LLaMA-Adapter: ajuste fino eficiente de modelos de linguagem com atenção zero
Introdução
O ponto do autor é que o modelo de linguagem grande recentemente recebeu ampla atenção da academia e da indústria, e os LLMs mostraram capacidades muito boas. Instruções ou prompts podem ser usados para gerar diálogos de contexto complexos e profissionais, mas os modelos de instrução a seguir são limitados por dados de código fechado e poder de computação .
O Alpaca é um modelo obtido pelo ajuste fino do LLaMA usando dados gerados por autoinstrução. Ele precisa apenas de 175 dados qa, gera 52k pares de dados qa por auto-instrução e seu desempenho é próximo a gpt3.5.
Os autores apontam que o ajuste completo do LLaMA ainda é demorado, não oferece suporte à multimodalidade e está inchado para diferentes tarefas de downstream.
Neste artigo, o autor adiciona uma adaptação que pode ser aprendida nas camadas superiores do modelo como um prefixo para injetar na nova instrução. Para evitar ruído no estágio inicial do treinamento, o mecanismo de atenção comum da camada de inserção é modificado para atenção inicial zero, com um fator de gating apreensível.
Resumindo, tem as seguintes vantagens:
- Os parâmetros de 1,2M atingem uma capacidade semelhante ao ajuste fino completo da Alpaca.
- 1 hora de ajuste fino.
- Comutação flexível de tarefas downstream.
- Suporte multimodal.
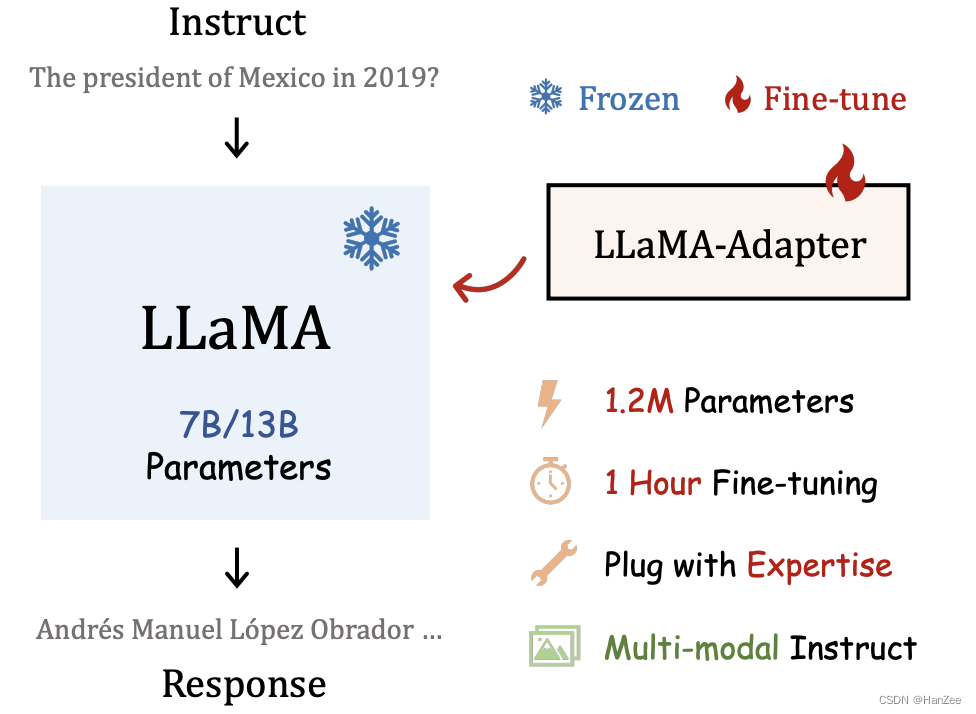
Adaptador LLaMA
Prompts de adaptação que podem ser aprendidos
Dado 52k de dados qa, n-camada PLM: LLaMA, a definição de prompt para transformador de camada L é expressa como:

Entre eles, K representa o comprimento do prompt e C representa a hidden_dimension do modelo.
L<N, L indica a camada que insere no máximo o prefixo e N indica o número de camadas do modelo, o autor disse que isso pode ajustar melhor a representação da linguagem com semântica avançada.
O modelo de definição originalmente possui M tokens em cada camada, e a combinação dos dois é expressa como:
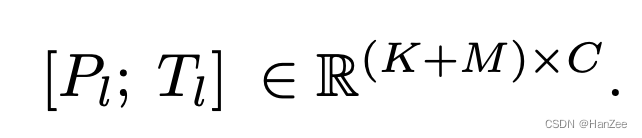
O autor acredita que desta forma, Pl pode guiar eficientemente a saída de cada camada Tl. (Eu me sinto um pouco como o P-tuningV2 aqui).
Atenção Inicial Zero
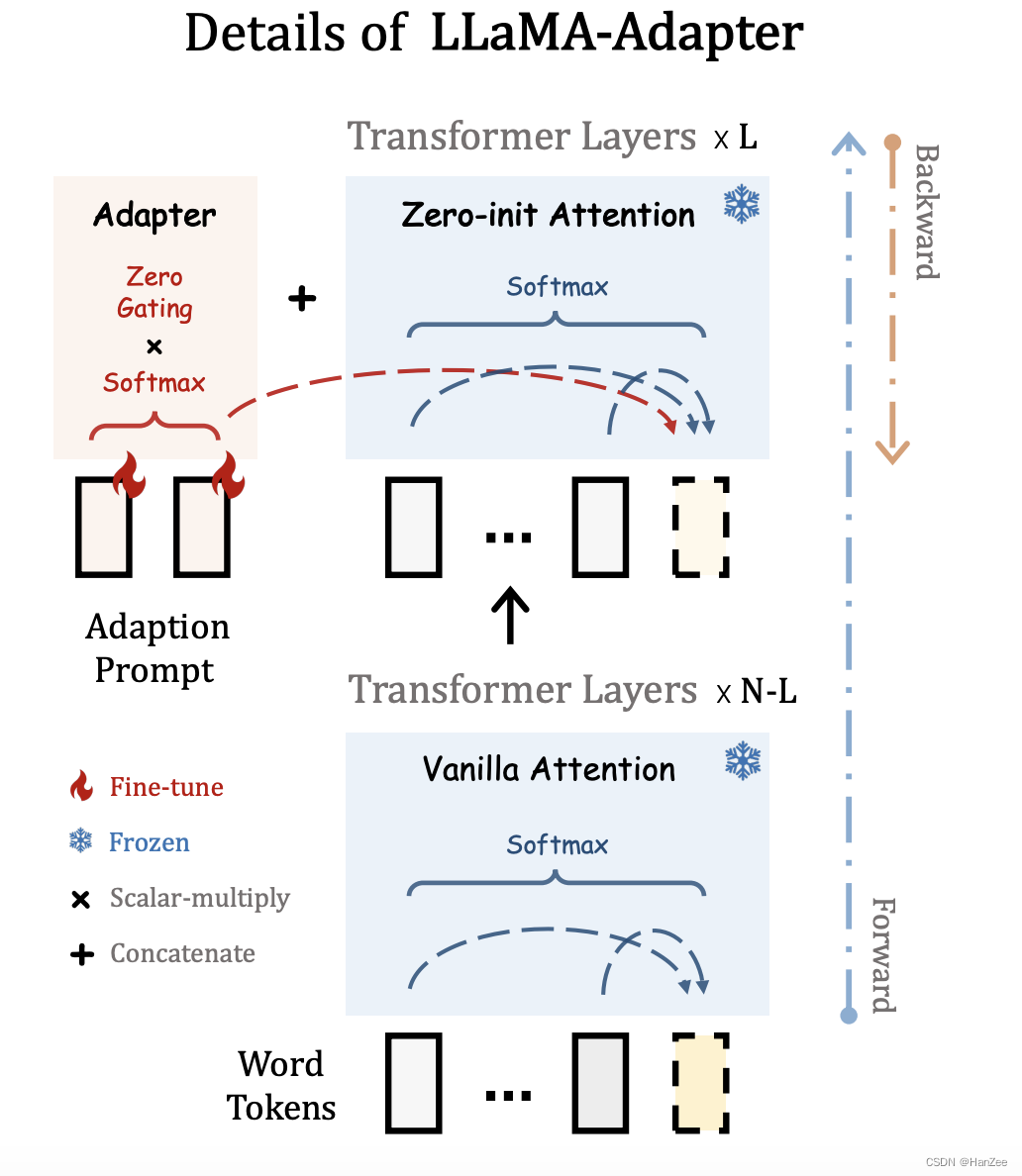
Como mostrado na figura acima, no método original, para prever o token amarelo, você precisa considerar o token amarelo e todos os tokens anteriores. Depois de adicionar um prefixo a esta camada de rede (usando inicialização aleatória), o ruído pode ser introduzido em o estágio inicial do treinamento do modelo. Causa instabilidade pré-treinamento.
O autor substituiu o original Vanilla Attention por Zero-init Attention.Para reduzir o ruído, o autor introduziu um Zero Gating apreensível, inicializou-o com zero e multiplicou-o pelo prefixo.
A segunda melhoria é que, ao calcular a pontuação de atenção, o softmax será calculado para todos os tokens (por conveniência, na verdade é baseado na fórmula de q*k) e o autor calcula o prefixo e o token original separadamente.
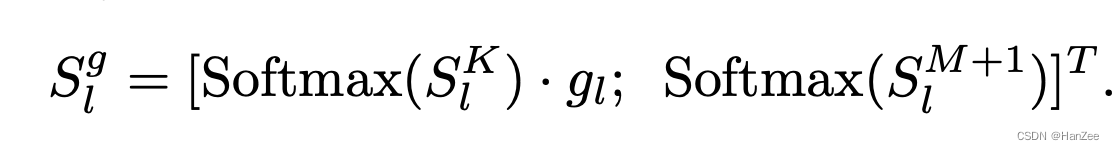
Em seguida, obtenha o resultado da próxima camada por meio de linear.
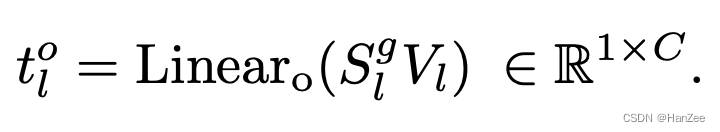
experimentar
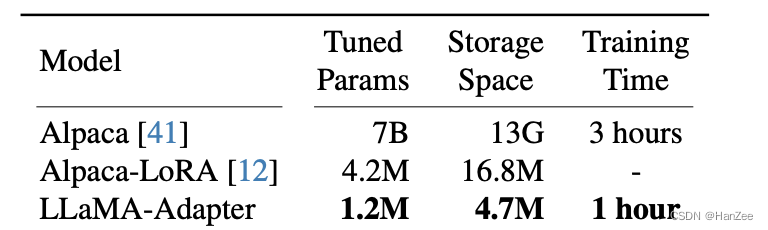
O número de parâmetros treináveis é menor que o de lora e o tempo de treinamento é reduzido em 3 vezes em comparação com a alpaca-lhama original. Aumente o número
de camadas de treinamento do adaptador e pode ser visto que a precisão de adicionar mais as camadas de treinamento serão melhores.
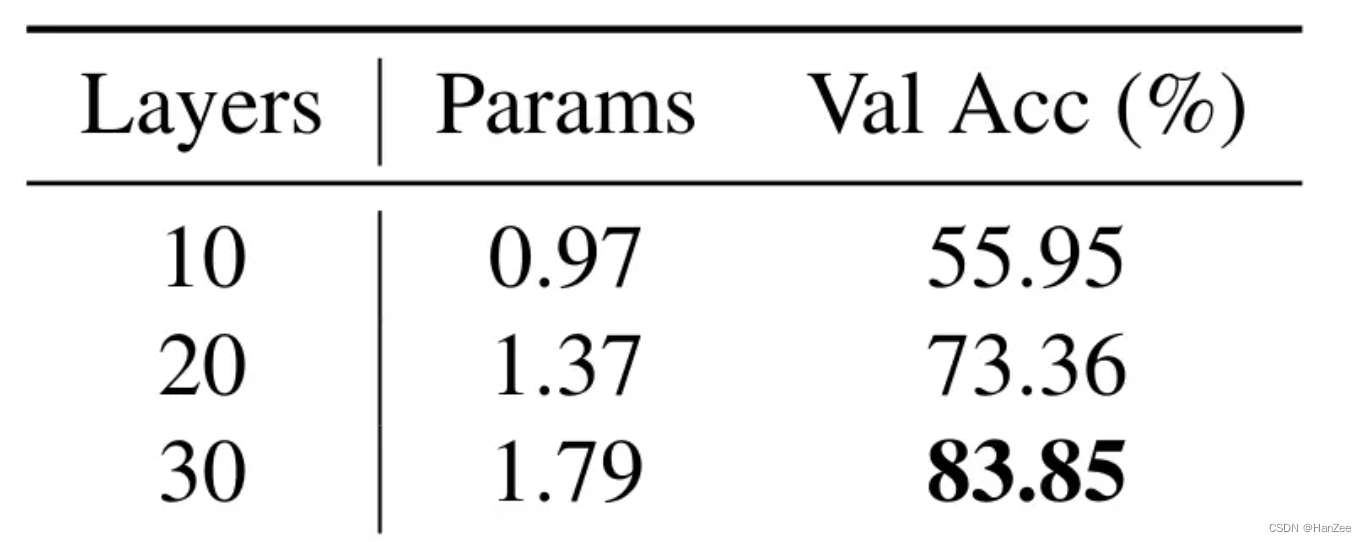
O método de efeito de inicialização zero

é mais eficaz para problemas de sobreajuste. Robusto, o acc é o mais alto ao treinar por 60 épocas.