
Índice
2. Desmontagem do fluxo de trabalho por processo
1. Código do fluxo de trabalho
2. Desmontagem do fluxo de trabalho
◆ Inicialização de hiperparâmetros
◆Inicialização do conjunto de dados
◆ Carregamento e quantificação
◆ Pré-processamento de conjunto de dados
I. Introdução
Anteriormente, analisamos e codificamos exemplos para cada etapa do processo relacionado ao LLM. A seguir, combinamos o código para organizar as partes acima em um fluxo de trabalho e fornecemos o fluxo de trabalho completo na estrutura para que todos possam se familiarizar com o processo de o processo de treinamento LLM.
Pontas:
O conjunto de dados e o código neste artigo referem-se principalmente ao Github LLaMA-Efficient-Tuning .
2. Desmontagem do fluxo de trabalho por processo
1. Código do fluxo de trabalho
Apenas o fluxo de trabalho de ajuste fino do SFT é fornecido aqui. Para um código mais completo, consulte o projeto git na introdução ou o código do HF Transformer fornecido na parte superior do código.
# Inspired by: https://github.com/huggingface/transformers/blob/v4.29.2/examples/pytorch/summarization/run_summarization.py
from typing import TYPE_CHECKING, Optional, List
from transformers import DataCollatorForSeq2Seq, Seq2SeqTrainingArguments
from llmtuner.dsets import get_dataset, preprocess_dataset, split_dataset
from llmtuner.extras.constants import IGNORE_INDEX
from llmtuner.extras.misc import get_logits_processor
from llmtuner.extras.ploting import plot_loss
from llmtuner.tuner.core import load_model_and_tokenizer
from llmtuner.tuner.sft.metric import ComputeMetrics
from llmtuner.tuner.sft.trainer import Seq2SeqPeftTrainer
if TYPE_CHECKING:
from transformers import TrainerCallback
from llmtuner.hparams import ModelArguments, DataArguments, FinetuningArguments, GeneratingArguments
# 1.通过 parser 获取参数
def run_sft(
model_args: "ModelArguments",
data_args: "DataArguments",
training_args: "Seq2SeqTrainingArguments",
finetuning_args: "FinetuningArguments",
generating_args: "GeneratingArguments",
callbacks: Optional[List["TrainerCallback"]] = None
):
# 2.Get Batch DataSet
dataset = get_dataset(model_args, data_args)
# 3.Load Lora Model And Bit or Not
model, tokenizer = load_model_and_tokenizer(model_args, finetuning_args, training_args.do_train, stage="sft")
# 4.Process Dataset
dataset = preprocess_dataset(dataset, tokenizer, data_args, training_args, stage="sft")
# 5.Data Collator
data_collator = DataCollatorForSeq2Seq(
tokenizer=tokenizer,
label_pad_token_id=IGNORE_INDEX if data_args.ignore_pad_token_for_loss else tokenizer.pad_token_id
)
# 6.Training Args 转化
# Override the decoding parameters of Seq2SeqTrainer
training_args_dict = training_args.to_dict()
training_args_dict.update(dict(
generation_max_length=training_args.generation_max_length or data_args.max_target_length,
generation_num_beams=data_args.eval_num_beams or training_args.generation_num_beams
))
training_args = Seq2SeqTrainingArguments(**training_args_dict)
# Initialize our Trainer
trainer = Seq2SeqPeftTrainer(
finetuning_args=finetuning_args,
model=model,
args=training_args,
tokenizer=tokenizer,
data_collator=data_collator,
callbacks=callbacks,
compute_metrics=ComputeMetrics(tokenizer) if training_args.predict_with_generate else None,
**split_dataset(dataset, data_args, training_args)
)
# Keyword arguments for `model.generate`
gen_kwargs = generating_args.to_dict()
gen_kwargs["eos_token_id"] = [tokenizer.eos_token_id] + tokenizer.additional_special_tokens_ids
gen_kwargs["pad_token_id"] = tokenizer.pad_token_id
gen_kwargs["logits_processor"] = get_logits_processor()
# Training
if training_args.do_train:
train_result = trainer.train(resume_from_checkpoint=training_args.resume_from_checkpoint)
trainer.log_metrics("train", train_result.metrics)
trainer.save_metrics("train", train_result.metrics)
trainer.save_state()
trainer.save_model()
if trainer.is_world_process_zero() and model_args.plot_loss:
plot_loss(training_args.output_dir, keys=["loss", "eval_loss"])
# Evaluation
if training_args.do_eval:
metrics = trainer.evaluate(metric_key_prefix="eval", **gen_kwargs)
if training_args.predict_with_generate: # eval_loss will be wrong if predict_with_generate is enabled
metrics.pop("eval_loss", None)
trainer.log_metrics("eval", metrics)
trainer.save_metrics("eval", metrics)
# Predict
if training_args.do_predict:
predict_results = trainer.predict(dataset, metric_key_prefix="predict", **gen_kwargs)
if training_args.predict_with_generate: # predict_loss will be wrong if predict_with_generate is enabled
predict_results.metrics.pop("predict_loss", None)
trainer.log_metrics("predict", predict_results.metrics)
trainer.save_metrics("predict", predict_results.metrics)
trainer.save_predictions(predict_results)
2. Desmontagem do fluxo de trabalho
◆ Inicialização de hiperparâmetros
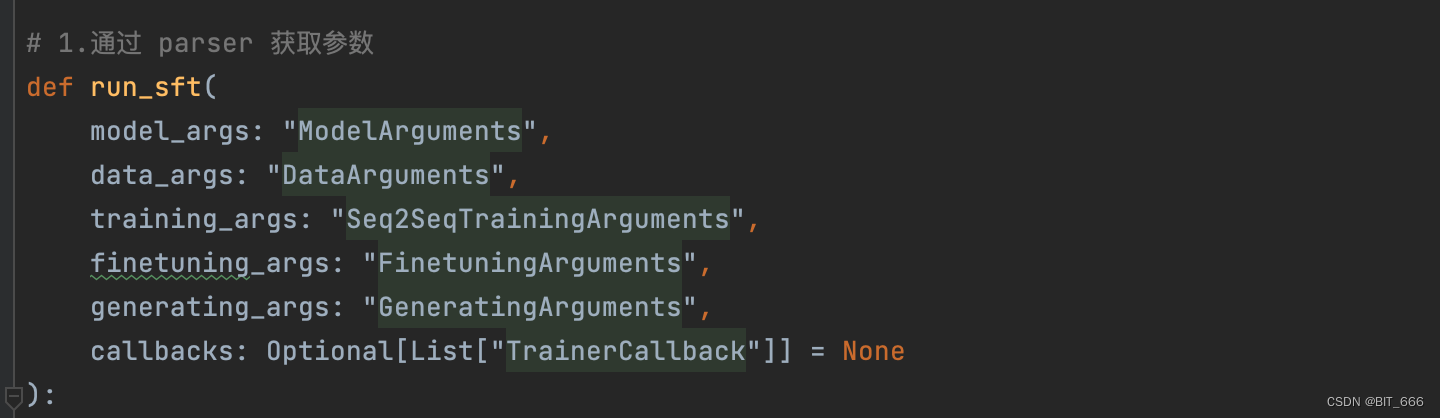
Além de passar o endereço ou caminho correspondente ao modelo, aqui passamos principalmente os parâmetros de treinamento relevantes, parâmetros de ajuste fino, parâmetros de geração, etc.
◆ Inicialização do conjunto de dados

data_args contém parâmetros de conjunto de dados relevantes. Carregamos o conjunto de dados alpaca_data_zh_51k.json aqui:

Vamos pegar as primeiras 5 linhas de saída e visualizar o conjunto de dados:
def show(dataset):
show_info = dataset.select(range(5))
print(show_info)
for row in show_info:
print(row)
Os recursos fornecem muitas colunas. Nós nos concentramos principalmente em palavras imediatas, perguntas de consulta e respostas.
◆ Carregamento e quantificação
![]()
A lógica específica da função aqui pode ser encontrada no link fornecido anteriormente. Principalmente responsável por obter parâmetros de modelo de model_args e obter parâmetros relacionados ao ajuste fino de finetuning_args, como lora_target, lora_rank, etc. O modelo é carregado através do componente Auto do HF, e o modelo Lora é implementado através da biblioteca Peft.
Modelo básico para Baichuan:
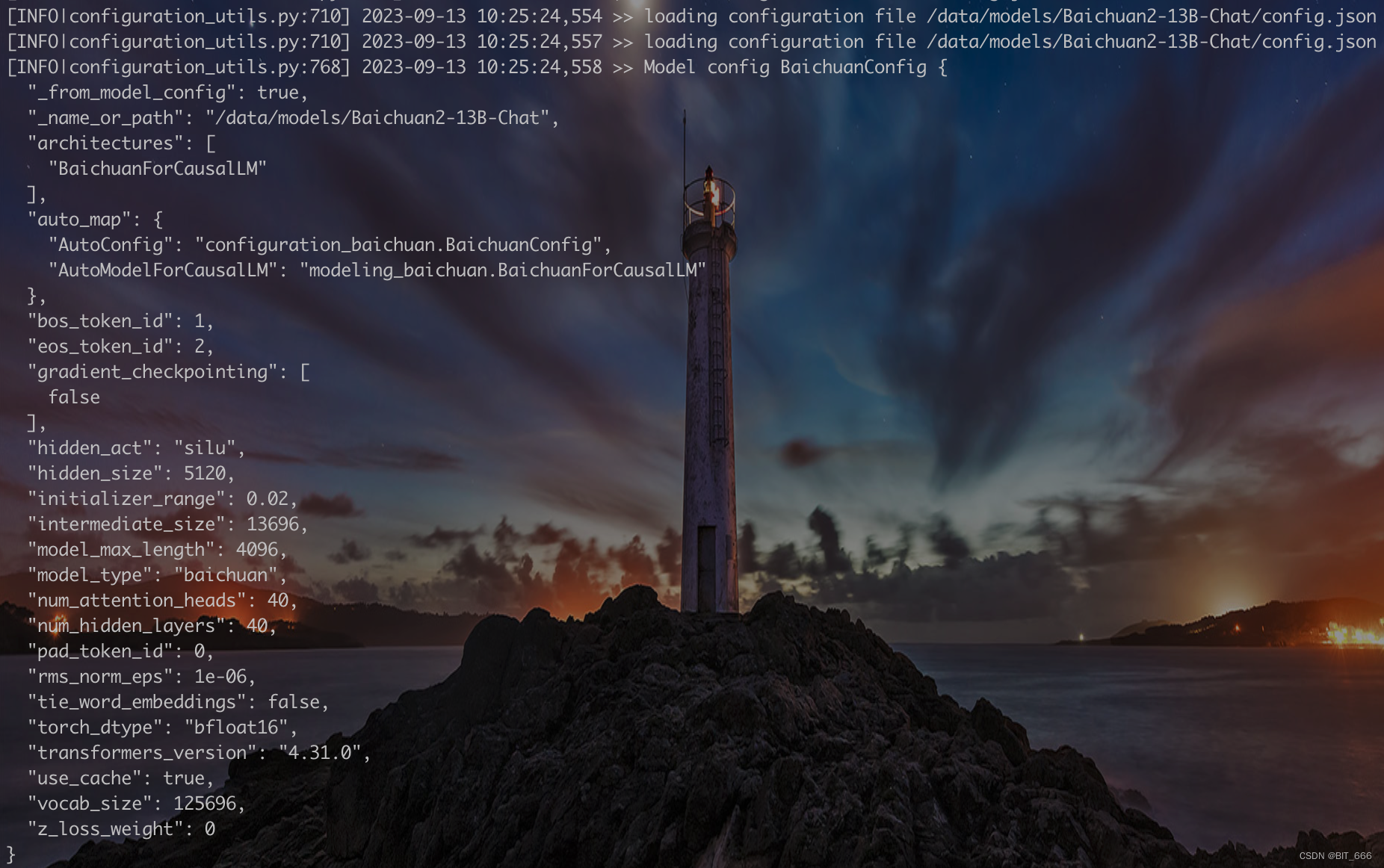
Na configuração do modelo relevante impressa após o modelo ser carregado, você pode ver o tipo de modelo, alguns IDs de token especiais e a função de ativação do silu mencionada anteriormente, etc. Não usamos o modelo de quantização aqui, mas o novo Baichuan2 fornece quantização online de 8 e 4 bits e soluções de quantização offline para todos escolherem.
Informações LoRA para Baichuan:

Como é um ajuste fino SFT, o módulo LoRA é adicionado através de peft. Aqui lora_target é 'W_pack', que também imprime a proporção de nossos parâmetros de ajuste fino em relação aos parâmetros totais.
◆ Pré-processamento de conjunto de dados
![]()
Como o pré-processamento de dados requer o tokenizer correspondente ao modelo, o modelo e o tokenizer precisam ser carregados primeiro. Aqui, nosso artigo recente apresenta os métodos de processamento dos três conjuntos de dados de modo de SFT, PT e RM. Execute o código de forma semelhante para ver as primeiras 5 linhas de dados. Como fica após a pré-processamento:

Após o processamento, o conjunto de dados contém apenas o conteúdo relevante exigido pelo SFT. input_ids é o ID do token correspondente à entrada, onde a entrada é prompt + "\t" + consulta + resposta, e os rótulos mascaram todas as partes, exceto a resposta.

以 第一 条 记录 为 例 , input_ids 为 prompt + consulta + resposta , etiquet_ids 将 的 的 token 用 -100 的 ignore_index 替换 , 其 对应 的 token 为 <snk> , 结尾处 的 , <s> 对应 的 为 为 2 为Portanto, todas as frases terminam com 2.
◆ DataCollator

O treinador do modelo também precisa de data_collator para gerar dados de treinamento correspondentes, onde Tokenizer e pad_token_ids correspondentes são especificados.
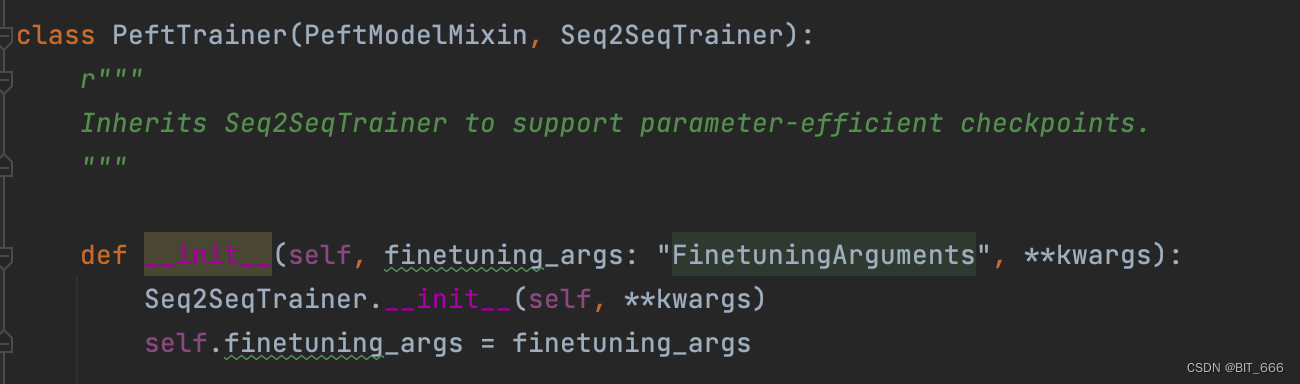
◆ Ajuste fino do modelo sft

O treinamento é herdado principalmente da importação de transformadores Seq2SeqTrainer:
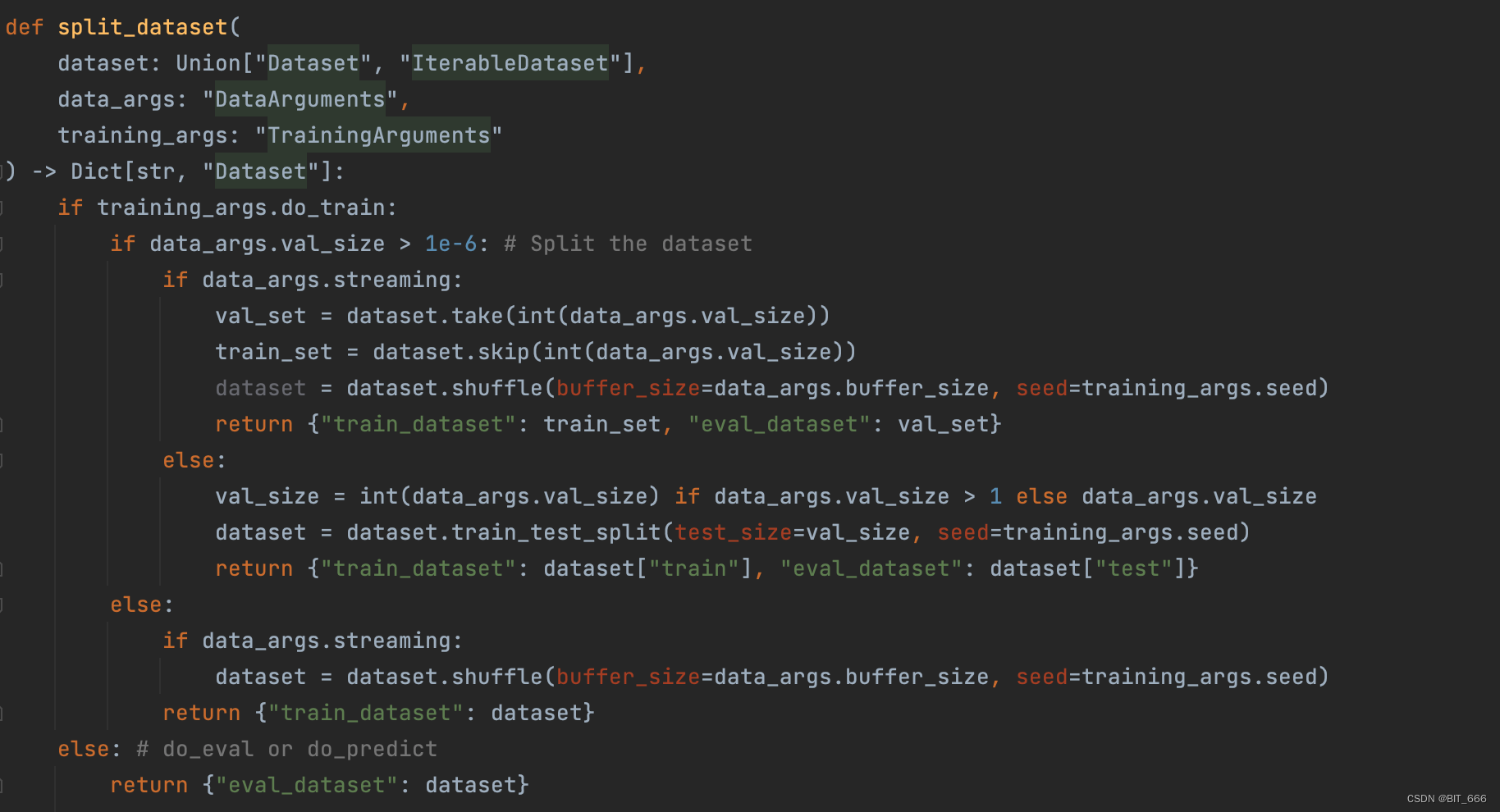
split_dataset é responsável por dividir o conjunto de dados em partes de treinamento e avaliação:
Registro de treinamento do modelo:
3. Resumo
Fazer modelos grandes é como uma montanha-russa. Eu acho que é muito poderoso, mas a estrutura é apenas uma pilha de Transformers; acho que pode ser facilmente treinado e ajustado, mas requer muita força e recursos financeiros para pagar; o código do fluxo de trabalho parece muito lógico, mas em na verdade, contém muitos pequenos detalhes. Vale a pena aprender detalhes. O complicado processo de aprendizagem, basta observar e aprender.