-------往期目录------
1. Algoritmo de otimização do Lobo Cinzento
Diretório de artigos
Otimizador Skyhawk
Aquila Optimizer (AO) é inspirado no comportamento natural do Aquila na captura de presas. Portanto, o processo de otimização do algoritmo AO proposto é dividido em quatro métodos: selecionando o espaço de busca com curvatura vertical alta subida, explorando dentro do espaço de busca divergente com vôo de contorno e ataques de planeio curto, e usando vôo baixo e ataques de descida lenta em convergência Explore o espaço de busca, bem como ataque a pé e agarre a presa. Com o objetivo de verificar a capacidade do novo otimizador em encontrar soluções ótimas para diferentes problemas de otimização, uma série de experimentos foram conduzidos.
提示:以下是本篇文章正文内容,下面案例可供参考
1. O primeiro método de pesquisa
Aquila identifica áreas de presas e seleciona as melhores áreas de caça voando verticalmente com uma inclinação. Aqui, os Skyhawks voam do alto até os exploradores para determinar uma área de 170° do espaço de busca onde a presa está. A Figura 1 mostra o comportamento de Aquila voando verticalmente e curvando-se. Este comportamento é representado matematicamente pela seguinte equação.
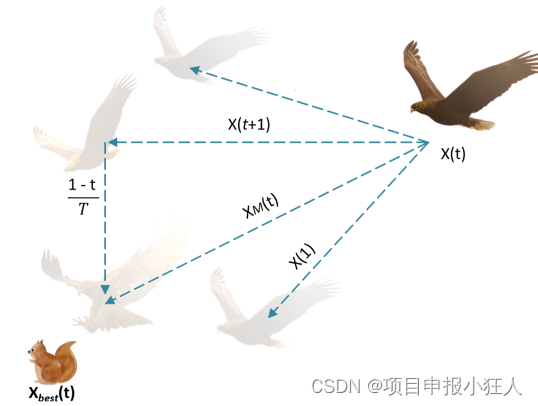
Figura 1: Comportamento de flexão vertical de Aquila
X 1 ( t + 1 ) = X best ( t ) × ( 1 − t T ) + ( XM ( t ) − (t+1)=X_{best}(t)\times\ esquerda(1-{\frac{t}{T}}\direita)+(X_{M}(t)-X_{melhor}(t) *rand)X1( t+1 )=Xmelhor _ _( t )×( 1-Tt)+( XM( t )-Xmelhor _ _( t )∗r e d )
XM ( t ) = 1 N ∑ i = 1 NX i ( t ) , ∀ j = 1 , 2 , . . . , D im X_{M}(t)={\frac{1}{N}}\sum_{i=1}^{N}X_{i}(t),\forall j=1,2,.. .,D euXM( t )=N1eu = 1∑NXeu( t ) ,∀j _=1 ,2 ,... ,D imonde
,X 1 ( t + 1 ) X_{1}(t+1)X1( t+1 ) é a solução da próxima iteração de t, determinada pelo primeiro método de busca (X 1 X_{1}X1)definição X melhor ( t ) X_{melhor}(t)Xmelhor _ _( t ) é a melhor solução obtida até a t-ésima iteração, que reflete a posição aproximada da presa. Esta equação1 − t T 1-{\frac{t}{T}}1-TtUsado para controlar a pesquisa estendida (exploração) por meio de iterações. XM(t)X_M(t)XM( t ) representa a média da posição da solução atual conectada na t-ésima iteração,rand ∈ [0, 1] rand∈[0,1]r e d∈[ 0 ,1 ] .
2. O segundo método de pesquisa
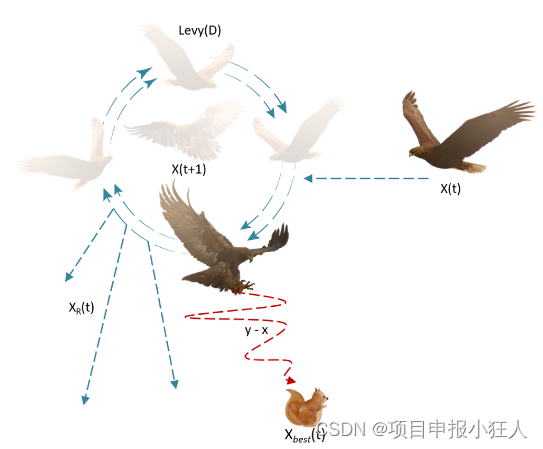
X 2 ( t + 1 ) = X melhor ( t ) × L evy ( D ) + XR ( t ) + ( y − x ) ∗ rand , X_{2}(t+1)=X_{melhor}(t) \vezes L evy(D)+X_{R}(t)+(yx)*rand,X2( t+1 )=Xmelhor _ _( t )×L e v y ( D )+XR( t )+( você-x )∗rand e ,
ondeX 2 ( t + 1 ) X_2(t+1 )X2( t+1 ) étA solução da próxima iteração de t é determinada pelo segundo método de busca X 2 X_2X2Gerar, DDD é o espaço dimensional,Levy (D) Levy (D)L e v y ( D )是imposiçãofunção de distribuição de voo l e v y , calculada usando a fórmulaXR ( t ) X_R(t)XR( t ) é ottºEm [1, N] [1,N]durante t iterações[ 1 ,Solução aleatória tomada dentro do intervalo de N ]
. L evy ( D ) = s × u × σ ∣ v ∣ 1 β L evy(D)=s\times{\frac{u\times\sigma}{|v|^ {\frac{1}{β}}}}L e v y ( D )=é×∣ v ∣b1você×p
onde s é um valor constante fixado em 0,01, uuvocê somavvv é0 0Número aleatório entre 0 e 1, σ σσ use os seguintes cálculos:
σ = Γ ( 1 + β ) × sin ( π β 2 ) Γ ( 1 + β 2 ) × β × 2 β − 1 2 \sigma={\frac{\Gamma(1+ \ beta)\times\sin\left({\frac{\pi\beta}{2}}\right)}{\Gamma\left({\frac{1+\beta}{2}}\right)\ times \beta\times2^{\frac{\beta-1}{2}}}}p=C(21 + b)×b×22b - 1C ( 1+b )×pecado(2pb _)
Mesmo a proporção β é de cerca de 1,5%.
r = r 1 + U × D 1 θ = − ω × D 1 + θ 1 θ 1 = 3 × π 2 \begin{array}{c}{ {r=r_{1}+U\times D_
{1} }}\\ {
{}}\\ {
{\theta=-\omega\times D_{1}+\theta_{1}}}\\ {
{}}\\ {
{\theta_{1}=\frac {3\times\in}{2}}}\end{array}R=R1+você×D1eu=- Ah×D1+eu1eu1=23 × π
R 1 ∈ [ 1 , 20 ] R_1∈[1,20]R1∈[ 1 ,20 ] , usado para número de ciclo de pesquisa fixo,UUU é um valor pequeno fixado em 0,00565. D 1 D_1D1é um número inteiro de 1 ao comprimento do espaço de busca (Dim), ω \omegaω é um valor pequeno fixado em 0,005. O comportamento de AO é mostrado na forma de uma espiral
x = r × sin ( θ ) y = r × cos ( θ ) r = − 0,005 × D 1 + 3 × π 2 \begin{array}{c}{ {x=
r \times s\mathrm{in}(\theta)}}\\ {
{y=r\times\cos(\theta)}}\\ { {
r=-0,005\times D_{1}+ \frac{3 \times\pi}{2}}}\end{matriz}x=R×está em ( eu )sim=R×porque ( θ )R=−0,005 _×D1+23 × π
3. O terceiro método de pesquisa
No terceiro método (X3), quando a área de presa é designada com precisão e o skyhawk se prepara para pousar e atacar, o skyhawk desce verticalmente e faz um ataque preliminar para detectar a reação da presa.
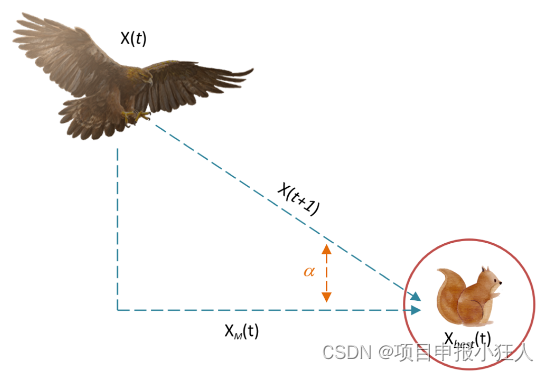
Um voo de baixa altitude conhecido como ataque de descida lenta. Aqui, o AO utiliza uma área selecionada do alvo para se aproximar da presa e atacar. A figura mostra o comportamento do ataque de descida lenta de voo de baixa altitude Aquila
X 3 ( t + 1 ) = ( X best ( t ) − X_{3}(t+1)=(X_{best}(t)-X_{M }(t))\times\alpha-r an d+((U BL B)\times correu d+LB)\times \deltaX3( t+1 )=( Xmelhor _ _( t )-XM( t ))×a-r e d+(( U B-L. B )×r e d+L. B )×δ
X 3 (t + 1) X_3(t+1)X3( t+1 ) é determinado pelo terceiro método de pesquisaX 3 X_3X3A solução gerada para a próxima iteração de t. XMelhor(t)X_Melhor(t)XBes t ( t ) refere-se à posição aproximada da presa antes da i-ésima iteração (a melhor solução obtida),XM (t) X_M(t)XM( t ) é a média da solução atual na t-ésima iteração, calculada usando a Eq. rand é um valor aleatório entre 0 e 1. α \alfaα和δ \deltaδ é o parâmetro de ajuste de desenvolvimento fixado em um valor pequeno (0,1) neste artigo. LB L_BeuBRepresenta o limite inferior do problema em questão, UB U_BvocêBRepresenta o limite superior de 200.
4. O quarto método de pesquisa
Ao se aproximar da presa, Áquila ataca a presa em terra com base em seus movimentos aleatórios. Este método é chamado de caminhar e capturar presas. Aqui, finalmente, o AO ataca a presa na última posição. A figura mostra Áquila caminhando e capturando presas.
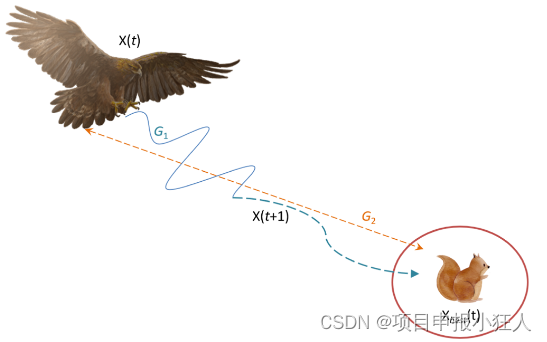
X 4 ( t + 1 ) = QF × }{
{X_{4}(t+1)=QF\vezes X_{bex}(t)-(G_{1}\vezes X(t)\vezes rand)- G_{2}\times L e\nu y(D)+rand×G_1}}\\{
{}}\end{array}X4( t+1 )=QF×Xb e x( t )-( G1×X ( t )×r e d )-G2×L e ν y ( D )+r e d×G1
QF ( t ) = trand − 1 ( 1 − T ) 2 QF(t)=t^{\frac{rand-1}{(1-T)^{2}}}QF ( t )=t( 1 - T )2r e d − 1
G 1 = 2 × rand − 1 G 2 = 2 × ( 1 − t T ) \begin{array}{c}{ {
G_{1}=2\times correu d-1}}\\ {
{}}\ \ {
{G_{2}=2\times\left(1-\frac{t}{T}\right)}}\end{array}G1=2×r e d-1G2=2×( 1-Tt)
QF( t ) QF(t)QF ( t ) é o primeiroithi^{th}euValor da função de qualidade nas iterações ,rand randr e d são valores aleatórios entre 0 e 1. t e T representam a iteração atual e o número máximo de iterações, respectivamente. Taxa (D) Taxa (D)Levy ( D ) é o imposto calculado usando a Eq .função de distribuição de voo l e v y
Código
完整代码请私信领取:
function [Best_FF,Best_P,conv]=AO(N,T,LB,UB,Dim,F_obj)
Best_P=zeros(1,Dim);
Best_FF=inf;
X=initialization(N,Dim,UB,LB);
Xnew=X;
Ffun=zeros(1,size(X,1));
Ffun_new=zeros(1,size(Xnew,1));
t=1;
alpha=0.1;
delta=0.1;
while t<T+1
for i=1:size(X,1)
F_UB=X(i,:)>UB;
F_LB=X(i,:)<LB;
X(i,:)=(X(i,:).*(~(F_UB+F_LB)))+UB.*F_UB+LB.*F_LB;
Ffun(1,i)=F_obj(X(i,:));
if Ffun(1,i)<Best_FF
Best_FF=Ffun(1,i);
Best_P=X(i,:);
end
end
G2=2*rand()-1; % Eq. (16)
G1=2*(1-(t/T)); % Eq. (17)
to = 1:Dim;
u = .0265;
r0 = 10;
r = r0 +u*to;
omega = .005;
phi0 = 3*pi/2;
phi = -omega*to+phi0;
x = r .* sin(phi); % Eq. (9)
y = r .* cos(phi); % Eq. (10)
QF=t^((2*rand()-1)/(1-T)^2); % Eq. (15)
%-------------------------------------------------------------------------------------
for i=1:size(X,1)
%-------------------------------------------------------------------------------------
if t<=(2/3)*T
if rand <0.5
Xnew(i,:)=Best_P(1,:)*(1-t/T)+(mean(X(i,:))-Best_P(1,:))*rand(); % Eq. (3) and Eq. (4)
Ffun_new(1,i)=F_obj(Xnew(i,:));
if Ffun_new(1,i)<Ffun(1,i)
X(i,:)=Xnew(i,:);
Ffun(1,i)=Ffun_new(1,i);
end
else
%-------------------------------------------------------------------------------------
Xnew(i,:)=Best_P(1,:).*Levy(Dim)+X((floor(N*rand()+1)),:)+(y-x)*rand; % Eq. (5)
Ffun_new(1,i)=F_obj(Xnew(i,:));
if Ffun_new(1,i)<Ffun(1,i)
X(i,:)=Xnew(i,:);
Ffun(1,i)=Ffun_new(1,i);
end
end
%-------------------------------------------------------------------------------------
else
if rand<0.5
Xnew(i,:)=(Best_P(1,:)-mean(X))*alpha-rand+((UB-LB)*rand+LB)*delta; % Eq. (13)
Ffun_new(1,i)=F_obj(Xnew(i,:));
if Ffun_new(1,i)<Ffun(1,i)
X(i,:)=Xnew(i,:);
Ffun(1,i)=Ffun_new(1,i);
end
else
%-------------------------------------------------------------------------------------
Xnew(i,:)=QF*Best_P(1,:)-(G2*X(i,:)*rand)-G1.*Levy(Dim)+rand*G2; % Eq. (14)
Ffun_new(1,i)=F_obj(Xnew(i,:));
if Ffun_new(1,i)<Ffun(1,i)
X(i,:)=Xnew(i,:);
Ffun(1,i)=Ffun_new(1,i);
end
end
end
end
%-------------------------------------------------------------------------------------
if mod(t,100)==0
display(['At iteration ', num2str(t), ' the best solution fitness is ', num2str(Best_FF)]);
end
conv(t)=Best_FF;
t=t+1;
end
end
function o=Levy(d)
beta=1.5;
sigma=(gamma(1+beta)*sin(pi*beta/2)/(gamma((1+beta)/2)*beta*2^((beta-1)/2)))^(1/beta);
u=randn(1,d)*sigma;v=randn(1,d);step=u./abs(v).^(1/beta);
o=step;
end
Abualigah, L., Yousri, D., Elaziz, MA, Ewees, AA, A. Al-qaness, MA, Gandomi, AH, Aquila Optimizer: Um novo algoritmo de otimização meta-heurística, Computadores e Engenharia Industrial (2021), doi : https://doi.org/10.1016/j.cie.2021.107250