De: Coma geleia sem cuspir a casca da geleia
Entre no grupo de PNL -> junte-se ao grupo de intercâmbio de PNL
Nos últimos anos, com a introdução das arquiteturas Transformer e MOE, o modelo de aprendizagem profunda pode facilmente romper trilhões de parâmetros.O modelo tradicional de máquina única e cartão único não pode mais atender aos requisitos de treinamento de modelos supergrandes. Portanto, precisamos treinar grandes modelos distribuídos baseados em cartões múltiplos de máquina única, ou mesmo cartões múltiplos de máquinas múltiplas.
O objetivo principal do aprendizado de máquina distribuído é usar clusters de IA para permitir que algoritmos de aprendizado profundo treinem de forma eficiente grandes modelos com excelente desempenho a partir de grandes quantidades de dados. Para atingir este objetivo, geralmente é necessário considerar a divisão das tarefas de computação, dados de treinamento e modelos de acordo com a correspondência de recursos de hardware e escala de dados/modelo, de modo a realizar armazenamento distribuído e treinamento distribuído. Portanto, as tecnologias distribuídas relacionadas com a formação merecem a nossa análise aprofundada do mecanismo por trás delas.
A seguir, explicamos principalmente a tecnologia paralela para treinamento distribuído de grandes modelos. Esta série está dividida em nove artigos.
Tecnologia paralela de treinamento distribuído de modelo grande (1) - visão geral
Tecnologia Paralela de Treinamento Distribuído de Modelo Grande (2) - Dados Paralelos
Tecnologia paralela de treinamento distribuído de modelo grande (3) - paralelismo de pipeline
Tecnologia paralela de treinamento distribuído de modelo grande (4) - Paralelismo de tensor
Tecnologia Paralela de Treinamento Distribuído de Modelo Grande (5) - Sequência Paralela
Tecnologia Paralela de Treinamento Distribuído de Modelo Grande (6) - Paralelo Híbrido Multidimensional
Tecnologia paralela de treinamento distribuído de modelo grande (7) - paralelismo automático
Tecnologia Paralela de Treinamento Distribuído de Modelo Grande (8) - MOE Paralelo
Tecnologia paralela de treinamento distribuído de grande modelo (9) - resumo
Este artigo é o primeiro sobre tecnologia paralela para treinamento distribuído e apresenta brevemente tecnologias paralelas comuns para treinamento distribuído de grandes modelos.
paralelismo de dados
O paralelismo de dados é a forma mais comum de paralelismo devido à sua simplicidade. No treinamento paralelo de dados, o conjunto de dados é dividido em vários fragmentos e cada fragmento é atribuído a um dispositivo. Isso equivale a paralelizar o processo de treinamento ao longo da dimensão do lote. Cada dispositivo conterá uma cópia completa do modelo, treinada nos fragmentos do conjunto de dados alocados. Após a retropropagação, todos os gradientes do modelo são reduzidos para que os parâmetros do modelo em diferentes dispositivos possam ser mantidos sincronizados. Implementação paralela de dados típica: PyTorch DDP.
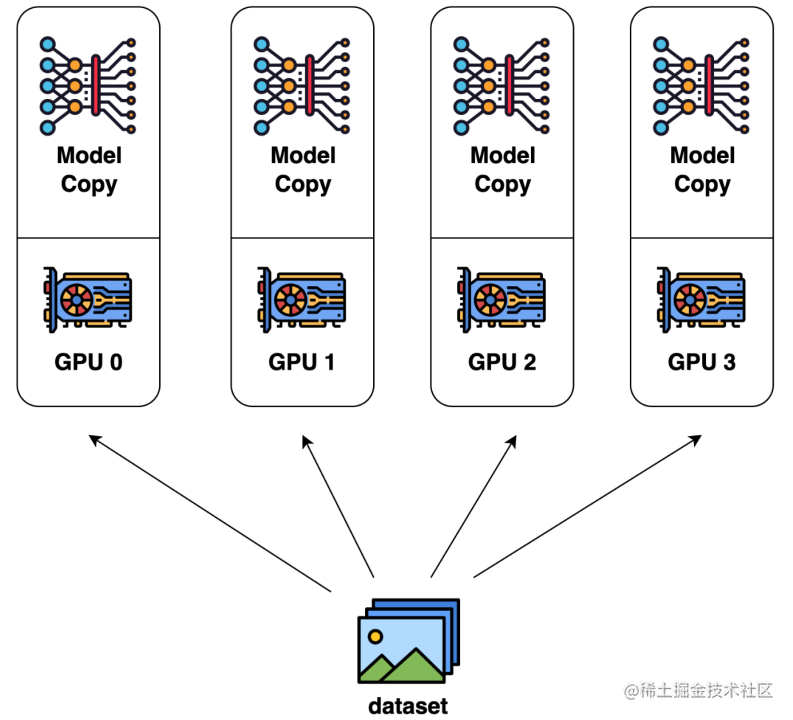
paralelismo de modelo
Um recurso notável no treinamento paralelo de dados é que cada GPU contém uma cópia de todos os pesos do modelo. Isso cria um problema de redundância. Outro modo de paralelismo é o paralelismo de modelo, onde o modelo é particionado e distribuído por uma série de dispositivos.
Geralmente existem dois tipos de paralelismo de modelo: paralelismo de tensor e paralelismo de pipeline.
O paralelismo tensorial é a computação paralela em uma operação, como a multiplicação matriz-matriz.
O paralelismo de pipeline é a computação paralela entre camadas.
Portanto, de outra perspectiva, o paralelismo tensorial pode ser visto como paralelismo intracamada, e o paralelismo pipeline pode ser visto como paralelismo intercamada.
Tensor Paralelo
O treinamento paralelo de tensores consiste em dividir um tensor em N blocos ao longo de uma dimensão específica, e cada dispositivo contém apenas 1/N de todo o tensor, sem afetar a correção do gráfico de cálculo. Isso requer comunicação adicional para garantir a exatidão dos resultados.
Tomando como exemplo a multiplicação geral de matrizes, suponha que temos C = AB. Podemos dividir B em [B0 B1 B2 ... Bn] ao longo das colunas, com cada dispositivo segurando uma coluna. Então multiplicamos A por cada coluna de B em cada dispositivo e obteremos [AB0 AB1 AB2 ... ABn] . Neste momento, cada dispositivo ainda contém uma parte do resultado, por exemplo, o dispositivo (classificação=0) contém AB0. Para garantir a exatidão dos resultados, precisamos coletar todos os resultados e concatenar os tensores ao longo da dimensão. Dessa forma, podemos distribuir tensores entre dispositivos e, ao mesmo tempo, garantir que o pipeline de computação permaneça correto.
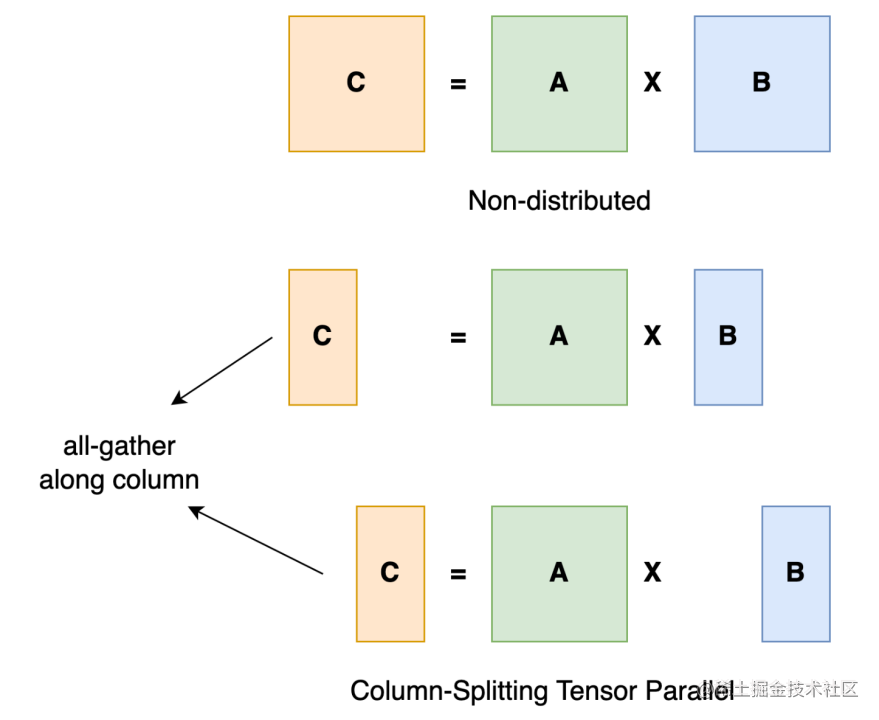
Implementações típicas de tensores paralelos: Megatron-LM (1D), Colossal-AI (2D, 2.5D, 3D).
Pipeline Paralelo
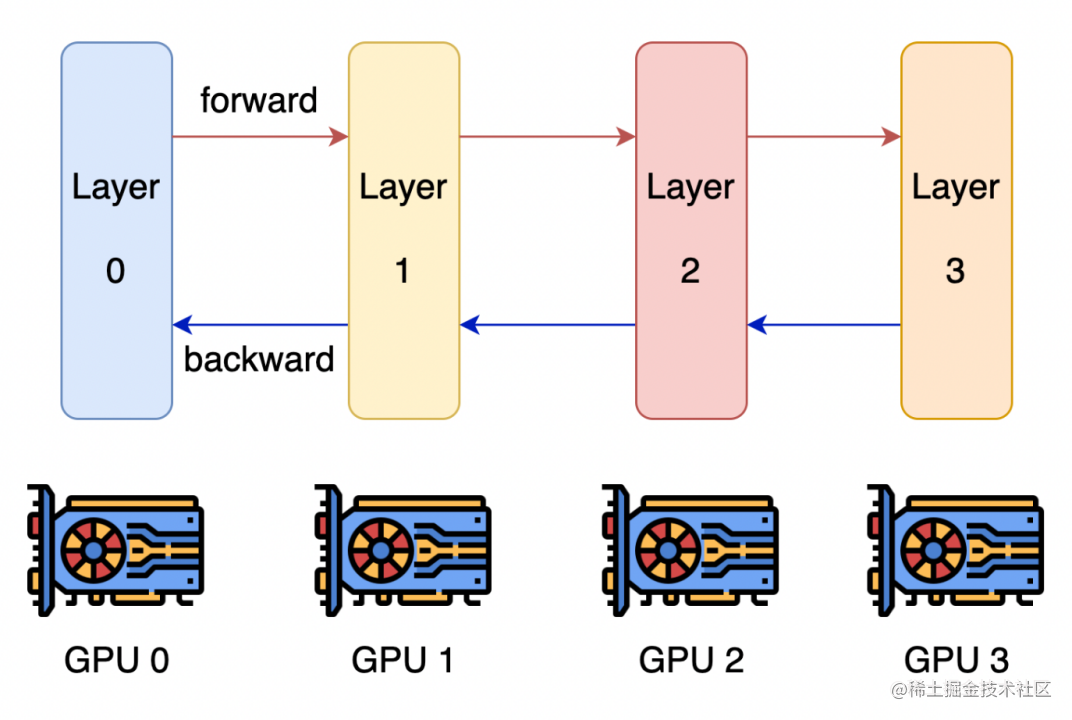
A ideia central do paralelismo de pipeline é que o modelo seja dividido em vários blocos por camadas, e cada bloco seja entregue a um dispositivo.
Durante a propagação direta, cada dispositivo passa ativações intermediárias para o próximo estágio.
Durante a retropropagação, cada dispositivo passa o gradiente do tensor de entrada de volta ao estágio anterior do pipeline.
Isso permite que os dispositivos realizem cálculos simultaneamente, aumentando o rendimento do treinamento.
Uma desvantagem óbvia do treinamento paralelo em pipeline é que o equipamento de treinamento está sujeito ao estado ocioso (porque o último estágio precisa esperar a conclusão do estágio anterior), resultando em desperdício de recursos de computação, e a eficiência de aceleração não é tão alta quanto a de dados paralelismo.
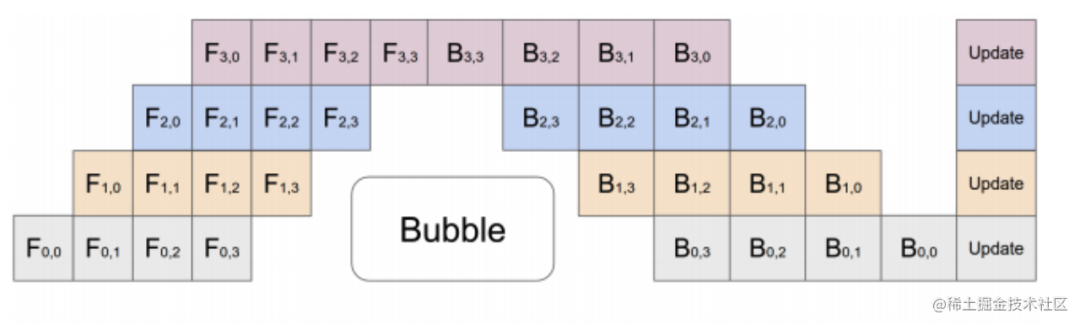
Implementações paralelas de pipeline típicas: GPipe, PipeDream, PipeDream-2BW, PipeDream Flush (1F1B).
paralelismo dependente do otimizador
Atualmente, à medida que o modelo se torna cada vez maior, a memória de vídeo de uma única GPU geralmente não consegue conter um modelo tão grande. Então devemos encontrar uma forma de otimizar o local onde a memória de vídeo está ocupada.
De modo geral, durante o processo de treinamento do modelo, os parâmetros que precisam ser armazenados na GPU incluem os parâmetros do próprio modelo, o estado do otimizador, o valor de saída da função de ativação, o gradiente e alguns buffers de tempo zero . A proporção de vários dados é mostrada na figura abaixo:
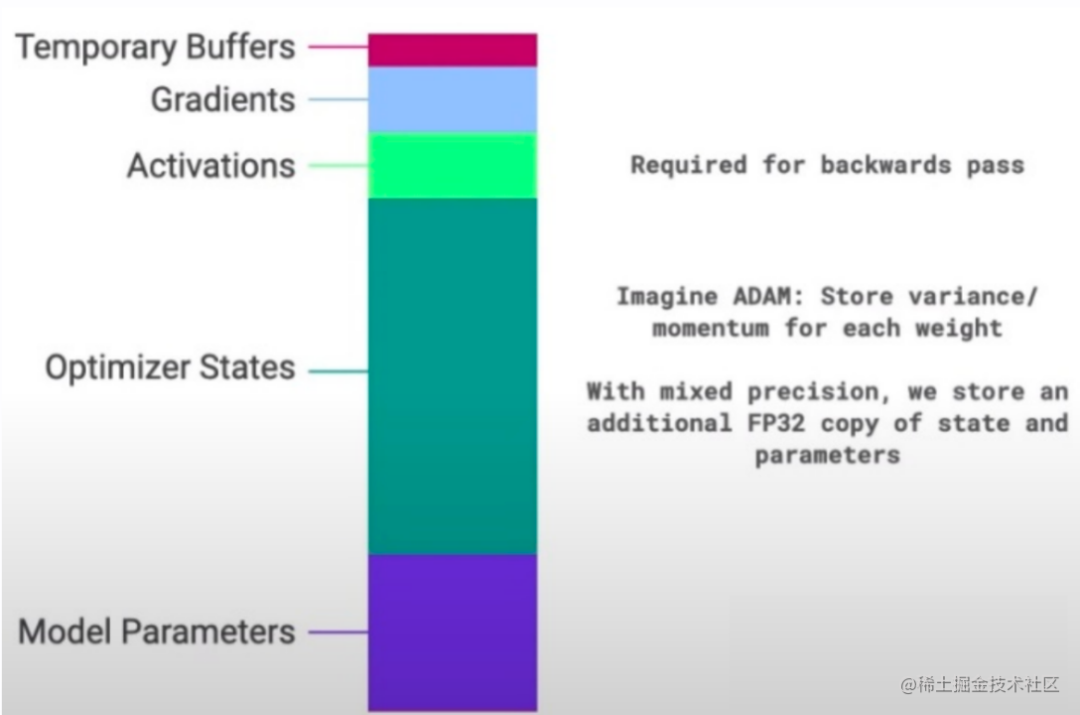
Pode-se observar que os parâmetros do modelo representam apenas uma parte de todos os dados no processo de treinamento do modelo. Ao realizar operações de precisão mista, os parâmetros de estado do modelo (estado do otimizador + gradiente + parâmetros do modelo) representam mais da metade. Portanto, precisamos encontrar uma maneira de remover dados redundantes durante o treinamento do modelo.
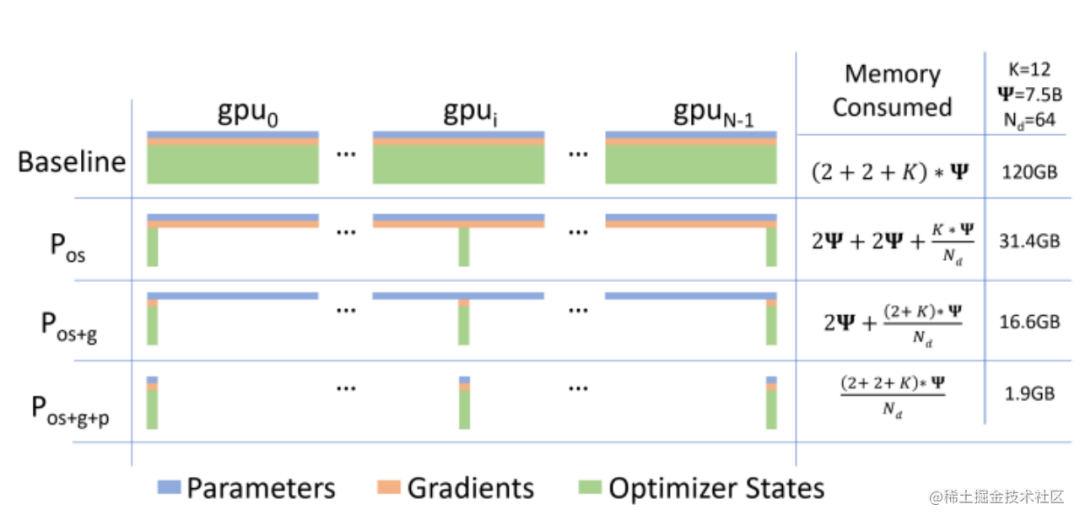
O paralelismo relacionado ao otimizador é um esquema paralelo para remoção de dados redundantes.Atualmente, o método mais popular desse tipo de paralelismo é o ZeRO (Zero Redundancy Optimizer). Para a otimização de armazenamento (remoção de redundância) do estado do modelo, o ZeRO utiliza sharding, ou seja, cada cartão armazena apenas 1/N do estado do modelo, de forma que apenas uma cópia do estado do modelo seja mantida no sistema. ZeRO possui três níveis diferentes, que fragmentam o estado do modelo em diferentes graus:
ZeRO-1: fragmentação de estados do otimizador
ZeRO-2: fragmentação de estados e gradientes do otimizador
ZeRO-3: Fragmentação de estados, gradientes e parâmetros do otimizador para fragmentação de estados, gradientes e parâmetros do otimizador
Sistema Heterogêneo Paralelo
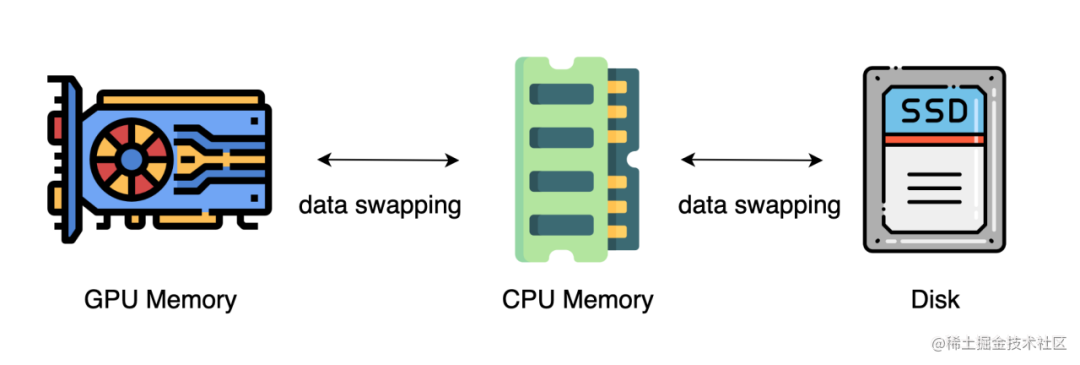
Nos métodos acima, geralmente é necessário um grande número de GPUs para treinar um modelo grande. O que muitas vezes é esquecido, entretanto, é que as CPUs têm significativamente mais memória do que as GPUs. Em um servidor típico, a CPU pode facilmente ter centenas de gigabytes ou até terabytes de memória, enquanto cada placa GPU normalmente possui apenas 48 ou 80 GB de memória. Isso leva as pessoas a se perguntarem por que a memória da CPU não está sendo usada para treinamento distribuído.
Avanços mais recentes dependem de CPUs ou mesmo de discos NVMe para treinar modelos grandes. A ideia principal é descarregar os tensores de volta para a memória da CPU ou disco NVMe quando não estiverem em uso.
Ao utilizar uma arquitetura de sistema heterogênea, é possível acomodar um modelo enorme em uma única máquina.
Paralelismo Misto Multidimensional
O paralelismo híbrido multidimensional refere-se à combinação de múltiplas tecnologias paralelas, como paralelismo de dados, paralelismo de modelo e paralelismo de pipeline para treinamento distribuído.
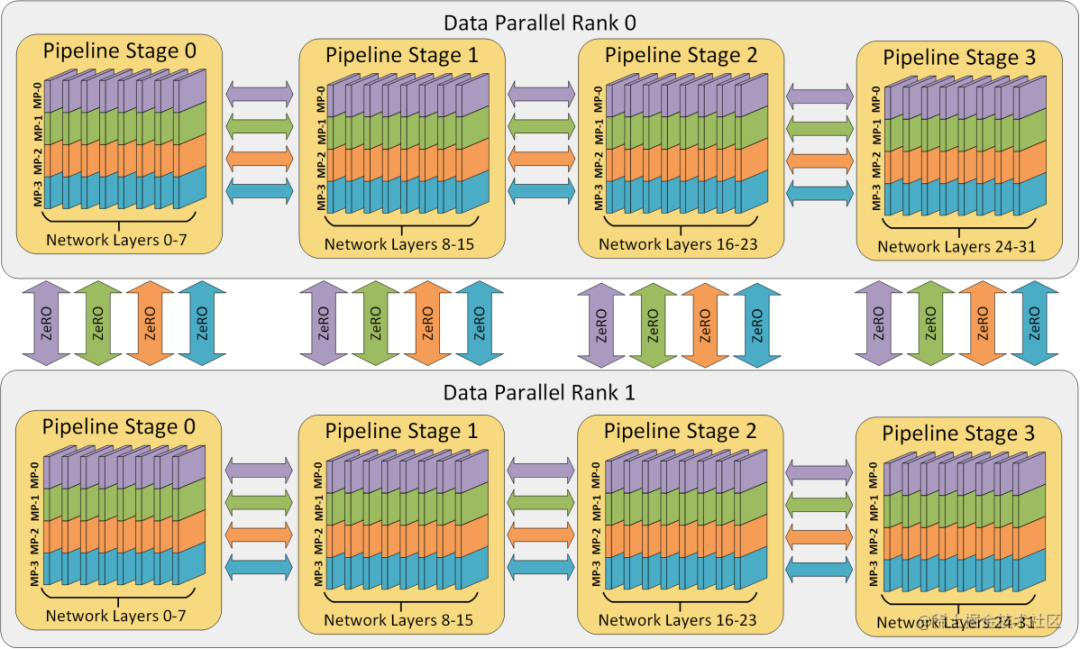
Normalmente, o paralelismo híbrido multidimensional é necessário para o pré-treinamento e o ajuste fino de todos os parâmetros de modelos de grande escala.
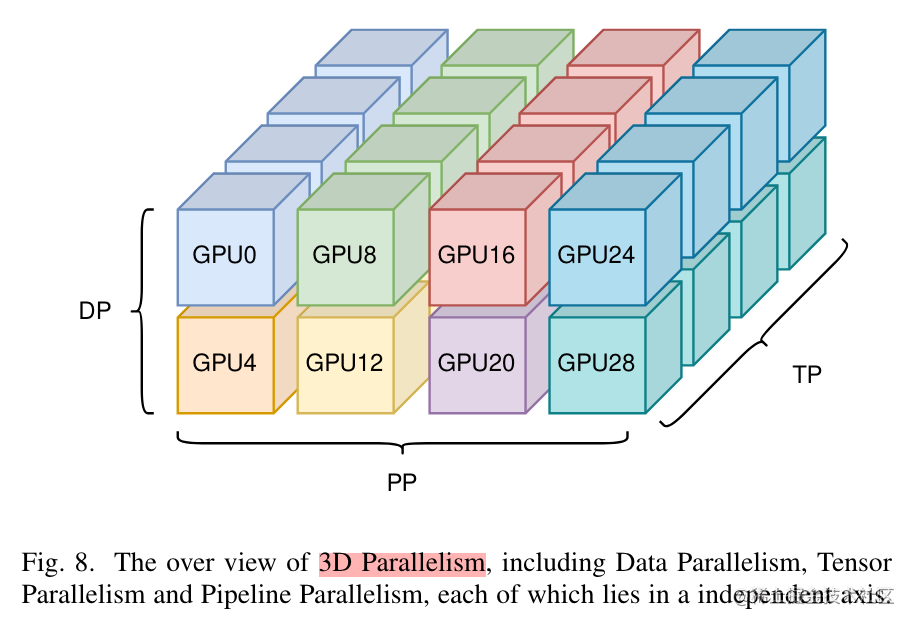
Para aproveitar ao máximo a largura de banda, em geral, a quantidade de comunicação necessária para o paralelismo tensor é a maior, enquanto a quantidade de comunicação necessária para o paralelismo de dados e o paralelismo de pipeline é relativamente pequena. Portanto, o paralelismo de tensores é usado dentro do mesmo servidor, enquanto o paralelismo de dados e o paralelismo de pipeline são usados entre servidores.
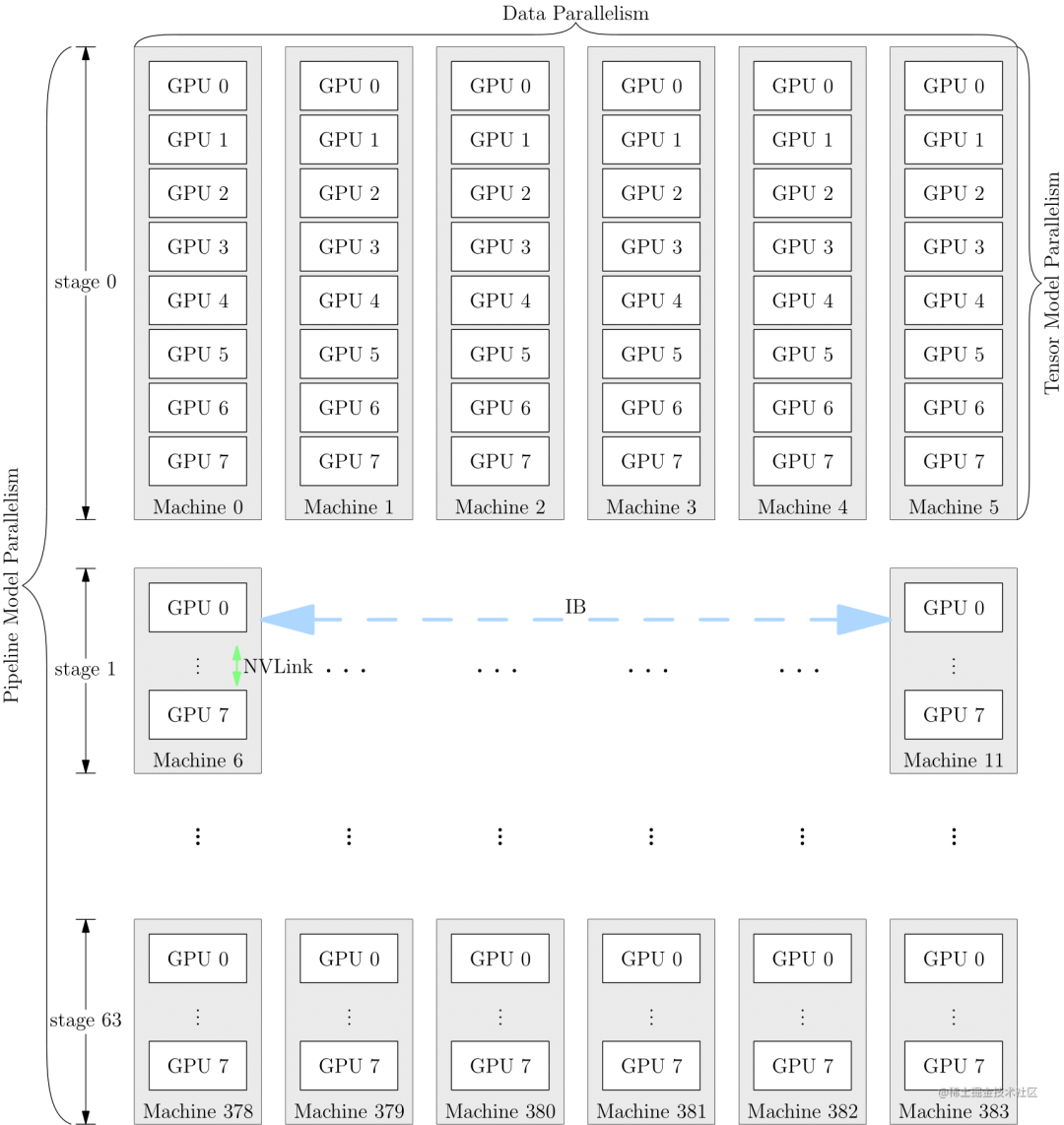
paralelização automática
O paralelismo híbrido multidimensional mencionado acima, como paralelismo de dados, paralelismo de tensor e paralelismo de pipeline, precisa dividir o modelo em vários cartões aceleradores de IA. Se os usuários forem obrigados a implementá-lo manualmente, será muito difícil para os desenvolvedores, e desempenho e memória precisam ser considerados. , comunicação, efeitos de treinamento e outras questões, se o modelo puder ser dividido automaticamente em diferentes placas aceleradoras por operador ou camada, isso pode reduzir bastante a dificuldade dos desenvolvedores. Portanto, surgiu o paralelismo automático.
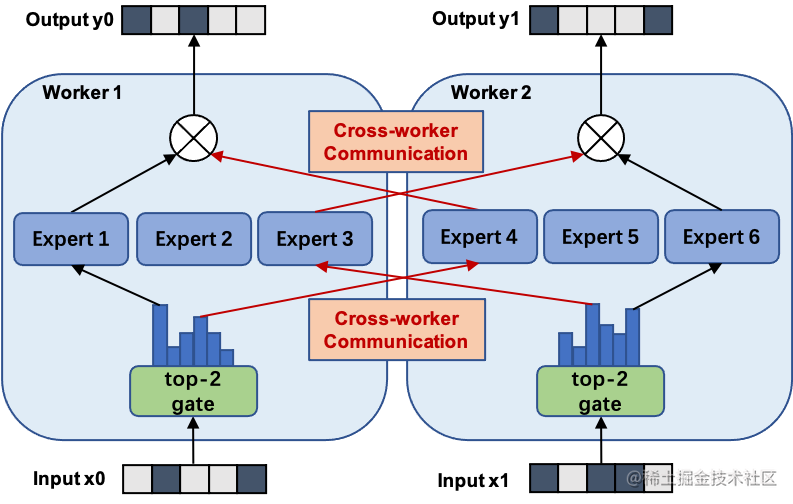
MOE Paralelo/Expert Paralelo
De modo geral, a expansão da escala do modelo levará a um aumento significativo nos custos de treinamento, e a limitação dos recursos computacionais tornou-se o gargalo do treinamento intensivo de modelos em larga escala. Para resolver este problema, é proposta uma arquitetura de modelo de aprendizagem profunda baseada em uma camada esparsa de MoE, ou seja, o modelo grande é dividido em vários modelos pequenos (especialistas, ), e cada rodada de iteração decide ativar uma parte do especialistas para cálculo de acordo com a amostra, o que experteconomiza o efeito dos recursos de computação; e introduz um mecanismo de porta () que pode ser treinado e garante esparsidade gate para garantir a otimização do poder de computação.
Usando a estrutura do MoE, o treinamento de modelos em grande escala pode ser alcançado enquanto o custo computacional aumenta sublinearmente, trazendo enormes ganhos para um orçamento constante de recursos computacionais. O paralelo MOE é essencialmente um método paralelo de modelo. A figura abaixo mostra um modelo com seis redes de especialistas sendo treinadas em paralelo por dois especialistas. Entre eles, os especialistas 1 a 3 são colocados na primeira unidade de computação e os especialistas de 4 a 6 são colocados na segunda unidade de computação.
epílogo
Este artigo apresenta brevemente tecnologias paralelas comuns para treinamento distribuído de grandes modelos. Os capítulos subsequentes explicarão em detalhes as diferentes soluções de tecnologias paralelas comuns.
Entre no grupo de PNL -> junte-se ao grupo de intercâmbio de PNL