
Envie uma mensagem para um colega de classe P pequeno que não quer ser identificado
0 Prefácio
Com a escala crescente de modelos e poder de computação, o treinamento não está mais limitado a um único cartão, mas uma abordagem paralela de várias máquinas e vários cartões para o treinamento de modelos. Ao mesmo tempo, existem muitos esquemas de otimização de treinamento paralelo diferentes, e o paralelismo de modelo é um deles.A seguir, apresentaremos três aspectos.
- Motivação e estado atual do paralelismo de modelos
- O princípio do paralelismo de modelos
- Combinando paralelismo de dados e paralelismo de modelo
1 Motivação e situação atual do paralelismo de modelos
1.1 Motivação
Ao treinar modelos grandes, limitados pelo tamanho da memória da placa gráfica, precisamos aplicar uma série de métodos técnicos para reduzir a memória computacional . Principalmente por dois aspectos:
- Memória de computação otimizada em um único cartão;
- Use vários cartões para compartilhar.
Na fragmentação de estado do Optimizer (ZeRO) , abordamos vários métodos que são usados na prática. O paralelismo de modelo, também conhecido como paralelismo tensorial e paralelismo intra-camada, é um deles, que utiliza o princípio da matriz de blocos e se concentra em resolver o problema de parâmetros muito grandes em uma única camada.
Um modelo muito grande não apenas se expandirá em profundidade, mas também em largura. A proporção destes precisa ser apreendida pelo projetista do modelo, e também existem alguns trabalhos que realizaram pesquisas e análises sobre esse tipo de problema. Para a memória de vídeo super grande trazida pela expansão profunda do modelo, o paralelismo de pipeline (paralelismo entre camadas) ou alguns métodos de otimização de sequência de cálculo (como checkpointing) podem ser usados para resolver o problema; e para os parâmetros super grandes trazidos por a expansão da largura do modelo, o paralelismo do modelo é, sem dúvida, o programa atual mais maduro.
O uso extensivo de camadas lineares em transformadores pode dar plena vantagem às vantagens do paralelismo de modelo.
1.2 Status Quo
Um método antigo usado em tarefas de reconhecimento facial é o InsightFace . Ele executa particionamento de parâmetros e computação paralela para as camadas FCfinais e.loss
O método transformeratualmente amplamente utilizado é o Megatron , que usa paralelismo de dados + paralelismo de modelo + paralelismo de pipeline para suportar 1 trilhão de treinamento de modelo grande em placas 3072. O projeto de paralelismo de modelo faz pleno uso transformerdos recursos de modeloAttention e como , combinados em paralelo para reduzir a comunicação.MLPlinear
Recentemente Pytorch, um torchshard foi de código aberto , Megatronque interface em , e é compatível com o uso misto de tecnologias como AMP, ZeROe fornece aos usuários uma maneira leve de usar o paralelismo de modelo.
Além disso, existem bibliotecas de código aberto como Parallelformers , fairscale , etc. Os princípios e designs são semelhantes, então não entrarei em detalhes aqui.
2 O princípio do paralelismo de modelo
A ideia principal do paralelismo de modelo é dividir a entrada, parâmetros e operações da camada de rede para diferentes placas, e o foco está nos parâmetros.
2.1 Princípios matemáticos
Para linearcamadas, a ideia mais simples é usar a regra de cálculo da matriz de blocos para obter consistência dos resultados.
Conforme mostrado nas fórmulas (1)e (2), divida a matriz em blocos por Ae respectivamente.B
\( \left[ \begin{matrix} X \end{matrix} \right] \times \left[ \begin{matrix} A_1 & A_2 \end{matrix} \right] =\left[ \begin{matrix} XA_1 & XA_2 \end{matriz} \direito] \tag{1} \)
\( \left[ \begin{matrix} Y_1 & Y_2 \end{matrix} \right] \times \left[ \begin{matrix} B_1 \\\\ B_2 \end{matrix} \right] =\left[ \ begin{matrix} Y_1B_1 + Y_2B_2 \end{matrix} \right] \tag{2} \)
Para não linearcamadas , nenhum projeto adicional é necessário. Quando a entrada recebida está em paralelo, você pode considerar atrasar a comunicação de dados ou encontrar maneiras de reduzir a quantidade de comunicação. Por exemplo, a softmaxcamada pode contar com transitividade matemática, ou seja, o máximo do máximo local é o máximo global; e a lei associativa, ou seja, a soma das somas locais é a soma global, para obter o efeito de redução tráfego.
2.1 Prática no transformermodelo
2.1.1 linearParalelismo
Na figura abaixo, tratamos X, Y, Zcomo os valores de ativação na rede, Ae , Bcomo os parâmetros das linearcamadas da rede.
O método paralelo mostrado na primeira linha é dividir os parâmetros de acordo com as colunas, para que a saída obtida possa ser emendada de acordo com as colunas, e o resultado equivalente possa ser obtido sem paralelismo.
A segunda linha mostra que os parâmetros estão divididos em linhas.Para corresponder ao formato da multiplicação da matriz, a entrada precisa ser dividida em colunas, para que a saída Z1e Z2possa ser somada para obter o resultado final Z.
Para simplificar a operação, a segmentação aqui se refere à divisão igual.
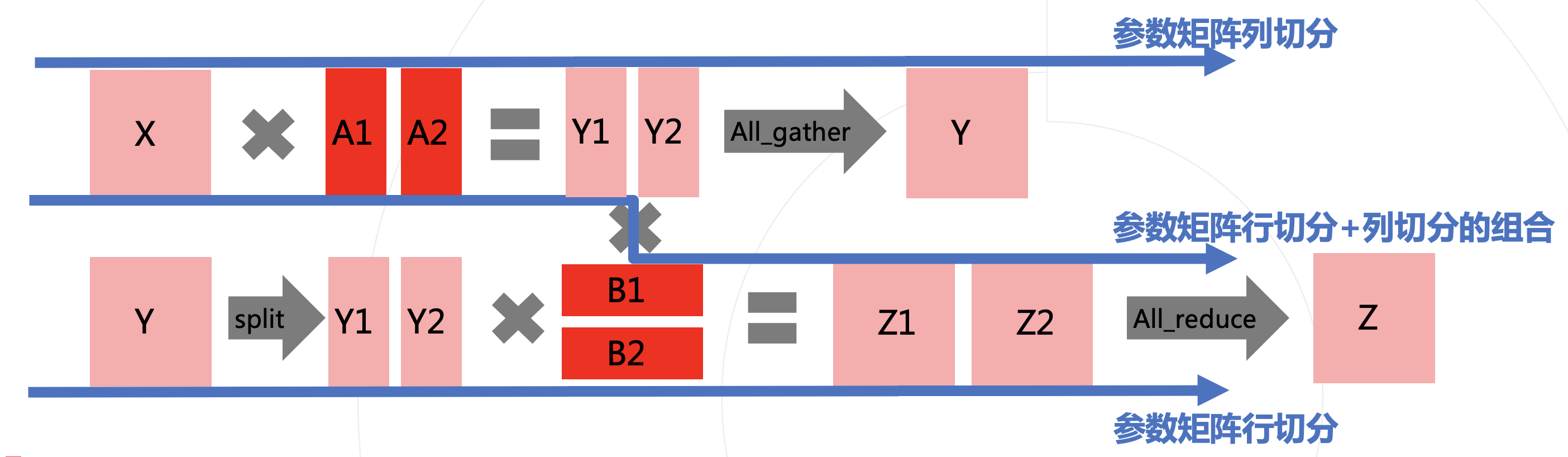
Cada split trará duas comunicações adicionais (mostrada na figura é a forwardfase , correspondentemente, a backwardfase também terá uma comunicação correspondente à regra). Para reduzir o custo da comunicação, uma ideia relativamente simples é que, se as duas segmentações puderem ser combinadas, a última da linha superior all_gathere o início da linha inferior splitpoderão ser omitidas. Ou seja, como mostra a linha tracejada no meio da figura, a combinação de segmentação de coluna e segmentação de linha da matriz de parâmetros.
A estrutura do transformador suporta naturalmente essa combinação. As duas figuras a seguir são do artigo da Megatron:


Vejamos primeiro o MLPmódulo . Os parâmetros na figura são Adivididos em colunas A1, A2, e o resultado obtido entra no GeLUmódulo . GeLUO cálculo está relacionado apenas ao elemento atual e é satisfeito GeLU([XA1, XA2])=[GeLU(XA1, XA2)], então ele pode continuar a se propagar para trás até a próxima matriz multiplicação é encontrada.
O f e g na figura representam operações relacionadas ao fatiamento de comunicação. No MLP, o avanço de f é uma fatia (split), e o retrocesso é uma soma (all_reduce); o forward de g é uma soma (all_reduce) e o inverso é uma fatia ( split).
Como mostrado na figura acima, existem combinações semelhantes em Attention. Costumamos usar Multiheads Attention, Q, , Ke Vapenas interagimos dentro da cabeça, e apenas dividimos as cabeças em paralelo, então entre as duas multiplicações de blocos de matrizes Entre, o cálculo é equivalente, e as duas operações de comunicação antes e depois são semelhantes ao MLP.
Uma versão típica de modelo paralelo do Multiheads Attention é mostrada no código a seguir:
class Attention(nn.Module):
def __init__(self, dim, num_heads=8, attn_drop=0., proj_drop=0.):
super().__init__()
self.num_heads = num_heads
head_dim = dim // num_heads
self.scale = head_dim ** -0.5
self.world_size = get_tensor_model_parallel_world_size() # 模型并行路数
self.dim_per_partition = divide(dim, self.world_size)
self.dim_per_attention_head = divide(dim, num_heads)
self.num_heads_per_partition = divide(num_heads, self.world_size)
self.qkv = ColumnParallelLinear(dim, dim * 3, gather_output=False) # gather_output=False,延迟 gather 的时间,和后面的 RowParallelLinear 组合起来
self.attn_drop = nn.Dropout(attn_drop)
self.proj = RowParallelLinear(dim, dim, input_is_parallel=True) # input_is_parallel=True,输入已经是按列切分的了
self.proj_drop = nn.Dropout(proj_drop)
def forward(self, x):
B, N, C = x.shape
qkv = self.qkv(x).reshape(B, N, self.num_heads_per_partition, 3, self.dim_per_attention_head).permute(3, 0, 2, 1, 4)
q, k, v = qkv[0], qkv[1], qkv[2]
attn = (q @ k.transpose(-2, -1)) * self.scale
attn = attn.softmax(dim=-1)
attn = self.attn_drop(attn)
x = (attn @ v).transpose(1, 2).reshape(B, N, self.dim_per_partition)
x = self.proj_drop(self.proj(x))
return x
2.2.2 cross_entropy_lossParalelismo
Se a saída cross_entropy_lossanterior for um column-parallel linear, o custo de comunicação imediato será relativamente grande. Na verdade, existe uma forma de economizar comunicação: acesse a versão paralela cross_entropy_loss. A primeira coisa a calcular é softmaxo valor de , conforme mostrado na fórmula a seguir, onde prepresenta o número do cartão no grupo paralelo do modelo
\( softmax(x_i) = \frac{e^{x_i}}{\sum_{j}{e^{x_j}}} = \frac{e^{x_i -x_{\max}}}{\sum_{ j}{e^{x_j-x_{\max}}}} = \frac{e^{x_i-x_{\max}}}{\sum_p{\sum_{k}{e^{x_k-x_{\ max}}}}} \tag{3} \)
\( x_{\max} = \max_p(\max_k(x_k)) \tag{4} \)
Para evitar estouro de ponto flutuante, em geral, o valor de \(x_{i}\) será subtraído de \(x_{\max}\) durante o cálculo , portanto, neste processo, haverá duas comunicações, uma é a comunicação Get \(x_{\max}\) , onde \(\underset{k}{\max}(x_k)\) se refere ao valor máximo em uma placa no grupo paralelo do modelo x, \(\ underset{p}{\ max}(\underset{k}{\max}(x_k))\) refere-se ao máximo geral no grupo paralelo do modelo obtido através da comunicação x. Outra comunicação é obter a soma total somando as partes.
softmaxApós obter o valor de , é necessário targetdividir e obter a perda de algumas categorias, e por fim fazer uma somatória para obter a perda de todas as categorias, para que cross_entropy_losso .
2.2.3 Processamento adicional
Quando vários paralelos lineares são combinados, se houver algumas operações como dropout no meio, é necessário garantir a consistência da aleatoriedade o máximo possível.
Além disso, em alguns locais onde são necessárias informações de parâmetros globais, a comunicação de parâmetros correspondente também precisa ser feita, por exemplo clip_grad_norm.
3 Combinação de paralelismo de dados e paralelismo de modelo
Em aplicações práticas, muitas vezes combinamos o paralelismo de modelo com vários métodos paralelos. O processo específico quando misturado com dados paralelos será apresentado em detalhes abaixo, e o pipeline paralelo não será discutido aqui por enquanto.
3.1 O Caminho Megatron
No megatron, o paralelismo de modelo geralmente é usado em uma única máquina e o paralelismo de dados é usado entre as máquinas.
Tome a figura a seguir como exemplo, existem 8 cartões no total, paralelo de dados de 2 vias, paralelo de modelo de 4 vias, os números de série dos cartões no grupo paralelo de dados são de 0 a 3, um total de dois grupos, no grupo modelo paralelo (grupo modelo paralelo)) O número de série da placa interna é de 0 a 1, totalizando quatro grupos.
Quando a comunicação é inicializada, esses números de cartão e grupos precisam ser claramente definidos. Durante o treinamento, tanto o alinhamento inicial do parâmetro quanto o alinhamento do gradiente em cada iteração precisam especificar o grupo correspondente.
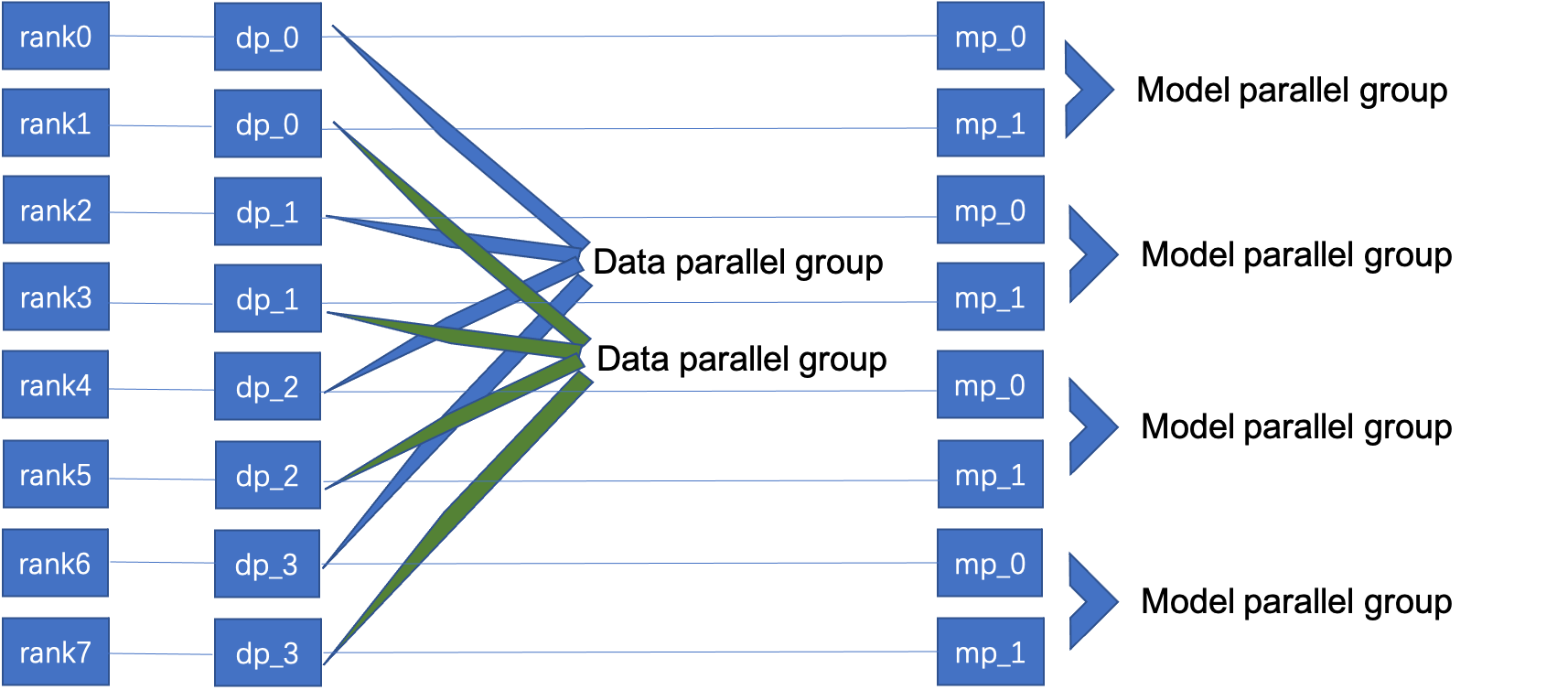
Dentro do mesmo grupo de dados paralelos, pouco mudou em comparação com a abordagem de dados paralelos puros. Tomando o PyTorch como exemplo, o modelo paralelo de dados geralmente usa DistributedDataParallel. Uma maneira é substituir seu parâmetro process_group por um grupo paralelo de dados.
# model 的 ddp 要传入 data_parallel_group 作为它的 process_group:在初始化 broadcast 阶段和 average_gradient 阶段起作用
model = DistributedDataParallel(model, process_group=data_parallel_group)
A seguir, explica-se o comportamento de grupos paralelos do mesmo modelo.
- Em primeiro lugar, para garantir que os parâmetros em diferentes placas no treinamento distribuído permaneçam sincronizados durante a inicialização, além do parâmetro transmitido no grupo paralelo de dados implícito no DDP acima, é necessário fazer uma camada não paralela adicional parâmetro no modelo de transmissão de grupo paralelo;
- Em segundo lugar, no mesmo grupo paralelo do modelo, os dados processados são os mesmos, o que requer não só a garantia no amostrador de dados, mas também para evitar que os dados de entrada na rede tenham deformações diferentes, geralmente antes do encaminhamento, o os dados são analisados no grupo Faça transmissões.
- Desta forma, em uma camada não paralela, como patch embedding, o mesmo comportamento é realizado no grupo. o grupo, mas os parâmetros foram divididos, então o resultado é um resultado parcial, que é então combinado por comunicação.
Megatron combina as funções mencionadas acima e as grava em uma classe semelhante a DistributedDataParallel.
3.2 Formas de InsightFace
Quando a maioria das camadas do modelo pode ser dividida pelo modelo em paralelo, o método acima é relativamente simples de implementar e tem forte escalabilidade. Mas quando a maioria das camadas do modelo não pode ser dividida, essa abordagem trará um problema maior: computação redundante.
Na tarefa de reconhecimento facial do InsightFace, a maioria das camadas frontais são camadas que não podem ser divididas, e apenas a última camada totalmente conectada terá o problema de parâmetros excessivos. Nesse caso, apenas a camada totalmente conectada e sua entropia cruzada subsequente modelam -computação paralela, e ainda mantém a abordagem de dados paralelos.
Para se adaptar a este método paralelo de divisão, é necessário fazer uma vez para o valor de ativação quando os dados são transferidos para o modelo em paralelo para all_gatherobter a entrada completa.
Esse método é mais flexível de usar, mas tem requisitos mais altos para os usuários. A divisão do grupo de comunicação dos parâmetros deve ser mais delicadamente desenhada e, ao mesmo tempo, deve haver um julgamento acurado sobre a conexão entre as camadas, de modo a inserir a comunicação adequadamente.
Referências
- Fragmentação de estado do otimizador (ZeRO):
https://zhuanlan.zhihu.com/p/394064174 - InsightFace:
https://github.com/deepinsight/insightface/tree/master/recognition - Megatron:
https://github.com/NVIDIA/Megatron-LM - tocha:
https://github.com/KaiyuYue/torchshard - Formadores paralelos
https://github.com/tunib-ai/parallelformers - escala justa:
https://github.com/facebookresearch/fairscale - O papel de Megatron:
https://arxiv.org/abs/1909.08053
Obrigado por ler, bem-vindo para deixar uma mensagem na área de comentários para discutir ~
PS Se você gostou deste artigo, por favor dê mais likes e deixe mais pessoas nos verem :D
Siga a conta pública "SenseParrots" para obter as últimas tendências do setor e pensamentos técnicos sobre estruturas de inteligência artificial.