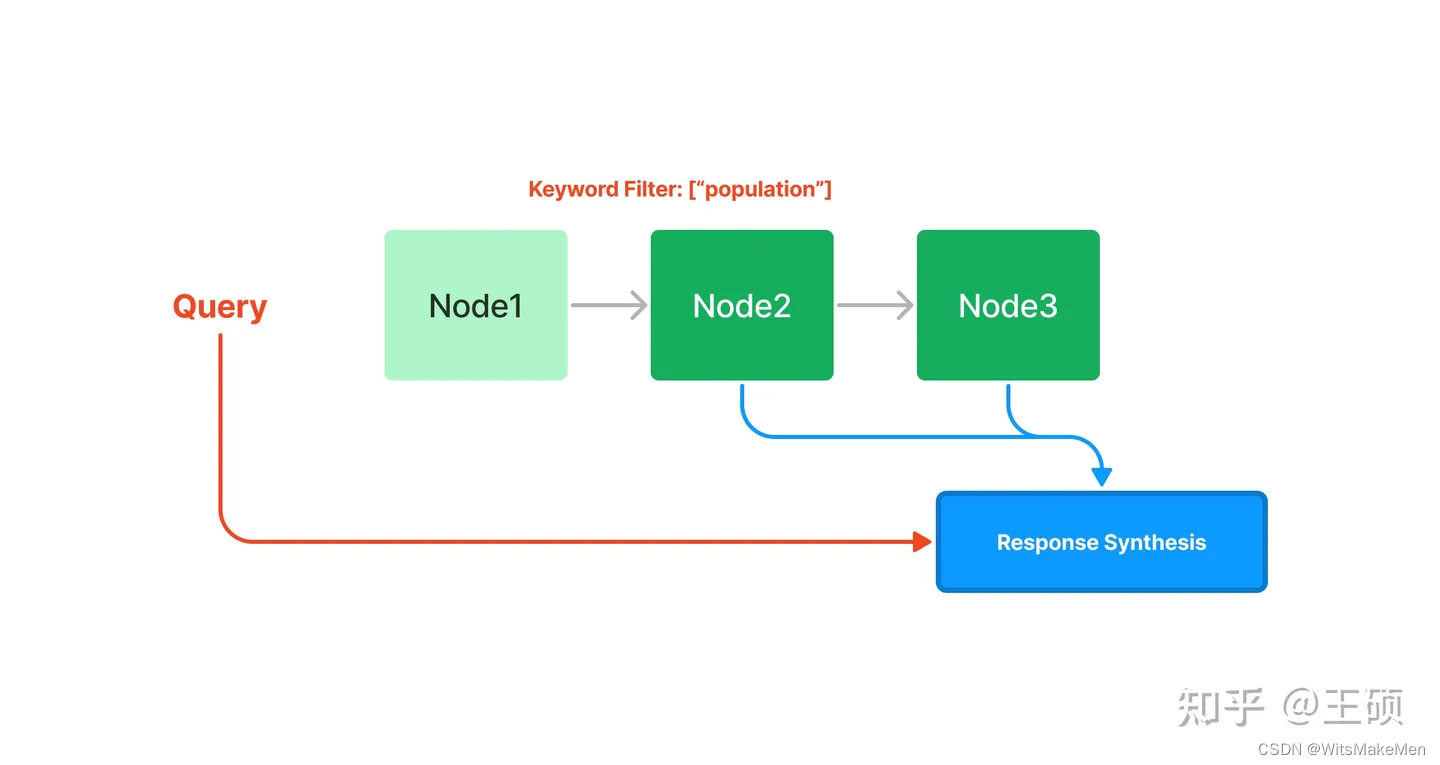
índice de árvore
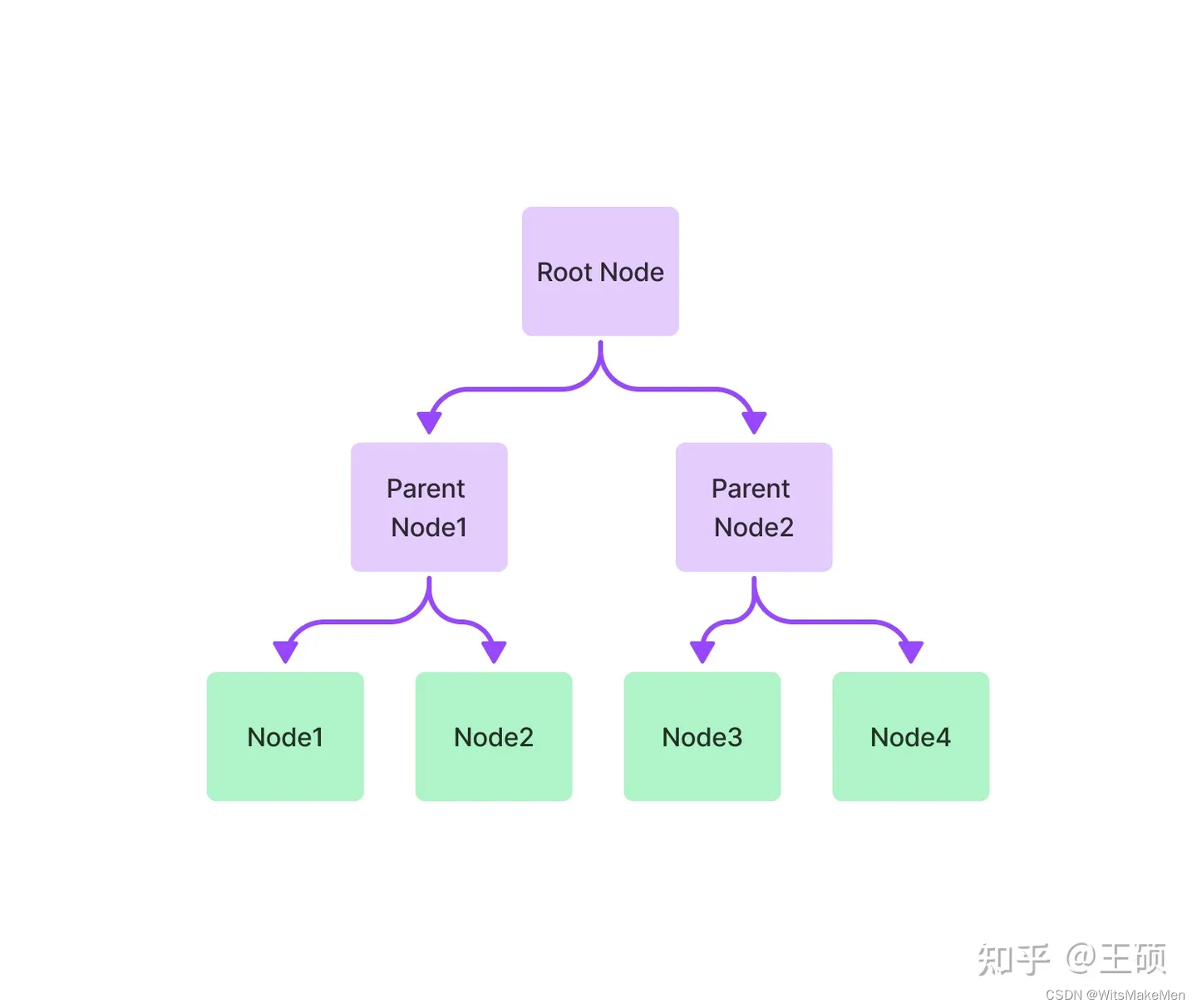
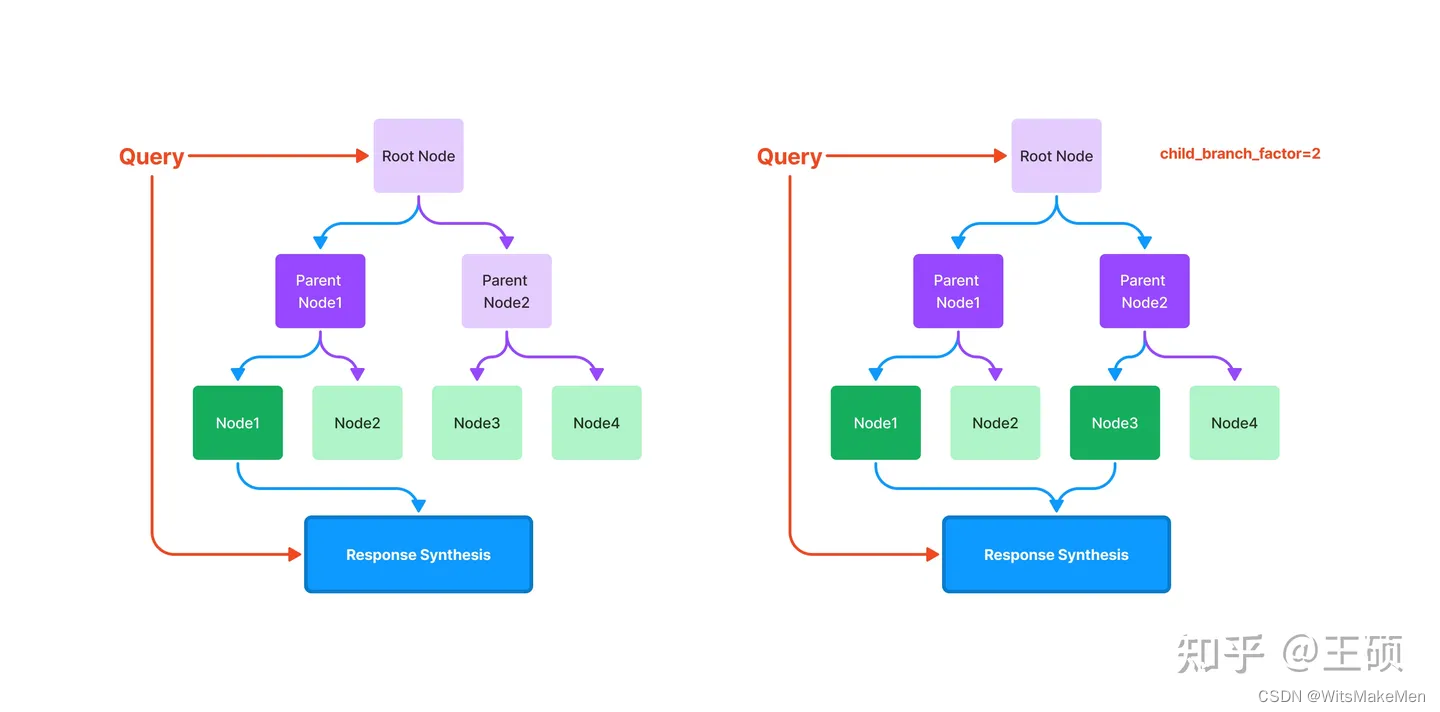
Um índice de árvore constrói um conjunto de nós (blocos de texto) em uma estrutura hierárquica de índice semelhante a uma árvore que é construída a partir de nós folha (blocos de texto originais), com cada nó pai sendo um resumo de um nó filho. Na fase de recuperação, você pode percorrer para baixo a partir do nó raiz ou usar diretamente as informações do nó raiz. Os índices de árvore fornecem uma maneira mais eficiente de consultar longos blocos de texto e também podem ser usados para extrair informações de diferentes partes do texto. Ao contrário dos índices encadeados, os índices em árvore não requerem consultas sequenciais.
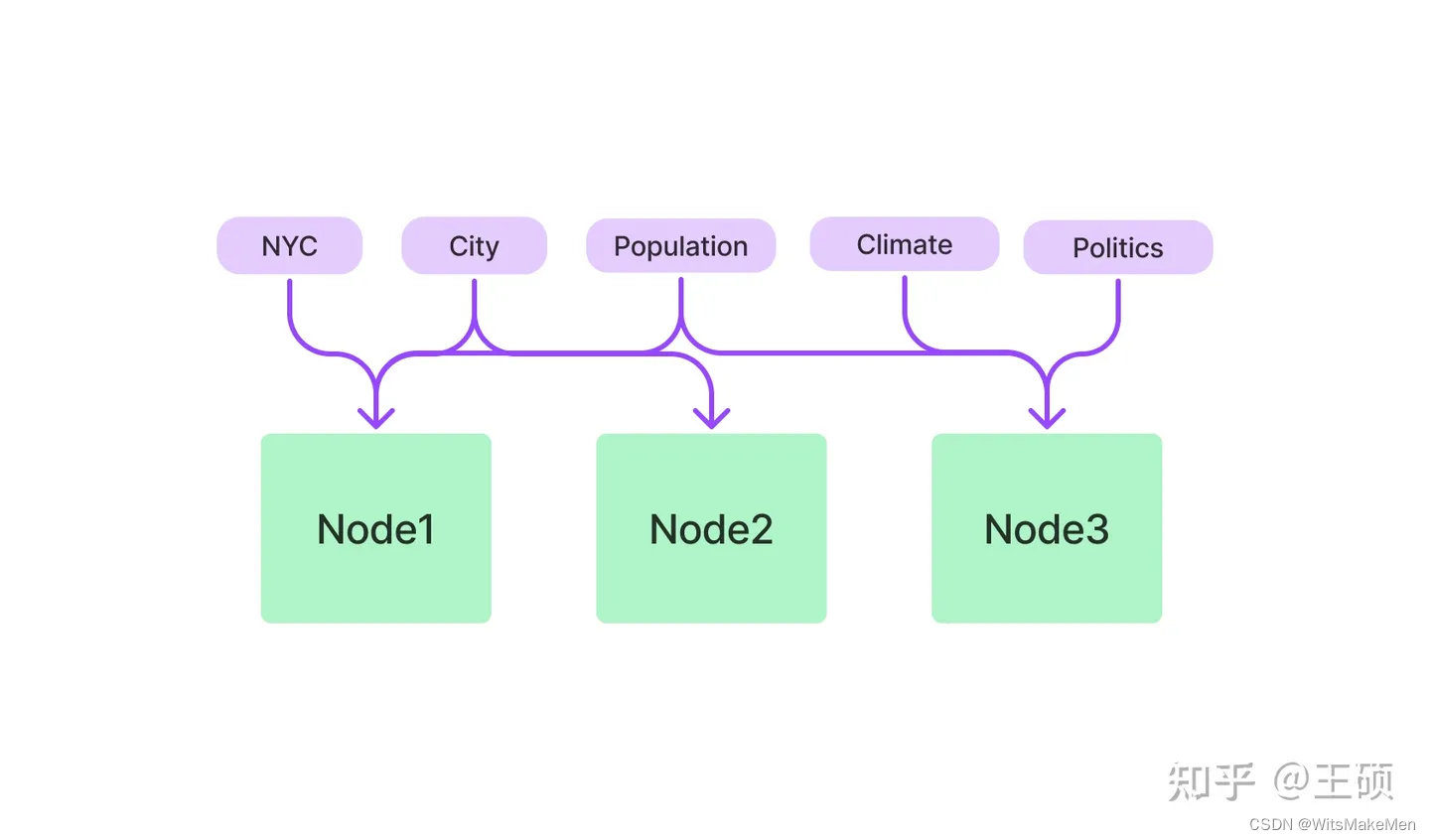
Índice da tabela de palavras-chave
O índice da tabela de palavras-chave extrai palavras-chave de cada nó e constrói um mapeamento muitos-para-muitos de cada palavra-chave para o nó correspondente, o que significa que cada palavra-chave pode apontar para vários nós, e cada nó também pode conter várias palavras-chave. Durante a fase de recuperação, os nós podem ser filtrados com base em palavras-chave nas consultas do usuário.
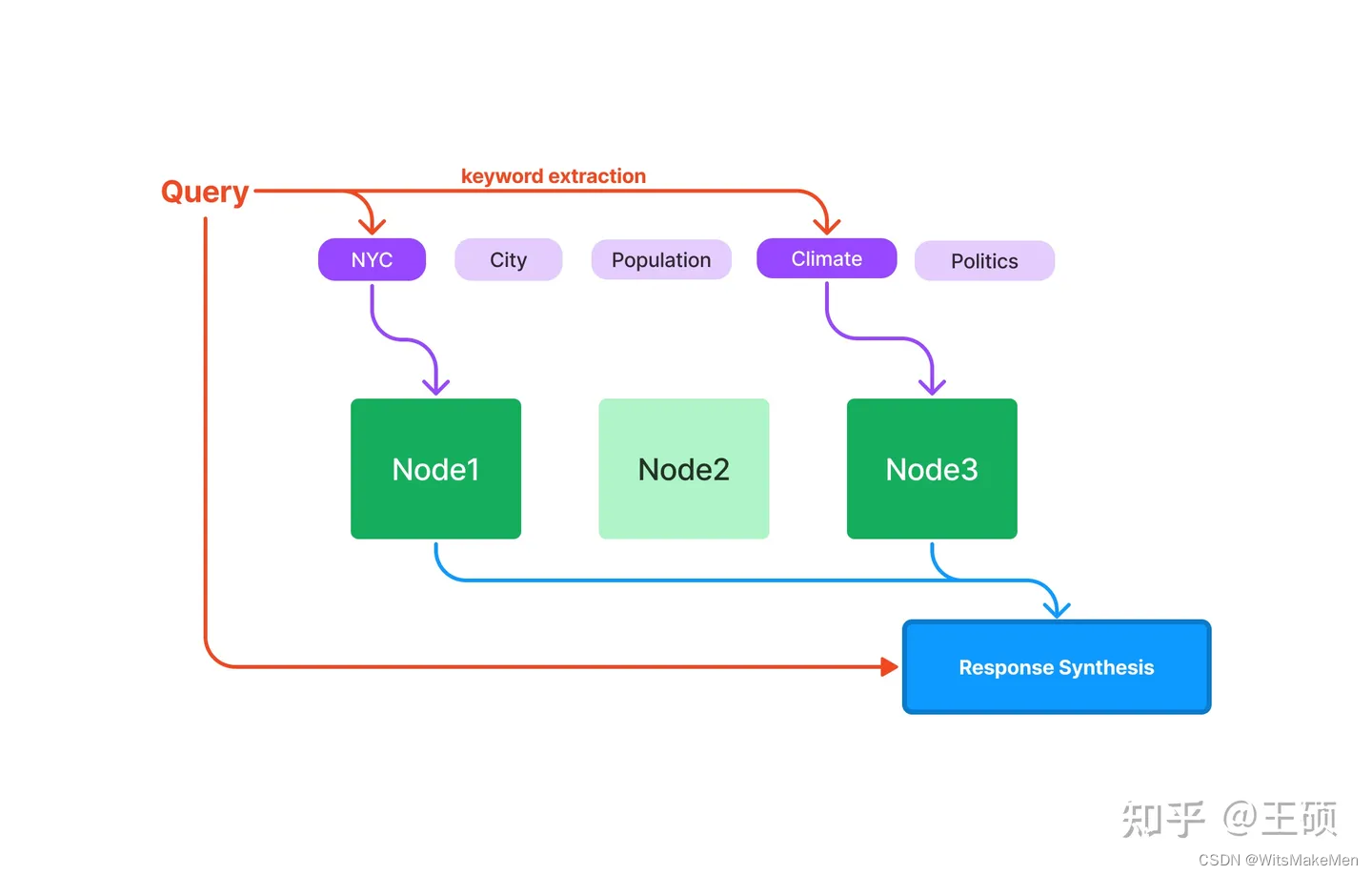
índice vetorial
A indexação vetorial é atualmente o método de indexação mais popular. Este método geralmente usa o modelo de incorporação de texto para mapear o bloco de texto em um vetor de comprimento fixo e, em seguida, armazená-lo no banco de dados de vetores . Durante a recuperação, o texto da consulta do usuário é mapeado em um vetor usando o mesmo modelo de incorporação de texto e, em seguida, o nó ou nós mais semelhantes são obtidos com base no cálculo de similaridade vetorial.
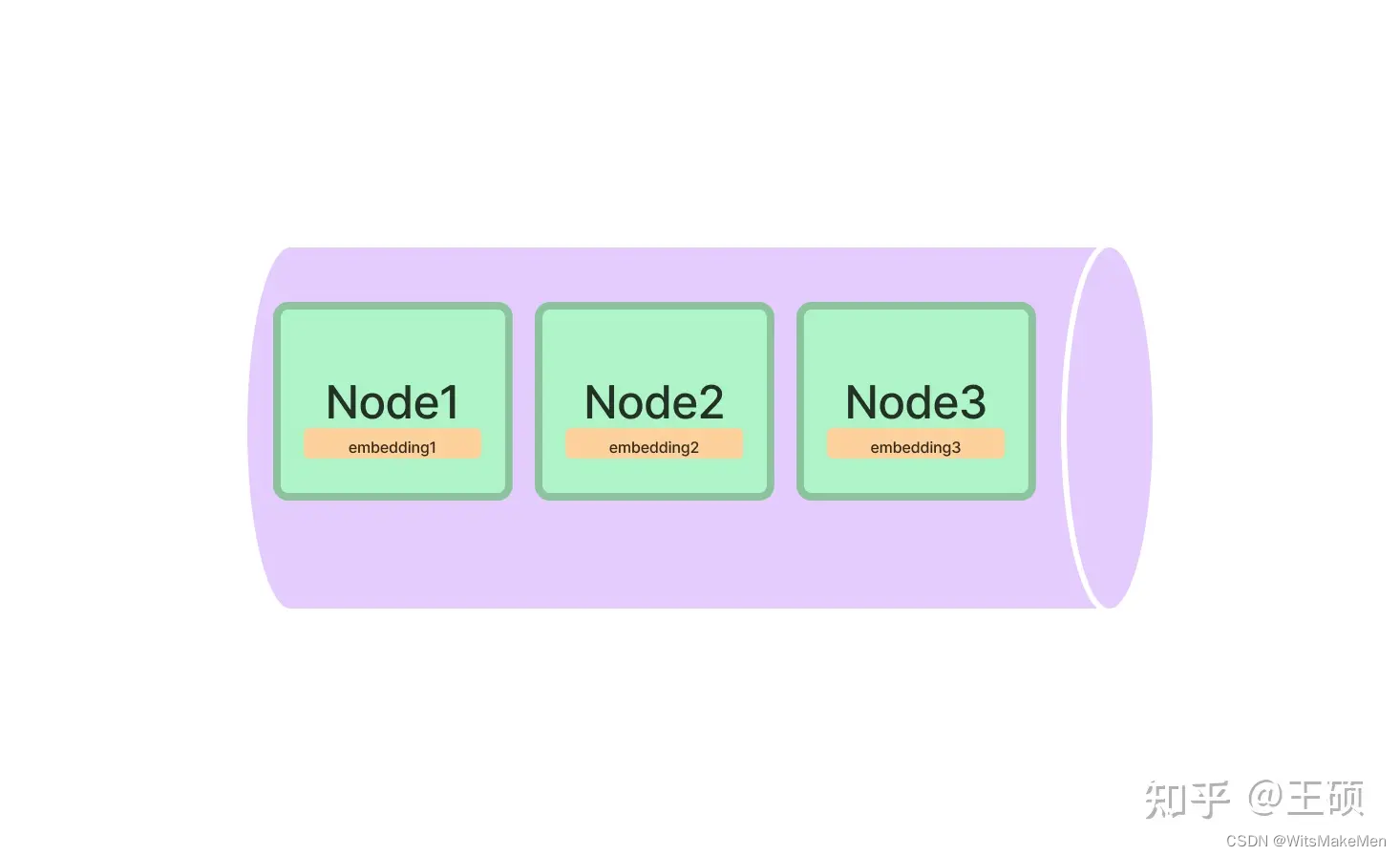
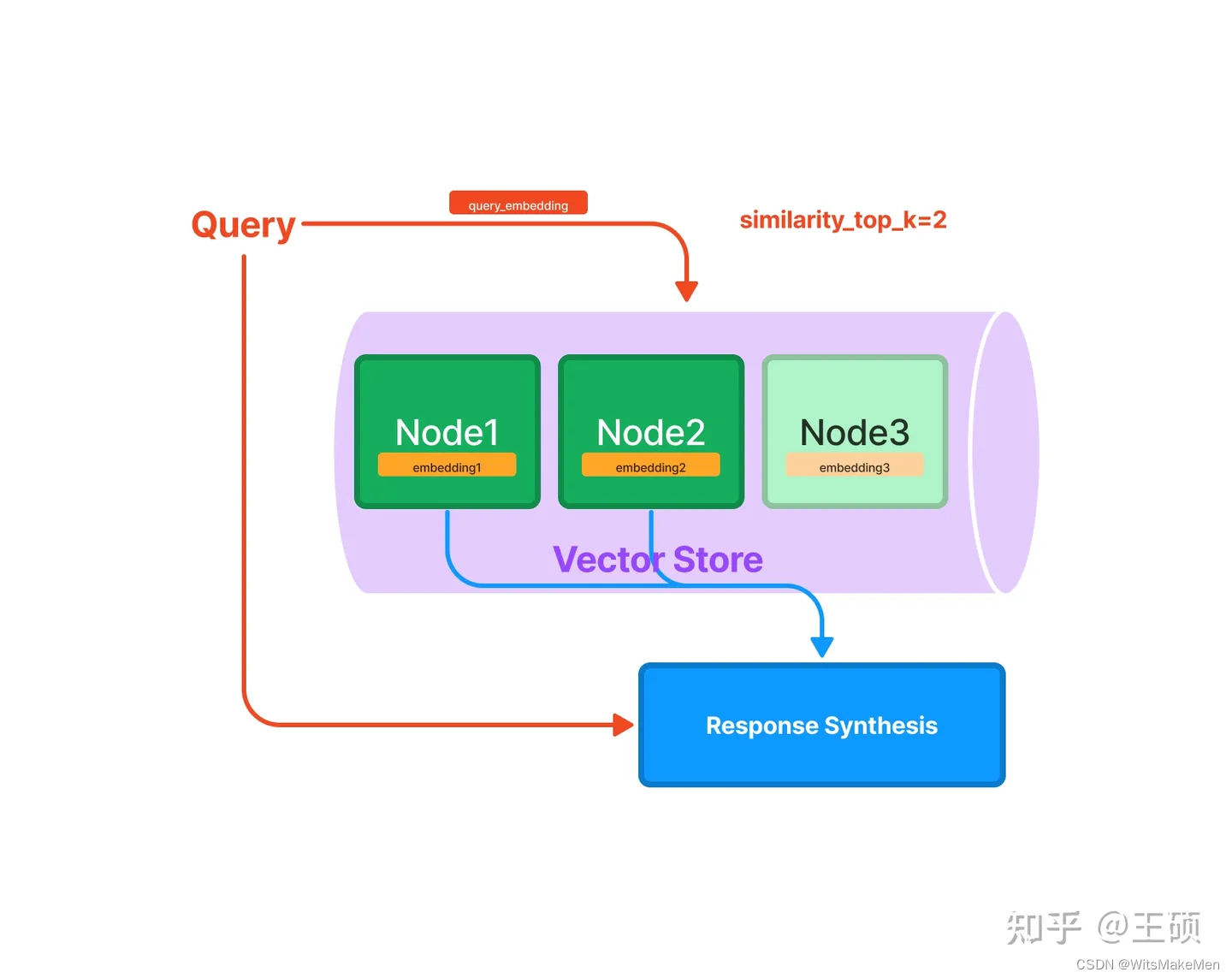
A declaração acima envolve três conceitos importantes na indexação e recuperação de vetores: modelo de incorporação de texto , recuperação de vetores semelhantes e banco de dados de vetores . Os detalhes são explicados um por um abaixo.
modelo de incorporação de texto
O modelo de incorporação de texto converte texto não estruturado em vetores estruturados (vetor).Atualmente, vetores densos obtidos por meio de aprendizado são comumente usados.
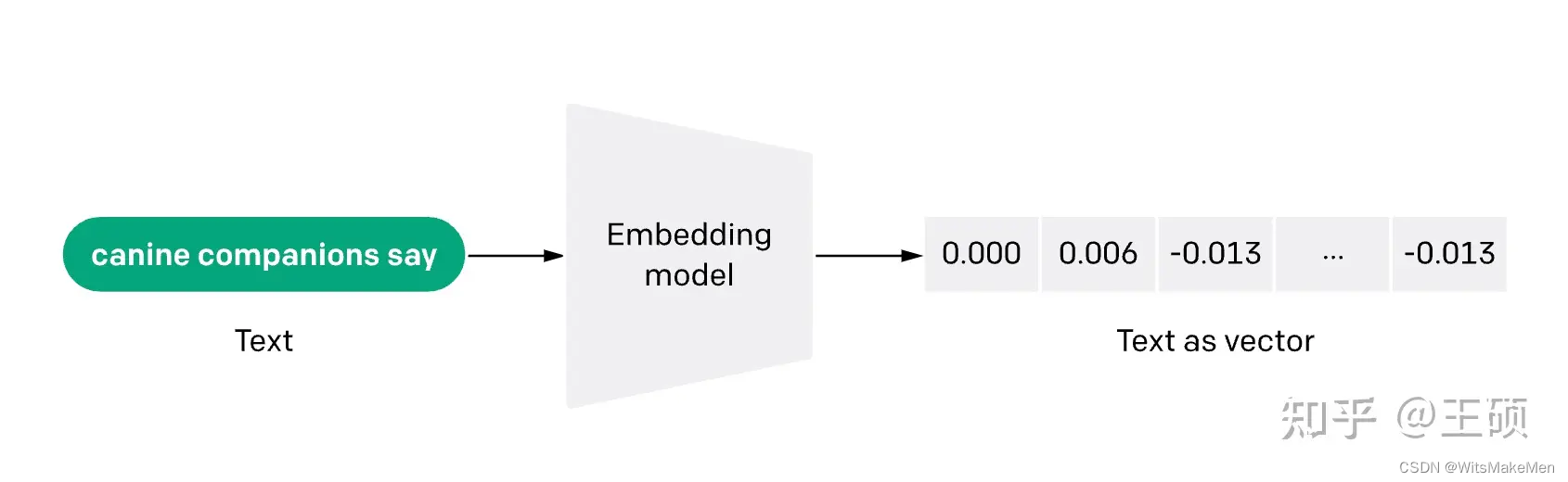
Atualmente, existem muitos modelos de incorporação de texto para escolher, como
- Os primeiros modelos Word2Vec, GloVe, etc. raramente são usados atualmente.
- O modelo Sentence Transformers [14] baseado no pré-treinamento da rede BERT dupla tem um melhor efeito de incorporação nas sentenças.
- O modelo text-embedding-ada-002 [15] fornecido pela OpenAI tem um bom desempenho na incorporação e pode lidar com texto com comprimento máximo de 8.191 tokens.
- O modelo do instrutor [16] , que é um modelo de incorporação de texto ajustado por instruções, pode fornecer instruções de tarefas para gerar personalização relativa de acordo com tarefas (como classificação, recuperação, agrupamento, avaliação de texto, etc.) e campos (como ciências). , finanças, etc.) vetores de incorporação de texto otimizados sem qualquer ajuste fino
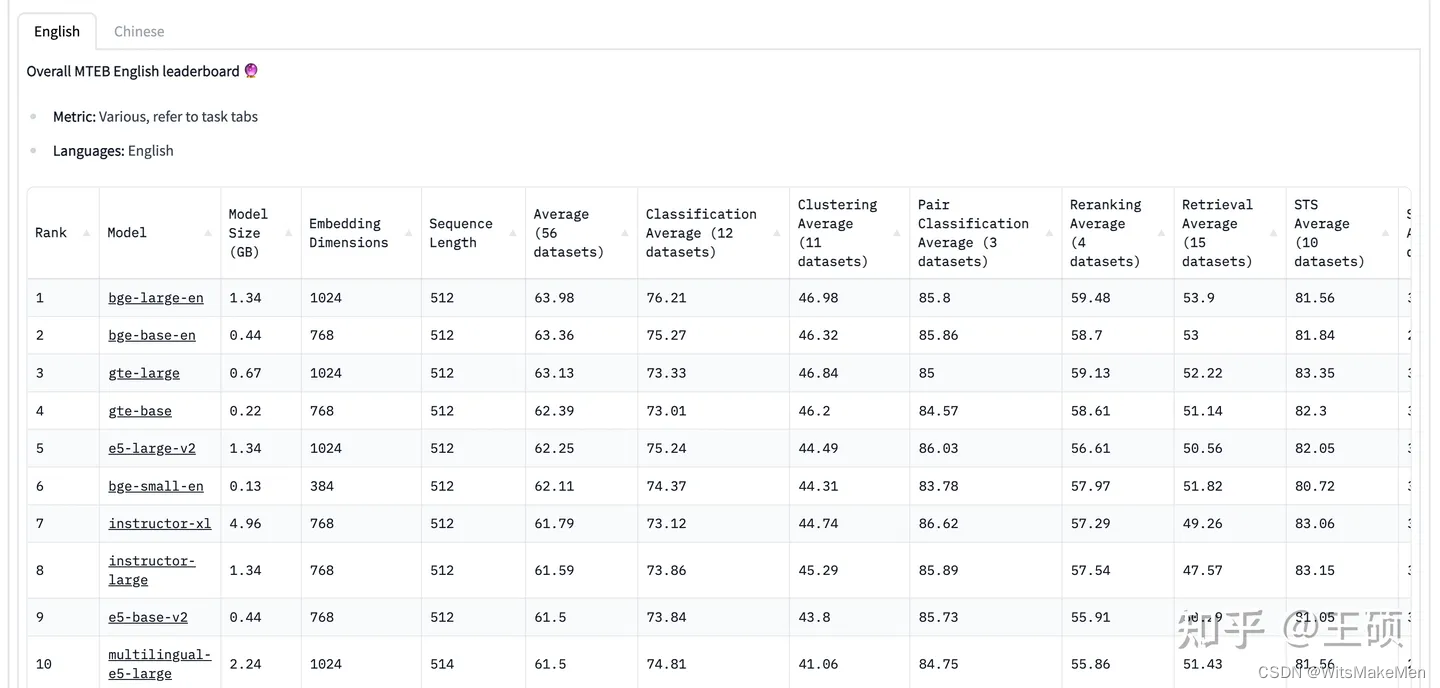
- Modelo BGE [17] : O modelo vetorial semântico chinês e inglês de código aberto do Zhiyuan Research Institute, atualmente classificado em primeiro lugar nas listas chinesa e inglesa do MTEB.
A seguir está a lista MTEB Leaderboard [18] para avaliar o efeito dos modelos de incorporação de texto (em 18/08/2023). É importante notar que esses modelos de incorporação de texto prontos para uso não são ajustados para tarefas downstream específicas, portanto, eles podem não necessariamente ter um desempenho suficientemente bom em tarefas downstream. A melhor maneira geralmente é treinar novamente ou ajustar seu próprio modelo de incorporação de texto em dados específicos downstream.
Pesquisa de vetor semelhante
O problema a ser resolvido pela recuperação de vetores semelhantes é que, dado um vetor de consulta, como recuperar com precisão e eficiência um ou mais vetores semelhantes a ele a partir de vetores candidatos. A primeira é a escolha do método de medição de similaridade , que pode usar similaridade de cosseno, produto escalar, distância euclidiana, distância de Hamming, etc. Em circunstâncias normais, a similaridade de cosseno pode ser usada diretamente. A segunda é a escolha do algoritmo de recuperação de similaridade e do método de implementação.A magnitude dos vetores candidatos, velocidade de recuperação e requisitos de precisão, limitações de memória, etc., são todos fatores que precisam ser considerados.
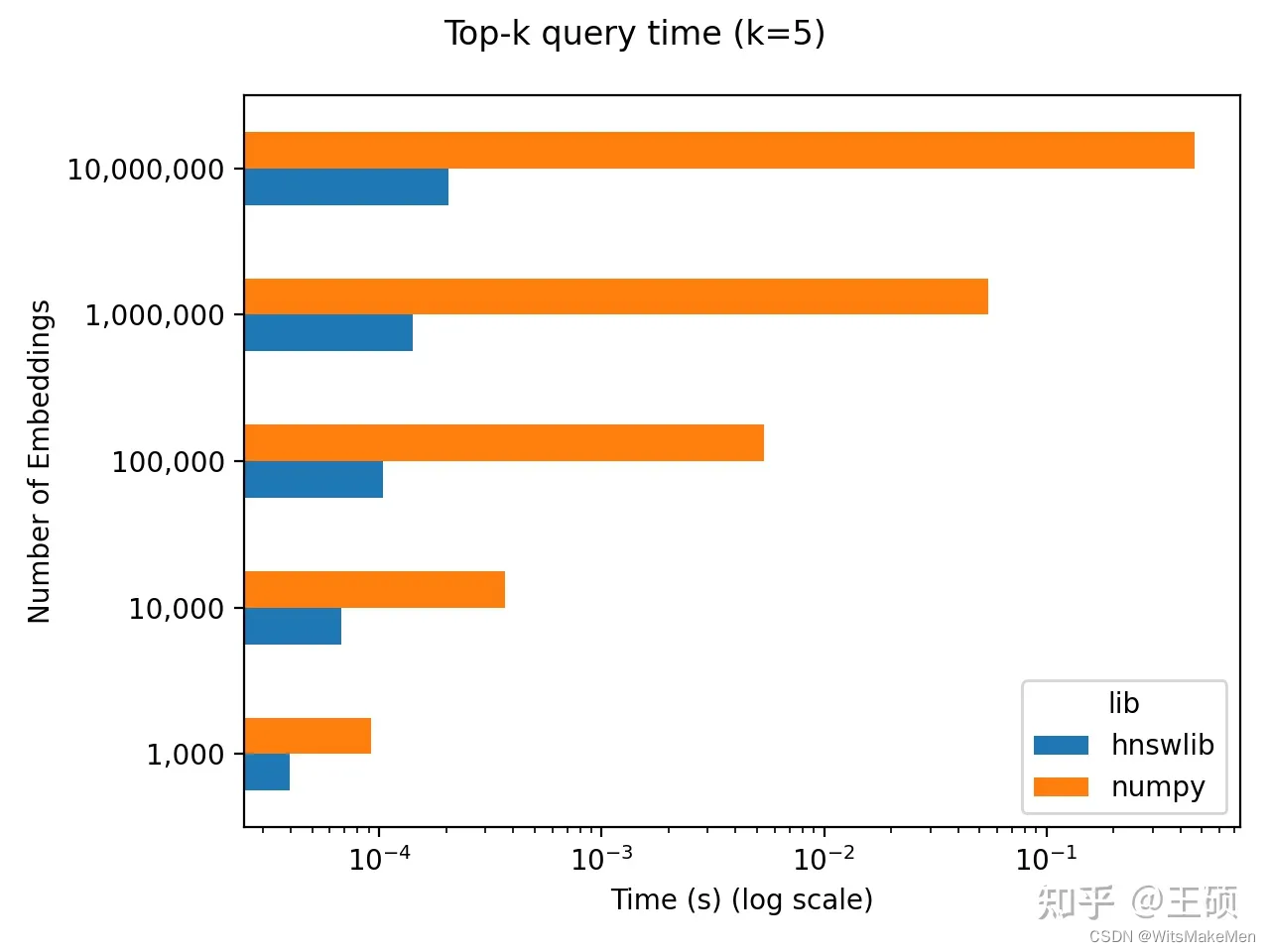
Quando o número de vetores candidatos é relativamente pequeno, por exemplo, existem apenas dezenas de milhares de vetores, a biblioteca Numpy pode implementar recuperação de vetores semelhante, que é simples de implementar, altamente precisa e rápida. Um blogueiro estrangeiro fez um teste de benchmark simples e descobriu que Você realmente precisa de um banco de dados de vetores [19] . Quando o número de vetores candidatos está abaixo de 100.000, ele foi implementado comparando Numpy com outra recuperação eficiente e aproximada do vizinho mais próximo. Biblioteca Hnswlib [20 ] , descobriram que não há diferença de ordem de grandeza na eficiência de recuperação, mas o processo de implementação do Numpy é mais simples.
A seguir está um código de implementação simples usando Numpy:
import numpy as np
# candidate_vecs: 2D numpy array of shape N x D
# query_vec: 1D numpy array of shape D
# k: number of top k similar vectors
sim_scores = np.dot(candidate_vecs, query_vec)
topk_indices = np.argsort(sim_scores)[::-1][:k]
topk_values = sim_scores[topk_indices]
Para recuperação de similaridade de vetores em grande escala, não é apropriado usar a biblioteca Numpy, sendo necessária uma solução de implementação mais eficiente. Faiss [21] , que é de código aberto da equipe do Facebook , é uma boa escolha. Faiss é uma biblioteca para pesquisa eficiente de similaridade e agrupamento de vetores. Ela implementa muitos algoritmos para pesquisa em coleções de vetores de qualquer tamanho. Além de rodar na CPU, alguns algoritmos também suportam aceleração de GPU. Faiss contém uma variedade de algoritmos de recuperação de similaridade. Qual algoritmo usar depende de fatores como volume de dados, frequência de recuperação, precisão e velocidade de recuperação.
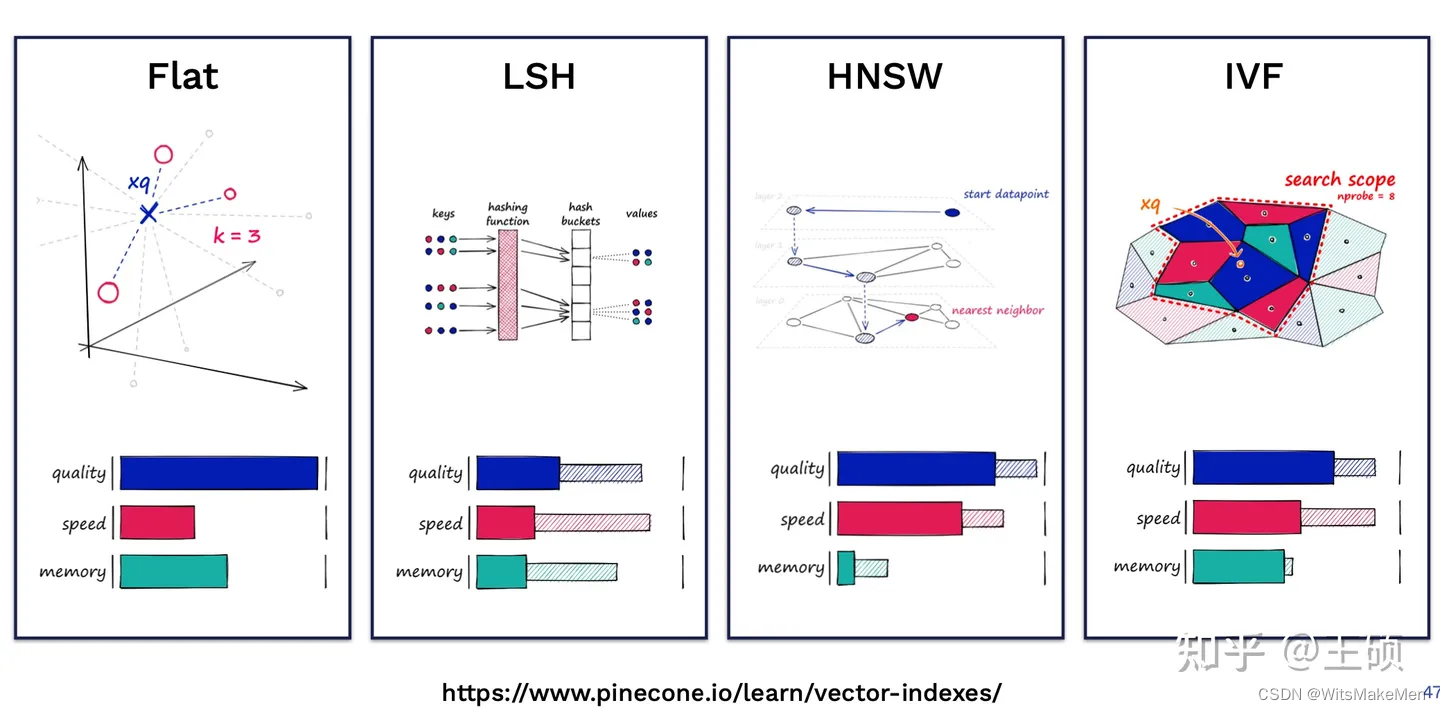
O blog da Pinecone, Índices de vizinhos mais próximos para pesquisa de similaridade [22], fornece uma introdução detalhada a vários índices comumente usados em Faiss. A figura a seguir é uma comparação qualitativa de vários índices em diferentes dimensões:
banco de dados vetorial
O esquema de recuperação de similaridade vetorial baseado em Numpy e Faiss mencionado acima ainda pode carecer de algumas funções se aplicado a produtos reais, como:
- Hospedagem e backup de dados
- Gerenciamento de dados, como inserção, exclusão e atualização de dados
- Armazenamento de dados originais e metadados correspondentes a vetores
- Escalabilidade, incluindo expansão vertical e horizontal
Então surgiu o banco de dados vetorial . Simplificando, um banco de dados vetorial é um banco de dados usado especificamente para armazenar, gerenciar e consultar dados vetoriais e pode obter recuperação, agrupamento, etc. semelhantes de dados vetoriais. Bancos de dados de vetores atualmente populares incluem Pinecone [23] , Vespa [24] , Weaviate [25] , Milvus [26] , Chroma [27] , Tencent Cloud VectorDB [28] , etc., a maioria dos quais fornece produtos de código aberto.
O blog da Pinecone, What is a Vector Database [29] , fornece uma introdução relativamente sistemática aos princípios relevantes e à composição dos bancos de dados vetoriais.A imagem a seguir é um fluxo comum de processamento de dados de um banco de dados vetorial fornecido no artigo:

- Indexação : Indexe vetores usando algoritmos como Quantização de Produto (Quantização de Produto), Hash Sensível à Localidade (LSH), HNSW, etc. Esta etapa mapeia o vetor para uma estrutura de dados para obter uma pesquisa mais rápida.
- Consulta : compare o vetor de consulta e o vetor de índice para encontrar vetores semelhantes vizinhos mais próximos.
- Pós-processamento : Em alguns casos, após o vetor vizinho mais próximo ser recuperado do banco de dados vetorial, ele é pós-processado e então o resultado final é retornado.
O uso do banco de dados vetorial é relativamente simples. A seguir está um exemplo de código para usar Python para operar o banco de dados vetorial Pinecone:
# install python pinecone client
# pip install pinecone-client
import pinecone
# initialize pinecone client
pinecone.init(api_key="YOUR_API_KEY", environment="YOUR_ENVIRONMENT")
# create index
pinecone.create_index("quickstart", dimension=8, metric="euclidean")
# connect to the index
index = pinecone.Index("quickstart")
# Upsert sample data (5 8-dimensional vectors)
index.upsert([
("A", [0.1, 0.1, 0.1, 0.1, 0.1, 0.1, 0.1, 0.1]),
("B", [0.2, 0.2, 0.2, 0.2, 0.2, 0.2, 0.2, 0.2]),
("C", [0.3, 0.3, 0.3, 0.3, 0.3, 0.3, 0.3, 0.3]),
("D", [0.4, 0.4, 0.4, 0.4, 0.4, 0.4, 0.4, 0.4]),
("E", [0.5, 0.5, 0.5, 0.5, 0.5, 0.5, 0.5, 0.5])
])
# query
index.query(
vector=[0.3, 0.3, 0.3, 0.3, 0.3, 0.3, 0.3, 0.3],
top_k=3,
include_values=True
)
# Returns:
# {'matches': [{'id': 'C',
# 'score': 0.0,
# 'values': [0.3, 0.3, 0.3, 0.3, 0.3, 0.3, 0.3, 0.3]},
# {'id': 'D',
# 'score': 0.0799999237,
# 'values': [0.4, 0.4, 0.4, 0.4, 0.4, 0.4, 0.4, 0.4]},
# {'id': 'B',
# 'score': 0.0800000429,
# 'values': [0.2, 0.2, 0.2, 0.2, 0.2, 0.2, 0.2, 0.2]}],
# 'namespace': ''}
# delete index
pinecone.delete_index("quickstart")
Módulo de consulta e recuperação
transformação de consulta
O método de expressão do texto de consulta afeta diretamente os resultados da pesquisa, e pequenas alterações no texto podem levar a resultados totalmente diferentes. Usar diretamente o texto de consulta original para recuperação pode ser simples e eficaz em muitos casos, mas às vezes pode ser necessário realizar algumas transformações no texto de consulta para obter melhores resultados de recuperação, o que tem maior probabilidade de gerar melhores resultados de resposta no futuro. Listados abaixo estão vários métodos comuns de transformação de consulta.
Transformação 1: Reescrita sinônima
Reescreva a consulta original em diferentes expressões com a mesma semântica. O trabalho de reescrita pode ser concluído chamando LLM. Por exemplo, para uma consulta original: What are the approaches to Task Decomposition?, ela pode ser reescrita nas seguintes expressões sinônimas:
Como a decomposição de tarefas pode ser abordada?
Quais são os diferentes métodos de decomposição de tarefas?
Quais são as várias abordagens para tarefas de decomposição?
Para cada expressão de consulta, um conjunto de documentos relevantes é recuperado separadamente e, em seguida, todos os resultados da recuperação são desduplicados e mesclados para obter um conjunto maior de documentos relevantes candidatos. Ao reescrever a mesma consulta em múltiplas consultas sinônimas, as limitações de uma única consulta podem ser superadas e um conjunto mais rico de resultados de pesquisa pode ser obtido.
Transformação 2: decomposição de consulta
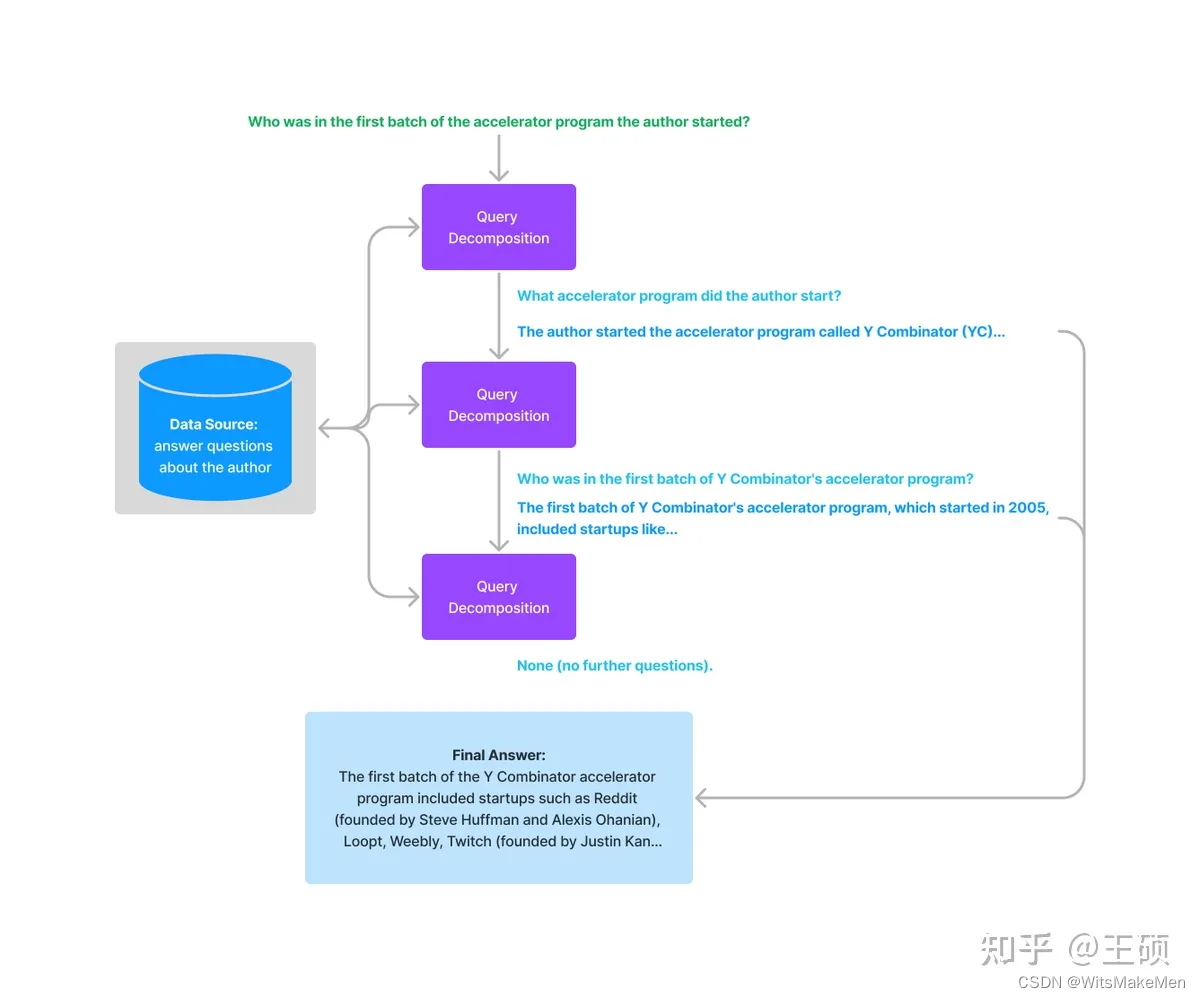
Estudos relevantes mostraram que ( self-ask [30] , ReAct [31] ), quando o LLM responde a perguntas complexas, se as perguntas complexas forem decompostas em subperguntas relativamente simples, o desempenho da resposta será melhor. Aqui ela pode ser dividida em decomposição em uma única etapa e decomposição em várias etapas .
A decomposição em etapa única transforma uma consulta complexa em várias subconsultas simples e funde a resposta de cada subconsulta como uma resposta à consulta complexa original.
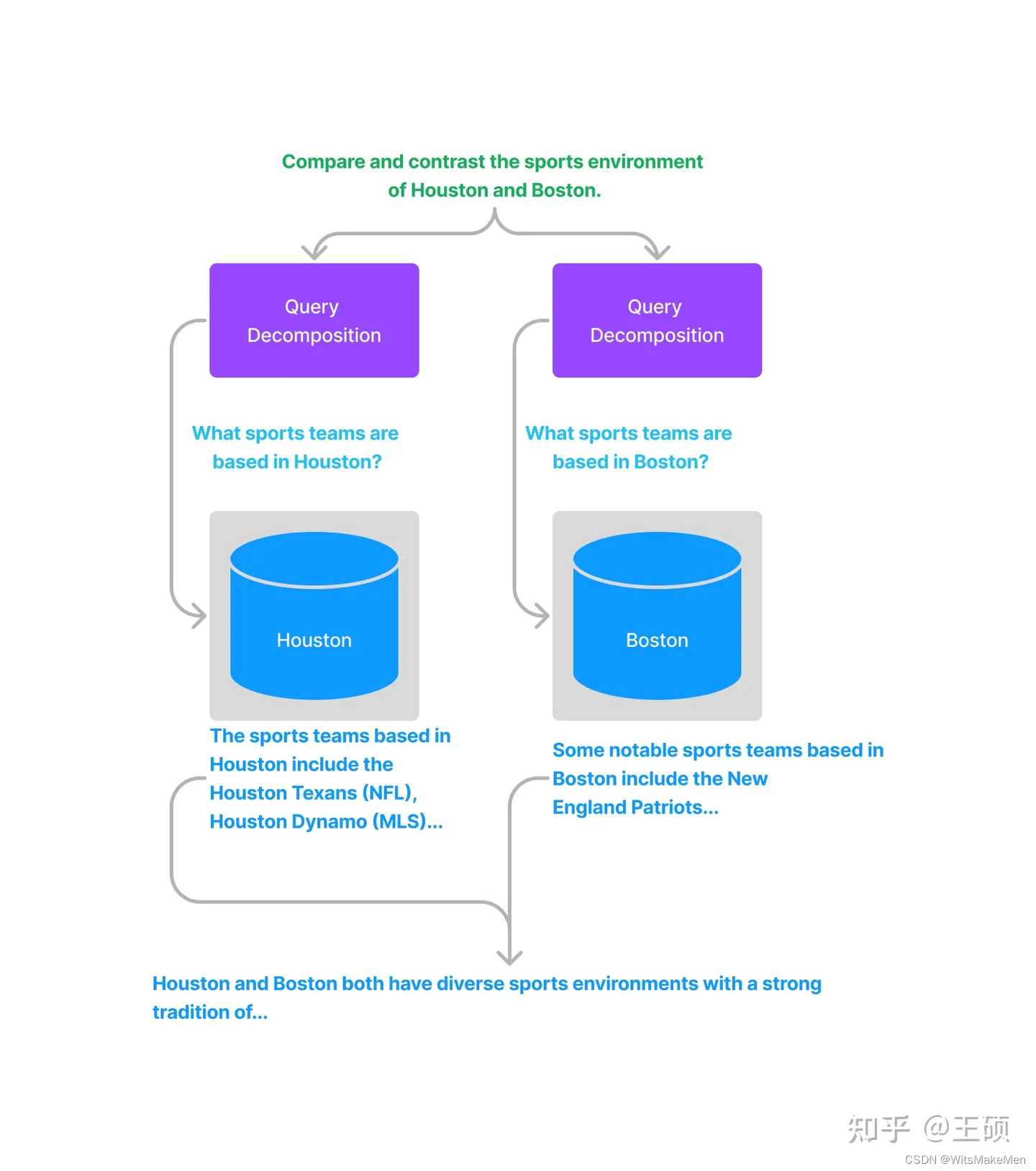
Para decomposição em várias etapas , uma determinada consulta complexa inicial será convertida em várias subconsultas passo a passo, e a próxima pergunta de consulta será gerada com base nos resultados da resposta da etapa anterior até que nenhuma outra pergunta possa ser feita. Por fim, as respostas de cada etapa são combinadas para gerar o resultado final.
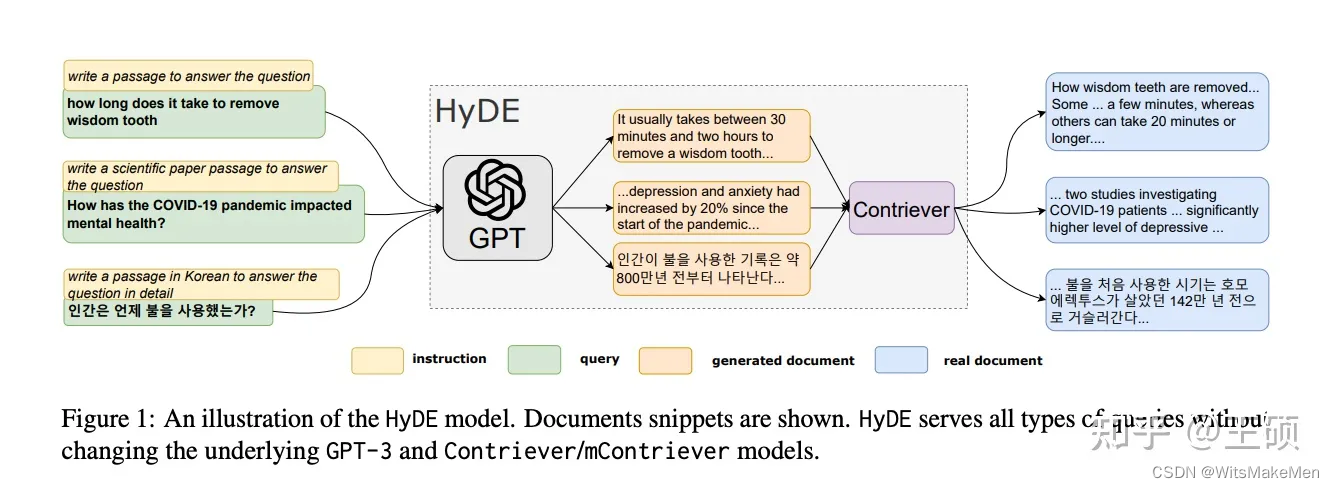
Transformação 3: HyDE
HyDE [32] , o nome completo é Hypothetical Document Embeddings, dada uma consulta inicial, primeiro use LLM para gerar um documento ou resposta hipotética e, em seguida, use esse documento ou resposta hipotética como uma nova consulta para recuperação, em vez de usar diretamente a inicial consulta. Essa transformação pode gerar um documento hipotético enganoso ou uma resposta sem contexto, o que pode resultar em uma resposta incorreta e não relevante para a consulta original. Aqui está um exemplo dado no artigo:
Classificação e pós-processamento
Após o processo de recuperação anterior, você poderá obter muitos documentos relacionados, que precisam ser filtrados e classificados. As estratégias comuns de filtragem e classificação incluem:
- Filtre e classifique com base na pontuação de similaridade
- Filtrar com base em palavras-chave, como limitar a inclusão ou exclusão de determinadas palavras-chave
- Deixe o LLM reordenar com base nos documentos relevantes retornados e suas pontuações de relevância
- Filtre e classifique com base no tempo, como filtrar apenas os documentos relevantes mais recentes
- Pondere a similaridade com base no tempo e, em seguida, classifique e filtre
Módulo de geração de resposta
Estratégia de geração de resposta
O módulo de recuperação recupera blocos de texto relevantes com base nas consultas do usuário, e o módulo de geração de resposta permite que o LLM use as informações relevantes recuperadas para gerar respostas à consulta original. Existem algumas estratégias diferentes de geração de respostas fornecidas no LlamaIndex.
Uma estratégia é combinar cada pedaço de texto relevante recuperado sequencialmente, revisando continuamente as respostas geradas a cada vez. Neste caso, haverá tantas chamadas LLM quantos forem os blocos de texto independentes relevantes. Outra estratégia é preencher o Prompt com tantos blocos de texto quanto possível em cada chamada LLM. Se um Prompt não puder ser preenchido, use operações semelhantes para construir vários Prompts. A mesma estratégia de correção de resposta da anterior pode ser usada para múltiplas chamadas de Prompt.
Responder para gerar modelo de prompt
Abaixo está um modelo de prompt fornecido no LlamaIndex para gerar uma resposta. Como você pode ver neste modelo, você pode usar alguns delimitadores (como ------) para distinguir o texto das informações relevantes. Você também pode especificar se o LLM precisa combinar seu próprio conhecimento para gerar uma resposta e quando fornecendo informações relevantes. Se não ajudar, você quer responder ou não?
template = f'''
Context information is below.
---------------------
{
context_str}
---------------------
Using both the context information and also using your own knowledge, answer the question: {
query_str}
If the context isn't helpful, you can/don’t answer the question on your own.
'''
O modelo de prompt abaixo permite que o LLM revise continuamente as respostas existentes.
template = f'''
The original question is as follows: {
query_str}
We have provided an existing answer: {
existing_answer}
We have the opportunity to refine the existing answer (only if needed) with some more context below.
------------
{
context_str}
------------
Using both the new context and your own knowledege, update or repeat the existing answer.
'''
Estudos de caso e aplicações
Plug-in de pesquisa ChatGPT
Plugin de recuperação ChatGPT O plug-in de recuperação ChatGPT [33] é um exemplo dado oficialmente pela OpenAI para aprimorar o LLM por meio de recuperação. Ele é uma maneira de o ChatGPT acessar conhecimento privado. Ele recebeu muita atenção no armazém de código aberto no Github em um curto espaço de tempo. período de tempo. . A seguir está um diagrama esquemático do princípio interno do plug-in de recuperação ChatGPT ( fonte da imagem: openai-chatgpt-retrieval-plugin-and-postgresql-on-azure [34] ).
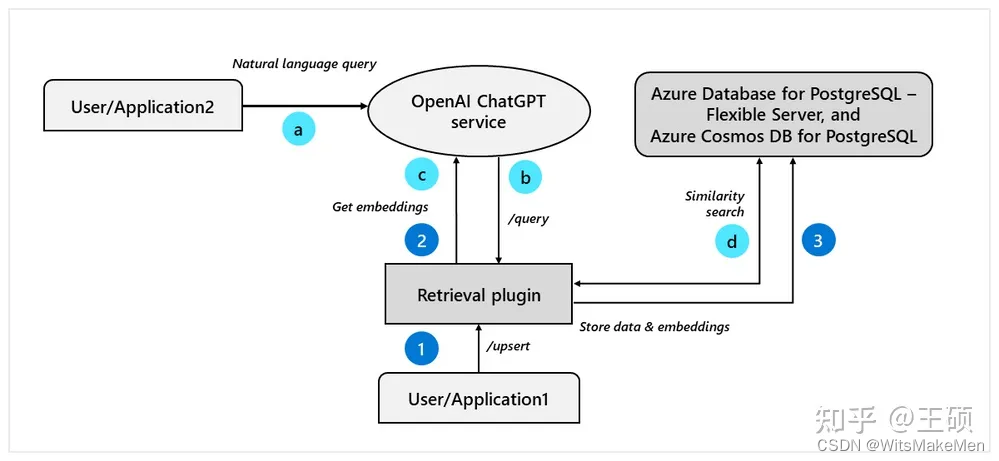
Em termos de design de interface API, o plug-in de pesquisa fornece as seguintes interfaces:
/upsert: Esta interface primeiro divide um ou mais documentos de texto carregados em blocos de texto, cada bloco de texto tem 200 tokens de tamanho, depois usa o modelo de incorporação de texto da OpenAI para converter os blocos de texto em vetores e, finalmente, junto com o texto original e meta informações armazenadas em um banco de dados vetorial, o repositório de código implementa suporte para quase todos os bancos de dados vetoriais convencionais./upsert-file: Esta interface permite o upload de um único arquivo nos formatos PDF, TXT, DOCX, PPTX e MD. Após a primeira conversão em texto simples, o processo de processamento subsequente é o mesmo da/upsertinterface./query: Esta interface implementa uma determinada consulta e retorna os blocos de texto mais relevantes para a consulta. O princípio de implementação também é baseado na recuperação de vetores semelhantes.filterOs usuários podem filtrar documentos por meio do parâmetro na solicitação etop_kespecificar o número de blocos de texto relevantes a serem retornados por meio do parâmetro./delete: Esta interface implementa a operação de exclusão de um ou mais documentos do banco de dados vetorial.
LlamaIndex e LangChain
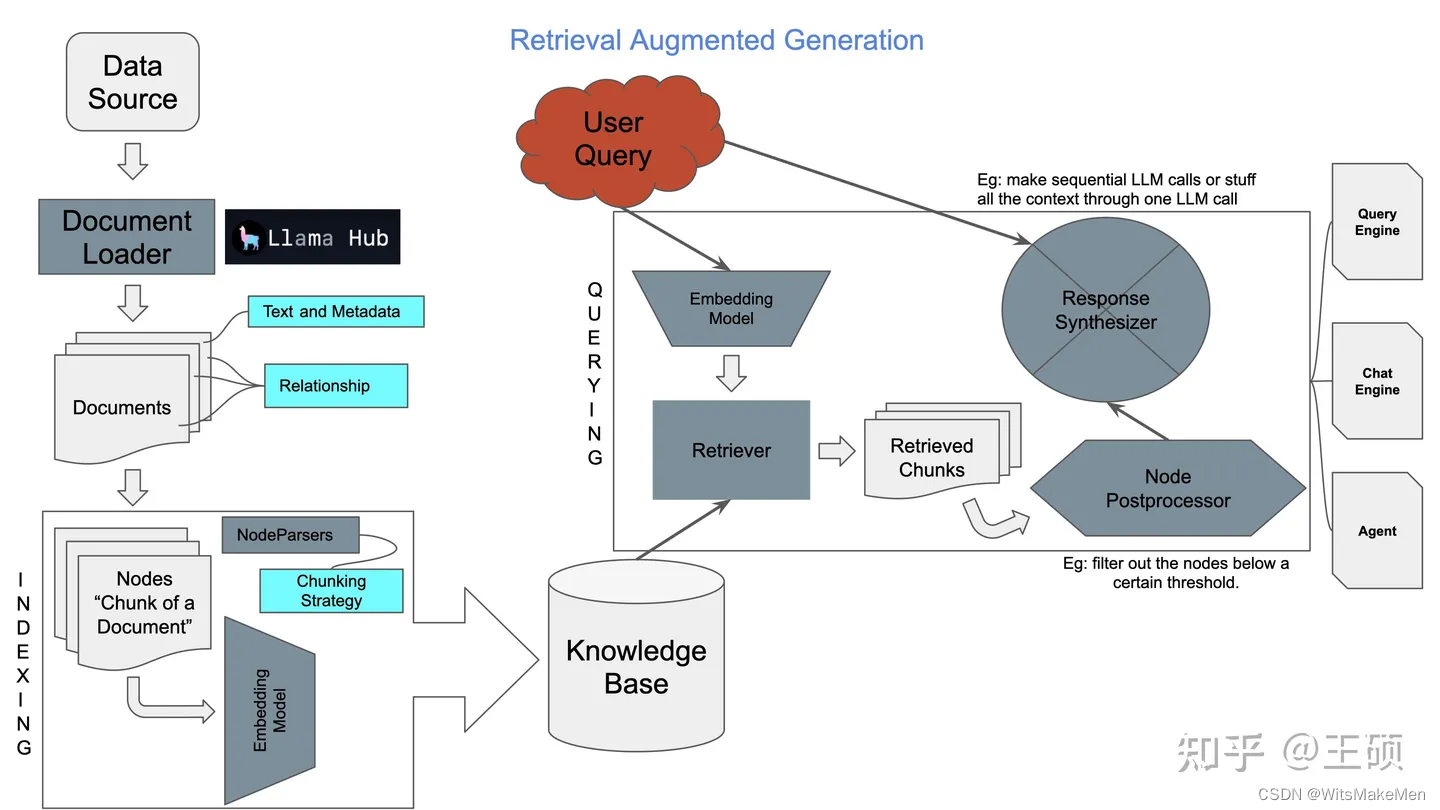
LlamaIndex [35] é uma estrutura de dados que atende aplicações LLM, fornecendo funções como importação, estruturação, indexação e consulta de fontes de dados externas. Grande parte da estrutura e do conteúdo deste artigo é baseada na documentação do LlamaIndex, que é mencionado no artigo.LlamaIndex basicamente possui implementações correspondentes para muitos dos módulos, algoritmos e estratégias mencionados e fornece APIs relevantes de alto e baixo nível.
LlamaIndex inclui principalmente os seguintes componentes e recursos:
- Conector de dados: pode importar dados de múltiplas fontes de dados.Existe um projeto especial Llama Hub [36] que pode conectar dados de múltiplas fontes.
- Índice de dados: suporta vários índices diferentes para leitura de dados para facilitar a recuperação posterior.
- Mecanismo de consulta e diálogo: suporta mecanismo de interação de consulta de rodada única e mecanismo de interação de diálogo de rodada múltipla
- Integração de aplicativos: pode ser facilmente integrado com alguns aplicativos populares, como ChatGPT, LangChain, Flask, Docker, etc.
A seguir está um diagrama esquemático da estrutura geral do LlamaIndex.
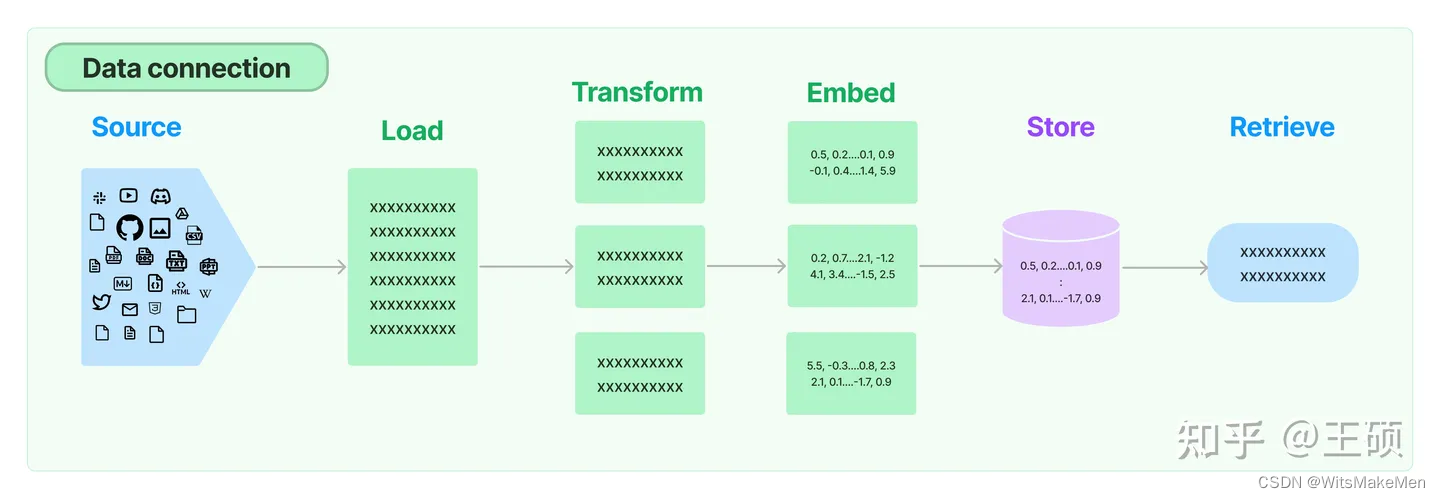
Além do LlamaIndex, LangChain [37] também é uma estrutura de desenvolvimento de aplicativos LLM atualmente popular, que também contém alguns componentes relacionados para LLM aprimorado por recuperação.No entanto, em comparação, o LlamaIndex se concentra mais no campo relativamente pequeno de LLM aprimorado por recuperação. LangChain cobre uma gama mais ampla de áreas, como aplicações em cadeia de LLM, criação e gerenciamento de Agentes, etc. A imagem abaixo é um diagrama esquemático do processo geral do módulo Retrieval [38] no LangChain, incluindo carregamento de dados, transformação, incorporação, armazenamento de vetores e recuperação. O fluxo geral de processamento é o mesmo do LlamaIndex.
Análise do copiloto do Github
Github Copilot [39] é uma ferramenta de programação assistida por IA. Se você o usou, descobrirá que o Github Copilot pode ajudar os usuários a gerar ou completar automaticamente o código com base no contexto do código. Às vezes, você pode apenas anotar o nome da classe ou da função, ou depois de escrever o comentário da função, o Copilot irá te damos o código gerado, e muitas vezes pode ser o código que queremos implementar. Como o Github Copilot não é de código aberto, algumas pessoas na Internet conduziram análises de engenharia reversa de seu plug-in VSCode, como copilot internals [40] e copilot analysis [41] , para que possamos ter uma compreensão geral do Copilot interno implementação. Simplificando, o plug-in Github Copilot coletará várias informações contextuais do usuário no ambiente de programação VSCode para construir um Prompt e, em seguida, enviará o Prompt construído para o modelo de geração de código (como Codex) para obter o código completo e exibi-lo no editor.meio. Como recuperar informações de contexto relevantes (Contexto) é um link muito importante. Github Copilot é uma aplicação de LLM aprimorada por pesquisa na direção de programação assistida por IA.
Deve-se observar que as duas análises reversas mencionadas acima foram feitas há alguns meses. O Github Copilpot pode ter feito muitas atualizações e iterações. Além disso, a análise foi obtida pelo autor original após ler e compreender o código reverso, então pode ser que haja alguns desvios de compreensão. O conteúdo a seguir foi gerado por mim combinando essas duas análises, portanto, alguns lugares podem ser imprecisos ou até errados, mas isso não nos impede de usar o exemplo do Copilot para compreender a importância da informação contextual na melhoria dos resultados da produção do LLM e para aprender algumas idéias práticas para recuperação de informações sensíveis ao contexto.
A seguir está um exemplo de prompt. Você pode ver que ele contém informações de código de prefixo (prefix), informações de código de sufixo (suffix), modo de geração (isFimEnabled) e informações de posição inicial de diferentes elementos do prompt (promptElementRanges).

Independentemente do efeito do modelo de geração de código em si, a qualidade da construção do Prompt afetará em grande parte o efeito da conclusão do código, e a extração e composição de informações relacionadas ao contexto (Contexto) determinará em grande parte a qualidade da construção do Prompt. Vamos dar uma olhada em algumas ideias-chave e implementações de extração de informações relacionadas ao contexto na construção Prompt do Github Copilot.
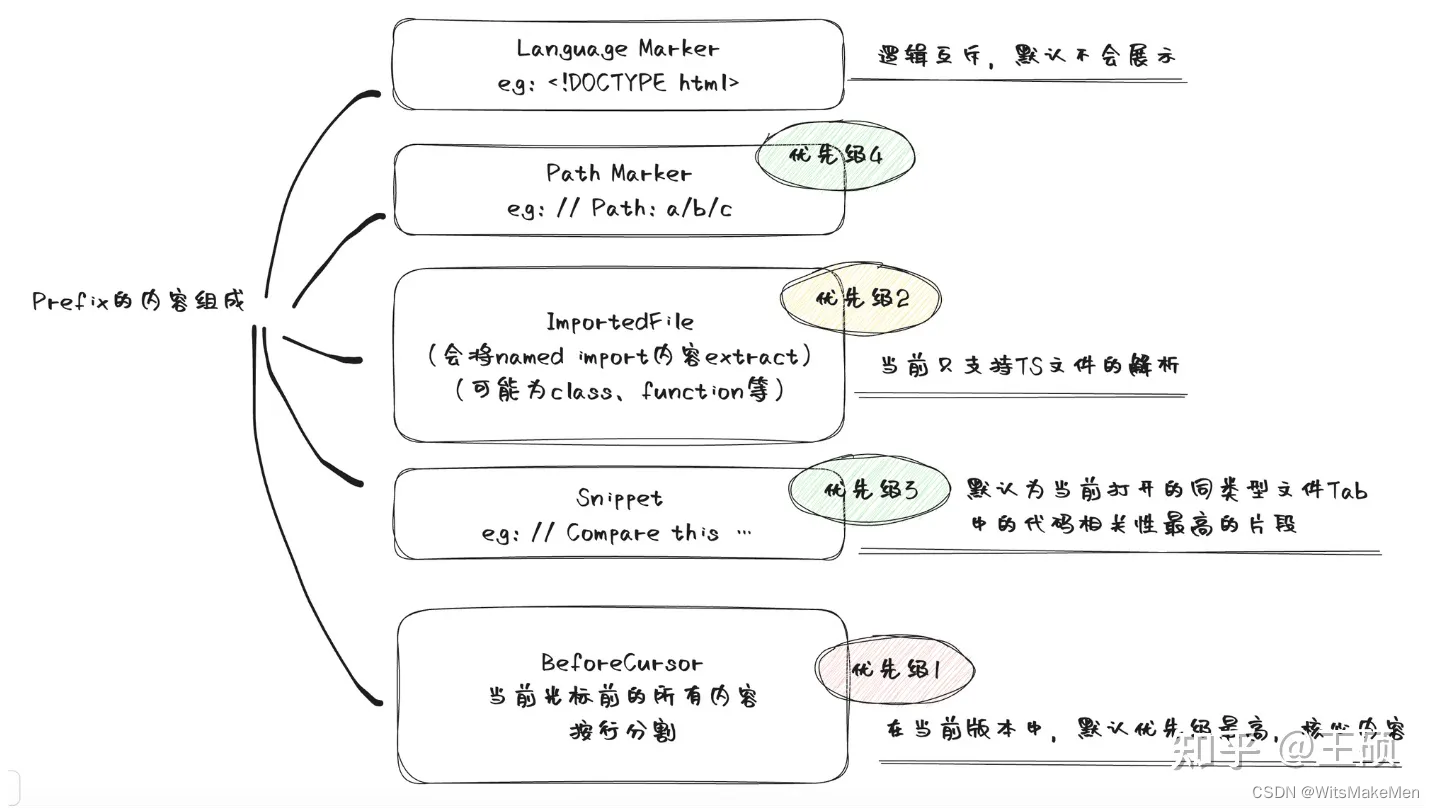
O Prompt do Copilot contém diferentes tipos de informações relacionadas, incluindo
BeforeCursor: Conteúdo antes do cursorAfterCursor: Conteúdo após o cursorSimilarFile: trechos de código altamente semelhantes ao arquivo atualImportedFile:importar dependênciaLanguageMarker: Tag de idioma no início do arquivoPathMarker: Informações relativas do caminho do arquivo
Para extrair trechos de código semelhantes, vários arquivos acessados recentemente no mesmo idioma serão primeiro obtidos como documentos candidatos para extrair trechos de código semelhantes. Em seguida, defina o tamanho da janela (por exemplo, o padrão é 60 linhas) e o tamanho do passo (por exemplo, o padrão é 1 linha) e divida os documentos candidatos em blocos de código em uma janela deslizante. Em seguida, calcule a similaridade entre cada bloco de código segmentado e o arquivo atual e, finalmente, retenha vários blocos de código com maior similaridade. Aqui, o arquivo atual é obtido interceptando o conteúdo do tamanho da janela do cursor atual para frente. A medida de similaridade usa o coeficiente de Jaccard . Especificamente, cada linha no bloco de código é segmentada e palavras-chave de código comuns são filtradas (como se, então, caso contrário, para estes), obtenha um conjunto de tokens (Token) e então você pode calcular a similaridade de Jaccard entre o conjunto de tokens do bloco de código atual e o bloco de código candidato. No cenário Copilot, este método de cálculo de similaridade é simples e eficaz.
J ( A , B ) = ∣ A ∩ B ∣ ∣ A ∪ B ∣ = ∣ A ∩ B ∣ ∣ A ∣ + ∣ B ∣ − ∣ A ∩ B ∣ J(A, B) = \frac{|A \cap B|}{|A \cup B|} = \frac{|A \cap B|}{|A| + |B| - |A \cap B|}J ( A ,B )=∣ UMA∪B ∣∣ UMA∩B∣ _=∣ UMA ∣+∣ B ∣-∣ UMA∩B ∣∣ UMA∩B∣ _
O artigo de análise acima resume a composição do Prompt na imagem a seguir.
Após construir o Prompt, o Copilot também determinará se é necessário iniciar uma solicitação. O cálculo do modelo de geração de código é muito intensivo em termos computacionais, por isso é necessário filtrar algumas solicitações desnecessárias. Um dos julgamentos é usar um modelo de regressão linear simples para pontuar o prompt. Quando a pontuação for inferior a um determinado limite, a solicitação não será enviada. Este modelo de regressão linear utiliza recursos como linguagem de código, se a última sugestão de conclusão de código foi aceita ou rejeitada, o período de tempo desde que a última sugestão de conclusão de código foi aceita ou rejeitada, o caractere à esquerda do cursor, etc. Ao analisar os pesos do modelo, o autor original fez algumas observações:
- Algumas linguagens de programação têm peso maior que outras linguagens (php > js > python > ferrugem > ...), e PHP tem peso maior. Com certeza, PHP é a melhor linguagem do mundo ( _ ).
- É lógico que o meio colchete direito (por exemplo
), , ) tenha menos peso que o meio colchete esquerdo.]
Através da análise do Github Copilot, um auxílio de programação, podemos perceber:
- Idéias e tecnologias de LLM aprimoradas para recuperação desempenham um papel importante na implementação do Github Copilot
- As informações relacionadas ao contexto (Contexto) podem ser um conceito amplo, podem ser textos relacionados ou fragmentos de código, ou podem ser caminhos de arquivos, dependências relacionadas, etc. Cada cenário pode definir seus elementos de contexto específicos.
- A medição de similaridade e o método de recuperação semelhante podem variar dependendo do cenário. Nem todos os cenários precisam usar similaridade de cosseno. Todos eles precisam encontrar documentos relevantes por meio da recuperação de similaridade vetorial. Por exemplo, na implementação do Copilot, um simples coeficiente de Jaccard é usado.Calcular a similaridade de conjuntos de tokens após a segmentação de palavras é simples e eficiente.
Pesquisa e perguntas e respostas para documentos e bases de conhecimento
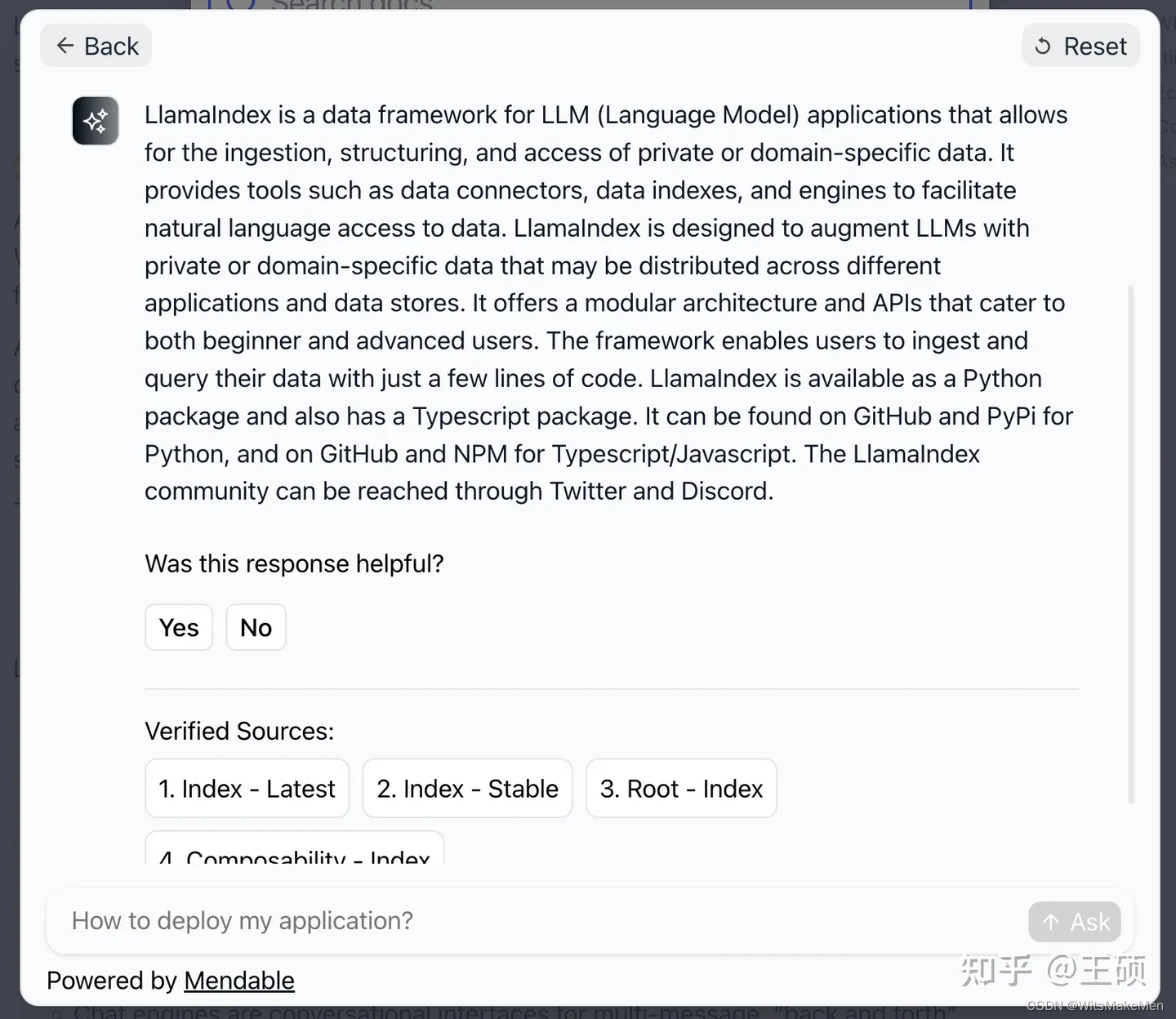
Uma aplicação típica da tecnologia LLM aprimorada de recuperação é a base de conhecimento ou perguntas e respostas de documentos, como recuperação e perguntas e respostas para a base de conhecimento interna de uma empresa ou alguns documentos. Atualmente existem muitos produtos comerciais e de código aberto nesta direção de aplicação. Por exemplo, Mendable [42] é um produto comercial que pode fornecer recuperação de IA baseada em documentos e recursos de perguntas e respostas. Os recursos de recuperação dos documentos oficiais do projeto LlamaIndex e LangChain mencionados acima são fornecidos pela Mendable. Abaixo está uma captura de tela do uso. Você pode ver que Mendable não apenas fornecerá respostas geradas, mas também anexará links de referência.
Além dos produtos comerciais, também existem muitos produtos similares de código aberto. por exemplo
- Danswer [43] : Fornece uma função de perguntas e respostas para documentos corporativos internos, pode importar dados de múltiplas fontes, suporta recuperação tradicional e perguntas e respostas baseadas em LLM e pode identificar de forma inteligente as intenções de pesquisa dos usuários, adotando assim diferentes estratégias de recuperação para apoiar gerenciamento de usuários e direitos de documentos, bem como suporte para implantação do Docker, etc.
- PandaGPT [44] : Oferece suporte aos usuários para fazer upload de arquivos e depois fazer perguntas sobre o conteúdo do arquivo
- FastGPT [45] : Uma plataforma de perguntas e respostas de base de conhecimento de IA baseada em LLM de código aberto
- Quivr [46] : Este projeto de código aberto permite aos usuários pesquisar e questionar arquivos pessoais ou bases de conhecimento, na esperança de se tornar o “segundo cérebro” do usuário
- ChatFiles [47] : Outro projeto de código aberto de perguntas e respostas de documentos baseado em LLM
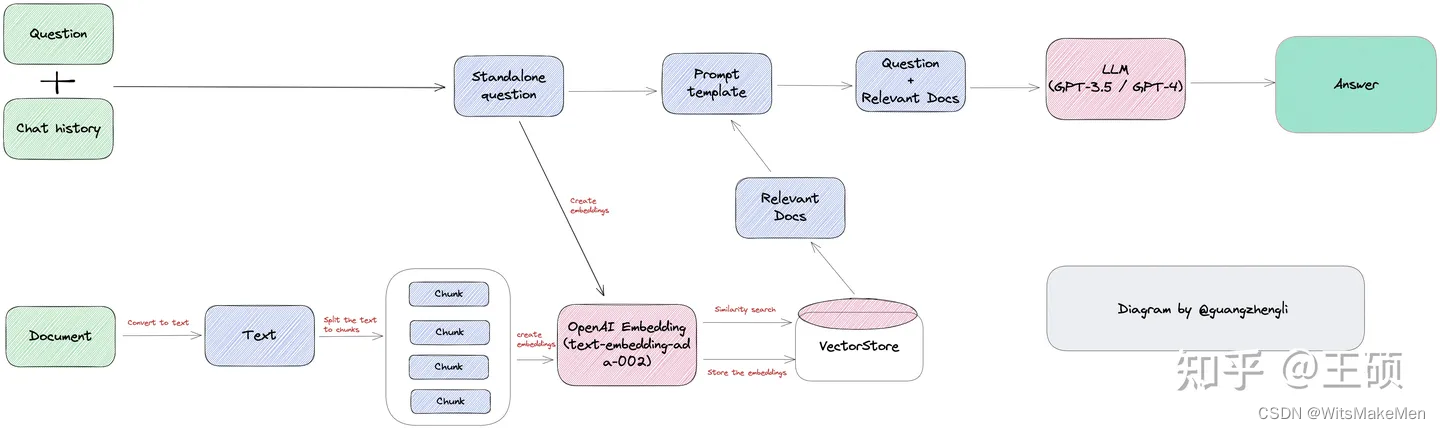
A imagem abaixo é o diagrama da arquitetura técnica do projeto ChatFiles. Pode-se descobrir que os módulos básicos e a arquitetura de tais projetos são muito semelhantes. Eles basicamente seguem a ideia de LLM aprimorado para recuperação. Este tipo de base de conhecimento o aplicativo de perguntas e respostas quase se tornou o aplicativo Hello World no campo LLM .
referência
[1] Alucinações: https://machinelearningmastery.com/a-gentle-introduction-to-hallucinations-in-large-language-models/
[2] Um guia para recuperação de LLM aumentado: https://github.com/Wang -Shuo/A-Guide-to-Retrieval-Augmented-LLM
[3] Estado do GPT: https://www.youtube.com/watch?v=bZQun8Y4L2A&ab_channel=MicrosoftDeveloper
[4] A nova pilha de modelos de linguagem: https:/ /www.sequoiacap.com/article/llm-stack-perspective/
[5] Arquiteturas emergentes para aplicativos LLM: https://a16z.com/emerging-architectures-for-llm-applications/
[6] Tutorial ACL 2023: recuperação Modelos de linguagem e aplicativos baseados em: https://acl2023-retrieval-lm.github.io/
[7] Grandes modelos de linguagem lutam para aprender conhecimento de cauda longa: https://arxiv.org/abs/2211.08411
[8] Extraindo dados de treinamento de grandes modelos de linguagem: https://arxiv.org/abs/2012.07805
[9] 100K: https://www.anthropic.com/index/100k-context-windows
[10] Perdido no Meio: https://arxiv.org/pdf/2307.03172.pdf
[11] Estratégias de chunking para aplicativos LLM: https://www.pinecone.io/learn/chunking-strategies/
[12] LangChain: https://python .langchain.com/docs/modules/data_connection/document_transformers/
[13] Como funciona cada índice: https://gpt-index.readthedocs.io/en/latest/core_modules/data_modules/index/index_guide.html
[14] Frase Transformadores: https://arxiv.org/abs/1908.10084
[15] text-embedding-ada-002: https://openai.com/blog/new-and-improved-embedding-model
[16] Instrutor: https: //instructor-embedding.github.io/
[17] BGE: https://github.com/FlagOpen/FlagEmbedding/blob/master/README_zh.md
[18] Tabela de classificação MTEB: https://huggingface.co/spaces/mteb/leaderboard
[19] Você realmente precisa um banco de dados vetorial: https://www.ethanrosenthal.com/2023/04/10/nn-vs-ann/
[20] Hnswlib: https://github.com/nmslib/hnswlib
[21] Faiss: https:/ /github.com/facebookresearch/faiss
[22] Índices de vizinhos mais próximos para pesquisa de similaridade: https://www.pinecone.io/learn/series/faiss/vector-indexes/
[23] Pinha: https://www.pinecone .io/
[24] Vespa: https://vespa.ai/
[25] Weaviate: https://weaviate.io/
[26] Milvus: https://milvus.io/
[27] Croma: https:/ /www.trychroma.com/
[28] Tencent Cloud VectorDB: https://cloud.tencent.com/product/vdb
[29] O que é um banco de dados vetorial: https://www.pinecone.io/learn/vector-database/
[30] auto-pergunta: https://ofir.io/self-ask.pdf
[31] ReAct: https://arxiv.org/abs/2210.03629
[32] HyDE: http://boston.lti.cs.cmu.edu/luyug/HyDE/HyDE.pdf
[33] Plug-in de recuperação ChatGPT: https://github. com/openai/chatgpt-retrieval-plugin
[34] Traduzido: openai-chatgpt-retrieval-plugin-and-postgresql-on-azure: https://techcommunity.microsoft.com/t5/azure-database-for-postgresql /openai-chatgpt-retrieval-plugin-and-postgresql-on-azure/ba-p/3826411
[35] LlamaIndex: https://gpt-index.readthedocs.io/en/latest/index.html#
[36] Lhama Hub: https://llamahub.ai/
[37] LangChain: https://python.langchain.com/docs/get_started/introduction.html
[38] Recuperação: https://python.langchain.com/docs/modules/data_connection/
[39] Copiloto do Github: https://github.com/features/copilot
[40] internos do copiloto: https://thakkarparth007. github.io/copilot-explorer/posts/copilot-internals
[41] análise de copiloto: https://github.com/mengjian-github/copilot-análise
[42] Mendável: https://www.mendable.ai/
[ 43] Dresposta: https://github.com/danswer-ai/danswer
[44] PandaGPT: https://www.pandagpt.io/
[45] FastGPT: https://fastgpt.run/
[46] Quivr: https://github.com/StanGirard/quivr
[47] ChatFiles: https://github.com/guangzhengli/ChatFiles
[48] Full stack LLM Bootcamp: Modelos de linguagem aumentada: https://fullstackdeeplearning.com