Email do autor do artigo: [email protected] Endereço: Huizhou, Guangdong
▲ O programa deste capítulo
⚪ Compreender o conceito MLlib do Spark;
⚪ Modelo de dados básico MLlib do Master Spark;
⚪ Domine os fundamentos das estatísticas MLlib do Spark;
1. Introdução ao Spark MLlib
1. Visão Geral
MLlib é uma biblioteca iterável de aprendizado de máquina para Apache Spark.
2. Fácil de usar
Disponível para linguagens Java, Scala, Python e R.
MLlib funciona com a API do Spark e interopera com as bibliotecas NumPy (começando no Spark 0.9) e R (começando no Spark 1.5) em Python. Você pode usar qualquer fonte de dados do Hadoop, como HDFS, HBase ou arquivos locais, facilitando a conexão ao fluxo de trabalho do Hadoop.
Caso:
//Chama MLib através de Python
dados = spark.read.format("libsvm").load("hdfs://...")
modelo = KMeans(k=10).fit(dados)
3. Execução eficiente
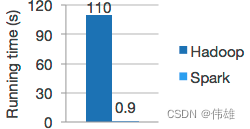
Algoritmo de alta qualidade, 100 vezes mais rápido que MapReduce.
O Spark é bom em cálculos iterativos, permitindo que o MLlib seja executado rapidamente. Ao mesmo tempo, nos concentramos no desempenho algorítmico: MLlib contém algoritmos de alta qualidade que utilizam iteração e podem produzir resultados melhores do que a aproximação de uma passagem às vezes usada no MapReduce. O modelo de dados do Hadoop e Spark é mostrado na figura abaixo.
4. Fácil de implantar
O Spark é executado em Hadoop, Apache Mesos, Kubernetes, autônomo ou na nuvem, visando diferentes fontes de dados.
Você pode executar o Spark usando seu modo de cluster independente, EC2, Hadoop YARN, Mesos ou Kubernetes. Acesse dados em HDFS, Apache Cassandra, Apache HBase, Apache Hive e centenas de outras fontes de dados.
5. Algoritmo
MLlib contém muitos algoritmos e utilitários.
Os algoritmos de ML incluem:
1. Classificação: regressão logística, Bayes ingênuo,….
2. Regressão: regressão linear generalizada, regressão de sobrevivência,….
3. Árvores de decisão, florestas aleatórias e árvores com gradiente aumentado.
4. Recomendação: Mínimos Quadrados Alternados (ALS).
5. Clustering: K-means, Mistura Gaussiana (GMM),….
6. Modelagem de tópicos: Alocação de Dirichlet Latente (LDA).
7. Conjuntos de itens frequentes, regras de associação e mineração sequencial de padrões.
As ferramentas de fluxo de trabalho de ML incluem:
1. Transformação de recursos: normalização, normalização, hash,….
2. Construção do pipeline de ML。
3. Avaliação do modelo e ajuste de hiperparâmetros.
4. Persistência de ML: salvando e carregando modelos e pipelines.
Outras ferramentas incluem:
Álgebra Linear Distribuída: SVD, PCA,….
Estatísticas: estatísticas resumidas, testes de hipóteses,….
6. Resumo
MLlib é uma biblioteca de aprendizado de máquina concorrente de alta velocidade construída no Spark, projetada especificamente para processamento de big data. É caracterizada pelo uso de cálculos iterativos e de análise de armazenamento de memória mais avançados, tornando o cálculo de dados e a velocidade de processamento muito maiores do que os dados comuns. .mecanismo de processamento.
A biblioteca de aprendizado de máquina MLlib ainda está sendo atualizada e os pesquisadores do Apache ainda estão adicionando mais algoritmos de aprendizado de máquina a ela. Atualmente, existem algoritmos gerais de aprendizagem e classes de ferramentas no MLlib, incluindo estatística, classificação, regressão, agrupamento, redução de dimensionalidade, etc.
MLlib é escrito na linguagem Scala. A linguagem Scala é uma linguagem de programação funcional que roda na JVM. É caracterizada por forte portabilidade. "Escreva uma vez, execute em qualquer lugar" é seu recurso mais importante. Com a ajuda do formato de entrada unificado de dados RDD, os usuários podem escrever programas de processamento de dados em diferentes IDEs. Depois de passar no teste de localização, eles podem ser executados diretamente no cluster após modificar ligeiramente os parâmetros operacionais. A obtenção de resultados é mais visual e intuitiva e não haverá diferenças ou alterações nos resultados devido a diferenças nas camadas subjacentes do sistema em execução.
2. Modelo de dados básico MLlib
1. Visão Geral
RDD é um formato de dados dedicado ao MLlib. Ele se refere às ideias de programação funcional Scala e introduz com ousadia o conceito de análise estatística para converter dados armazenados na forma de vetores e matrizes para armazenamento e cálculo. Dessa forma, os dados podem ser expressos quantitativamente. e com mais precisão.Agrupe e analise os resultados.
Vários tipos de dados
MLlib oferece suporte inerente a uma variedade de formatos de dados, desde o conjunto de dados Spark mais básico RDD até vetores e matrizes implantados no cluster. Da mesma forma, o MLlib também oferece suporte a formatos localizados implantados na máquina local.
A tabela a seguir fornece os tipos de dados suportados pelo MLlib.
| Digite o nome |
Definição |
| Vetor local |
Conjunto de vetores locais. Fornece principalmente ao Spark um conjunto de coletas de dados que podem ser operados |
| Ponto rotulado |
Rótulos vetoriais. Permitir que os usuários classifiquem diferentes coleções de dados |
| Matriz local |
matriz local. Combine dados e armazene em formato de matriz no computador local |
| Matriz distribuída |
Matriz distribuída. Armazene uma coleção de matrizes em um computador distribuído como uma matriz |
Os tipos de dados acima são suportados pelo MLlib. As matrizes distribuídas são divididas em quatro tipos diferentes de acordo com diferentes funções e cenários de aplicação.
2. Vetor local
O tipo de armazenamento localizado usado pelo MLlib é vetorial, e os vetores aqui são compostos principalmente de dois tipos: conjuntos de dados esparsos (sobressalentes) e conjuntos de dados densos (densos) . Por exemplo, dados vetoriais (9,5,2,7) podem ser armazenados como (9,5,2,7) de acordo com o formato de dados intensivo, e o conjunto de dados é armazenado como um conjunto como um todo. Para dados esparsos, eles podem ser armazenados como (4, Array(0,1,2,3), Array(9,5,2,7)) de acordo com o tamanho do vetor.
Caso número um:
importar org.apache.spark.{SparkConf,SparkContext}
def principal(args:Array[String]):Unit={
//--Criar vetores densos
//--dense pode ser entendido como um formulário de coleção dedicado ao MLlib, que é semelhante ao Array
val vd=Vetores.dense(2,0,6)//
imprimir(vd)
//①Referência: tamanho. O método sobressalente é decompor os dados fornecidos da matriz (9,5,2,7) em partes de tamanho especificado para processamento, neste caso são 7 partes
//③parâmetro: dados de entrada. Neste caso é Array(9,5,2,7)
//②Parâmetro: O subscrito correspondente aos dados de entrada deve ser incremental e o valor máximo deve ser menor ou igual ao tamanho
val vs=Vetores.sparse(7,Array(0,1,3,6),Array(9,5,2,7))
imprimir(vs(6))
}
}