Diretório de artigos
prefácio
Este artigo é o primeiro da coluna Segmentação de imagens. A segmentação de imagem é uma parte muito importante de todo o processo de processamento de imagem. A maior parte é usada como uma etapa de pré-processamento de todo o processamento de imagem. O objetivo da segmentação é principalmente obter a área ROI e estabelecer uma base sólida para a extração subsequente de recursos e reconhecimento de padrões. .
Este artigo apresenta principalmente como usar o método Kmeans para segmentação de imagens.
1. O que é Kmeans?
Kmeans é um algoritmo de agrupamento simples que divide os dados de entrada em categorias K. Esse algoritmo pode extrair continuamente o ponto central da classificação atual e, finalmente, concluir o agrupamento quando a classificação estiver estável. Essencialmente, Kmeans é um algoritmo iterativo.
O objetivo geral do algoritmo Kmeans é classificar os dados, deixar o computador analisar os dados e dividi-los automaticamente em k categorias. A imagem é, na verdade, uma matriz bidimensional ou tridimensional, e a classificação Kmeans da imagem completará naturalmente a segmentação.
2. Como usar o Kmeans
1. Função Kmeans em opencv
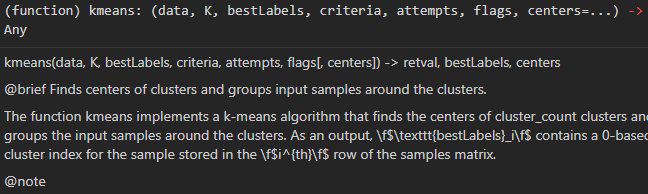
Esta imagem é a análise de parâmetros da função Kmeans em opencv-python.Há muita informação na Internet, então não vou entrar em detalhes aqui.
2. Exemplo de código Kmeans
Classifique dados unidimensionais
from sys import flags
from cv2 import cv2
from matplotlib.image import imread
import numpy as np
from matplotlib import pyplot as plt
from numpy.core.defchararray import center
'''
Kmeans对一维数据进行聚类
'''
# 随机生成小米和大米两组数据,小米数值特征范围0到50,大米特征范围200到250,都是60个
xiaomi = np.random.randint(0,50,60)
dami = np.random.randint(200,250,60)
# 将大米小米数据按水平线方向合并,得到(120,)
mi = np.hstack((xiaomi,dami))
# print(mi.dtype)
# print(mi.shape)
# 将mi的形状变成一维向量,并且数据类型变成Kmeans需要的float32
mi = mi.reshape((120,1))
mi = np.float32(mi)
# 设置Kmeans的终止条件
critera = (cv2.TermCriteria_EPS+cv2.TermCriteria_MAX_ITER,10,1.0)
# 设置Kmeans的初始化方式
flags = cv2.KMEANS_RANDOM_CENTERS
# 将数据传入,进行聚类
r,best,center = cv2.kmeans(mi,2,None,criteria=critera,attempts=10,flags=flags)
print(r)
print(best)
print(center)
# 标签为0的是小米,将该结果数据利用逻辑索引取出赋给新变量xiaomi
xm = mi[best==0]
dm = mi[best==1]
# 展示结果
plt.plot(xm,'ro')
plt.plot(dm,'bo')
plt.plot(center[0],'rx')
plt.plot(center[1],'bx')
plt.show()
O resultado é mostrado na figura abaixo
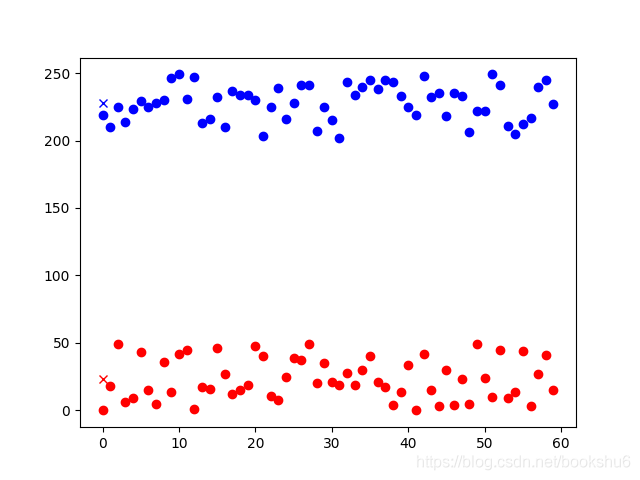
Classifique os dados bidimensionais
# 每组数据是二维,xiaomi数据是(30,2)的size,且数据范围是0到20,dami的size也是(30,2),范围是40到60
xiaomi = np.random.randint(0,20,(30,2))
dami = np.random.randint(40,60,(30,2))
# 将两种数据按照垂直方式合并,得到(60,2)
mi = np.vstack((xiaomi,dami))
print(mi.dtype)
print(mi.shape)
# 转换数据格式
mi = np.float32(mi)
# 设置Kmeans函数参数
critera = (cv2.TermCriteria_EPS+cv2.TermCriteria_MAX_ITER,10,1.0)
flags = cv2.KMEANS_RANDOM_CENTERS
r,best,center = cv2.kmeans(mi,2,None,criteria=critera,attempts=10,flags=flags)
print(r)
print(best.shape)
print(center)
# 因为是二维数据,得到的标签不是(120,),而是(120,1),是一个一维向量,所以逻辑索引和上面有的区别
xm = mi[best[:,0]==0]
dm = mi[best[:,0]==1]
plt.scatter(xm[:,0],xm[:,1],c='g',marker='s')
plt.scatter(dm[:,0],dm[:,1],c='r',marker='s')
plt.xlabel('height'),plt.ylabel('width')
plt.show()

Segmente a imagem
# 对图像用kmeans聚类
# 显示图片的函数
def show(winname,src):
cv2.namedWindow(winname,cv2.WINDOW_GUI_NORMAL)
cv2.imshow(winname,src)
cv2.waitKey()
img = cv2.imread('segmentation/1.jpg')
o = img.copy()
print(img.shape)
# 将一个像素点的rgb值作为一个单元处理,这一点很重要
data = img.reshape((-1,3))
print(data.shape)
# 转换数据类型
data = np.float32(data)
# 设置Kmeans参数
critera = (cv2.TermCriteria_EPS+cv2.TermCriteria_MAX_ITER,10,0.1)
flags = cv2.KMEANS_RANDOM_CENTERS
# 对图片进行四分类
r,best,center = cv2.kmeans(data,4,None,criteria=critera,attempts=10,flags=flags)
print(r)
print(best.shape)
print(center)
center = np.uint8(center)
# 将不同分类的数据重新赋予另外一种颜色,实现分割图片
data[best.ravel()==1] = (0,0,0)
data[best.ravel()==0] = (255,0,0)
data[best.ravel()==2] = (0,0,255)
data[best.ravel()==3] = (0,255,0)
# 将结果转换为图片需要的格式
data = np.uint8(data)
oi = data.reshape((img.shape))
# 显示图片
show('img',img)
show('res',oi)
Imagem original

Resultado imagem

Resumir
A segmentação da imagem do Kmeans é essencialmente baseada na segmentação em tons de cinza, pois, por se basear na segmentação em tons de cinza, será sensível a mudanças de iluminação. Mas esse tipo de segmentação é diferente da segmentação de limite tradicional, pois pode segmentar diretamente a imagem colorida e tem mais adaptabilidade do que a segmentação de limite tradicional. Obviamente, a força dessa adaptabilidade e do algoritmo Otsu (ostu) ainda precisa ser verificada.