Na postagem do blog "Na era pós-epidêmica, a ciência de dados capacita a melhoria da qualidade do serviço da indústria do turismo" , apresentamos os antecedentes e a solução do projeto de análise de texto do TripAdvisor e mostramos os resultados finais da análise. A seguir, para os leitores interessados em PNL em chinês e inglês, explicaremos em detalhes os princípios e a implementação de código envolvidos nas etapas de coleta de dados, armazenamento de dados, limpeza de dados e modelagem de dados. Devido a limitações de espaço, a primeira parte se concentrará nas três etapas de coleta de dados, armazenamento e limpeza de dados, e a segunda parte explicará o processo completo de modelagem de dados.
coleção de dados
1. Análise do rastreador
A raspagem da Web é uma das maneiras de obter dados da Internet. Para desenvolvedores que usam Python para web scraping, as ferramentas mais populares são as seguintes:
bela sopa
Beautiful Soup é a biblioteca de raspagem da web mais acessível entre várias ferramentas, que pode ajudar rapidamente os desenvolvedores a obter dados de arquivos em formato HTML ou XML. Nesse processo, o Beautiful Soup lerá a estrutura de dados desses arquivos até certo ponto e fornecerá muitas equações relacionadas à localização e obtenção de conteúdo de dados com base nisso. Além disso, a documentação abrangente e fácil de entender do Beautiful Soup e a comunidade ativa permitem que os desenvolvedores não apenas comecem rapidamente, mas também dominem-no rapidamente e usem-no com flexibilidade em seus próprios aplicativos.
No entanto, devido a essas características de trabalho, o Beautiful Soup também possui defeitos óbvios em comparação com outras bibliotecas. Em primeiro lugar, o Beautiful Soup precisa confiar em outras bibliotecas Python (como Requests) para enviar solicitações ao servidor de objetos para obter o rastreamento do conteúdo da página da Web; ele também precisa confiar em outros analisadores Python (como html.parser) para analisar o conteúdo capturado. Em segundo lugar, como o Beautiful Soup precisa ler e entender o quadro de dados de todo o arquivo com antecedência para encontrar o conteúdo posteriormente, do ponto de vista da velocidade de leitura do arquivo, o Beautiful Soup é relativamente lento. No processo de captura de muitas informações de páginas da Web, as informações necessárias podem representar apenas uma pequena parte e essa etapa de leitura não é necessária.
Scrapy
Scrapy é uma das bibliotecas de web scraping de código aberto mais populares. Seu recurso mais proeminente é sua velocidade de rastreamento rápida e, por ser baseado na estrutura de rede assíncrona Twisted, as solicitações enviadas pelos usuários são enviadas ao servidor de maneira não bloqueada mecanismo, que é melhor do que bloquear O mecanismo é mais flexível e eficiente em termos de recursos. Portanto, o Scrapy possui as seguintes funcionalidades:
- Para páginas da Web do tipo HTML, use XPath ou CSS para expressar o suporte para obtenção de dados
- Pode ser executado em uma variedade de ambientes, não apenas limitados ao Python. Linux, Windows, Mac e outros sistemas podem usar a biblioteca Scrapy.
- Escalabilidade forte
- Maior velocidade e eficiência
- Requer menos memória, recursos de CPU
Embora o Scrapy seja uma poderosa biblioteca de raspagem da Web e tenha suporte da comunidade relacionado, a documentação irregular e difícil desencoraja muitos desenvolvedores e dificulta o início.
Selênio
As origens do Selenium foram desenvolvidas para testar aplicativos da web e ele busca o conteúdo da web de uma maneira muito diferente de outras bibliotecas. O projeto estrutural do Selenium é obter os resultados retornados pela página da Web por meio de operações automatizadas da página da Web. Ele tem boa compatibilidade com Java e pode responder facilmente às solicitações AJAX e PJAX. Semelhante ao Beautiful Soup, o Selenium é relativamente fácil de começar, mas comparado com outras bibliotecas, sua maior vantagem é que ele pode lidar com a entrada de texto para obter informações ou páginas pop-up etc. de rastreamento da Web. Há um caso de ações intervenientes no navegador. Esses recursos tornam os desenvolvedores mais flexíveis nas etapas de rastreamento da Web e, portanto, o Selenium se tornou uma das bibliotecas de rastreamento da Web mais populares.
Como é necessário lidar com a entrada da barra de pesquisa, páginas pop-up e virada de página no processo de obtenção de avaliações de pontos cênicos, neste projeto, usaremos o Selenium para capturar dados de texto da página da web.
2. Compreensão preliminar dos dados e da estrutura da página da web
Cada site tem sua própria estrutura e lógica no processo de desenvolvimento. A mesma página da Web baseada em HTML, mesmo que a interface do usuário seja a mesma, o relacionamento hierárquico por trás dela pode ser bem diferente. Isso significa que, para esclarecer a lógica do rastreamento da Web, devemos não apenas entender as características da página da Web de destino, mas também entender a atualização da mesma URL no futuro e as características das páginas da Web em outras plataformas do mesmo tipo e classificar um relativamente flexível, comparando partes semelhantes, buscando lógica.
As etapas de rastreamento da versão internacional do site do TripAdvisor são semelhantes às da versão chinesa. Aqui, usamos www.tripadvisor.cn como exemplo para observar as etapas gerais desde a página inicial até as avaliações de pontos turísticos.
Etapa 1: entre na página inicial, digite o nome da atração que deseja pesquisar na barra de pesquisa e pressione Enter

Passo 2: A página é atualizada, aparece uma lista de atrações, selecione a atração alvo

Depois de pesquisar o nome da atração, precisamos bloquear a atração de destino na lista mostrada na figura. Pode haver duas camadas de superposição lógica aqui para nos ajudar a atingir esse objetivo:
- O próprio mecanismo de busca do TripAdvisor comparará o nome da atração com a entrada de pesquisa e usará sua própria lógica interna para classificar as atrações qualificadas no topo
- Depois que os resultados aparecerem, podemos usar informações como províncias e cidades para filtrar as atrações de destino
Passo 3: Clique na atração alvo, uma nova página aparecerá, mude para esta página e procure por comentários relevantes
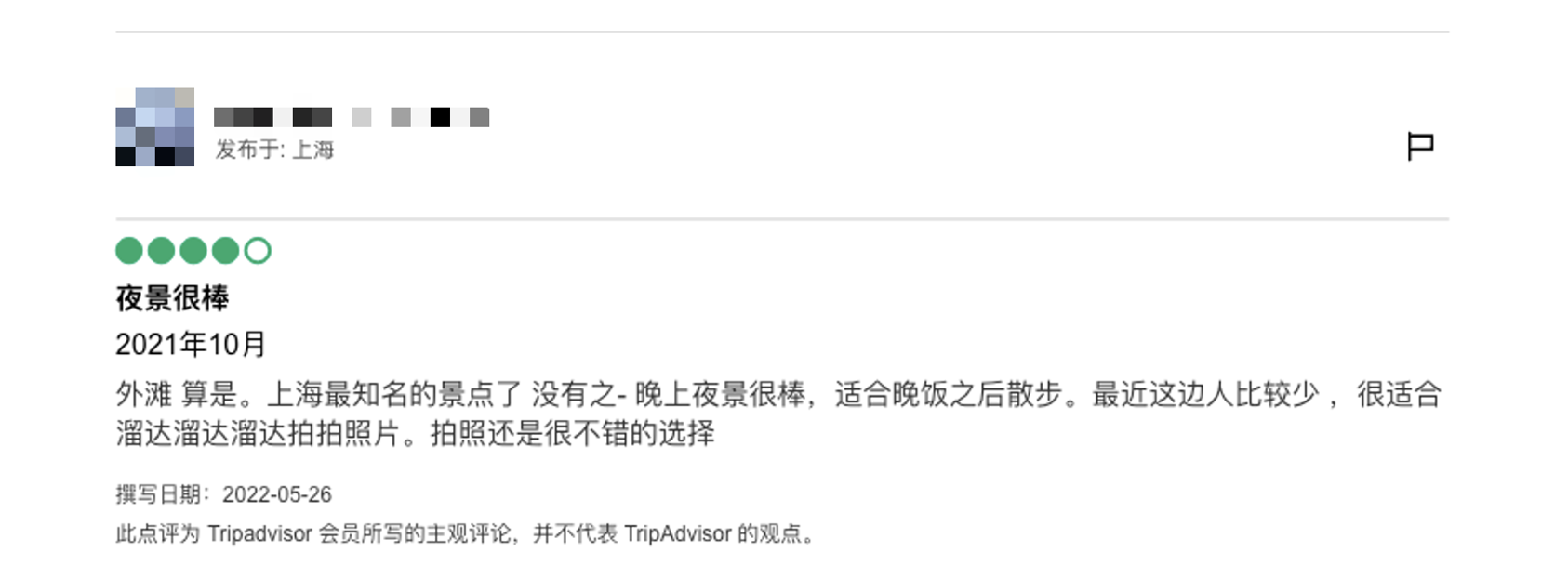
De acordo com as características do formato do comentário, as informações que podemos capturar são as seguintes:
- do utilizador
- localização do usuário
- pontuação
- título da crítica
- Data da visita
- tipo de viagem
- Comentários detalhados
- data de escrita
Passo 4: Vire a página para obter mais comentários

Pode-se observar que existem muitas ações que precisam ser realizadas pelo navegador no processo de obtenção de páginas da web relacionadas, por isso escolhemos o Selenium. Portanto, nosso rastreador da Web passa pelas mesmas etapas antes da coleta de dados.
Uma maneira muito conveniente de localizar o conteúdo necessário no código HTML ao desenvolver um programa de rastreador da web é mover o mouse para a área onde o conteúdo está localizado no navegador, clicar com o botão direito do mouse e selecionar "Inspecionar", o navegador exibirá o Elemento HTML da página da Web e Localize o código relevante para o conteúdo. Com base nessa abordagem, podemos usar o Selenium para automação e extração de dados.
Tomando como exemplo o comentário acima, sua posição na estrutura HTML é a seguinte:
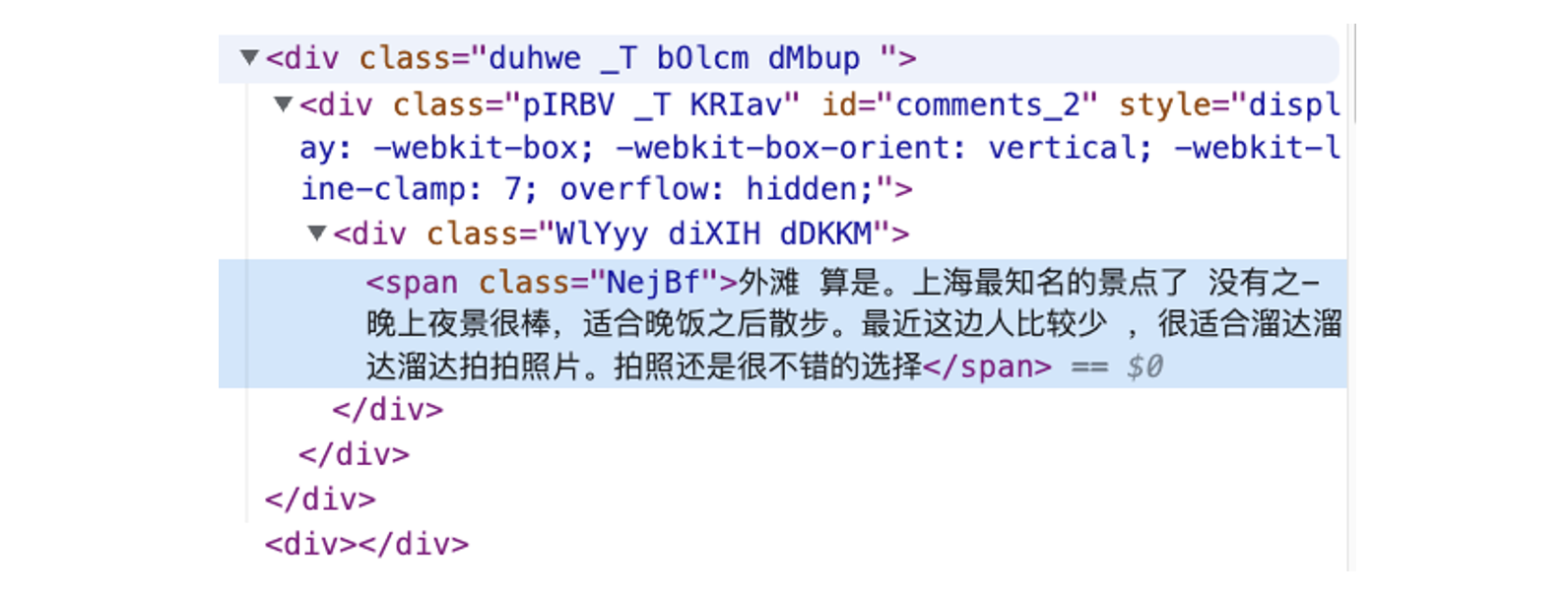
Ao usar o Selenium, categorias de elementos e nomes de classe podem nos ajudar a localizar conteúdo relevante, realizar outras operações e obter dados de texto relevantes. Podemos usar esses dois métodos de posicionamento: CSS ou XPATH, os desenvolvedores podem escolher de acordo com suas próprias necessidades. Em última análise, o processo de web scraping que realizamos pode ser dividido em duas etapas:
- Etapa 1: envie uma solicitação, use o Selenium para operar o navegador para encontrar a página de comentários do ponto cênico especificado
- Etapa 2: entre na página de comentários e pegue os dados do comentário
3. Obtenha dados de comentários
A implementação da função desta parte precisa primeiro instalar e importar as seguintes bibliotecas Python:
from selenium import webdriver
import chromedriver_binary
from webdriver_manager.chrome import ChromeDriverManager
from selenium.webdriver.common.by import By
from selenium.webdriver.common.keys import Keys
import time
import datetime
import re
import pandas as pd
from utility import print_log_message, read_from_configEntre eles, o utilitário é um módulo auxiliar que contém equações para impressão de sessões e tempos de ocorrência, e equações para leitura de informações do programa a partir de arquivos de configurações ini. As equações auxiliares no utilitário podem ser repetidas em quantos módulos forem necessários.
#utility.py
import time
import configparser
def print_log_message(app_name, procedure, message):
ts = time.localtime()
print(time.strftime("%Y-%m-%d %H:%M:%S", ts) + " **" + app_name + "** " + procedure + ":", message)
return
def read_from_config(file_name, section, var):
config = configparser.ConfigParser()
config.read(file_name)
var_value = config.get(section, var)
return var_valueAntes de iniciar o rastreamento da web, precisamos iniciar um processo de sessão da web.
# Initiate web session
chrome_options = webdriver.ChromeOptions()
chrome_options.add_argument('--no-sandbox')
chrome_options.add_argument('--window-size=1920,1080')
chrome_options.add_argument('--headless')
chrome_options.add_argument('--disable-gpu')
chrome_options.add_argument('--disable-dev-shm-usage')
wd = webdriver.Chrome(ChromeDriverManager().install(),chrome_options=chrome_options)
wd.get(self.web_url)
wd.implicitly_wait(5)
review_results = {}Considerando que o ambiente operacional não é um PC ou uma instância com recursos suficientes, precisamos indicar no código que o programa não possui requisitos de exibição. ChromeDriverManager() pode ajudar o programa a baixar o arquivo de driver necessário em um ambiente sem driver Chrome e passá-lo para o processo de sessão do Selenium.
Observe que muitas páginas da web estão relacionadas à versão do Chrome, recursos, ambiente do sistema e tempo. As páginas usadas neste projeto não são afetadas por tais informações ou circunstâncias, mas são limitadas pelas configurações de exibição do navegador, que por sua vez afetam o que é rastreado. Preste atenção para verificar se as informações exibidas na página da Web são consistentes com os dados reais capturados ao desenvolver esse tipo de programa de rastreamento.
Depois de entrar na página inicial do TripAdvisor (https://www.tripadvisor.cn/), digite o nome da atração desejada na barra de pesquisa e pressione Enter. Depois de entrar na nova página, classifique as atrações na lista de acordo com o mecanismo de busca , província e cidade, localize e clique para ir para a página correta da atração. Aqui, tomamos "The Bund" como exemplo:
location_name = '外滩'
city = '上海'
state = '上海'# Find search box
wd.find_element(By.CSS_SELECTOR, '.weiIG.Z0.Wh.fRhqZ>div>form>input').click()# Enter location name
wd.find_element(By.XPATH, '//input[@placeholder="去哪里?"]').send_keys(f'{location_name}')
wd.find_element(By.XPATH, '//input[@placeholder="去哪里?"]').send_keys(Keys.ENTER)# Find the right location with city + province info
element = wd.find_element(By.XPATH,
f'//*[@class="address-text" and contains(text(), "{city}") and contains(text(), "{state}")]')
element.click()Depois de clicar na atração alvo, mude para a nova página que salta. Depois de entrar na página de avaliação da atração, podemos obter as informações necessárias de acordo com a estrutura HTML da página e a posição da avaliação em sua hierarquia de código. Quando o Selenium está procurando por um determinado elemento, ele procurará informações relevantes em todo o quadro da página da Web e não poderá bloquear uma determinada parte como algumas outras bibliotecas de rastreamento da Web e procurará apenas o elemento desejado nesta parte. Portanto, precisamos capturar um tipo de informação uniformemente e depois eliminar algumas informações desnecessárias. Esse processo requer verificação repetida das informações exibidas na página da Web real para evitar que conteúdo indesejado seja capturado e afete a qualidade dos dados.
O código usado para rastreamento é o seguinte:
comment_section = wd.find_element(By.XPATH, '//*[@data-automation="WebPresentation_PoiReviewsAndQAWeb"]')# user id
user_elements = comment_section.find_elements(By.XPATH, '//div[@class="ffbzW _c"]/div/div/div/span[@class="WlYyy cPsXC dTqpp"]')
user_list = [x.text for x in user_elements]Para a captura de dados de comentários em inglês, além de algumas diferenças na estrutura da página da Web, os dados sobre o local são mais complicados e requerem processamento adicional. No processo de rastreamento, a vírgula padrão é o separador, o valor antes da vírgula é a cidade e o valor após a vírgula é o país.
# location
loca_elements = comment_section.find_elements(By.XPATH,
'//div[@class="ffbzW _c"]/div/div/div/div/div[@class="WlYyy diXIH bQCoY"]')
loca_list = [x.text[5:] for x in loca_elements]# trip type
trips_element = comment_section.find_elements(By.XPATH, '//*[@class="eRduX"]')
trip_types = [self.separate_trip_type(x.text) for x in trips_element]Observe que, como é relativamente difícil localizar o tempo de avaliação, a categoria de classe de texto conterá informações sobre a introdução das atrações da página da web e precisamos remover essa parte dos dados desnecessários.
# comment date
comments_date_element = comment_section.find_elements(By.CSS_SELECTOR, '.WlYyy.diXIH.cspKb.bQCoY')# drop out the first element
comments_date_element.pop(0)
comments_date = [x.text[5:] for x in comments_date_element]Como a classificação do usuário não é um texto, precisamos encontrar o elemento que a representa na estrutura HTML para calcular a classificação por estrelas. Na página HTML do TripAdvisor, o elemento estrela é "bolha". Precisamos encontrar o código relevante na estrutura HTML e extrair os dados da estrela no código.
# rating
rating_element = comment_section.find_elements(By.XPATH,
'//div[@class="dHjBB"]/div/span/div/div[@style="display: block;"]')
rating_list = []
for rating_code in rating_element:
code_string = rating_code.get_attribute('innerHTML')
s_ind = code_string.find(" bubble_")
rating_score = code_string[s_ind + len(" bubble_"):s_ind + len(" bubble_") + 1]
rating_list.append(rating_score)# comments title
comments_title_elements = comment_section.find_elements(By.XPATH,
'//*[@class="WlYyy cPsXC bLFSo cspKb dTqpp"]')
comments_title = [x.text for x in comments_title_elements]# comments content
comments_content_elements = wd.find_element(By.XPATH,
'//*[@data-automation="WebPresentation_PoiReviewsAndQAWeb"]'
).find_elements(By.XPATH, '//*[@class="duhwe _T bOlcm dMbup "]')
comments_content = [x.text for x in comments_content_elements]A lógica de encontrar imagens em comentários é a mesma de encontrar classificações de estrelas.Você deve primeiro encontrar a parte que representa as imagens na estrutura HTML e, em seguida, verificar se os comentários contêm informações de imagem no código.
# if review contains pictures
pic_sections = comment_section.find_elements(By.XPATH,
'//div[@class="ffbzW _c"]/div[@class="hotels-community-tab-common-Card__card--ihfZB hotels-community-tab-common-Card__section--4r93H comment-item"]')
pic_list = []
for r in pic_sections:
if 'background-image' in r.get_attribute('innerHTML'):
pic_list.append(1)
else:
pic_list.append(0)Para resumir, podemos pegar e integrar os dados de revisão do site do TripAdvisor de acordo com o nome da atração de entrada e o número necessário de páginas de revisão e, finalmente, salvá-lo como um Pandas DataFrame.
Todo o processo pode ser automatizado e empacotado em um arquivo .py chamado data_processor. Para obter os dados de avaliação, precisamos apenas executar a seguinte equação para obter as informações de avaliação da atração no formato Pandas DataFrame.
#引入之前定义的Python Class:
from data_processor import WebScrapper
scrapper = WebScrapper()#运行网页抓取方程抓取中文语料:
trip_review_data = scrapper.trip_advisor_zh_scrapper_runner(location, location_city, location_state, page_n=int(n_pages))Onde location representa o nome da atração, location_city e location_state representam a cidade e a província onde a atração está localizada e page_n representa o número de páginas a serem rastreadas.
Armazenamento de dados
Depois de obter os dados de comentários capturados, podemos armazenar os dados no banco de dados para compartilhamento de dados e posterior análise e modelagem. Tomando o banco de dados PieCloudDB como exemplo, podemos usar o driver Postgres SQL do Python para conectar ao PieCloudDB.
A forma como este projeto implementa o armazenamento de dados é que, após obter os dados do comentário e integrá-los em um Pandas DataFrame, usaremos o mecanismo SQLAlchemy para carregar os dados do Pandas no banco de dados por meio do psycopg2. Primeiro, precisamos definir o mecanismo para se conectar ao banco de dados:
from sqlalchemy import create_engine
import psycopg2
engine = create_engine('postgresql+psycopg2://user_name:password@db_ip:port /database')Entre eles, postgresql + psycopg2 é o driver que precisamos usar ao conectar ao banco de dados, user_name é o nome de usuário do banco de dados, password é a senha de login correspondente, db_ip é o ip do banco de dados ou endpoint, port é a interface de conexão externa do banco de dados , e database é o nome do banco de dados.
Depois de passar o mecanismo para o Pandas, podemos facilmente carregar o Pandas DataFrame no banco de dados para concluir a operação de armazenamento.
data.to_sql(table_name, engine, if_exists=‘replace’, index=False)data são os dados Pandas DataFrame que precisamos armazenar, table_name é o nome da tabela, engine é o mecanismo SQLAlchemy que definimos antes, if_exists='replace' e index=False são as opções da equação Pandas to_sql(). O significado desta opção é que se a tabela já existe, os dados existentes serão substituídos pelos dados existentes, e não precisamos considerar o índice durante o processo de armazenamento.
limpeza de dados
Nesta etapa, limparemos os dados do comentário de acordo com as características dos dados originais para prepará-los para a modelagem subsequente. Os dados de comentários capturados contêm as três categorias de informações a seguir:
- Informações do usuário (como localização, etc.)
- Informações de comentários (como incluir ou não informações de imagem, etc.)
- corpus de comentários
Antes de entrar oficialmente nesta etapa, precisamos importar as seguintes bibliotecas de código, algumas das quais serão utilizadas na etapa de modelagem de dados:
import numpy as np
import pandas as pd
import psycopg2
from sqlalchemy import create_engine
import langid
import re
import emoji
from sklearn.preprocessing import MultiLabelBinarizer
import demoji
import random
from random import sample
import itertools
from collections import Counter
import matplotlib.pyplot as pltA aplicação de informações do usuário e informações de comentários é refletida principalmente na parte de BI, e a parte de modelagem depende principalmente dos dados do corpus de comentários. Precisamos adotar métodos apropriados de limpeza, segmentação de palavras e modelagem de acordo com a linguagem do comentário. Primeiro, recuperamos os dados do banco de dados, o que pode ser feito por meio do código a seguir.
Dados de comentários chineses:
df = pd.read_sql('SELECT * FROM "上海_上海_外滩_source_review"', engine)
df.shape
Dados de avaliação em inglês:
df = pd.read_sql('SELECT * FROM "Shanghai_Shanghai_The Bund (Wai Tan)_source_review_EN"', engine)
df.shape
Rastreamos 171 páginas de comentários no site da versão chinesa, com 10 comentários por página, totalizando 1710 comentários; no site da versão internacional, capturamos 200 páginas de comentários, totalizando 2000 comentários.
1. Processamento de tipo de dados
Como os dados gravados no banco de dados são todos do tipo string, precisamos revisar e converter primeiro o tipo de dados de cada coluna de dados. Nos dados de comentários chineses, as variáveis que precisam ser transformadas são tempo de comentário e classificação.
df['comment_date'] = pd.to_datetime(df['comment_date'])
df['rating'] = df['rating'].astype(str)
df['comment_year'] = df['comment_date'].dt.year
df['comment_month'] = df['comment_date'].dt.month2. Entenda o estado dos dados
Antes de lidar com valores nulos e transformar dados, podemos navegar brevemente pelos dados e ter uma compreensão preliminar da situação do valor nulo.
df.isnull().sum()A situação geral do valor nulo dos dados de comentários chineses é a seguinte:

Diferentemente dos dados de revisão chineses, os dados de revisão ingleses precisam processar mais dados em branco, concentrados principalmente nas duas variáveis de localização do usuário e tipo de viagem.

3. Lidar com valores nulos de tipo de viagem
Para variáveis com valores nulos, podemos obter uma compreensão geral de suas características através das estatísticas de cada categoria de variáveis. Tomando como exemplo o tipo de viagem (trip_type), existem 6 tipos de variáveis, sendo uma delas o tipo de viagem não especificada pelo usuário, e este tipo de dado existe na forma de valores nulos:
df.groupby(['trip_type']).size()
Como o tipo de viagem é uma variável categórica, no caso deste projeto, preenchemos os nulos com a categoria "desconhecido" ou "NA".
Dados de comentários chineses:
df['trip_type'] = df['trip_type'].fillna('未知')Dados de avaliação em inglês:
df['trip_type'] = df['trip_type'].fillna('NA')Na análise do texto das resenhas chinesas, os tipos de viagem são divididos nos seis tipos a seguir, que correspondem ao inglês: viagem em família, viagem de negócios, viagem de casal, viagem individual, viagem com acompanhante e desconhecido. Para facilitar a análise posterior, precisamos criar uma tabela de pesquisa para corresponder aos tipos de viagem dos dois idiomas.
zh_trip_type = ['全家游', '商务行', '情侣游', '独自旅行', '结伴旅行', '未知']
en_trip_type = ['Family', 'Business', 'Couples', 'Solo', 'Friends', 'NA']
trip_type_df = pd.DataFrame({'zh_type':zh_trip_type, 'en_type':en_trip_type})Em seguida, grave a tabela no banco de dados para posterior análise visual.
trip_type_df.to_sql("tripadvisor_TripType_lookup", engine, if_exists="replace", index=False)4. Processe as informações de localização do usuário em dados de comentários em inglês
Nos dados de comentários em inglês, como a localização do usuário é a informação que o usuário preenche, os dados regionais são muito confusos e não são preenchidos em uma determinada ordem ou lógica. Os campos cidade e país não precisam apenas lidar com valores nulos, mas também precisam ser corrigidos. Ao obter dados, nossa lógica para obter informações da região é:
- Se as informações da região estiverem separadas por vírgulas, a primeira palavra é cidade e a última palavra é país/província
- Se não houver vírgula, as informações serão padronizadas para as informações do país
Para a análise da revisão da versão internacional do site, optamos por subdividir a localização dos usuários ao nível do país. Observe que, como muitos usuários têm problemas com erros de ortografia ou preenchimento de nomes de lugares falsos, nosso objetivo é corrigir as informações o máximo possível, como corrigir letras maiúsculas, abreviaturas, informações de cidades correspondentes etc. Aqui, nossa solução específica é:
- Extraia o país/província abreviado e processe-o separadamente (principalmente os Estados Unidos, os usuários só preenchem o nome do estado ao preencher as informações regionais)
- Visualize as informações do país além das abreviaturas. Se o nome do país não aparecer na lista de países, ele será considerado uma informação da cidade
- Se o nome da cidade estiver preenchido incorretamente no campo do país (como uma cidade grande) e erros de ortografia, ele deve ser modificado manualmente
Observe que os nomes de países e regiões usados neste projeto referem-se à fonte das informações de nomes de países e à fonte dos estados dos EUA e suas abreviações .
Primeiro, lemos as informações do país no sistema de arquivos:
country_file = open("countries.txt", "r")
country_data = country_file.read()
country_list = country_data.split("\n")
countries_lower = [x.lower() for x in country_list]
读取美国州名及其缩写信息:
state_code = pd.read_csv("state_code_lookup.csv")A equação a seguir pode ler uma sequência de nomes de países e determinar se a limpeza e modificação são necessárias:
def formating_country_info(s_input):
if s_input is None: #若字符串输入为空值,返回空值
return None
if s_input.strip().lower() in countries_lower: #若字符串输入在国家列表中,返回国家名
c_index = countries_lower.index(s_input.strip().lower())
return country_list[c_index]
else:
if len(s_input) == 2: #若输入为缩写,在美国州名、墨西哥省名和英国缩写中查找,若可以找到,返回对应国家名称
if s_input.strip().upper() in state_code["code"].to_list():
return "United States"
elif s_input.strip().upper() == "UK":
return "United Kingdom"
elif s_input.strip().upper() in ("RJ", "GO", "CE"):
return "Mexico"
elif s_input.strip().upper() in ("SP", "SG"):
return "Singapore"
else:
# could not detect country info
return None
else: #其他情况,需要手动修改国家名称
if s_input.strip().lower() == "caior":
return "Egypt"
else:
return NoneAgora que temos uma equação que limpa um único valor, podemos aplicar essa equação às colunas do Pandas DataFrame que representam as informações do país por meio da função .apply().
df["location_country"] = df["location_country"].apply(formating_country_info)Em seguida, verifique o resultado da limpeza:
df["location_country"].isnull().sum()![]()
Notamos que o número de valores nulos aumentou. Além de corrigir alguns dados, para alguns nomes de lugares inexistentes, a equação acima irá convertê-los em valores nulos. Em seguida, vamos pegar as informações da cidade e preencher a variável country com informações sobre os países que podem ser classificados como cidades. Podemos filtrar as informações que podem ser extraviadas de acordo com o nome do país e usar esse tipo de informação como preenchimento das informações do país, e o restante são os nomes das cidades por padrão.
def check_if_country_info(city_list):
clean_list = []
country_fill_list = []
for city in city_list:
if city is None:
clean_list.append(None)
country_fill_list.append(None)
elif city.strip().lower() in countries_lower: #如城市变量中出现的是国家名,记录国家名称
c_index = countries_lower.index(city.strip().lower())
country_name = country_list[c_index]
if country_name == "Singapore": #如城市名为新加坡,保留城市名,如不是则将原先的城市名转换为空值
clean_list.append(country_name)
else:
clean_list.append(None)
country_fill_list.append(country_name)
else:
# format city string
city_name = city.strip().lower().capitalize()
clean_list.append(city_name)
country_fill_list.append(None)
return clean_list, country_fill_listExecutando a equação acima, obteremos duas séries, uma com os dados da cidade limpa e a outra com os dados preenchidos com as informações do país.
city_list, country_fillin = check_if_country_info(df["location_city"].to_list())Crie uma nova coluna nos dados para armazenar a matriz preenchida com as informações do país.
df["country_fill_temp"] = country_fillinSubstitua as informações da cidade nos dados do comentário em inglês, preencha a coluna recém-criada com o valor vazio das informações do país e exclua a coluna usada para preenchimento.
df["location_city"] = city_list
df["location_country"] = df["location_country"].fillna(df["country_fill_temp"])
df = df.drop(columns=["country_fill_temp"])Até agora, explicamos e concluímos os princípios e a implementação de código da coleta de dados, armazenamento de dados e etapas de limpeza de dados neste projeto. Embora o processo de processamento de dados seja árduo e demorado, é muito valioso poder transformar grandes quantidades de dados brutos em dados úteis. Se você estiver interessado em etapas de modelagem de dados mais avançadas e quiser saber como implementar a análise de emojis, palavras-chave de segmentação de palavras, análise de sentimentos de texto, análise de frequência de palavras de parte do discurso e classificação de texto de modelo de tópico de dados de texto, continue a pagar atenção às postagens de blog de acompanhamento do Data Science Lab .
Referências:
- Dai Bin | O mercado de turismo da Festa da Primavera abriu em alta e a economia do turismo cresceu de forma constante ao longo do ano
- West Lake Scenic Area recebe 2,9286 milhões de turistas durante o Festival da Primavera
- Scrapy Vs Selenium Vs Beautiful Soup para Web Scraping
- Extraia Emojis de Strings Python e Frequência de Gráfico usando Spacy, Pandas e Plotly
- Modelagem de tópicos com LSA, PLSA, LDA e lda2Vec
Parte dos dados deste artigo vem da Internet, se houver alguma infração, entre em contato para excluir