
O compartilhamento de dados está se tornando um elemento importante das estratégias de dados empresariais. Para as empresas, os serviços de tecnologia em nuvem da Amazon, como o Amazon Data Exchange, oferecem uma maneira de compartilhar ou monetizar dados de valor agregado com outras empresas. Algumas empresas pretendem uma plataforma de partilha de dados onde possam construir uma abordagem colaborativa e estratégica para a troca de dados com um conjunto limitado de empresas num ambiente fechado, seguro e exclusivo. Por exemplo, uma empresa de serviços financeiros com a sua empresa de auditoria ou uma empresa de produção com os seus parceiros da cadeia de abastecimento. Isto pode facilitar o desenvolvimento de novos produtos e serviços e ajudar a tornar as suas operações mais eficientes.
A partilha de dados é um esforço de equipa e vale a pena notar que, além de construir a infra-estrutura certa, uma partilha de dados bem sucedida também exige que as empresas garantam que os líderes empresariais apoiam iniciativas de partilha de dados. Eles também precisam garantir que dados de alta qualidade estejam disponíveis. Os proprietários de plataformas de dados e as equipes de segurança devem incentivar o uso adequado dos dados e corrigir quaisquer problemas de privacidade e confidencialidade.
Este artigo discute várias opções de compartilhamento de dados e padrões de arquitetura comuns que as empresas podem adotar para configurar sua infraestrutura de compartilhamento de dados com base na disponibilidade do serviço de nuvem da Amazon e na conformidade de dados.
Opções de compartilhamento de dados e tipos de classificação de dados
As empresas estão sujeitas a vários requisitos de conformidade de segurança durante a operação. Algumas empresas podem usar Amazon Web Services como Amazon Data Exchange. No entanto, algumas organizações que trabalham em setores fortemente regulamentados, como agências federais ou serviços financeiros, podem estar limitadas a usar opções expressamente permitidas do Amazon Web Services. Por exemplo, se uma empresa for obrigada a operar em um ambiente Fedramp Medium ou Fedramp High, suas opções de compartilhamento de dados poderão ser limitadas aos serviços da AWS disponíveis e expressamente permitidos. A disponibilidade do serviço é baseada na certificação da plataforma da Amazon Cloud Technology, e a lista de permissões é baseada na definição da empresa sobre sua estrutura e diretrizes de conformidade de segurança.
O tipo de dados que uma empresa pretende partilhar com os seus parceiros também pode ter impacto no método utilizado para a partilha de dados. O cumprimento das regras de classificação de dados pode limitar ainda mais as opções de partilha de dados que podem escolher.
Aqui estão alguns tipos gerais de classificação de dados:
Dados Públicos – Informações que são importantes, mas geralmente gratuitas para as pessoas lerem, pesquisarem, visualizarem e armazenarem. Esses dados geralmente têm a classificação de dados e o nível de segurança mais baixos.
Dados privados – Informações que você deseja manter privadas, como conteúdo de caixas de entrada de e-mail, telefones celulares, números de identificação de funcionários ou endereços de funcionários. Os dados privados podem representar um pequeno risco para indivíduos ou empresas se forem partilhados, destruídos ou alterados.
Dados confidenciais ou restritos – Informações confidenciais às quais indivíduos ou grupos limitados têm acesso, geralmente exigindo permissão ou autorização especial. O acesso a dados confidenciais ou restritos pode envolver aspectos como gestão de identidade e autorização. Exemplos de dados confidenciais incluem números de segurança social e números de identificação de veículos.
Abaixo está um exemplo de árvore de decisão que você pode consultar ao escolher uma opção de compartilhamento de dados com base na disponibilidade do serviço, tipo de classificação e formato de dados (estruturados ou não estruturados). Outros fatores, como disponibilidade, acessibilidade a múltiplos parceiros, tamanho dos dados, padrões de uso (carregamento em massa/acesso à API), etc., também podem influenciar a escolha do modelo de compartilhamento de dados.
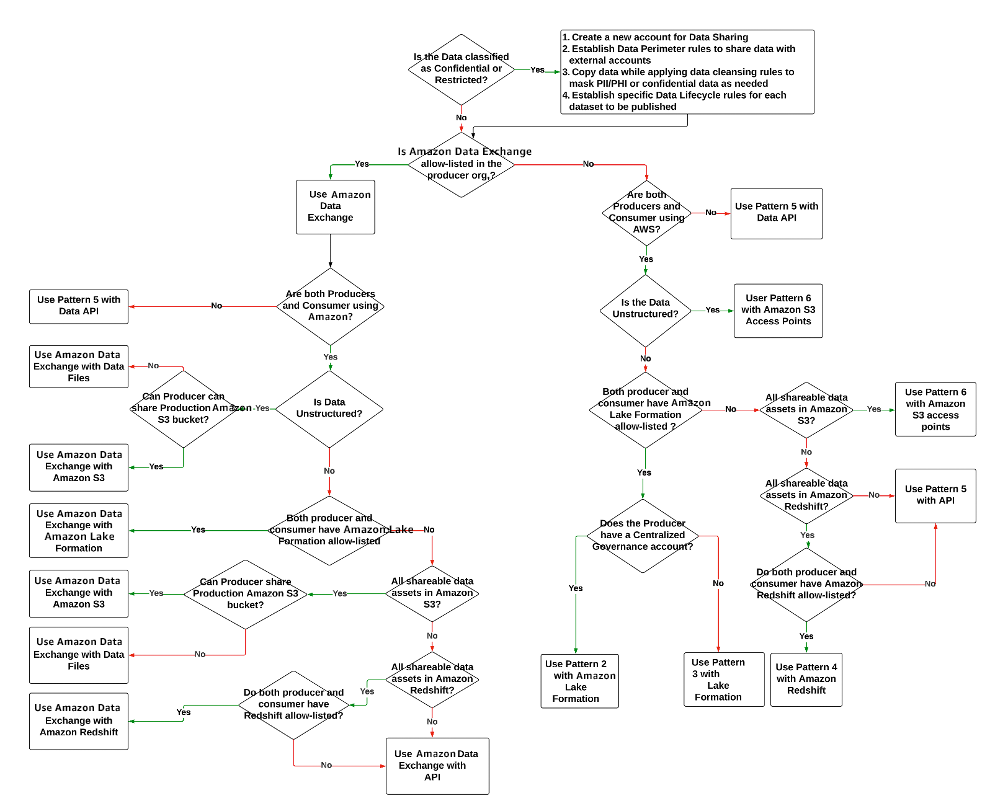
Nas seções a seguir, discutiremos cada modo em detalhes.
Modo 1:
Usando o Amazon Data Exchange
O Amazon Data Exchange simplifica o processo de troca de dados, ajudando as empresas a reduzir custos, aumentar a agilidade e acelerar a inovação. As empresas podem optar por compartilhar dados de forma privada com parceiros externos usando o Amazon Data Exchange. O Amazon Data Exchange fornece controles de limite aplicados em nível de identidade e recurso. Esses controles determinam quais identidades externas têm acesso a recursos de dados específicos. O Amazon Data Exchange oferece vários modos diferentes para partes externas acessarem dados, como:
Amazon Data Exchange para Amazon Redshift
Amazon Data Exchange para Amazon Lake Formation (atualmente em versão prévia)
Amazon Data Exchange para APIs de dados
Amazon Data Exchange para arquivos de dados
Amazon Data Exchange para Amazon S3 (atualmente em versão prévia)
O diagrama a seguir mostra um exemplo de arquitetura.
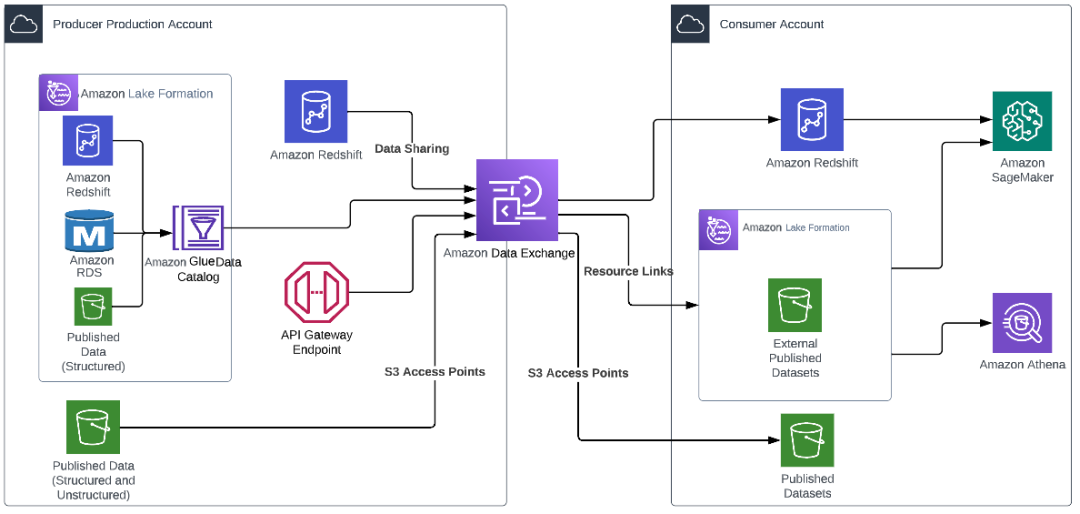
Com o Amazon Data Exchange, depois que um conjunto de dados é configurado para ser compartilhado (ou vendido), o Amazon Data Exchange gerencia automaticamente a autorização (e o faturamento) entre criadores e consumidores. Os criadores não precisam gerenciar políticas, configurar novos pontos de acesso ou criar novos compartilhamentos de dados do Amazon Redshift para cada consumidor, e o acesso é automaticamente revogado no final da assinatura. Isto pode reduzir significativamente a sobrecarga operacional do compartilhamento de dados.
Modo 2:
Usando a formação do Amazon Lake
Gerenciamento de acesso centralizado
Você pode usar esse modo quando criadores e usuários usam Amazon Web Services e têm contas da Amazon Web Services que podem usar o Amazon Lake Formation. Esse padrão fornece uma maneira de compartilhar dados sem escrever código. O diagrama a seguir mostra um exemplo de arquitetura.
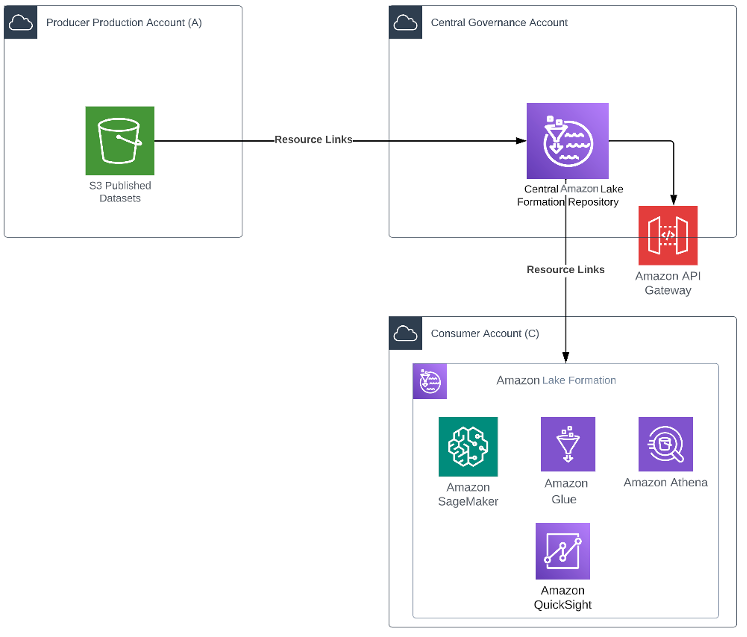
Neste modelo, uma conta de custódia central é configurada com Lake Formation, que gerencia o acesso às contas empresariais criadoras. Links de recursos no bucket Amazon Simple Storage Service (Amazon S3) da conta de produção são criados no Lake Formation. O criador concede permissões do Lake Formation no recurso Amazon Glue Data Catalog para uma conta externa ou diretamente para um principal do Amazon Identity and Access Management (IAM) em outra conta. Lake Formation usa Amazon Resource Access Manager (Amazon RAM) para compartilhar recursos. Se a conta do beneficiário pertencer à mesma empresa que a conta do concedente, o recurso partilhado pode ser imediatamente fornecido ao beneficiário. Se a conta do beneficiário não pertencer à mesma empresa, o Amazon RAM enviará um convite à conta do beneficiário para aceitar ou recusar a concessão de recursos. Para que o recurso compartilhado esteja disponível para uso, um administrador consumidor na conta do beneficiário deve aceitar o convite usando o console do Amazon RAM ou a Amazon Command Line Interface (Amazon CLI).
Os principais autorizados podem compartilhar recursos explicitamente com os principais do IAM em contas externas. Este recurso é útil quando os criadores desejam controlar quem em uma conta externa pode acessar seus recursos. Os principais do IAM obtêm permissões concedidas diretamente, além de permissões concedidas no nível da conta e transmitidas ao principal. O administrador do data lake da conta receptora pode visualizar autorizações diretas entre contas, mas não pode revogar permissões.
Modo 3:
Use da conta compartilhada externamente do criador
Formação do Lago Amazonas
Os criadores podem ter requisitos de segurança rigorosos para que nenhum utilizador externo tenha acesso às suas contas de produção ou às suas contas de governação centralizadas. Também é possível que eles não tenham habilitado o Lake Formation em suas plataformas de produção. Nesse caso, a conta de produção do criador (Conta A) é dedicada aos seus usuários corporativos internos, conforme diagrama abaixo. O criador cria outra conta, a conta de compartilhamento externo do criador (Conta B), dedicada ao compartilhamento externo. Isso permite aos criadores maior liberdade para criar políticas específicas para negócios específicos.
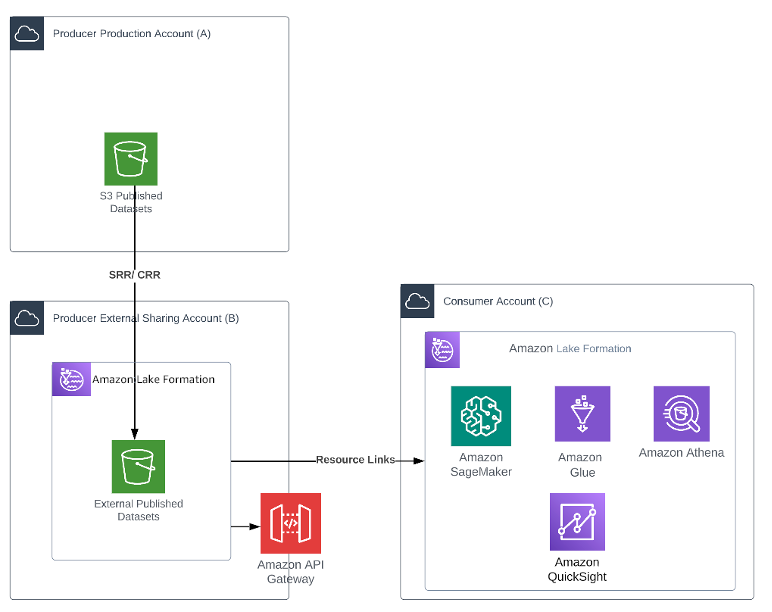
O criador implementa um processo para criar uma cópia assíncrona dos dados na conta B. Para objetos que precisam ser compartilhados, o bucket pode ser configurado como replicação na mesma região (SRR, replicação na mesma região) ou replicação entre regiões (CRR, replicação entre regiões). Isso ajuda a liberar automaticamente os dados para o bucket S3 de conjuntos de dados publicados externos da conta externa sem gravar nenhum código.
Ao criar cópias de dados, os criadores podem isolar ainda mais os consumidores externos dos seus dados de produção. Também pode ajudar com quaisquer requisitos de conformidade ou soberania de dados.
O Lake Formation é configurado na conta B, e o administrador cria um link de recurso para o bucket S3 de conjuntos de dados publicados externos na conta para conceder acesso. O administrador concede acesso seguindo o mesmo processo descrito anteriormente.
Modo 4:
Usando o compartilhamento de dados do Amazon Redshift
Este modelo é ideal para criadores que publicam produtos de dados principalmente no Amazon Redshift. Esse modelo também exige que tanto a conta de compartilhamento externa do criador (Conta B) quanto a conta do consumidor (Conta C) tenham um cluster criptografado do Amazon Redshift ou um endpoint do Amazon Redshift Serverless e que atendam aos pré-requisitos de compartilhamento de dados do Amazon Redshift.
O diagrama arquitetônico a seguir mostra uma visão geral do esquema.
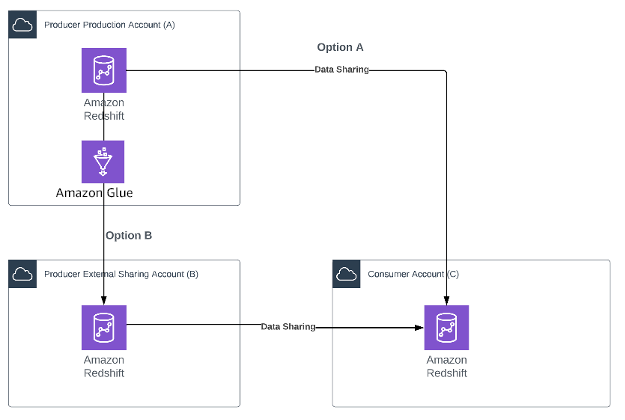
Dependendo das restrições de conformidade do criador, existem duas opções:
Opção A : o criador permite o compartilhamento de dados diretamente no cluster de produção do Amazon Redshift.
Opção B – O criador pode impor restrições ao compartilhamento do cluster de produção. O criador cria um trabalho simples do Amazon Glue para copiar dados do cluster do Amazon Redshift da conta de produção A para o cluster do Amazon Redshift da conta externa B. Este trabalho do Amazon Glue pode agendar atualizações de dados sob demanda dos consumidores. Quando há dados na conta B, o criador pode criar diversas visualizações e vários compartilhamentos de dados conforme necessário.
Em ambas as opções, os criadores têm controle total sobre quais dados são compartilhados, enquanto os administradores consumidores têm controle total sobre quais usuários em sua empresa podem acessar os dados.
Depois que o criador e os administradores consumidores aprovarem a solicitação de compartilhamento de dados, o usuário consumidor poderá acessar os dados como se existissem em sua própria conta, sem escrever nenhum código adicional.
Modo 5:
Compartilhe dados de forma segura e privada usando APIs
Você pode usar esse modelo quando o parceiro externo não estiver usando nenhum serviço da AWS. Você também pode usar esse padrão quando o produto de dados publicado for distribuído entre vários serviços (por exemplo, Amazon S3, Amazon Redshift, Amazon DynamoDB e Amazon OpenSearch Service) e o criador quiser manter uma interface única para compartilhar os dados.
Um exemplo desse cenário de uso é o seguinte: a Empresa A deseja compartilhar alguns dados de log quase em tempo real com sua parceira, a Empresa B, e a Empresa B usa esses dados para gerar insights preditivos para a Empresa A. A empresa A armazena esses dados no Amazon Redshift. A Empresa A deseja mascarar informações de identificação pessoal (PII) antes de compartilhar dados transacionais com parceiros para gerar insights de maneira acessível e segura. A Empresa B não usa serviços de tecnologia em nuvem da Amazon.
A empresa A usa funções do Amazon Lambda ou Amazon Glue para configurar um pequeno processo em lote que consulta o Amazon Redshift em busca de dados de log incrementais, aplica regras para mascarar PII e carrega esses dados em um bucket S3 de conjuntos de dados publicados. Isso instanciará o processo SRR/CRR que libera esses dados no bucket S3 de compartilhamento externo.
O diagrama abaixo mostra como os consumidores podem acessar esses dados por meio de uma abordagem baseada em API.

Este fluxo de trabalho consiste nas seguintes etapas:
Os consumidores de API enviam solicitações de API HTTPS para a camada de proxy da API.
O API Proxy encaminha solicitações de API HTTPS para o Amazon API Gateway em uma conta da Amazon Web Services compartilhada externamente.
O Amazon API Gateway invoca a função Amazon Lambda do receptor de solicitação.
A função de receptor de solicitação grava o estado na tabela de controle do DynamoDB.
A segunda função Lambda é um poller que verifica o status dos resultados na tabela do DynamoDB.
A função poller extrai resultados do Amazon S3.
A função poller envia ao solicitante um URL pré-assinado para baixar o arquivo do bucket S3 por meio do Amazon Simple Email Service (Amazon SES).
O solicitante usa esse URL para fazer download do arquivo.
As contas AWS de periféricos de rede permitem apenas conexões de saída com a Internet.
A camada proxy da API impõe controles de segurança de saída e um firewall de perímetro antes que o tráfego saia do perímetro de rede do criador.
A tabela de rotas VPC de saída segura do Amazon Transit Gateway permite conexões apenas da sub-rede do criador desejada, evitando o acesso à Internet.
Modo 6:
Use um ponto de acesso do Amazon S3.
Os cientistas de dados podem precisar colaborar em imagens, vídeos e documentos de texto. As equipes jurídicas e de auditoria podem precisar compartilhar relatórios e declarações com os auditores. Este padrão discute métodos para compartilhar tais documentos. Este modelo pressupõe que parceiros externos também usam a tecnologia Amazon Cloud. Os pontos de acesso do Amazon S3 permitem que os criadores configurem o acesso entre contas, compartilhando o acesso com seus consumidores sem editar políticas de bucket.
Um ponto de acesso é um endpoint de rede designado conectado a um bucket que pode ser usado para executar operações de objeto S3, como GetObject e PutObject. Cada ponto de acesso tem permissões e controles de rede diferentes que o Amazon S3 aplica a qualquer solicitação feita por meio desse ponto de acesso. Cada ponto de acesso impõe uma política de ponto de acesso personalizada, que é usada em conjunto com a política de bucket anexada ao bucket subjacente.
O diagrama arquitetônico a seguir mostra uma visão geral do esquema.
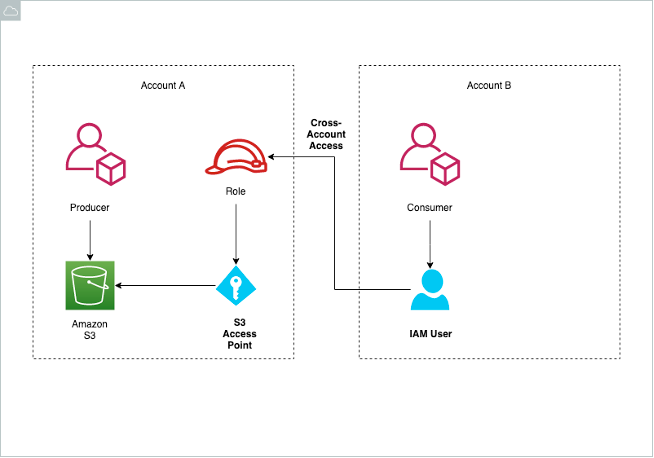
O criador cria o bucket S3 e habilita o uso do ponto de acesso. Como parte da configuração, os criadores especificam usuários, funções do IAM e permissões para consumidores.
Um usuário consumidor com uma função IAM na conta de consumidor pode acessar o bucket S3 pela Internet, bem como por meio do VPC endpoint e do Amazon PrivateLink, somente por meio do Amazon VPC.
Resumir
Cada empresa tem um conjunto único de restrições e requisitos que precisam ser atendidos para construir uma solução eficaz de compartilhamento de dados. Nesta postagem, apresentamos as diversas opções e práticas recomendadas disponíveis para as empresas. Os proprietários de plataformas de dados e as equipes de segurança devem trabalhar juntos para avaliar qual abordagem é melhor para sua situação específica. A equipe de contas da Amazon Web Services também pode ajudar.
recursos relacionados
Para obter mais informações sobre tópicos relacionados, consulte o seguinte:
Limite de dados na tecnologia Amazon Cloud
https://aws.amazon.com/identity/data-perimeters-on-aws/
Troca de dados da Amazon
https://aws.amazon.com/data-exchange/
Compartilhe dados com segurança entre contas da AWS usando o Amazon Lake Formation
https://aws.amazon.com/blogs/big-data/securely-share-your-data-across-aws-accounts-using-aws-lake-formation/
Compartilhe dados entre clusters no Amazon Redshift
https://docs.aws.amazon.com/redshift/latest/dg/datashare-overview.html
Configurando o acesso entre contas do Amazon S3 usando pontos de acesso S3
https://aws.amazon.com/blogs/storage/setting-up-cross-account-amazon-s3-access-with-s3-access-points/
URL original:
https://aws.amazon.com/blogs/big-data/patterns-for-enterprise-data-sharing-at-scale/
O autor deste artigo

Venkata Sistla
Cloud Architect na Amazon Web Technologies, com foco em dados e análises. Ele é especialista na construção de recursos de processamento de dados que ajudam os clientes a remover restrições que os impedem de aproveitar os dados para obter insights de negócios.

Santosh Chiplunkar
Arquiteto Residente Chefe da Amazon Cloud Technology. Ele tem mais de 20 anos de experiência ajudando clientes a resolver desafios de dados. Ele ajuda os clientes a desenvolver estratégias de dados e análises e fornece orientação sobre como implementá-las.


Ouvi dizer, clique nos 4 botões abaixo
Você não encontrará bugs!
