A fonte deste artigo é o departamento editorial do coração da máquina
A falha trazida pelo GAN na super-pontuação da cena real te incomoda?
A super-resolução de imagens (SR) usando redes adversárias generativas (GANs) obteve grande sucesso na recuperação de detalhes realistas. No entanto, sabe-se que os modelos SR baseados em GAN produzem artefatos inaceitáveis, especialmente em cenários do mundo real. Estudos anteriores geralmente suprimem artefatos através de penalidades de perda adicionais durante a fase de treinamento, mas esses métodos são aplicáveis apenas aos tipos de artefatos gerados sob a mesma distribuição durante o treinamento.
No entanto, quando estes métodos são aplicados a cenários do mundo real, observamos que estes métodos ainda produzem artefatos significativos durante a inferência. Em resposta a isto, investigadores do Tencent ARC Lab, da equipa XPixel e da Universidade de Macau propuseram um novo método de DeSRA e publicaram artigos. É capaz de detectar e remover artefatos de super-resolução gerados durante a fase de inferência. Este artigo foi aceito pelo ICML 2023.

Link do artigo: https://arxiv.org/abs/2307.02457
Link do código: https://github.com/TencentARC/DeSRA
“Falhas no treinamento GAN” vs. “Falhas na inferência GAN”
Os métodos baseados em GAN alcançaram grande sucesso na geração de resultados de restauração realistas com texturas. BSRGAN [1] e Real-ESRGAN [2] estendem modelos baseados em GAN para aplicações do mundo real, demonstrando sua capacidade de recuperar texturas de imagens do mundo real. No entanto, os métodos GAN-SR muitas vezes geram artefatos visualmente inaceitáveis, afetando seriamente a experiência do usuário. Este problema é ainda mais grave em cenários do mundo real, uma vez que a degradação de imagens de baixa resolução é desconhecida e complexa.

A primeira coluna: entrada de baixa resolução; a segunda coluna: defeitos causados por métodos de super-resolução existentes; a terceira coluna: áreas de defeito detectadas pelo DeSRA; a quarta coluna: remoção de defeitos pelo DeSRA
Para amenizar a geração de defeitos, o LDL [3] analisa o tipo de textura, calcula a probabilidade de cada pixel ser um defeito e suprime os defeitos aumentando a perda durante o processo de treinamento. Embora melhore os resultados do GAN-SR, ainda podemos observar falhas significativas na inferência do LDL em dados de teste do mundo real, conforme mostrado na figura acima. Portanto, é difícil solucionar essas falhas apenas melhorando o treinamento do modelo, pois essas falhas podem não aparecer durante o treinamento do modelo GAN-SR.
Aqui distinguimos entre as falhas no treinamento GAN e as falhas nos testes:
Falhas no treinamento GAN (artefatos de treinamento GAN): aparecem na fase de treinamento, principalmente devido à instabilidade da otimização da rede durante o treinamento e ao mau posicionamento do SR nos mesmos dados de distribuição. Na presença de imagens limpas de alta definição, esses artefatos podem ser restringidos durante o treinamento para aliviar a geração de artefatos, como o LDL [3].
Artefatos de inferência GAN: Aparecendo na fase de inferência, esses artefatos geralmente aparecem em dados invisíveis do mundo real. Esses artefatos geralmente não estão na distribuição dos dados de treinamento e não aparecem durante a fase de treinamento. Portanto, esses artefatos não podem ser abordados por métodos que melhorem o processo de treinamento, como o LDL [3].
Lidar com os artefatos decorrentes da inferência GAN é uma tarefa nova e desafiadora. Em primeiro lugar, as imagens de baixa resolução de cenas reais não possuem imagens de alta resolução correspondentes. Além disso, como esses artefatos raramente ou nunca ocorrem no conjunto de treinamento, é difícil simulá-los. Em outras palavras, esses artefatos são desconhecidos do modelo e estão fora da distribuição de seus dados de treinamento. Resolver este problema é a chave para a aplicação do modelo GAN-SR a cenários reais e tem um valor prático importante.
Detectando falhas na inferência GAN

Neste artigo, a equipe de pesquisa se concentra em lidar com as imperfeições da inferência GAN. Estas imperfeições têm um grande impacto negativo nas aplicações práticas, pelo que resolvê-las é de grande valor prático. Devido à complexidade e variedade desses defeitos, é um desafio resolvê-los todos de uma vez.
Este artigo trata principalmente de falhas que possuem as duas características a seguir:
Esses artefatos não aparecem no modelo MSE-SR pré-treinado.
Essas manchas são óbvias e grandes e podem ser facilmente detectadas pelo olho humano. A imagem acima mostra algumas amostras que contêm esses artefatos.
Para o primeiro recurso, a equipe de pesquisa queria ter certeza de que os artefatos eram causados pelo GAN e que os resultados correspondentes do MSE-SR eram bons resultados de referência para os dados de teste distinguirem os artefatos. A justificativa para isso é que os artefatos GAN são frequentemente apresentados com muitos "detalhes" indesejados de alta frequência. Em outras palavras, a equipe de pesquisa trouxe treinamento GAN para gerar detalhes finos, mas não queria que o GAN gerasse muita diferença em relação aos resultados do MSE-SR. Observe que os resultados do MSE-SR são fáceis de obter mesmo para dados de teste de cenas reais não vistas, uma vez que geralmente ajustamos o modelo GAN-SR com base no modelo MSE-SR. Para esta última característica, aqueles artefatos que são óbvios e ocupam uma grande área são considerados de forma ideal porque este tipo de artefato tem um grande impacto na percepção humana.
Especificamente, a equipe de pesquisa primeiro projetou um indicador quantitativo para medir a diferença de textura entre os resultados da geração de modelos baseados em MSE e baseados em GAN, calculando a variação local. O índice inclui as seguintes partes no total.
Complexidade da textura local: o desvio padrão σ(i, j) das intensidades de pixel na região local P para representar a textura local
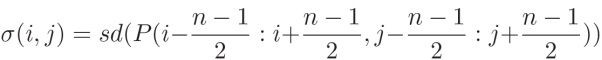
Diferença absoluta de textura d: desvio padrão de duas regiões locais (x indica área GAN-SR, y indica área MSE-SR)
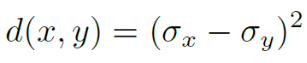
Diferença relativa de textura d':
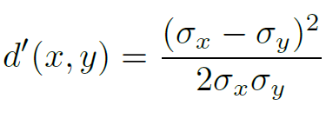
Normalizar para [0, 1]:
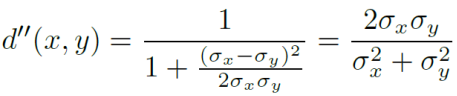
Introduza uma constante C: trate do caso em que o denominador é relativamente pequeno
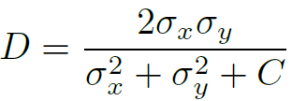
Após obter o mapa de diferença de textura D, ele pode ser utilizado para determinar a área que precisa ser processada. No entanto, não basta apenas usar a diferença na complexidade da textura como base de julgamento, porque a tolerância perceptiva de diferentes regiões semânticas é diferente. Por exemplo, detalhes em áreas com texturas complexas, como vegetação, cabelo, etc., são difíceis de serem percebidos como manchas, enquanto pixels em áreas com textura lisa ou regular apresentam grandes diferenças, como oceanos, céu e edifícios, são sensíveis. à percepção humana e são facilmente detectados, sendo considerados um defeito. Portanto, a equipe de pesquisa e eu ajustamos ainda mais o mapa do artefato D de acordo com as informações semânticas e obtivemos 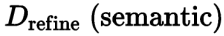 a sexta coluna na figura abaixo.
a sexta coluna na figura abaixo.

Por fim, a equipe de pesquisa obteve os resultados finais da detecção de defeitos por meio de operações morfológicas, que é a sétima coluna da figura abaixo. Especificamente, eles primeiro realizam uma operação de erosão usando uma matriz 5×5 de todos os 1s. Em seguida, é realizada uma operação de dilatação utilizando esta matriz para conectar regiões descontínuas. A seguir, uma matriz 3x3 de unidades é usada para preencher as lacunas no mapa. Finalmente, pequenas regiões discretas são filtradas como ruído de detecção.
Remova falhas na inferência GAN
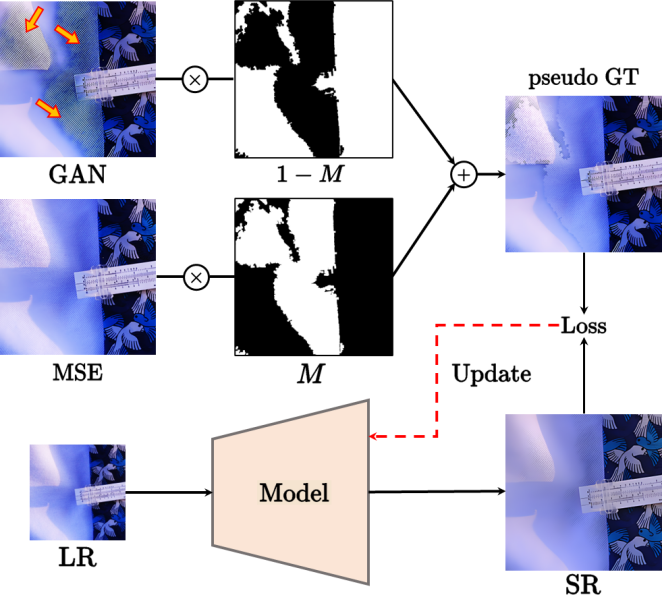
A detecção de falhas nos resultados da restauração é de grande valor prático por si só. Com base neste resultado, a equipe de pesquisa espera melhorar ainda mais o modelo GAN-SR. Considerando que, para aplicações práticas, os usuários muitas vezes não conseguem tolerar falhas óbvias, e resultados de restauração fracos sem falhas (com um pouco menos de detalhes) são mais aceitáveis do que resultados de restauração fortes com falhas. Portanto, eles utilizaram os resultados do MSE-SR como referência para o resultado do modelo. Conforme mostrado na figura abaixo, a equipe de pesquisa utilizou os resultados do MSE-SR para substituir as regiões onde as manchas foram detectadas nos resultados do GAN-SR. As imagens mescladas são usadas como imagens pseudo HD (pseudo-GT).
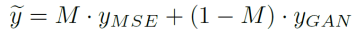
onde 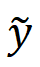 denota o pseudo-GT gerado
denota o pseudo-GT gerado 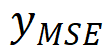 e
e 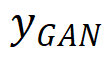 são os resultados MSE-SR e GAN-SR respectivamente, (・) denota a multiplicação elemento a elemento e M é o mapa do artefato detectado. Em seguida, a equipe de pesquisa ajustou o modelo usando uma pequena quantidade de dados para gerar pares de dados (x,) a partir dos dados reais
são os resultados MSE-SR e GAN-SR respectivamente, (・) denota a multiplicação elemento a elemento e M é o mapa do artefato detectado. Em seguida, a equipe de pesquisa ajustou o modelo usando uma pequena quantidade de dados para gerar pares de dados (x,) a partir dos dados reais 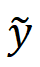 , onde x representa os dados LR. Com apenas um pequeno número de iterações de ajuste fino necessárias (cerca de 1K iterações foram suficientes neste experimento), o modelo atualizado produzirá resultados que são visualmente perceptivelmente bons e livres de artefatos óbvios. Além disso, não afeta os detalhes em áreas que não apresentam manchas. Essa abordagem funciona reduzindo os artefatos na inferência GAN, estreitando a lacuna entre a distribuição de dados sintéticos e a distribuição de dados reais por meio do processo de ajuste fino.
, onde x representa os dados LR. Com apenas um pequeno número de iterações de ajuste fino necessárias (cerca de 1K iterações foram suficientes neste experimento), o modelo atualizado produzirá resultados que são visualmente perceptivelmente bons e livres de artefatos óbvios. Além disso, não afeta os detalhes em áreas que não apresentam manchas. Essa abordagem funciona reduzindo os artefatos na inferência GAN, estreitando a lacuna entre a distribuição de dados sintéticos e a distribuição de dados reais por meio do processo de ajuste fino.
Avaliação e análise de experimentos
A equipe de pesquisa utilizou Real-ESRGAN [2], LDL [3] e SwinIR [4] para verificar a eficácia de seu método. Considerando que vários conjuntos de dados de super-resolução existentes no mundo real assumem degradações específicas da câmera, os resultados estarão longe da situação real. Portanto, eles construíram um conjunto de dados de manchas anotadas por humanos. Considerando a diversidade do conteúdo e da degradação da imagem, eles usam o conjunto de validação do ImageNet 1K como dados de baixa resolução do mundo real. Em seguida, 200 imagens com falhas de inferência GAN em cada método são selecionadas para construir o conjunto de dados de falhas, e as regiões defeituosas são rotuladas manualmente usando labelme. Este é o primeiro conjunto de dados para detecção de falhas de inferência GAN. Para o processo de ajuste fino, eles dividiram 200 imagens, das quais 50 são usadas para ajuste fino do modelo e 150 como conjunto de validação.
Índice de Avaliação
Devido à falta de imagens de referência de alta definição de dados reais de baixa resolução, indicadores clássicos como PSNR e SSIM não podem ser adotados. Portanto, a equipe de pesquisa considerou três indicadores para avaliar os resultados da detecção, incluindo 1) a relação intersecção sobre união (IoU) entre a área do defeito detectado e a área do defeito real (rotulada manualmente), 2) a precisão do resultado da detecção e 3) é a taxa de recuperação dos resultados da detecção. Quando A e B denotam as manchas detectadas e reais para uma determinada região z, o IoU é definido como:
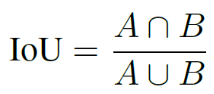
Calcule o IoU para cada imagem e use o IoU médio no conjunto de validação para avaliar o algoritmo de detecção. IoU mais alto significa melhor precisão de detecção. Então, definimos o conjunto de regiões de manchas detectadas como S, e o conjunto de amostras corretas T como:
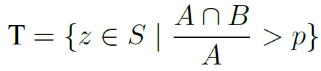
Precisão = 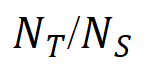 Indica a razão entre o número de regiões detectadas corretamente (
Indica a razão entre o número de regiões detectadas corretamente ( 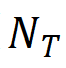 ) e o número total de regiões detectadas (
) e o número total de regiões detectadas ( 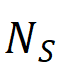 ).
).
A equipe de pesquisa define a região de defeito real como G e calcula a região de defeito GT detectada definida R pelo seguinte método:
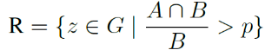
Recall = a razão entre 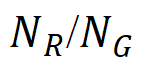 o número de regiões de defeito GT detectadas corretamente (
o número de regiões de defeito GT detectadas corretamente ( 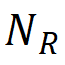 ) e o número total de regiões de defeito GT (
) e o número total de regiões de defeito GT ( 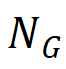 ). Entre eles, p é um limite, que a equipe de pesquisa definiu empiricamente como 0,5.
). Entre eles, p é um limite, que a equipe de pesquisa definiu empiricamente como 0,5.
Resultado da detecção de falhas
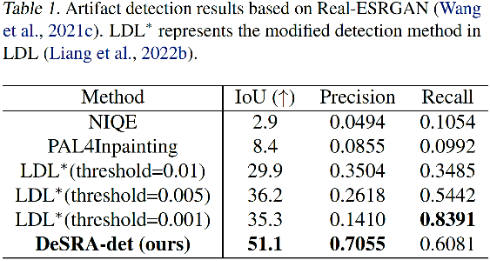
Conforme mostrado na tabela abaixo, para os resultados de detecção de defeitos no modelo LDL, o método deste artigo obteve o melhor IoU e precisão, superando em muito outros esquemas. Observe que o LDL atinge a recordação mais alta no limite = 0,001. Isto ocorre porque o esquema trata a maioria das áreas como manchas, de modo que tais detecções são quase sem sentido. Os resultados do Real-ESRGAN e SwinIR podem referir-se ao texto original.
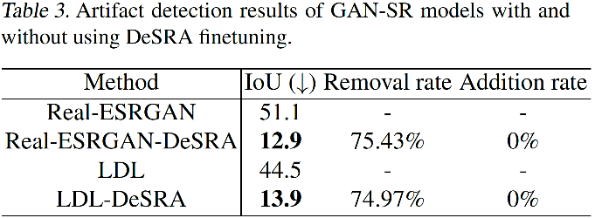
A equipe de pesquisa também comparou os resultados da detecção de defeitos antes e depois de usar a estratégia de ajuste fino DeSRA. Os resultados são mostrados na tabela abaixo. Depois de aplicar seu DeSRA, o IoU do Real-ESRGAN caiu de 51,1 para 12,9, e o IoU do O LDL caiu de 44,5 para 13,9, o que mostra que a área de detecção da área do defeito é bastante reduzida. As taxas de remoção são de 75,43% e 74,97%, respectivamente, indicando que três quartos das manchas nos dados de teste podem ser completamente removidas após o ajuste fino. Além disso, o seu método não introduz artefatos adicionais, com uma taxa de adição de 0.
O artigo fornece uma comparação visual dos resultados da melhoria do modelo GAN-SR com e sem o método da figura abaixo. Comparado com os resultados do modelo original, o modelo GAN-SR aprimorado gera resultados com melhor qualidade visual e sem artefatos GAN-SR óbvios. Todos esses resultados experimentais provam que o método deste artigo pode efetivamente aliviar os defeitos que o modelo irá aparecer ao processar imagens reais de baixa resolução.

Estudo do usuário
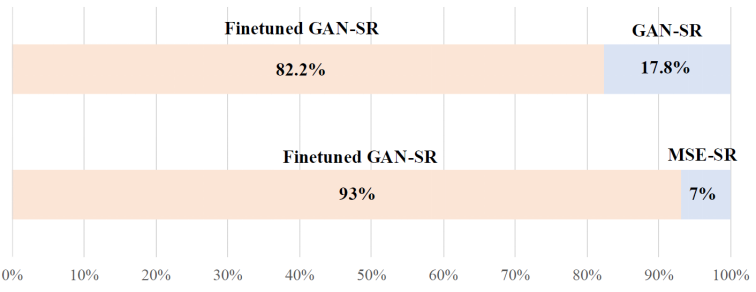
A fim de verificar ainda mais a eficácia da estratégia de ajuste fino do DeSRA neste artigo, a equipe de pesquisa conduziu dois estudos de usuários. O primeiro item compara os resultados gerados pelo modelo GAN-SR original e pelo modelo GAN-SR ajustado. Para este experimento, o foco da comparação é se há artefatos óbvios na imagem. A equipe de pesquisa gerou um total de 20 conjuntos de imagens, cada um contendo a saída do modelo GAN-SR e do modelo GAN-SR ajustado. Essas imagens são embaralhadas aleatoriamente. Um total de 15 pessoas participaram do estudo de usuários e para cada grupo selecionaram imagens que consideravam conter menos artefatos. Os resultados estatísticos finais são mostrados na Figura 9. 82,23% dos participantes acreditaram que o modelo GAN-SR ajustado produziu menos artefatos. Pode-se observar que o método deste artigo elimina em grande parte os artefatos produzidos pelo modelo original.
O segundo item é a comparação dos resultados do modelo GAN-SR ajustado e do modelo MSE-SR original. Este experimento visa comparar se os resultados gerados pelo modelo possuem mais detalhes. No total, a equipe de pesquisa gerou 20 conjuntos de imagens, cada um contendo a saída do modelo MSE-SR e do modelo GAN-SR ajustado. Essas imagens são embaralhadas aleatoriamente. Um total de 15 pessoas participaram do estudo de usuários e, para cada grupo, selecionaram imagens que consideravam mais detalhadas. Os resultados estatísticos finais são mostrados na Figura 9. 93% dos participantes sentiram que o modelo GAN-SR ajustado produziu resultados mais detalhados. Pode-se observar que o modelo GAN-SR ajustado ainda é capaz de gerar mais detalhes do que o modelo MSE-SR.
para concluir
Neste trabalho, a equipe de pesquisa analisou os artefatos introduzidos pelos GANs durante a fase de inferência e propôs métodos para detectá-los e removê-los. Especificamente, eles primeiro calcularam a variação local relativa de MSE-SR e GAN-SR e incorporaram ainda informações semânticas para localizar as regiões defeituosas. Depois de detectar áreas com manchas, eles ajustam o modelo usando os resultados baseados em MSE como imagens pseudo-HD. Usando apenas uma pequena quantidade de dados, o modelo ajustado pode remover com sucesso as falhas do modelo original no processo de inferência. Os resultados experimentais mostram a superioridade do seu método na detecção e remoção de manchas e melhoram significativamente a capacidade dos modelos GAN-SR para aplicações práticas.
Aprendizagem Contínua Online
Nosso método pode ser combinado com aprendizado contínuo, proporcionando assim um novo paradigma para solucionar as falhas que surgem durante a fase de inferência online. Por exemplo, para um sistema online de super-resolução que lida com dados do mundo real, o pipeline de detecção da equipe de pesquisa pode ser usado para detectar se os resultados restaurados possuem artefatos de inferência GAN. Eles podem então usar as imagens detectadas com artefatos para ajustar rapidamente o modelo de super-resolução para lidar com artefatos semelhantes até que o sistema encontre novos artefatos de inferência GAN. A aprendizagem contínua tem sido extensivamente estudada em tarefas de visão de alto nível, mas não foi aplicada à super-resolução. A equipe de pesquisa espera estudar este problema no futuro, pois pode avançar muito na aplicação dos métodos GAN-SR em cenários reais.
referências:
[1] BSRGAN: Projetando um modelo prático de degradação para super-resolução de imagens cegas profundas.
[2] Real-ESRGAN: Treinamento de super-resolução cega do mundo real com dados sintéticos puros.
[3] LDL: Detalhes ou artefatos: Uma abordagem de aprendizagem localmente discriminativa para super-resolução de imagens realistas.
[4] SwinIR: Restauração de imagem usando transformador swin.
Preste atenção na conta oficial [Machine Learning and AI Generation Creation], coisas mais interessantes estão esperando por você para ler
Explicação detalhada do ControlNet, um algoritmo controlável de geração de pintura AIGC!
O GAN clássico deve ser lido: StyleGAN
 Clique em mim para ver os álbuns da série GAN ~!
Clique em mim para ver os álbuns da série GAN ~!
Uma xícara de chá com leite, torne-se a fronteira da visão AIGC + CV!
O resumo 100 mais recente e completo! Gerar modelos de difusão Modelos de difusão
ECCV2022 | Resumo de alguns artigos sobre geração de rede de confronto GAN
CVPR 2022 | Mais de 25 direções, 50 artigos GAN mais recentes
ICCV 2021 | Resumo dos artigos do GAN sobre 35 tópicos
Mais de 110 artigos! CVPR 2021 penteado de papel GAN mais completo
Mais de 100 artigos! CVPR 2020 mais completo penteado de papel GAN
Desmontando o novo GAN: dissociando a representação MixNMatch
StarGAN versão 2: geração de imagens de diversidade multidomínio
Download em anexo | Versão chinesa de "Explainable Machine Learning"
Download em anexo | "Algoritmos de aprendizado profundo do TensorFlow 2.0 na prática"
Download em anexo | Compartilhar "Métodos Matemáticos em Visão Computacional"
"Uma revisão dos métodos de detecção de defeitos de superfície baseados em aprendizagem profunda"
Uma pesquisa sobre classificação de imagens Zero-Shot: uma década de progresso
"Uma pesquisa de aprendizagem rápida baseada em redes neurais profundas"
O "Livro dos Ritos · Xue Ji" tem um ditado: "Aprender sozinho, sem amigos, é solitário e ignorante."
Clique em uma xícara de chá com leite e torne-se o líder da visão AIGC + CV! , junte-se ao planeta da criação gerada por IA e do conhecimento de visão computacional!