Diretório de artigos
prefácio
Prometheus é um kit de ferramentas de monitoramento e alerta de sistema de código aberto desenvolvido em linguagem GO . Foi originalmente lançado pela SoundCloud em 2012 e posteriormente usado por muitas grandes empresas e organizações. Ingressou na Cloud Native Computing Foundation em 2016. Foundation, CNCF) , e formado em 2018, agora é um projeto independente de código aberto e mantido independentemente de qualquer empresa.
O Prometheus é uma ferramenta de monitoramento muito boa, para ser mais preciso, é uma solução de monitoramento. O Prometheus fornece um conjunto completo de soluções de monitoramento para monitoramento de coleta de dados, armazenamento, visualização de processamento e alarmes.
-
Site oficial: https://prometheus.io/
-
endereço do github: https://github.com/prometheus/prometheus
Grafana é uma ferramenta de visualização e análise de medição multiplataforma de código aberto que oferece suporte a várias fontes de dados, como Prometheus, Elasticsearch, InfluxDB, etc. Ele fornece uma grande variedade de gráficos e painéis visuais que podem ajudar os usuários a entender e analisar melhor os dados de monitoramento.
- Endereço do documento: https://grafana.com/docs/grafana/latest/
- endereço github: https://github.com/grafana/grafana
O próprio Prometheus carrega uma IU da web para exibir gráficos de dados, mas é um pouco rudimentar, e o Grafana pode suportar a produção e exibição de belos gráficos, e suporta o próprio Prometheus, então a solução clássica de monitoramento é Prometheus + Grafana.
1. Conceito
1.1 Desenvolvimento
O desenvolvimento do monitoramento de operação e manutenção pode ser rastreado até o estágio inicial da tecnologia de computadores. Com o desenvolvimento contínuo da tecnologia de computadores, o monitoramento de operação e manutenção também está em constante evolução e melhoria.
- O monitoramento inicial de O&M foi feito principalmente pela verificação manual dos logs do sistema e das métricas de desempenho, o que consumia muito tempo e era propenso a erros.
- Com o contínuo desenvolvimento da informática, surgiram algumas ferramentas de monitoramento baseadas no protocolo SNMP, como Nagios, Zabbix e assim por diante. Essas ferramentas podem coletar automaticamente logs do sistema e indicadores de desempenho, analisá-los e processá-los para ajudar os usuários a entender melhor o status operacional do sistema.
- Nos últimos anos, com o desenvolvimento contínuo da computação em nuvem e da tecnologia de contêineres, o monitoramento de operação e manutenção também está em constante evolução e aprimoramento. Por exemplo, o Prometheus é um sistema de monitoramento de código aberto baseado na tecnologia nativa da nuvem, que pode ajudar os usuários a gerenciar e monitorar melhor os aplicativos nativos da nuvem.
Em suma, com o desenvolvimento contínuo da tecnologia de computador, o monitoramento de operação e manutenção também está em constante evolução e melhoria. Desde a inspeção manual inicial até ferramentas de monitoramento baseadas no protocolo SNMP, e agora para as atuais ferramentas automáticas de monitoramento de operação e manutenção, operação e manutenção O monitoramento fornece aos usuários melhor serviço e suporte.
1.2 Dados de séries temporais
Dados de séries temporais, ou seja, dados de séries temporais (Time Series Data), dados registrados e indexados em ordem de dimensão temporal. Vários tipos de equipamentos em áreas como a Internet das Coisas, a Internet dos Veículos e a Internet Industrial gerarão grandes quantidades de dados de séries temporais, que representarão mais de 90% do total de dados do mundo. Na plataforma de monitoramento, os dados de séries temporais geralmente se referem a dados sequenciais com carimbos de data/hora, como indicadores de desempenho do sistema e informações de registro.
A comparação entre dados de séries temporais e dados relacionais tradicionais, os dados de séries temporais se concentram em CR em CRUD, sem U
1.3 Métrica
Métrica (medição, indicador) é um conceito muito importante. Aparece com muita frequência no monitoramento de operação e manutenção. Refere-se a indicadores no sistema de monitoramento, como uso de CPU, uso de memória, tráfego de rede, etc. No Prometheus, sua essência refere-se para Existe um registro no banco de dados.
Pode ser dividido em 4 tipos no cliente Prometheus
- Contador: uma métrica cumulativa que representa um contador de aumento monotônico cujo valor só pode ser aumentado ou redefinido para zero em uma reinicialização. Por exemplo, você pode usar contadores para representar o número de solicitações atendidas, tarefas concluídas ou erros.
- Medidor: Um valor único que pode flutuar arbitrariamente. Os medidores são normalmente usados para valores medidos, como temperatura ou uso de memória atual, mas também são usados para "contagens" que podem variar para cima e para baixo, como o número de solicitações simultâneas.
- Histograma: Histograma, que representa os resultados estatísticos da amostragem de dados durante um período de tempo, e a distribuição das amostras é contada por agrupamento. Por exemplo, conte o tempo que a interface consome, quantas requisições caem em 10ms - 20ms, quantas requisições caem em 20ms - 30ms, etc.
- Resumo: Semelhante ao histograma, o percentil é calculado com base na amostra. Por exemplo, as estatísticas vinculam o consumo de tempo, TP99, TP95, etc.
2. Prometeu
2.1 Arquitetura

-
Servidor Prometheus : Use o mecanismo de descoberta de serviço para obter o destino que precisa ser monitorado e extraia os dados do indicador do destino por meio do método Pull. De acordo com a regra definida, os dados do indicador podem ser calculados novamente com antecedência e o gatilho o alarme é enviado ao componente alertmanager para coleta e processamento. Armazena dados de séries temporais.
-
PushGateway : Cada host de destino pode relatar dados para o PushGateway e, em seguida, o servidor Prometheus extrai os dados do pushgateway uniformemente.
-
Exportadores : Colete indicadores existentes de monitoramento de serviços de terceiros e exponha métricas. O Prometheus oferece suporte a uma variedade de exportadores, por meio dos quais dados de métricas podem ser coletados e enviados ao servidor Prometheus.
-
Alertmanager : O componente envia notificações correspondentes de acordo com o modo de alarme do alarme. Depois que os alertas forem recebidos do servidor Prometheus, eles serão desduplicados, agrupados e roteados para o receptor correspondente, e um alarme será emitido. Os métodos comuns de recebimento são: email, WeChat, DingTalk, slack, etc.
-
Grafana : componente de visualização de dados, painel de monitoramento, consulta de dados do servidor Prometheus por meio do PromQL e exibição deles
-
IU da Web do Prometheus : console da Web simples, porta padrão 9090
2.2 configuração
O Prometheus pode carregar arquivos de configuração por meio da opção de comando --config.file.
Quando --web.enable-lifecycle está ativado, uma solicitação POST pode ser enviada por meio da URL ///reload para carregar o arquivo de configuração sem reiniciar o Prometheus
Documento de configuração: https://prometheus.io/docs/prometheus/latest/configuration/configuration/ , a seguir estão 4 categorias de configuração comumente usadas
-
global
Configure informações globais, como monitoramento de intervalo de dados, período de tempo limite de negócios, ciclo de execução de regra de alarme, etc.
- scrape_interval O intervalo de tempo padrão para puxar alvos, o padrão é 1m
- scrape_timeout pull timeout, padrão 10s
- avaliação_intervalo executa o intervalo de regras, o padrão é 1m
-
rule_files
Contém dois arquivos de regras: regra de registro e regra de alarme.
-
regras de registro
As regras de gravação permitem que expressões que geralmente são necessárias ou caras para calcular sejam pré-computadas e seus resultados salvos como um novo conjunto de séries temporais. Consultar resultados pré-computados geralmente é muito mais rápido do que executar a expressão original sempre que for necessário. Isso é especialmente útil para painéis que precisam consultar a mesma expressão repetidamente em cada atualização.
Documentação: https://prometheus.io/docs/prometheus/latest/configuration/recording_rules/
-
regras de alerta
Defina as condições de alerta com base no PromQL e envie notificações para serviços externos sobre alertas acionados.
Documentação: https://prometheus.io/docs/prometheus/latest/configuration/alerting_rules/
-
-
alertando
Gerenciador de alertas de gerenciamento de configuração
-
scrape_configs
Configure o trabalho do nó de dados pull, documento: https://prometheus.io/docs/prometheus/latest/configuration/configuration/#scrape_config
- job_name nome do trabalho
- frequência de rastreamento scrape_interval , padrão global.scrape_interval
- scrape_timeout tempo limite de rastreamento, padrão global.scrape_timeout
- metrics_path caminho de captura, padrão /metric
- static_configs rastrear endereço URL de destino
2.3 Linguagem de consulta PromQL
O Prometheus fornece uma linguagem de consulta funcional chamada PromQL (Prometheus Query Language), que permite aos usuários selecionar e agregar dados de séries temporais em tempo real. Endereço do documento: https://prometheus.io/docs/prometheus/latest/querying/basics/
-
consulta de filtro
Use {} para filtrar os resultados. O valor do rótulo interno pode usar = para indicar igualdade, != para indicar desigualdade, =~ para indicar uma correspondência regular e !~ para indicar uma incompatibilidade regular
http_requests_total{ method="GET"} http_requests_total{ environment=~"staging|testing|development",method!="GET"} http_requests_total{ status!~"4.."} -
consulta de intervalo de tempo
Pode ser selecionado por [valor de tempo], por exemplo
http_requests_total [5m] -
Consulta de tempo de deslocamento
offset permite alterar o deslocamento de tempo de vetores instantâneos individuais e vetores de intervalo em uma consulta. Por exemplo, o número total de solicitações http nos últimos 5 minutos
http_requests_total offset 5m -
consulta de tempo fixo
@ permite alterar o tempo de computação de vetores instantâneos individuais e vetores de intervalo na consulta. A hora fornecida ao modificador @ é um carimbo de data/hora unix representado como um número de ponto flutuante
Por exemplo: retorne o valor em 2021-01-04T07:40:00+00:00
http_requests_total @ 1609746000 -
consulta de agregação
Prometheus fornece sum, max, min, avg, count, bottomk, topk e outros comandos de agregação para consultar dados
sum(http_requests_total) sum by (application, group) (http_requests_total) topk(5, http_requests_total) -
consulta de função
O Prometheus fornece funções para participar da computação de dados de consulta, documento: https://prometheus.io/docs/prometheus/latest/querying/functions/
rate(http_requests_total[5m])[30m:1m]
2.4 Exportador
O Prometheus obtém os dados por meio do Exporter, que pode ser baixado e instalado sob demanda conforme link do documento: https://prometheus.io/docs/instrumenting/exporters/
3. Grafana
3.1 Fonte de dados

3.2 Permissões
O Grafana fornece um sistema de permissões que permite aos usuários ter diferentes permissões de acordo com diferentes funções, como visualização de painéis, edição etc.
Existem três tipos de permissões: administrador, visualizador, editor
Os usuários podem ser adicionados convidando usuários e enviando links para usuários e podem ser notificados por meio de grupos para visualizar o controle de permissão do painel
3.3 Visualização do painel
Documentação relacionada: https://grafana.com/docs/grafana/latest/panels-visualizations/
-
expressão de consulta do painel

-
Tipo de painel
O mais comum é o Graph, mais tipos podem ser baixados e importados do site oficial, preste atenção na próxima versão

-
parâmetros do painel
Se o parâmetro do eixo y for uma porcentagem, ele pode ser controlado da seguinte maneira

3.4 Painel
A integração dos vários painéis acima é o painel
-
importar
Além de personalizar os painéis, você também pode usar os painéis feitos por terceiros https://grafana.com/grafana/dashboards/ , importar através do menu Importar
-
Verificar
-
O painel de exibição pode adicionar parâmetros por meio de url e quiosque, ocultar a barra lateral e o menu superior
-
acesso anônimo
Modifique o arquivo de configuração conf/defaults.ini
[auth.anonymous] # 设置为true即可匿名访问,不用登陆就可以直接访问url enabled = true -
Aninhamento permitido
Modifique o arquivo de configuração conf/defaults.ini
# 设置为true即可嵌套 allow_embedding = true
-
-
variável
A lista suspensa pode ser implementada através de variáveis para selecionar a parte que deseja exibir: Documentação: https://grafana.com/docs/grafana/latest/dashboards/variables/
Quatro, combate real
4.1 Monitorar Windows/Linux
Windows: Baixar Exportador https://github.com/prometheus-community/windows_exporter/releases
linux: Baixe https://github.com/prometheus/node_exporter/releases
Vamos pegar as janelas como exemplo
windows_exporter.exe --collectors.enabled "[defaults],process,container"
windows_exporter.exe --config.file config.yml

item de monitoramento
| Indicadores de monitoramento | expressão |
|---|---|
| utilização do CPU | 100 - (média por (instância, região) (irate(windows_cpu_time_total{mode=“idle”}[2m])) * 100) |
| uso de memória | 100-(windows_os_physical_memory_free_bytes/windows_cs_physical_memory_bytes)*100 |
| uso total do disco | (sum(windows_logical_disk_size_bytes{volume!~“Harddisk. "}) por (instância) - sum(windows_logical_disk_free_bytes{volume!~"Harddisk. ”}) por (instance)) / sum(windows_logical_disk_size_bytes{volume!~"Harddisk. "} ) por (instância) *100 |
| Uso de disco individual | 100- 100 * (windows_logical_disk_free_bytes/windows_logical_disk_size_bytes) |
| largura de banda | (sum(irate(windows_net_bytes_total[1m])) > 1)* 8 |
| thread do sistema | windows_system_threads |
| processo do sistema | windows_os_processes |
4.2 Monitorando JVMs
Baixar Exportador: https://github.com/prometheus/jmx_exporter/releases
java -javaagent:jmx_prometheus_javaagent-0.18.0.jar=12345:config.yml -jar vhr-web-0.0.1-SNAPSHOT.jar
rules:
- pattern: ".*"

| Indicadores de monitoramento | expressão |
|---|---|
| uso de memória heap jvm | jvm_memory_bytes_used{area=“pilha”} |
| Uso da área do Éden | jvm_memory_pool_bytes_used{pool=“PS Eden Space”} |
| Uso de área antiga | jvm_memory_pool_bytes_used{pool=“PS Old Gen”} |
| Uso de metaespaço | jvm_memory_pool_bytes_used{pool=“Metaespaço”} |
| tempo gc | aumentar(jvm_gc_collection_seconds_sum[$__interval]) |
| tempos de crescimento gc | aumentar(jvm_gc_collection_seconds_count[$__interval]) |
4.3 Monitorando o MySQL
https://github.com/prometheus/mysqld_exporter/releases
mysqld_exporter.exe --config.my-cnf config.cnf --web.listen-address=localhost:9104
[client]
user=root
password=

| Indicadores de monitoramento | expressão |
|---|---|
| Conexões | sum(max_over_time(mysql_global_status_threads_connected[$__interval])) |
| Número de consultas lentas | sum(rate(mysql_global_status_slow_queries[$__interval])) |
| Número médio de threads em execução | sum(avg_over_time(mysql_global_status_threads_running[$__interval])) |
| QPS atual | rate(mysql_global_status_queries[$__interval]) |
4.4 Monitorando a API do Springboot
Às vezes, no projeto Springboot, é necessário contar o número de chamadas e tempos de chamada da interface API. Você pode usar atuador+micrômetro, e duas anotações internas foram incorporadas para realizar ambas as funções. Como o aop é usado, o pacote aop precisa ser importado
Documentação: https://docs.spring.io/spring-boot/docs/current/reference/html/actuator.html#actuator.enabling
<dependency>
<groupId>io.micrometer</groupId>
<artifactId>micrometer-registry-prometheus</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-actuator</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-aop</artifactId>
</dependency>
management:
metrics:
tags:
application: ${
spring.application.name}
web:
server:
max-uri-tags: 200
endpoints:
web:
exposure:
include: prometheus
spring:
application:
name: prometheus-test-api
@Bean
public TimedAspect timedAspect(MeterRegistry registry) {
return new TimedAspect(registry);
}
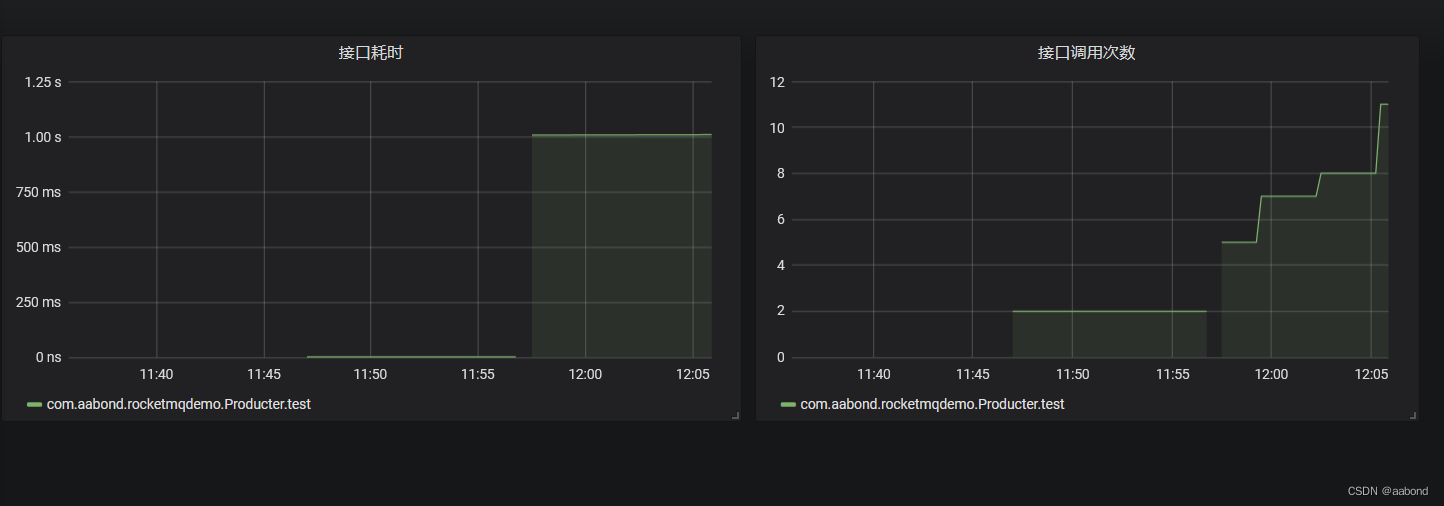
@GetMapping("/test")
@Timed(value = "test_method",description = "测试接口耗时")
@Counted(value = "test_method", description = "测试接口次数")
public String test() {
//try {
// Thread.sleep(1000);
//} catch (InterruptedException e) {
// throw new RuntimeException(e);
//}
return "ok";
}