Índice
1. Introdução geral ao projeto
2. Introdução à estrutura de rede
1. Diagrama da estrutura geral
YOLOv7是一种优秀的端到端检测算法。YOLOv7由Proposto em 2022 por Alexey Bochkovskiy, Chien-Yao Wang e outros (equipe YOLOv4). O YOLOv7 supera todos os detectores de objetos conhecidos em velocidade e precisão na faixa de 5 FPS a 120 FPS, com a maior precisão de 56,8% AP entre todos os detectores de objetos em tempo real conhecidos a 30 FPS.
1. Introdução geral ao projeto
A pasta do projeto yolov7 e a pasta do conjunto de dados estão no mesmo nível. Os conjuntos de dados são divididos em imagens (fotos) e rótulos (rótulos). As imagens e rótulos são divididos em teste (conjunto de teste), trem (conjunto de treinamento), val ( conjunto de validação) três pastas.



A primeira pasta cfg na pasta yolov7 armazena o arquivo de configuração do modelo (model.yaml). Armazenados na pasta de dados estão o arquivo de configuração do conjunto de dados (data.yaml) e o arquivo de configuração do hiperparâmetro (hyperparameters.yam). A demonstração implantada para o servidor de inferência nvidia triton na pasta de implantação. A pasta de figuras contém algumas imagens de resultados de demonstração do yolov7 (detecção 3D, detecção de pontos-chave, etc.). A inferência armazena dados com inferência (imagens, pastas). Armazenados em modelos estão códigos comumente usados para composição da estrutura de rede yolov7. O papel é o papel yolov7. as corridas são os resultados de treinamento e teste. Ferramentas inclui algumas ferramentas em formato de arquivo ipynb (conversão de modelo, comparação de modelo, etc.). Funções utilitárias (funções de ativação, funções de desenho, etc.) são armazenadas em utils. .gitignore é o arquivo ignorado do docker. LICENSE.md é o arquivo de licença. README.md é o arquivo de instruções de uso. código de detecção detect.py. código de exportação do modelo export.py. hubconf.py é o arquivo hub pytorch. requisitos.txt depende do arquivo de ambiente. arquivo de teste test.py. train.py é o arquivo de treinamento para yolov7-tiny e yolov7. train_aux.py é o arquivo de treinamento para yolov7-w6 e yolov7-e6. 
2. Introdução à estrutura de rede
1. Diagrama da estrutura geral
A estrutura geral do yolov7 consiste em quatro partes: Entrada, Backbone, Head e Detect. A entrada é entrada de dados 640*640*3. Backbone é a rede de backbone composta por CBS, ELAN e MP-1. Head consiste em CBS, SPPCSPC, E-ELAN, MP-2 e RepConv. A detecção consiste em três cabeças de detecção. Exceto o código do módulo Detect que está em models/yolo.py, os outros códigos do módulo estão todos em models/common.py.
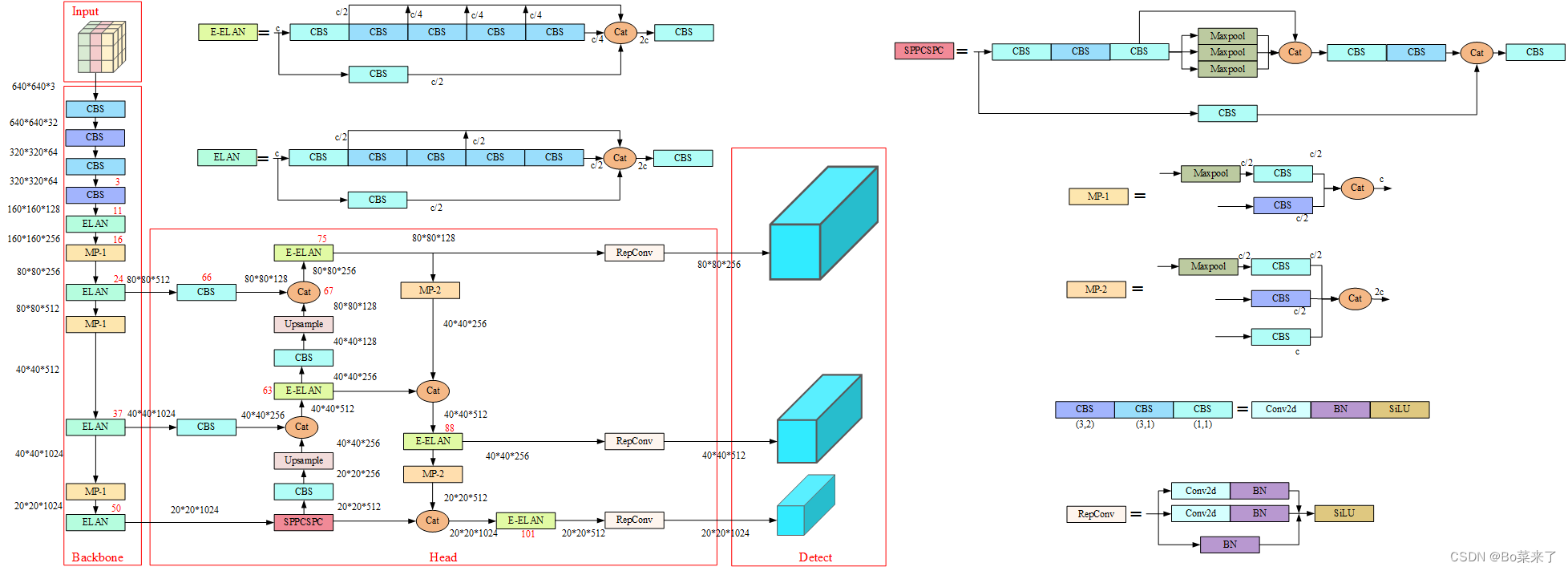
2.CBS
código mostrado abaixo:
class Conv(nn.Module):
# Standard convolution
def __init__(self, c1, c2, k=1, s=1, p=None, g=1, act=True): # ch_in, ch_out, kernel, stride, padding, groups
super(Conv, self).__init__()
self.conv = nn.Conv2d(c1, c2, k, s, autopad(k, p), groups=g, bias=False)
self.bn = nn.BatchNorm2d(c2)
self.act = nn.SiLU() if act is True else (act if isinstance(act, nn.Module) else nn.Identity())
def forward(self, x):
return self.act(self.bn(self.conv(x)))
def fuseforward(self, x):
return self.act(self.conv(x))结构如下:

Entre eles (3,2) está um kernel de convolução 3*3 com avanço de 2. É composto por convolução bidimensional, normalização de lote e função de ativação SiLU.
3.ELAN e E-ELAN
O módulo ELAN é composto pelos caminhos de gradiente mais longos e mais curtos. Mais blocos são empilhados nos caminhos mais curtos para aprender mais recursos.

A estrutura é a seguinte (E-ELAN à esquerda, ELAN à direita):
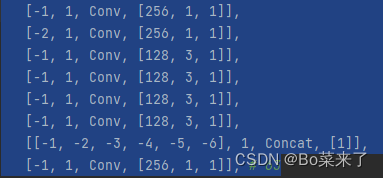
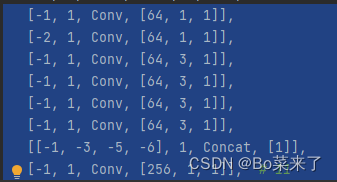

4.MP
A função geral do MP: obter uma redução da resolução que reduza a perda de recursos. O módulo MP-1 consiste em 2 ramificações e o módulo MP-2 consiste em 3 ramificações. A primeira ramificação primeiro usa Maxpool (pooling máximo) para implementar a redução da resolução e, em seguida, usa uma convolução 1*1 para alterar o número de canais. O outro ramo do MP-1 é uma convolução 3*3 com um tamanho de passo do kernel de convolução de 2, que implementa a redução da resolução.
Estrutura da rede (MP-1 à esquerda, MP-2 à direita):

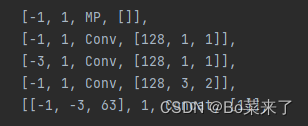

5. SPPCSP
A função do SPP é realizar a fusão de informações de diferentes escalas de recursos, usando pooling máximo em quatro escalas diferentes para processamento.Os tamanhos do kernel de pooling do pool máximo são 13x13, 9x9, 5x5 e 1x1 (1x1 significa sem processamento). O módulo CSP é dividido em duas partes: uma parte realiza o processamento da estrutura SPP e a outra parte processa o número do canal por meio da convolução 1 * 1. Finalmente, as duas partes são concatenadas. SPPCSP realiza a fusão de informações de diferentes escalas de recursos, reduz a quantidade de cálculos e melhora a velocidade.
código mostrado abaixo:
class SPPCSPC(nn.Module):
# CSP https://github.com/WongKinYiu/CrossStagePartialNetworks
def __init__(self, c1, c2, n=1, shortcut=False, g=1, e=0.5, k=(5, 9, 13)):
super(SPPCSPC, self).__init__()
c_ = int(2 * c2 * e) # hidden channels
self.cv1 = Conv(c1, c_, 1, 1)
self.cv2 = Conv(c1, c_, 1, 1)
self.cv3 = Conv(c_, c_, 3, 1)
self.cv4 = Conv(c_, c_, 1, 1)
self.m = nn.ModuleList([nn.MaxPool2d(kernel_size=x, stride=1, padding=x // 2) for x in k])
self.cv5 = Conv(4 * c_, c_, 1, 1)
self.cv6 = Conv(c_, c_, 3, 1)
self.cv7 = Conv(2 * c_, c2, 1, 1)
def forward(self, x):
x1 = self.cv4(self.cv3(self.cv1(x)))
y1 = self.cv6(self.cv5(torch.cat([x1] + [m(x1) for m in self.m], 1)))
y2 = self.cv2(x)
return self.cv7(torch.cat((y1, y2), dim=1))A estrutura da rede é a seguinte:

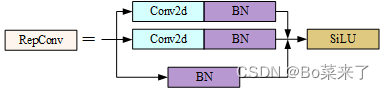
6.RepConv
yolov7 substitui Conv por RepConv no final do cabeçalho. A fase de treinamento consiste em múltiplos ramos, 3x3, 1x1 e identidade (mapeamento), a fase de inferência torna-se apenas uma convolução 3x3, o que reduz o número de parâmetros e acelera a inferência. O processo de treinamento RepConv aprende mais recursos e o processo de inferência é acelerado.
código mostrado abaixo:
class RepConv(nn.Module):
# Represented convolution
# https://arxiv.org/abs/2101.03697
def __init__(self, c1, c2, k=3, s=1, p=None, g=1, act=True, deploy=False):
super(RepConv, self).__init__()
self.deploy = deploy
self.groups = g
self.in_channels = c1
self.out_channels = c2
assert k == 3
assert autopad(k, p) == 1
padding_11 = autopad(k, p) - k // 2
self.act = nn.SiLU() if act is True else (act if isinstance(act, nn.Module) else nn.Identity())
if deploy:
self.rbr_reparam = nn.Conv2d(c1, c2, k, s, autopad(k, p), groups=g, bias=True)
else:
self.rbr_identity = (nn.BatchNorm2d(num_features=c1) if c2 == c1 and s == 1 else None)
self.rbr_dense = nn.Sequential(
nn.Conv2d(c1, c2, k, s, autopad(k, p), groups=g, bias=False),
nn.BatchNorm2d(num_features=c2),
)
self.rbr_1x1 = nn.Sequential(
nn.Conv2d( c1, c2, 1, s, padding_11, groups=g, bias=False),
nn.BatchNorm2d(num_features=c2),
)
def forward(self, inputs):
if hasattr(self, "rbr_reparam"):
return self.act(self.rbr_reparam(inputs))
if self.rbr_identity is None:
id_out = 0
else:
id_out = self.rbr_identity(inputs)
return self.act(self.rbr_dense(inputs) + self.rbr_1x1(inputs) + id_out)O processo de treinamento está estruturado da seguinte forma:
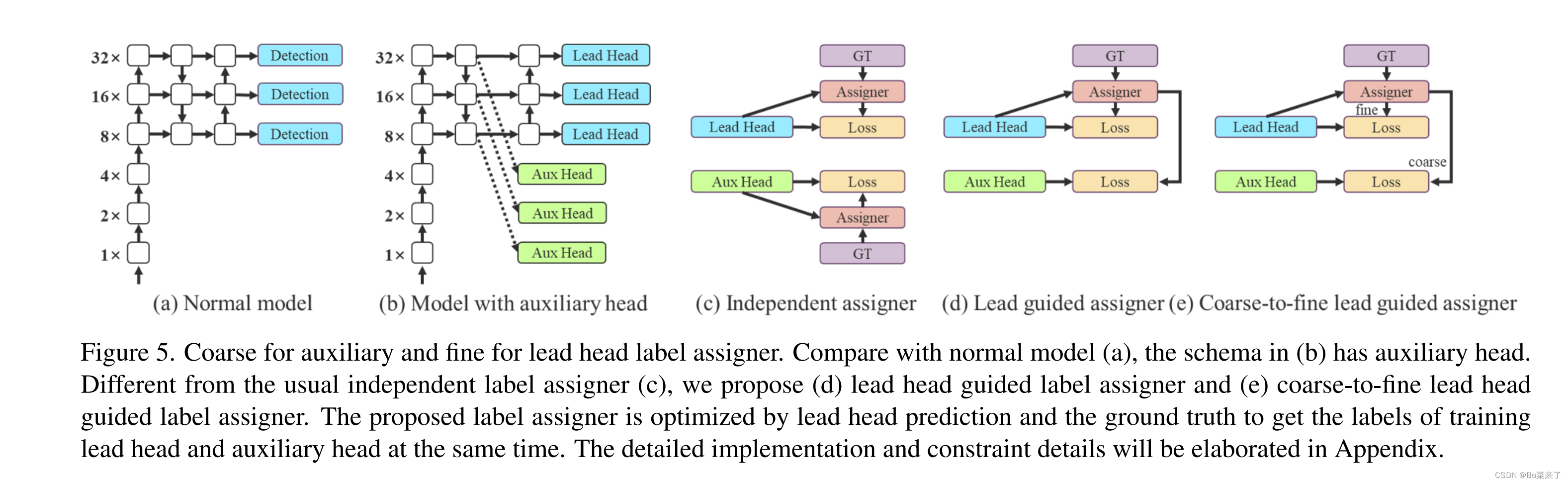
7.Detectar
O código está na classe IDetect(nn.Module) do yolo.py. (d) O cabeçote de detecção gera rótulos suaves através do otimizador com base nos resultados do cabeçote Lead (cabeça líder) e GT (valor verdadeiro do rótulo). Os rótulos flexíveis são usados ao treinar modelos para cabeçotes auxiliares (cabeçotes auxiliares) e cabeçotes principais. A razão para isso é que o líder principal tem uma capacidade de aprendizagem relativamente forte, portanto, os rótulos suaves gerados por ele devem ser mais representativos da distribuição e correlação entre os dados de origem e os dados de destino. Além disso, o aprendizado residual é adicionado, permitindo que o cabeçote auxiliar mais raso aprenda diretamente as informações aprendidas pelo cabeçote principal, para que o cabeçote principal possa se concentrar melhor no aprendizado das informações residuais que não foram aprendidas. (e) Adicionado ajuste fino.
3. Treine seus próprios dados
O processo de treinamento é muito diferente de outros YOLO. Consulte README.md diretamente ![]() https://github.com/WongKinYiu/yolov7#readme
https://github.com/WongKinYiu/yolov7#readme