1. O que é uma tabela de consulta?
1.1 Definição
Uma tabela de pesquisa é uma coleção de elementos de dados do mesmo tipo. Por exemplo, uma lista telefônica e um dicionário podem ser vistos como uma tabela de consulta.
1.2 Várias operações de tabelas de consulta:
1) Encontre um elemento de dados específico na tabela de pesquisa;
2) Insira o elemento de dados na tabela de pesquisa;
3) Exclua o elemento de dados da tabela de pesquisa;
1.3 Tabela de consulta estática e tabela de consulta dinâmica
Uma tabela de pesquisa que executa apenas operações de pesquisa sem alterar os elementos de dados na tabela é chamada de tabela de pesquisa estática ; por outro lado, uma tabela de pesquisa que insere ou exclui dados enquanto executa uma operação de pesquisa é chamada de tabela de pesquisa estática. A tabela é dinâmica. tabela de consulta .
1.4 Palavras-chave
Ao procurar um elemento específico na tabela de consulta, a premissa é que você precisa conhecer alguns atributos desse elemento. Por exemplo, todos terão seu próprio número de aluno quando forem para a escola, porque seu nome e idade podem ser iguais aos dos outros, mas o número de aluno não será repetido. Esses atributos dos alunos (número do aluno, nome, idade, etc.) podem ser chamados de palavras-chave.
As palavras-chave são subdivididas em palavras-chave primárias e palavras-chave secundárias. Se uma palavra-chave puder identificar exclusivamente um elemento de dados, ela será chamada de palavra-chave primária. Por exemplo, o número de identificação de estudante de um aluno é único; pelo contrário, palavras-chave como nome e idade de um aluno não são exclusivas porque não são exclusivas. Sexo , chamada de palavra-chave secundária.
2. Encontre explicações detalhadas e exemplos de algoritmos
Use uma palavra-chave para identificar um elemento de dados. Ao pesquisar, com base em um determinado valor, determine um registro ou elemento de dados na tabela cujo valor da palavra-chave seja igual ao valor fornecido. O método de pesquisa em um computador é determinado pela estrutura organizacional dos registros da tabela .
2.1 Pesquisa sequencial
A pesquisa sequencial também é chamada de pesquisa linear. Começando em uma extremidade da tabela linear da estrutura de dados, ela verifica sequencialmente e compara as palavras-chave do nó verificado com o valor k fornecido. Se forem iguais, a pesquisa será bem-sucedida; se ainda for não encontrados após a varredura, nós com palavras-chave iguais a k indicam que a busca falhou.
Exemplo de código em linguagem C:
#include <stdio.h>
#include <stdlib.h>
typedef struct {
int key;//查找表中每个数据元素的值
//如果需要,还可以添加其他属性
}ElemType;
typedef struct{
ElemType *elem;//存放查找表中数据元素的数组
int length;//记录查找表中数据的总数量
}SSTable;
//创建查找表
void create(SSTable **st,int length){
(*st)=(SSTable*)malloc(sizeof(SSTable));
(*st)->length=length;
(*st)->elem =(ElemType*)malloc((length+1)*sizeof(ElemType));
printf("输入表中的数据元素:\n");
//根据查找表中数据元素的总长度,在存储时,从数组下标为 1 的空间开始存储数据
for (int i=1; i<=length; i++) {
scanf("%d", &((*st)->elem[i].key));
}
}
//查找表查找的功能函数,其中key为关键字
int search_seq(SSTable *st,int key){
st->elem[0].key=key;//将关键字作为一个数据元素存放到查找表的第一个位置,起监视哨的作用
int i=st->length;
//从查找表的最后一个数据元素依次遍历,一直遍历到数组下标为0
while (st->elem[i].key!=key) {
i--;
}
//如果 i=0,说明查找失败;反之,返回的是含有关键字key的数据元素在查找表中的位置
return i;
}
int main() {
SSTable *st;
int length;
printf("请输入查找数据的长度:\n");
scanf("%d", &length);
create(&st, length);
printf("请输入查找数据的关键字:\n");
int key;
scanf("%d", &key);
int location = search_seq(st, key);
if (location == 0) {
printf("查找失败");
}else{
printf("数据在查找表中的位置为:%d \n\n",location);
}
return 0;
}Resultado de saída:
2.2 Pesquisa binária (pesquisa pela metade)
A pesquisa binária requer que os nós na tabela linear sejam organizados em ordem crescente ou decrescente por valor de palavra-chave. O valor k fornecido é primeiro comparado com a palavra-chave do nó intermediário. O nó intermediário divide a tabela linear em duas subtabelas. Se eles são iguais, a pesquisa é bem-sucedida; se não forem iguais, o resultado da comparação entre k e a chave do nó intermediário é usado para determinar qual subtabela pesquisar em seguida. Isso é feito recursivamente até que a pesquisa seja encontrada ou verifica-se que não existe tal nó na tabela no final da pesquisa.
Descrição do processo:
{3,5,9,10,12,14,17,20,22,25,28}O processo de uso do algoritmo de pesquisa binária para encontrar a palavra-chave 10 na tabela de pesquisa estática é:
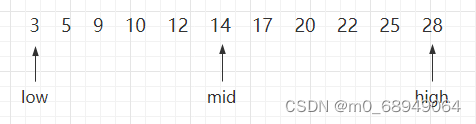
Figura 1 Processo de meia busca (a)
Conforme mostrado na Figura 1 acima, os ponteiros baixo e alto apontam para a primeira chave e a última chave da tabela de pesquisa, respectivamente, e o ponteiro médio aponta para a chave no meio dos ponteiros baixo e alto. Durante o processo de pesquisa, ele é sempre comparado com a palavra-chave apontada por mid. Como os dados de toda a tabela estão ordenados, a localização aproximada da palavra-chave a ser encontrada pode ser conhecida após a comparação.
Por exemplo, ao pesquisar a palavra-chave 10, primeiro compare-a com 14. Como 10 é 10 < 14e a tabela de pesquisa é classificada em ordem crescente, pode-se determinar que se houver uma palavra-chave 10 na tabela de pesquisa estática, ela deve existem nos pontos baixo e médio, no meio da área.
Portanto, ao percorrer novamente, é necessário atualizar as posições do ponteiro alto e do ponteiro médio, mover o ponteiro alto para uma posição à esquerda do ponteiro médio e fazer o ponto médio novamente para a posição intermediária entre o ponteiro baixo e o ponteiro alto. conforme mostrado na imagem 2:
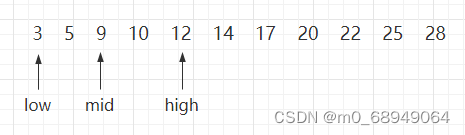
Figura 2 Processo de meia busca (b)
Da mesma forma, compare 10 com 9 apontado pelo ponteiro médio, 9 < 10para que possa ser determinado que se 10 existir, ele deve estar na área apontada por médio e alto. Portanto, deixe o ponto baixo apontar para uma posição no lado direito do meio e atualize a posição do meio ao mesmo tempo.

Figura 3 Processo de meia busca (3)
Quando o julgamento foi feito pela terceira vez, constatou-se que no meio estava a palavra-chave 10, e a busca foi encerrada.
Nota: Durante o processo de pesquisa, se a posição intermediária do ponteiro inferior e do ponteiro superior estiver localizada entre as duas palavras-chave durante o cálculo, ou seja, a posição intermediária não é um número inteiro e uma operação de arredondamento precisa ser executada uniformemente.
Exemplo de código em linguagem C:
#include <stdio.h>
#include <stdlib.h>
typedef struct {
int key;//查找表中每个数据元素的值
//如果需要,还可以添加其他属性
}ElemType;
typedef struct{
ElemType *elem;//存放查找表中数据元素的数组
int length;//记录查找表中数据的总数量
}SSTable;
//创建查找表
void create(SSTable **st, int length){
(*st) = (SSTable*)malloc(sizeof(SSTable));
(*st)->length = length;
(*st)->elem = (ElemType*)malloc((length+1)*sizeof(ElemType));
printf("输入表中的数据元素:\n");
//根据查找表中数据元素的总长度,在存储时,从数组下标为 1 的空间开始存储数据
for (int i=1; i<=length; i++) {
scanf("%d",&((*st)->elem[i].key));
}
}
//折半查找算法
int search_bin(SSTable *ST, int key){
int low=1;//初始状态 low 指针指向第一个关键字
int high=ST->length;//high 指向最后一个关键字
int mid;
while (low<=high) {
mid=(low+high)/2;//int 本身为整形,所以,mid 每次为取整的整数
if (ST->elem[mid].key==key)//如果 mid 指向的同要查找的相等,返回 mid 所指向的位置
{
return mid;
}else if(ST->elem[mid].key>key)//如果mid指向的关键字较大,则更新 high 指针的位置
{
high=mid-1;
}
//反之,则更新 low 指针的位置
else{
low=mid+1;
}
}
return 0;
}
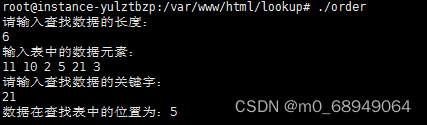
int main(int argc, const char * argv[]) {
SSTable *st;
int length;
printf("请输入查找数据的长度:\n");
scanf("%d", &length);
create(&st, length);
printf("请输入查找数据的关键字:\n");
int key;
scanf("%d",&key);
int location = search_bin(st, key);
//如果返回值为 0,则证明查找表中未查到 key 值,
if (location == 0) {
printf("查找表中无该元素");
}else{
printf("数据在查找表中的位置为:%d \n\n",location);
}
return 0;
}Resultado de saída:

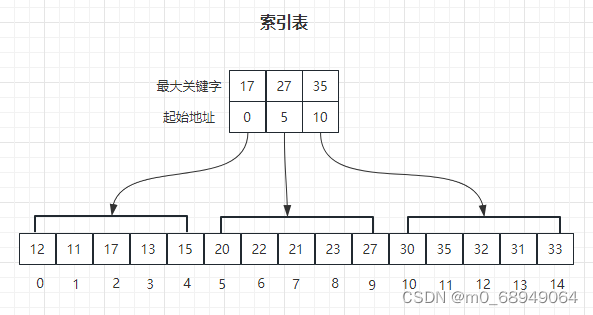
2.3 Bloquear pesquisa
A pesquisa de bloco também é chamada de pesquisa de índice. A linha é dividida em vários blocos. A ordem de armazenamento dos elementos de dados em cada bloco é arbitrária, mas é necessário que os blocos sejam organizados em ordem de acordo com o tamanho do valor da chave, e o estabelecimento de uma tabela de índice organizada em ordem crescente de valores de palavras-chave. Um item na tabela de índice corresponde a um bloco na tabela linear. O item de índice inclui dois conteúdos: ① O campo-chave armazena a palavra-chave máxima do bloco correspondente; ② O campo cadeia armazena o ponto para este bloco. Ponteiro para o primeiro nó. A pesquisa de bloco é realizada em duas etapas: primeiro, determine a qual bloco pertence o nó a ser pesquisado e, em seguida, procure o nó dentro do bloco.
Descrição do processo:
1. Primeiro selecione a maior palavra-chave em cada bloco para formar uma tabela de índice.
2. A pesquisa é dividida em duas partes: primeiro, realiza-se uma pesquisa binária ou uma pesquisa sequencial na tabela de índices para determinar em qual bloco está o registro a ser pesquisado. Em seguida, pesquise sequencialmente nos blocos identificados.
Exemplo de código em linguagem C:
#include <stdio.h>
struct index /*定义块的结构*/
{
int key;
int start;
int end;
} index_table[4]; /*定义结构体数组*/
int block_search(int key, int a[]) /*自定义实现分块查找*/
{
int i, j;
i = 1;
while (i <= 3 && key > index_table[i].key) /*确定在那个块中*/
{
i++;
if (i > 3) /*大于分得的块数,则返回0*/
{
return 0;
}
j = index_table[i].start; /*j等于块范围的起始值*/
while (j <= index_table[i].end && a[j] != key) /*在确定的块内进行查找*/
{
j++;
if (j > index_table[i].end) /*如果大于块范围的结束值,则说明没有要查找的数,j置0*/
{
j = 0;
}
}
}
return j;
}
int main()
{
int i, j = 0, k, key, a[15];
printf("输入长度15的数据元素:\n");
for (i = 0; i < 15; i++)
{
scanf("%d", &a[i]); /*输入由小到大的15个数*/
index_table[i].start = j + 1; /*确定每个块范围的起始值*/
j = j + 1;
index_table[i].end = j + 4; /*确定每个块范围的结束值*/
j = j + 4;
index_table[i].key = a[j]; /*确定每个块范围中元素的最大值*/
}
printf("请输入要查找的关键字:\n");
scanf("%d", &key); /*输入要查询的数值*/
k = block_search(key, a); /*调用函数进行查找*/
if (k != 0)
{
printf("数据在查找表中的位置为:%d \n\n",k);
}else{
printf("未找到");
}
}Resultado de saída:

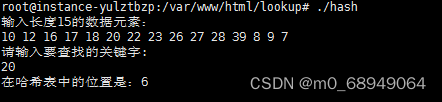
2.4 Pesquisa de tabela hash
A pesquisa na tabela hash serve para encontrar diretamente o endereço do nó operando no valor da palavra-chave registrada.É um método de conversão direta de palavra-chave em endereço sem comparação repetida. Suponha que f contém n nós e é um dos nós (1≤i≤n), que
é o valor da palavra-chave. Uma certa relação funcional é estabelecida entre o endereço
de e e
o valor da palavra-chave pode ser convertido em O endereço do o nó correspondente é: addr(
)=H(
), addr(
) é a função hash.
O endereço hash representa simplesmente o local de armazenamento na tabela de consulta, não o local de armazenamento físico real. f(x) é uma função através da qual o endereço hash dos dados correspondentes à palavra-chave pode ser encontrado rapidamente, que é chamada de "função hash".
2.4.1 Existem 6 métodos de construção de função hash comumente usados: método de endereçamento direto, método de análise digital, método de centralização quadrada, método de dobramento, método de divisão deixando resto e método de número aleatório.
Construir uma função hash requer métodos apropriados com base na situação real da tabela de pesquisa.Os seguintes fatores são geralmente considerados:
- O comprimento da palavra-chave. Se os comprimentos forem desiguais, use o método dos números aleatórios. Se a palavra-chave tiver um grande número de dígitos, use o método de dobramento ou o método de análise numérica; inversamente, se a palavra-chave tiver um número curto de dígitos, considere o método do meio quadrado;
- O tamanho da tabela hash. Se o tamanho for conhecido, você pode optar por usar o método de divisão com resto;
- Distribuição de palavras-chave;
- A frequência de pesquisa da tabela de pesquisa;
- O tempo necessário para calcular a função hash (incluindo fatores para instruções de hardware)
Método de endereçamento direto : Sua função hash é uma função linear, que tem as duas formas a seguir:
H(chave)= chave ou H(chave)=a * chave + b
Entre eles, H (chave) significa que a palavra-chave é o endereço hash correspondente à chave, e tanto a como b são constantes.
Por exemplo, existe uma tabela estatística de estatísticas populacionais de 1 a 100 anos, conforme mostra a Tabela 1:

Tabela 1 Tabela demográfica
Supondo que sua função hash esteja na primeira forma, o valor de sua chave representa o local de armazenamento final. Se você precisar encontrar o número de pessoas com 25 anos, coloque a idade de 25 anos na função hash e encontre diretamente o endereço hash correspondente de 25 (o endereço hash obtido significa que o registro está localizado na 25ª posição na tabela de pesquisa) Bit ).
Método de análise numérica : Se a palavra-chave consistir em vários caracteres ou números, você pode considerar a extração de 2 ou mais dígitos como o endereço hash correspondente à palavra-chave. No método de seleção, tente escolher os bits que mudam mais para evitar conflitos.
Por exemplo, a Tabela 2 lista algumas palavras-chave, cada palavra-chave consiste em 8 dígitos decimais:

mesa 2
Ao analisar a composição da palavra-chave, fica óbvio que o primeiro e o segundo dígitos da palavra-chave são fixos, enquanto o terceiro dígito é um número 3 ou 4, e o último dígito só pode ser 2, 7 e 5., apenas os 4 bits do meio têm valores aproximadamente aleatórios, portanto, para evitar conflitos, 2 bits podem ser selecionados aleatoriamente dos 4 bits como seu endereço hash.
O método do meio quadrado consiste em realizar uma operação quadrada na palavra-chave e considerar o número do meio como o endereço hash. Este método também é um método comumente usado para construir funções hash.
Por exemplo, a sequência de palavras-chave é {421,423,436}, e o resultado da quadratura de cada palavra-chave é {177241,178929,190096}, então os dois dígitos do meio podem ser considerados {72,89,00}seu endereço hash.
O método de dobramento consiste em dividir a palavra-chave em várias partes com o mesmo número de dígitos (o número de dígitos na última parte pode ser diferente) e, em seguida, tomar a soma da superposição dessas partes (com o carry arredondado) como o hash endereço. Este método é adequado para situações em que existem muitos dígitos de palavras-chave.
Por exemplo, os livros nas bibliotecas são numerados usando um número decimal de 10 dígitos como chave. Se uma tabela hash for criada para a tabela de consulta, o método de dobramento poderá ser usado.
Se o número de um livro for: 0-442-20586-4, o método de divisão é mostrado na Figura 1. Existem duas maneiras de dobrá-lo: uma é dobradura por deslocamento e a outra é dobradura por limite:
- A dobragem em deslocamento consiste em alinhar cada parte dividida de acordo com sua parte mais baixa e, em seguida, adicioná-las, conforme mostrado na Figura 1 (a);
- A dobra intermediária é a dobra para frente e para trás ao longo da linha divisória de uma extremidade à outra, conforme mostrado na Figura 1 (b).

Figura 1 Dobra em turnos e dobra em limites
Método de divisão com resto : Se o comprimento máximo m de toda a tabela hash for conhecido, você pode pegar um número p que não seja maior que m e, em seguida, realizar uma operação de resto na chave de palavra-chave, ou seja H(key)= key % p:.
Neste método, o valor de p é muito importante. Sabe-se por experiência que p pode ser um número primo não maior que m ou um número composto que não contém fatores primos menores que 20.
Método de número aleatório: assume um valor de função aleatório da palavra-chave como seu endereço hash, ou seja:, H(key)=random(key)este método é adequado para situações em que os comprimentos da palavra-chave não são iguais.
Nota: A função aleatória aqui é na verdade uma função pseudo-aleatória. A função aleatória significa que mesmo que a chave fornecida seja sempre a mesma, H (chave) é diferente; enquanto a função pseudo-aleatória é exatamente o oposto, cada tecla corresponde a um H fixo (chave).
2.4.2 Métodos de tratamento de conflitos
Para o estabelecimento de uma tabela hash, é necessário selecionar uma função hash apropriada, mas para conflitos inevitáveis, devem ser tomadas medidas adequadas para lidar com eles.
Os métodos comumente usados para lidar com conflitos incluem o seguinte:
- Método de endereçamento aberto H (chave) = (H (chave) + d) MOD m (onde m é o comprimento da tabela hash, d é um incremento) Quando o endereço hash obtido entrar em conflito, escolha os três métodos a seguir. métodos obtém o valor de d e, em seguida, continua o cálculo até que o endereço hash calculado não entre mais em conflito. Esses três métodos são:
- Método de detecção linear: d=1, 2, 3,…, m-1
- Método de detecção secundária: d=12,-12,22,-22,32,…
- Método de detecção de número pseudo-aleatório: d = número pseudo-aleatório

Figura 2 Método de endereçamento aberto
Nota: No método de detecção linear, quando ocorre um conflito, a partir da posição onde ocorre o conflito, +1 é detectado a cada vez, até que haja uma posição livre; no método de detecção secundária, a partir da posição onde ocorre o conflito , de acordo com +12, -12, +22, ... são detectados desta forma até que haja uma posição ociosa; a detecção pseudo-aleatória é realizada adicionando um número aleatório a cada vez até que uma posição ociosa seja detectada.
- Método Rehash:
Quando o endereço hash obtido pela função hash entra em conflito com outras palavras-chave, outra função hash é usada para calcular até que o conflito não ocorra mais. - O método de endereço em cadeia
armazena todos os dados correspondentes a todas as palavras-chave conflitantes na mesma lista linear vinculada . Por exemplo, existe um grupo de palavras-chave{19,14,23,01,68,20,84,27,55,11,10,79}cuja função hash é:H(key)=key MOD 13A tabela hash construída usando o método de endereço em cadeia é mostrada na Figura 3:
Figura 3 Tabela hash construída pelo método de endereço em cadeia
- Crie uma área de overflow pública.
Crie duas tabelas, uma é a tabela básica e a outra é a tabela de overflow. A tabela básica armazena dados sem conflitos.Quando o endereço hash gerado pela função hash de uma chave entra em conflito, os dados são preenchidos na tabela overflow.
Exemplo de código em linguagem C:
#include "stdio.h"
#include "stdlib.h"
#define HASHSIZE 15 //定义散列表长为数组的长度
#define NULLKEY -1
typedef struct{
int *elem;//数据元素存储地址,动态分配数组
int count; //当前数据元素个数
}HashTable;
//对哈希表进行初始化
void init(HashTable *hashTable){
int i;
hashTable->elem= (int *)malloc(HASHSIZE*sizeof(int));
hashTable->count=HASHSIZE;
for (i=0;i<HASHSIZE;i++){
hashTable->elem[i]=NULLKEY;
}
}
//哈希函数(除留余数法)
int Hash(int data){
return data % HASHSIZE;
}
//哈希表的插入函数,可用于构造哈希表
void insert(HashTable *hashTable,int data){
//求哈希地址
int hashAddress=Hash(data);
//发生冲突
while(hashTable->elem[hashAddress]!=NULLKEY){
//利用开放定址法解决冲突
hashAddress=(++hashAddress)%HASHSIZE;
}
hashTable->elem[hashAddress]=data;
}
//哈希表的查找算法
int search(HashTable *hashTable,int data){
//求哈希地址
int hashAddress=Hash(data);
//发生冲突
while(hashTable->elem[hashAddress]!=data){
//利用开放定址法解决冲突
hashAddress=(++hashAddress) % HASHSIZE;
//如果查找到的地址中数据为NULL,或者经过一圈的遍历回到原位置,则查找失败
if (hashTable->elem[hashAddress] == NULLKEY || hashAddress==Hash(data)){
return -1;
}
}
return hashAddress;
}
int main(){
int i, result, key;
HashTable hashTable;
int arr[HASHSIZE];
printf("输入长度15的数据元素:\n");
for (i = 0; i < 15; i++)
{
scanf("%d", &arr[i]); /*输入由小到大的15个数*/
}
//初始化哈希表
init(&hashTable);
//利用插入函数构造哈希表
for (i=0;i<HASHSIZE;i++){
insert(&hashTable,arr[i]);
}
//调用查找算法
printf("请输入要查找的关键字:\n");
scanf("%d", &key); /*输入要查询的数值*/
result= search(&hashTable, key);
if (result==-1){
printf("查找失败");
}
else {
printf("在哈希表中的位置是:%d \n\n", result+1);
}
return 0;
}Resultado de saída: