1. HDMapNet
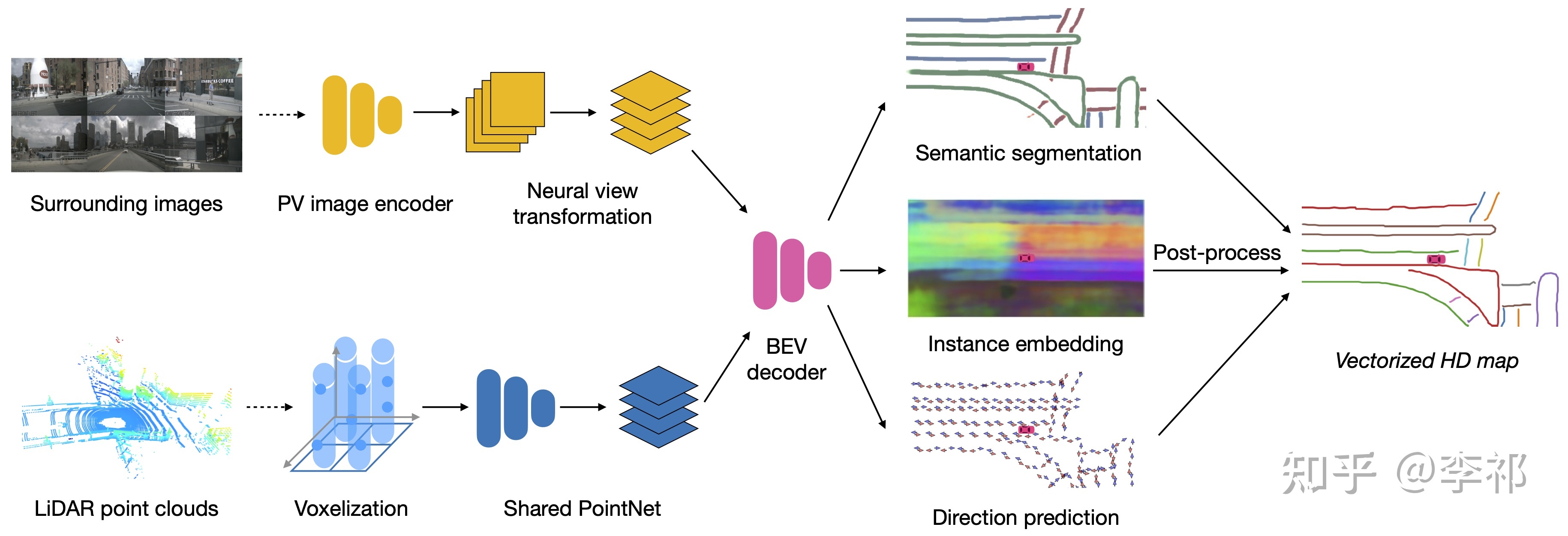
A arquitetura geral da rede é mostrada na figura. O decodificador final gera três ramificações, uma para segmentação semântica, uma para incorporação e uma para previsão de direção. Essas informações são então processadas em uma representação vetorial da estrada por meio de pós-processamento. A previsão de direção divide 360 graus em N partes. Então, no GT, duas direções são 1 e o restante é 0. Obtemos duas direções, multiplicamos pelo tamanho do passo para obter o próximo ponto e o pós-processamento as conecta avidamente.
O método img2bev anteriormente contava com IPM, que completava a conversão assumindo que a altura do solo era 0. No entanto, devido à existência de inclinação do solo e solavancos do veículo, não podemos garantir que as linhas da pista sejam projetadas corretamente no BEV. Quanto ao LSS, como não existe profundidade explícita como supervisão, o efeito não é muito bom. Aqui adotamos um método VPN e usamos uma rede totalmente conectada para aprender como mudar a perspectiva.
2. MapaTR
1. Pontos de inovação do artigo:
1. Influenciado pelo DETR, um algoritmo de construção de mapa vetorizado ponta a ponta é projetado, usando um esquema de incorporação de consulta hierárquica para codificar com flexibilidade informações em nível de instância e nível de ponto e realizar correspondência binária hierárquica para alocar instâncias e pontos em sequência. apontar. Perda ponto a ponto e perda de direção de borda também são propostas para supervisionar informações de direção geométrica em nível de ponto e borda.
2. Propor um método de modelagem de deslocamento equivalente para construir cada elemento do mapa como um conjunto de pontos com um conjunto de deslocamentos equivalentes.
3. Comparado com o pós-processamento complexo e demorado do HDmapNet, o vectorMapNet anterior também representava cada elemento do mapa como uma sequência de pontos, mas usava um decodificador autorregressivo para prever pontos sequencialmente, resultando em tempo de inferência e substituição mais longo. Este artigo prevê vários pontos de várias instâncias ao mesmo tempo e os gera em paralelo.
2. Modelagem equivalente de deslocamento
Os elementos do mapa podem ser divididos em dois tipos, um polígono de forma fechada e uma polilinha de forma aberta, ambos os quais podem ser representados como conjuntos de pontos ordenados. O primeiro possui arranjos 2n, e o segundo possui dois arranjos. Na verdade, todos eles podem ser usados para representar um elemento do mapa, e é obviamente irracional usar um conjunto de pontos de arranjo fixo de GT como supervisão no vectormapnet. Por esta razão, consideramos todos os arranjos possíveis de um elemento do mapa como objetos correspondentes húngaros, o que equivale a construir um conjunto de permutações equivalente.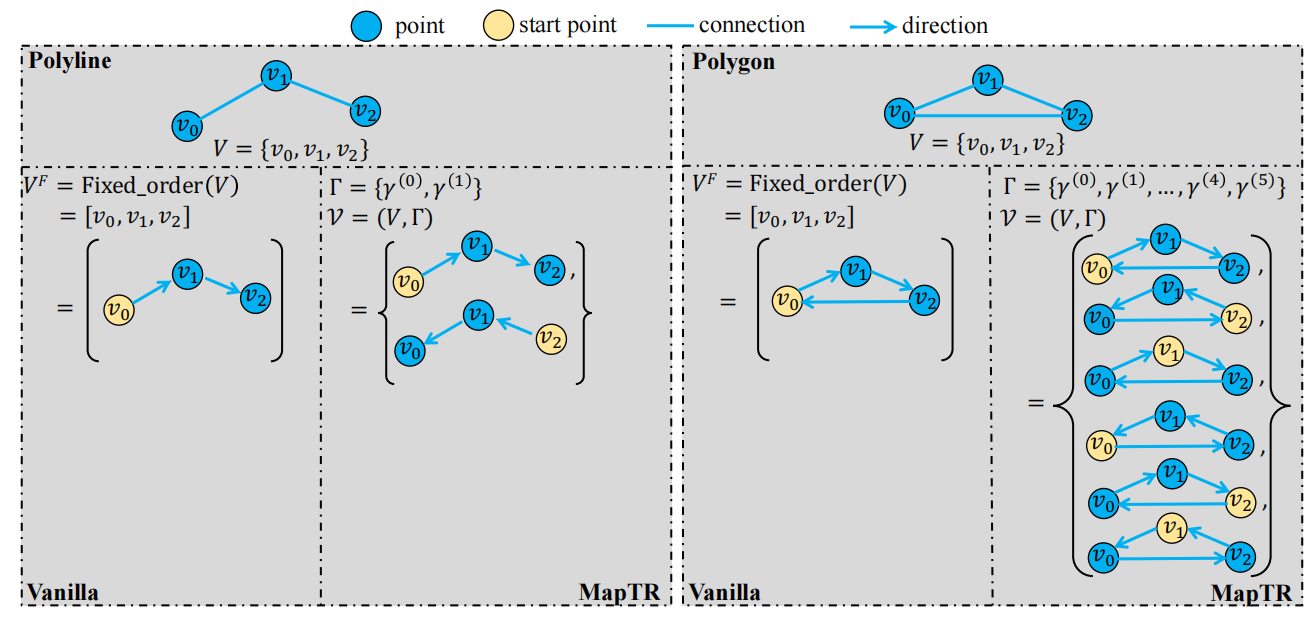
3. Correspondência de nível
Primeiro, um conjunto de elementos do mapa de tamanho fixo N é especulado em paralelo. Ao mesmo tempo, também preencheremos os elementos do mapa GT com conjuntos vazios e preencheremos seu comprimento até N. Cada elemento do mapa contém (um rótulo de elemento + ponto de elemento do mapa conjunto + conjunto de pontos Todas as permutações e combinações), então os elementos do mapa previstos pelo modelo incluem (um rótulo de elemento + um conjunto de pontos ordenados do mapa), um algoritmo hierárquico de correspondência de gráfico bipartido é introduzido e correspondência em nível de instância e correspondência em nível de ponto são executados em ordem.
Correspondência em nível de instância : primeiro encontre a atribuição ideal de rótulo em nível de instância entre os elementos previstos do mapa e os valores reais, para que o custo seja minimizado. O custo tem duas partes, uma é a perda focal do rótulo e a outra é a perda de correspondência de posição dos dois conjuntos de pontos.
Aqui está uma armadilha: qual é a perda de correspondência de posição do conjunto de pontos? É um conjunto de pontos ordenado ou um conjunto de pontos não ordenado? A fórmula deve ser o conjunto de pontos ordenado previsto e o conjunto de pontos não ordenado em GT. Estou muito curioso sobre a diferença entre este e o conjunto de pontos correspondente abaixo. Depois de ler o livro deste irmão interpretação
, Como mencionado acima, na verdade, a perda de correspondência de posição é exatamente a mesma que a perda de correspondência de nível de ponto abaixo.
Notas de leitura do MapTR e observação das linhas da pista - Zhihu (zhihu.com)
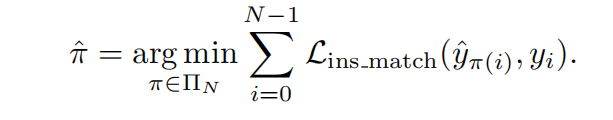
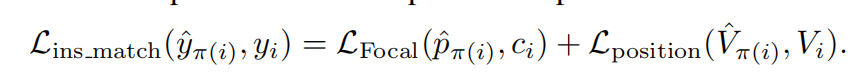

Correspondência em nível de ponto: após a correspondência em nível de instância, os elementos do mapa que correspondem a instâncias não vazias GT são considerados amostras positivas e realizamos correspondência em nível de ponto neles. Ou seja, o custo de correspondência é calculado entre o conjunto de pontos previsto pelo modelo e todas as permutações do conjunto de pontos GT, e a permutação do conjunto de pontos GT com o custo mínimo de correspondência é selecionada. O que procuramos aqui é a perda de distância de Manhattan entre os pontos.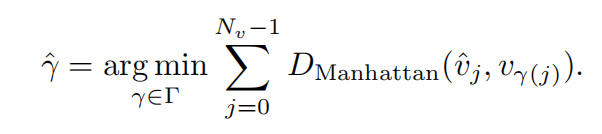
4.Estrutura do modelo
Use câmeras puras para gerar mapas on-line de alta precisão. O método GKT proposto pela Horizon usado por img2bev. Para consulta BEV, primeiro obtenha sua posição anterior na imagem (que pode corresponder a várias imagens) por meio de parâmetros internos e externos e extraia as proximidades w*h Os recursos da área do kernel são então usados para criar um mecanismo de atenção cruzada com a consulta bev.
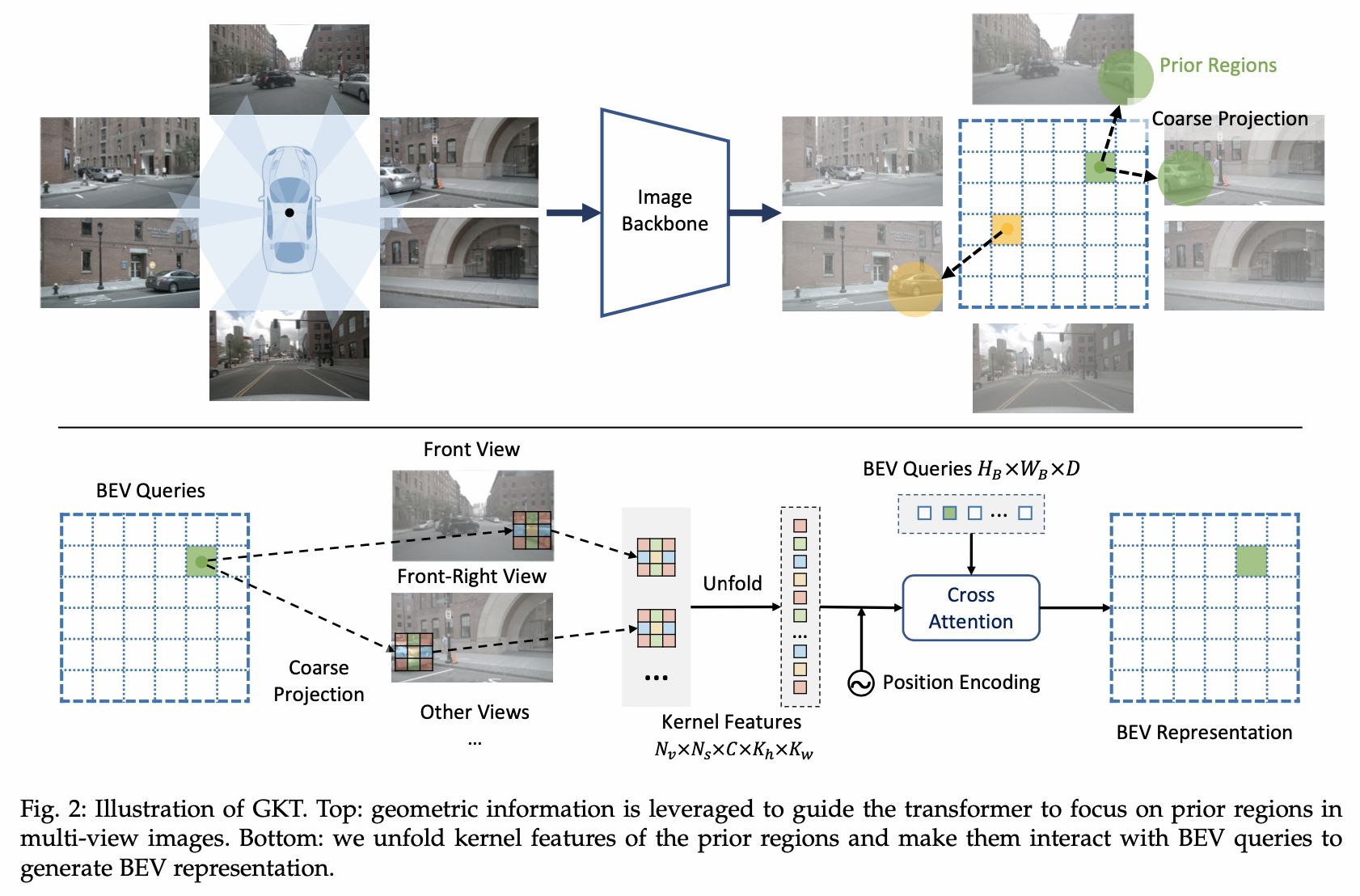
Depois de obter os recursos do BEV, um decodificador semelhante à estrutura DETR é usado no artigo. O autor apresenta dois embeddings de consulta, um é um vetor de consulta em nível de instância (há N) e o outro é um vetor de consulta em nível de ponto (existem NV). , o vetor de consulta em nível de ponto é compartilhado por todos os elementos do mapa (ou seja, instâncias). Então, a expressão de consulta hierárquica do j-ésimo ponto do i-ésimo elemento do mapa é seu vetor de consulta correspondente em nível de instância + o vetor de consulta correspondente em nível de ponto.
Depois de obter as características de cada ponto, primeiro o enviamos para o mecanismo de autoatenção multi-head para permitir que consultas hierárquicas troquem informações (incluindo nível de instância e entre conjuntos de pontos) e, em seguida, usamos o mecanismo de atenção deformável para permitir consultas hierárquicas para troca de informações. Há interação entre a consulta e os recursos do BEV. Cada consulta qij prevê um ponto de coordenada xy normalizado bidimensional no BEV, em seguida, faz uma amostragem dos recursos do BEV próximos ao ponto de coordenada e atualiza os recursos da consulta qij, e assim ligado. Iterar. No final, cada elemento do mapa é um conjunto de pontos de referência, que é enviado ao cabeçote de predição para obter uma pontuação de classificação e um vetor de dimensões 2Nv, representando as posições dos pontos Nv no conjunto de pontos de predição.
5. Composição das perdas
Para obter o resultado de correspondência ideal no nível da instância, usamos a perda focal para calcular sua perda de classificação.
Então, após a conclusão da correspondência em nível de ponto, calculamos a perda de distância de Manhattan entre os pontos para restringir a posição dos pontos.
No entanto, apenas a posição do ponto é restringida, e a direção da linha da borda não é bem restringida, então a perda de direção da borda é adicionada.O autor considera a semelhança de cosseno entre a borda prevista e a borda verdadeira no conjunto de pontos emparelhados para constrangê-lo.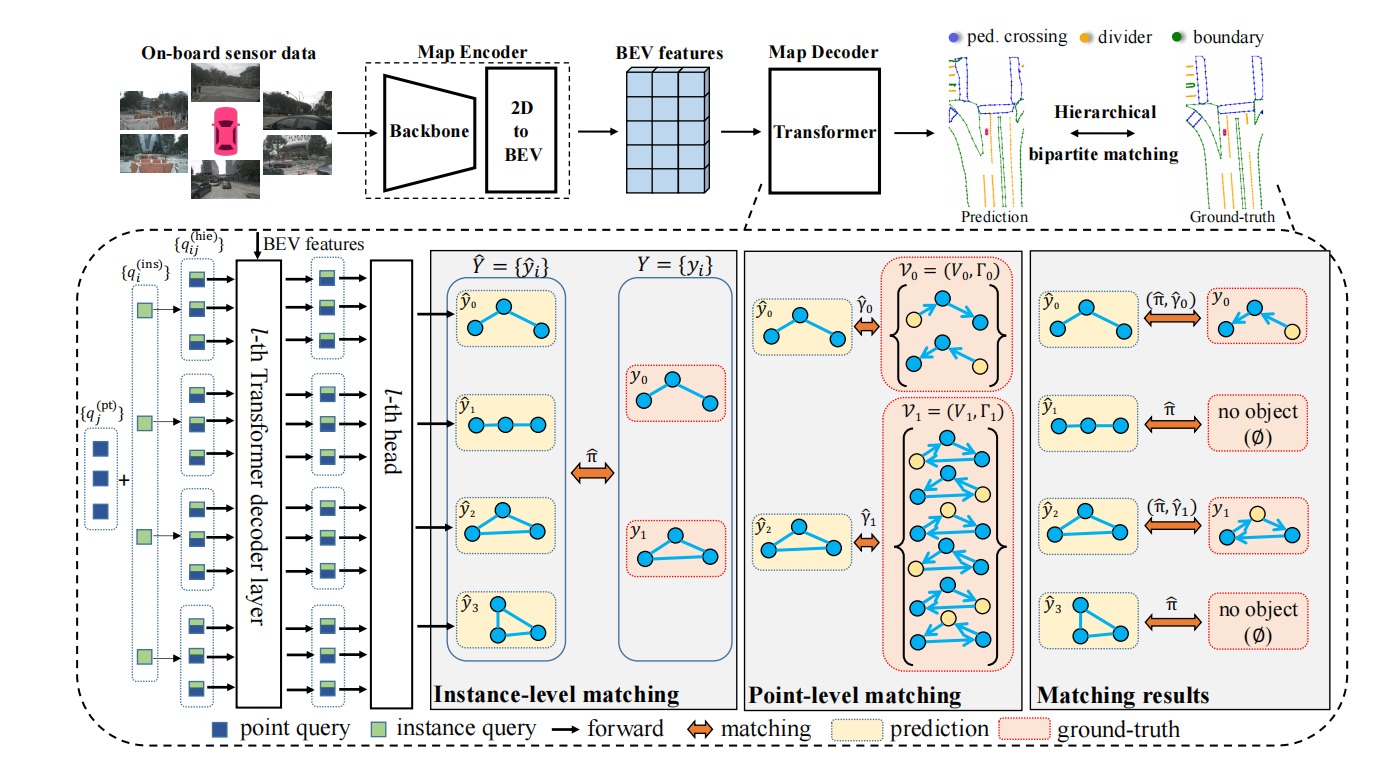
6.Melhorias do MapTRV2
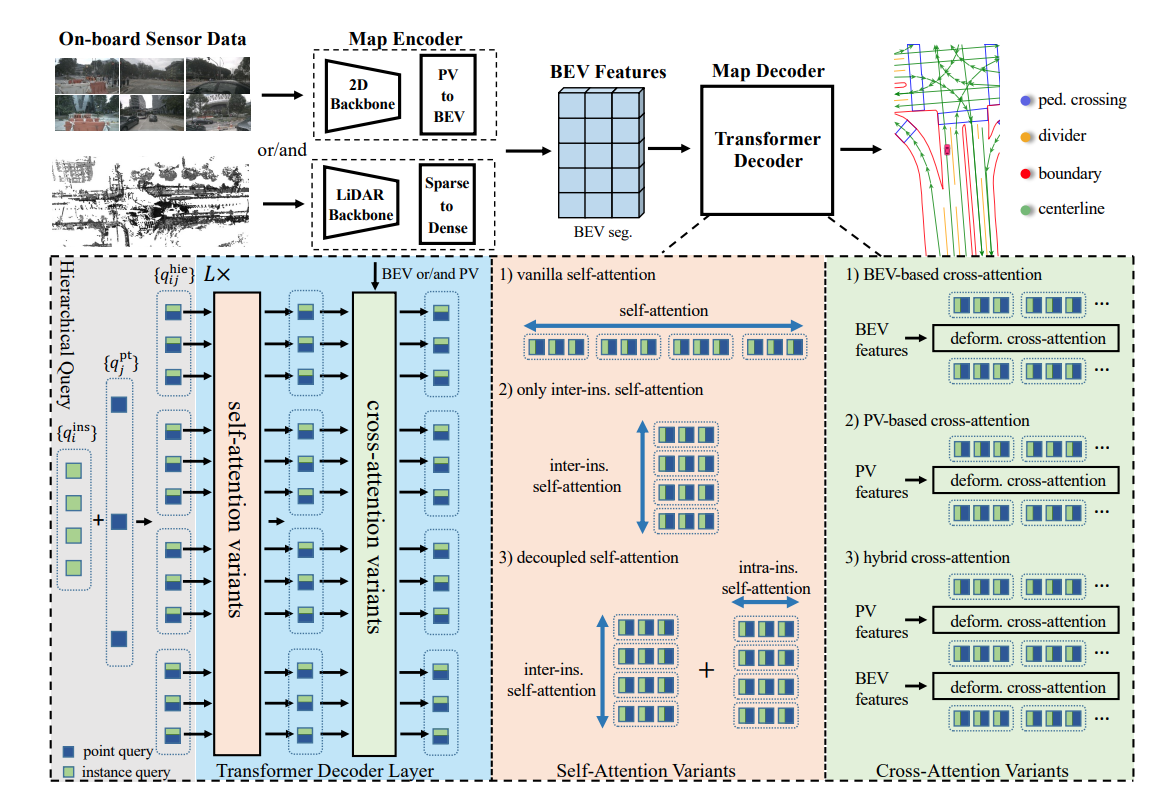
1. Desacoplar o módulo de autoatenção do mecanismo de consulta hierárquica. Isso reduz bastante o consumo de memória.
2. Propôs uma variante mais eficiente do mecanismo de atenção cruzada. Não apenas os recursos BEV são consultados, mas também os recursos PV.
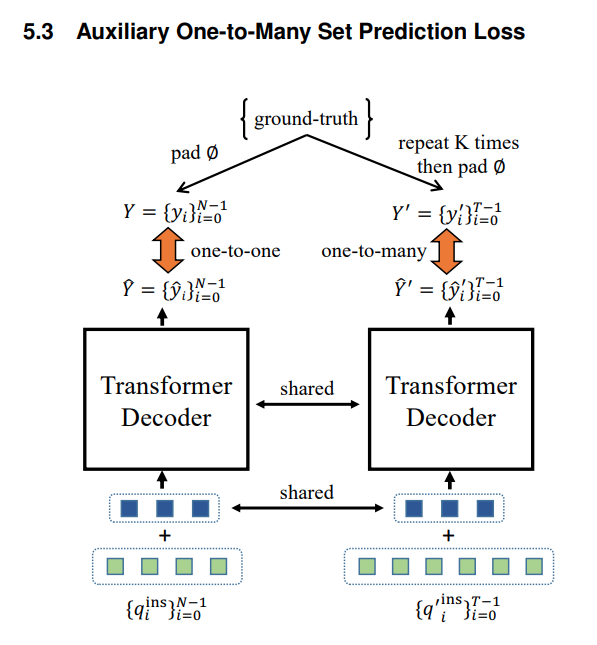
3. Para acelerar a convergência do treinamento, um ramo de correspondência auxiliar um para muitos é adicionado durante o treinamento.
4. Três perdas auxiliares de predição densa são adicionadas para auxiliar no treinamento.
Vamos falar primeiro sobre o primeiro ponto: a consulta de previsão original é N * Nv pontos e, em seguida, a complexidade de tempo do mecanismo de autoatenção é (N * Nv) ^ 2. No artigo, uma operação de desacoplamento é realizada aqui,
e a autoatenção entre instâncias é realizada separadamente.Mecanismo de força e mecanismo de autoatenção, por exemplo, pontos internos. A complexidade do tempo é reduzida para (N^2 + Nv^2).
Segundo ponto: O mecanismo de atenção cruzada anterior prevê um ponto e usa atenção deformável para extrair características no BEV. Agora o ponto é projetado na imagem e então as características são extraídas para torná-las mais ricas.
O terceiro ponto: repetimos GT K vezes como o valor verdadeiro do ramo auxiliar para aumentar a proporção de amostras positivas. Ao mesmo tempo, o ramo principal e o ramo auxiliar compartilham o decodificador e a consulta em nível de ponto.
O quarto ponto: LSS é usado, e o ramo auxiliar de predição de profundidade, o ramo de segmentação semântica PV e o ramo de segmentação semântica BEV são adicionados. A perda de previsão de profundidade refere-se ao BEVDepth. Adicionado um cabeçote de segmentação BEV adicional para auxiliar no treinamento. Além disso, para aproveitar ao máximo a supervisão intensiva, o mapa GT é usado para combinar os parâmetros internos e externos da câmera para obter a máscara de primeiro plano na vista em perspectiva, e o cabeçote auxiliar de segmentação fotovoltaica é usado para treinar a rede.
7. Algumas reflexões sobre o MapTR
Em comparação com a previsão pixel por pixel, a precisão da distância final da previsão ponta a ponta ainda é um pouco pior. No entanto, as tediosas operações de pós-processamento são omitidas, portanto o desempenho em tempo real é muito forte. Ao mesmo tempo, como gera diretamente 20 pontos por instância, o modelo será mais robusto à oclusão do que o modelo de pixel. Ao mesmo tempo, outra crítica é que o tempo de treinamento é muito longo. Pessoalmente, acho que durante a decodificação, uma consulta irá prever uma posição no BEV, mas não possui recursos precisos no BEV. Como podemos obter a precisão Posição BEV? Por exemplo, sua posição real é (100, 100), mas no início o modelo prevê aleatoriamente (20, 20). Neste momento, o mecanismo de atenção deformável extrai características próximas de (20, 20). Ele pode corrigi-lo? Sinto que as características de (20,20) não permitem que ele se aproxime de (100,100), porque afinal não é um mecanismo de atenção global, mas sim local. Sinto que esta deve ser a razão pela qual seu a convergência da formação tem sido muito lenta.
3. Superfusão
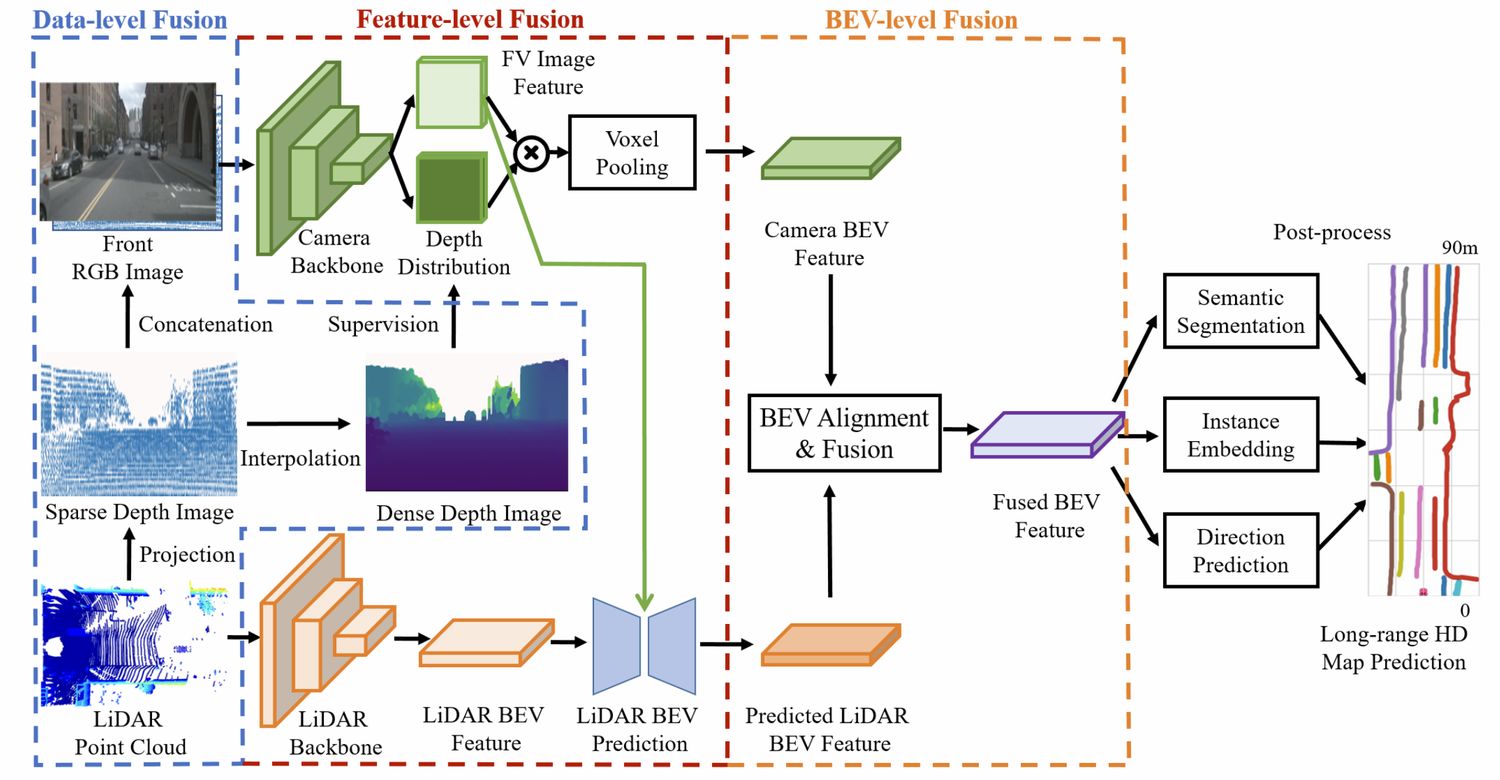
Isso é feito usando a fusão de recursos de nuvem de pontos de imagem em vários níveis.
A primeira é a fusão no nível dos dados. Primeiro, a nuvem de pontos é projetada na imagem e, em seguida, a profundidade esparsa é concatenada com a imagem. Ao mesmo tempo, a interpolação bilinear é usada para obter um mapa de profundidade denso para supervisionar o estimativa de profundidade do LSS.
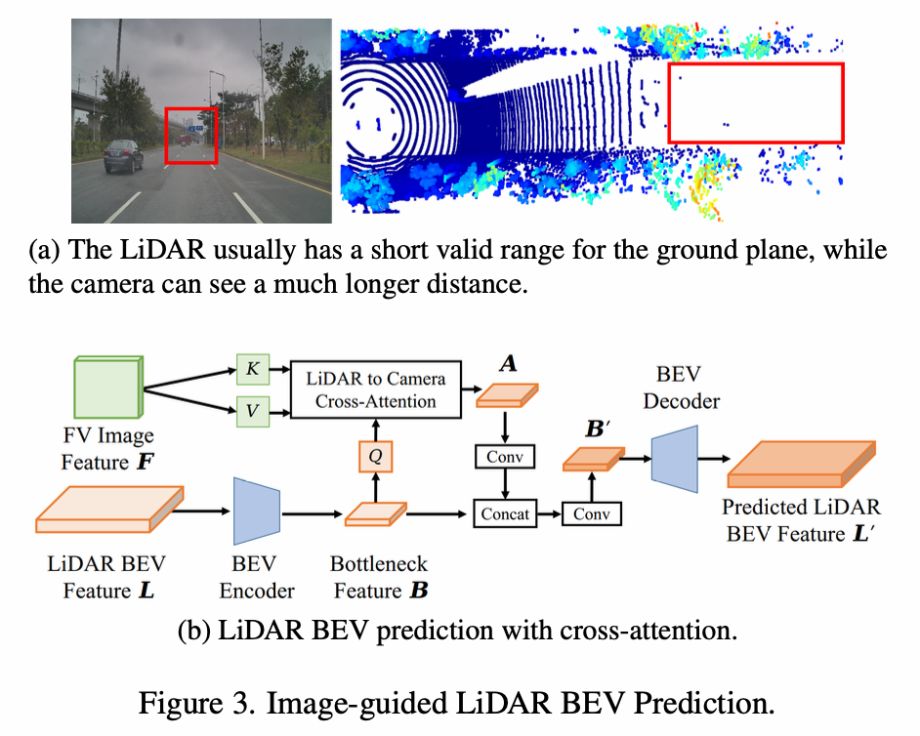
Para fusão em nível de recurso, os recursos BEV da nuvem de pontos são usados como Q para consultar os recursos da imagem, e a atenção cruzada é usada para obter novos recursos BEV, que são então fundidos por meio de uma série de convoluções. Obtenha as características finais da nuvem de pontos BEV.
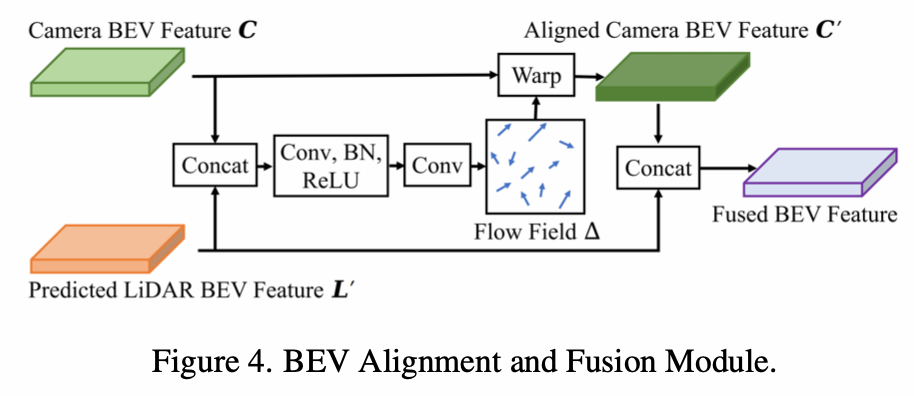
Para fusão no nível BEV, os recursos de imagem são transferidos para o BEV através do LSS e depois fundidos com os recursos BEV da nuvem de pontos.No entanto, devido a parâmetros internos e externos e erros de estimativa de profundidade, a concatenação direta causará desalinhamento de recursos. Portanto, ele primeiro concatena e depois aprende um campo de fluxo, recalcula os recursos BEV da imagem com base no campo de fluxo (uma direção de fluxo em cada posição e, em seguida, usa interpolação bilinear para obter os recursos pós-fluxo como os recursos BEV da imagem atual) e, em seguida, Ambos concatenam.
A parte de pós-processamento é igual ao HDMapNet.