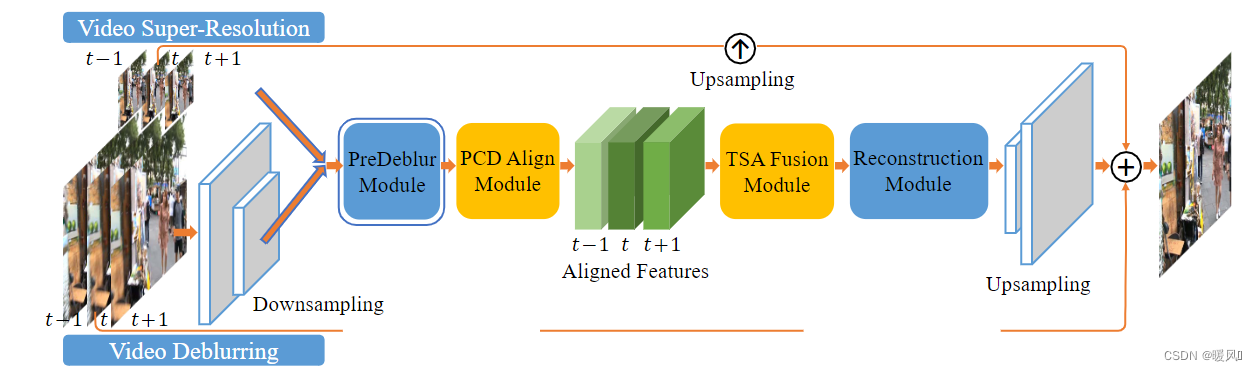
Este artigo combina as vantagens da rede deformável no tempo em TDAN e as vantagens do mecanismo de atenção de fusão em Robust-VSR . Com base nisso, uma estrutura piramidal é injetada e um novo método VSR EDVR (Enhanced Deformable Video Restoration) é proposto. é dividido principalmente em duas partes específicas:Redes de Alinhamento Deformável em Cascata Pirâmide(PCD) eRede de super-resolução de fusão de atenção espaço-temporal(TSA). é uma arquitetura geral aplicável a uma variedade de tarefas de restauração de vídeo, incluindo super-resolução, desfocagem, remoção de ruído, desbloqueio, etc.
原文链接: EDVR : Restauração de vídeo com redes convolucionais deformáveis aprimoradas [CVPR 2019]
solução com Dinâmica Temporal Aprendida
EDVR: restauração de vídeo com redes convolucionais deformáveis aprimoradas
Abstrato
A estrutura geral do EDVR ainda é dividida em quatro partes, como a arquitetura usual de super-resolução de vídeo: extração de recursos, alinhamento , fusão e reconstrução. Apenas mergulhei na parte de alinhamento e fusão para fazer com que o vídeo mantenha um desempenho excelente quando contém grande movimento, oclusão e desfoque severo.
Um novo conjunto de dados , conjunto de dados REalistic and Diverse Scenes (REDS), foi lançado no 2019 NTIRE Video Super Score Challenge. Em comparação com conjuntos de dados existentes, os vídeos REDS contêm movimentos maiores e mais complexos, tornando a tarefa de reconstrução de vídeo mais realista e desafiadora. O desempenho de muitos métodos anteriores de reconstrução de vídeo caiu muito neste conjunto de dados. Isso também está impulsionando o progresso nas tarefas de reconstrução de super-resolução de vídeo.
Uma Rede de Alinhamento Convolucional Deformável em Cascata em Pirâmide (PCD) e uma Rede SR de Fusão de Atenção Espaço-temporal (TSA) são propostas.
- Rede de Alinhamento Convolucional Deformável em Cascata da Pirâmide (PCD), o PCD é baseado no método de alinhamento de convolução deformável DCN, de um estágio e livre de fluxo, usando uma estrutura de pirâmide para alinhar o DCN com base em mapas de recursos de diferentes níveis (diferentes níveis representam informações de recursos de diferentes frequências) , e Passar e fundir os mapas de recursos alinhados (deslocamento) de diferentes níveis para o nível de mapa de recursos de resolução mais alta produz uma estrutura de compensação de movimento implícita de grosseira a fina.
- Rede SR de fusão de atenção espaço-temporal (TSA), o TSA é baseado no mecanismo de atenção. Como as informações contidas em diferentes quadros e diferentes pontos de recursos têm importância diferente para a reconstrução da imagem, ele atribui pesos diferentes para focar em informações importantes e ignora informações inúteis ou erradas. Não apenas a atenção espacial (SA) do tipo RCAN, mas também a atenção temporal (TA) são usadas nesta rede.
1. Introdução
Normalmente, o pipeline de tarefas de super-resolução de vídeo consiste em quatro partes, ou seja, extração de recursos, alinhamento, fusão e reconstrução . O desafio está no design dos módulos de alinhamento e fusão quando os vídeos contêm oclusões, grandes movimentos e desfoques intensos . Para obter uma saída de alta qualidade, duas chaves devem ser compreendidas:
- Como alinhar e estabelecer correspondência precisa entre vários quadros, movimentos grandes e complexos podem facilmente causar artefatos nos quadros de vídeo reconstruídos.
- Como fundir com eficiência recursos que não podem ser alinhados com precisão para reconstrução.
O conjunto de dados REDS existe especificamente para os defeitos mencionados acima do algoritmo anterior.
Por que grandes movimentos levam a uma diminuição no desempenho?
- Grandes movimentos levam a
对齐的难度aumentos. Precisamos usar informações redundantes na hora de complementar os detalhes de um único quadro, desde que as imagens frontal e traseira estejam alinhadas, caso contrário, a diferença entre os dois quadros é muito grande e o conteúdo é completamente irrelevante, e as informações não podem ser usadas . A existência de grande movimento dificulta a captura da trajetória do movimento , e o processo intermediário pode ser apenas especulação aleatória. A precisão do alinhamento definitivamente será muito afetada e é provável que apareçam artefatos. O alinhamento impreciso causará sobreposição ou desfoque no próximo estágio de fusão, o que afetará o desempenho do SR. - Em movimento suave e de pequena escala, o desempenho da rede SR de fusão também será afetado devido à capacidade limitada da rede de alinhamento. Razão: Seja uma rede de alinhamento baseada em fluxo (como VESPCN, Robust-LTD da série STN) ou uma rede de alinhamento livre de fluxo (como o TDAN da série DCN), haverá uma estimativa aproximada ou um problema
无法做到精确对齐. - O método de alinhamento baseado em fluxo também tem um defeito grave que depende muito da precisão da estimativa de movimento.Uma vez que haja um problema com a estimativa, artefatos aparecerão no alinhamento e será difícil corrigi-lo posteriormente. O método de alinhamento sem fluxo relativo baseado em DCN é alinhado no nível do recurso, e o cálculo aproximado do deslocamento também pode fazer com que artefatos apareçam no mapa de recursos alinhados, mas, felizmente, ainda há espaço para correção e uma camada é adicionado atrás da Convolução pode reduzir a aparência de artefatos (em TDAN).
Como realizar uma fusão eficaz para melhorar o desempenho da reconstrução de super-resolução?
Quando o alinhamento faz com que artefatos como desfoque e fantasma apareçam na entrada do quadro alinhado para a rede SR ou quando há muito movimento no vídeo, na parte de fusão, deixe a rede prestar mais atenção às informações do recurso que podem melhorar a qualidade de reconstrução, ignorando o desfoque e 引入注意力机制as informações de recursos pesados, como sombras, e use o mecanismo de atenção para atribuir pesos de acordo com a importância.
Uma breve revisão do desenvolvimento da fusão e alinhamento nos últimos anos:
Alinhamento:
O alinhamento é dividido principalmente em duas formas:
- Com base no método de fluxo óptico (baseado em fluxo), usando STN como base, deforme o quadro de suporte diretamente no Image-wise: estruturas VSR típicas incluem VESPCN, Robust-LTD, etc.
- O método que não depende do fluxo óptico (sem fluxo), usando DCN como base, alinha o mapa de recursos do quadro de suporte na compensação de movimento implícita em termos de recursos: estruturas VSR típicas incluem DUF, TDAN, etc.
pergunta:
- Os métodos anteriores são alinhados apenas em uma única escala de resolução , portanto, nem com base em fluxo nem sem fluxo podem ser alinhados com eficiência em grandes vídeos de movimento.
- Há também um problema de precisão de alinhamento No algoritmo acima, exceto VESPCN, que usa um alinhamento grosseiro a fino de 2 níveis, o restante usa apenas alinhamento de 1 nível, portanto, a precisão da compensação de movimento não pode ser garantida. No entanto, o método baseado em fluxo do VESPCN é altamente dependente da precisão da estimativa de movimento e pertence ao método de dois estágios; portanto, se você precisar concluir o alinhamento multinível, levará mais tempo e recursos, em comparação com livre de fluxo. Uma abordagem de um estágio é mais lenta!
Fusão:
- No VESPCN, são propostos três métodos de fusão de fusão precoce, fusão lenta e convolução 3D;
- Rede de super-resolução de vídeo recorrente de quadro e rede de retroprojeção recorrente para super-resolução de vídeo usam rede neural cíclica para fusão de recursos;
- Robust-LTD usa uma rede adaptável ao tempo para projetar um método de fusão baseado em um mecanismo de atenção para selecionar automaticamente uma escala de tempo.
pergunta:
- Diferentes quadros contêm informações de diferentes graus de importância, mas os métodos de fusão mencionados acima tratam diferentes quadros da mesma maneira,
- Diferentes pontos de recursos têm valores diferentes para super-resolução e algumas informações de recursos são borradas por alinhamento impreciso ou aparecem artefatos como fantasmas.
Portanto, um mecanismo de atenção é introduzido no EDVR para aprender a atribuir diferentes valores de peso a informações de diferentes importâncias em recursos. Para as informações que não são benéficas para o treinamento da rede de super-resolução, um peso pequeno é atribuído e um peso de atenção maior é atribuído às informações valiosas.
Em resposta aos problemas acima, o autor propõe o método EDVR, que melhora tanto o alinhamento quanto a fusão, e propõe uma rede de alinhamento convolucional deformável em cascata piramidal (PCD) e uma rede SR de fusão de atenção espaço-temporal (TSA).
Peça de alinhamento:
Para grandes problemas de movimento, o EDVR leva aRede de Alinhamento Convolucional Deformável em Cascata da Pirâmide (PCD), o PCD é baseado no método de alinhamento de convolução deformável DCN, de um estágio e livre de fluxo, usando uma estrutura de pirâmide para alinhar o DCN com base em mapas de recursos de diferentes níveis (diferentes níveis representam informações de recursos de diferentes frequências) , e Transferir e fundir o mapa de recursos alinhado (deslocamento) de diferentes níveis para o nível do mapa de recursos de resolução mais alta para gerar uma estrutura de compensação de movimento implícita de aproximada a precisa; além disso, um TDAN adicional é definido no PCD fora da pirâmide para melhorar ainda mais o alinhamento Robustez da rede.
Parte de fusão:
Para a fusão de multi-movimento e desfoque, o EDVR leva aRede SR de fusão de atenção espaço-temporal (TSA), o TSA é baseado no mecanismo de atenção. Como as informações contidas em diferentes quadros e diferentes pontos de recursos têm importância diferente para a reconstrução da imagem, ele atribui pesos diferentes para focar em informações importantes e ignora informações inúteis ou erradas. Não apenas a atenção espacial (SA) do tipo RCAN, mas também a atenção temporal (TA) são usadas nesta rede. A atenção temporal é calcular a semelhança entre o quadro de suporte e o quadro de referência para obter o peso, usando a dependência temporal entre o quadro de suporte e o quadro de referência.
2 Método
EDVR é uma rede de reconstrução de vídeo multifuncional, que inclui funções de super-resolução, desfocagem, redução de ruído e desbloqueio.
A tarefa de desfocagem está fora do escopo de nossa discussão, portanto não entraremos em detalhes. A parte cinza cercada pelo círculo pontilhado vermelho é a função de pré-desfoque.
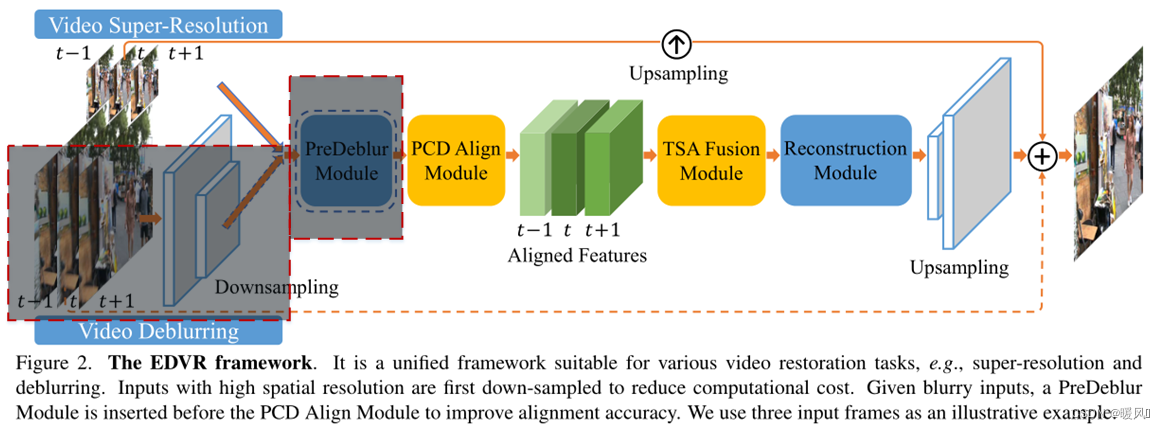
Estrutura da parte da superssegmentação de vídeo: Como outros métodos VSR, a entrada é fluxo de vídeo contínuo de 2N+1 quadro I [ t − N : t + N ] LR I_{[tN:t+N]}^{LR}EU[ t − N : t + N ]L R, onde o quadro intermediário I t LR I_t^{LR}EUtL Rcomo quadro de referência. Ao PCD对齐网络alinhar cada quadro adjacente com o quadro de referência no nível do recurso, são obtidos os 2N quadros alinhados do quadro de suporte e um quadro do quadro de referência. Depois de TSA融合模块fundir as informações da imagem de diferentes quadros e extrair recursos, o SR' é reconstruído, que 重建模块é uma cascata de vários blocos residuais (que podem ser substituídos por outros módulos avançados na tarefa SR) e as operações são executadas no final da rede 上采样para aumentar a resolução da imagem. , e então usar a imagem aumentada do quadro de referência LR como um termo de regularização para correção e, finalmente, obter um SR de alta resolução. (O módulo de desfoque também é útil para super-resolução. Ele pode ser colocado antes do módulo de alinhamento para reduzir efetivamente o problema de desfoque causado pela entrada, melhorando assim a qualidade do alinhamento.)
Para outras tarefas com entrada de alta resolução (por exemplo, desfoque de vídeo): os quadros de entrada são primeiro reduzidos usando convoluções, fazendo com que todo o processo seja computado no espaço de baixa resolução (economizando custo computacional). Usado antes do módulo de alinhamento 预模糊模块para pré-processar a entrada difusa e melhorar a precisão do alinhamento. No meio está a parte superpontuada. A camada de upsampling final redimensionará os recursos de volta à resolução de entrada original.
Nota: O autor usou estratégias de dois estágios, cascateando duas redes EDVR, mas a profundidade da segunda rede é menor, principalmente para refinar o quadro de saída do primeiro estágio. As redes em cascata podem remover ainda mais o desfoque de movimento grave que os modelos anteriores não conseguem lidar.
2.1 Alinhamento com PCD
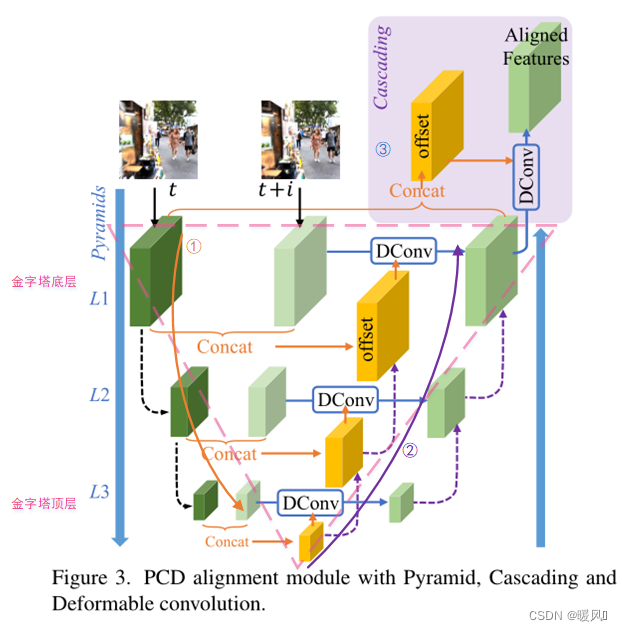
PCD (Pyramid, Cascading and Deformable Convolution) convolução deformável em cascata de pirâmide é um método baseado na convolução deformável DCN (Deformable Convolution Net), semelhante à variante de TDAN que contém informações de tempo. No entanto, o alinhamento em TDAN é relativamente grosseiro e é alinhado apenas uma vez. No PCD, o autor introduz uma estrutura piramidal e gradualmente extrai e funde recursos hierarquicamente. É um método grosseiro para fino, com recursos inteligentes.
Primeiro, entenda brevemente a visão geral dessa estrutura: insira dois quadros da imagem I t I_t de cada vezEUt和I t + i I_{t+i}EUt + eu, o primeiro passo é unir e obter o deslocamento ao longo da direção da linha amarela no lado esquerdo da pirâmide invertida , e o segundo passo é seguir a direção da linha roxa do recurso de camada mais alto para usar o deslocamento para executar convolução deformável e mesclar para a camada superior (amostragem superior, fusão) . A terceira etapa é a parte da cor de fundo roxa clara no canto superior direito. As feições do quadro de suporte após a fusão multicamada são emendadas com o quadro de referência e basta fazer um TDAN para obter o mapa de feições alinhado final Alinhado Recursos .
Esta seção requer o conhecimento de TDAN , que na verdade é uma estrutura variante de DCN que adiciona informações de tempo.
Deixe-me falar brevemente sobre porque o método é de grosseiro para fino.Esta rugosidade e precisão visam a precisão das características posicionais . O trabalho que temos que fazer é o alinhamento, e o mais importante para o alinhamento são as informações de posição. Na parte inferior da pirâmide, a resolução do recurso de imagem é a mais alta (o tamanho da imagem é o maior) e as informações de localização são mais precisas . A extração de recursos da parte da linha amarela é apenas um trabalho de pré-processamento da convolução deformável. O PCD primeiro executa a convolução deformável no mapa de recursos com a menor resolução para alinhamento aproximado e, em seguida, transfere o deslocamento e o mapa de recursos para uma imagem de recursos de resolução mais alta, e cada alinhamento se tornará mais preciso.
O módulo de alinhamento PCD é baseado em DCN (convolução deformável), que é quase exatamente o mesmo que o uso de DCN em TDAN. A única diferença é que apenas uma rede DCN é usada em TDAN; enquanto PCD usa várias redes DCN e redes convolucionais A estrutura piramidal é formada por cascata , e cada DCN é alinhado com base em mapas de características de diferentes níveis , então o alinhamento do PCD é um processo de grosseiro para fino, de cima para baixo.
Primeiro, deixe-me apresentar como a convolução deformável é feita no PCD:
Ao contrário do DCN clássico, o DCN no VSR precisa combinar informações de tempo e a entrada são dois quadros de imagens, portanto, é necessário simplesmente fundir o quadro de referência e o suporte frame primeiro , geralmente Use Early fusion para concatenação direta seguida por uma camada convolucional para reduzir a dimensão do canal. Em seguida, aprenda o deslocamento por meio de uma camada convolucional, usando o operador f ( ⋅ ) f(\cdot)f ( ⋅ ) representa a rede que aprende o deslocamento. F t + i , i ∈ [ − N , N ] F_{t+i},i\in [-N,N]Ft + eu,eu∈[ - N ,N ] significa2 N + 1 2N+12N_ _+1 quadro de imagem (cada amostra contém 2N+1 quadro de imagem), ondeF t F_tFté o quadro de referência e o resto são quadros de suporte, então a matriz de deslocamento Δ P \Delta PΔ P表达式为:
Δ P t + i = f ( [ F t + i , F t ] ) , i ∈ { − N , ⋯ , 1 , ⋯ , N } . (1) \Delta P_{t+i} = f([F_{t+i}, F_t]),i\in\{-N,\cdots, 1, \cdots,N\}.\tag{1 }P_ _t + eu=f ( [ Ft + eu,Ft] ) ,eu∈{
− N ,⋯,1 ,⋯,N } .( 1 )
AumentarΔ P = { Δ p } \Delta P =\{\Delta p\}P_ _={
Δ p },[ ⋅ , ⋅ ] [\cdot,\cdot][ ⋅ ,⋅ ] indica a operação concat.
Δ P t + i \Delta P_{t+i}P_ _t + euA resolução e F t + i F_{t+i}Ft + euÉ o mesmo (o deslocamento de cada posição em todo o patch é obtido) e a profundidade pode ser 2K ou K (2K significa direções xey).
Com o deslocamento, o deslocamento é então usado para suportar o quadro F t + i , i ∈ { − N , ⋯ , − 1 , 1 , ⋯ , N } F_{t+i},i\in\{-N, \ cdots,-1, 1, \cdots,N\}Ft + eu,eu∈{
− N ,⋯,− 1 ,1 ,⋯,N } , obtenha a imagem do recurso após a transformação da posição, geralmente a nova posição obtida é decoordenadas sub-pixel, portanto, o valor do pixel correspondente será obtido por meio deinterpolação bilineare o quadro de suporte após a transformação da posição será convoluído e a saída serão alinhados O mapa de recursos de suporteF t + ia F^a_{t+i}Ft + euum,Portanto:
F t + ia = ∑ k = 1 K w ( pk ) ⋅ F t + i ( p 0 + pk + Δ pk ⏟ p ) + b ( pk ) , (2) F^a_{t +i} = \sum^K_{k=1} w(p_k)\cdot F_{t+i}(\underbrace{p_0+p_k+\Delta p_k}_p) + b(p_k),\tag{2}Ft + euum=k = 1∑Kw ( pk)⋅Ft + eu(p
p0+pk+p_ _k)+b ( pk) ,( 2 )
Entre eles, w ( pk ) , b ( pk ) w(p_k), b(p_k)w ( pk) 、b ( pk) representa os parâmetros da convolução deformável,pk p_kpkRepresenta uma certa posição no kernel de convolução, assumindo convolução 3 × 3, então pk ∈ { ( − 1 , − 1 ) , ( − 1 , 0 ) , ⋯ , ( 1 , 1 ) } p_k\in \{( -1 ,-1), (-1, 0), \cdots, (1,1)\}pk∈{ ( − 1 ,− 1 ) ,( -1 , _0 ) ,⋯,( 1 ,1 ) } e K representa o número de parâmetros de um kernel de convolução.
Em seguida, apresentarei como é a estrutura em cascata da pirâmide: (o processo geral do PCD)
A primeira etapa: ( linha amarela ① )
Primeiro, os dois quadros de imagens (quadro de referência e quadro de suporte) na mesma janela de tempo são convoluídos para gerar seus respectivos mapas de recursos como as informações de recursos da primeira camada F t + i 1 F_ {t+i}^1Ft + eu1; Em seguida, use convolução strided para gerar informações de recursos F t + il F^l_{t+i} reduzido para 2Ft + eueu, onde uma camada l ∈ [ 1 , L ] l\in[1,L]eu∈[ 1 ,L ] , na figura acimaL = 3 L=3eu=3 , ou seja, são gerados três níveis deinformações de recursos, e a resolução de cada nível é, por sua vez,× 2 \times 2× 2 para atenuação.
Etapa 2: (linha roxa ②)
do último andarL 3 L3A partir de L 3 , os recursos do quadro de referência e o quadro de suporte da camada são fundidos (concat+convolução para reduzir a dimensão), odeslocamento da camada é obtido, e o deslocamento e o mapa de recursos de suporte do layer são usados para gerar a referência alinhada dacamada Feature map( F t + ia ) 3 (F^{a}_{t+i})^3( Ft + euum)3 (o "3" no sobrescrito indica o terceiro nível da pirâmide).
Em seguida, alinhe o deslocamento aprendido pela terceira camada com o mapa de recursos de referência ( F t + ia ) 3 (F^{a}_{t+i})^3( Ft + euum)3 é enviado para a próxima camada, a segunda camada. O deslocamento da segunda camada é combinado com o deslocamento obtido pela fusão dos dois mapas de recursos desta camada e, em seguida, reamostrado com o deslocamento obtido pela camada anterior. A saída do mapa de recursos alinhados por esta camada não é apenas derivada da saída da convolução deformável desta camada, mas também depende do mapa de recursos alinhados da camada anterior (semelhante ao deslocamento). A expressão específica é:
Δ P t + il = h ( [ f ( [ F t + i , F t ] ) , ( Δ P t + il + 1 ) ↑ 2 ] ) , (3) \Delta P_{t+ i }^l = h([f([F_{t+i},F_t]), (\Delta P_{t+i}^{l+1})^{\uparrow 2}]),\tag{ 3 }P_ _t + eueu=h ( [ f ( [ Ft + eu,Ft] ) ,( P_ _t + eueu + 1)↑ 2 ]),( 3 )
( F t + ia ) l = g ( [ DC onv ( F t + i , Δ P t + il ) , ( ( F t + ia ) l + 1 ) ↑ 2 ] ) . (4) (F^a_{t+i})^l = g([{DConv(F_{t+i},\Delta P^l_{t+i})},{((F^a_{t +i})^{l+1})^{\uparrow 2}}]).\tag{4}( Ft + euum)eu=g ( [ D C o n v ( Ft + eu,P_ _t + eueu) ,( ( Ft + euum)eu + 1 )↑ 2 ]).( 4 )
onde( ⋅ ) ↑ 2 (\cdot)^{\uparrow 2}( ⋅ )↑ 2 significa upsampling de 2 vezes usando interpolação bilinear;DC on ( ⋅ ) DCon(\cdot)D C o n ( ⋅ ) significa convolução deformável;g ( ⋅ ) , h ( ⋅ ) g(\cdot),h(\cdot)g ( ⋅ ) ,h ( ⋅ ) representa o processo de convolução geral;[ ⋅ , ⋅ ] [\cdot ,\cdot][ ⋅ ,⋅ ] significa concatenar.
Passe -o para a camada com alta resolução até a última camada, a primeira camada (ou seja, a camada inferior da pirâmide) e obtenha o mapa de recursos do quadro de suporte alinhado.
Etapa 3: ( quadro de fundo roxo claro ③ )
Fora da estrutura da pirâmide, simplesmente faça um TDAN . O mapa de recursos do quadro de referência da primeira camada e o mapa de recursos do quadro de suporte de alinhamento obtido ( F t + ia ) 1 (F^a_{t+i})^1( Ft + euum)1 é fundido para obter um deslocamento e, em seguida, use esse deslocamento e( F t + ia ) 1 (F^a_{t+i})^1( Ft + euum)1 executa a convolução deformável para produzir o mapa de recursos de suporte alinhado final. Isso permiteum ajuste adicional domapa de recursos de alinhamento retificado. Melhorar a robustez da rede.
Vantagens da estrutura piramidal PCD:
- Usando o DCN como bloco básico, em comparação com o STN de dois estágios, o DCN é de um estágio e tem mais vantagens em velocidade . Além disso, o DCN é baseado em recursos, que é uma compensação de movimento implícita que pode reduzir a influência de artefatos e não depende da precisão da estimativa de fluxo óptico .
- Múltiplos DCNs são colocados em cascata e cada DCN é baseado em mapas de recursos de diferentes níveis. Para recursos de diferentes resoluções , a compensação de movimento é executada de grosseira a fina para completar o alinhamento do quadro de suporte e dos recursos do quadro de referência. A estrutura DCN multinível ajuda para melhorar a precisão do alinhamento. A convolução deformável com base em diferentes mapas de recursos pode gerar transformações mais complexas, de modo que o alinhamento PCD possa aprender como alinhar estruturas de suporte a estruturas de referência sob movimentos grandes ou complexos.
2.2 Fusão com TSA
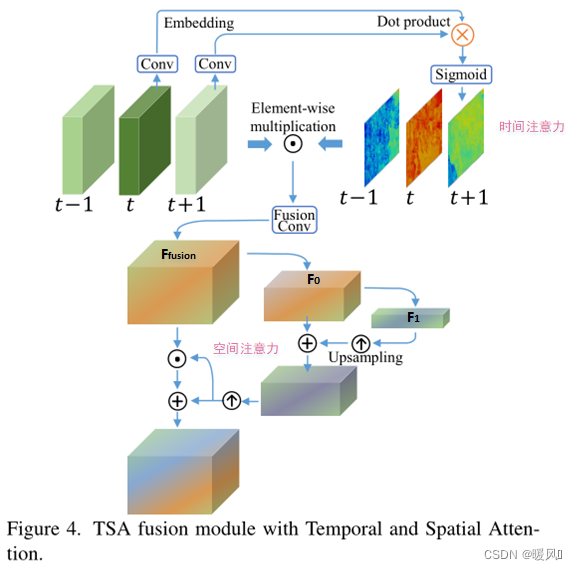
Fazer pleno uso da relação temporal entre os quadros e a relação espacial dentro dos quadros é crucial na fusão, mas
- Diferentes quadros adjacentes contêm informações com importância diferente devido à existência de alguns atributos (fantasma, desfoque, oclusão, etc.)
- Se houver um problema de baixa precisão ou alinhamento impreciso no estágio anterior , isso causará inconsistência no conteúdo dos quadros dianteiro e traseiro durante a fusão , o que afetará o efeito de reconstrução.
Para resolver os problemas acima, um mecanismo de atenção é introduzido no tempo e no espaço, ignorando as informações ruins sobre as características e focando nas informações importantes sobre as características. Um módulo de fusão TSA é proposto para atribuir pesos de agregação em nível de pixel a cada quadro para melhorar a eficácia e a eficiência da fusão.
Visão geral:
- Atenção ao tempo: a entrada é 2N+1 quadros, primeiro convola e depois calcule a semelhança entre cada quadro e o quadro de referência: através da multiplicação de pontos com o quadro de referência e depois através do Sigmóide (quadro de referência e multiplicação de pontos por você) para obter a similaridade de cada quadro Pesos de atenção temporal (nível de pixel). Em seguida, execute a multiplicação e a convolução do elemento com a entrada de quadro 2N+1 para obter o resultado fundido no tempo F fusão F_{fusão}Ff u s i o n。
- Atenção espacial: traço F fusão após fusão temporal F_{fusão}Ff u s i o nApós duas convoluções e downsampling, após um {upsampling e adição dos recursos da camada anterior}, outro upsampling para obter o valor do peso da atenção espacial (tamanho e F fusão F_{fusão}Ff u s i o nmesmo). O peso de atenção obtido mais ele mesmo e F fusão F_{fusão}Ff u s i o nOs valores multiplicados elemento a elemento fornecem a estimativa final da estrutura de suporte.
Atenção temporal:
O objetivo da atenção temporal é calcular a semelhança entre diferentes quadros e o quadro de referência, ou seja, os quadros adjacentes semelhantes ao quadro de referência têm alta importância e devem receber mais peso (nível de elemento de recurso).
O projeto da rede de atenção temporal é realizar primeiro a convolução, depois encontrar a similaridade entre cada quadro e o quadro de referência e, então, combinar os pesos de entrada e atenção elemento a elemento. Use θ ( ⋅ ) , ϕ ( ⋅ ) \theta(\cdot), \phi(\cdot)θ ( ⋅ ) e ϕ ( ⋅ ) representam respectivamente a convolução do mapa de recursos de suporte e do mapa de recursos de referência, portanto,a fórmula para calcular o peso da atenção temporal é:
h ( F t + ia , F ta ) = sigmóide ( θ ( F t + ia ) T ϕ ( F ta ) ) . (5) h(F^a_{t+i},F_t^a) = sigmóide(\theta(F^a_{t+i})^T \phi ( F_t^a)).\tag{5}h ( Ft + euum,Ftum)=s i g m o i d ( θ ( Ft + euum)T ϕ(Ftum) ) .( 5 )
sigmóide ( ⋅ ) sigmóide(\cdot)s i g m o i d ( ⋅ ) combina o mecanismo de portão no design de atenção para recuar o peso entre 0 e 1, o que ajuda a aumentar a estabilidade do treinamento. A CA de atenção do canal no RCAN pode ser vista como uma forma de escalonamento residual.
Depois de obter o peso de atenção, você pode executar a saída de fusão de tempo F fusão F_{fusão}Ff u s i o n,公式如下:
F ~ t + ia = F t + ia ⊙ h ( F t + ia , F ta ) , (6) \tilde{F}^a_{t+i} = F^a_{t+i} \odot h(F^a_{t+i},F_t^a),\tag{6}F~t + euum=Ft + euum⊙h ( Ft + euum,Ftum) ,( 6 )
F fusão = C onv ( [ F ~ t − N a , ⋯ , F ~ ta , ⋯ , F ~ t + N a ] ) . (7) F_{fusão} = Conv([\tilde{F}_{tN}^a,\cdots, \tilde{F}_{t}^a, \cdots, \tilde{F}_{t+ N}^a]).\tag{7}Ff u s i o n=C o n v ( [F~t − Num,⋯,F~tum,⋯,F~t + Num] ) .( 7 )
onde [ ⋅ , ⋅ ] [\cdot, \cdot][ ⋅ ,⋅ ] significa concat, e a essência da fórmula (7) é uma fusão inicial.
Atenção espacial:
O resultado da fusão do tempo pode ser considerado como um mapa de recursos sem dimensão de tempo .
Saída F fusão F_{fusão} após fusão de tempoFf u s i o nPrimeiro, use 2 reduções de amostragem de convolução e, em seguida, obtenha uma fusão F_{fusão} por meio de upsampling, adição e outras operaçõesFf u s i o nA atenção espacial do mesmo tamanho é finalmente multiplicada por elementos para produzir um mapa de recursos combinado com a fusão de atenção espacial e, finalmente, enviada para a rede de reconstrução para produzir uma versão de alta resolução do quadro de suporte. A expressão específica da atenção espacial é a seguinte:
F 0 = C onv ( F fusão ) , F 1 = C onv ( F 0 ) , F 2 = F 0 + F 1 ↑ , F = F 2 ↑ + F fusão ⊙ F 2 ↑ . F_0=Conv(F_{fusão}),\\F_1 = Conv(F_0),\\ F_2 = F_0 + F_1^{\uparrow},\\ F = F_2^{\uparrow} + F_{fusão} \ odot F_2^{\uparrow}.F0=C o n v ( Ff u s i o n) ,F1=C o n v ( F0) ,F2=F0+F1↑,F=F2↑+Ff u s i o n⊙F2↑.where ( ⋅ ) ↑ , ⊙ (\cdot)^{\uparrow}, \
odot( ⋅ )↑ ,⊙representam upsampling e multiplicação elementar, respectivamente.
Estratégia de dois estágios:
Duas redes EDVR são colocadas em cascata, mas a segunda rede é mais rasa, principalmente 细化第一阶段的输出帧para As redes em cascata podem remover ainda mais o desfoque de movimento grave que os modelos anteriores não conseguem lidar.
- Elimina efetivamente o problema de desfoque que não pode ser tratado por um único bloco EDVR e melhora a qualidade da restauração;
- As descontinuidades entre os quadros de saída de um único bloco EDVR são atenuadas.
3 experimentos
Treinamento: conjunto de dados REDS, este conjunto de dados tem uma resolução de 720p, um total de 240 vídeos no conjunto de treinamento, 30 vídeos no conjunto de teste e 30 vídeos no conjunto de verificação, mas o conjunto de teste não é público, então o autor extraiu
4 vídeos como conjunto de teste (REDS4 ) e os 266 vídeos restantes são usados para treinamento e verificação.
Conjunto de dados de treinamento do Vimeo-90K . Este conjunto de dados é de baixa resolução, mas alto em número.
Testado: Testado
em Vid4 e Vimeo-90K-T . Os 4 vídeos no Vid4 são relativamente lentos em movimento ; Vimeo-90K-T é relativamente grande, com muito movimento e cenas; REDS4 é um vídeo de alta definição com movimento maior e mais complexo.
configuração:
O estágio de extração de recursos no PCD usa 5 blocos residuais para extrair recursos.
(EDVR) 1 (EDVR)_1( E D V R )1A parte de reconstrução SR usa 40 blocos residuais ; (EDVR) 2 (EDVR)_2( E D V R )2A parte de reconstrução SR usa 20 blocos residuais . Os canais dos blocos residuais são todos definidos como 128 .
O patch de treinamento de super resolução é 64 × 64 e o patch para a tarefa de desfocagem é 256 × 256.
lote=32.
1 amostra contém 5 quadros consecutivos.
Durante o treinamento, dois tipos de auto-reforço são usados: flip horizontal e rotação de 90°.
A função de perda de treinamento é L = ∣ ∣ O ^ t − O t ∣ ∣ 2 + ϵ 2 , ϵ = 1 0 − 3 \mathcal{L}=\sqrt{||\hat{O}_t - O_t||^ 2 + \epsilon^2},\epsilon=10^{-3}eu=∣ ∣O^t−Ot∣ ∣2+ϵ2,ϵ=1 0− Otimização de 3
Adams, a taxa de aprendizado inicial é definida como4 × 1 0 − 4 4\times 10^{-4}4×1 0− 4
Primeiro treine a camada rasa( EDVR ) 2 (EDVR)_2( E D V R )2, então passe seu argumento como deep (EDVR)1(EDVR)_1( E D V R )1parâmetros de inicialização para acelerar a convergência.
O experimento comparou os resultados entre diferentes métodos SOTA; estudou as respectivas funções e efeitos de PCD e TSA; estudou o desvio do conjunto de dados; para
comparação experimental específica, consulte EDVR
para concluir:
- No vídeo em câmera lenta de Vid4, EDVR e DUF obtiveram o melhor desempenho de reconstrução, mas EDVR não aumentou a lacuna.
- No teste REDS4, o EDVR demonstrou sua capacidade de super-resolução adaptada a movimentos grandes e complexos e abriu uma lacuna com o DUF.
- O PCD pode alinhar quadros de suporte e quadros de referência sob grandes movimentos, e o módulo TSA atribuirá pesos mais altos a quadros melhor alinhados para melhorar o desempenho da reconstrução.
- Os resultados do treinamento em diferentes conjuntos de dados no mesmo conjunto de teste terão um grande desvio.
- A autointegração tem pouco efeito na melhoria do desempenho do VSR, enquanto a estratégia de dois estágios apresenta uma melhoria maior no desempenho.
4 Conclusões
Este artigo melhora principalmente a parte de alinhamento e a parte de fusão na tarefa VSR , absorvendo as vantagens da rede deformável no tempo em TDAN e o mecanismo de atenção à fusão em Robust-VSR, usando a estrutura piramidal como estrutura. É dividido principalmente em duas partes específicas:Redes de Alinhamento Deformável em Cascata Pirâmide(PCD) eRede de super-resolução de fusão de atenção espaço-temporal(TSA)。
- Múltiplos DCNs em PCD são colocados em cascata, e cada DCN é baseado na
不同层级的feature mapcompensação de movimento grosso a fino para completar o alinhamento dos recursos do quadro de suporte e do quadro de referência. A estrutura DCN multinível ajuda a melhorar a precisão do alinhamento. A convolução deformável com base em diferentes mapas de recursos pode gerar transformações mais complexas, de modo que o alinhamento PCD possa aprender como alinhar estruturas de suporte a estruturas de referência sob movimentos grandes ou complexos. - No TSA
时间和空间注意力, quadros adjacentes que são mais semelhantes ao quadro de referência receberão valores de peso mais altos, e quadros ou posições que não estão alinhados com precisão no módulo de alinhamento receberão valores de peso menores. (em termos de elemento) - O novo conjunto de dados de vídeo REDS contém movimentos maiores e mais complexos, tornando as tarefas de reconstrução de vídeo mais realistas e desafiadoras, enquanto o EDVR pode lidar com elas com facilidade.
- EDVR é uma arquitetura geral aplicável a uma variedade de tarefas de restauração de vídeo, incluindo super-resolução, desfocagem, remoção de ruído, desbloqueio, etc.
Registre o uso de uma cor de fundo:
algoritmo de super-resolução EDVR \colorbox{blue}{algoritmo de super-resolução EDVR}Algoritmo de super resolução E D V R
<font color = white>$\colorbox{blue}{超分算法EDVR}$</font> ##蓝底白字
Por fim, desejo a todos sucesso na pesquisa científica, boa saúde e sucesso em tudo~