A propósito, este artigo explica principalmente o mecanismo de armazenamento InnoDB.
- classificação de índice
A classificação do índice pode ser classificada a partir de diferentes dimensões
1. De acordo com a estrutura de dados utilizada
-
Índice de árvore B+
-
índice de hash
-
…
2. De acordo com a divisão da estrutura de dados de armazenamento físico real
-
índice agrupado
-
Índice não agrupado (índice secundário)
Índices agrupados e índices não agrupados serão enfatizados posteriormente.
3. Dividido por características do índice
-
índice de chave primária
-
índice único
-
índice normal
-
índice de texto completo
-
…
4. Divida pelo número de campos
-
índice de coluna única
-
índice comum
- estrutura de dados do índice
2.1 preparação
Para explicar melhor o próximo artigo, aqui preparei uma usertabela, e os exemplos de todo o artigo serão explicados com esta tabela
CREATE TABLE `user` (
`id` int(10) NOT NULL AUTO_INCREMENT,
`name` varchar(255) DEFAULT NULL,
`age` int(10) DEFAULT NULL,
`city` varchar(255) DEFAULT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;
2.2 Índice de hash
Os índices de hash não são muito práticos, principalmente porque o InnoDB, o mecanismo de armazenamento mais comum, não oferece suporte à criação explícita de índices de hash, mas apenas a índices de hash adaptativos.
Embora você possa usar a instrução sql para exibir e declarar o índice Hash no InnoDB, na verdade isso não tem efeito

Crie um índice Hash no campo nome, mas você show index from 表名descobrirá que na verdade é uma árvore B +
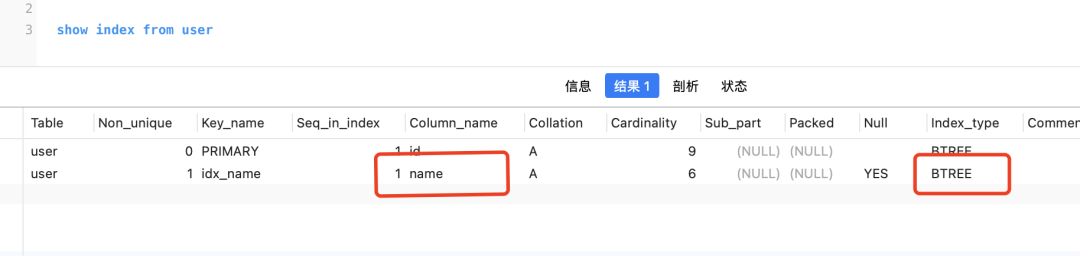
No mecanismo de armazenamento, o mecanismo de memória oferece suporte ao índice Hash
O índice de hash é, na verdade, um pouco como a estrutura de dados subjacente do HashMap em Java. Ele também possui vários slots, que também armazenam pares chave-valor. O valor da chave é a coluna do índice e o valor é o ponteiro da linha dos dados . Você pode encontrá-lo através dos dados do ponteiro de linha
Assumindo que a tabela agora userusa o mecanismo de armazenamento de memória, um índice Hash é estabelecido para o campo de nome e três partes de dados são inseridas na tabela
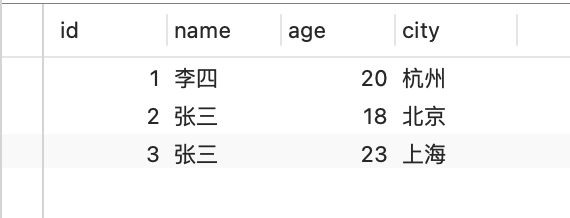
O índice Hash executará o cálculo de Hash no valor do nome da coluna do índice e, em seguida, encontrará o slot correspondente, conforme mostrado na figura a seguir
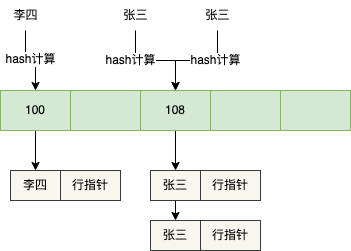
Quando o valor de Hash do campo nome for o mesmo, ou seja, um conflito de Hash, uma lista encadeada será formada, por exemplo, se houver dois dados de nome = Zhang San, uma lista encadeada será formada.
Depois disso, se você quiser verificar os dados de name = Li Si, você só precisa executar o cálculo de Hash em Li Si, encontrar o slot correspondente, percorrer a lista encadeada, retirar o ponteiro da linha correspondente a name = Li Si e em seguida, procure os dados correspondentes de acordo com o ponteiro da linha.
Vantagens e desvantagens do índice de hash
-
O índice de hash só pode ser usado para comparação de igualdade, portanto, a eficiência da consulta é muito alta
-
As consultas de intervalo não são suportadas e a classificação não é suportada porque a distribuição de colunas indexadas é desordenada
2.3 Árvore B+
B + tree é a estrutura de dados mais usada no índice mysql, que não será apresentada aqui, mas será apresentada na próxima seção.
Além do Hash e da árvore B+, existem outros índices como o full-text index, que não serão discutidos aqui
- índice agrupado
3.1 Armazenamento de dados da página de dados
Sabemos que os dados que inserimos na tabela acabarão por ser persistidos no disco. O InnoDB propõe o conceito de páginas para facilitar o gerenciamento desses dados . Ele divide os dados em várias páginas. O tamanho padrão de cada página é 16KB Podemos chamar esta página de página de dados .
Ao inserirmos um dado, os dados serão armazenados na página de dados, conforme a figura abaixo
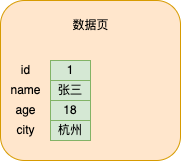
Quando os dados são inseridos continuamente na página de dados, os dados serão classificados de acordo com o tamanho da chave primária (caso contrário, ela será gerada automaticamente) para formar uma lista encadeada unidirecional
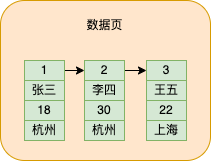
Além de armazenar os dados que inserimos, a página de dados também terá uma parte do espaço para armazenar informações adicionais. Existem muitos tipos de informações adicionais. Vou conhecer uma mais tarde e dizer uma
3.2 Pesquisa de dados para uma única página de dados
Como os dados serão armazenados na página de dados, como verificar os dados da página de dados?
Suponha que agora você precise localizar os dados deste registro com id=2 na página de dados, como localizá-lo rapidamente?
Existe uma maneira estúpida de percorrer a lista encadeada desde o início, julgar se o id é igual a 2 e, se for igual a 2, basta retirar os dados.
Embora esse método seja viável, se uma página de dados armazena muitos dados, dezenas ou centenas de partes de dados, não é muito problemático percorrer dessa maneira todas as vezes
Então o mysql pensou em uma boa forma, que é agrupar esses dados
Supondo que 12 partes de dados sejam armazenadas na página de dados, todo o agrupamento é mais ou menos como mostrado na figura abaixo
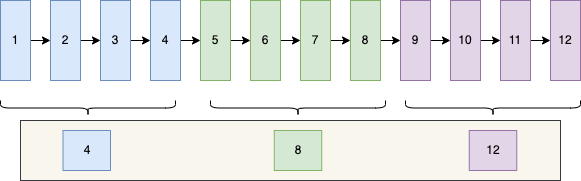
Por conveniência, marquei aqui apenas o valor do id, omitindo os valores dos outros campos
Aqui eu assumo que cada 4 pedaços de dados contam como um grupo, e há 3 grupos na imagem. Depois que o grupo estiver completo, o mysql irá tirar o maior valor de id em cada grupo, que é 4, 8 e 12 em a imagem. Encontre um local na página de dados para salvá-la. Esta é uma das informações adicionais armazenadas na página de dados mencionada acima, que é chamada de diretório da página
Suponha que depois de consultar os dados com id = 6 neste momento, você só precisa pesquisar no diretório da página de acordo com a pesquisa binária e descobrir que está entre 4 e 8. Como 4 e 8 são os maiores ids de seus grupos, então id=6 deve estar no grupo de 8, então vá para o grupo com id=8, percorra cada dado e julgue se o id é igual a 6 ou não.
Como o mysql estipula que o número de itens de dados em cada grupo é de cerca de 4 a 8, deve ser muito mais rápido do que percorrer os dados de toda a página de dados
Na verdade, simplifiquei um pouco a situação de agrupamento acima, mas não atrasa a compreensão
3.3 Pesquisa de dados em várias páginas de dados
Quando inserimos dados continuamente na tabela, o espaço ocupado pelos dados continuará a aumentar, mas o tamanho de uma página de dados é fixo. Quando uma página de dados não pode armazenar dados, uma página de dados será recriada para armazenar dados

Para distinguir cada página, o mysql atribuirá um número de página a cada página de dados, que será armazenado no espaço de armazenamento de informações adicionais. Ao mesmo tempo, as informações adicionais também armazenarão a posição da página de dados anterior e seguinte da página de dados atual, formando assim uma lista de página de dados duplamente encadeada entre
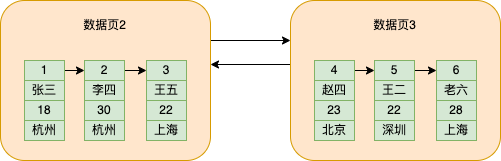
O número da página de dados 2 é 2 e o número da página de dados 3 é 3. Aqui, para facilitar o entendimento, escrevo diretamente o número de páginas de dados.
E o mysql estipula que o valor máximo do id de dados armazenados da página de dados anterior é menor que o valor mínimo do id de dados armazenados da próxima página de dados, para que os dados sejam classificados de acordo com o tamanho do id em todos os dados páginas .
Agora, se houver várias páginas de dados, o que devemos fazer quando precisarmos encontrar os dados com id=5?
Obviamente, o método estúpido acima ainda pode ser usado, ou seja, percorrer a partir da primeira página de dados e, em seguida, percorrer os dados em cada página de dados e, finalmente, encontrar os dados com id=5.
Mas se você pensar bem, esse método estúpido é equivalente a uma varredura completa da tabela, que definitivamente não funcionará.
Então, como otimizá-lo?
A ideia de otimização do mysql é realmente semelhante à ideia de otimização anterior de procurar dados em uma única página de dados
Ele pegará o menor id em cada página de dados e o colocará em outra página de dados separadamente. Esta página de dados não armazena os dados que realmente inserimos, mas apenas armazena o menor id e o número da página de dados onde o id está localizado, como mostrado na figura
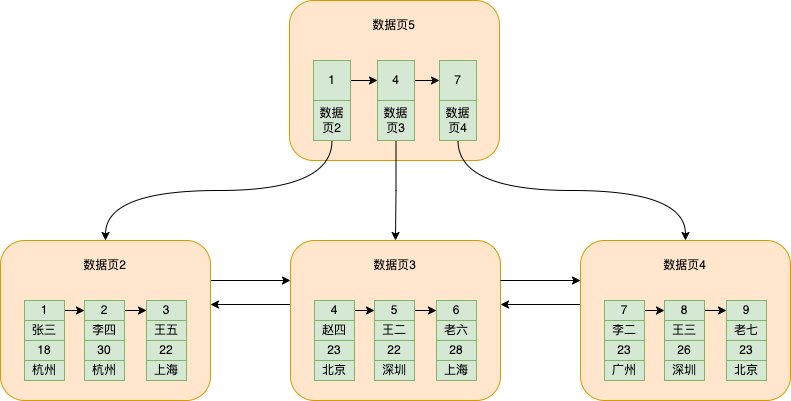
Para tornar a imagem mais completa, adicionei uma página de dados para armazenar dados 4
Neste momento, a página de dados 5 é extraída, que armazena o id mínimo e o número da página de dados correspondente das três páginas de dados a seguir que armazenam dados
É muito conveniente encontrar os dados com id=5 neste momento, divididos aproximadamente nas seguintes etapas:
-
Da página de dados 5 diretamente com base na pesquisa binária, encontrada entre 4-7
-
Como 4 e 7 são os menores ids das páginas de dados, os dados com id=5 devem estar na página de dados com id=4 (porque o menor id da página de dados com id=7 é 7),
-
Em seguida, vá para o número da página de dados 2 correspondente a id=4 para encontrar a página de dados 2
-
Em seguida, pesquise os dados de acordo com o processo de pesquisa em uma única página de dados com base no ID da chave primária dos dados mencionados acima
Dessa forma, é possível encontrar dados entre várias páginas de dados de acordo com o ID da chave primária
3.4 Índice Agrupado
À medida que a quantidade de dados continua a aumentar, o número de páginas de dados que armazenam dados continua a aumentar, e a página de dados 5 conterá mais e mais dados, mas cada página de dados é padronizada para 16k, então a página de dados 5 também será dividida em vários dados situação das páginas, conforme mostrado abaixo
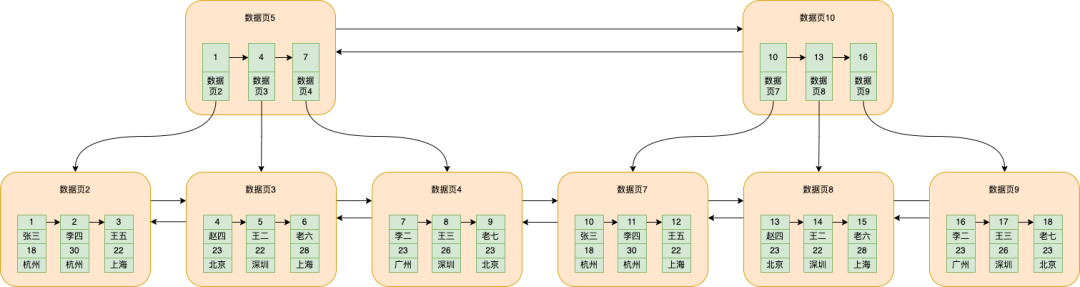
A página de dados 10 funciona da mesma forma que a página de dados 5
Neste momento, se você deseja pesquisar os dados com id = 5, deve ir para a página de dados 5 para pesquisa binária ou ir para a página de dados 10 para pesquisa binária?
A maneira estúpida é percorrer, mas é realmente desnecessário, o mysql irá extrair o id do menor dado armazenado na página de dados 5 e na página de dados 10 e o número da página de dados correspondente, e colocá-los separadamente em uma página de dados, conforme mostrado em a figura abaixo
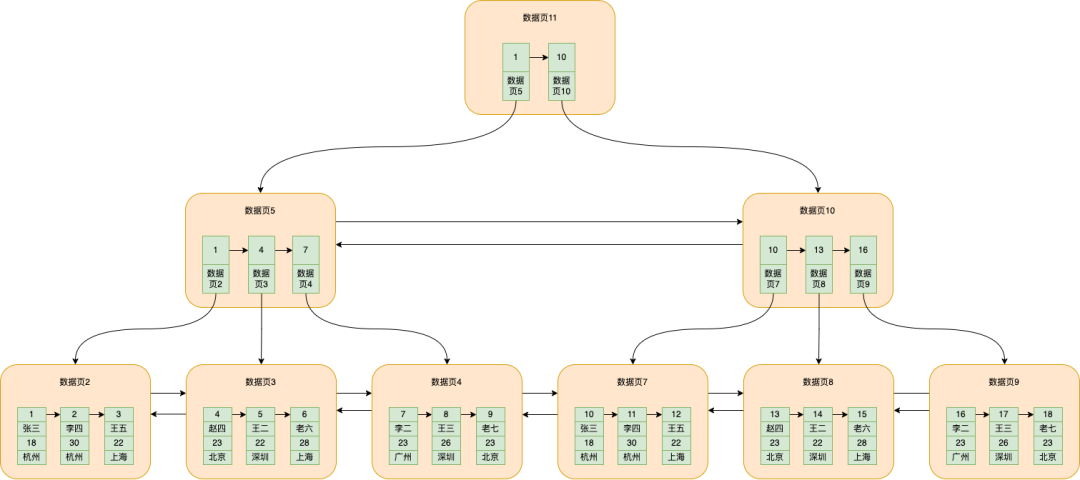
A página de dados 11 é a página de dados recém-extraída, que armazena o número da página id=1 e a página de dados correspondente 5 e o número id=10 e o número da página correspondente da página de dados 10
E esta é a árvore B+ .
De um modo geral, a árvore B + do banco de dados mysql pode conter dezenas de milhões de dados em três camadas.
Neste momento, a busca por dados com id=5 é dividida aproximadamente nas seguintes etapas:
-
Na página de dados 11, localize id=5 de acordo com a pesquisa binária, correspondente à página de dados 5
-
Em seguida, vá para a página de dados 5 e localize a página de dados 3 de acordo com a pesquisa binária id=5
-
Em seguida, vá para a página de dados 3 para encontrar dados de acordo com id = 5. A lógica específica foi mencionada muitas vezes antes.
Desta forma, os dados podem ser encontrados com sucesso.
A árvore B+ na qual os nós folha armazenam os dados realmente inseridos é chamada de índice clusterizado , e os nós não-folha armazenam o ID do registro e o número da página de dados correspondente.
Portanto, para o mecanismo de armazenamento InnoDB, os próprios dados são armazenados em uma árvore B+.
- índice secundário
Um índice secundário também é chamado de índice não clusterizado, que é uma árvore B +. Um índice secundário corresponde a uma árvore B +, mas os dados armazenados na árvore B + do índice secundário são diferentes dos do índice clusterizado.
Conforme mencionado anteriormente no índice clusterizado, os nós folha armazenam os dados que inserimos no banco de dados e os nós não folha armazenam o ID da chave primária dos dados e o número da página de dados correspondente.
Os nós folha do índice secundário armazenam os dados da coluna do índice e o id da chave primária correspondente, e os nós não folha também armazenam o número da página de dados, além dos dados e id da coluna do índice.
A página de dados mencionada acima é na verdade chamada de página de índice, porque o nó folha armazena os dados da tabela real, então eu a chamo de página de dados. Em seguida, porque eu realmente quero falar sobre o índice, usarei o índice secundário A página é chamada de página de índice , você sabe que é a mesma, mas os dados armazenados não são os mesmos.
4.1 Índice de coluna única
Suponha que agora adicionamos um índice não exclusivo comum ao campo de nome, então nome é a coluna de índice e o índice de nome também é um índice de coluna única
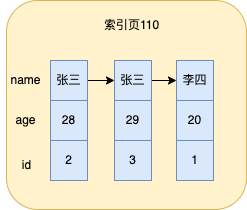
Neste momento, se três partes de dados forem inseridas na tabela, os dados armazenados no nó folha do índice de nome serão mostrados na figura abaixo

Mysql irá classificar de acordo com o valor do campo nome. Aqui eu assumo que Zhang San está classificado na frente de Li Si. Quando os valores das colunas do índice forem iguais, eles serão classificados de acordo com o id, então o índice foi realmente classificado de acordo com o valor da coluna de índice.
Deve haver alguns amigos aqui com dúvidas, os chineses armazenados no campo de nome podem ser classificados?
A resposta é sim, e o mysql suporta muitos tipos de regras de classificação. Podemos especificar as regras de classificação ao construir bancos de dados ou tabelas, e a classificação das strings envolvidas nos artigos a seguir é feita aleatoriamente por mim. A situação real pode não ser a mesma . o mesmo .
A pesquisa de dados para uma única coluna de índice é a mesma do índice clusterizado mencionado acima, e os dados também são agrupados e, em seguida, os dados podem ser pesquisados em uma única coluna de índice de acordo com a pesquisa binária.
Quando os dados continuarem a aumentar e uma página de índice não puder armazenar os dados, várias páginas de índice serão usadas para armazenar os dados e as páginas de índice formarão diretamente uma lista duplamente vinculada

Quando o número de páginas de índice continuar aumentando, para facilitar a busca de dados em diferentes páginas de índice, uma página de índice também será extraída. Além de armazenar o id na página, também armazenará o valor do índice coluna correspondente ao id
Quando os dados se tornarem cada vez maiores, eles serão extraídos e uma árvore B + de três camadas será formada, então não vou desenhá-la aqui.
4.2 Índice de junta
Além do índice de coluna única, o índice conjunto é realmente o mesmo, exceto que os dados armazenados na página de índice possuem mais colunas de índice.
Por exemplo, para criar um índice conjunto de nome e idade, uma única página de índice é mostrada na figura
Primeiro classifique por nome, depois classifique por idade se o nome for o mesmo, se houver outras colunas e assim por diante e, finalmente, classifique por id.
Em comparação com o índice com apenas o campo de nome, a página de índice armazena mais uma coluna de índice.
A árvore B+ final é simplificada conforme mostrado na figura abaixo

4.3 Resumo
De fato, pode ser visto na análise acima que as principais diferenças entre o índice clusterizado e o índice não clusterizado são as seguintes
-
Os nós folha do índice clusterizado armazenam os valores de todas as colunas, e os nós folha do índice não clusterizado armazenam apenas os valores das colunas do índice e o ID da chave primária
-
Os dados do índice clusterizado são classificados por id e os dados do índice não clusterizado são classificados pela coluna do índice
-
Os nós não folha do índice clusterizado armazenam o id da chave primária e o número da página, e os nós não folha do índice não clusterizado armazenam a coluna do índice, o id da chave primária e o número da página
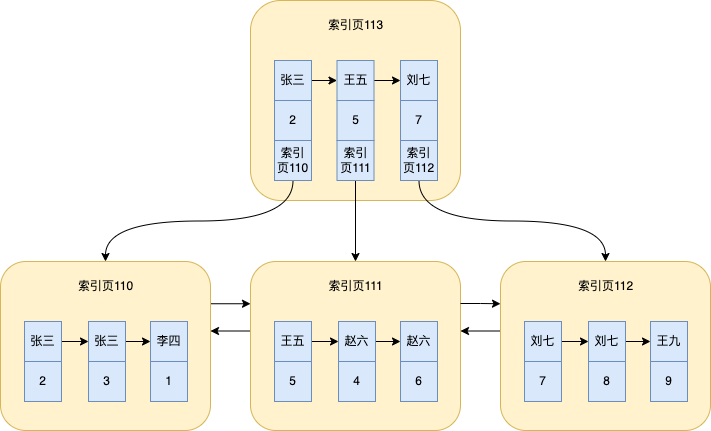
Como a última árvore de índice será usada com frequência, para sua conveniência, inseri os dados correspondentes na tabela com base nos dados da árvore de índice acima e o sql está no final do artigo
Na realidade, a árvore do índice B + pode não estar ordenada como mostra a minha foto, mas não atrasa o entendimento.
- formulário de devolução
-
Depois de falar sobre o índice secundário, vamos falar sobre como usar o índice secundário para encontrar dados.
Aqui é assumido que um índice é criado no campo nome, e vários dados no exemplo acima são armazenados na tabela, aqui vou tirar a foto novamente

Então, como o seguinte sql deve ser executado?
select * from `user` where name = '赵六';
Como a condição de consulta é name = '赵六', o índice de nome será usado
Todo o processo é dividido basicamente nas seguintes etapas:
-
Inicie a pesquisa binária na página de índice superior, que é a página de índice 113 em nossa figura. Se houver outra camada acima da página de índice 113, inicie a pesquisa binária na camada superior
-
Encontre entre e na página de índice 113 e
赵六, em seguida , vá para a página de índice correspondente 111 para pesquisar王五刘七王五赵六 -
赵六O primeiro registro encontrado na página de índice 111 , ou seja, aquele com id=4 -
Por ser
select *, você precisa verificar outros campos. Neste momento, você procurará outros dados de campo no índice agrupado de acordo com id=4. Esse processo de pesquisa já foi mencionado várias vezes antes. Isso é para pesquisar dados no índice clusterizado baseado em id = 4. Backlist _ -
Como é um índice não único,
赵六este valor pode ser repetido, então ele continuará percorrendo a lista encadeada na página de índice 111. Se o nome ainda estiver lá,赵六ele retornará à tabela de acordo com o valor de id, e assim por diante, até que o nome Não seja mais igual赵六, para a ilustração, na verdade são dois dados
A partir da análise do processo de busca de dados do índice secundário acima, podemos entender o significado de retornar à tabela , que é primeiro encontrar o ID da chave primária correspondente do índice secundário de acordo com o valor do campo da condição de consulta e em seguida, procure os valores de outros campos de acordo com o id e depois com o índice clusterizado.
- índice de cobertura
A seção anterior disse que quando este sql é executado , o ID da chave primária correspondente select * from user where name = '赵六';será encontrado primeiro na página de índice e, em seguida, retornado à tabela para consultar os valores de outros campos no índice clusterizado.name = '赵六';
Então, o que acontece quando o seguinte sql é executado?
select id from `user` where name = '赵六';
Desta vez, o campo de consulta select *muda de select id, e as condições de consulta permanecem inalteradas, portanto, o índice de nome também será usado
Portanto, ainda é o mesmo de antes. Depois de descobrir o name = '赵六';id da chave primária correspondente na página de índice, fiquei surpreso ao descobrir que o valor do id do campo que precisa ser consultado no SQL já foi encontrado. Quando o id é alcançado, qual tabela deve ser retornada.
A situação em que os campos que precisam ser consultados estão todos na coluna de índice é chamada de índice de cobertura e a coluna de índice cobre o significado do campo de consulta.
Ao usar um índice de cobertura, o número de vezes para retornar à tabela será reduzido, para que a velocidade da consulta seja mais rápida e o desempenho seja maior.
Portanto, no desenvolvimento diário, tente não selecionar *, e verifique o que você precisa.Se houver um índice de cobertura, a consulta será muito mais rápida.
- pushdown de índice
Supondo que um índice conjunto de nome e idade seja estabelecido para a tabela agora, para facilitar o entendimento, tomarei novamente a figura anterior

Em seguida, execute o seguinte sql
select * from `user` where name > '王五' and age > 22;
Antes do MySQL5.6 (excluindo 5.6), as etapas gerais de execução de todo o SQL são as seguintes:
-
Primeiro, de acordo com a pesquisa binária, localize
name > '王五'o primeiro dado, ou seja, Zhao Liu com id=4 -
Depois disso, ele retornará à tabela de acordo com id = 4, pesquisará os dados em outros campos com id = 4 no índice clusterizado e julgará se a idade nos dados é maior que 22, se for, significa que são os dados que precisamos encontrar, caso contrário, não é
-
Em seguida, siga a lista vinculada, continue a percorrer e retorne à tabela uma vez quando um registro for encontrado e, em seguida, julgue a idade e assim por diante até o final
Portanto, conforme mostrado na figura, todo o processo de pesquisa passará por 5 operações de volta à tabela, dois Zhao Liu, dois Liu Qi e um Wang Jiu e, finalmente, os dados que atendem às condições são os dados de Zhao Liu com id=6, e as demais idades não correspondem a e.
Embora não haja nenhum problema com essa execução, não sei se você já percebeu que não é necessário retornar tantas vezes à tabela, pois pode-se observar no diagrama de índice acima que os dados correspondentes são os dados name > '王五' and age > 22de Zhao Liu com id = 6
Então, depois do MySQL5.6, a lógica de julgamento acima age > 22é otimizada
Ainda é o mesmo de antes, encontre Zhao Liu com id = 4 e depois não volte para a tabela para julgar a idade, porque a coluna do índice tem o valor da idade, então julgue diretamente se é maior que 22 de acordo para a idade no índice, se for maior, Retorne à tabela para consultar os dados de campo restantes (porque é select *) e, em seguida, percorra a lista encadeada sequencialmente até o final
Então, após essa otimização, o número de vezes para retornar à mesa passa a ser 1, o que reduz muito o número de vezes para retornar à mesa em relação às 5 vezes anteriores.
E essa otimização chama-se index pushdown , que consiste em reduzir o número de vezes para retornar à tabela.
A razão pela qual essa otimização é chamada de index pushdown está, na verdade,
age > 22relacionada ao local onde a lógica de julgamento é executada, então não vou entrar em detalhes aqui.
- mesclagem de índice
Index merge (index merge) é um mecanismo de otimização de índice introduzido a partir do MySQL5.1. Nas versões anteriores do MySQL, várias condições de consulta em um sql podem usar apenas um índice . No caso de vários índices serão verificados e, em seguida, os resultados da verificação serão ser mesclado
Os resultados serão mesclados nas três situações a seguir:
-
Pegue a interseção (interseção)
-
Tome união
-
União após a classificação (sort-união)
Para não atrasar a demonstração, exclua todos os índices anteriores e crie um índice secundário idx_name e idx_age para nome e idade, respectivamente
8.1 Interseção (intersecção)
Quando o seguinte sql for executado, a interseção aparecerá
select * from `user` where name = '赵六' and age= 22;
Ver plano de execução
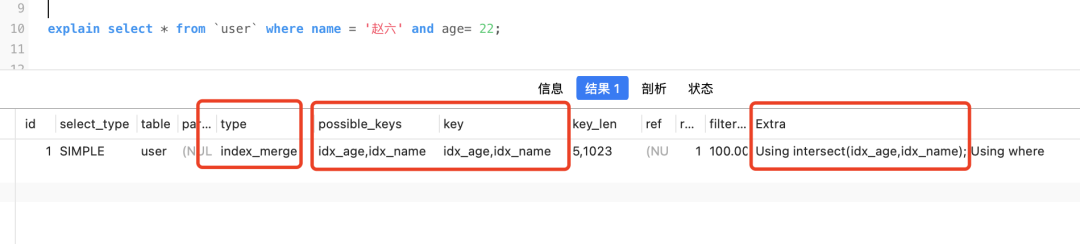
O tipo é yes index_merge, e possible_key e key são somas idx_name, idx_ageindicando que a mesclagem de índice é usada e Extra está disponível Using intersect(idx_age,idx_name)e intersect significa interseção.
Todo o processo é mais ou menos assim, retire o id da chave primária correspondente de acordo com idx_namee respectivamente, e então pegue a interseção do id da chave primária, então o id desta parte da interseção deve atender às condições de consulta da consulta no mesmo tempo (pense bem), e então retorne à tabela de acordo com o id da interseçãoidx_agename = '赵六' and age= 22
No entanto, se você quiser usar o índice conjunto que usa a interseção, precisará garantir que os IDs de chave primária encontrados pelos respectivos índices sejam classificados, o que é conveniente para obter rapidamente a interseção
Por exemplo, o seguinte sql não pode usar o índice comum
select * from `user` where name = '赵六' and age > 22;
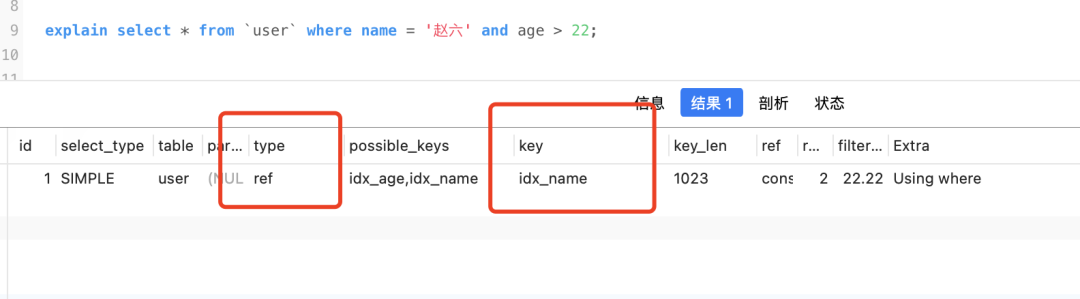
Você só pode usar o índice de nomes, porque age > 22os IDs encontrados estão fora de ordem.Eu mencionei as regras de classificação das colunas do índice quando falei sobre índices.
Pode-se ver a partir disso que as condições para usar um índice conjunto são relativamente duras.
8.2 União
andTirar a união é substituir o exemplo anterior poror
select * from `user` where name = '赵六' or age = 22;
A execução anterior é a mesma. De acordo com as condições, vá para os respectivos índices para pesquisar e, em seguida, pegue a união do id da consulta para desduplicar e depois retorne à tabela
Da mesma forma, obter a união também requer que os IDs de chave primária encontrados pelos respectivos índices sejam classificados. Se a condição de consulta for alterada age > 22para
select * from `user` where name = '赵六' or age > 22;
8.3 União após triagem (sort-união)
Embora a união exija que os IDs da chave primária encontrados pelos respectivos índices sejam classificados, mas se houver uma situação não classificada, o mysql otimizará automaticamente esta situação, classificando primeiro o ID da chave primária e, em seguida, buscando e mesclando Set, esta situação é chamada sort-união.
Por exemplo, o sql mencionado acima que não pode pegar diretamente a união está de acordo com a situação de pegar a união após a classificação (sort-union)
select * from `user` where name = '赵六' or age > 22;
- Como o mysql escolhe índices
Na produção diária, uma tabela pode ter vários índices, então como o mysql determina qual índice usar ao executar o SQL ou varrer a tabela inteira?
Quando o mysql seleciona o índice, ele julgará de acordo com o custo de uso do índice
O custo de uma execução sql é aproximadamente dividido em duas partes
-
Custo de IO, porque essas páginas estão todas no disco, se você quiser julgar, primeiro deve carregá-las na memória. O MySQL estipula que o custo de carregamento de uma página é 1,0
-
Custo de CPU, além do custo de IO, há também o custo de julgamento condicional, ou seja, custo de CPU. Por exemplo, no exemplo anterior, você deve julgar que o
name = '赵六'caractere de dados carregado não atende às condições. O MySQL estipula que o custo de cada dado julgado é 0,2
9.1 Cálculo de custo de varredura de tabela completa
Para uma varredura completa da tabela, o cálculo do custo é mais ou menos o seguinte
mysql vai contar os dados da tabela, essa estatística é aproximada, não muito precisa, você show table status like '表名'pode visualizar os dados estatísticos através
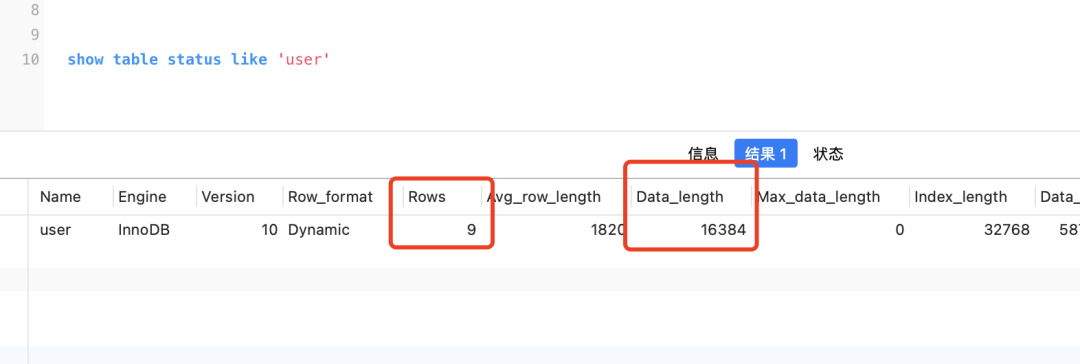
Por exemplo, quantas linhas de dados existem nesta tabela e o número de bytes data_length ocupados pelo índice clusterizado, já que o padrão é 16kb, você pode calcular o número aproximado de páginas de dados (data_length/1024/16).
Portanto, o custo da varredura completa da tabela é calculado assim
rows * 0.2 + data_length/1024/16 * 1.0
9.2 Índice secundário + cálculo de custo da tabela de retorno
O cálculo do custo do índice secundário + retorno da tabela é mais complicado e seus dados de custo dependem do número de intervalos de varredura e do número de tempos de retorno da tabela em duas partes
Para facilitar a descrição do intervalo de varredura, aqui vou tirar a foto acima novamente

select * from `user` where name = '赵六';
Olha a foto!
A condição de consulta name = '赵六'irá gerar um intervalo de varredura, de Zhao Liu com id=4 a Zhao Liu com id=6
Para outro exemplo, se a condição de consulta for name > '赵六', um intervalo de varredura será gerado de Liu Qi com id=7 até o final dos dados (Wang Jiu com id=9)
Para outro exemplo, se a condição de consulta for name < '李四' and name > '赵六', dois intervalos de varredura serão gerados neste momento, um é contado de Zhang San com id=2 a Zhang San com id=3 e o outro é contado de Liu Qi com id=7 até o final dos dados
Portanto, o intervalo de varredura significa o intervalo de registro que atende às condições da consulta
Ao calcular o custo do índice secundário, o mysql estipula que o custo de leitura de um intervalo é o mesmo que o custo IO de leitura de uma página, sendo que ambos são 1,0
Depois que o intervalo estiver disponível, ele estimará quantos pedaços de dados estão nesses intervalos com base em dados estatísticos, porque para ler e gravar esses dados, o custo de leitura é aproximadamente o número de pedaços * 0,2
Portanto, o custo de passar pelo índice secundário é区间个数 * 1.0 + 条数 * 0.2
Depois, esses dados precisam ser devolvidos à tabela (se necessário). O Mysql estipula que o custo IO de cada retorno à tabela seja o mesmo da leitura de uma página, que também é 1,0
Ao retornar à tabela, é necessário julgar as condições de consulta restantes para os dados recuperados do índice clusterizado, que é o custo da CPU, que é aproximadamente o número de entradas * 0,2
Portanto, o custo de devolução da mesa é aproximadamente条数 * 1.0 + 条数 * 0.2
Portanto, o custo aproximado do índice secundário + retorno da tabela é区间个数 * 1.0 + 条数 * 0.2 + 条数 * 1.0 + 条数 * 0.2
Quando o custo do índice e o custo da varredura completa da tabela são calculados, o mysql escolherá o índice com o menor custo para executar
O mysql ajustará os resultados do cálculo de custo acima, mas o valor do ajuste fino é muito pequeno, então o omito aqui, e aqui está apenas uma introdução geral às regras de cálculo de custo. A situação real será mais complicada, como consultar tabelas, etc., existem Parceiros interessados podem consultar informações relevantes
9.3 Resumo
Em geral, esta seção é principalmente para permitir que você entenda uma coisa, quando o mysql seleciona um índice, ele calcula o custo de uso de cada índice de acordo com dados estatísticos e regras de cálculo de custo e, em seguida, escolhe usar o índice com o menor custo. executar consulta
- falha de índice
No desenvolvimento diário, você deve ter encontrado mais ou menos o problema de falha de índice. Aqui, resumi vários cenários comuns de falha de índice.
Para facilitar a explicação, aqui vou tirar a foto novamente
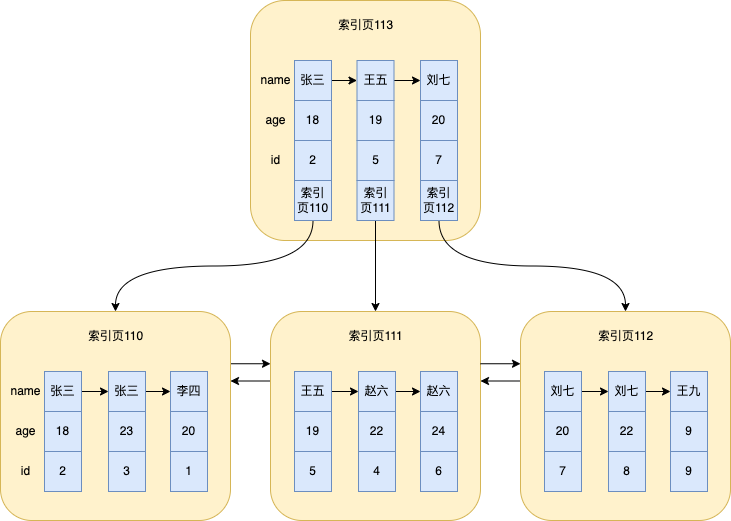
10.1 Inconsistência e princípio de correspondência de prefixo mais à esquerda
ou seja, mais à esquerda primeiro
Quando não corresponde ao princípio de correspondência de prefixo mais à esquerda, fará com que o índice falhe
- Por exemplo,
likese começar com %, o índice é inválido ou o índice conjunto não ocupa a primeira coluna do índice. - Nome do índice comum, idade. De facto, são criados dois índices, nomeadamente (nome), (nome, idade). Portanto, consultar o índice apenas com a idade não surte efeito; o mysql sempre corresponderá à direita até encontrar uma consulta de intervalo (>, <, entre, como) e parar de corresponder
Por exemplo, quando o índice conjunto de nome e idade é executado select * from user where name > '王五' and age > 22;, se você deseja usar o índice, precisa verificar todo o índice neste momento, porque as colunas do índice são classificadas primeiro pelo campo de nome e depois pela idade Para idade, em O índice inteiro está desordenado. Também pode ser visto na figura que 18, 23...9 estão fora de ordem, portanto, é impossível localizar age > 22de qual página de índice começa
Portanto, se você usar o índice, precisará verificar o índice inteiro, julgar um por um e, finalmente, retornar à tabela, o que consome muito desempenho. É melhor verificar diretamente o índice clusterizado, ou seja, o índice completo digitalização da tabela.
10.2 Colunas indexadas são calculadas
+1,abs(),f;oor()etc
Ao executar cálculos de expressão ou usar funções no índice, isso também fará com que o índice se torne inválido
Isso ocorre principalmente porque o valor original do campo de índice é salvo no índice. Como pode ser visto na figura desenhada acima, quando o valor é calculado pela função, não há como ir para o índice
10.3 Conversões implícitas
Quando a coluna do índice tem uma conversão implícita, o índice pode se tornar inválido
Por exemplo, o mysql estipula que quando uma string é comparada com um número, ele irá primeiro converter a string em um número e depois compará- la. Quanto a como converter uma string em um número, o mysql tem suas próprias regras
Por exemplo, uma conversão implícita ocorre quando executo o seguinte sql
select * from `user` where name = 9527;
O campo nome é um tipo varchar, 9527, sem aspas, é um número, o mysql nameprimeiro converterá o valor do campo em um número de acordo com as regras e depois comparará com 9527. Neste momento, nameo índice é inválido porque o campo foi convertido
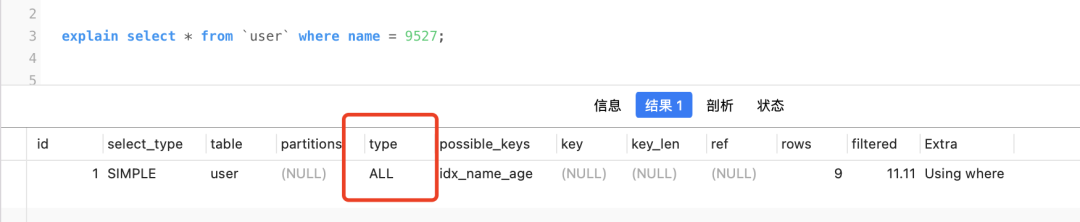
ALL significa que o índice não foi obtido e é inválido.
Mas suponha que você crie um índice na idade agora e execute o seguinte sql
select * from `user` where age = '22';
Neste momento, o índice de idade não será inválido, principalmente por causa da frase mencionada anteriormente:
Quando uma string é comparada com um número, a string será convertida em um número antes da comparação
Portanto, '22'ele será convertido implicitamente em um número e depois comparado com a idade. Neste momento, o campo idade não sofreu conversão implícita, portanto, não será inválido.
Portanto, conversões implícitas podem invalidar o índice.
10.4 erro de dados estatísticos mysql é grande
Grandes erros nos dados estatísticos do mysql também podem levar à falha do índice, porque, como mencionado anteriormente, o mysql calculará o custo do uso de índices com base em dados estatísticos; portanto, uma vez que os erros de dados estatísticos sejam grandes, os erros de custo calculados serão grandes e é possível O custo real da indexação é pequeno, mas o custo calculado da indexação é grande, resultando na falha do índice
Quando isso acontecer, você pode executar analyze table 表名este sql, e o mysql contará novamente os dados e o índice será válido novamente
- Princípios de indexação
11.1 O número de índices de tabela única não deve ser muito
-
Pela análise acima, sabemos que cada índice corresponde a uma árvore B +, e os nós folha armazenam a quantidade total de dados na coluna do índice. Uma vez que o número de índices é grande, ele ocupará uma grande quantidade de espaço em disco
-
Ao mesmo tempo, como mencionado anteriormente, o custo do índice será calculado antes da consulta, uma vez que existem muitos índices, o número de cálculos será grande, o que também pode prejudicar o desempenho.
11.2 Campos que costumam aparecer depois de onde devem ser indexados
Desnecessário dizer que o índice deve acelerar. Se não houver nenhum índice adequado, a varredura completa da tabela será executada. Para InnoDB, a varredura completa da tabela começa no primeiro nó folha do índice clusterizado e julga um por um ao longo do lista encadeada. O serviço de dados não atende às condições de consulta
11.3 Campos após order by e group by podem ser indexados
Por exemplo, o seguinte sql
select * from `user` where name = '赵六' order by age asc;
Consulte name = '赵六'e junte-se ao índice por ageordem, nome e idade
Você pode não se lembrar da árvore de índice, vou trazer a árvore de índice
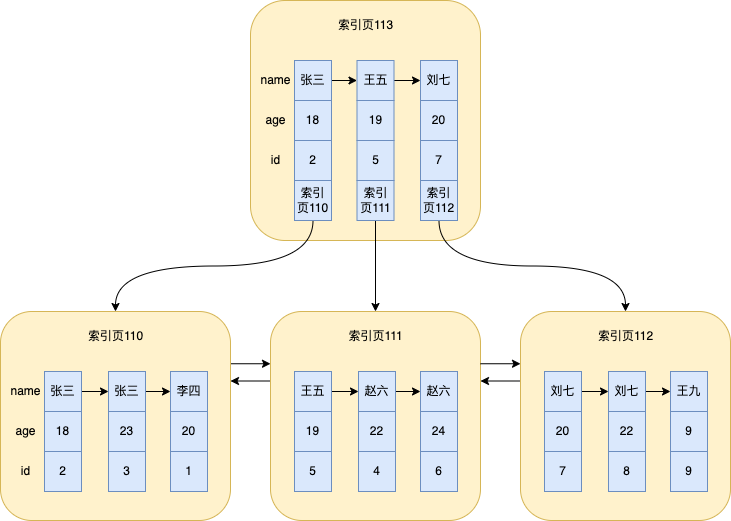
Neste ponto, olhando para a árvore de índice, você pode descobrir name = '赵六'que ageela foi classificada naquele momento (as regras de classificação foram mencionadas na introdução anterior ao índice), então você pode usar agea coluna de índice para classificação.
11.4 Campos atualizados com frequência não devem ser indexados
Como o índice precisa ser classificado de acordo com o valor da coluna do índice, uma vez que os dados do campo do índice são atualizados com frequência, a fim de garantir a ordem do índice, a posição da coluna do índice na página do índice deve ser movida com frequência
Como índice comum de nome e idade
王九Neste momento, altere o nome dos dados com id=9 de 赵六para, em seguida, mova os dados alterados na página de índice entre Wang Wu e Zhao Liu com id=4, porque quando os nomes são iguais, a garantia do pedido, e ao mesmo tempo classificar por idade, a idade de id=9 é 9, a menor, então é classificada em primeiro lugar.
Portanto, criar um índice para campos atualizados com frequência aumentará o custo de manutenção do índice.
11.5 Escolha campos altamente diferenciados para indexação
Isso porque, se a discriminação for baixa, o efeito do índice não é bom.
Por exemplo, suponha que haja um campo de gênero sexo, que é masculino ou feminino. Se o sexo for indexado, supondo que o masculino esteja antes do feminino, os dados na página de índice serão organizados aproximadamente da seguinte maneira:

Aqui eu desenhei 6 pedaços de dados, assumindo que há 10w pedaços de dados, então isso continuará a ser organizado, com homens na frente e mulheres atrás.
Neste momento, se você for ao índice de sexo e consultar os dados com sexo = masculino, assumindo que os dados de masculino e feminino são meio a meio, então os registros digitalizados terão 5w e, se você quiser retornar à tabela, então, de acordo com as regras de cálculo de custo, você descobrirá que o custo é enorme, não é tão bom quanto a verificação direta da tabela completa.
Portanto, escolha um campo com alto grau de discriminação como índice
- Resumo
-
Neste ponto, este artigo acabou, aqui está uma revisão do conteúdo deste artigo
Em primeiro lugar, ele falou principalmente sobre índice clusterizado e índice não clusterizado e, em seguida, falou sobre a otimização do MySQL para algumas consultas comuns, como índice de cobertura e pushdown de índice, todos os quais são para reduzir o número de vezes de retorno para a tabela, reduzindo assim o consumo de desempenho causado e, posteriormente, é mencionado como o MySQL seleciona índices e, finalmente, apresenta os cenários de falha de índice e os princípios de estabelecimento de índice.
Finalmente, espero que este artigo seja útil para você!
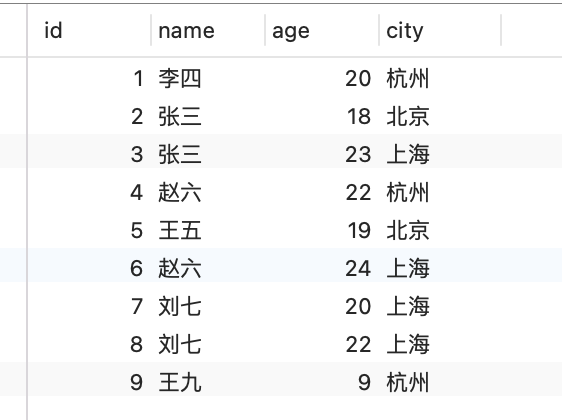
Finalmente, a tabela de dados sql é a seguinte
INSERT INTO `user` (`id`, `name`, `age`, `city`) VALUES (1, '李四', 20, '杭州');INSERT INTO `user` (`id`, `name`, `age`, `city`) VALUES (2, '张三', 18, '北京');INSERT INTO `user` (`id`, `name`, `age`, `city`) VALUES (3, '张三', 23, '上海');INSERT INTO `user` (`id`, `name`, `age`, `city`) VALUES (4, '赵六', 22, '杭州');INSERT INTO `user` (`id`, `name`, `age`, `city`) VALUES (5, '王五', 19, '北京');INSERT INTO `user` (`id`, `name`, `age`, `city`) VALUES (6, '赵六', 24, '上海');INSERT INTO `user` (`id`, `name`, `age`, `city`) VALUES (7, '刘七', 20, '上海');INSERT INTO `user` (`id`, `name`, `age`, `city`) VALUES (8, '刘七', 22, '上海');INSERT INTO `user` (`id`, `name`, `age`, `city`) VALUES (9, '王九', 9, '杭州');
referência:
[1]. "Como funciona o MySQL"
[2].https://blog.csdn.net/weixin_44953658/article/details/127878350