O Apache Spark nasceu originalmente no laboratório APM da Universidade da Califórnia, Berkeley, em 2009, e teve o código aberto em 2010. É agora um dos principais projetos de código aberto da Apache Software Foundation. O objetivo do Spark é projetar um modelo de programação que possa realizar análises de dados rapidamente. O Spark fornece computação de memória e reduz a sobrecarga de E / S. Além disso, o Spark é escrito com base em Scala, fornecendo uma experiência de programação interativa. Após 10 anos de desenvolvimento, o Spark se tornou uma plataforma de processamento de big data importante e a versão mais recente é o Spark3.0. Este artigo é principalmente para fornecer uma visão geral do Spark, e o conteúdo de acompanhamento discutirá detalhes específicos. O conteúdo principal deste artigo inclui:
- Análise de atenção do Spark
- Recursos do Spark
- Alguns conceitos importantes do Spark
- Visão geral dos componentes do Spark
- Visão geral da arquitetura operacional do Spark
- Primeira experiência de programação Spark
Análise de interesse do Spark
Visão geral
A figura abaixo mostra as tendências de pesquisa doméstica para Spark, Hadoop e Flink no ano passado
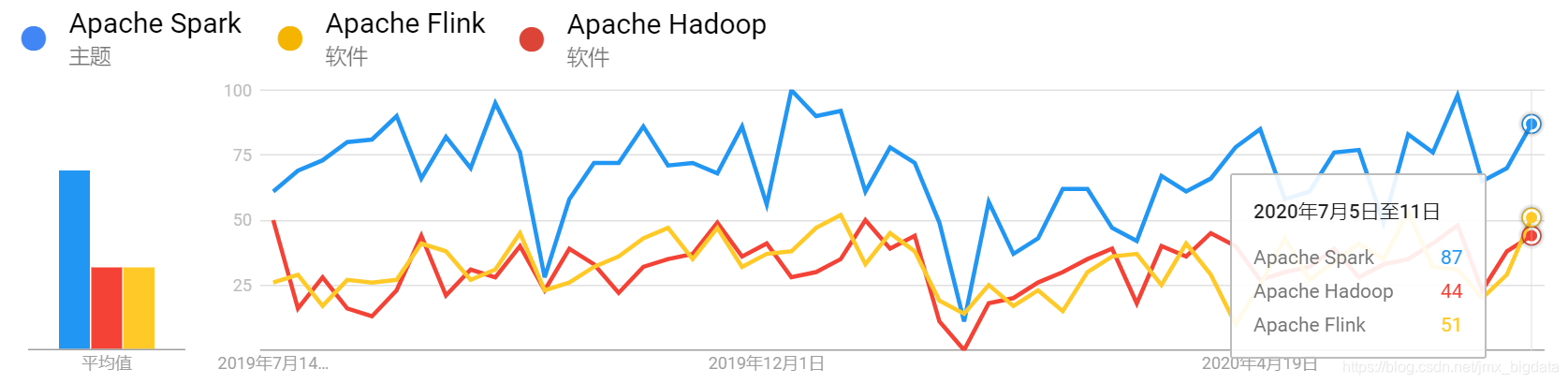
As tendências de pesquisa globais para Spark, Hadoop e Flink no ano passado são as seguintes:

Distribuição regional do interesse de pesquisa doméstico no Spark, Hadoop e Flink no ano passado (em ordem decrescente do interesse de pesquisa no Flink):

Distribuição regional do interesse de pesquisa global no Spark, Hadoop e Flink no ano passado (em ordem decrescente do interesse de pesquisa no Flink):

análise
Pode-se ver pelas 4 fotos acima que no ano passado, seja nacional ou globalmente, o interesse de pesquisa por Spark sempre foi maior do que por Hadoop e Flink. Nos últimos anos, o Flink se desenvolveu rapidamente. É endossado por Ali na China. As características naturais de processamento de fluxo de Flink o tornam a estrutura preferida para o desenvolvimento de aplicativos de fluxo. Pode-se ver que embora o Flink seja muito popular na China, ainda não é tão popular quanto o Spark no mundo. Portanto, aprender e dominar a tecnologia Spark ainda é uma boa escolha. A tecnologia tem muitas semelhanças. Se você dominou o Spark e aprendeu o Flink, acredito que se sentirá familiarizado.
Recursos do Spark
-
alta velocidade
Apache Spark usa agendador DAG, otimizador de consulta e mecanismo de execução física para fornecer alto desempenho para processamento em lote e fluxo.
-
Fácil de usar
Suporta o uso de Java, Scala, Python, R e SQL para escrever aplicativos rapidamente. O Spark oferece mais de 80 operadores de operação avançada para construir facilmente aplicativos paralelos.
-
Versatilidade
O Spark fornece uma pilha ecológica muito rica, incluindo componentes como consulta SQL, computação de fluxo, aprendizado de máquina e computação gráfica. Esses componentes podem ser integrados perfeitamente em um aplicativo e, por meio de implantação completa, pode lidar com uma variedade de cenários de computação complexos
-
Vários modos de operação
O Spark pode ser executado no modo autônomo ou em ambientes como Hadoop, Apache Mesos e Kubernetes. E você pode acessar dados de várias fontes de dados, como HDFS, Alluxio, Apache Cassandra, Apache HBase e Apache Hive.
Alguns conceitos importantes do Spark
-
RDD
Conjunto de dados distribuído resiliente, um conceito abstrato de memória distribuída, fornece um modelo de memória compartilhada altamente restrito
-
DIA
Gráfico acíclico direcionado, refletindo a dependência entre RDDs
-
Inscrição
Programa escrito pelo usuário do Spark, o programa do driver e a composição dos executores
-
Jar aplicativo
pacote JAR aplicação escrita pelo usuário -
O programa do driver
usa o processo da função main () do programa para criar SparkContext -
O gerenciador de
cluster gerenciador de cluster é um serviço externo usado para alocação de solicitação de recursos (como gerenciador autônomo, Mesos, YARN) -
Modo de implantação
O modo de implantação determina onde o processo do driver é executado. Se for o modo de cluster , o próprio framework iniciará o processo do Driver em uma máquina dentro do cluster. Se estiver em modo cliente , o processo do Driver será iniciado na máquina onde o programa é submetido
-
Nó de trabalho
O nó Executor que executa a aplicação no cluster é um processo executado no nó Worknode, responsável por executar tarefas específicas e armazenar dados para a aplicação
-
Unidade de tarefa de trabalho em execução no executor -
Trabalho
Um trabalho contém vários RDDs e uma série de operações do operador em execução no RDD. O trabalho precisa ser acionado por operações de ação (como salvar, coletar etc.) -
Estágio
Cada trabalho é dividido por um estágio composto de uma tarefa em série que seria o estágio de interdependência
Visão geral dos componentes do Spark
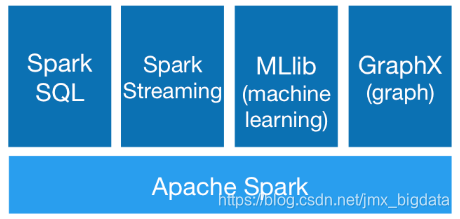
O ecossistema Spark inclui principalmente componentes como Spark Core, SparkSQL, SparkStreaming, MLlib e GraphX, conforme mostrado na figura a seguir:
-
Spark Core
O núcleo do Spark é o núcleo do Spark, incluindo as funções básicas do Spark, como computação de memória, agendamento de tarefas, modo de implantação, gerenciamento de armazenamento, etc. SparkCore fornece uma API baseada em RDD que é a base de outras APIs de alto nível e sua função principal é implementar o processamento em lote.
-
Spark SQL
Spark SQL é projetado para processar dados estruturados e semiestruturados.O SparkSQL permite que os usuários consultem dados estruturados usando SQL, DataFrame e DataSetAPI em programas Spark e suporta as linguagens Java, Scala, Python e R. Como a API DataFrame fornece uma maneira unificada de acessar várias fontes de dados (incluindo Hive, Avro, Parquet, ORC e JDBC), os usuários podem se conectar a qualquer fonte de dados da mesma maneira. Além disso, o Spark SQL pode usar os metadados do hive, conseguindo assim uma integração perfeita com o Hive. Os usuários podem executar trabalhos do Hive diretamente no Spark. O Spark SQL pode ser acessado por meio de comandos shell spark-sql .
-
SparkStreaming
SparkStreaming é um módulo muito importante do Spark, que pode realizar a escalabilidade, alto rendimento e processamento de fluxo tolerante a falhas de fluxos de dados em tempo real. Internamente, seu método de trabalho é dividir o fluxo de dados de entrada em tempo real em uma série de microlotes, que são então processados pelo mecanismo Spark. SparkStreaming oferece suporte a várias fontes de dados, como kafka, Flume e soquetes TCP, etc.
-
MLlib
MLlib é uma biblioteca de aprendizado de máquina fornecida pelo Spark. Os usuários podem usar a API Spark para criar um aplicativo de aprendizado de máquina. O Spark é particularmente bom em computação iterativa e seu desempenho é 100 vezes maior que o do Hadoop. A lib contém algoritmos de aprendizado de máquina comuns, como regressão logística, máquina de vetores de suporte, classificação, agrupamento, regressão, floresta aleatória, filtragem colaborativa, análise de componente principal, etc.
-
GraphX
GraphX é uma API para computação gráfica no Spark. Pode ser considerada como uma reescrita e otimização do Pregel no Spark. GraphX tem bom desempenho, funções e operadores ricos e pode executar algoritmos gráficos complexos livremente em grandes quantidades de dados. O GraphX tem muitos algoritmos de gráfico integrados, como o famoso algoritmo PageRank.
Visão geral da arquitetura operacional do Spark
Em geral, a arquitetura do aplicativo Spark inclui as seguintes partes principais:
- Programa de motorista
- Nó mestre
- Nó de trabalho
- Executor
- Tarefas
- SparkContext
No modo autônomo , a arquitetura em execução é mostrada na figura abaixo:
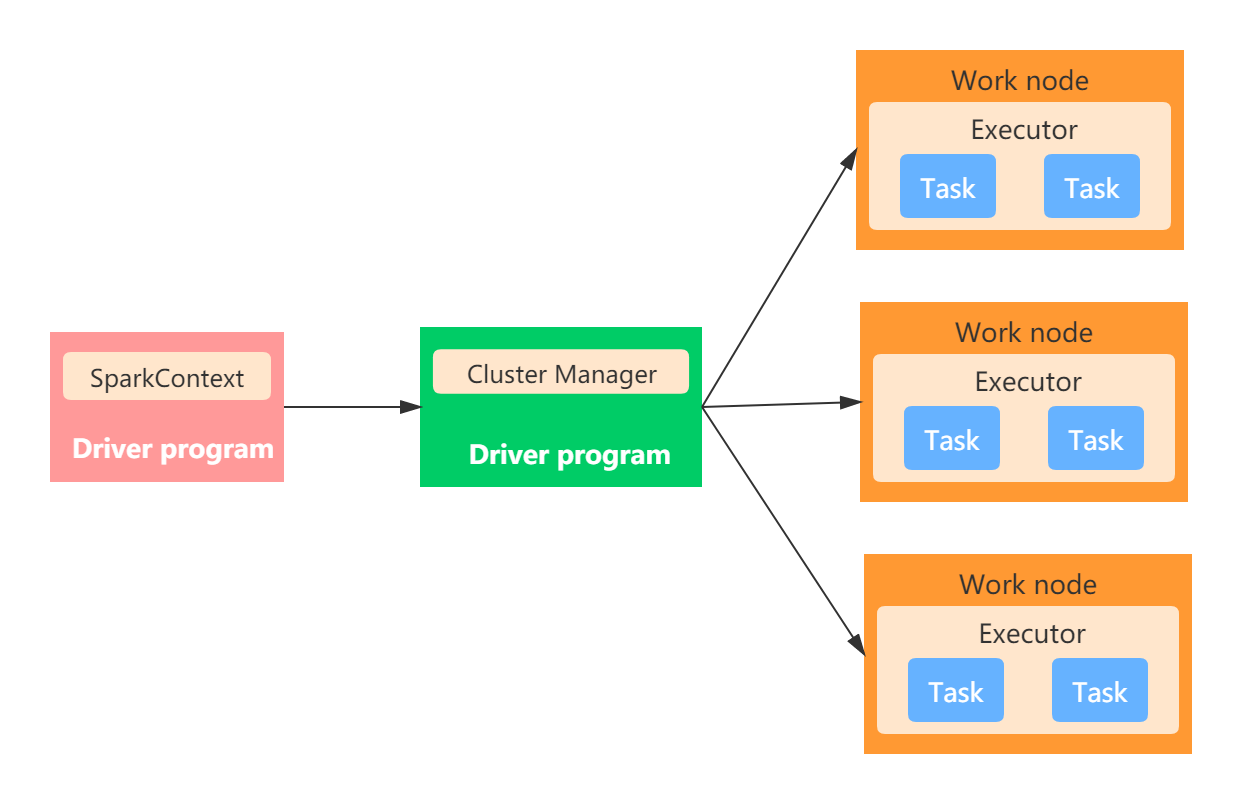
Programa de motorista
O programa do driver é a função main () do aplicativo Spark (crie uma sessão SparkContext e Spark). O nó que executa o processo do Driver é chamado de nó do Driver. O processo do Driver se comunica com o Gerenciador de Cluster e envia as tarefas agendadas ao Executor.
Gerenciador de clusters
É chamado de gerenciador de cluster e é usado principalmente para gerenciar o cluster. Os gerenciadores de cluster comuns incluem YARN, Mesos e Standalone. Os gerenciadores de cluster independentes incluem dois processos de segundo plano de longa execução, um dos quais está no nó Mestre e o outro está no nó Trabalho. No artigo de acompanhamento do modo de implantação de cluster, discutiremos o conteúdo desta parte em detalhes, aqui está uma impressão geral.
Nó de trabalho
Amigos que estão familiarizados com o Hadoop devem saber que o Hadoop inclui nós de namenode e datanode. O Spark é semelhante e chama o nó que executa tarefas específicas. O nó irá relatar os recursos disponíveis do nó atual para o nó Mestre. Normalmente, um processo de trabalho em segundo plano é iniciado em cada nó de trabalho para iniciar e monitorar o Executor.
Executor
O nó mestre aloca recursos, usa o nó Trabalho no cluster para criar um Executor e o Driver usa esses Executores para alocar e executar tarefas específicas. Cada aplicativo tem seu próprio processo Executor, que usa vários threads para executar tarefas específicas. O Executor é o principal responsável por executar tarefas e salvar dados.
Tarefa
Tarefa é a unidade de trabalho enviada ao Executor
SparkContext
SparkContext é a entrada para uma sessão Spark e é usado para se conectar a um cluster Spark. Antes de enviar um aplicativo, você primeiro precisa inicializar o SparkContext. SparkContext implica em comunicação de rede, sistema de armazenamento, mecanismo de computação, WebUI e outros conteúdos. É importante notar que só pode haver um SparkContext em um processo JVM. Se você deseja criar um novo SparkContext, é necessário chamar o método stop () no SparkContext original.
Teste de programação do Spark
Implementação Spark de agrupamento e caso topN
Descrição : existe um arquivo order.txt para dados do pedido no HDFS. O campo do arquivo tem um símbolo de segmentação ",", onde os campos indicam a id do pedido, da mercadoria e o valor da transação, por sua vez. Os dados de amostra são os seguintes:
Order_00001,Pdt_01,222.8
Order_00001,Pdt_05,25.8
Order_00002,Pdt_03,522.8
Order_00002,Pdt_04,122.4
Order_00002,Pdt_05,722.4
Order_00003,Pdt_01,222.8
Pergunta : Use o sparkcore para encontrar a id do produto com o maior giro em cada pedido
Código de implementação
import org.apache.spark.sql.Row
import org.apache.spark.sql.hive.HiveContext
import org.apache.spark.sql.types.{StringType, StructField, StructType}
import org.apache.spark.{SparkConf, SparkContext}
object TopOrderItemCluster {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setAppName("top n order and item")
val sc = new SparkContext(conf)
val hctx = new HiveContext(sc)
val orderData = sc.textFile("data.txt")
val splitOrderData = orderData.map(_.split(","))
val mapOrderData = splitOrderData.map { arrValue =>
val orderID = arrValue(0)
val itemID = arrValue(1)
val total = arrValue(2).toDouble
(orderID, (itemID, total))
}
val groupOrderData = mapOrderData.groupByKey()
/**
***groupOrderData.foreach(x => println(x))
***(Order_00003,CompactBuffer((Pdt_01,222.8)))
***(Order_00002,CompactBuffer((Pdt_03,522.8), (Pdt_04,122.4), (Pdt_05,722.4)))
***(Order_00001,CompactBuffer((Pdt_01,222.8), (Pdt_05,25.8)))
*/
val topOrderData = groupOrderData.map(tupleData => {
val orderid = tupleData._1
val maxTotal = tupleData._2.toArray.sortWith(_._2 > _._2).take(1)
(orderid, maxTotal)
}
)
topOrderData.foreach(value =>
println("最大成交额的订单ID为:" + value._1 + " ,对应的商品ID为:" + value._2(0)._1)
/**
***最大成交额的订单ID为:Order_00003 ,对应的商品ID为:Pdt_01
***最大成交额的订单ID为:Order_00002 ,对应的商品ID为:Pdt_05
***最大成交额的订单ID为:Order_00001 ,对应的商品ID为:Pdt_01
*/
)
//构造出元数据为Row的RDD
val RowOrderData = topOrderData.map(value => Row(value._1, value._2(0)._1))
//构建元数据
val structType = StructType(Array(
StructField("orderid", StringType, false),
StructField("itemid", StringType, false))
)
//转换成DataFrame
val orderDataDF = hctx.createDataFrame(RowOrderData, structType)
// 将数据写入Hive
orderDataDF.registerTempTable("tmptable")
hctx.sql("CREATE TABLE IF NOT EXISTS orderid_itemid(orderid STRING,itemid STRING) ROW FORMAT DELIMITED FIELDS TERMINATED BY '\\t'")
hctx.sql("INSERT INTO orderid_itemid SELECT * FROM tmptable")
}
}
Empacote o código acima e envie-o ao cluster para execução. Você pode inserir o shell hive cli ou spark-sql para visualizar os dados no Hive.
Resumindo
Este artigo apresenta principalmente o Spark como um todo, incluindo a análise de popularidade de pesquisa do Spark, os principais recursos do Spark, alguns conceitos importantes do Spark e a arquitetura de execução do Spark e, finalmente, é fornecido um caso de programação do Spark. Este artigo é o primeiro compartilhado pela série Spark. Você pode primeiro ter uma ideia da perspectiva global do Spark. O próximo artigo compartilhará o guia de programação do Spark Core.
