
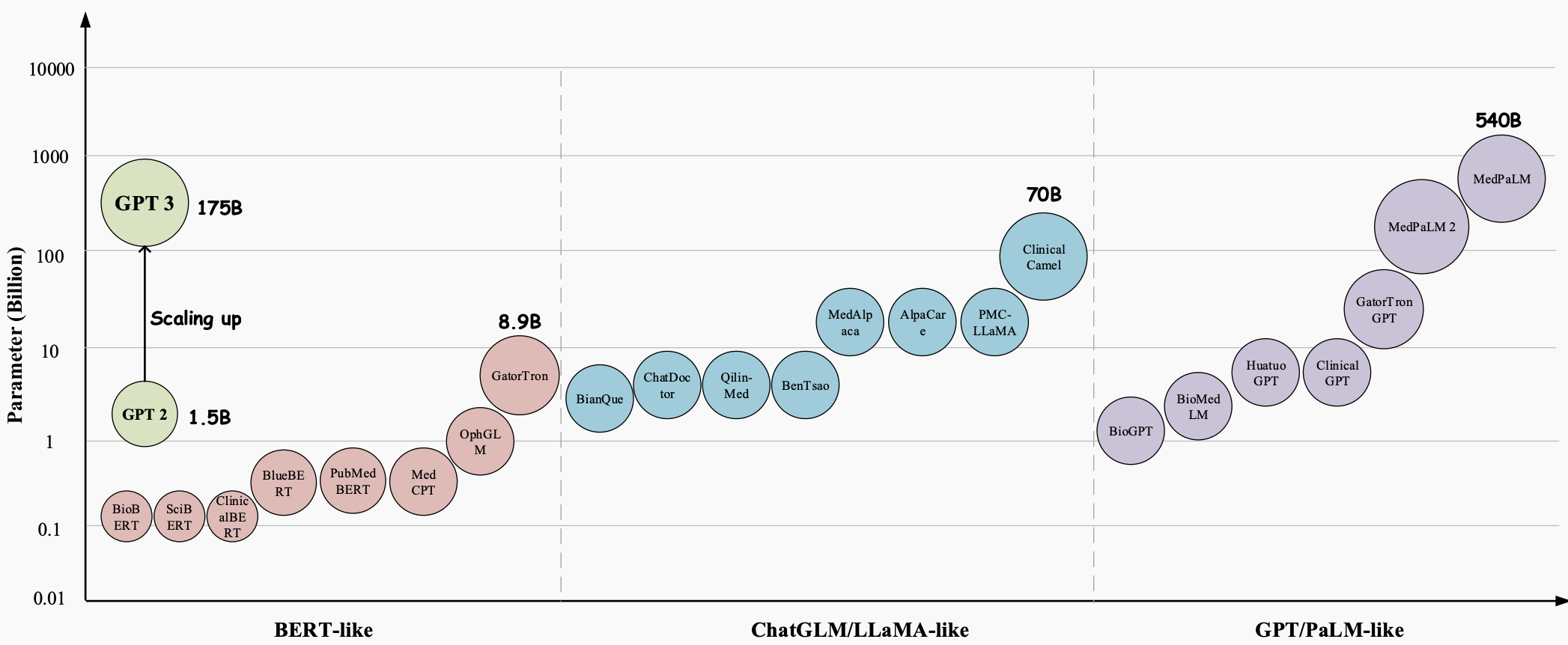
Ao longo dos anos, os Large Language Models (LLMs) evoluíram para uma tecnologia inovadora com enorme potencial para revolucionar todos os aspectos do setor de saúde. Esses modelos, como GPT-3 , GPT-4 e Med-PaLM 2 , demonstraram capacidades superiores na compreensão e geração de texto semelhante ao humano, tornando-os ferramentas valiosas para lidar com tarefas médicas complexas e melhorar o atendimento ao paciente. Eles se mostram muito promissores em uma variedade de aplicações médicas, como resposta a perguntas médicas (QA), sistemas de diálogo e geração de texto. Além disso, com o crescimento exponencial dos registros eletrônicos de saúde (EHRs), da literatura médica e dos dados gerados pelos pacientes, os LLMs podem ajudar os profissionais médicos a extrair informações valiosas e a tomar decisões informadas.
No entanto, apesar do enorme potencial dos grandes modelos de linguagem (LLMs) na área médica, ainda existem alguns desafios importantes e específicos que precisam de ser resolvidos.
Quando o modelo é utilizado no contexto de conversas de entretenimento, o impacto dos erros é mínimo, porém, este não é o caso quando utilizado na área médica, onde interpretações e respostas incorretas podem ter consequências graves no atendimento e nos resultados do paciente; A precisão e a confiabilidade das informações fornecidas pelos modelos de linguagem podem ser uma questão de vida ou morte, pois podem impactar decisões médicas, diagnósticos e planos de tratamento.
Por exemplo, quando o GPT-3 foi questionado sobre quais medicamentos as mulheres grávidas poderiam usar, o GPT-3 recomendou incorretamente a tetraciclina, embora também afirmasse corretamente que a tetraciclina é prejudicial ao feto e não deve ser usada por mulheres grávidas. Se você realmente seguir este conselho errado e dar remédios a mulheres grávidas, isso poderá fazer com que os ossos da criança cresçam mal no futuro.

Para fazer bom uso de modelos de linguagem tão amplos na área médica, esses modelos devem ser projetados e avaliados de acordo com as características da indústria médica. Como os dados e aplicativos médicos possuem características especiais próprias, elas devem ser levadas em consideração. E é realmente importante desenvolver métodos para avaliar estes modelos para uso médico, não apenas para investigação, mas porque podem representar riscos se utilizados incorretamente no trabalho médico no mundo real.
O Open Source Medical Large Model Ranking visa enfrentar esses desafios e limitações, fornecendo uma plataforma padronizada para avaliar e comparar o desempenho de vários modelos de linguagem grande em uma variedade de tarefas médicas e conjuntos de dados. Ao fornecer uma avaliação abrangente do conhecimento médico e da capacidade de resposta a perguntas de cada modelo, a classificação promove o desenvolvimento de modelos médicos mais eficazes e confiáveis.
Esta plataforma permite que pesquisadores e profissionais identifiquem os pontos fortes e fracos de diferentes abordagens, impulsionem o desenvolvimento adicional na área e, em última análise, ajudem a melhorar os resultados dos pacientes.
Conjuntos de dados, tarefas e configurações de avaliação
O Medical Large Model Ranking contém uma variedade de tarefas e usa a precisão como sua principal métrica de avaliação (a precisão mede a porcentagem de respostas corretas fornecidas pelo modelo de linguagem em vários conjuntos de dados de perguntas e respostas médicas).
MedQA
O conjunto de dados MedQA contém questões de múltipla escolha do Exame de Licenciamento Médico dos Estados Unidos (USMLE). Abrange uma ampla gama de conhecimentos médicos e inclui 11.450 questões de conjuntos de treinamento e 1.273 questões de conjuntos de testes. Com 4 ou 5 opções de resposta por pergunta, este conjunto de dados foi projetado para avaliar o conhecimento médico e as habilidades de raciocínio necessárias para obter uma licença médica nos Estados Unidos.

MedMCQA
MedMCQA é um conjunto de dados de perguntas e respostas de múltipla escolha em grande escala derivado do Indian Medical Entrance Examination (AIIMS/NEET). Abrange 2.400 tópicos da área médica e 21 disciplinas médicas, com mais de 187.000 perguntas no conjunto de treinamento e 6.100 perguntas no conjunto de testes. Cada pergunta tem 4 opções de resposta com explicações. MedMCQA avalia o conhecimento médico geral e as habilidades de raciocínio de um modelo.

PubMedQA
PubMedQA é um conjunto de dados de resposta a perguntas de domínio fechado onde cada pergunta pode ser respondida observando o contexto relevante (resumo do PubMub). Ele contém 1.000 pares de perguntas e respostas rotulados por especialistas. Cada pergunta é acompanhada por um resumo do PubMed para contextualizar, e a tarefa é fornecer uma resposta sim/não/talvez com base nas informações do resumo. O conjunto de dados é dividido em 500 questões de treinamento e 500 questões de teste. PubMedQA avalia a capacidade de um modelo de compreender e raciocinar sobre a literatura biomédica científica.

Subconjunto MMLU (medicina e biologia)
O benchmark MMLU (Measuring Large-Scale Multi-Task Language Understanding) contém questões de múltipla escolha de vários domínios. Para as classificações de grandes modelos médicos de código aberto, nos concentramos no subconjunto mais relevante para o conhecimento médico:
- Conhecimento clínico: 265 questões que avaliam o conhecimento clínico e as habilidades de tomada de decisão.
- Genética Médica: 100 questões abordando temas relacionados à genética médica.
- Anatomia: 135 questões que avaliam o conhecimento da anatomia humana.
- Medicina Profissional: 272 questões que avaliam o conhecimento exigido do profissional médico.
- Biologia universitária: 144 questões cobrindo conceitos de biologia de nível universitário.
- Medicina universitária: 173 questões que avaliam o conhecimento médico de nível universitário. Cada subconjunto MMLU contém questões de múltipla escolha com 4 opções de resposta projetadas para avaliar a compreensão do modelo de um domínio médico e biológico específico.

As classificações de grandes modelos médicos de código aberto fornecem uma avaliação robusta do desempenho do modelo em vários aspectos do conhecimento e raciocínio médico.
Insights e análises
O Open Source Medical Large Model Ranking avalia o desempenho de vários modelos de linguagem grande (LLMs) em uma série de tarefas de resposta a perguntas médicas. Aqui estão algumas de nossas principais descobertas:
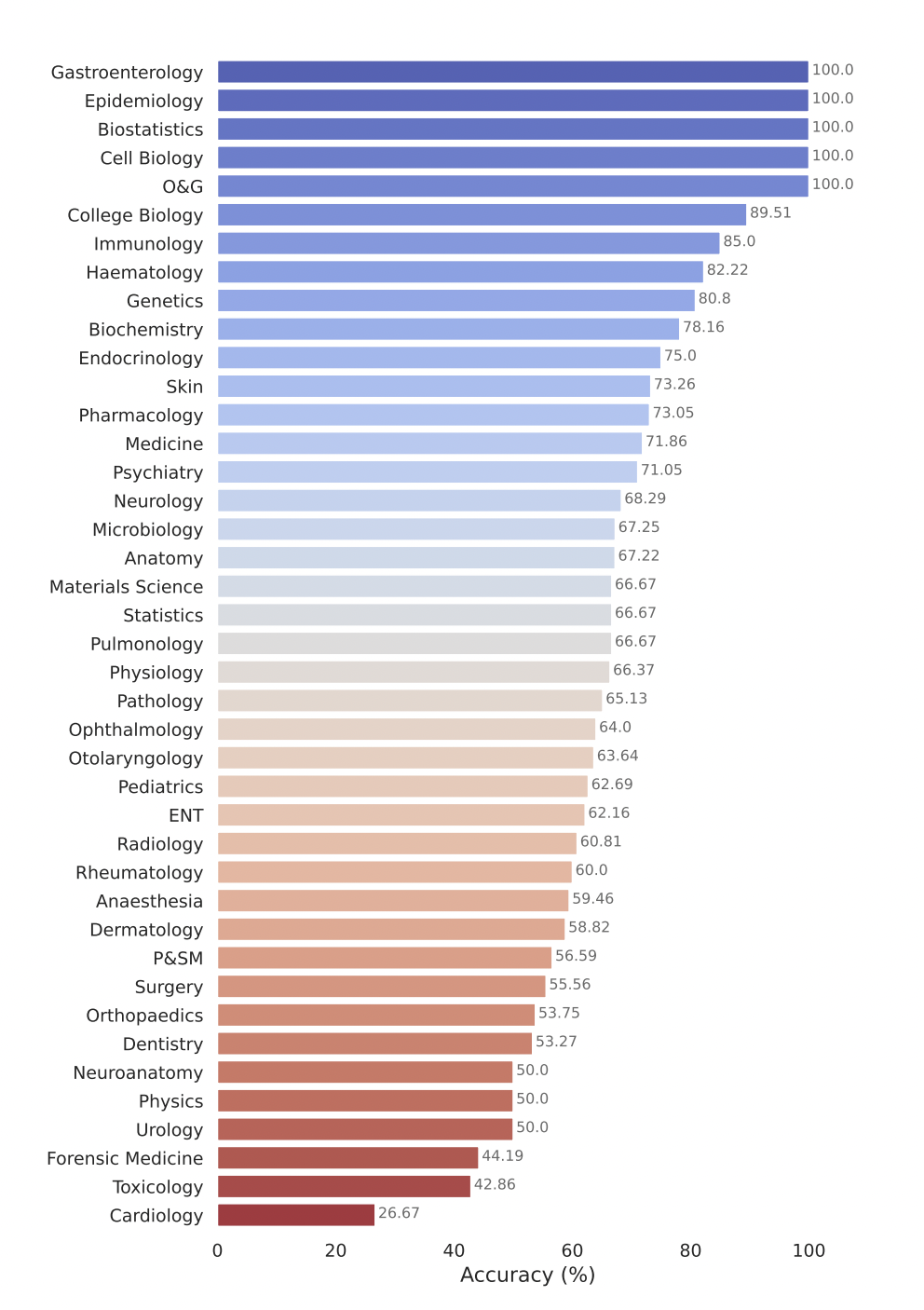
- Modelos comerciais como GPT-4-base e Med-PaLM-2 alcançam consistentemente pontuações de alta precisão em vários conjuntos de dados médicos, demonstrando forte desempenho em diferentes áreas médicas.
- Modelos de código aberto, como Starling-LM-7B , gemma-7b , Mistral-7B-v0.1 e Hermes-2-Pro-Mistral-7B , embora o número de parâmetros seja de apenas cerca de 7 bilhões, apresentam bom desempenho em determinados dados conjuntos e tarefas entregaram desempenho competitivo.
- Os modelos comerciais e de código aberto apresentam bom desempenho em tarefas como compreensão e raciocínio sobre a literatura biomédica científica (PubMedQA) e aplicação de conhecimento clínico e habilidades de tomada de decisão (subconjunto de conhecimento clínico MMLU).

O modelo Gemini Pro do Google demonstrou forte desempenho em vários campos médicos, especialmente em tarefas processuais e com uso intensivo de dados, como bioestatística, biologia celular e obstetrícia e ginecologia. No entanto, apresentou desempenho moderado a baixo em áreas-chave como anatomia, cardiologia e dermatologia, revelando lacunas que requerem melhorias adicionais para aplicação em uma medicina mais abrangente.
Envie seu modelo para avaliação
Para enviar seu modelo para avaliação no Open Source Healthcare Large Model Ranking, siga estas etapas:
1. Converta os pesos do modelo para o formato Safetensors
Primeiro, converta os pesos do seu modelo para o formato de tensores seguros. Os Safetensors são um novo formato de armazenamento de pesos, mais seguro e rápido de carregar e usar. A conversão do seu modelo para este formato também permitirá que o placar exiba o número de parâmetros do seu modelo na tabela principal.
2. Garanta a compatibilidade com AutoClasses
Antes de enviar o modelo, certifique-se de carregar o modelo e o tokenizer usando AutoClasses na biblioteca Transformers. Use o seguinte trecho de código para testar a compatibilidade:
from transformers import AutoConfig, AutoModel, AutoTokenizer
config = AutoConfig.from_pretrained(MODEL_HUB_ID)
model = AutoModel.from_pretrained("your model name")
tokenizer = AutoTokenizer.from_pretrained("your model name")
Se você falhar nesta etapa, siga a mensagem de erro para depurar seu modelo antes de enviar. Muito provavelmente o seu modelo foi carregado incorretamente.
3. Torne seu modelo público
Certifique-se de que seu modelo seja acessível publicamente. As tabelas de classificação não podem avaliar modelos privados ou modelos que requeiram acesso especial.
4. Execução remota de código (em breve)
Atualmente, as classificações de grandes modelos médicos de código aberto não suportam os use_remote_code=Truemodelos necessários. No entanto, a equipe da tabela de classificação está adicionando ativamente esse recurso, portanto, fique atento às atualizações.
5. Envie seu modelo através do site do placar
Depois que seu modelo for convertido para o formato safetensors, compatível com AutoClasses e acessível ao público, você poderá avaliá-lo usando o painel Enviar aqui no site Open Source Medical Large Model Ranking. Preencha as informações necessárias, como nome do modelo, descrição e quaisquer detalhes adicionais, e clique no botão Enviar. A equipe da tabela de classificação processará seu envio e avaliará o desempenho do seu modelo em vários conjuntos de dados médicos de perguntas e respostas. Assim que a avaliação for concluída, a pontuação do seu modelo será adicionada ao placar e você poderá comparar seu desempenho com outros modelos.
Qual é o próximo? Classificações expandidas de grandes modelos médicos de código aberto
O Open Source Healthcare Large Model Ranking está comprometido em se expandir e se adaptar para atender às novas necessidades da comunidade de pesquisa e do setor de saúde. As principais áreas incluem:
- Incorpore conjuntos de dados de saúde mais amplos, abrangendo todos os aspectos dos cuidados, como radiologia, patologia e genômica, por meio da colaboração com pesquisadores, organizações de saúde e parceiros da indústria.
- Aprimore as métricas de avaliação e os recursos de relatórios explorando medidas de desempenho adicionais além da precisão, como pontuações ponto a ponto e métricas específicas de domínio que capturam as necessidades exclusivas das aplicações médicas.
- Já há algum trabalho em andamento nesse sentido. Se você estiver interessado em colaborar no próximo benchmark que planejamos propor, junte-se à nossa comunidade Discord para saber mais e se envolver. Adoraríamos colaborar e debater!
Se você é apaixonado pela interseção entre IA e saúde, pela construção de modelos para a saúde e se preocupa com as questões de segurança e alucinação de grandes modelos médicos, convidamos você a se juntar à nossa comunidade ativa no Discord .
Agradecimentos

Agradecimentos especiais a todos que ajudaram a tornar isso possível, incluindo Clémentine Fourrier e a equipe Hugging Face. Gostaria de agradecer a Andreas Motzfeldt, Aryo Gema e Logesh Kumar Umapathi pelas discussões e feedback durante o desenvolvimento da tabela de classificação. Gostaríamos de expressar nossos sinceros agradecimentos ao Professor Pasquale Minervini, da Universidade de Edimburgo, por seu tempo, assistência técnica e suporte de GPU.
Sobre IA de Ciências da Vida Abertas
Open Life Sciences AI é um projeto que visa revolucionar a aplicação da inteligência artificial nas ciências da vida e nas áreas médicas. Ele serve como um hub central que lista modelos médicos, conjuntos de dados, benchmarks e rastreia prazos de conferências, promovendo colaboração, inovação e avanço no campo da saúde assistida por IA. Nós nos esforçamos para estabelecer a Open Life Sciences AI como o principal destino para qualquer pessoa interessada na interseção entre IA e saúde. Fornecemos uma plataforma para investigadores, médicos, decisores políticos e especialistas da indústria dialogarem, partilharem ideias e explorarem os mais recentes desenvolvimentos na área.

Citar
Se você achar nossa avaliação útil, considere citar nosso trabalho
Classificações de grandes modelos médicos
@misc{Medical-LLM Leaderboard,
author = {Ankit Pal, Pasquale Minervini, Andreas Geert Motzfeldt, Aryo Pradipta Gema and Beatrice Alex},
title = {openlifescienceai/open_medical_llm_leaderboard},
year = {2024},
publisher = {Hugging Face},
howpublished = "\url{https://huggingface.co/spaces/openlifescienceai/open_medical_llm_leaderboard}"
}
> Texto original em inglês: https://hf.co/blog/leaderboard-medicalllm > Autor original: Aaditya Ura (em busca de doutorado), Pasquale Minervini, Clémentine Fourrier > Tradutor: inovação64
Um programador nascido na década de 1990 desenvolveu um software de portabilidade de vídeo e faturou mais de 7 milhões em menos de um ano. O final foi muito punitivo! Alunos do ensino médio criam sua própria linguagem de programação de código aberto como uma cerimônia de maioridade - comentários contundentes de internautas: Contando com RustDesk devido a fraude desenfreada, serviço doméstico Taobao (taobao.com) suspendeu serviços domésticos e reiniciou o trabalho de otimização de versão web Java 17 é a versão Java LTS mais comumente usada no mercado do Windows 10 Atingindo 70%, o Windows 11 continua a diminuir Open Source Daily | Google apoia Hongmeng para assumir o controle de telefones Android de código aberto apoiados pela ansiedade e ambição da Microsoft; Electric desliga a plataforma aberta Apple lança chip M4 Google exclui kernel universal do Android (ACK) Suporte para arquitetura RISC-V Yunfeng renunciou ao Alibaba e planeja produzir jogos independentes na plataforma Windows no futuro