Explore modelos de linguagem
introduzir
Nesta postagem do blog, discutirei grandes modelos de linguagem, como BERT, BART e T5. Desenvolvimentos significativos na área de LL.M. em 2020 incluem o desenvolvimento desses modelos. BERT e T5 foram desenvolvidos pelo Google, e BART foi desenvolvido pela Meta. Abordarei os detalhes desses modelos em ordem com base na data de lançamento. Em minha última postagem no blog, Modelos autorregressivos para processamento de linguagem natural, discuti as propriedades autorregressivas de transformadores generativos pré-treinados. Neste blog, compararei como esses modelos diferem dos modelos autorregressivos. Então, se você ainda não leu o artigo anterior, dê uma olhada. O artigo BERT foi lançado em 2018, BART em 2019 e T5 em 2020. Apresentarei os detalhes do artigo na mesma ordem.
Representação de codificador bidirecional de transformador (BERT)
O modelo BERT é baseado em um codificador Transformer bidirecional multicamadas. O BERT visa pré-treinar representações bidirecionais profundas de texto não rotulado, condicionando conjuntamente o contexto esquerdo e direito em todas as camadas. Portanto, um modelo BERT pré-treinado pode ser ajustado com apenas uma camada de saída adicional para criar um modelo de última geração. O BERT usa um objetivo de pré-treinamento de modelo de linguagem mascarado para superar a restrição unidirecional. O pré-treinamento do BERT também é concluído por meio da previsão da próxima frase.
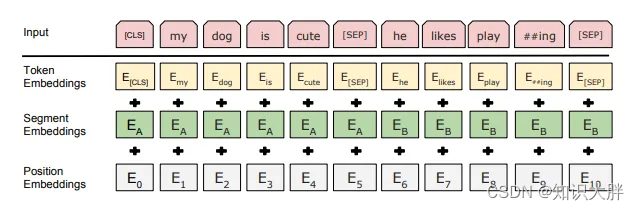
Comparado com o Transformer, a representação de entrada do BERT é a soma da incorporação de token, incorporação de segmento e incorporação de posição. Marcadores de categorias especiais e marcadores separadores de frases também foram adicionados. Embeddings de token são embeddings de blocos com um vocabulário de 30.000. Os conjuntos de dados utilizados no pré-treinamento são BookCorpus e Wikipedia.
Modelo de linguagem mascarada
No pré-treinamento de MLM, 15% das palavras da sequência de entrada são retiradas. 80% deles foram bloqueados, 10% foram substituídos por palavras aleatórias e 10% permaneceram inalterados. portanto�