Blog relacionado
[Processamento de linguagem natural] [Modelo grande] Análise de código de estrutura de modelo ChatGLM-6B (versão autônoma) [
Processamento de linguagem natural] [Modelo grande] Análise de código-fonte de estrutura de modelo BLOOM (versão autônoma)
[Processamento de linguagem natural] [Modelo grande] Ajuste fino de métodos de modelo grande com recursos extremamente baixos Código de implementação LoRA e BLOOM-LORA
[Processamento de linguagem natural] [Modelo grande] Gopher do modelo grande da DeepMind
[Processamento de linguagem natural] [Modelo grande] Chinchilla: modelo de linguagem grande com treinamento ideal e utilização de computação
[Processamento de linguagem natural] [Modelo grande] Modelo de linguagem grande Teste da ferramenta de raciocínio BLOOM
[Processamento de linguagem natural] [Modelo grande] GLM-130B: um modelo de linguagem bilíngue pré-treinado de código aberto
[Processamento de linguagem natural] [Grande Modelo] 8- para transformadores grandes Introdução à multiplicação de matrizes de bits
[Processamento de linguagem natural] [Modelo grande] BLOOM: Um modelo multilíngue com parâmetros 176B e acesso aberto
[Processamento de linguagem natural] [Modelo grande] PaLM: Um modelo de linguagem grande baseado em Pathways
[Processamento de linguagem natural] [série chatGPT] Grandes modelos de linguagem podem se aprimorar
1. O princípio da LoRA
LoRA é um método de ajuste fino de modelos grandes com recursos muito baixos, que vem do artigo LoRA: Low-Rank Adaptation of Large Language Models .
1. O dilema do ajuste fino de grandes modelos
À medida que a escala do modelo continua a se expandir, o modelo “emergirá” com vários recursos. Especialmente para o modelo de linguagem grande (LLM), à medida que a escala se expande, suas capacidades, como tiro zero e raciocínio de bom senso, serão bastante melhoradas. O custo de ajuste fino e de implantação de modelos grandes é muito alto em comparação com modelos menores. Por exemplo, o ajuste fino do modelo GPT-3 175B requer 1,2 TB de memória de vídeo. Além disso, se vários modelos forem ajustados para diferentes tarefas posteriores, será necessário economizar um peso de modelo para cada tarefa posterior, o que é muito caro. Em alguns cenários, pode até ser necessário ajustar diferentes modelos para diferentes usuários, então o custo do ajuste fino e da implantação do modelo será inaceitável .
Portanto , como reduzir o custo do ajuste fino e da implantação de modelos em grande escala será uma parte importante da comercialização de modelos em grande escala .
2. Abordagem pré-LoRA
Antes da proposta do método LoRA, também havia muitos métodos para tentar resolver o dilema do ajuste fino de modelos grandes. Existem duas direções principais: (1) adicionar uma camada adaptadora; (2) devido a alguma forma de ativação da camada de entrada. Mas ambas as abordagens têm limitações:
2.1 A camada Adaptador introduzirá atraso de inferência
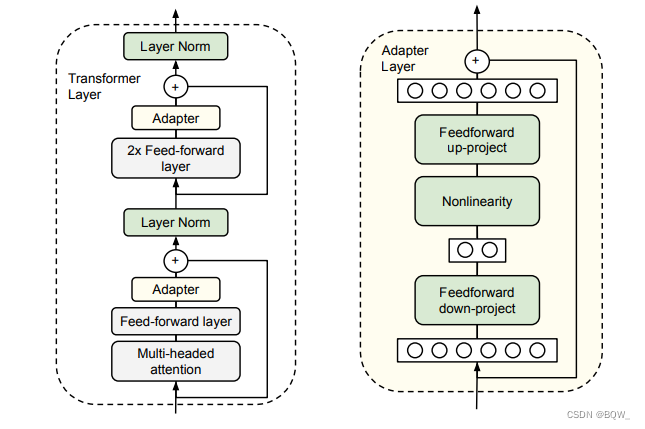
Simplificando, o adaptador serve para corrigir os parâmetros originais e adicionar alguns parâmetros adicionais para ajuste fino. Na figura acima, dois adaptadores serão adicionados ao bloco transformador original, um atrás da atenção multi-cabeça e outro atrás do FFN.
Obviamente, o adaptador adicionará camadas adicionais ao modelo, o que fará com que modelos grandes exijam mais comunicação da GPU durante a inferência e também restringirá o paralelismo do modelo. Esses problemas levarão a uma inferência lenta do modelo .
2.2 O ajuste de prefixo é difícil de otimizar

O método de ajuste de prefixo é inspirado na capacidade de aprendizagem no contexto do modelo de linguagem.Desde que haja um contexto adequado, o modelo de linguagem pode resolver bem as tarefas de linguagem natural. No entanto, leva muito tempo para encontrar o prefixo de tokens discretos para uma tarefa específica. O ajuste de prefixo propõe o uso de incorporação contínua de tokens virtuais para substituir tokens discretos.
Especificamente, para cada camada do transformador, uma incorporação de token virtual treinável é inserida na frente da representação da frase. Para modelos autorregressivos (série GPT), adicione um prefixo contínuo antes da frase, ou seja, z = [ PREFIX ; x ; y ] z=[\text{PREFIX};x;y]z=[ PREFIXO ;x ;e ] . Para o modelo Codificador-Decodificador (T5), adicione um prefixo contínuo antes do Ecoder e do Decodificadorz = [ PREFIX ; x ∣ PREFIX ′ ; y ] z=[\text{PREFIX};x|\text{PREFIX}';y ]z=[ PREFIXO ;x ∣ PREFIXO' ;e ] . O processo de adição de um prefixo é mostrado na figura acima.
Embora o ajuste de prefixo não adicione muitos parâmetros extras. No entanto, o ajuste de prefixo é difícil de otimizar e reduzirá o comprimento da sequência das tarefas posteriores.
3. Formulação formal do problema
Termos e convenções . Devido à introdução do princípio LoRA, será utilizada a arquitetura Transformer. Portanto, algumas convenções terminológicas são fornecidas aqui primeiro. As dimensões de entrada e saída de uma camada Transformer são dmodel d_{model}dmodelo _ _ _ _, usando W q W_qCq、W k W_kCk、W v W_vCvJaponês W o W_oCóRepresenta a matriz de projeção de consulta/chave/valor/saída no módulo de autoatenção. Guerra MundialW ouW 0 W_0C0Representa a matriz de pesos do modelo pré-treinado, Δ W \Delta WΔW representa a atualização do gradiente do modelo durante o processo de ajuste. rrr para representar a classificação do módulo LoRA. Usando Adam como otimizador de modelo, a dimensão da camada feed-forward do Transformer MLP édffn = 4 × dmodel d_{ffn}=4\times d_{model}dff n=4×dmodelo _ _ _ _。
Declaração do problema . Embora LoRA não tenha nada a ver com o objetivo de treinamento, aqui está um exemplo de modelagem de linguagem. Suponha um modelo de linguagem autoregressivo pré-treinado P Φ ( y ∣ x ) P_{\Phi}(y|x)PF( y ∣ x ) Φ\PhiΦ é um parâmetro do modelo. O objetivo é adaptar o modelo de linguagem para tarefas posteriores, como resumo e compreensão de leitura de máquina. Cada tarefa downstream tem um conjunto de treinamento que consiste em pares de amostra de destino de contexto:Z = { ( xi , yi ) } i = 1 , … , N \mathcal{Z}=\{(x_i,y_i)\}_{i = 1,\pontos,N}Z={( xeu,simeu) }eu = 1 , … , N, entre os quais xi x_ixeusoma yi y_isimeuTodas são sequências simbólicas. Por exemplo, para uma tarefa de resumo, xi x_ixeué o conteúdo do artigo, yi y_isimeué o resumo.
No processo de ajuste fino completo, o modelo usa o peso pré-treinado Φ 0 \Phi_0Fi0para inicializar o modelo e, em seguida, atualizar os parâmetros Φ 0 + Δ Φ \Phi_0+\Delta\Phi maximizando o modelo de linguagem condicionalFi0+ΔΦ:
max Φ ∑ ( x , y ) ∈ Z ∑ t = 1 ∣ y ∣ log ( P Φ ( yt ∣ x , y < t ) ) (1) \max_{\Phi}\sum_{(x, y)\in \mathcal{Z}}\sum_{t=1}^{|y|}\log (P_\Phi(y_t|x,y_{<t})) \tag{1}Fimáximo( x , y ) ∈ Z∑t = 1∑∣ e ∣log g ( PF( vocêt∣x , _sim< t))( 1 )
A principal desvantagem do ajuste fino completo: Para cada tarefa downstream, uma atualização de parâmetro diferenteΔ Φ \Delta\PhiΔΦ , onde dimensão∣ Δ Φ ∣ = ∣ Φ 0 ∣ |\Delta\Phi|=|\Phi_0|∣ΔΦ∣=∣Φ _0∣ . Portanto, se o modelo pré-treinado for grande, será muito desafiador armazenar e implantar muitas instâncias independentes de modelo ajustado.
Para ser mais eficiente em termos de parâmetros, LoRA usa um parâmetro relativamente muito pequeno Θ \ThetaΘ para representar o incremento do parâmetro relacionado à tarefaΔ Φ = Δ Φ ( Θ ) \Delta\Phi=\Delta\Phi(\Theta)DF=ΔΦ ( Θ ),使用∣ Θ ∣ ≪ ∣ Φ 0 ∣ |\Theta|\ll |\Phi_0|∣Θ∣≪∣Φ _0∣ . EncontreΔ Φ \Delta\PhiA tarefa de ΔΦ passa a serΘ \ThetaMáx. padrão
Θ ∑ ( x , y ) ∈ Z ∑ t = 1 ∣ y ∣ log ( p Φ 0 + Δ Φ ( Θ ) ( yt ∣ x , y < t ) ) (2) \max_{\ Theta} \sum_{(x,y)\in\mathcal{Z}}\sum_{t=1}^{|y|}\log(p_{\Phi_0+\Delta\Phi(\Theta)}(y_t| x, y_{<t})) \tag{2}ºmáximo( x , y ) ∈ Z∑t = 1∑∣ e ∣log g ( pFi0+ ΔΦ ( Θ )( vocêt∣x , _sim< t))( 2 )
LoRA usará uma representação de baixa classificação para codificarΔ Φ \Delta\PhiΔΦ , alcançando eficiência computacional e eficiência de armazenamento. Quando o modelo de pré-treinamento é 175B GPT-3, os parâmetros treináveis∣ Θ ∣ |\Theta|∣Θ∣ pode ser tão pequeno quanto∣ Φ 0 ∣ |\Phi_0|∣Φ _0∣0,01 % de0,01\%0,01 %
4. LoRA
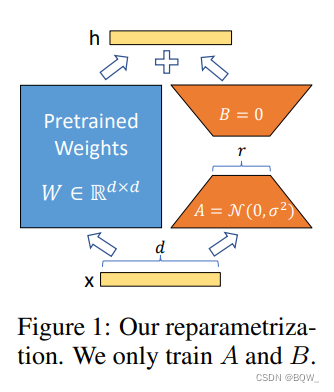
Normalmente, uma rede neural conterá muitas camadas densas que realizam a multiplicação de matrizes, e essas camadas geralmente são de classificação completa. Adgajanyan et al.A pesquisa de et al mostra que modelos de linguagem pré-treinados apresentam baixa “dimensionalidade intrínseca”. Inspirado neste trabalho, as atualizações de peso também devem ter baixa "classificação intrínseca" durante a adaptação do modelo para tarefas posteriores. Para matriz de peso pré-treinamento W 0 ∈ R d × k W_0\in\mathbb{R}^{d\times k}C0∈Rd × k , sua atualização pode ser representada pela decomposição de baixo escalãoW 0 + Δ W = W 0 + BA W_0+\Delta W=W_0+BAC0+Δ W=C0+B A,B ∈ R d × r , A ∈ R r × k B\in\mathbb{R}^{d\times r},A\in\mathbb{R}^{r\times k}B∈Rd × r ,A∈Rr × k且秩r ≪ min ( d , k ) r\ll\min(d,k)R≪min ( d ,k ) . Durante o treinamento,W 0 W_0C0está congelado e não aceita atualizações de gradiente, AAA eBBB é um parâmetro treinável. Observe queW 0 W_0C0Soma Δ W = BA \Delta W=BAΔ W=Tanto B quanto A serão multiplicados pela mesma entrada. Parah = W 0 xh=W_0xh=C0x , a propagação direta se torna:
h = W 0 x + Δ W x = W 0 x + BA x (3) h=W_0x+\Delta Wx=W_0x+BAx \tag{3}h=C0x+Δ W x=C0x+B A x( 3 )
matriz de pares AAA é inicializado com um Gaussiano aleatório e a matrizBBB é inicializado com 0, entãoΔ W = BA \Delta W=BAΔ W=B A é 0 no início do treinamento. Useα r \frac{\alpha}{r}Raescalar Δ W x \Delta WxΔ W x , ondeα \alphaα é menor querrconstante para r . Ao usar a otimização Adam, após a inicialização adequada do dimensionamento, o ajuste deα \alphaα é quase o mesmo que ajustar a taxa de aprendizagem.
Ao implantar, calcule e armazene explicitamente W = W 0 + BAW=W_0+BAC=C0+B A e execute a inferência normalmente. W 0 W_0C0Bacharelado Japonês BAB A éR d × k \mathbb{R}^{d\times k}Rd × k . Quando for necessário mudar para outra tarefa posterior, isso pode ser feito subtraindoBA BAB A para restaurarW 0 W_0C0, e então adicione diferentes B ′ A ′ B'A'B′ Um' . Crucialmente, é garantido que isso não introduzirá nenhuma latência de inferência adicional.
5. LoRA aplicado ao Transformer
Em teoria, o LoRA pode ser aplicado à matriz de pesos de qualquer rede neural, reduzindo assim o número de parâmetros treináveis. O módulo de autoatenção na arquitetura Transformer possui 4 matrizes de peso: W q , W k , W v , W o W_q,W_k,W_v,W_oCq,Ck,Cv,Cóe as matrizes de peso dos dois modelos MLP. W q W_qCq(ou W k , W v W_k,W_vCk,Cv) como uma dimensão dmodel × dmodel d_{model}\times d_{model}dmodelo _ _ _ _×dmodelo _ _ _ _de uma única matriz. Por simplicidade e eficiência de parâmetros, este estudo limita-se a adaptar pesos de atenção para tarefas posteriores e congelar o módulo MLP.
Vantagens . A vantagem mais notável é a redução da memória de vídeo e do espaço de armazenamento. Para um grande Transformer treinado com Adam, se r ≪ dmodelr\ll d_{model}R≪dmodelo _ _ _ _, o uso de VRAM é reduzido em 2/3, pois não há necessidade de armazenar o estado do otimizador para parâmetros congelados. Para GPT-3 175B, o consumo de memória durante o treinamento foi reduzido de 1,2 TB para 350 GB. quando r = 4 r=4R=4 E ao ajustar apenas a matriz de consulta e a matriz de valor, o tamanho do ponto de verificação é reduzido em 10.000 vezes (de 350 GB para 35 MB). Outra vantagem é que as tarefas podem ser trocadas no momento da implantação a um custo menor, apenas pela troca de pesos LoRA. Além disso, em comparação com o ajuste fino completo, o GPT-3 175B treina 25% mais rápido porque os gradientes para a grande maioria dos parâmetros não precisam ser calculados.
2. Código: Implementar BLOOM-LoRA
Esta seção mostra como usar LoRA para ajustar o florescimento do modelo de linguagem grande.
-
Dados : Use 1 milhão de instruções fornecidas pela BELLE para ajustar os dados;
-
Modelo : Use bloomz-7b1-mt, esta versão do bloomz também é um modelo após o ajuste fino das instruções. Veja o princípio do BLOOM:
-
Pacotes dependentes : use transformadores para fornecer carregamento e treinamento de modelo; use peft para fornecer implementação LoRA; use DeepSpeed para fornecer suposições de treinamento.
Nota: O pacote peft ainda está em processo de iteração rápida e pode haver grandes mudanças nas interfaces subsequentes e também pode haver alguns bugs. Versão do pacote de dependência principal:
transformers==4.26.1
torch==1.13.1
deepspeed==0.8.2
peft==0.2.0
1. Código de treinamento
Para resumir, suponha que o código de treinamento esteja localizado em train.py.
1.1 Importar pacotes dependentes
import os
import torch
import random
import datasets
import numpy as np
from tqdm import tqdm
from typing import Dict
from torch.utils.data import DataLoader
from transformers import (
AutoModelForCausalLM,
AutoTokenizer,
DataCollatorForSeq2Seq,
TrainingArguments,
Trainer
)
from peft import (
LoraConfig,
TaskType,
get_peft_model,
get_peft_model_state_dict,
set_peft_model_state_dict
)
def set_random_seed(seed):
if seed is not None and seed > 0:
random.seed(seed)
np.random.seed(seed)
torch.manual_seed(seed)
torch.random.manual_seed(seed)
torch.cuda.manual_seed(seed)
torch.cuda.manual_seed_all(seed)
torch.backends.cudnn.deterministic = True
set_random_seed(1234)
1.2 Configuração de parâmetros
# LoRA参数
LORA_R = 8
LORA_ALPHA = 32
LORA_DROPOUT = 0.1
# 训练参数
EPOCHS=3
LEARNING_RATE=5e-5
OUTPUT_DIR="./checkpoints"
BATCH_SIZE=4 # 2
GRADIENT_ACCUMULATION_STEPS=3
# 其他参数
MODEL_PATH = "bigscience/bloomz-7b1-mt"
DATA_PATH = "./data/belle_open_source_1M.train.json"
MAX_LENGTH = 512
PATTERN = "{}\n{}"
DS_CONFIG = "ds_zero2_config.json"
tokenizer = AutoTokenizer.from_pretrained(MODEL_PATH) # 加载tokenizer
1.3 Carregar dados
dataset = datasets.load_dataset("json", data_files=DATA_PATH)
# print(dataset["train"][0])
1.4 tokenizar
def tokenize(text: str, add_eos_token=True):
result = tokenizer(
text,
truncation=True,
max_length=MAX_LENGTH,
padding=False,
return_tensors=None)
# 判断是否要添加eos_token
if (result["input_ids"][-1] != tokenizer.eos_token_id
and len(result["input_ids"]) < MAX_LENGTH
and add_eos_token):
result["input_ids"].append(tokenizer.eos_token_id)
result["attention_mask"].append(1)
result["labels"] = result["input_ids"].copy()
return result
def preprocess(example: Dict, train_on_inputs: bool = False):
prompt = example["input"]
response = example["target"]
text = PATTERN.format(prompt, response)
tokenized_inp = tokenize(text)
# 若train_on_inputs为False,则将label中与input相关的token替换为-100
if not train_on_inputs:
tokenized_prompt = tokenize(prompt,add_eos_token=False)
prompt_tokens_len = len(tokenized_prompt["input_ids"])
tokenized_inp["labels"] = [-100]*prompt_tokens_len + tokenized_inp["labels"][prompt_tokens_len:]
return tokenized_inp
train_data = dataset["train"].shuffle().map(preprocess, remove_columns=["id", "input", "target"])
print(train_data[0])
1.5 collate_fn
# pad_to_multiple_of=8表示padding的长度是8的倍数
collate_fn = DataCollatorForSeq2Seq(tokenizer, pad_to_multiple_of=8, return_tensors="pt", padding=True)
1.6 Carregando o modelo
device_map = {
"": int(os.environ.get("LOCAL_RANK") or 0)}
# device_map指定模型加载的GPU;troch_dtype=torch.float16表示半精度加载模型
model = AutoModelForCausalLM.from_pretrained(MODEL_PATH, torch_dtype=torch.float16, device_map=device_map)
1.7 LoRA relacionado
# 转换模型
model = get_peft_model(model, lora_config)
model.config.use_cache = False
old_state_dict = model.state_dict
model.state_dict = (
lambda self, *_, **__: get_peft_model_state_dict(self, old_state_dict())
).__get__(model, type(model))
# 打印模型中的可训练参数
model.print_trainable_parameters()
1.8 Parâmetros de treinamento
args = TrainingArguments(
output_dir=OUTPUT_DIR, # checkpoint的存储目录
per_device_train_batch_size=BATCH_SIZE, # 单设备上的batch size
gradient_accumulation_steps=GRADIENT_ACCUMULATION_STEPS, # 梯度累加的step数
warmup_steps=100,
num_train_epochs=EPOCHS,
learning_rate=LEARNING_RATE,
fp16=True, # 使用混合精度训练
logging_steps=50,
evaluation_strategy="no", # 不进行评估
save_strategy="steps",
save_steps=2000, # 保存checkpoint的step数
save_total_limit=5, # 最多保存5个checkpoint
deepspeed=DS_CONFIG
)
1.9 Treinamento de modelo
trainer = Trainer(
model=model,
train_dataset=train_data,
eval_dataset=None,
args=args,
data_collator=collate_fn
)
trainer.train()
model.save_pretrained("best_model")
2. Arquivo de configuração DeepSpeed
O arquivo de configuração do DeepSpeed é denominado ds_zero2_config.json.
{
"train_micro_batch_size_per_gpu": "auto",
"gradient_accumulation_steps": "auto",
"steps_per_print": 50,
"gradient_clipping": 1.0,
"zero_optimization": {
"stage": 2,
"offload_optimizer": {
"device": "cpu"
},
"contiguous_gradients": true,
"overlap_comm": true
},
"zero_allow_untested_optimizer": true,
"fp16": {
"enabled": true,
"loss_scale": 0,
"loss_scale_window": 1000,
"hysteresis": 2,
"min_loss_scale": 1
},
"optimizer": {
"type": "Adam",
"params": {
"lr": "auto",
"betas": "auto",
"eps": "auto",
"weight_decay": "auto"
}
},
"activation_checkpointing": {
"partition_activations": true,
"contiguous_memory_optimization": true
},
"wall_clock_breakdown": false
}
3. começar
deepspeed --include=localhost:0,1,2,3 train.py
4. Raciocínio
O nome do arquivo de inferência é inference.py
import torch
from peft import PeftModel
from transformers import AutoModelForCausalLM, AutoTokenizer
BASE_MODEL = "bigscience/bloomz-7b1-mt"
LORA_WEIGHTS = "best_model"
tokenizer = AutoTokenizer.from_pretrained(BASE_MODEL)
model = AutoModelForCausalLM.from_pretrained(
BASE_MODEL,
torch_dtype=torch.float16, # 加载半精度
device_map={
"":0}, # 指定GPU 0
)
model.eval()
# 加载LoRA权重
model = PeftModel.from_pretrained(model, LORA_WEIGHTS, torch_dtype=torch.float16)
model.half()
prompt = ""
inp = tokenizer(prompt, max_length=512, return_tensors="pt").to("cuda")
outputs = model.generate(input_ids=inp["input_ids"], max_new_tokens=256)
print(tokenizer.decode(outputs[0]))
Referências
https://arxiv.org/pdf/2106.09685.pdf
https://zhuanlan.zhihu.com/p/615235322
https://github.com/tloen/alpaca-lora/blob/main/finetune.py
https://github.com/huggingface/peft/blob/main/examples/conditional_Generation/peft_lora_seq2seq_accelerate_ds_zero3_offload.py