As informações de borda são introduzidas durante a reconstrução de super-resolução para preservar os detalhes de alta frequência das imagens. Este trabalho combina as informações de borda com as informações de baixa frequência da imagem usando um kernel de convolução específico na operação de convolução. Preserve melhor os detalhes da borda enquanto melhora a clareza e os detalhes da imagem.
Modelo de hiperresolução em tempo real da implantação de dispositivos de borda usando o método de reparametrização estrutural
论文名称:Bloco de convolução orientado para a borda para super resolução em tempo real em dispositivos móveis
Endereço de papel:
https://www4.comp.polyu.edu.hk/~cslzhang/paper/MM21_ECBSR.pdf
Vantagens dos modelos estilo VGG
O método de reparametrização de estruturas foi proposto pela primeira vez por RepVGG[1], o grande deus Ding Xiaohan.
Interpretação do método de reparametrização estrutural (RepVGG):
RepVGG: arquitetura minimalista, desempenho SOTA, tornando os modelos no estilo VGG excelentes novamente (CVPR-2021)
https://zhuanlan.zhihu.com/p/344324470
Métodos de reparametrização estrutural são usados para poda (ResRep [2] ):
ResRep: Podando SOTA! Compressão Sem Perdas de CNNs com Reparametrização Estrutural (ICCV)
https://zhuanlan.zhihu.com/p/402106979
Métodos de reparametrização estrutural são usados para projetar redes MLP (RepMLPNet [3] ):
Discussão quente: MLP, RepMLP, conexão completa e "involução"
https://zhuanlan.zhihu.com/p/375422742
Métodos de reparametrização estrutural são usados para projetar grandes redes convolucionais de kernel (RepLKNet [4] ):
Interpretação do autor do RepLKNet: Kernel de convolução super grande, tão grande quanto 31x31, quanto maior, mais violento, mais alto o ponto e mais eficiente! (CVPR 2022) See More
https://zhuanlan.zhihu.com/p/481445076
Os modelos "estilo VGG" referem-se a:
1. Ter uma arquitetura simples ou feed-forward como VGG, sem nenhuma ramificação, significa que cada camada recebe a saída de sua camada anterior como entrada e a saída é passada apenas para a próxima camada.
2. Use apenas convolução 3x3 e ReLU como função de ativação.
3. A arquitetura detalhada do modelo (incluindo profundidade e número de canais) não passa pelo processo de busca de arquitetura ou ajuste fino manual.
A arquitetura básica do modelo RepVGG: empilhe 20 camadas de convoluções 3 x 3 e divida-as em 5 estágios. A primeira camada de cada estágio é reduzida com stride=2 e cada camada convolucional usa ReLU como função de ativação.
Vantagens da convolução 3×3:
A vantagem da convolução 3×3 é que ela foi altamente otimizada por bibliotecas de computação modernas (como NVIDIA cuDNN [5]). A Figura 1 abaixo mostra a quantidade de cálculo teórico, tempo de execução e densidade de cálculo teórico de diferentes tamanhos de kernels de convolução em NVIDIA 1080Ti (tamanho do lote = 32, canal de entrada = canal de saída = 2048, resolução = 56 × 56, passo = 1, cuDNN 7,5 .0). TFLOPS refere-se a Tera FLoating-point Operations Per Second, que é a densidade de cálculo de uma determinada operação. A densidade de cálculo teórico de 3×3 conv é cerca de 4 vezes maior do que os outros, o que mostra que o cálculo teórico FLOPs não representa a velocidade real de diferentes arquiteturas.  Figura 1: A quantidade de cálculo teórico, tempo de execução e densidade de cálculo teórico de kernels de convolução de diferentes tamanhos em NVIDIA 1080Ti (tamanho do lote = 32, canal de entrada = canal de saída = 2048, resolução = 56 × 56, passo = 1, cuDNN 7,5. 0)
Figura 1: A quantidade de cálculo teórico, tempo de execução e densidade de cálculo teórico de kernels de convolução de diferentes tamanhos em NVIDIA 1080Ti (tamanho do lote = 32, canal de entrada = canal de saída = 2048, resolução = 56 × 56, passo = 1, cuDNN 7,5. 0)
As vantagens da arquitetura minimalista do "VGG" são:
-
Velocidade de cálculo rápida: VGG-16 é 8,4 vezes a quantidade de cálculo do EfficientNet-B3, mas a velocidade de execução no 1080 Ti é 1,8 vezes maior que a do último, o que significa que a densidade de cálculo do primeiro é cerca de 15 vezes maior que a do último . Além de se beneficiar do próprio algoritmo de Winograd, a melhoria da velocidade de execução também se beneficia do custo de acesso à memória (Memory Access Cost, MAC) e do paralelismo. O MAC indica o uso de memória, ou seja, quanta memória é usada para executar esta operação. Por exemplo, na operação multibranchal Inception, o MAC da ResNet é muito grande. Por exemplo, embora a quantidade de cálculo necessária para operações com várias ramificações seja insignificante, o MAC é extremamente alto. Além disso, modelos com alto paralelismo são mais rápidos que modelos com baixo paralelismo para os mesmos FLOPs.
-
Economia de uso de memória: A razão pela qual a arquitetura multi-ramificação é ineficiente em relação à memória é que, no processo de cálculo da saída de várias ramificações, os resultados de cada ramificação devem ser armazenados na memória antes que os resultados do cálculo do multi-caminho sejam finalmente adicionado, resultando em maior uso de memória. A Figura 2 abaixo ilustra este problema: Depois que a conexão residual é adicionada, o valor de pico de uso de memória se torna o dobro do original (supondo que o tamanho do recurso de cada camada permaneça inalterado).
-
Flexibilidade: A arquitetura de soquete único é mais flexível. A conexão residual requer que a dimensão do tensor da saída final seja do mesmo tamanho da entrada, o que traz limitações ao projeto do modelo. Além disso, a arquitetura simples é fácil de alterar a largura de cada camada (como poda). Mas o modelo multibranch não é fácil de podar cada camada, o que também levará a uma queda significativa de desempenho ou baixa aceleração. Por outro lado, a arquitetura simples nos permite configurar com flexibilidade cada camada de conversão para obter a melhor relação entre desempenho e eficiência.
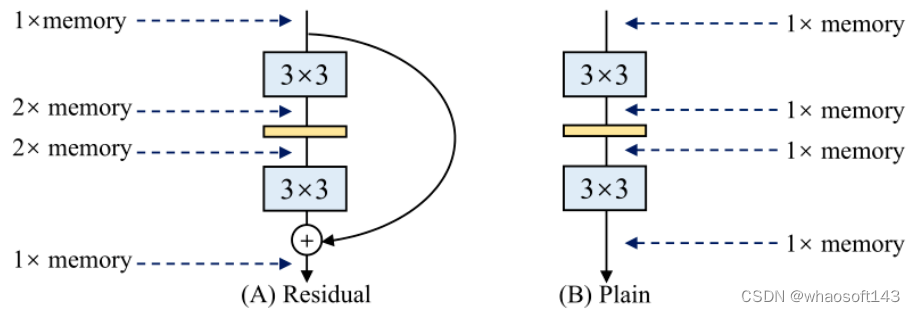 Figura 2: O uso de memória do modelo residual e do modelo simples: Antes que o modelo residual finalmente adicione os resultados do cálculo de vários canais, os resultados de cada ramificação devem ser armazenados na memória, resultando em um maior uso de memória
Figura 2: O uso de memória do modelo residual e do modelo simples: Antes que o modelo residual finalmente adicione os resultados do cálculo de vários canais, os resultados de cada ramificação devem ser armazenados na memória, resultando em um maior uso de memória
Introdução aos Métodos de Reparametrização Estrutural
A ideia do método de reparametrização estrutural é aproveitar as respectivas vantagens da arquitetura multibranch e da arquitetura single-branch. Quais são as vantagens e desvantagens de arquiteturas multibranch (como ResNet, Inception, DenseNet, várias arquiteturas NAS) e estruturas de ramificação única (modelos de estilo VGG)?
-
O treinamento da arquitetura multiramificação é mais estável e fácil . Por exemplo, a conexão residual do ResNet pode resolver bem o problema do desaparecimento do gradiente. No entanto, a velocidade de inferência é lenta e o uso de memória é grande.
-
A velocidade de raciocínio da estrutura de ramificação única é rápida e economiza memória . Mas o treinamento é mais difícil e o desempenho do treinamento é menor.
O método específico de reparametrização estrutural é mostrado na Figura 3 abaixo.
Durante o treinamento , conforme mostrado na Figura 3 (b), uma ramificação de convolução paralela 1x1 e uma ramificação de mapeamento de identidade são adicionadas a cada camada convolucional 3 × 3 para formar um bloco RepVGG. Este projeto é baseado na prática do ResNet.A diferença é que o ResNet adiciona uma ramificação a cada duas ou três camadas, enquanto o autor adiciona todas as camadas. Após a adição, o modelo se torna um modelo multibranch.O autor usa a estabilidade do treinamento de arquitetura multibranch para treinar essa arquitetura multibranch.
Ao implantar , conforme mostrado na Figura 3 (c), use o método de reparametrização para pegar os pesos da Figura 3 (b) e realizar uma transformação equivalente no modelo , diretamente na arquitetura VGG da Figura 3 (c).  Figura 3: arquitetura RepVGG
Figura 3: arquitetura RepVGG
Essa estratégia de conversão equivalente é mostrada na Figura 4 abaixo. O princípio utilizado é a homogeneidade da operação de convolução, especificamente:
-
Uma convolução 1x1 é equivalente a uma convolução 3x3 especial (muitos 0's no kernel).
-
O mapa de identidade é uma convolução 1x1 especial (com a matriz de identidade como núcleo de convolução), portanto, também é uma convolução 3x3 especial.
Então só precisamos:
1. Converta a convolução 1x1 para a convolução 3x3 de forma equivalente e preencha o excesso com 0.
2. Para converter a operação Identity em uma convolução 1x1, basta construir uma convolução 1x1 com a matriz identidade como o kernel da convolução.  Após a fusão, a convolução se torna:
Após a fusão, a convolução se torna: 
 Figura 4: O processo de reparametrização da estrutura do Bloco RepVGG. Para facilitar a visualização, considere C_out=C_in=2, de modo que a convolução 3 × 3 e a convolução 1 × 1 contenham 4 matrizes 3 × 3 e 4 matrizes 1 × 1, respectivamente
Figura 4: O processo de reparametrização da estrutura do Bloco RepVGG. Para facilitar a visualização, considere C_out=C_in=2, de modo que a convolução 3 × 3 e a convolução 1 × 1 contenham 4 matrizes 3 × 3 e 4 matrizes 1 × 1, respectivamente
De RepVGG para ECBSR
A velocidade de inferência direta do modelo de super-resolução é o gargalo dos aplicativos de super-resolução do mundo real. Embora o trabalho atual tenha proposto muitos projetos de rede leves com menos FLOPs, eles podem não funcionar mais rápido na prática porque os FLOPs não refletem com precisão a velocidade real, como discutido acima, VGG-16 é 8,4 vezes o valor de cálculo do EfficientNet-B3, mas a execução a velocidade do 1080 Ti é 1,8 vezes a do último, o que significa que a densidade de cálculo do primeiro é cerca de 15 vezes a do segundo. Além disso, as conexões Skip e Dense amplamente existentes em modelos de super-resolução introduzirão sobrecarga adicional de memória da GPU. O modelo da classe simples pode aproveitar ao máximo a capacidade de aceleração de computação paralela da GPU.
Portanto, neste artigo, o autor deseja projetar um modelo de super-resolução do tipo simples, mas o treinamento direto de tal modelo sempre resultará em desempenho ruim. Portanto, o autor espera usar a arquitetura multi-branch na super-resolução treinamento do modelo com a ajuda da tecnologia de reparametrização Após o treinamento, o modelo convertido em plano é usado para implantação e raciocínio. Especificamente, o ECBSR usa uma combinação linear de vários ramos para treinar o modelo e os mescla em uma convolução 3 × 3 padrão no estágio de inferência. A eficiência do treinamento é aprimorada sem sacrificar a velocidade de inferência. O ECBSR incorpora conhecimento de domínio de orientação clássica e filtros de borda ao projetar o modelo em tempo de treinamento.
Arquitetura do modelo básico RepSR
A arquitetura do modelo básico do ECBSR é mostrada na Figura 5 (a) a seguir.Para manter baixo o custo computacional e o consumo de memória, o raciocínio do ECBSR inclui uma série de funções de ativação e convolução 3 × 3 (PReLU). Upsampling com operação PixelShuffle e interpolação do vizinho mais próximo no final do modelo. Esse modelo básico que consiste nas operações mais básicas é para garantir alta velocidade de inferência em dispositivos móveis disponíveis comercialmente e implantação entre dispositivos .
Embora topologias complexas como multi-branch[6] e conexão densa[7] possam enriquecer as representações de recursos, essas topologias levam a um custo de acesso à memória (MAC) mais alto e sacrificam o paralelismo, o que reduz drasticamente a velocidade de inferência. FSRCNN[8] com estrutura de rede simples tem FLOPs mais altos do que IMDN-RTC[9] com topologia complexa, mas executa duas ordens de magnitude mais rápido no SnapDragon 865, permitindo escalar de 540p para 1080p.  Figura 5: (a) Arquitetura do modelo básico ECBSR. (b) Bloco ECB: contém um ramo de convolução normal 3 × 3, ramo de convolução Expand-and-Squeeze, ramo de convolução e filtro de Sobel, ramo de convolução e filtro Laplaciano
Figura 5: (a) Arquitetura do modelo básico ECBSR. (b) Bloco ECB: contém um ramo de convolução normal 3 × 3, ramo de convolução Expand-and-Squeeze, ramo de convolução e filtro de Sobel, ramo de convolução e filtro Laplaciano
A operação BN não é amigável para a tarefa de super-resolução. O método ECBSR alivia esse problema excluindo a operação BN e usando um módulo complexo projetado à mão (incluindo filtros Sobel e Laplaciano). Especificamente, a estrutura do ECB durante o treinamento inclui as quatro partes a seguir:
Uma ramificação normal de convolução 3 × 3: nenhuma operação BN é usada. Escrito como a fórmula: 
 função de ativação não linear de entrada de recurso de saída.
função de ativação não linear de entrada de recurso de saída.
Método de reparametrização da estrutura ECBSR
Passo 1: Fusão de convolução 1×1 e convolução 3×3.
 Resultados Experimentais ECBSR
Resultados Experimentais ECBSR
Os autores conduzem experimentos extensivos para verificar o desempenho superior do modelo ECBSR em cinco conjuntos de dados de benchmark SR e sua alta eficiência em dois hardwares típicos. O conjunto de treinamento usa DIV2K, o conjunto de verificação usa Set5, Set14, BSD100, Urban100, conjunto de verificação DIV2K, treinamento L1 Loss é usado, o otimizador usa Adam, 700 épocas, a taxa de aprendizado inicial é definida como 5e-4, após a conversão RGB para o formato YCbCr PSNR e SSIM são calculados no canal Y.
Os autores comparam RepSR com métodos SR representativos, incluindo SRCNN, FSRCNN, ESPCN, VDSR, LapSRN, CARN, MoreMNAS-{B,C}, FALSR-{B,C}, TPSR-NoGAN, EDSR, IMDN.
Vale ressaltar que além de #Params, FLOPs, o índice de avaliação também possui tempos de ativação #Acts (M).  Figura 6: resultados do experimento ECBSR
Figura 6: resultados do experimento ECBSR
ECBSR-M4C8, como a menor versão do modelo, supera SRCNN e ESPCN em todos os cinco benchmarks, tendo cerca de 12×/10× menos parâmetros, 92×/9× menos FLOPs e 9 menos ativações ×/2× vezes. O ECBSR-M4C8 requer apenas um pouco mais de computação e memória para obter um desempenho muito melhor do que o upsampling bicúbico. ECBSRM4C16, ECBSR-M10C16 e ECBSR-M10C32 superam significativamente os concorrentes na maioria dos casos em termos de desempenho e complexidade do modelo. O modelo SR mais complexo ECBSR-M16C64 supera o VDSR por uma grande margem em todos os cinco conjuntos de dados. O ECBSR-M16C64 pode alcançar desempenho comparável ao EDSR-R16C64, CARN-M e IMDN, mas é menor e mais leve. Embora aumentar ainda mais o número de blocos e autocanais do ECBSR possa levar a um melhor desempenho, os custos computacionais e de armazenamento serão muito grandes para dispositivos móveis.
A figura a seguir é o resultado da visualização da super-resolução. Como o ECBSR se concentra no SR em tempo real em dispositivos móveis , ele compara apenas modelos SR que podem atingir velocidade em tempo real ou quase real, incluindo upsampling bicúbico, FSRCNN, ESPCN, ECBSR-M4C8, ECBSR-M4C16, ECBSR-M10C16 e ECBSRM10C32. A Figura 7 abaixo mostra os resultados ×2 SR de duas imagens de exemplo típicas do Urban100. Pode-se ver que ESPCN, FSRCNN e ECBSR-M4C8 têm apenas uma qualidade visual ligeiramente melhor do que o upsampling bicúbico, nenhum deles pode recuperar bordas nítidas o suficiente na image033. Com profundidade e largura aprimoradas, o ECBSR-M4C16, o ECBSR-M10C16 e o ECBSR-M10C32 obtêm qualidade visual consistentemente melhor, com bordas mais nítidas e texturas mais nítidas. O ECBSR-M10C32 teve o melhor desempenho entre todos os modelos, restaurando fielmente a estrutura e os detalhes das bordas da malha.  Figura 7: Resultados da visualização da super-resolução
Figura 7: Resultados da visualização da super-resolução
O autor avaliou ainda mais sua velocidade de execução real em dois dispositivos móveis. O autor selecionou dois SoCs móveis emblemáticos representativos para avaliação, Dimensity 1000+ GPU e SnapDragon 865 DSP. Como o SDK também desempenha um papel importante na velocidade de inferência, os autores executam todos os modelos com o mesmo SDK nas mesmas configurações. O autor usa o aplicativo de benchmark AI para execução do modelo. Escolha TFLITE GPU e Hexagon NN como representante do mecanismo de inferência. Além disso, todos os modelos são quantizados para 8 bits. A Figura 8 abaixo mostra a velocidade de execução do upscaling da imagem para resolução de 1080p nas tarefas ×2 e ×4.  Figura 8: Comparação da velocidade de execução do hardware do modelo SR para dois principais dispositivos móveis para ampliar a imagem para 1920×1080 (vermelho significa menos de 30 fps, ou seja, em tempo real; azul representa entre 15 e 30 fps, que é, quase em tempo real) whaosoft aiot http://143ai.com
Figura 8: Comparação da velocidade de execução do hardware do modelo SR para dois principais dispositivos móveis para ampliar a imagem para 1920×1080 (vermelho significa menos de 30 fps, ou seja, em tempo real; azul representa entre 15 e 30 fps, que é, quase em tempo real) whaosoft aiot http://143ai.com
Pode-se observar que o ECBSR-M4C8 e o ECBSR-M4C16 são extremamente eficientes, permitindo inferência em tempo real em ambos os dispositivos. O ECBSR-M10C16 e o ECBSR-M10C32 também podem alcançar desempenho quase em tempo real na maioria dos casos, enquanto o ECBSR-M16C64 é muito pesado para ambos os dispositivos móveis. Embora o SRCNN use uma arquitetura de modelo concisa, ele é muito mais lento devido à sua estratégia de pré-upampling, que aumenta muito o consumo de memória e computação. Mesmo com versões leves, EDSR-R5C32 e IMDN-RTC não podem alcançar velocidades quase em tempo real em ambos os dispositivos porque suas conexões densas e topologia multidrop introduzem muitos MACs, reduzindo o paralelismo.
Como experimento comparativo, o autor experimentou o impacto do uso de diferentes ramificações do bloco ECB, e os resultados são mostrados na Figura 9 abaixo. Pode-se ver que o uso de qualquer um desses três componentes melhora o desempenho do modelo de linha de base, enquanto a remoção de qualquer um dos componentes do ECB diminui seu desempenho. Isso significa que todos os componentes do ECB contribuem para a tarefa de RS e esses componentes são complementares.  Figura 9: Impacto do uso de diferentes agências para blocos do ECB
Figura 9: Impacto do uso de diferentes agências para blocos do ECB
Resumir
Neste artigo, o autor deseja projetar um modelo de super-resolução do tipo simples com a ajuda da tecnologia de reparametrização. O ECBSR usa uma combinação linear de vários ramos para treinar o modelo e os mescla em uma convolução 3 × 3 padrão no estágio de inferência. A operação BN não é amigável para a tarefa de super-resolução, e o método ECBSR alivia esse problema excluindo a operação BN e usando um módulo complexo projetado à mão. Especificamente, a estrutura do ECB no tempo de treinamento inclui um ramo de convolução 3 × 3 normal, ramo de convolução Expand-and-Squeeze, convolução e ramo de filtro de Sobel, convolução e ramo de filtro Laplaciano. Os resultados da avaliação em dois SoCs móveis emblemáticos mostram que o ECBSR permite inferência em tempo real em ambos os dispositivos. O ECBSR também pode obter melhor qualidade visual em tarefas de super-resolução em tempo real.