Índice
2. Arquitetura e componentes do cluster k8s
1.2Gerenciador de controlador Kube
3. Configurar centro de armazenamento
3. Fluxo de trabalho de criação de pod em k8s
4.Seletor de etiqueta (seletor de etiqueta)
Informações de configuração de recursos 9.k8s:
1. Introdução ao Kubernetes
kubernetes, conhecido como k8s (k12345678s). Um sistema de código aberto para implantação, dimensionamento e gerenciamento automático de "aplicativos em contêineres". Pode-se entender que K8S é um cluster responsável pela operação e manutenção automatizada de múltiplos programas conteinerizados (como Docker), sendo uma ferramenta de framework de orquestração de contêineres com um ecossistema extremamente rico.
K8S é o sistema de gerenciamento de cluster de contêiner de código aberto do Google. Baseado em tecnologias de contêiner como Docker, ele fornece uma série de funções completas, como implantação e operação, agendamento de recursos, descoberta de serviços e escalonamento dinâmico para aplicativos em contêineres, melhorando a eficiência de aplicativos em grande escala. gerenciamento de cluster de contêineres. Conveniência.
1.A origem do k8s
K8S é baseado no sistema Borg do Google (sistema Borg, uma ferramenta de orquestração de contêineres em grande escala usada internamente pelo Google) como protótipo, sendo posteriormente reescrito usando as ideias de Borg na linguagem GO e doado à Fundação CNCF para código aberto.
A Cloud Native Foundation (CNCF) foi criada em dezembro de 2015 e é afiliada à Linux Foundation. O primeiro projeto incubado pela CNCF foi o Kubernetes.Com o uso generalizado de contêineres, o Kubernetes se tornou o padrão de fato para ferramentas de orquestração de contêineres.
Site oficial: Kubernetes
GitHub: GitHub - kubernetes/kubernetes: agendamento e gerenciamento de contêineres de nível de produção
2. Por que usar o k8s?
Imagine o método tradicional de implantação de back-end: coloque o pacote do programa (incluindo arquivos binários executáveis, arquivos de configuração, etc.) no servidor, execute o script de inicialização para executar o programa e, ao mesmo tempo, inicie o script daemon regularmente verifique o status de execução do programa e reinicie se necessário. Abra o programa.
Imagine, e se o número de solicitações de serviço aumentar e o serviço implantado não puder responder? A abordagem tradicional geralmente é que, se o volume de solicitação, a memória e a CPU excederem o limite e um alarme for emitido, o pessoal de operação e manutenção adicionará imediatamente mais alguns servidores. Após a implantação do serviço, eles se conectarão ao balanceamento de carga para compartilhar a pressão dos serviços existentes.
Surge um problema: desde o monitoramento de alarmes até a implantação de serviços, é necessária intervenção humana! Então, existe uma maneira de implantar, atualizar, desinstalar, expandir e reduzir serviços automaticamente?
E é isso que o K8S tem que fazer: automatizar o gerenciamento de operação e manutenção de programas conteinerizados (Docker).
3. Principais funções do k8s
- Orquestre contêineres entre hosts.
- Faça uso mais completo dos recursos de hardware para maximizar as necessidades dos aplicativos empresariais.
- Controle e automatize a implantação e atualizações de aplicativos.
- Monte e adicione armazenamento para aplicativos com estado.
- Dimensione aplicativos em contêineres e seus recursos on-line.
- O gerenciamento declarativo de contêineres garante que os aplicativos implantados operem de acordo com a forma como os implantamos.
- Realize a verificação do status do aplicativo e a autocorreção por meio de layout automático, reinicialização automática, replicação automática e escalonamento automático.
- Fornece descoberta de serviço e balanceamento de carga para vários contêineres, eliminando a necessidade de os usuários considerarem problemas de IP do contêiner.
2. Arquitetura e componentes do cluster k8s
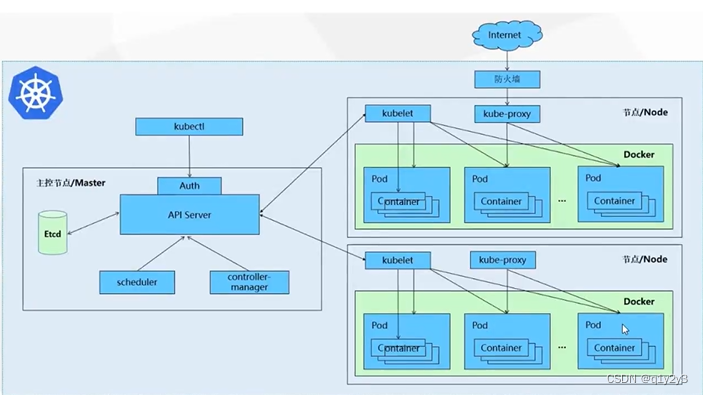
K8S pertence ao modelo de dispositivo mestre-escravo (arquitetura Mestre-Escravo), ou seja, o nó Mestre é responsável pelo agendamento, gerenciamento, operação e manutenção do cluster, e o nó Escravo é o nó de carga de trabalho de computação no cluster .
No K8S, o nó principal é geralmente chamado de nó Mestre, e o nó escravo é chamado de Nó de Trabalho. Cada nó receberá alguma carga de trabalho do Mestre.
O componente Master pode ser executado em qualquer computador do cluster, mas é recomendado que o nó Master ocupe um servidor separado. Como o Master é o cérebro de todo o cluster, se o nó onde o Master está localizado falhar ou ficar indisponível, todos os comandos de controle se tornarão inválidos. Além do Master, outras máquinas no cluster K8S são chamadas de Worker Nodes. Quando um Node fica inativo, a carga de trabalho nele será automaticamente transferida para outros nós pelo Master.
1. Componentes mestres
1.1Apiserver Kube
Usado para expor a API Kubernetes. Qualquer solicitação de recurso ou operação de chamada é realizada por meio da interface fornecida por kube-apiserver. A API HTTP Restful é usada para fornecer serviços de interface. Todas as operações de adição, exclusão, modificação, consulta e monitoramento de recursos de objeto são entregues ao servidor API para processamento e depois enviadas ao armazenamento Etcd.
Pode-se entender que o API Server é o serviço de entrada de solicitações do K8S. O API Server é responsável por receber todas as solicitações K8S (da interface UI ou ferramenta de linha de comando CLI) e, em seguida, notificar outros componentes para funcionarem de acordo com as solicitações específicas do usuário. Pode-se dizer que o API Server é o cérebro da arquitetura do cluster K8S.
1.2Gerenciador de controlador Kube
O controlador de gerenciamento de operações é um processo em segundo plano que lida com tarefas regulares no cluster K8S.É o centro de controle automatizado para todos os objetos de recursos no cluster K8S.
Em um cluster K8S, um recurso corresponde a um controlador, e o gerenciador do controlador é responsável por gerenciar esses controladores.
Tipos de controladores:
- Controlador de nó: Responsável por detectar e responder a falhas de nó.
- Controlador de replicação: Responsável por garantir que o número de cópias do Pod associadas a um RC (controlador de replicação de objeto de recurso) no cluster sempre mantenha o valor predefinido. Pode ser entendido como uma garantia de que existem e existem apenas N instâncias de Pod no cluster, onde N é o número de cópias de Pod definidas em RC.
- Controlador de endpoints: preenche objetos de endpoint (ou seja, conecta serviços e pods) e é responsável por monitorar alterações em serviços e cópias de pods correspondentes. Pode-se entender que um endpoint é um ponto de acesso exposto por um serviço, se você precisar acessar um serviço, deverá conhecer seu endpoint.
- Controladores de conta de serviço e token: crie contas padrão e tokens de acesso de API para novos namespaces.
- Controlador ResourceQuota (Controlador de Quota de Recursos): Certifique-se de que o objeto de recurso especificado não ocupe excessivamente os recursos físicos do sistema em nenhum momento.
- Controlador de namespace: gerencia o ciclo de vida de um namespace.
- Controlador de Serviço (Service Controller): Pertence a um controlador de interface entre o cluster K8S e a plataforma de nuvem externa.
1.3 Agendador Kube
É o processo responsável pelo agendamento de recursos e seleciona um nó Node adequado para o Pod recém-criado de acordo com o algoritmo de agendamento.
Pode ser entendido como o agendador de todos os nós do nó K8S. Quando um usuário deseja implantar um serviço, o Agendador selecionará o Node mais apropriado para implantar o Pod com base no algoritmo de agendamento.
- Estratégia de predicado (predicado)
- estratégia preferida (prioridades)
O servidor API recebe a solicitação para criar um lote de pods. O servidor API solicitará ao gerente do controlador para criar pods de acordo com o modelo predefinido. O gerente do controlador irá ao agendador através do servidor API para selecionar o nó mais adequado nó para o pod recém-criado. Por exemplo, a execução deste pod requer recursos 2C4G, e o Agendador filtrará os nós do Node que não atendem à política por meio da política de pré-seleção. Os recursos restantes no nó Node são relatados ao servidor API e armazenados no etcd. O servidor API chamará um método para encontrar os recursos restantes de todos os nós Node no etcd e, em seguida, compará-los-á com os recursos exigidos pelo pod. Se um nó do nó tem recursos insuficientes Ou se você não atender às condições da estratégia de pré-seleção, não conseguirá passar na pré-seleção. Os nós selecionados na fase de pré-seleção serão pontuados e classificados de acordo com a estratégia de otimização na fase de pré-seleção, sendo selecionado o nó com maior pontuação. Por exemplo, um Node com recursos mais ricos e carga menor pode ter uma classificação mais elevada.
2. Componentes do nó
2.1 O cubo
O monitor do nó Node e o comunicador com o nó Master. Kubelet é o "delineador" do nó Mestre instalado no nó Nó. Ele reportará regularmente ao Servidor API o status dos serviços em execução em seu nó Nó e aceitará instruções do nó Mestre para tomar medidas de ajuste.
Obtenha o status esperado do pod em seu próprio nó do nó mestre (como qual contêiner executar, o número de réplicas em execução, como configurar a rede ou armazenamento, etc.) e interaja diretamente com o mecanismo de contêiner para implementar o gerenciamento do ciclo de vida do contêiner. Se o status do pod em seu próprio nó for diferente de Se o estado esperado for inconsistente, chame a interface da plataforma do contêiner correspondente (ou seja, a interface do docker) para atingir esse estado.
Gerencie a limpeza de imagens e contêineres para garantir que as imagens nos nós não ocupem espaço em disco e que os contêineres encerrados não ocupem muitos recursos.
Resumo:
Em um cluster Kubernetes, um processo de serviço kubelet é iniciado em cada nó (também conhecido como nó de trabalho). Este processo é usado para processar tarefas atribuídas pelo Master a este nó e gerenciar Pods e contêineres nos Pods. Cada processo kubelet registrará as próprias informações do nó no servidor API, relatará regularmente o uso dos recursos do nó ao mestre e monitorará os recursos do contêiner e do nó por meio do cAdvisor.
2.2Proxy Kube
O proxy de rede Pod é implementado em cada nó Node, que é o portador dos recursos do Serviço Kubernetes e é responsável por manter as regras de rede e o balanceamento de carga de quatro camadas. Responsável por escrever regras em iptables e ipvs para implementar mapeamento de acesso ao serviço.
O Kube-Proxy em si não fornece diretamente uma rede para pods. A rede do pod é fornecida pelo Kubelet. Na verdade, o Kube-Proxy mantém uma rede de cluster de pod virtual.
Kube-apiserver atualiza o serviço Kubernetes e mantém endpoints monitorando Kube-Proxy.
O balanceamento de carga de microsserviços no cluster K8S é implementado pelo Kube-proxy. Kube-proxy é o balanceador de carga dentro do cluster K8S. É um servidor proxy distribuído que executa um componente proxy Kube em cada nó do K8S.
2.3 docker ou foguete
O mecanismo de contêiner executa o contêiner e é responsável pela criação e gerenciamento local do contêiner.
Quando o kubernetes agenda um pod para um nó, o kubelet no nó instrui o docker a iniciar um contêiner específico. Em seguida, o kubelet coletará continuamente informações do contêiner por meio do docker e as enviará ao nó mestre. O Docker extrairá a imagem do contêiner e iniciará ou interromperá o contêiner normalmente. A única diferença é que isso é controlado por um sistema automatizado, em vez de ser executado manualmente por um administrador em cada nó.
3. Configurar centro de armazenamento
3.1etcd
Serviço de armazenamento K8S. etcd é um sistema de armazenamento de valor-chave distribuído que armazena configurações de chave e configurações de usuário do K8S. Somente o servidor API no K8S tem permissões de leitura e gravação, e outros componentes devem passar pela interface do servidor API para ler e gravar dados.
3. Fluxo de trabalho de criação de pod em k8s
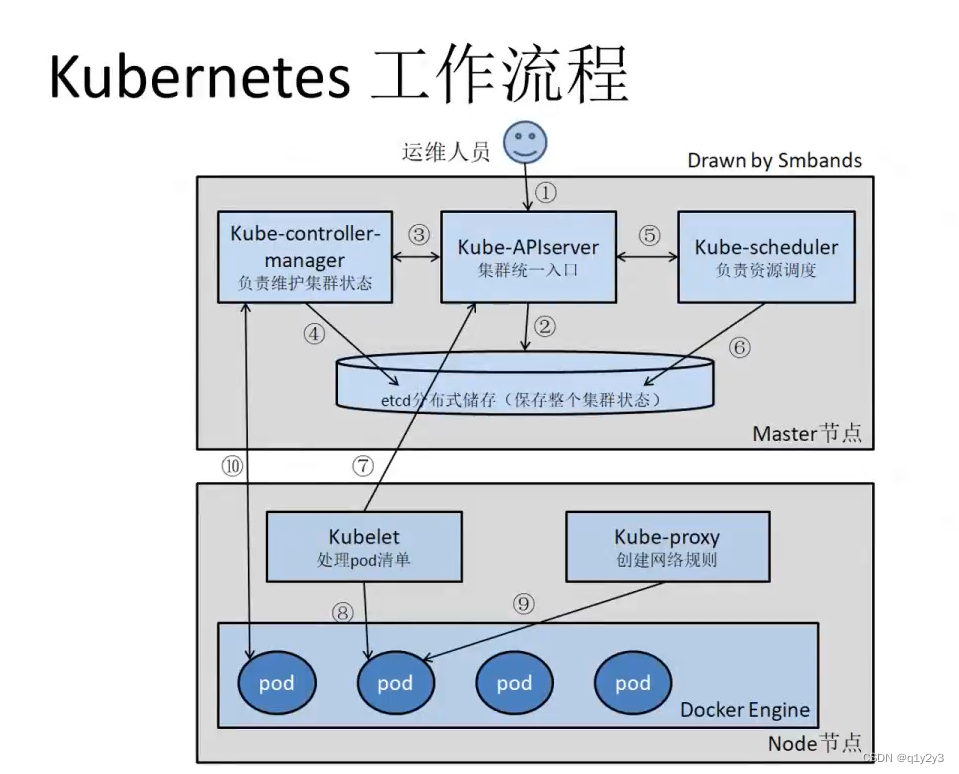
- O usuário envia uma solicitação para criar um pod ao apiserver no nó mestre por meio do cliente.
- O apiserver primeiro gravará as informações da solicitação no etcd e as salvará e, em seguida, encontrará o controller-manager para criar recursos do Pod de acordo com o modelo de configuração de recurso predefinido.
- Em seguida, o gerenciador do controlador irá até o agendador por meio do apiserver para selecionar o nó mais apropriado para o pod recém-criado.
- O escalonador seleciona os nós mais adequados para escalonamento por meio da estratégia de pré-seleção e estratégia de otimização do algoritmo de escalonamento.
- Em seguida, encontre o kubelet no nó correspondente por meio do apiserver para criar e gerenciar pods.
- kubelet irá interagir com o mecanismo de contêiner para gerenciar o ciclo de vida do Pod/contêiner
- Os usuários também podem escrever regras de rede no kube-proxy por meio do apiserver, criar recursos de serviço e realizar descoberta de serviço e balanceamento de carga de pods.
4. O conceito central do k8s
Kubernetes contém muitos tipos de objetos de recursos: Pod, Label, Service, Replication Controller, etc.
Todos os objetos de recursos podem ser adicionados, excluídos, modificados, verificados, etc. por meio da ferramenta kubectl fornecida pelo Kubernetes e armazenados no etcd para armazenamento persistente.
Kubernets é na verdade um sistema de controle de recursos altamente automatizado que realiza funções avançadas, como controle automático e correção automática de erros, rastreando e comparando a diferença entre o status esperado do recurso salvo no armazenamento etcd e o status real do recurso no ambiente atual.
1.Pod
Pod é a menor/mais simples unidade básica criada ou implantada pelo Kubernetes. Um Pod representa um processo em execução no cluster.
As vagens podem ser entendidas como vagens de ervilha, e cada recipiente na mesma vagem é uma ervilha.
Um Pod consiste em um ou mais contêineres. Os contêineres no Pod compartilham recursos de rede, armazenamento e computação e são executados no mesmo host Docker.
Vários contêineres podem ser executados em um pod, também chamado de modo SideCar. Em um ambiente de produção, um único contêiner ou vários contêineres com forte correlação e complementaridade formam um Pod.
Os contêineres no mesmo pod podem acessar uns aos outros por meio do host local e montar todos os volumes de dados no pod; no entanto, os contêineres entre pods diferentes não podem acessar por meio do host local nem montar os volumes de dados de outros pods.
2. Controlador de pod
O controlador de pod é um modelo para inicialização de pod, usado para garantir que os pods iniciados no K8S sempre sejam executados de acordo com as expectativas do usuário (número de cópias, ciclo de vida, verificação de status de integridade, etc.).
Existem muitos controladores Pod fornecidos no K8S, e os comumente usados são os seguintes:
- Implantação: implantação de aplicativo sem estado. A função do Deployment é gerenciar e controlar Pods e ReplicaSets e controlá-los para serem executados no estado esperado pelo usuário.
- Replicaset: garantindo o número esperado de réplicas de pod. A função do ReplicaSet é gerenciar e controlar os pods e controlá-los para que funcionem bem. No entanto, o ReplicaSet é controlado pelo Deployment.
- Daemonset: certifique-se de que todos os nós executem o mesmo tipo de pod e que um desses pods esteja sendo executado em cada nó. Geralmente é usado para implementar tarefas em segundo plano no nível do sistema.
- Statefulset: implantação de aplicativos com estado
- Trabalho: uma tarefa única. De acordo com as configurações do usuário, o Pod gerenciado pelo Job será encerrado automaticamente após a conclusão da tarefa com sucesso.
- Cronjob: tarefas agendadas periódicas
A relação entre implantação e Replicatset:
- Pode-se entender que a Deployment é a contratada geral, que é a principal responsável por supervisionar o trabalho dos Pods de trabalho abaixo e garantir que a quantidade de Pods exigida pelo usuário esteja sempre funcionando. Se você descobrir que um pod de trabalho está fora de serviço, instale rapidamente um novo pod para substituí-lo. ReplicaSet é o subcontratado do empreiteiro geral.
- Da perspectiva dos usuários do K8S, os usuários operarão diretamente o serviço de implantação de implantação e, quando a implantação for implantada, o K8S gerará automaticamente o ReplicaSet e o Pod necessários. Os usuários só precisam se preocupar com o Deployment e não com o ReplicaSet.
- O objeto de recurso Replication Controller é o antecessor do ReplicaSet. É oficialmente recomendado usar Deployment em vez de Replication Controller para implantar serviços.
3. Etiqueta
- Tags são um método de gerenciamento característico do K8S, que facilita a classificação e gerenciamento de objetos de recursos.
- Os rótulos podem ser anexados a vários objetos de recursos, como Node, Pod, Service, RC, etc., e são usados para associar objetos, consultar e filtrar.
- Um rótulo é um par chave-valor, onde a chave e o valor são especificados pelo usuário.
- Um objeto de recurso pode definir qualquer número de rótulos, e o mesmo rótulo também pode ser adicionado a qualquer número de objetos de recurso ou pode ser adicionado ou excluído dinamicamente após a criação do objeto.
- As funções de gerenciamento de agrupamento de recursos multidimensionais podem ser alcançadas agrupando um ou mais rótulos diferentes com objetos de recursos especificados.
A diferença entre rótulo e anotação:
a diferença é que um valor de rótulo válido deve ter 63 caracteres ou menos e deve estar vazio ou começar e terminar com caracteres alfanuméricos ([a-z0-9A-Z]) e pode estar entre Contém traços (-), sublinhados (_), pontos (.) e letras ou números. Não há limite de comprimento de caracteres para valores de comentários.
4.Seletor de etiqueta (seletor de etiqueta)
- Definir um rótulo para um objeto de recurso equivale a atribuir um rótulo a ele; então você pode consultar e filtrar objetos de recurso que possuem determinados rótulos por meio do seletor de rótulo (seletor de rótulo).
- Atualmente existem dois tipos de seletores de tags: baseados em relacionamentos de equivalência (igual a, diferente de) e baseados em relacionamentos de conjunto (pertence a, não pertence a, existe).
5.Serviço
- Em um cluster K8S, embora cada pod receba um endereço IP separado, como os pods têm um ciclo de vida (eles podem ser criados e não serão reiniciados após serem destruídos), eles podem mudar a qualquer momento devido a mudanças nos negócios. Como resultado, esse endereço IP também desaparecerá quando o pod for destruído.
- Serviço é o conceito central usado para resolver este problema.
- Serviço no K8S não significa “serviço” como costumamos dizer, mas sim como uma camada de gateway, que pode ser considerada como a interface de acesso externo e balanceador de tráfego de um grupo de Pods que fornecem o mesmo serviço.
- Os pods em que o serviço atua são definidos por meio de seletores de rótulos.
- Em um cluster K8S, Serviço pode ser considerado como a interface de acesso externo de um grupo de Pods que fornecem o mesmo serviço. O serviço que o cliente precisa acessar é o objeto Service. Cada serviço tem um IP virtual fixo (esse IP também é chamado de IP de cluster), que é vinculado automática e dinamicamente ao pod de back-end. Todas as solicitações de rede acessam diretamente o IP virtual do serviço, e o serviço será encaminhado automaticamente para o back-end. .
- Além de fornecer um método de acesso externo estável, o Serviço também pode funcionar como um balanceador de carga, distribuindo automaticamente o tráfego de solicitações para todos os serviços de back-end. O Serviço pode ser dimensionado horizontalmente de forma transparente para os clientes.
- A chave para realizar a função de serviço é o kube-proxy. kube-proxy é executado em cada nó e monitora alterações nos objetos de serviço no servidor API. A rede pode ser implementada por meio dos três modos de agendamento de tráfego a seguir: espaço do usuário (obsoleto), iptables (prestes a serem abandonados) e ipvs (recomendado , melhor desempenho) encaminhamento.
- O serviço é o núcleo dos serviços K8S. Ele protege os detalhes do serviço e expõe a interface do serviço para o exterior de forma unificada, alcançando verdadeiramente "microsserviços". Por exemplo, um de nossos serviços A implantou 3 cópias, ou seja, 3 Pods; para os usuários, eles só precisam ficar atentos à entrada de um Serviço, e não precisam se preocupar com qual Pod deve ser solicitado.
- As vantagens são muito óbvias: por um lado, os usuários externos não precisam estar cientes das alterações de IP causadas por falhas inesperadas de serviços nos Pods ou K8S reiniciando Pods. Os usuários externos também não precisam estar cientes das alterações de IP causadas pelo Pod. substituições devido a atualizações ou alterações de serviço.
6. Entrada
O serviço é o principal responsável pela topologia de rede dentro do cluster K8S. Então, como a parte externa do cluster acessa o interior do cluster? O ingresso é necessário neste momento. Ingress é a camada de acesso de todo o cluster K8S e é responsável pela comunicação dentro e fora do cluster.
Ingress é um aplicativo de camada 7 que funciona sob o modelo de referência de rede OSI no cluster K8S. É uma interface exposta externamente. O método de acesso típico é http/https.
O serviço só pode realizar agendamento de tráfego na quarta camada, na forma de ip+porta. O Ingress pode agendar o tráfego comercial em diferentes domínios comerciais e diferentes caminhos de acesso de URL.
Por exemplo: o cliente solicita http://www.kgc.com:port ---> Ingress ---> Service ---> Pod
7.Nome
- Como o K8S utiliza “recursos” internamente para definir cada conceito lógico (função), cada “recurso” deve ter seu próprio “nome”.
- "Recursos" incluem versão da API (apiversion), categoria (tipo), metadados (metadados), lista de definições (especificações), status (status) e outras informações de configuração.
- O “nome” geralmente é definido nas informações de “metadados” do “recurso”. Deve ser exclusivo dentro do mesmo namespace.
8. Espaço de nomes
À medida que os projetos aumentam, o pessoal aumenta e a escala do cluster se expande, é necessário um método que possa isolar logicamente vários "recursos" dentro do K8S. Este é o Namespace.
O Namespace nasceu para dividir um cluster K8S em vários grupos de clusters virtuais cujos recursos não podem ser compartilhados.
Os nomes dos "recursos" em diferentes namespaces podem ser iguais, mas os "nomes" do mesmo tipo de "recursos" no mesmo namespace não podem ser os mesmos.
O uso adequado do Namespace do K8S pode permitir que os administradores de cluster classifiquem, gerenciem e naveguem melhor nos serviços entregues ao K8S.
Os namespaces que existem por padrão no K8S incluem: default, kube-system, kube-public, etc.
Para consultar um “recurso” específico no K8S, é necessário trazer o Namespace correspondente.
Informações de configuração de recursos 9.k8s:
- Apliverison: a versão da interface API usada por cada objeto de recurso em k8s
- Tipo: o tipo de objeto de recurso
- Maledala: Metadados de objetos de recursos, como nome de recurso, namespace namespace. rótulo de rótulos, comentário de anulações
- Especificação: A lista de configuração de recursos (atributos de configuração) do objeto de recurso, como número de cópias, nome da imagem, volume de dados, seletor de rótulo, etc.
- Status: as informações de status de execução atual do objeto de recurso