Artigo: https://arxiv.org/pdf/2308.00692
Código: GitHub - dvlab-research/LISA
Resumo
Embora os sistemas de percepção tenham feito um progresso notável nos últimos anos, eles ainda dependem de instruções humanas explícitas para identificar objetos ou categorias de destino antes de realizar tarefas de reconhecimento visual. Esses sistemas carecem da capacidade de raciocinar ativamente e entender a intenção implícita do usuário. Neste trabalho, propomos uma nova tarefa de segmentação - segmentação por inferência . O objetivo desta tarefa é produzir uma máscara de segmentação a partir de um texto de consulta complexo e implícito . Além disso, construímos um benchmark composto por mais de mil pares de instruções de imagem, incorporando raciocínio complexo e conhecimento de mundo para fins de avaliação . Finalmente, propomos o LISA: Large Language Instructed Segmentation Assistant, que herda os recursos de geração de linguagem de modelos multimodais de linguagem grande (LLMs), além de ter a capacidade de gerar máscaras de segmentação . Nós estendemos o vocabulário original usando a tag <SEG> e propomos embeddings como um paradigma de mascaramento para desbloquear capacidades de segmentação. Notavelmente, LISA pode lidar com as seguintes situações: 1 ) raciocínio complexo; 2) conhecimento de mundo; 3) respostas interpretativas; 4) diálogo multi-turn . Além disso, mostra forte capacidade de tiro zero quando treinado apenas no conjunto de dados sem inferência. Além disso, o ajuste fino do modelo usando apenas 239 pares de instruções de imagem de segmentação de inferência melhora ainda mais o desempenho. As experiências mostram que o método não apenas desbloqueia novos recursos de segmentação de inferência, mas também é eficaz tanto na segmentação de inferência complexa quanto nas tarefas de segmentação de referência padrão.

fundo
Neste trabalho, introduzimos uma nova tarefa de segmentação - segmentação por inferência, que requer a geração de máscaras de segmentação binária baseadas em textos de consulta implícitos envolvendo raciocínio complexo.
Notavelmente, o texto da consulta não se restringe a referências simples (por exemplo, “laranjas”), mas a descrições mais complexas envolvendo raciocínio complexo ou conhecimento de mundo (por exemplo, “alimentos de alta qualidade contêm vitamina C”). Para realizar esta tarefa, o modelo deve ter duas capacidades principais: 1) raciocinar sobre consultas textuais complexas e implícitas em conjunto com imagens; e 2) gerar máscaras de segmentação.
Embora alguns estudos tenham integrado recursos robustos de raciocínio em LLMs multimodais para entrada visual, a maioria desses modelos se concentra principalmente em tarefas de geração de texto e requer tarefas de formato de saída refinadas ainda são insuficientes, como segmentação.
Ao representar as máscaras de segmentação como incorporações, o LISA ganha recursos de segmentação e se beneficia do treinamento de ponta a ponta.
contribuir
1) Introduzimos a tarefa de segmentação por inferência, que requer raciocínio baseado em instruções humanas implícitas. Esta tarefa destaca a importância da capacidade de auto-raciocínio, que é crucial para a construção de um sistema de percepção verdadeiramente inteligente.
2) Construímos um benchmark de segmentação por inferência, ReasonSeg, contendo mais de mil pares de instruções de imagem. Esse benchmark é fundamental para avaliar e incentivar a comunidade a desenvolver novas tecnologias.
3) Propomos nosso modelo - LISA, que emprega o embedding como um paradigma de mascaramento para incorporar novos recursos de segmentação. Quando treinado no conjunto de dados sem inferência, o LISA mostra forte capacidade de tiro zero na tarefa de segmentação de inferência, e o desempenho é aprimorado ainda mais pelo ajuste fino de 239 pares de instruções de imagem envolvendo inferência. Acreditamos que o LISA facilitará o desenvolvimento da inteligência perceptiva e inspirará novos avanços nessa direção.
Trabalho relatado
Segmentação de imagem SEGMENTAÇÃO DE IMAGEM
O objetivo da segmentação semântica é atribuir um rótulo de classe a cada pixel em uma imagem.
Numerosos estudos propuseram vários designs (por exemplo, codificador-decodificador, convolução dilatada, módulos de agrupamento de pirâmides, operadores não locais, etc.) para codificar com eficiência informações semânticas.
Estudos de segmentação de instância e segmentação de visão completa introduziram várias inovações arquitetônicas para segmentação em nível de instância, incluindo estruturas baseadas em DETR (Carion et al., 2020), atenção de máscara e convolução dinâmica .
Mais recentemente, Kirillov e outros (2023) introduziram SAMs , treinados com bilhões de máscaras de alta qualidade, suportando caixas delimitadoras e pontos como sugestões, enquanto demonstravam excelente qualidade de segmentação. O X-Decoder (Zou et al., 2023a) une visão e linguagem, unificando várias tarefas em um único modelo. SEEM (Zou et al., 2023b) suporta ainda vários métodos de interação humana, incluindo texto, áudio e rabiscos. No entanto, esses estudos se concentram principalmente na compatibilidade e unificação multitarefa, ignorando a injeção de novos recursos.
Neste trabalho, propomos o LISA para resolver tarefas de segmentação por inferência e aumentar os segmentadores visuais existentes com capacidades de auto-raciocínio .
Modelo de linguagem grande multimodal MODELO DE LINGUAGEM GRANDE MULTI-MODAL
Motivados pelas capacidades superiores de raciocínio dos LLMs, os pesquisadores estão explorando maneiras de transferir essas capacidades para o domínio da visão, desenvolvendo LLMs multimodais.
Flamingo (Alayrac, 2022) emprega uma estrutura de atenção cruzada para focar em contextos visuais, permitindo a aprendizagem do contexto visual.
Modelos como BLIP-2 (Li et al., 2023b) e mPLUG-OWL (Ye et al., 2023) propõem codificar recursos de imagem com um codificador visual, que são então alimentados em um LLM junto com incorporações de texto.
Otter (Li et al., 2023a) incorpora ainda recursos robustos de poucos disparos por meio de ajuste de instrução contextual no conjunto de dados MIMIC-IT proposto. O LLaVA (Liu et al., 2023b) e o MiniGPT-4 (Zhu et al., 2023) primeiro executam o alinhamento de recurso imagem-texto seguido pelo ajuste da instrução.
Além disso, vários trabalhos (Wu et al., 2023; Yang et al., 2023b; Shen et al., 2023; Liu et al., 2023c; Yang et al., 2023a) utilizam engenharia instantânea para conectar módulos independentes por meio de chamadas de API , mas não Benefícios do treinamento de ponta a ponta.
Recentemente, houve vários estudos explorando a interseção entre LLM e multimodalidade em tarefas de visão.
O VisionLLM (Wang et al., 2023) fornece uma interface flexível para várias tarefas centradas na visão por meio do ajuste de instrução, mas não consegue utilizar totalmente o LLM para raciocínio complexo.
Kosmos-2 (Peng et al., 2023) constrói dados em larga escala com base em pares imagem-texto, injetando a capacidade de basear-se em LLM. GPT4RoI (Zhang et al., 2023) introduz caixas espaciais como entrada e treina o modelo em pares região-texto
Em contraste, nosso trabalho visa
1) Injetar recursos de segmentação com eficiência em LLMs multimodais
2) Desbloqueie a capacidade de auto-raciocínio do sistema de percepção atual.
Introdução à segmentação de raciocínio

definição de problema
A tarefa de segmentação de inferência é produzir uma máscara de segmentação binária M dada uma imagem de entrada ximg e uma instrução de texto de consulta implícita xtxt
Em vez de frases simples (por exemplo, "lata de lixo"), o texto da consulta pode conter expressões mais complexas (por exemplo, "coisas que devem ser colocadas no lixo") ou frases mais longas (por exemplo, "depois de cozinhar, coma Onde podemos jogar o sobras e sobras?"), que envolve raciocínio complexo ou conhecimento de mundo.
Referências
Na ausência de avaliação quantitativa, é necessário estabelecer um benchmark para tarefas de segmentação de inferência. Para garantir uma avaliação confiável, coletamos um conjunto diversificado de imagens de OpenImages (Kuznetsova et al., 2020) e ScanNetv2 (Dai et al., 2017) e as combinamos com instruções de texto implícitas e máscaras de objetos de alta qualidade. Elas são anotadas . Nossas legendas incluem dois tipos: 1) frases curtas; 2) frases longas, como mostra a Figura 2. O benchmark ReasonSeg resultante contém um total de 1218 pares de instruções de imagem. O conjunto de dados é dividido em três partes: train, val e test, contendo 239, 200 e 779 pares de instruções de imagem, respectivamente. Como o objetivo principal do benchmark é a avaliação, os conjuntos de validação e teste contêm mais amostras de instruções de imagem.
método
estrutura do modelo

Incorporando como máscara
O VisionLLM (Wang et al., 2023) pode suportar a representação de máscaras de segmentação como texto simples, analisando-as em sequências de polígonos e permite o treinamento de ponta a ponta dentro das estruturas LLM multimodais existentes. No entanto, o treinamento de ponta a ponta de sequências de polígonos apresenta desafios de otimização e pode prejudicar a generalização, a menos que grandes quantidades de dados e recursos computacionais sejam usados. Por exemplo, para treinar um modelo 7B, o VisionLLM requer 4 × 8 GPUs NVIDIA 80G A100 e 50 épocas, o que é computacionalmente proibitivo. Por outro lado, o treinamento do LISA-7B requer apenas 10.000 etapas em 8 GPUs NVIDIA 24G 3090 .
Para tanto, propomos embeddings como um paradigma de mascaramento para injetar novos recursos de segmentação em LLMs multimodais.
passo 1
Texto
Primeiro, estendemos o vocabulário LLM original com um novo token, chamado <SEG>, que representa uma solicitação de saída de segmentação. Dada uma instrução de texto xtxt e uma imagem de entrada ximg, nós as alimentamos em um LLM F multimodal, que por sua vez gera uma resposta de texto ytxt.

Quando o LLM pretende gerar máscaras de segmentação binária, a saída ytxt deve conter um token <SEG>.
Em seguida, extraímos a incorporação da última camada correspondente ao token <SEG> - hseg e aplicamos a camada de projeção MLP γ para obter hseg .
imagem
Enquanto isso, uma rede neural de backbone visual extrai incorporações visuais de imagens de entrada visual. Finalmente, hseg e f são enviados para o decodificador Fdec para produzir a máscara de segmentação final M. A estrutura detalhada do decodificador Fdec refere-se a Kirillov et al (2023). Este processo pode ser expresso como

Objetivos de Treinamento
função de perda
O modelo é treinado de ponta a ponta usando a perda de geração de texto Lxt e a perda de máscara de segmentação Lmask . O alvo total L é uma soma ponderada dessas perdas, determinada por λtxt e λmask:
![]()
Especificamente, Ltxt é uma perda autoregressiva de entropia cruzada para geração de texto e Lmask é uma perda de máscara, que leva o modelo a produzir resultados de segmentação de alta qualidade. Para calcular Lmask, empregamos uma combinação de perda de entropia cruzada binária por pixel (BCE) e perda DICE com pesos de perda correspondentes λbce e λdice, respectivamente. Dados os alvos reais ytxt e m, essas perdas podem ser expressas como:

Formulação de dados de treinamento fórmula de dados de treinamento
Nossos dados de treinamento consistem em três partes, todas derivadas de conjuntos de dados públicos amplamente usados. Detalhes a seguir

Conjunto de dados de segmentação semântica. Conjunto de dados de segmentação semântica
Os conjuntos de dados de segmentação semântica geralmente consistem em imagens e rótulos de várias classes correspondentes.
Durante o treinamento, selecionamos aleatoriamente várias categorias para cada imagem. Para gerar dados que correspondam ao formato da pergunta e resposta visual, usamos o seguinte modelo de pergunta e resposta
" USER: <IMAGE> Você pode segmentar {CLASS NAME} nesta imagem?" Assistente: Sim <SEG>, onde {CLASS NAME} é a categoria selecionada e <IMAGE> representa o espaço reservado para o token de patches de imagem.
A supervisão de perda de máscara é fornecida usando a máscara de segmentação binária correspondente como verdade básica. Durante o treinamento, também usamos outros modelos para gerar dados de controle de qualidade para garantir a diversidade de dados. Empregamos conjuntos de dados de segmentação de peças ADE20K , COCO-Stuff e LVIS-PACO .
Conjunto de dados de segmentação de referência Vanilla Conjunto de dados de segmentação de referência
Conjuntos de dados de segmentação de referência fornecem descrições curtas explícitas de imagens de entrada e objetos de destino.
Portanto, é fácil convertê-los em pares de perguntas e respostas usando um modelo como "O USUÁRIO: <IMAGEM> pode dividir {descrição} nesta imagem?" Assistente: Claro, <SEG>, onde {descrição} é a descrição explícita fornecida. Esta seção usa os conjuntos de dados refCOCO , refCOCO+ , refCOCOg e refCLEF .
Conjunto de dados de resposta a perguntas visuais Conjunto de dados de respostas a perguntas de imagens
Para manter a capacidade original de resposta a perguntas visuais (VQA) do LLM multimodal, também incluímos o conjunto de dados VQA durante o treinamento. Usamos diretamente os dados llava-instruction-150k gerados pelo GPT-4 (Liu et al., 2023b).
parâmetros treináveis
Para preservar a capacidade de generalização do LLM F multimodal pré-treinado (ou seja, LLaVA em nossos experimentos), aproveitamos o LoRA (Hu et al., 2021) para um ajuste fino eficiente e congelamos completamente o backbone visual. O decodificador Fdec é totalmente ajustado. Além disso, a incorporação de palavras e a camada de projeção γ do LLM também são treináveis.
experimentar
configurações do experimento
estrutura de rede
Salvo disposição em contrário, adotamos LLaVA-7B-v1-1 ou LLaVA-13B-v1-1 como o LLM F multimodal
A rede de backbone ViT-H SAM é usada como a rede de backbone visual.
A camada de projeção de γ é um MLP com canais [256, 4096, 4096] .
detalhes de implementação
8 GPUs NVIDIA 24G 3090
O roteiro de treinamento é baseado no motor deepspeed (Rasley et al., 2020). Usamos o otimizador AdamW (Loshchilov & Hutter, 2017) com taxa de aprendizado e decaimento de peso definidos como 0,0003 e 0, respectivamente .
Também adotamos WarmupDecayLR como o escalonador de taxa de aprendizado , onde as iterações de aquecimento são definidas como 100.
Os pesos da perda de geração de texto λtxt gen e da perda de máscara λmask são definidos como 1,0 e 1,0, respectivamente,
Os pesos de bce loss λbce e dice loss λdice são definidos como 2,0 e 0,5, respectivamente.
Além disso, o tamanho do lote de cada dispositivo é definido como 2 e a etapa de acumulação de gradiente é definida como 10. Durante o treinamento, escolhemos até 3 categorias para cada imagem no conjunto de dados de segmentação semântica.
conjunto de dados
Para conjuntos de dados de segmentação semântica, usamos ADE20K (Zhou et al., 2017) e COCO-Stuff (Caesar et al., 2018). Além disso, para aprimorar os resultados da segmentação de certas partes de objetos, também usamos conjuntos de dados de segmentação semântica parcial, incluindo PACO-LVIS (Ramanathan et al., 2023), PartImageNet (He et al., 2022) e PASCAL-Part (Chen et al. Pessoas, 2014);
Para os conjuntos de dados de segmentação de referência, usamos refCLEF , refCOCO , refCOCO+ (Kazemzadeh et al., 2014) e refCOCOg (Mao et al., 2016).
Para o conjunto de dados Visual Question Answering (VQA), usamos o conjunto de dados llava-instruction-150k (Liu et al., 2023b). Para evitar vazamento de dados, excluímos amostras COCO cujas imagens aparecem no conjunto de validação refCOCO(+/g) durante o treinamento.
Além disso, descobrimos surpreendentemente que o desempenho do modelo pode ser melhorado ajustando o modelo em 239 amostras de pares de instruções de imagem ReasonSeg.
índice de avaliação
Seguimos a maioria dos trabalhos anteriores sobre segmentação de referência (Kazemzadeh et al., 2014;) gIoU é definido pela média de todas as interseções-união (iou) por imagem, enquanto cIoU é definido pela interseção-união cumulativa. Uma vez que cIoU tem um grande viés para objetos de grande área e flutua muito, gIoU é o preferido .
Resultados experimentais
SEGMENTAÇÃO DE RACIOCÍNIO

Um modelo só pode fazer um bom trabalho se realmente entender a consulta. Os trabalhos existentes são limitados a citações explícitas sem métodos adequados para entender consultas implícitas, enquanto nosso modelo utiliza um LLM multimodal para conseguir isso.
O desempenho do LISA-13B é muito melhor do que o do 7B, especialmente no cenário de consulta longa, sugerindo que o atual gargalo de desempenho ainda pode estar na compreensão do texto da consulta, e um LLM multimodal mais poderoso pode levar a melhores resultados
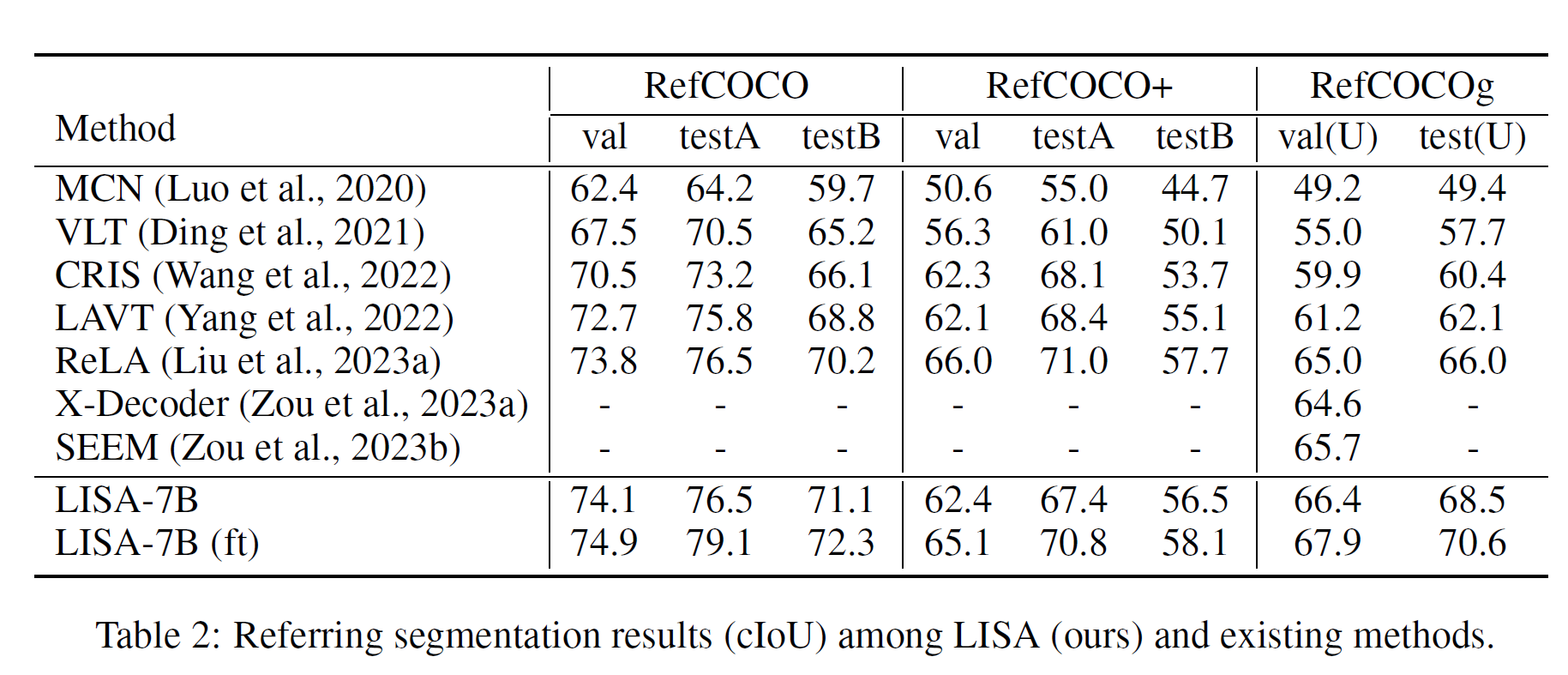
SEGMENTAÇÃO REFERENTE VANILLA
experimento de ablação
Salvo indicação em contrário, relatamos as métricas gIoU e cIoU para LISA-7B no conjunto de validação.
Opções de design para o backbone visual

As opções de design para o backbone visual são flexíveis e não se limitam ao SAM
Ajuste fino de SAM LoRA
Percebemos que o backbone SAM ajustado por LoRA não teve um desempenho tão bom quanto o backbone congelado. Uma possível razão é que o ajuste fino enfraquece a capacidade de generalização do modelo SAM original
Pesos pré-treinados SAM
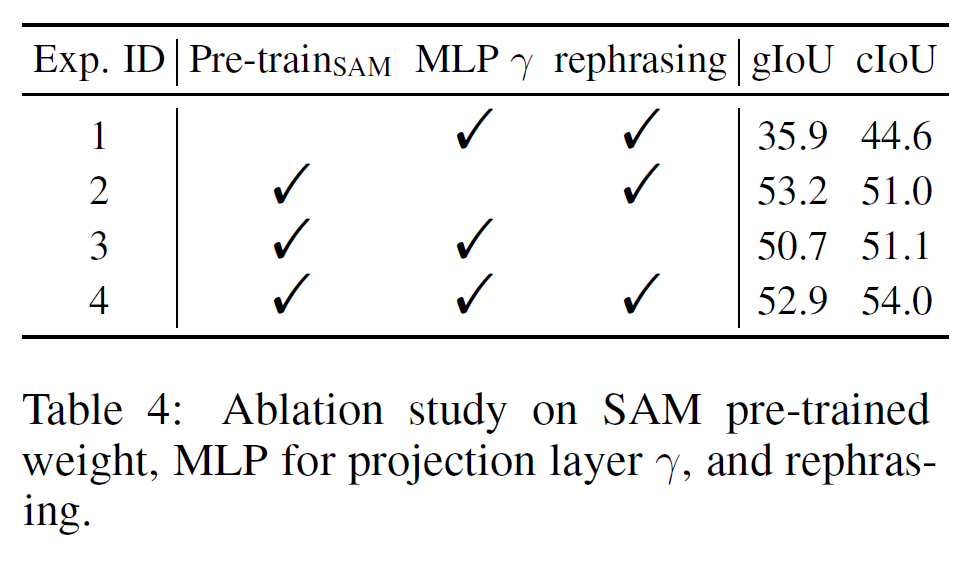
Sem pesos pré-treino, o desempenho cai drasticamente!
MLP vs. Camada de Projeção Linear
Notamos que fazer γ MLP tem uma pequena queda de desempenho em gIoU, mas um desempenho relativamente alto em cIoU↑
Contribuição de todos os tipos de dados de treinamento
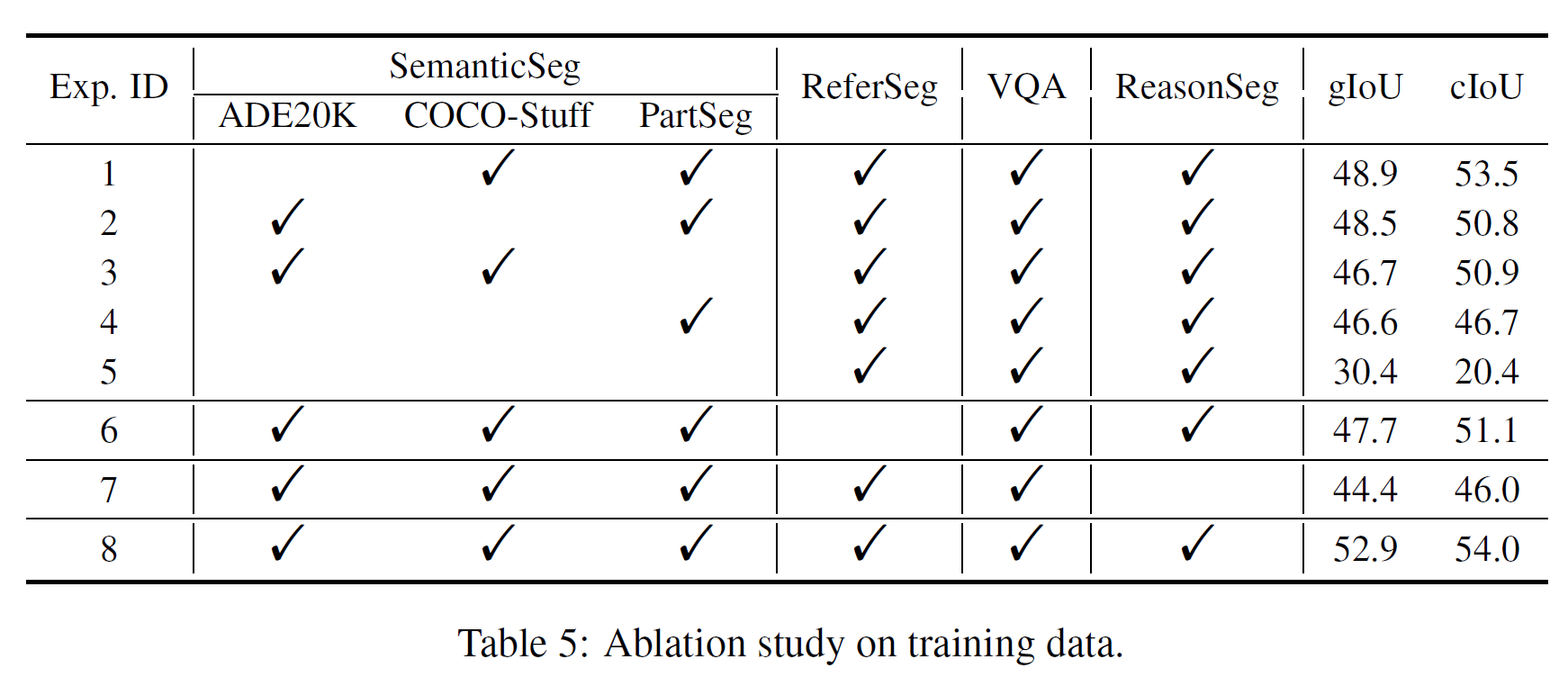
Vale ressaltar que no Exp. 4 não usamos nenhum conjunto de dados de segmentação semântica e o desempenho caiu muito. Conjecturamos que o conjunto de dados de segmentação semântica fornece um grande número de máscaras binárias de verdade para treinamento, uma vez que um rótulo multiclasse pode gerar várias máscaras binárias. Isso mostra que os conjuntos de dados de segmentação semântica são cruciais no treinamento
Recapitulação do Comando GPT-3.5
No processo de ajuste fino do par de instruções de imagem para segmentação de inferência, usamos GPT-3.5 para reescrever a instrução de texto e selecionar uma aleatoriamente. A comparação do Experimento 3 e do Experimento 4 na Tabela 4 mostra que o desempenho melhora em 2,2% e 2,9% cIoU, respectivamente. Este resultado verifica a eficácia deste método de aumento de dados.
APÊNDICE - ALGUNS RESULTADOS EXPERIMENTAIS

