Este artigo baseia-se principalmente nos seguintes artigos, e alguns códigos abaixo são explicados em detalhes neste artigo
1. "K" e "significa"
K: Existem k centróides (clusters).
significa: O centróide é a média de todos os pontos em um cluster.
K-means pertence ao hard clustering. O cluster rígido significa que os dados podem pertencer apenas a um cluster, ao contrário do cluster flexível: os dados podem pertencer a várias classes em graus variados.
2. Etapas do algoritmo
S1: Selecione o centróide inicial: selecione aleatoriamente K pontos dos pontos amostrais como o centróide.
S2: Classifique todos os pontos amostrais: calcule as distâncias de todos os pontos amostrais até os K centróides e divida-os nos clusters onde estão localizados os centros dos clusters com as distâncias mais próximas.
S3: Redeterminar o centróide: novo centróide = média de todos os pontos no cluster.
S4: Atualização do loop: Repita os passos S2 e S3 até que o centro de massa não mude mais.
3. Fluxograma

4. Código
import numpy as np
import matplotlib.pyplot as plt
img = plt.imread('1.jpg')
row = img.shape[0]
col = img.shape[1]
plt.subplot(121)
plt.imshow(img)
def knn(data, iter, k):
data = data.reshape(-1, 3)
data = np.column_stack((data, np.ones(row*col)))
# 1.随机产生初始簇心
cluster_center = data[np.random.choice(row*col, k)]
# 2.分类
distance = [[] for i in range(k)]
for i in range(iter):
print("迭代次数:", i)
# 2.1距离计算
for j in range(k):
distance[j] = np.sqrt(np.sum((data - cluster_center[j])**2, axis=1))
# 2.2归类
data[:, 3] = np.argmin(distance, axis=0)
# 3.计算新簇心
for j in range(k):
cluster_center[j] = np.mean(data[data[:, 3] == j], axis=0)
return data[:, 3]
if __name__ == "__main__":
image_show = knn(img, 100, 2)
image_show = image_show.reshape(row, col)
plt.subplot(122)
plt.imshow(image_show, cmap='gray')
plt.show()
5. Como usar o código?
O primeiro passo é colocar a imagem a ser dividida no arquivo do projeto, assim:
A segunda etapa, a terceira linha do código: 'img = plt.imread()', adicione o caminho da imagem entre colchetes: "nome da imagem. formato do arquivo", por exemplo, 1.jpeg, 2.bmp e assim por diante .
6. Resultados da execução
1. Repita 100 vezes, o número total de clusters = 5

2. Repita 10 vezes, o número total de clusters = 2

7. Explicação do código principal
7.1 Processo de processamento de informações de imagem
7.1.1 Imagem → Matriz tridimensional (altura da imagem, largura da imagem, 3)
img = plt.imread(‘path’)7.1.2 Array tridimensional (altura da imagem, largura da imagem, 3) → array bidimensional (largura da imagem*altura, 3)
img = img.reshape(-1, 3)7.1.3 (-1, 3) matriz → (-1, 4) matriz
Adicione 1 coluna para armazenar informações de classificação
img = np.column__stack((img, np.ones(row*col)))7.1.4 Resultado de retorno do algoritmo kmeans
Retorna apenas os resultados da classificação de todos os pixels
return img[:, 3]7.2 Representando imagens com arrays
7.2.1 Descrevendo pixels
Uma matriz unidimensional [R, G, B] pode representar um pixel, o conteúdo da matriz é o valor das três cores primárias e o tamanho do elemento da matriz ∈ [0, 255].
7.2.2 Descrevendo fotos
Uma matriz tridimensional pode representar uma imagem.Se a resolução da imagem for m*n, então a forma da matriz é (n, m, 3). Esta matriz tridimensional descreve a informação RGB de todos os pixels (m*n no total) da imagem.
(n, m, 3):n个形状为(m, 3)的2维数组。
n:图片的高
m:图片的宽
3:[RGB]长=3
7.3plt.imread()
7.3.1 Sintaxe
img = plt.read(‘图片路径’)7.3.2 Função
Extraia as informações da imagem em uma matriz (converta a imagem em uma matriz).
7.3.3 Tipo de valor de retorno
Tipo de valor de retorno: matriz numpy
<class 'numpy.ndarray'>7.3.4 Conteúdo do valor de retorno
Suponha que a resolução da imagem = m * n, largura * altura
- Se for uma imagem em tons de cinza, retorne uma matriz 2D de formato (n, m).
- Se for uma imagem RGB, retorne uma matriz tridimensional de forma (n, m, 3).
7.3.5 Exemplos
Leia uma foto e obtenha uma matriz 3D contendo todas as informações sobre essa foto.
A resolução da foto = 371*543
import numpy as np
import matplotlib.pyplot as plt
img = plt.imread('1.jpg') # 读入图片
print(img.shape, type(img))
print(img)
plt.imshow(img) # 利用数组显示图片
plt.show()
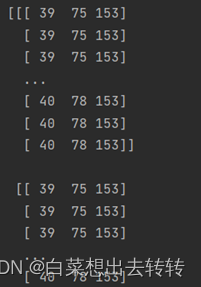
输出:(543, 371, 3) <class 'numpy.ndarray'>
输出:img记录着所有像素点的RGB值:
7.4plt.imshow()
7.4.1 Função: Array -> Imagem
Mapeie as informações RGB armazenadas na matriz em uma imagem colorida.
7.4.2 Sintaxe
plt.imshow(img, cmap='gray')
plt.imshow(img) # hsv图片
plt.show()
img é um array tridimensional contendo todas as informações da imagem.
O parâmetro cmap em plt.imshow() tem dois valores: gray (representação em tons de cinza), hsv (espaço de cores hsv) e o valor padrão é hsv.
7.4.3 Forma da matriz
(1) Tridimensional: O array extraído da imagem é tridimensional e pode ser exibido normalmente por plt.imshow().
(2) Bidimensional: O resultado da segmentação da imagem é um array bidimensional, e cada elemento do array corresponde a um tipo de pixel. Se a imagem tiver 3 tipos de clusters, então o valor da matriz bidimensional é [0, 1, 2], representando diferentes tipos de pertença.
7.4.4 Características das imagens exibidas por diferentes formas de matriz
Seja um array bidimensional ou tridimensional, quando expresso por plt.imshow(img), se o parâmetro cmap não estiver definido, o padrão é hsv.
Em particular, o tipo de cor da imagem exibida pela matriz bidimensional é igual ao número de valores possíveis dos elementos da matriz bidimensional, para que os resultados da segmentação possam ser distinguidos. Abaixo, a segmentação dos dois clusters.

7.5plt.show()
7.5.1 Função
imagem de exibição.
7.5.2 Características: Bloqueio
Quando plt.show() é executado, o programa é bloqueado nesta linha e não desce até que a janela da imagem seja fechada, o programa prossegue para baixo.
7.6 Gerar corações de cluster aleatoriamente
7.6.1 Indexação de matriz bidimensional
Em geral, para uma matriz bidimensional, use 1 ou 1 par de números para indexar uma linha ou um elemento da matriz, respectivamente.
Também pode ser indexado com um vetor para obter uma matriz de linhas especificadas.
Em seguida, indexe uma matriz bidimensional com um vetor:
import numpy as np
x = np.array([[1, 2], [3, 4], [5, 6], [7, 8], [9, 10]])
print( x[0] ) #[1, 2]
print( x[0,0,] ) # 1
print( x[[0, 1, 2]] ) #[[1, 2], [3, 4], [5, 6]]
7.6.2 Gerar k corações de cluster aleatoriamente
Primeiro, gere aleatoriamente um vetor de comprimento k de [0, linha*col-1] e, em seguida, indexe o vetor em dados para obter k pontos aleatórios
distance = np.sqrt(np.sum((x - y)**2, axis=1))como corações de cluster.
cluster_center = data[np.random.choice(row*col, k)]
#row = data.shape[0]
#col = data.shape[1]
7.7. Distância euclidiana
7.7.1 Definição de distância euclidiana
![]()
7.7.2 Implementação
distance = np.sqrt(np.sum((x - y)**2, axis=1))7.7.3 Nota: Matrizes na mesma coluna, mas em linhas diferentes, podem ser adicionadas e subtraídas.
Calcule a matriz RGB da imagem e uma distância do centro do cluster, as duas formas são: [n, 3] e [1, 3].
import numpy as np
x = np.array([[1, 2], [3, 4], [5, 6], [7, 8], [9, 10]])
y = np.array([1, 2])
print(x-y)
输出:

7.8 Classificação
7.8.1 Ideias
Crie uma nova coluna para o array tridimensional, e coloque as informações de classificação dos pixels. Se pertencer ao cluster k, a informação de classificação é armazenada como k.
O resultado final retornado por K-means: a informação correspondente a cada pixel é apenas a qual classe ele pertence, e o intervalo de valores é [0, k-1].
7.8.2 Implementação
np.argmin: Retorna o índice do menor elemento em uma linha/coluna.
data[:, 3] = np.argmin(distance, axis=0)7.9 Cálculo de novos centros de cluster
7.9.1 Princípio
Centro do cluster = o valor médio de todos os pontos no cluster, e o centro do cluster não é necessariamente o valor RGB do pixel real.
7.9.2 Implementação
for j in range(k): # k为簇的个数
cluster.center[j] = np.mean(data[data[:, 3] == j], axis=0)
Entre eles, data[data[:, 3] == j]: retorna todas as linhas com o elemento especificado.