introdução
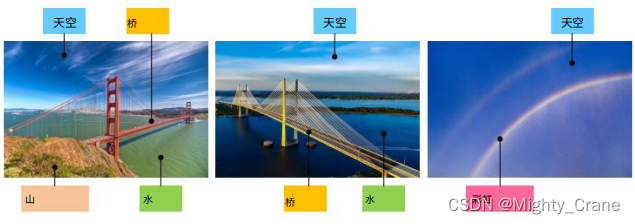
O hashing tradicional existente é considerado contanto que pelo menos uma tag corresponda, portanto, no exemplo mostrado na figura, ab e ac são considerados correspondentes, o que torna impossível para top1 classificar a semelhança de pares multi-rótulo, portanto,
o semântica mantida por cada imagem Os rótulos propõem uma definição suave de similaridade de pares. Especificamente, as semelhanças aos pares são quantificadas como porcentagens usando rótulos semânticos normalizados. (contribuição: 1)
Assim, duas similaridades são propostas. A similaridade rígida considera que todos os rótulos combinam, então o aprendizado de entropia cruzada é usado; a similaridade suave considera a correspondência parcial de rótulos, então o erro quadrático médio é usado (contribuição 2)
Trabalho relatado
Uma abordagem simples para o aprendizado profundo de hash é limitar diretamente os recursos de alto nível, tipificados por DLBHC [46], que aprende a representação de hash de classe. Embora a rede esteja bem ajustada na tarefa de classificação, os recursos da camada de hash latente
são considerados discriminativos, o que de fato mostra melhor desempenho do que os recursos artesanais.(也就是说deephash比特征工程好,但相比起直接deep,直接Alexnet或者传统hash效果咋样呢)
Para recuperação multi-rótulo, DSRH [25] tenta utilizar a informação de classificação de similaridades multi-nível para aprender uma função hash e propõe uma perda de proxy para resolver o problema de otimização de medidas de classificação. O IAH [47] se concentra no aprendizado de representações de imagens com reconhecimento de instância e usa uma perda de tripleto ponderada para manter classificações de similaridade para imagens com vários rótulos. No entanto, as funções de perda de tripleto ponderadas empregadas por DSRH [25] e IAH [47] não impõem restrições diretas ao aprendizado de similaridade semântica multinível refinada , uma vez que se concentram em manter a classificação correta das imagens de acordo com sua semelhança com o consulta(也就是说一直在纠结于损失函数,而没有针对多标签相似度的痛点来解决问题吧)
Com base nisso, DMSSPH [48] tenta construir uma função hash para maximizar a discriminabilidade do espaço de saída a fim de preservar a similaridade multinível entre imagens multirótulo. Embora o DMSSPH [48] tenha explorado a similaridade semântica multinível refinada para o aprendizado de similaridade pairwise, ainda há espaço para mais explorações. Uma nova e eficaz abordagem TALR é proposta em [36], que considera classificações limitadas sobre distâncias de Hamming de valor inteiro e otimiza diretamente as métricas de avaliação baseadas em classificação Precisão Média (MAP) [49] e Ganho Cumulativo Descontado Normalizado (NDCG) [50 ]. Ele atinge alto desempenho em vários conjuntos de dados de referência. Em [51], dois novos protocolos para avaliar métodos de hashing supervisionados são propostos no contexto de aprendizado por transferência.
Neste artigo, exploramos a diversidade de semelhança semântica pairwise em conjuntos de dados multi-rótulo para melhorar a qualidade do hash. Especificamente, os valores de similaridade pairwise refinados são definidos de forma contínua (将离散的汉明距离改成连续值?). Assim, a similaridade pairwise é dividida em dois casos, e uma função de perda pairwise conjunta é construída para executar simultaneamente o aprendizado de recursos e a geração de código hash.
método
Para examinar a similaridade multi-rótulo, o rótulo quantitativo é uma porcentagem de valor contínuo, ou seja, a semelhança de cosseno dos vetores de rótulo semântico das duas imagens (este artigo é o primeiro a usar a distância do cosseno para quantificar a similaridade semântica granulada de imagens emparelhadas)
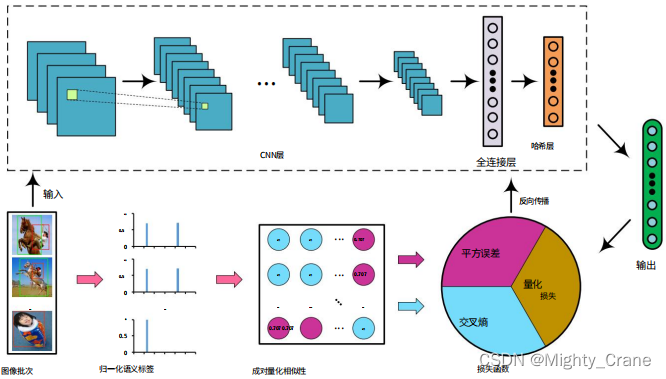
A imagem passa pelo Alexnet e a saída da camada fc8 final é mapeada para (-1,1) por meio da seguinte função de ativação(提到本文的Alexnet是可以随意替换成vgg、Googlenet等,所以为啥这俩更新的网络不如初号机有啥说道吗)
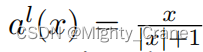
semelhança difícil
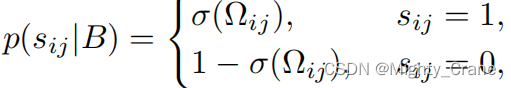
onde Ω é o produto interno dos dois códigos hash
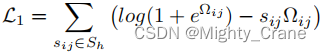
semelhança suave
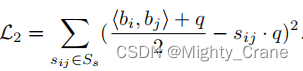
aprendizagem conjunta
Para aprender os dois casos simultaneamente e formar uma forma unificada, Mij é usado para rotular os dois casos, onde Mij = 1 indica o caso de "semelhança rígida" e Mij = 0 indica o caso de "semelhança suave". Portanto, a perda de similaridade pairwise é reescrita como:(这不其实就是那俩损失函数结合嘛)
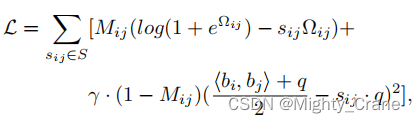
A otimização direta da equação é um desafio. Como a restrição binária bi ∈ {−1, 1} q requer o limite da saída da rede, isso pode levar a um problema de gradiente de desaparecimento na retropropagação durante o treinamento.
Perda de quantização escalonada em pares

A perda final é C = L + λQ
experimentar
Desempenho
Ganho cumulativo médio (ACG) [60],
ganho cumulativo descontado normalizado (NDCG) [50], média
Precisão Média (MAP) [49] e Precisão Média Ponderada (WAP) [25].
Em relação à função de perda de hash, ela mapeia dados de alta dimensão para códigos binários de baixa dimensão para melhorar a velocidade e a eficiência da recuperação de dados.
A entrada consiste em quatro parâmetros:
D: Representa a matriz de autovetores da amostra, com formato(batch_size, feature_dim).label: Representa a matriz do vetor rótulo da amostra, a forma é(batch_size, num_class), ondenum_classrepresenta o número de categorias.alpha,beltaegama: representam os coeficientes de peso dos três itens de perda.m: Indica o comprimento do código hash.
Especificamente, essa função de perda de hash consiste em três partes: perda de similaridade de cosseno , restrição de comprimento de código hash e termo de regularização . Entre eles, a perda de similaridade de cosseno pode corresponder ao código hash comparando a similaridade de cosseno entre os pares de amostra,
primeiro calcule a matriz de similaridade de cosseno do rótulo
label_count = tf.expand_dims(tf.sqrt(tf.reduce_sum(tf.square(label), 1)),1)
# 标签向量的模长
norm_label = label/tf.tile(label_count,[1,args.num_class])
# 标签向量的单位向量
w_label = tf.matmul(norm_label, norm_label, False, True)
# 标签向量之间的余弦相似度矩阵
semi_label = tf.where(w_label>0.99, w_label-w_label,w_label)
# 将大于阈值0.99的相似度设置为0后的相似度矩阵
Em seguida, calcule a similaridade do cosseno das amostras
p2_distance = tf.matmul(D, D, False, True)
A restrição de comprimento do código hash pode garantir que o comprimento do código hash não exceda o valor especificado. Na implementação, precisamos calcular o código hash da amostra e compará-lo com o comprimento do código hash especificado para obter a perda de restrição de comprimento do código hash.
scale_distance = belta * p2_distance / m
# 对距离矩阵进行缩放后的值
temp = tf.log(1+tf.exp(scale_distance))
loss = tf.where(semi_label<0.01,temp - w_label * scale_distance, gama*m*tf.square((p2_distance+m)/2/m-w_label))
regularizer = tf.reduce_mean(tf.abs(tf.abs(D) - 1))
d_loss = tf.reduce_mean(loss) + alpha * regularizer
Dessa forma, a restrição de comprimento do código hash C=L+αQ no artigo pode garantir que o comprimento do código hash não exceda o valor especificado, e o termo de regularização pode ajudar o modelo a evitar o overfitting.
A saída dessa função consiste em dois valores:
d_loss: Indica o valor total da perda de hash.w_label: Representa a matriz de similaridade de cossenos entre tags, com formato(batch_size, batch_size).
Na implementação da função, os rótulos de amostra são primeiro padronizados e, em seguida, a matriz de semelhança de cosseno entre os rótulos é calculada e a similaridade maior que o limite é definida como 0. Em seguida, calcule a matriz de semelhança de cosseno entre as amostras e mapeie a matriz de distância para um intervalo de valores entre 0 e 1. Finalmente, três itens de perda são calculados e sua soma ponderada é tomada como o valor total de perda de hash.
principal
A função desse código é ler os dados no arquivo tfrecord, construir o modelo AlexNet, calcular a perda de hash ( d_loss) e usar o otimizador para treinamento.
Especificamente, primeiro reader.read_and_decodeleia os dados do arquivo tfrecord por meio da função (这个在tf2版本里要大改了,需要换成data相关函数), e obtenha um conjunto de imagens ( img) e seus rótulos correspondentes ( label). Em seguida, use tf.train.shuffle_batcha função para embaralhar as imagens e rótulos lidos para formar um args.batch_sizelote de tamanho , que é usado para treinar o modelo.
Em seguida, use AlexNeta função para construir o modelo AlexNet e pegue os dados da imagem no lote como entrada e obtenha uma saída D. Esta saída contém o código hash correspondente a cada imagem.(哈希码的维度由num_bits控制)
Em seguida, use hashing_lossa função para calcular a perda de hash e use o valor de saída De o valor do rótulo label_batchcomo parâmetros de entrada. Entre eles, args.alpha, args.beltae args.gamaestão os hiperparâmetros, que controlam o peso da perda de similaridade, a restrição de comprimento do código hash e o termo de regularização, respectivamente.
Finalmente, a perda de hash calculada ( d_loss) e a saída do modelo ( out) são retornadas.
Em seguida, otimize o processo de treinamento:
- De acordo com os skip_layers especificados, todas as variáveis treináveis são divididas em duas categorias: var_list1 e var_list2. Entre eles, var_list1 inclui todas as variáveis que precisam de ajuste fino e var_list2 inclui todas as variáveis que precisam ser treinadas do zero.
- Defina learning_rate e defina o declínio exponencial.
- Defina dois otimizadores Adam: opt1 e opt2. Entre elas, a taxa de aprendizado de opt1 é learning_rate*0.01, que é usada para otimizar as variáveis em var_list1; a taxa de aprendizado de opt2 é learning_rate, que é usada para otimizar as variáveis em var_list2.
- Calcula as graduações de gradiente para todas as variáveis e divide as graduações em duas partes: grads1 e grads2 de acordo com var_list1 e var_list2.
- Use opt1 e opt2 para otimizar os gradientes em grads1 e grads2, respectivamente, e atualize global_step.
- Combine as operações de atualização dos dois otimizadores em um train_op.
Portanto, o processo de treinamento de todo o modelo é realizado e os gradientes dos dois tipos de variáveis são atualizados por meio de diferentes otimizadores, realizando assim dois métodos de treinamento diferentes de ajuste fino e treinamento do zero.
No loop de treinamento, o Node no gráfico de cálculo do TensorFlow (Graph) é executado por meio do objeto de sessão (Session).
Primeiro, um objeto Saver é definido para salvar o modelo treinado. Em seguida, use sess.runo método para inicializar variáveis globais e locais e para carregar os pesos de modelo pré-treinados na rede. Em seguida, inicie o encadeamento da fila do conjunto de dados (这个应该只能用在tf1中,tf2就尬住了)e insira o loop de treinamento.
No loop de treinamento, sess.runtrês nós são executados através do método, a saber train_op(nó de treinamento), d_loss(nó de perda) e global_step(nó de etapas globais). Entre eles, train_opestá o nó da operação que aplica o gradiente calculado à variável, e o valor de retorno é Nenhum; d_lossé o nó que calcula a perda, e o valor de retorno é um escalar; global_stepé uma variável, e seu valor é aumentado por um toda vez que o nó de treinamento é executado.
Durante o processo de treinamento, ele é step1 % 10 == 0controlado por informações de treinamento de saída a cada 10 iterações, incluindo o número de iteração atual (step1), valor de perda (loss_t) e demorado (elapsed_time). Use para controlar o salvamento do modelo step1 % args.save_freq == 0a cada iteração . args.save_freqQuando todas as amostras no conjunto de dados forem percorridas, o treinamento termina. Por fim, interrompa o encadeamento da fila e saia da sessão.
Em relação ao alexnet, o método de convolução é semelhante ao caffe. Quando os grupos são iguais a 1, a operação de convolução é realizada diretamente; quando os grupos são maiores que 1, a entrada e o kernel de convolução são agrupados de acordo com o número de grupos e a operação de convolução é realizada separadamente e, finalmente, o resultado é combinado. Os resultados finais da saída são processados por polarização, ativação ReLU, etc. (grupos: o número de grupos para convolução de grupo, o padrão é 1)