Treine seu próprio Llama 2! Introdução à tecnologia de ajuste fino de modelos grandes

Nuvem de tendência
Trend Cloud é uma plataforma de desenvolvimento para engenheiros de algoritmos de IA, fornecendo aos engenheiros funções como desenvolvimento de modelo, treinamento de modelo, gerenciamento de dados e código.
Recentemente, muitos fãs perguntaram ao Hashforce, o Trend Cloud suporta o treinamento de modelos grandes? Claro apoio!
Assim que o recém-popular Llama 2 foi lançado, os amiguinhos em torno do poderoso cavalheiro da computação já haviam atropelado. Este artigo apresentará o Llama 2 e a tecnologia de ajuste fino de modelo em grande escala relacionada. A poderosa tecnologia de pooling de GPU da Trendcloud juntamente com o software relacionado é a primeira escolha para pesquisa e desenvolvimento de modelos grandes ~

Llama 2: Android na Era dos Grandes Modelos
Há alguns dias, o Meta open source Llama 2, que é conhecido como um grande evento na área de grandes modelos por causa de seu excelente desempenho e recursos de código aberto, que pode ser usado tanto em pesquisa quanto em negócios. Algumas pessoas pensam que é uma alternativa de código aberto para produtos como ChatGPT , e é chamado de Android no campo de modelos grandes.
-
Guia de uso: https://ai.meta.com/llama/
-
Código-fonte aberto: https://github.com/facebookresearch/llama
O Llama 2 é um conjunto de modelos de linguagem de grande escala (LLMs) pré-treinados e ajustados . É a segunda geração de modelos de linguagem de grande escala lançada pela Meta AI, com parâmetros que variam de 7 bilhões a 70 bilhões.
Além disso, o Llama 2-Chat é uma versão aprimorada do Llama 2 , otimizada para cenários de conversação. O modelo supera os modelos de diálogo de código aberto na maioria dos benchmarks, e o Llama 2 é muito bom do ponto de vista de utilidade e segurança, de acordo com os resultados da avaliação humana.
O modelo Llama 2 é treinado em 2 trilhões de tokens com o dobro do comprimento de contexto do Llama 1 . O modelo Llama-2-chat foi adicionalmente treinado em mais de 1 milhão de novos dados rotulados por humanos .
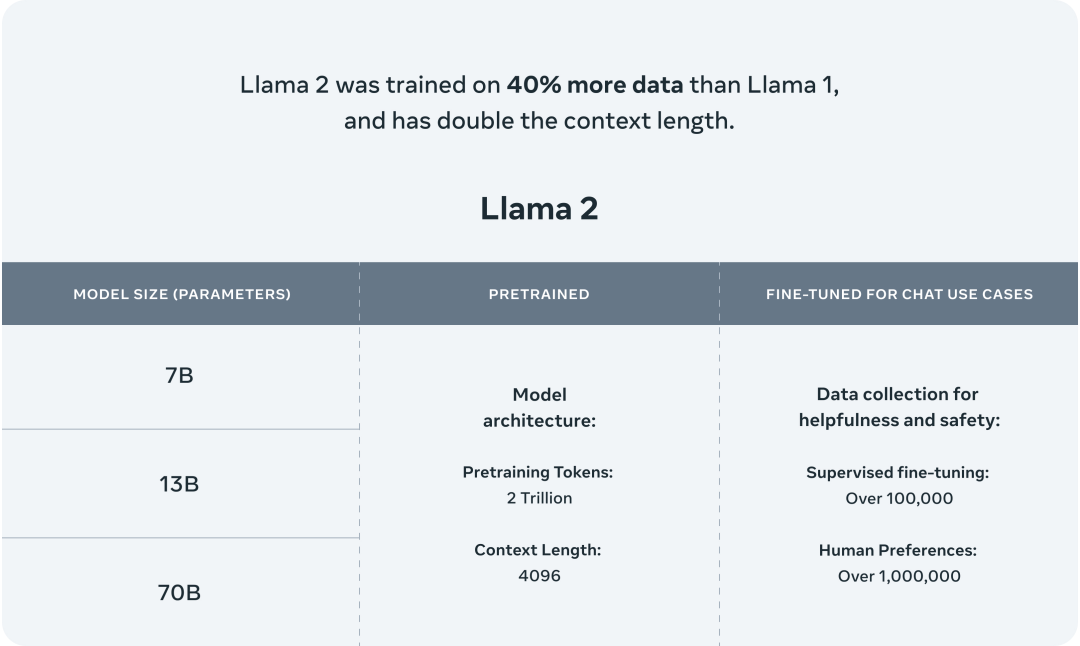
Apresentação do modelo Llama 2
O Llama 2 supera outros modelos de linguagem de código aberto em muitos benchmarks externos, incluindo inferência, codificação, proficiência e testes de conhecimento.
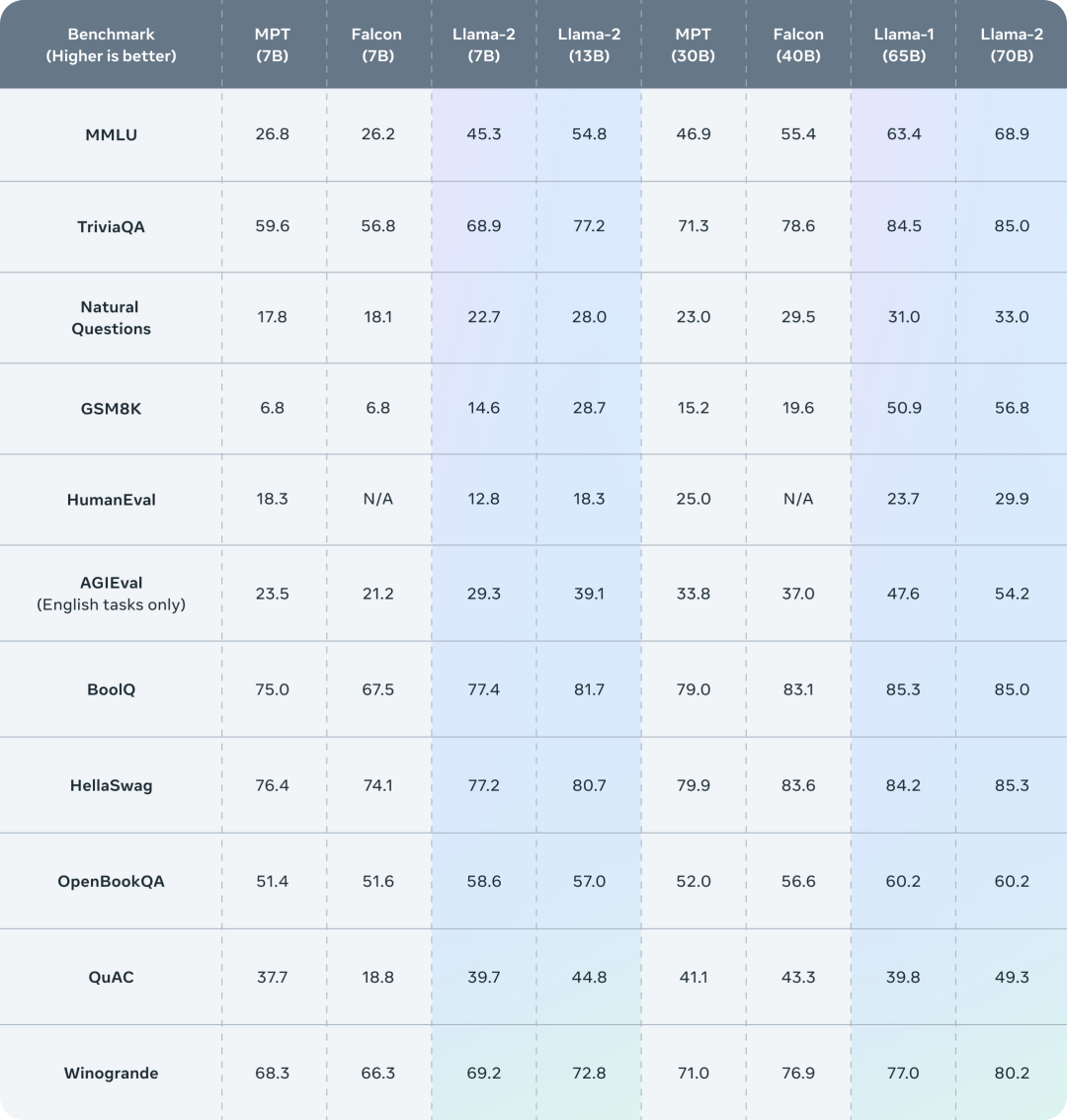
Desempenho do Llama 2 em benchmarks
Embora a Meta tenha reduzido bastante o limite para que as pessoas usem modelos grandes ao abrir o código do Llama 2, ainda não é fácil retreinar e ajustar o Llama 2 em conjuntos de dados personalizados. amigável O preço é a primeira escolha para pesquisar modelos grandes.
O autor de código aberto do Llama 2 fornece conselhos técnicos sobre o ajuste fino do modelo grande, vamos dar uma olhada.
Tecnologia de ajuste fino de modelo grande
Ajuste fino do modelo com eficiência de parâmetros
Representantes desse tipo de método são LORA (https://arxiv.org/pdf/2106.09685.pdf), LLaMA Adapter, Prefix-tuning, congelando todo o modelo durante o ajuste fino e adicionando um pequeno número de parâmetros ou redes que podem ser aprendidos para a camada de modelo, apenas esta parte é ajustada durante o treinamento.
Na verdade, esse método usa o modelo grande como uma ferramenta para extrair recursos. Como a grande quantidade de parâmetros do modelo em si não precisa ser ajustada, o custo de cálculo não é alto e pode até ser ajustado em um único placa gráfica de nível de consumidor.
Se seu cenário de uso para modelos grandes não estiver longe dos recursos existentes de modelos grandes já treinados, você deve tentar este método primeiro.
Os benefícios dessa estratégia de ajuste fino são óbvios:
1. O custo do ajuste fino é baixo, não há necessidade de enfrentar os desafios de cálculo e transmissão em grande escala e pode até rodar em placas gráficas de nível de consumidor;
2. O custo de implantação é baixo e os grandes modelos implantados podem ser reutilizados, não sendo necessário implantar vários modelos quando novos negócios surgem;
3. Evitar o esquecimento catastrófico, para que o modelo grande não perca sua capacidade de processar tarefas previamente treinadas porque aprendeu novas tarefas.
Os autores de código aberto do Llama 2 afirmam que usam a biblioteca PEFT para ajustar o modelo grande. Para a introdução e uso da biblioteca, consulte:
https://github.com/huggingface/peft
https://huggingface.co/blog/peft
Ajuste fino do modelo de todos ou alguns parâmetros
Ajustar todos ou parte dos parâmetros do próprio modelo também tem suas vantagens únicas, métodos comuns como:
1. Congele o backbone do modelo pré-treinado e ajuste apenas a camada de tarefas, como a parte do classificador;
2. Congele o backbone do modelo pré-treinado, adicione uma camada totalmente conectada e ajuste a nova peça;
3. Ajuste todas as camadas do modelo.
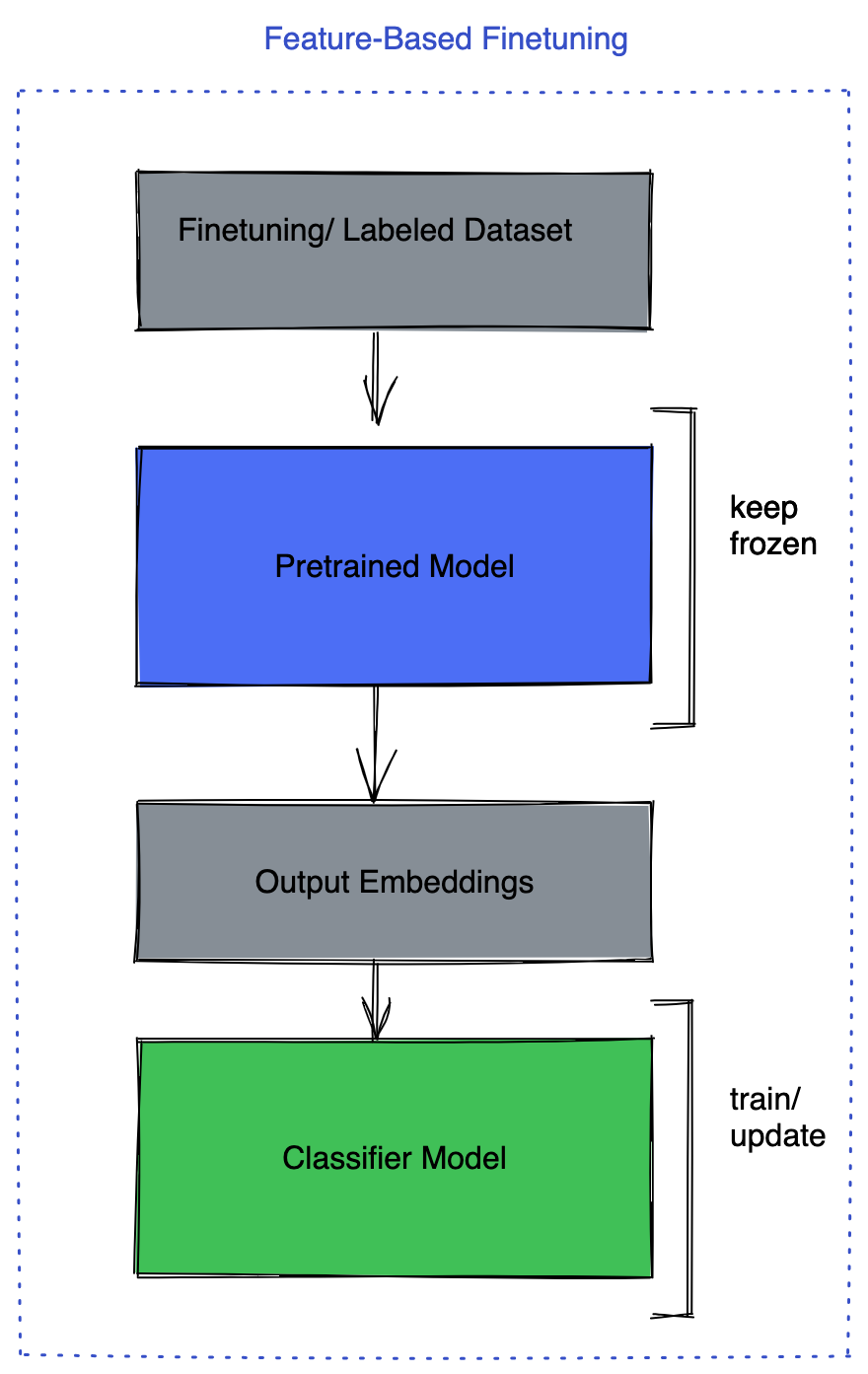
Ajustar camadas de tarefas
Ajuste a nova camada
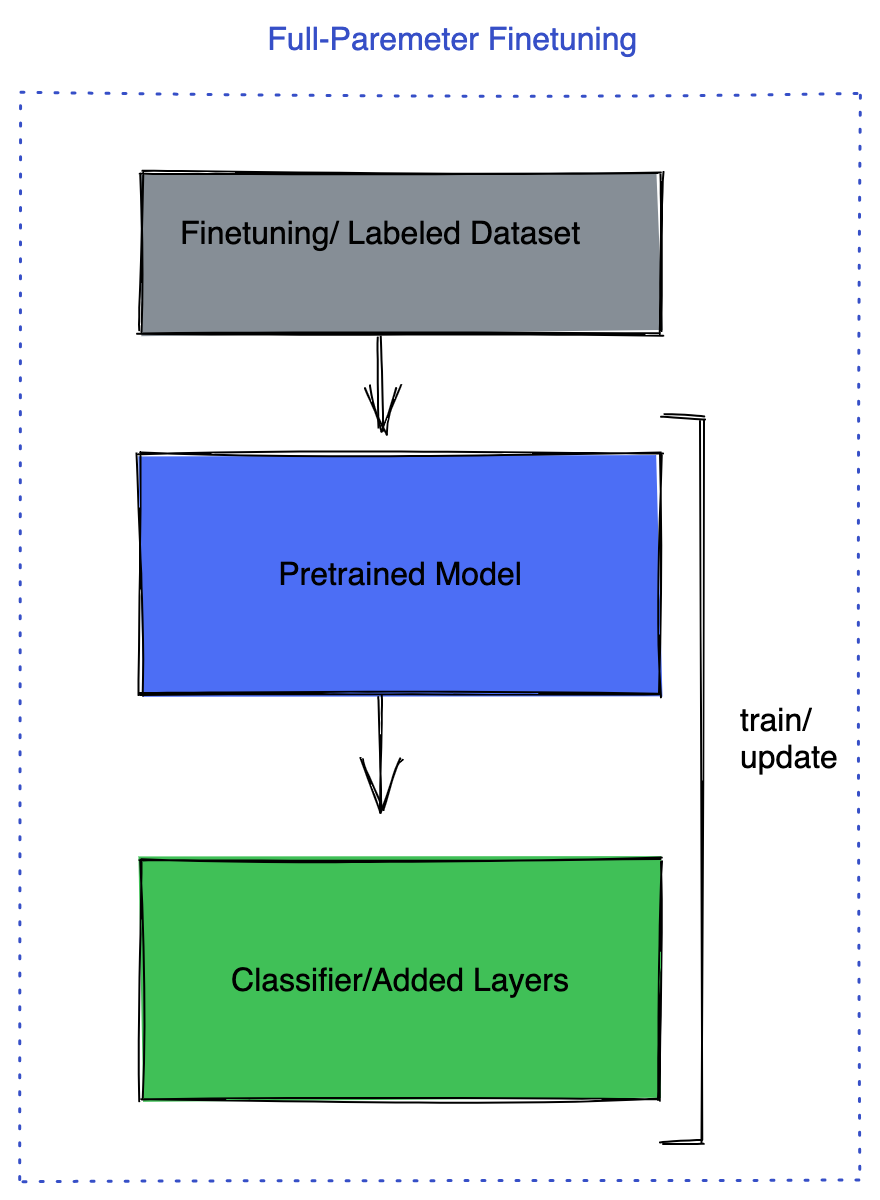
Ajustar todas as camadas
Claro, você também pode optar por ajustar um pequeno número de camadas no modelo, e já existem algumas diretrizes para orientar essa escolha. Mas o método acima é mais comum.
Neste momento, uma GPU geralmente não é suficiente. Por exemplo, o ajuste fino do Llama 2 7B requer mais memória de vídeo. Você precisa usar memória de vídeo suficiente de acordo com o número de parâmetros de ajuste fino, estratégia de treinamento e precisão dos parâmetros.
O autor de código aberto do Llama 2 disse que o pacote FSDP (Fully Sharded Data Parallel) no PyTorch pode ajudar no treinamento neste momento e pode treinar modelos que não podem ser treinados em uma única GPU em várias GPUs.
O FSDP fragmenta não apenas os dados, mas também os parâmetros do modelo, gradientes e estado do otimizador. Apenas uma fatia do modelo é salva por GPU, o que economiza muita memória e possibilita colocar modelos maiores em várias GPUs.
Além disso, para melhorar ainda mais o desempenho do ajuste fino com FSDP, várias propriedades podem ser exploradas:
1. Precisão mista: FSDP fornece uma maneira mais flexível de definir a precisão dos parâmetros do modelo, buffers e gradientes;
2. Ponto de verificação de ativação: economiza memória descartando valores de ativação intermediários durante a passagem para frente e recalculando-os durante a passagem para trás;
3. auto_wrap_policy: Este recurso permite que os usuários especifiquem como o FSDP fragmenta o modelo. Isso inclui suporte padrão para Transformers, que ajuda o FSDP a criar unidades de comunicação mais refinadas que otimizam os custos de comunicação.
Resumindo, o FSDP é uma ferramenta comprovada e eficaz para ajustar o modelo como um todo.
A solução de memória de vídeo grande da Trendcloud ajuda a treinar grandes modelos com mais calma
Grandes produtos de memória de vídeo da Trendcloud, a maior memória de vídeo pode atingir 80G :

O cartão com memória de vídeo 80G custa apenas 8,49 yuans por hora
Equipado com uma plataforma completa de desenvolvimento e treinamento baseada na tecnologia de pooling de GPU, o custo pode ser economizado em até 75% e a eficiência de pesquisa e desenvolvimento pode ser aumentada em 55% É a primeira escolha para treinamento e implantação de modelos grandes. Registre-se agora e obtenha poder de computação!
Referências: https://github.com/facebookresearch/llama-recipes/blob/main/docs/LLM_finetuning.md