O histórico de desenvolvimento do modelo de linguagem grande é apresentado no artigo de história do modelo de linguagem grande GPT, e o processo de treinamento do modelo de linguagem grande é brevemente apresentado. Este artigo elabora os detalhes de treinamento e algoritmos relacionados.
Depois de 2020, as empresas globais de Internet e as empresas iniciantes de IA desenvolveram muitos modelos supergrandes de IA (dezenas de bilhões ou mesmo centenas de bilhões de parâmetros), os representantes típicos são GPT-3, LlaMA no campo de PNL, DALL*E2 , Difusão Estável e V -MoE. A maioria das ferramentas generativas de IA existentes baseia-se nos modelos de pré-treinamento desenvolvidos pelos principais fabricantes e usa pequenos dados para cenários específicos para iterar rapidamente o modo Fine-Tune.
DALL-E2: DALL-E2 é um modelo de geração de imagens proposto pela OpenAI em 2021. É baseado no modelo de pré-treinamento GPT-3 e utiliza um mecanismo de autoatenção para processar imagens de entrada. DALL-E2 pode gerar imagens de alta qualidade e pode gerar imagens baseadas em descrições de texto.
Difusão Estável: Difusão Estável é um modelo de geração de imagens proposto pelo Facebook AI Research em 2021. É baseado em processos de difusão e equações diferenciais estocásticas e usa um mecanismo de autoatenção para processar imagens de entrada. A difusão estável pode gerar imagens de alta qualidade, realizar aprendizado não supervisionado e controlar o estilo das imagens geradas.
O processo de treinamento do ChatGPT é dividido nas quatro etapas a seguir:
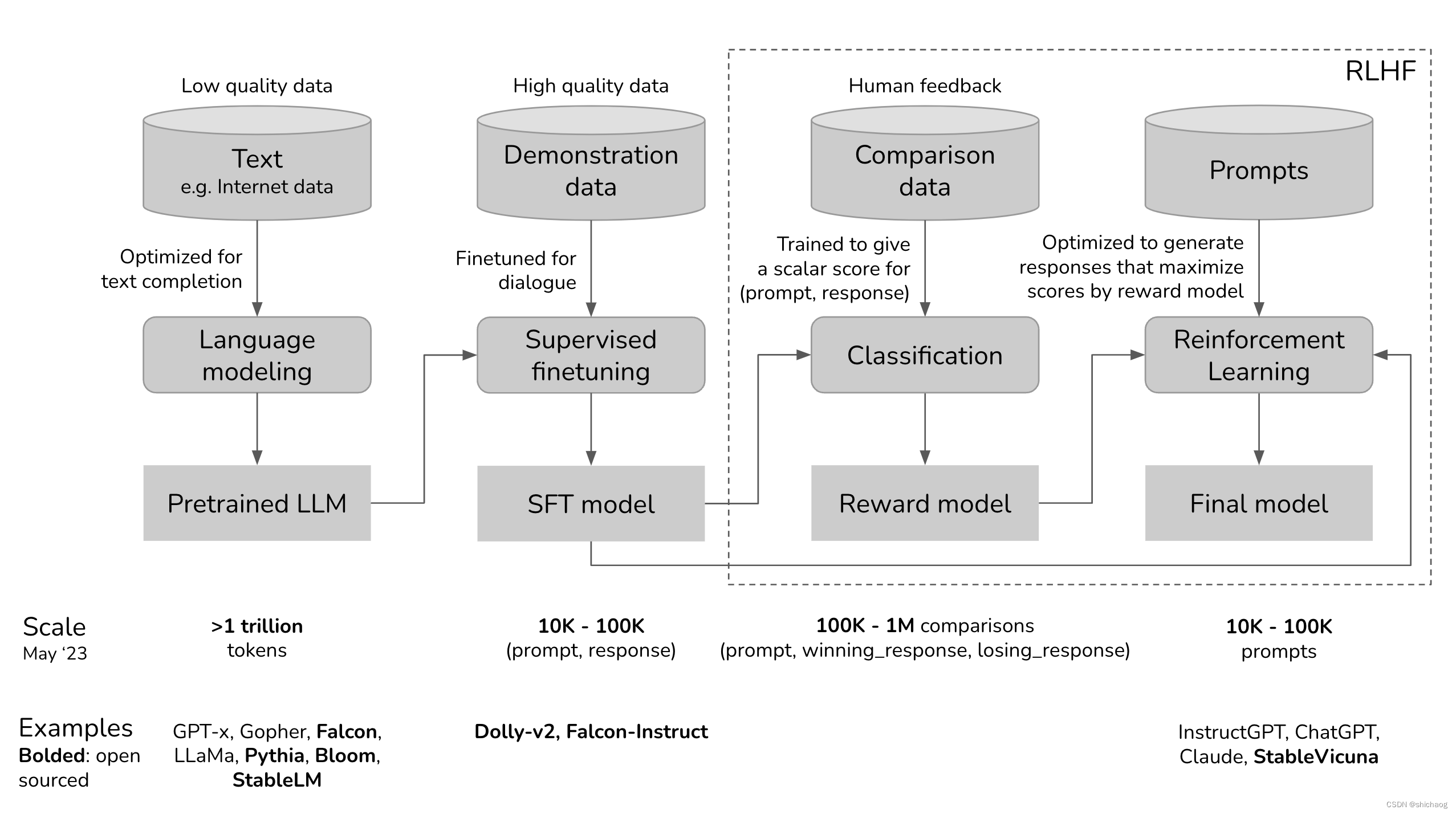
1. O modelo de pré-treinamento (pré-treinamento) é baseado em uma grande quantidade de modelos de aprendizagem autossupervisionados não rotulados, porque os dados rastreados da Internet não foram limpos, então alguns falsos informações na Internet, teorias da conspiração, preconceitos e erros de bom senso serão todos treinados pelo modelo, então o modelo neste estágio é geralmente chamado de modelo de pré-treinamento; 2. Em seguida, use dados de maior qualidade para ajustar
o modelo de pré-treinamento.Esses dados de alta qualidade, como StackOverflow, Quora, Wikipedia, Enciclopédia Baidu e anotações humanas, etc., fazem com que o modelo produza o mínimo de conteúdo prejudicial e inútil possível.
3. Em seguida, use RLHF para ajustar ainda mais o modelo para torná-lo mais adequado às necessidades específicas da aplicação.
Nas três etapas de treinamento do modelo acima, o modelo de pré-treinamento (pré-treinamento) na primeira etapa ocupa a maior parte do poder de computação e dos dados.De acordo com os dados do site oficial da OpenAI, o InstructGPT ocupa 98% do estágio do modelo de pré-treinamento (https://openai.com/research/instruction-following) poder de computação e dados. Pense em SFT e RLHF como recursos de desbloqueio que o modelo pré-treinado já possui, mas que são difíceis de serem acessados pelo usuário com apenas uma dica. Portanto, o SFT na segunda etapa e o RLHF na terceira etapa não dotam o modelo de novas habilidades em essência, mas selam as más habilidades e desbloqueiam as boas e necessárias habilidades.
A primeira etapa do pré-treinamento
O produto do modelo de pré-treinamento é um modelo de linguagem grande, como GPT-x (OpenAI), Gopher (DeepMind), LLaMa (Meta).
O modelo de linguagem codifica as informações de fala. Em um contexto específico, a probabilidade de ocorrência de palavras/palavras diferentes é diferente. A tarefa do modelo de linguagem é prever a próxima palavra. O modelo de fala pode ser considerado como uma tarefa de preenchimento de palavras, dada uma solicitação (Prompt) e complementada abaixo.
Prompt (用户输入):今天天气真好,我打算出去逛街,
补充 (语言模型): 去买买衣服和包包。
Isso parece ser uma coisa muito simples, mas na verdade é uma função muito poderosa: pode completar tradução, resumo, escrever código, resolver problemas aritméticos, escrever direitos autorais, etc. Por exemplo, dado o prompt: Como você está em chinês é ..., A conclusão do modelo de linguagem produzirá como você está, que é a realização da função de tradução.
Representação matemática pré-treinada
Dados de treinamento: dados não marcados de baixa qualidade
Escala de dados: No momento em que este artigo foi escrito, os tokens dos dados de treinamento usados pelo grande modelo de linguagem eram da ordem de trilhões. De acordo com a taxa de crescimento atual do grande modelo pré- conjunto de dados de treinamento, será publicado na Internet em alguns anos. Há uma grande probabilidade de que os dados possam ser rastreados por empresas líderes. Nessa altura, a vantagem da dimensão dos dados será trazida pelos dados privados.
- Escala de token do conjunto de dados GPT-3 (OpenAI), usando 0,5 trilhão, GPT-4 não é público
- O tamanho do token do conjunto de dados LlaMA-1 (Meta) é de 140 milhões, e o LlaMA-2 usa 2 trilhões de tokens para pré-treinamento.
Descrição da fórmula:
- LLM ϕ LLM_{\phi}LL Mϕ: Grande modelo de linguagem a ser treinado, onde ϕ \phiϕ é um parâmetro, o objetivo do treinamento é obter o conjunto de parâmetros ϕ \phicom a menor perda de entropia cruzadaϕ ;
- [ T 1 , T 2 ,… , TV ] [T_1, T_2, …, T_V][ T1,T2,…,TV] : vocabulário, o número total de tokens no conjunto de treinamento, o vocabulário do GPT-2 (OpenAI) é 50257. O tamanho do vocabulário do LlaMA-1 e do LlaMA-2 é 32.000.
- VVV : é o tamanho do vocabulário. 32.000 para LlaMA-1/LlaMA-2.
- f(x) f(x)f ( x ) : mapeia o token para sua posição no vocabulário, se tokenxxA posição de x no vocabulário éT k T_kTk, então f ( x ) = kf(x)=kf ( x )=k .
- Para uma frase de comprimento n ( x 1 , x 2 , … , xn ) (x_1, x_2, …, x_n)( x1,x2,…,xnão) , de acordo com o token dividido na sequência necessária para treinar o modelo, que obterá n amostras de treinamento.
- Importar x= ( x 1 , x 2 , … , xi − 1 ) (x_1, x_2,…, x_{i-1})( x1,x2,…,xeu − 1)
- A palavra prevista é xi x_ixeu
- Para cada amostra de treinamento ( x , xi ) (x,x_i)( x ,xeu) :
- 令k = f (xi) k=f(x_i)k=f ( xeu)
- Exportação de modelo: LLM ( x ) = [ y 1 , y 2 ,… , yv ] LLM (x) = [y_1, y_2,…, y_v]LL M ( x )=[ e1,sim2,…,simv] ,∑ jyj = 1 \soma_j y_j=1∑jsimj=1
- perda为: CE ( x , xi ; ϕ ) = − logiak CE(x,x_i;\phi) = -logia_kCE ( x ,xeu;) _=− l o g yk
- Função objetivo: encontre o conjunto de parâmetros ϕ \phiϕ minimiza a perda de todas as amostras de treinamento:CE ( ϕ ) = − E x log yk CE(\phi)=-E_x\log{y_k}CE ( ϕ )=−E _xei _simk
Fase 2: Pré-treinamento supervisionado Ajuste fino supervisionado (SFT)
Por que o SFT é necessário?
Como a tarefa do modelo de pré-treinamento é prever a próxima palavra, se o modelo de pré-treinamento for inserido: como fazer camarões salgados e apimentados
, então o modelo de pré-treinamento pode produzir:
1.? Quais ingredientes são necessários e quais são as etapas para prepará-los?
2. Não é gorduroso, crocante e delicioso?
3. Ingredientes detalhados e etapas de produção
Na verdade, a terceira etapa de produção detalhada é o que precisamos.O objetivo do SFT é melhorar a probabilidade do resultado desejado.
Como podemos melhorar a probabilidade de melhores resultados para os cenários desejados (como questionários de conhecimento, resumos, traduções, etc.)? Como o modelo imita o conjunto de dados, com base no modelo pré-treinado, um lote de amostras de um tipo específico é fornecido para o modelo imitar novamente. É isso que o estágio SFT faz. Os exemplos no estágio SFT são dado por (prompt, resposta) OpenAI chama isso de clonagem de comportamento de ajuste fino supervisionado por chamada.A distribuição do conjunto de dados de amostra SFT do InstructGPT é a seguinte: a coluna da esquerda mostra a proporção de casos diferentes, e a direita mostra

exemplos de prompt para três casos.
conjunto de dados de amostra
Conjuntos de dados de exemplo podem ser fornecidos por pessoas (como as práticas InstructGPT e ChatGPT da OpenAI), que são diferentes da anotação de dados tradicional. Os provedores de exemplo são compostos por intelectuais com alta escolaridade que passaram no teste. 90% dos prompts do InstructGPT foram diplomas universitários., um terço tem mestrado. O nível de educação de seu pessoal detalhado é o seguinte:

40 engenheiros rápidos empregados pela OpenAI criaram 13.000 exemplos (prompt, resposta) para o InstructGPT, um dos quais é o seguinte:
| Incitar | Resposta |
|---|---|
| Serendipidade significa a ocorrência e o desenvolvimento de eventos por acaso, de forma feliz ou benéfica. Use a palavra em uma frase. | Encontrar Margaret e ser apresentado a Tom foi um golpe de sorte. |
| ELI5: Qual é a causa do “caroço de ansiedade” em nosso peito durante experiências estressantes ou desanimadoras? | O nó de ansiedade na garganta é causado pela tensão muscular que mantém a glote dilatada para maximizar o fluxo de ar. A sensação de aperto no peito ou dor de cabeça é causada pelo nervo vago, que diz aos órgãos para bombear o sangue mais rapidamente, parar de digerir e produzir adrenalina e cortisol. |
| Crie uma lista de compras com esta receita: Corte as pontas da abobrinha. Corte a abobrinha ao meio no sentido do comprimento; retire a polpa, deixando 1/2 pol. cartuchos. Pique a polpa finamente. Em uma frigideira, cozinhe a carne, a polpa de abobrinha, a cebola, os cogumelos e o pimentão em fogo médio até que a carne não fique mais rosada; ralo. Retire do fogo. Adicione 1/2 xícara de queijo, ketchup, sal e pimenta; misture bem. Coloque nas cascas de abobrinha. Coloque em uma forma untada de 13x9 pol. assadeira. Polvilhe com o queijo restante. | Abobrinha, carne, cebola, cogumelo, pimentão, queijo, ketchup, sal, pimenta |
O conjunto de dados de exemplo de método da OpenAI é de alta qualidade, mas o custo e o tempo também são altos. Assim, também existem exemplos obtidos na Internet por meio de filtragem heurística de conversas. Gopher (DeepMind) adota essa abordagem.
LlaMA-2 usa 27.540 exemplos (prompt, resposta), que são exemplos de alta qualidade (prompt, resposta) selecionados pelo Meta a partir de milhões de anotações em conjuntos de dados de terceiros.
Representação matemática do SFT
- Conjunto de dados: (prompt, resposta) Conjunto de dados anotado de alta qualidade.
- Escala de dados: 10.000 a 100.000 exemplos (prompt, resposta)
- InstructGPT: ~145.000, dos quais 13.000 são de engenheiros imediatos e 1.500 são de usuários
- LIGUE-2 27540条
- Entrada e saída do modelo:
- entrada: prompt
- Saída: a resposta correspondente
- A função de perda de treinamento usa o critério de entropia cruzada.
Estágio Três: RLHF
Empiricamente, o RLHF melhora significativamente o desempenho em comparação com o SFT sozinho. A explicação de Anrowpic para isso é: "Esperamos que o feedback humano (HF) tenha a maior vantagem comparativa sobre outras técnicas quando as pessoas têm intuições complexas que são fáceis de extrair, mas difíceis de formalizar e automatizar." (Bai et al., 2022 )

Diálogo seja flexível. Dada uma solicitação, há muitas respostas razoáveis, algumas melhores que outras. Os dados de demonstração informam ao modelo quais respostas são plausíveis para um determinado contexto, mas não informam ao modelo quão boas ou ruins são as respostas.
A ideia é: e se tivéssemos uma função de pontuação que, dada uma solicitação e uma resposta, produzisse uma pontuação de quão boa é uma resposta? Em seguida, usamos essa função de pontuação para treinar ainda mais nosso LLM para fornecer respostas com pontuação alta. Isto é exatamente o que o RLHF faz. O RLHF consiste em duas partes:
1. Treinar o modelo de recompensa como função de pontuação.
2. Otimizando o LLM para gerar respostas para as quais o modelo de recompensa dará pontuações altas.
Modelo RM
A tarefa do modelo RM é pontuar (prompt, resposta), e treinar um modelo para gerar uma pontuação em uma determinada entrada é uma tarefa muito comum em ML. Pode ser facilmente estruturado como uma tarefa de classificação ou regressão. O desafio no treinamento de modelos de recompensa está na obtenção de dados confiáveis. É muito difícil conseguir que pessoas diferentes atribuam notas consistentes às mesmas respostas. É muito mais fácil comparar as duas respostas e decidir qual é a melhor.
Portanto, o processo de rotulagem é o processo de saída de pares (prompt, resposta vencedora, resposta_perdida), que é chamado de comparação de dados. A próxima pergunta são apenas esses pares de dados de comparação, como treinar o modelo para dar uma pontuação específica?
Para InstructGPT, o objetivo é maximizar a diferença de pontuação entre (prompt, resposta_vitória) e (prompt, resposta_perda) (veja a seção de fórmula matemática para detalhes). A partir dessa ideia, pode-se ver que, ao mesmo tempo em que incentiva a resposta vencedora_resposta, também suprime a resposta da classe loss_response do modelo de recompensa.
O modelo RM pode ser inicializado de diferentes maneiras, mas a propagação do modelo SFT parece dar os melhores resultados, e a intuição é que o RM deve ser pelo menos tão poderoso quanto o LLM para poder pontuar bem as respostas do LLM .
Representação matemática de RM
- Conjunto de dados: alta qualidade (prompt, resposta vencedora, resposta_perdida)
- Escala de dados: 100.000 a 1 milhão de amostras,
- O InstructGPT possui 50.000 prompts, e cada prompt possui 49 respostas, que podem formar 636 pares (resposta_vencedora, resposta_perdedora). Isso significa que o tamanho dos dados é de 300.000 a 1,8 milhão de exemplos.
- Além de usar dados de terceiros, o LlaMA-chat-2 também usa dados autoconstruídos.A diferença do InstructGPT é que as respostas podem ser geradas por diferentes modelos além da escrita humana.

Distribuição do conjunto de dados de treinamento LlaMA-2 RM
A fórmula diz:
- r θ r_{\teta}Reu: RM a ser treinado, o conjunto de parâmetros usa θ \thetaθ significa que o objetivo do processo de treinamento é encontrar o conjunto de parâmetrosθ \thetaθ torna a perda a menor geral no conjunto de dados RM;
- Formato de organização dos dados de treinamento:
- x\mathbf{x}x : entrada
- yw \ mathbf y_wsimo que: Saída do modelo relativamente boa, w significa resposta vencedora
- il\mathbf y_lsimeu: Saída do modelo relativamente ruim, l significa resposta à perda
- Para cada amostra de treinamento ( x , yw , yl ) (\mathbf x, \mathbf y_w, \mathbf y_l)( x ,simo que,simeu):
- S w = r θ ( x , yw ) \mathbf S_w=r_{\theta }(\mathbf x, \mathbf y_w)So que=Reu( x ,simo que) : A pontuação de resposta vencedora do modelo RM
- S l = r θ ( x , yl ) \mathbf S_l=r_{\theta}(\mathbf x,\mathbf y_l)Seu=Reu( x ,simeu) : a pontuação de resposta à perda do modelo RM
- perda: − log ( σ ( S w − S l ) ) -\log(\sigma(S_w -S_l))-registro ( σ ( S _o que-Seu))
- Função objetivo: encontrar o conjunto de parâmetros θ {\theta} com a menor perda para todas as amostras de treinamentoθ,即− E x log ( σ ( sw − sl ) ) -E_x \log(\sigma(s_w-s_l))−E _xregistro g ( s ( so que-éeu)) mínimo
Você pode dar uma olhada em como funciona essa função de perda, seja d = sw − sld=s_w-s_ld=éo que-éeu,f ( d ) = − log ( σ ( d ) ) f(d)=-\log(\sigma(d))f ( d )=-O gráfico de log g ( σ ( d )) é o seguinte. Para d negativo, o valor da perda será grande. Esta função fará com que a pontuação do modelo RM seja mais alta para a resposta vencedora.

Ajuste fino usando o modelo de recompensa RM
Nesta fase, treinaremos ainda mais o modelo SFT para gerar respostas de saída que maximizem a pontuação do RM. Hoje, a maioria das pessoas usa o Proximal Policy Optimization (PPO), um algoritmo de aprendizagem por reforço lançado pela OpenAI em 2017.
O ajuste fino é realizado com base no modelo SFT, e as etapas fornecidas no artigo do InstructGPT são as seguintes:

Durante esse processo, as dicas são selecionadas aleatoriamente na distribuição - por exemplo, OpenAI pode escolher aleatoriamente entre as solicitações do usuário. Cada um desses prompts é inserido em um modelo LLM para obter uma resposta, e o RM pontua a resposta.
O processo de treinamento é o seguinte. O modelo de linguagem inicial na figura abaixo é o modelo SFT, enquanto o modelo de linguagem sintonizada é o modelo (estratégia RL). As iterações relevantes de perda e gradiente são mostradas na figura abaixo:

A OpenAI também considerou necessário adicionar uma restrição: o modelo produzido por este estágio não deve se desviar muito do modelo produzido pelo estágio SFT (matematicamente expresso como o termo de divergência KL na função objetivo abaixo) e do modelo original pré-treinado . A intuição é que, para qualquer prompt, há muitas respostas possíveis, a grande maioria das quais RM nunca viu. Para muitas amostras desconhecidas ((prompt, resposta), o RM pode atribuir incorretamente pontuações extremamente altas ou baixas. Sem esta restrição, o modelo pode ser tendencioso para as respostas com pontuações extremamente altas, mesmo que possam não ser boas respostas.
Representação matemática do ajuste fino do modelo de recompensa
- Esta etapa emprega uma abordagem de aprendizagem por reforço
- Espaço de ação: o token usado pelo vocabulário LLM. A ação tomada corresponde à seleção da saída do token pelo modelo.
- Espaço de observação: a distribuição de todos os prompts possíveis.
- Política: A distribuição de probabilidade sobre todas as ações (e, portanto, tokens) a serem tomadas após uma observação (prompt). O LLM constitui uma estratégia porque determina a probabilidade de os tokens serem gerados a seguir.
- Função de recompensa: modelo RM acima.
- Conjunto de dados de treinamento: prompts selecionados aleatoriamente
- Escala de dados: 10.000-100.000 prompts
- InstructGPT: 4 万 prompts
Representação de fórmula
- RM: O modelo descrito na seção do modelo RM
- LLMSFT LLM^{SFT}LL MSFT : modelo de ajuste fino de instrução obtido na subseção do modelo SFT, dado o promptx \mathbf xx , a saída do modelo é a probabilidade de responder, no artigo InstructGPT,LLMSFT LLM^{SFT}LL MSFT用π SFT \pi^{SFT}PiSFT disse.
- LLM ϕ RL LLM_{\phi}^{RL}LL MϕR.L. _: O conjunto de parâmetros usa ϕ \phiϕ representa o modelo de treinamento de aprendizagem por reforço.
- O objetivo do treinamento de aprendizagem por reforço é encontrar o conjunto de parâmetros ϕ \phi que maximiza a pontuação do modelo RMϕ
- Dado o prompt x \mathbf xx , cuja saída corresponde à distribuição de probabilidade das respostas.
- No artigo do InstructGPT, LLM ϕ RL LLM_{\phi}^{RL}LL MϕR.L. _Escreva π ϕ RL \pi_{\phi}^{RL}PiϕR.L. _
- x\mathbf xx : alerta
- DRL D_{RL}DR.L. _: A distribuição imediata usada pelo modelo RM
- D pré-treino D_{pré-treino}Dpré - treinamento _ _: Distribuição do conjunto de dados de treinamento do modelo pré-treinado
Para cada etapa de treinamento, de DRL D_{RL}DR.L. _Selecione uma amostra de tamanho de lote, denotada como x RL \mathbf x_{RL}xR.L. _, e de D pré-treinamento D_{pré-treinamento}Dpré - treinamento _ _Selecione uma amostra do tamanho do lote, registrada como xpretrain \mathbf x_{pretrain}xpré - treinamento _ _. Esses dois tipos de dados vêm de conjuntos de amostras diferentes, portanto as funções objetivo são diferentes.
1. Para cada entrada do modelo RM x RL \mathbf x_{RL}xR.L. _, então use o modelo de aprendizagem por reforço LLM ϕ RL LLM_{\phi}^{RL}LL MϕR.L. _Obtenha a saída no prompt, registrada como y ∼ LLM ϕ RL ( x RL ) y \sim LLM_{\phi}^{RL}(\mathbf x_{RL})sim∼LL MϕR.L. _( xR.L. _) , então a função objetivo é calculada da seguinte forma,
O 1 ( x RL , y ; ϕ ) = RM ( x RL , y ) − β log LLM ϕ RL ( y ∣ x ) LLMSFT ( y ∣ x ) O_1 {( \ mathbf x_{RL},y;ϕ)=RM(\mathbf x_{RL},y)−β \log \frac{LLM^{RL}_ϕ(y|x)}{LLM^{SFT}(y |x)}}Ó1( xR.L. _,você ;) _=RM ( xR.L. _,você )-bei _LL MSFT (y∣x)LL MϕR.L. _( y ∣ x )
O segundo item é a divergência KL introduzida para que o modelo RL não se desvie muito do modelo SFT.
2. Para cada xpretrain \mathbf x_{pretrain}xpré - treinamento _ _, a função objetivo deve ser que a saída do modelo RM neste prompt não seja pior do que o modelo de pré-treinamento:
O 2 ( xpretrain ; ϕ ) = γ log LLM ϕ RL ( xpretrain ) O_2(\mathbf x_{ pré-treinamento}; \phi) = \gamma \log LLM_{\phi}^{RL}(\mathbf x_{pré-treinamento})Ó2( xpré - treinamento _ _;) _=cei _LL MϕR.L. _( xpré - treinamento _ _)
A função objetivo final é a soma das duas e, na configuração RL, maximiza a função objetivo.
objetivo ( ϕ ) = E x ∼ DRLE y ∼ LLM ϕ RL ( x ) [ RM ( x , y ) − β log LLM ϕ RL ( y ∣ x ) LLMSFT ( y ∣ x ) ] + γ E x ∼ D pré-treinamento log LLM ϕ RL ( x ) objetivo (ϕ)=E_{x \sim D_{RL}}E_{y∼LLM^{RL}_ϕ(x)}[RM(x,y)−β\log\frac {LLM^{RL}_ϕ(y|x)}{LLM^{SFT}(y|x)]}+γE_x∼D_{pré-treinamento}\log LLM^{RL}_ϕ(x)o bj ec t i v e ( ϕ )=Ex ∼ DR.L. _Ey ∼ LL MϕR.L. _( x )[ RM ( x ,você )-bei _LL MSFT (y∣x)]LL MϕR.L. _( y ∣ x )+c Ex∼Dpré - treinamento _ _ei _LL MϕR.L. _( x )
A função objetivo do artigo InstructGPT com o mesmo significado é:

Modelo de linguagem grande conteúdo gerado ficticiamente
Encontrei duas hipóteses para explicar a produção de conteúdo construtivo do LLM:
A primeira hipótese, proposta pela primeira vez na DeepMind por Pedro A. Ortega et al., em outubro de 2021, era que os LLMs foram gerados devido à sua "falta de compreensão da causa e efeito de suas ações " (na época, a DeepMind usava a palavra "delírio" por "alucinações"). Eles mostram que isto pode ser resolvido encarando a geração de respostas como uma intervenção causal.
A segunda hipótese é que a geração de ficção é causada por um descompasso entre o conhecimento interno do LLM e o conhecimento interno do rotulador. Em uma palestra na UC Berkeley (abril de 2023), o cofundador da OpenAI e autor do PPO, John Schulman, sugeriu que a clonagem comportamental pode levar à geração espúria. Durante o SFT, o LLM é treinado para imitar respostas escritas por humanos. Se respondermos com o conhecimento que temos, mas o LLM não, estamos ensinando ficção no LLM.
Em dezembro de 2021, outro funcionário da OpenAI, Leo Gao, também expôs muito bem esse ponto . Em teoria, os anotadores humanos poderiam incluir todo o contexto que conhecem em cada prompt para ensinar o modelo a usar apenas o conhecimento existente. No entanto, isso não é possível na prática.
Schulman argumenta que os LLMs sabem se sabem alguma coisa, o que significa que se encontrarmos uma forma de forçar os LLMs a dar respostas que contenham apenas informações que eles conhecem, a ficção pode ser resolvida. Então ele propôs várias soluções.
- Verificação: O LLM é solicitado a explicar (recuperar) a fonte de onde obteve a resposta.
- aprendizagem por reforço. Os modelos RM são treinados usando apenas comparações: a resposta A é melhor que a resposta B, sem qualquer informação sobre quanto ou por que A é melhor. Schulman argumenta que podemos resolver as alucinações tendo uma melhor função de recompensa, por exemplo, punindo um modelo imaginário.
Uma captura de tela da visão de Schulman de abril de 2023 sobre os métodos RL para resolver a ficção é a seguinte:

No entanto, o artigo do InstructGPT mostra que o RLHF na verdade torna a ficção pior. Como mostrado abaixo:
