Índice
Em segundo lugar, a ideia de classificação rápida
Três, pesquisa binária (meia pesquisa)
1. Descrição do problema
Escreva um módulo chamado find.py, com duas funções integradas para implementar a classificação rápida e o algoritmo de pesquisa binária e, em seguida, chame esse módulo para classificar e localizar uma sequência contendo N inteiros aleatórios em [a,b] Se um número inserido pelo usuário está na sequência.
Em segundo lugar, a ideia de classificação rápida
Primeiro, a " divisão única " é realizada na sequência de registro não ordenada e, em seguida, a classificação rápida " recursiva " é realizada nas duas subsequências obtidas da divisão .
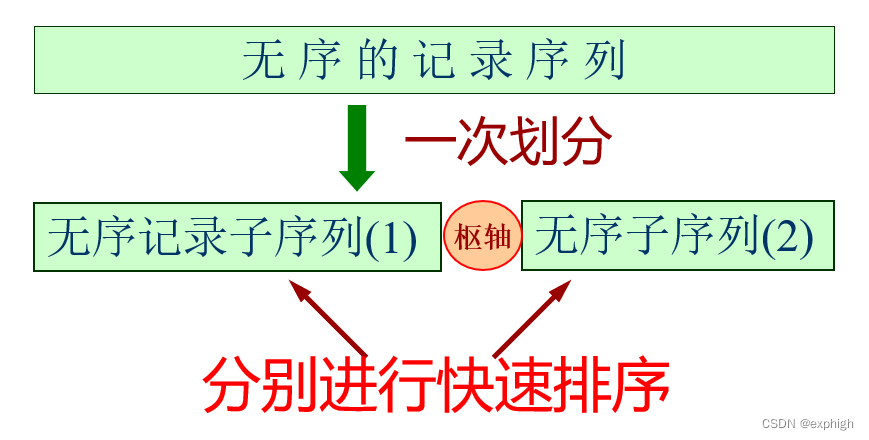
O objetivo da "divisão única" é encontrar um registro e usar sua chave como um "pivô" . Todos os registros cuja chave é menor que o pivô são movidos para a frente do registro , caso contrário, todos os registros com chave maior que o pivô é movido para depois deste registro .
Como resultado, após uma viagem de classificação , a sequência não ordenada registrada R[ s..t ] será dividida em duas partes : R[s..i-1] e R[i+1..t] e
R[j].chave≤ R[i].chave ≤ R[j].chave
( s≤j≤i-1) pivô (i+1≤j≤t)
Python é muito conveniente de implementar, usando a ideia "recursiva", diretamente no código:
def Quick_Sort(myList,start,end): #myList表示输入序列 #start表示起始位置 #end表示终止位置 if start < end: i,j = start,end pivot = myList[i]#枢轴位置 while i < j: while (i < j) and (myList[j] >= pivot): j = j - 1 myList[i] = myList[j] while (i < j) and (myList[i] <= pivot): i = i + 1 myList[j] = myList[i] myList[i] = pivot Quick_Sort(myList, start, i - 1)#递归排序枢轴左侧序列 Quick_Sort(myList, j + 1, end)#递归排序枢轴右侧序列 return myList
Três, pesquisa binária (meia pesquisa)
Ideia básica : primeiro determine o escopo dos registros a serem verificados. Assumindo que as variáveis low e high são usadas para representar o primeiro e o último subscrito da área de pesquisa atual , compare a chave da palavra-chave a ser pesquisada com a chave do elemento do meio da área ( subscript mid=(low+high ) / 2 ) . Os resultados da comparação têm as seguintes três situações:
(1) key==A[mid].key : Se a pesquisa for bem-sucedida, retorna o valor de mid .
(2) key<A[mid].key : O registro deve estar na área à esquerda de mid ( subscripts from low to mid-1 ) , e a chave gravada na posição do meio continuará a ser comparada nesta área .
(3) key>A[mid].key : O elemento só pode estar na área direita ( subscrito de mid+1 a high) , e continue a comparar a chave registrada na posição intermediária nesta área.
Implementação de programação de algoritmo de pesquisa binária python:
def Bin_Search(Mylist,value):
#Mylist为有序序列
#value为待查找的值
low=0
high=len(Mylist)-1
while low <=high:
mid=(low+high)//2
if Mylist[mid]==value:
print('查找成功,元素所在位置为:{}'.format(mid))
return mid
elif Mylist[mid]>value:
high=mid-1
else:
low=mid+1
return -1
Salve a função Quick_Sort e Bin_Search como find.py e importe-os com import.
importar encontrar
Gere N inteiros aleatórios em [a,b]:
def Myrandom(a,b,N):
lst=[]
for i in range(N):
x=random.randint(a,b)
lst.append(x)
return lstfunção principal:
import find
import random
def Myrandom(a,b,N):
lst=[]
for i in range(N):
x=random.randint(a,b)
lst.append(x)
return lst
def main():
a = 0
b = 1000
N = 50
lst=Myrandom(a,b,N)
print('随机生成的N个数的序列:{}'.format(lst))
find.Quick_Sort(lst,0,N-1)
print('QuickSort:')
print(lst)
n = int(input('请输入一个数字:'))
a = find.Bin_Search(lst, n)
if (a == -1):
print('{}未在序列中'.format(n))
if __name__ == '__main__':
main()resultado da operação:

