Grandes modelos de linguagem têm sido usados em muitos campos, e suas aplicações incluem escrita inteligente, criação musical, questionário de conhecimento, bate-papo, atendimento ao cliente, redação publicitária, jornais, notícias, redação de romances, polimento, resumos de conferências/artigos, etc. Nos negócios, o modelo é o produto, o serviço é o produto e o plug-in é o produto. Qualquer forma de produto acessível ao usuário pode ser produto. Os pagamentos comerciais geralmente são baseados em associação ou pagamento por uso. A estrutura central do atual modelo de grande profecia é baseada no Transformer.
Uma das razões mais importantes pelas quais o efeito do modelo grande excede as expectativas é que o modelo sofrerá mudanças qualitativas depois de atingir um determinado nível, e a memória e a generalização do modelo podem ser combinadas. O transformador pode tornar o modelo muito grande, tão grande que o modelo na área de PNL pode sofrer mudanças qualitativas, o que permite o surgimento de aplicações em diversas áreas, mas ainda existem alguns problemas que precisam ser resolvidos. Este tipo de modelo grande é essencialmente geração de conteúdo. O conteúdo está em conformidade com os três princípios a seguir:
útil (Útil);
credível (Honesto);
inofensivo (Inofensivo)
O grande modelo de previsão (também conhecido como modelo de pré-treinamento) baseado na estrutura do Transformer por si só não é suficiente para atender totalmente aos requisitos das aplicações comerciais. O desenvolvimento da indústria será desdobrado em um blog de acompanhamento. Este artigo falará primeiro sobre o Transformer, a arquitetura central do modelo de grande linguagem.
O Transformer originou-se da proposta do Google Brain para tarefas de tradução automática em 2017. O artigo "Atenção é tudo que você precisa" explicava detalhadamente a estrutura da rede. Antes disso, a estrutura da rede usava principalmente RNN, CNN, LSTM, GRU e outras formas de rede. Isso o artigo propõe que uma nova estrutura central-transformador seja redesenhada para a fraqueza da rede RNN na tradução automática.No processo de modelagem da arquitetura codificadora-decodificadora tradicional, o processo de cálculo no momento seguinte dependerá da saída no momento anterior. , e esta propriedade inerente restringe o modelo tradicional de codificador-decodificador de ser capaz de realizar cálculos em paralelo.
O código-fonte deste artigo foi hospedado no endereço do link do github
Introdução à estrutura do modelo
O Transformer proposto pelo Google também inclui duas partes: codificador e decodificador, mas o núcleo dessas duas partes é a estrutura de atenção, não CNN, LSTM, GRU e outras estruturas.
Para o codificador, ele contém duas camadas, uma camada de autoatenção e uma rede neural feed-forward.A autoatenção pode ajudar o nó atual não apenas a se concentrar na palavra atual, mas também a obter a semântica do contexto. O decodificador também inclui a rede de duas camadas mencionada pelo codificador, mas há uma camada de atenção entre as duas camadas para ajudar o nó atual a obter o conteúdo principal que precisa ser prestado atenção no momento.
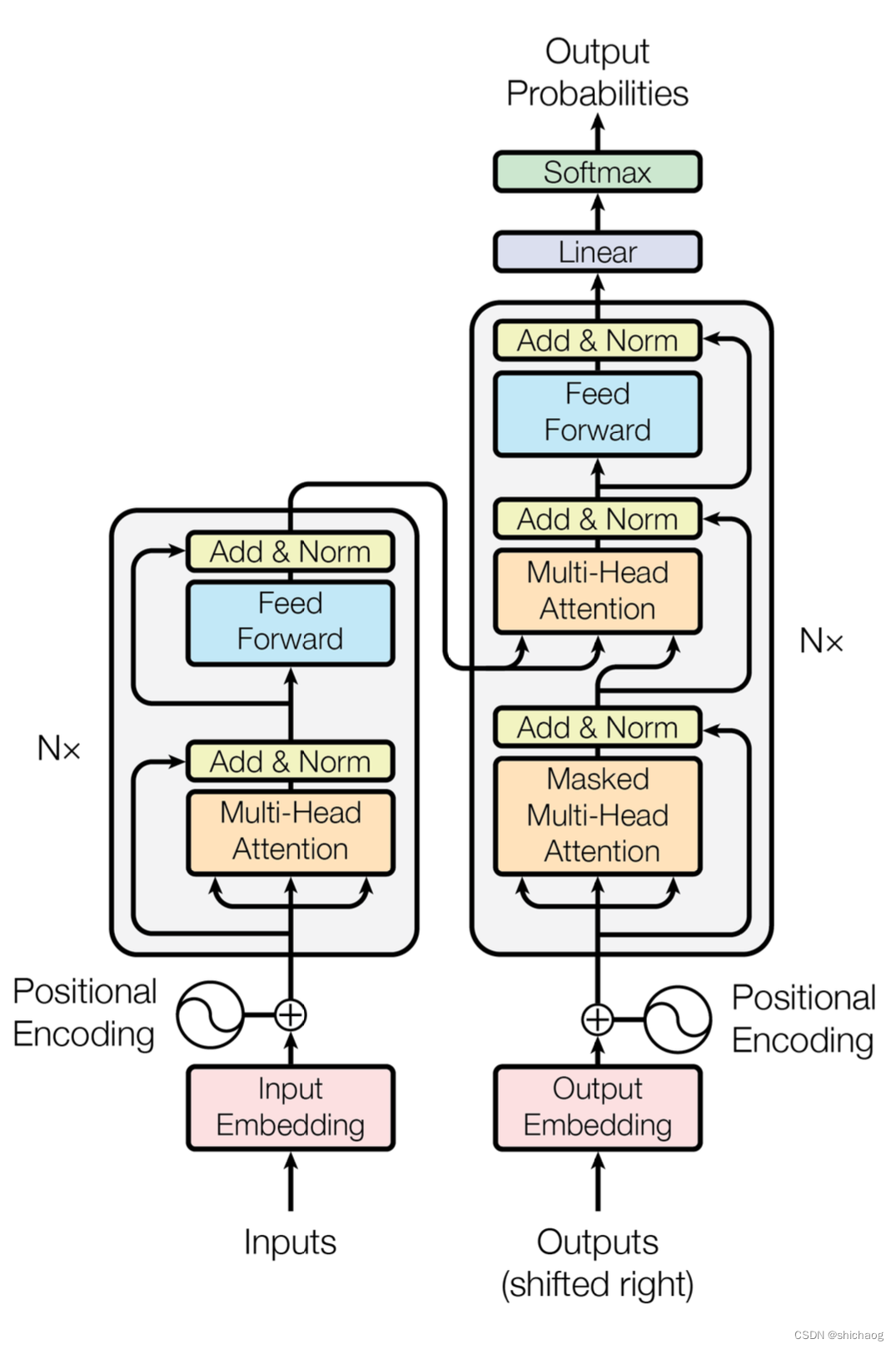
O modelo de arquitetura do modelo Transformer
precisa realizar uma operação de incorporação nos dados de entrada (a caixa vermelha na figura).Embora a atenção possa extrair as informações de interesse, ela não possui informações de tempo, e a codificação de posição é realizada convertendo informações de tempo em posição informações. Após a conclusão da incorporação, o código de posição é adicionado e, em seguida, inserido na camada do codificador. Depois que a autoatenção processa os dados, os dados são enviados para a rede neural feed-forward (Feed Forward azul). O cálculo da rede neural feed-forward pode ser paralelizada e a saída obtida será a entrada para o próximo codificador.
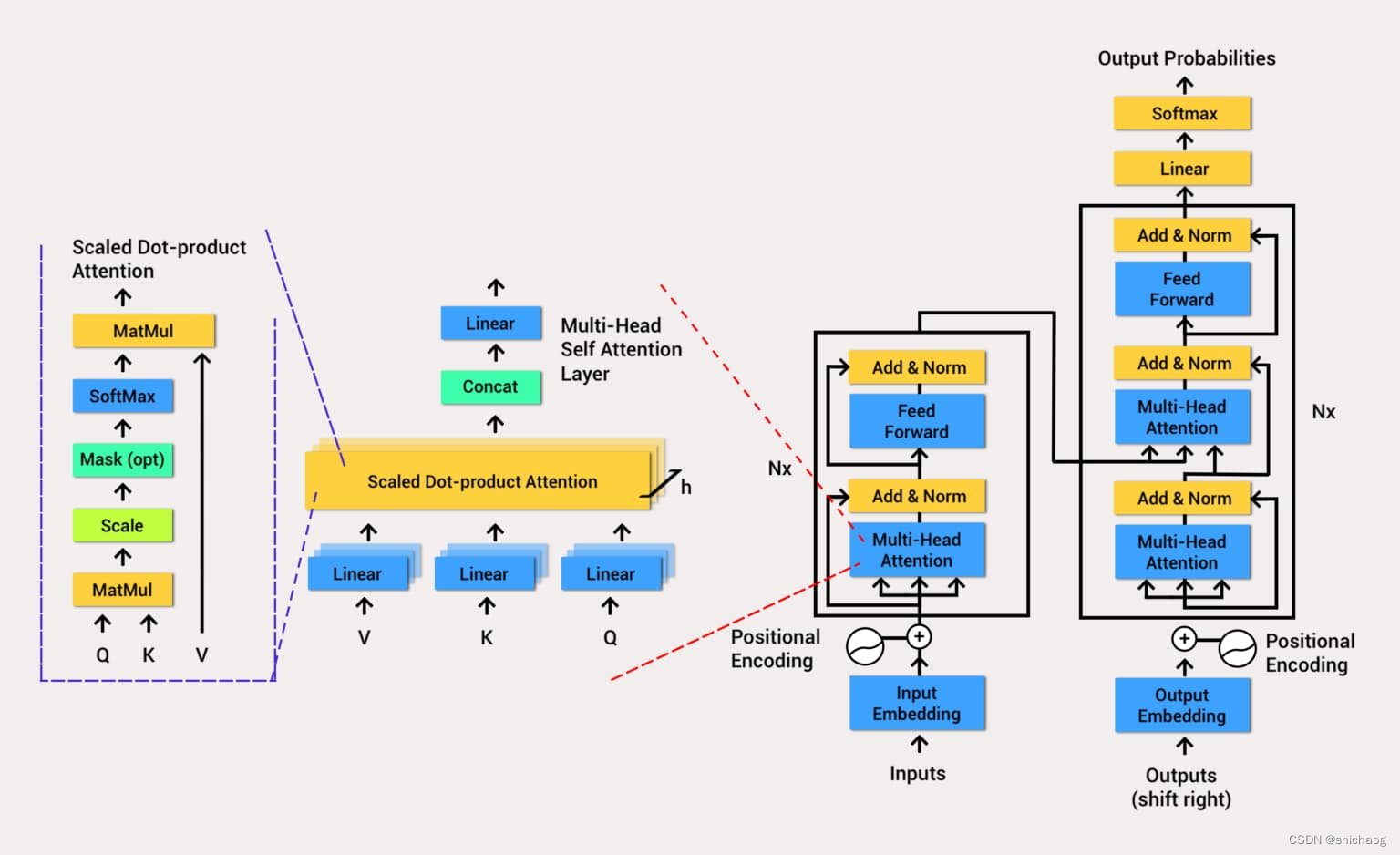
- Codificador codificador
- Atenção Multi-Cabeça
- O mecanismo de autoatenção multi-head pode calcular o valor-chave da consulta (Query-Key-Value) em paralelo, inserindo informações, para que a rede subsequente possa usar o contexto para saber quais informações precisam receber atenção no operação atual. Observe que a matriz para cálculo do QKV aqui também faz parte dos parâmetros da rede, e o treinamento pode tornar a atenção da rede mais eficaz e focada. Como o campo da PNL é causal em séries temporais, o modelo aprimorado usa um modelo causal de autoatenção com múltiplas cabeças.
- Adicionar conexão residual
- O principal papel da conexão residual principal aqui é usar mapeamento de identidade para treinar redes mais profundas (identidade de entrada e saída), atenção multi-head e normalização de camada, rede neural feedforward e normalização de camada, ambas as partes usam conexões residuais.
- Normalização da camada normativa
- A função da Normalização de Camada é normalizar a rede neural com a dimensão da amostra como camada, de forma a acelerar a velocidade de treinamento e acelerar a convergência. As novas melhorias colocam a Normalização de Camada na frente e não atrás.
- Feed Forward Rede Neural Feedforward
- Após passar pela camada de atenção, a informação de atenção extraída pelo mecanismo de ponderação é convertida no espaço semântico de acordo com a informação de atenção.
- Portanto, o MLP reprojeta o vetor obtido pela Atenção Multi-Head em um espaço maior (no papel, o espaço é ampliado em 4 vezes).Nesse espaço grande, é mais conveniente extrair as informações necessárias (usando a função de ativação Relu ) e, finalmente, Projete de volta ao espaço original do vetor de token.
- Atenção Multi-Cabeça
- Decodificador
- Basicamente igual ao Encoder, a composição é dividida em Masked Multi-Head Attention, Masked Encoder-Decoder Attention (esta camada é a camada de atenção que conecta o codificador e o decodificador, e como o GPT usa apenas o codificador, esta camada é excluída. .) E na rede neural Feed Forward, cada uma das três partes possui uma conexão residual, seguida de uma Normalização de Camada. O seguinte descreve a autoatenção mascarada do decodificador e a atenção do codificador-decodificador em duas partes,
- Atenção mascarada de múltiplas cabeças
- Há um problema com o mecanismo de autoatenção. Os dados rotulados completos durante o processo de treinamento serão expostos ao decodificador. Isso está obviamente errado. Precisamos realizar algum processamento na entrada do decodificador. Esse processamento é chamado de máscara, e os dados são expostos seletivamente ao Decodificador (em GPT equivale a cobrir todos os dados por trás, que são gerados sequencialmente pela rede).
- Atenção Multi-Cabeça
- Adicionar conexão residual
- Normalização da camada normativa
- Feed Forward Rede Neural Feedforward
- A camada linear e o Softmax
passam pelo codificador e decodificador e, finalmente, uma camada de camadas totalmente conectadas e SoftMax (o modelo de linguagem grande aprimorado posteriormente usa a função Unidades Lineares de Erro Gaussiano). A camada linear é uma rede neural simples e totalmente conectada que projeta os vetores produzidos pela pilha de decodificadores em um vetor maior chamado vetor logits. Uma camada Softmax (Softmax é uma função de ativação para problemas de classificação multiclasse) converte vetores em probabilidades (todos positivos e soma 1,0). A unidade com maior probabilidade é selecionada e a palavra associada a ela é gerada como saída para este intervalo de tempo.
Implementação do modelo Pytorch
A parte vermelha é a incorporação de entrada e saída.
class Embedder(nn.Module):
def __init__(self, vocab_size, d_model):
super().__init__()
self.embed = nn.Embedding(vocab_size, d_model)
def forward(self, x):
#[123, 0, 23, 5] -> [[..512..], [...512...], ...]
return self.embed(x)
Código de localização
Conforme mostrado no código a seguir, seu valor será adicionado à incorporação acima e então inserido no módulo codec.
class PositionalEncoder(nn.Module):
def __init__(self, d_model: int, max_seq_len: int = 80):
super().__init__()
self.d_model = d_model
#Create constant positional encoding matrix
pos_matrix = torch.zeros(max_seq_len, d_model)
# for pos in range(max_seq_len):
# for i in range(0, d_model, 2):
# pe_matrix[pos, i] = math.sin(pos/1000**(2*i/d_model))
# pe_matrix[pos, i+1] = math.cos(pos/1000**(2*i/d_model))
#
# pos_matrix = pe_matrix.unsqueeze(0) # Add one dimension for batch size
den = torch.exp(-torch.arange(0, d_model, 2) * math.log(1000) / d_model)
pos = torch.arange(0, max_seq_len).reshape(max_seq_len, 1)
pos_matrix[:, 1::2] = torch.cos(pos * den)
pos_matrix[:, 0::2] = torch.sin(pos * den)
pos_matrix = pos_matrix.unsqueeze(0)
self.register_buffer('pe', pos_matrix) #Register as persistent buffer
def forward(self, x):
# x is a sentence after embedding with dim (batch, number of words, vector dimension)
seq_len = x.size()[1]
x = x + self.pe[:, :seq_len]
return x
autoatenção
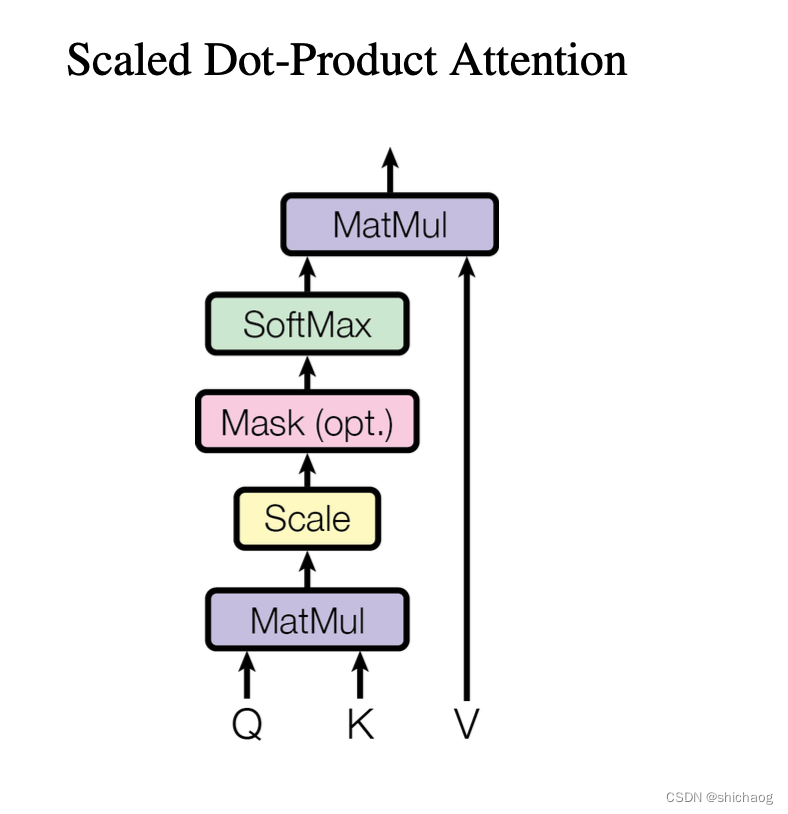
## Scaled Dot-Product Attention layer
def scaled_dot_product_attention(q, k, v, mask=None, dropout=None):
# Shape of q and k are the same, both are (batch_size, seq_len, d_k)
# Shape of v is (batch_size, seq_len, d_v)
attention_scores = torch.matmul(q, k.transpose(-2, -1)) / math.sqrt(q.shape[-1]) # size (bath_size, seq_len, d_k)
# Apply mask to scores
# <pad>
if mask is not None:
attention_scores = attention_scores.masked_fill(mask == 0, value=-1e9)
# Softmax along the last dimension
attention_weights = F.softmax(attention_scores, dim=-1)
if dropout is not None:
attention_weights = dropout(attention_weights)
output = torch.matmul(attention_weights, v)
return output
Camada de atenção de múltiplas cabeças
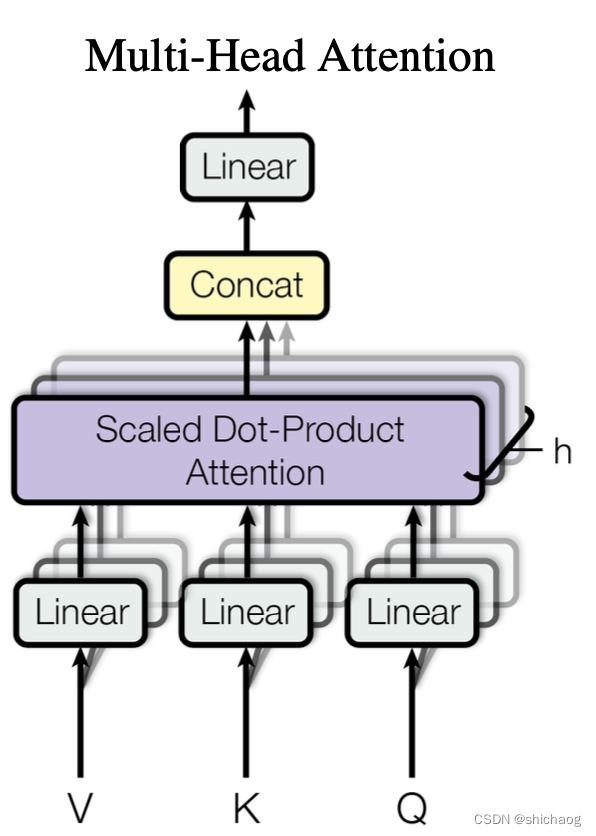
# Multi-Head Attention layer
class MultiHeadAttention(nn.Module):
def __init__(self, n_heads, d_model, dropout=0.1):
super().__init__()
self.n_heads = n_heads
self.d_model = d_model
self.d_k = self.d_v = d_model // n_heads
# self attention linear layers
#Linear layers for q, k, v vectors generation in different heads
self.q_linear_layers = []
self.k_linear_layers = []
self.v_linear_layers = []
for i in range(n_heads):
self.q_linear_layers.append(nn.Linear(d_model, self.d_k))
self.k_linear_layers.append(nn.Linear(d_model, self.d_k))
self.v_linear_layers.append(nn.Linear(d_model, self.d_v))
self.dropout = nn.Dropout(dropout)
self.out = nn.Linear(n_heads*self.d_v, d_model)
def forward(self, q, k, v, mask=None):
multi_head_attention_outputs = []
for q_linear, k_linear, v_linear in zip(self.q_linear_layers,
self.k_linear_layers,
self.v_linear_layers):
new_q = q_linear(q) # size: (batch_size, seq_len, d_k)
new_k = q_linear(k) # size: (batch_size, seq_len, d_k)
new_v = q_linear(v) # size: (batch_size, seq_len, d_v)
# Scaled Dot-Product attention
head_v = scaled_dot_product_attention(new_q, new_k, new_v, mask, self.dropout) # (batch_size, seq_len,
multi_head_attention_outputs.append(head_v)
# Concat
# import pdb; pdb.set_trace()
concat = torch.cat(multi_head_attention_outputs, -1) # (batch_size, seq_len, n_heads*d_v)
# Linear layer to recover to original shap
output = self.out(concat) # (batch_size, seq_len, d_model)
return output
exemplo de tradução
O link do github aqui
mostra a estrutura e o uso do modelo de rede descrito no artigo do Transformer com um exemplo de tradução do inglês para o francês. As informações da versão de instalação do Python são as seguintes:
Python 3.7.16
torch==2.0.1
torchdata==0.6.1
torchtext==0.15.2
spacy==3.6.0
numpy==1.25.2
pandas
times
portalocker==2.7.0
processamento de dados
Tokenização e mapeamento de palavras para números tensorizados
É mais conveniente usar as ferramentas fornecidas pelo torchtext para criar um conjunto de dados que seja conveniente para processar modelos iterativos de tradução de fala, começando com a segmentação de palavras do texto original, construindo um vocabulário e marcando-o como um tensor digital. Embora o torchtext forneça suporte básico à segmentação de palavras em inglês, a tradução aqui inclui francês além do inglês, portanto, a biblioteca python de segmentação de palavras Spacy é usada.
A primeira é criar o ambiente, e a próxima é baixar os tokenizers para inglês e francês, pois este é um exemplo muito pequeno, então use o modelo de processamento de linguagem espacial das notícias:
#python3 -m spacy download en_core_web_sm
#python3 -m spacy download fr_core_news_sm
Como mostrado abaixo:
A próxima etapa é segmentar os dados em palavras e, em seguida, mapear as palavras em números tensorizados
#Data processing
import spacy
from torchtext.data.utils import get_tokenizer
from collections import Counter
import io
from torchtext.vocab import vocab
src_data_path = 'data/english.txt'
trg_data_path = 'data/french.txt'
en_tokenizer = get_tokenizer('spacy', language='en_core_web_sm')
fr_tokenizer = get_tokenizer('spacy', language='fr_core_news_sm')
def build_vocab(filepath, tokenizer):
counter = Counter()
with io.open(filepath, encoding="utf8") as f:
for string_ in f:
counter.update(tokenizer(string_))
return vocab(counter, specials=['<unk>', '<pad>', '<bos>', '<eos>'])
en_vocab = build_vocab(src_data_path, en_tokenizer)
fr_vocab = build_vocab(trg_data_path, fr_tokenizer)
def data_process(src_path, trg_path):
raw_en_iter = iter(io.open(src_path, encoding="utf8"))
raw_fr_iter = iter(io.open(trg_path, encoding="utf8"))
data = []
for (raw_en, raw_fr) in zip (raw_en_iter, raw_fr_iter):
en_tensor_ = torch.tensor([en_vocab[token] for token in en_tokenizer(raw_en)], dtype=torch.long)
fr_tensor_ = torch.tensor([fr_vocab[token] for token in fr_tokenizer(raw_fr)], dtype= torch.long)
data.append((en_tensor_, fr_tensor_))
return data
train_data = data_process(src_data_path, trg_data_path)
Carregador de dados
DataLoader é um método fornecido por torch.utils.data que combina conjuntos de dados e amostradores para fornecer objetos iteráveis para um determinado conjunto de dados. DataLoader suporta carregamento de processo único ou multiprocesso, ordem de carregamento personalizada e lote automático opcional (mesclagem) e fixação de memória de conjuntos de dados mapeados e iteráveis.
collate_fn (opcional), que mescla listas de amostras para formar minilotes de tensores. Usado ao carregar em massa com conjuntos de dados em estilo de mapa.
#Train transformer
d_model= 512
n_heads = 8
N = 6
src_vocab_size = len(en_vocab.vocab)
trg_vocab_size = len(fr_vocab.vocab)
BATH_SIZE = 32
PAD_IDX = en_vocab['<pad>']
BOS_IDX = en_vocab['<bos>']
EOS_IDX = en_vocab['<eos>']
from torch.nn.utils.rnn import pad_sequence
from torch.utils.data import DataLoader
def generate_batch(data_batch):
en_batch, fr_batch = [], []
for (en_item, fr_item) in data_batch:
en_batch.append(torch.cat([torch.tensor([BOS_IDX]), en_item, torch.tensor([EOS_IDX])], dim=0))
fr_batch.append(torch.cat([torch.tensor([BOS_IDX]), fr_item, torch.tensor([EOS_IDX])], dim=0))
en_batch = pad_sequence(en_batch, padding_value=PAD_IDX)
fr_batch = pad_sequence(fr_batch, padding_value=PAD_IDX)
return en_batch, fr_batch
train_iter = DataLoader(train_data, batch_size=BATH_SIZE, shuffle=True, collate_fn=generate_batch)
O resultado do treinamento é o seguinte:
