1. Fundo
O que é uma tabela zipper? Quando o data warehouse é estabelecido, um importante método de processamento de dados da tabela pode ser usado para estruturar os dados em um algoritmo, análogo à tabela zipper no data warehouse, para resolver os requisitos de SCD no estabelecimento do data warehouse, então o que é SCD? É a dimensão de mudança lenta, conforme o tempo passa, os dados mudam lentamente em relação à tabela de fatos.
Os métodos de processamento comuns de SCD são os seguintes:
Mantenha o valor original
Cobertura direta
Adicionar nova coluna de atributo
Tabela de instantâneos
Mesa com zíper
Este artigo explica principalmente a mesa zíper para lidar com o problema do SCD, suas características estão resumidas a seguir, quando houver os seguintes cenários, pode-se usar a mesa zíper.
1. A quantidade de dados do medidor é grande e o medidor completo vai ocupar muito espaço de armazenamento
2. Os dados da tabela serão modificados, com tabelas incrementais, é difícil lidar com dados duplicados e modificados
3. Há uma necessidade de retrocesso e você precisa saber a quantidade total de dados em um determinado ponto da história
4. Os dados foram modificados, mas a frequência e a quantidade não são muito grandes, por exemplo, apenas uma parte por milhão foi modificada
2. Teoria de processamento da tabela Zipper
Em primeiro lugar, a tabela zíper é uma tabela em escala real e não uma tabela de partição. Para alcançar os vários efeitos descritos acima, uma tabela intermediária deve ser usada como um trampolim intermediário. A tabela trampolim intermediária é uma tabela de partição. Os dados são dados incrementais. O conteúdo incremental inclui modificações e adições geralmente create_time or update_timecaem no dia atual. Para a tabela zipper, dois campos que não têm nada a ver com os dados originais precisam ser adicionados para identificar a hora de início dos dados e o prazo efetivo. Por exemplo, essas duas datas são start_datee end_dateExistem três métodos principais de processamento para a tabela zipper: inicialização, atualização de dados todos os dias e reversão de dados.
2.1 Inicialização e novos dados
O método diário de rolagem é o seguinte:
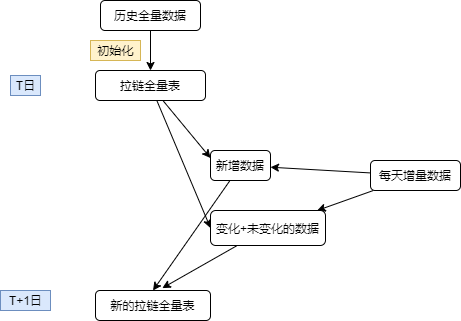
A parte de inicialização é o tempo de início da escala total do zíper e também define o primeiro tempo em que a reversão pode ser revertida. A lógica de atualização diária é mostrada na figura acima. Os novos dados serão divididos em dois partes, uma é os dados adicionados a cada dia, e a partição para o dia existem variações ou não o mesmo quando os dados são alterados, correspondendo respectivamente para modificar start_datee end_dateconseguir atualizar os dados.
2.1 Rollback de dados
Para a lógica de atualização acima, vamos considerar como reverter os dados, ou seja, retornar a um determinado ponto da história. Para a tabela zipper, é uma escala completa, portanto, há apenas uma reversão. A estratégia de reversão pode apontar para a reversão do tempo e geração de dados start_datee end_date, especificamente como reverter, examinamos o seguinte diagrama:
 Nos
Nos end_date < rollback_datedados a serem reservados para o processamento end_date ≥ rollback_date ≥ start_datedefinido end_datepara 9999-12-31, reverter os resultados, a fim de manter a integridade geral dos dados, os dados podem ser revertidos em um novo prendedor de mesa temporário.
3. Caixa de processamento de mesa com zíper
Para o DIM hierárquico comumente usado do data warehouse, ou seja, a camada de dimensão é o cenário comum da tabela zíper, aqui está um exemplo para ver como adicionar e reverter a tabela zíper.
A mesa de zíper é usada para realizar a tabela de dimensão do comerciante da camada DIM na análise de transação central e realizar a reversão da mesa de zíper.
3.1 Criar tabela e importar dados
A estrutura da tabela de dimensões do comerciante é a seguinte:
--创建商家信息表(增量表 分区表)
drop table if exists ods.ods_trade_shops;
create table ods.ods_trade_shops(
`shopid` int COMMENT '商铺ID',
`userid` int COMMENT '商铺负责人',
`areaid` int COMMENT '区域ID',
`shopname` string COMMENT '商铺名称',
`shoplevel` int COMMENT '商铺等级',
`status` int COMMENT '商铺状态',
`createtime` string COMMENT '创建日期',
`modifytime` string COMMENT '修改日期'
) COMMENT '商家信息表'
PARTITIONED BY (`dt` string)
row format delimited fields terminated by ',';
-- 创建商家信息维表
drop table if exists dim.dim_trade_shops;
create table dim.dim_trade_shops(
`shopid` int COMMENT '商铺ID',
`userid` int COMMENT '商铺负责人',
`areaid` int COMMENT '区域ID',
`shopname` string COMMENT '商铺名称',
`shoplevel` int COMMENT '商铺等级',
`status` int COMMENT '商铺状态',
`createtime` string COMMENT '创建日期',
`modifytime` string COMMENT '修改日期',
`startdate` string COMMENT '生效起始日期',
`enddate` string COMMENT '失效结束日期'
) COMMENT '商家信息表';
Importe os seguintes dados de teste:
/root/data/shop-2020-11-20.dat
100050,1,100225,WSxxx营超市,1,1,2020-06-28,2020-11-20 13:22:22
100052,2,100236,新鲜xxx旗舰店,1,1,2020-06-28,2020-11-20 13:22:22
100053,3,100011,华为xxx旗舰店,1,1,2020-06-28,2020-11-20 13:22:22
100054,4,100159,小米xxx旗舰店,1,1,2020-06-28,2020-11-20 13:22:22
100055,5,100211,苹果xxx旗舰店,1,1,2020-06-28,2020-11-20 13:22:22
/root/data/shop-2020-11-21.dat
100057,7,100311,三只xxx鼠零食,1,1,2020-06-28,2020-11-21 13:22:22
100058,8,100329,良子xxx铺美食,1,1,2020-06-28,2020-11-21 13:22:22
100054,4,100159,小米xxx旗舰店,2,1,2020-06-28,2020-11-21 13:22:22
100055,5,100211,苹果xxx旗舰店,2,1,2020-06-28,2020-11-21 13:22:22
/root/data/shop-2020-11-22.dat
100059,9,100225,乐居xxx日用品,1,1,2020-06-28,2020-11-22 13:22:22
100060,10,100211,同仁xxx大健康,1,1,2020-06-28,2020-11-22 13:22:22
100052,2,100236,新鲜xxx旗舰店,1,2,2020-06-28,2020-11-22 13:22:22
load data local inpath '/root/data/shop-2020-11-20.dat' overwrite into table ods.ods_trade_shops partition(dt='2020-11-20');
load data local inpath '/root/data/shop-2020-11-21.dat' overwrite into table ods.ods_trade_shops partition(dt='2020-11-21');
load data local inpath '/root/data/shop-2020-11-22.dat' overwrite into table ods.ods_trade_shops partition(dt='2020-11-22');

3.2 Inicialização da mesa Zipper
Supondo que os dados do primeiro dia sejam todos dados históricos
INSERT OVERWRITE TABLE dim.dim_trade_shops
SELECT shopid,
userid,
areaid,
shopname,
shoplevel,
status,
createtime,
modifytime,
CASE
WHEN modifytime IS NOT NULL THEN substr(modifytime, 0, 10)
ELSE substr(createtime, 0, 10)
END AS startdate,
'9999-12-31' AS enddate
FROM ods.ods_trade_shops
WHERE dt ='2020-11-20';3.3 Atualizar tabela zíper
Para tabelas incrementais, a lógica geral é, create_timeou a modifytimeinterceptação da partição do dia dt, modifytimemaior ou igual a create_time, pegue os dois primeiros
INSERT OVERWRITE TABLE dim.dim_trade_shops
SELECT shopid,
userid,
areaid,
shopname,
shoplevel,
status,
createtime,
modifytime,
CASE
WHEN modifytime IS NOT NULL THEN substr(modifytime, 0, 10)
ELSE substr(createtime, 0, 10)
END AS startdate,
'9999-12-31' AS enddate
FROM ods.ods_trade_shops
WHERE dt = '2020-11-21'
UNION ALL
SELECT b.shopid,
b.userid,
b.areaid,
b.shopname,
b.shoplevel,
b.status,
b.createtime,
b.modifytime,
b.startdate,
CASE
WHEN a.shopid IS NOT NULL
AND b.enddate ='9999-12-31' THEN date_add('2020-11-21', -1)
ELSE b.enddate
END AS enddate
FROM
(SELECT *
FROM ods.ods_trade_shops
WHERE dt='2020-11-21') a
RIGHT JOIN dim.dim_trade_shops b ON a.shopid = b.shopid;O script para carregar a tabela zipper é o seguinte:
dim_load_shops.sh
#!/bin/bash
source /etc/profile
if [ -n "$1" ]
then
do_date=$1
else
do_date=`date -d "-1 day" +%F`
fi
sql="
INSERT OVERWRITE TABLE dim.dim_trade_shops
SELECT shopid,
userid,
areaid,
shopname,
shoplevel,
status,
createtime,
modifytime,
CASE
WHEN modifytime IS NOT NULL THEN substr(modifytime, 0, 10)
ELSE substr(createtime, 0, 10)
END AS startdate,
'9999-12-31' AS enddate
FROM ods.ods_trade_shops
WHERE dt = '$do_date'
UNION ALL
SELECT b.shopid,
b.userid,
b.areaid,
b.shopname,
b.shoplevel,
b.status,
b.createtime,
b.modifytime,
b.startdate,
CASE
WHEN a.shopid IS NOT NULL
AND b.enddate ='9999-12-31' THEN date_add('$do_date', -1)
ELSE b.enddate
END AS enddate
FROM
(SELECT *
FROM ods.ods_trade_shops
WHERE dt='$do_date') a
RIGHT JOIN dim.dim_trade_shops b ON a.shopid = b.shopid;
"
hive -e "$sql"Você pode executar este script para carregar 2020-12-22os dados,sh dim_load_shops.sh 2020-12-22

3.4 Reverta a mesa do zíper para um determinado ponto no tempo
Primeiro crie uma tabela temporária tmp.shops_tmppara colocar os dados revertidos
DROP TABLE IF EXISTS tmp.shops_tmp;
CREATE TABLE IF NOT EXISTS tmp.tmp_shops AS
SELECT shopid,
userid,
areaid,
shopname,
shoplevel,
status,
createtime,
modifytime,
startdate,
enddate
FROM dim.dim_trade_shops
WHERE enddate < '2020-11-21'
UNION ALL
SELECT shopid,
userid,
areaid,
shopname,
shoplevel,
status,
createtime,
modifytime,
startdate,
'9999-12-31' AS enddate
FROM dim.dim_trade_shops
WHERE startdate <= '2020-11-21'
AND enddate >= '2020-11-21';
INSERT OVERWRITE TABLE dim.dim_trade_shops
SELECT *
FROM tmp.tmp_shops;O script de rollback é semelhante ao script de atualização, contanto que o sql nele seja atualizado, ele não será repetido aqui. Wu Xie, Xiao San Ye, um pequeno novato no fundo, big data e inteligência artificial. Por favor, preste atenção a mais