Diretório de artigos
referência chinesa
Awesome-Chinese-LLM: https://github.com/HqWu-HITCS/Awesome-Chinese-LLM
Este projeto coleta e classifica modelos, aplicativos, conjuntos de dados e tutoriais de código aberto relacionados ao LLM chinês. Os recursos incluídos atualmente têm chegou a 100+!
C-Eval
C-EVAL: Uma suíte de avaliação chinesa multinível e multidisciplinar para modelos de fundação
Endereço do artigo: https://arxiv.org/pdf/2305.08322v1.pdf
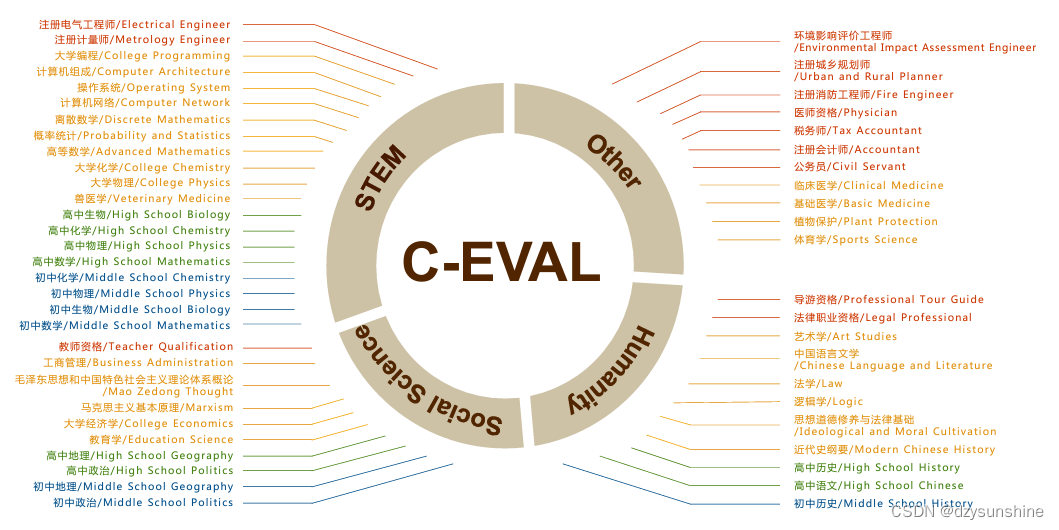
Os corpos principais de cores diferentes representam quatro níveis de dificuldade: ensino fundamental, ensino médio, universitário e profissional.
endereço do github: https://github.com/SJTU-LIT/ceval
A lista C-Eval é um kit de avaliação de modelo básico chinês abrangente (um kit de modelo básico de avaliação de linguagem multinível e multidisciplinar). Consiste em 13.948 questões de múltipla escolha abrangendo 52 assuntos diferentes e quatro níveis de dificuldade, e o conjunto de teste é usado para avaliação do modelo (em termos simples, é uma máquina de teste abrangente para modelos chineses)
Endereço da lista C-Eval: https://cevalbenchmark.com/static/leaderboard.html
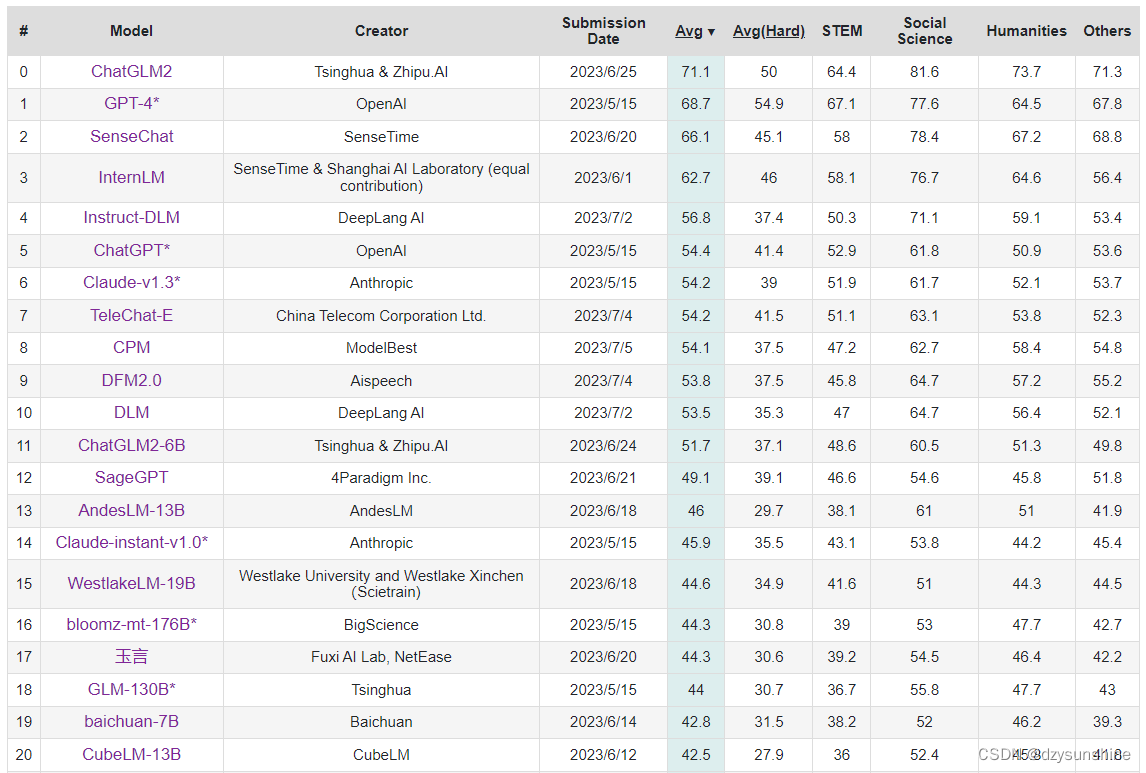
A lista mudará em tempo real.
Endereço do conjunto de dados: https://huggingface.co/datasets/ceval/ceval-exam
Gaokao
Avaliando o Desempenho de Modelos de Linguagem Grandes no endereço do documento GAOKAO Benchmark
: https://arxiv.org/abs/2305.12474
Gaokao é um conjunto abrangente de avaliação de teste com base nas questões do vestibular chinês elaboradas pela equipe de pesquisa da Universidade de Fudan.
O GAOKAO-bench é um conjunto de dados baseado em questões do vestibular chinês, com o objetivo de fornecer uma estrutura de avaliação que se alinha com os humanos, intuitivamente e avalia com eficiência a capacidade de compreensão da linguagem e a capacidade de raciocínio lógico de modelos grandes.
GAOKAO-bench coletou as questões do vestibular nacional de 2010 a 2022, incluindo 1.781 questões objetivas e 1.030 questões subjetivas. A avaliação é dividida em duas partes, a parte objetiva da avaliação automatizada e a parte subjetiva que conta com especialistas pontuação. Os resultados em duas partes compõem a pontuação final.
endereço do github: https://github.com/OpenLMLab/GAOKAO-Bench
conjunto de dados
| tipo de tópico | Número de tópicos | Relação de quantidade |
|---|---|---|
| múltipla escolha | 1781 | 63,36% |
| preencha o espaço em branco | 218 | 7,76% |
| responder a perguntas | 812 | 28,89% |
| número total de perguntas | 2811 | 100% |
O conjunto de dados contém os seguintes campos
| campo | ilustrar |
|---|---|
| palavras-chave | Assunto ano, assunto e outras informações |
| exemplo | Lista de tópicos, incluindo informações específicas do tópico |
| exemplo/ano | O ano da prova do vestibular em que o tema está localizado |
| exemplo/categoria | O tipo de prova de vestibular onde o tema está localizado |
| exemplo/pergunta | Tema |
| exemplo/resposta | Resposta da questão |
| exemplo/análise | análise de tópico |
| exemplo/índice | número do tópico |
| exemplo/pontuação | Pontuação do item |
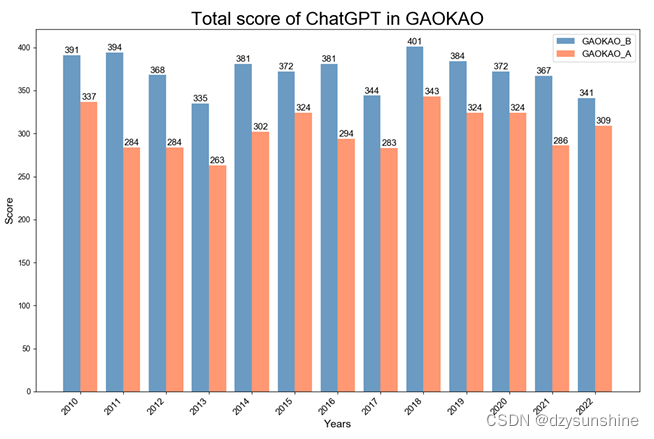
A figura abaixo mostra as notas do vestibular de gpt-3.5-turbo ao longo dos anos, em que GAOKAO-A representa disciplinas de ciências e GAOKAO-B representa disciplinas de artes liberais.
AGIEval
AGIEval: AHuman-CentricBenchmarkfor EvaluatingFoundationModels
endereço do artigo: https://arxiv.org/pdf/2304.06364.pdf
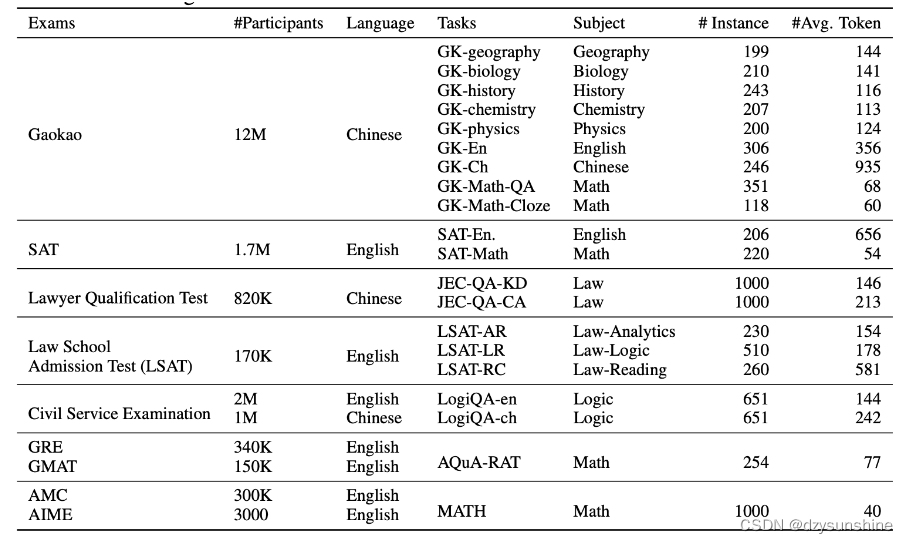
O AGIEval é um benchmark centrado no ser humano projetado especificamente para avaliar a capacidade geral dos modelos subjacentes em tarefas relacionadas à cognição humana e à resolução de problemas. A referência é derivada de 20 admissões oficiais, públicas e de alto padrão e exames de qualificação para candidatos gerais, como exames gerais de admissão em faculdades (como o Gaokao chinês e o SAT dos EUA), exames de admissão em faculdades de direito, concursos de matemática, exames de bar, Exame Nacional da Função Pública.
AGIEval v1.0 contém 20 tarefas, incluindo duas tarefas de cloze (gaokao-mathematics-cloze e math) e 18 tarefas de resposta de múltipla escolha (o resto). Nas tarefas de resposta de múltipla escolha, há uma ou mais respostas para Gaokao Physics e JEC-QA, e apenas uma resposta para as demais tarefas. Você pode encontrar uma lista completa de tarefas na tabela abaixo.
PromptCBLUE
PromptCBLUE: benchmark de avaliação LLM para cenários médicos chineses
endereço do github: https://github.com/michael-wzhu/PromptCBLUE
A fim de promover o desenvolvimento e a implementação do LLM na área médica, a equipe do professor Wang Xiaoling, da East China Normal University, lançou em conjunto o benchmark de avaliação PromptCBLUE com a plataforma Alibaba Tianchi, Huashan Hospital afiliado à Fudan University, Northeastern University, Harbin Institute of Technology (Shenzhen), Pengcheng Laboratory e Tongji University, realizou o desenvolvimento secundário do benchmark CBLUE e transformou todas as 16 tarefas diferentes de PNL em cenários médicos em tarefas de geração de linguagem com base em prompts, formando o primeiro benchmark de avaliação LLM para cenários médicos chineses. Como uma das tarefas de avaliação do CCKS-2023, o PromptCBLUE foi lançado na plataforma Alibaba Tianchi Competition para avaliação aberta.
Benchmark de Avaliação de Inglês
MMLU
Measuring Massive Multitask Language Understanding
paper address: https://arxiv.org/abs/2009.03300
MMLU é um conjunto de dados de avaliação de inglês contendo 57 tarefas de múltipla escolha, abrangendo matemática elementar, história americana, ciência da computação, direito etc. .
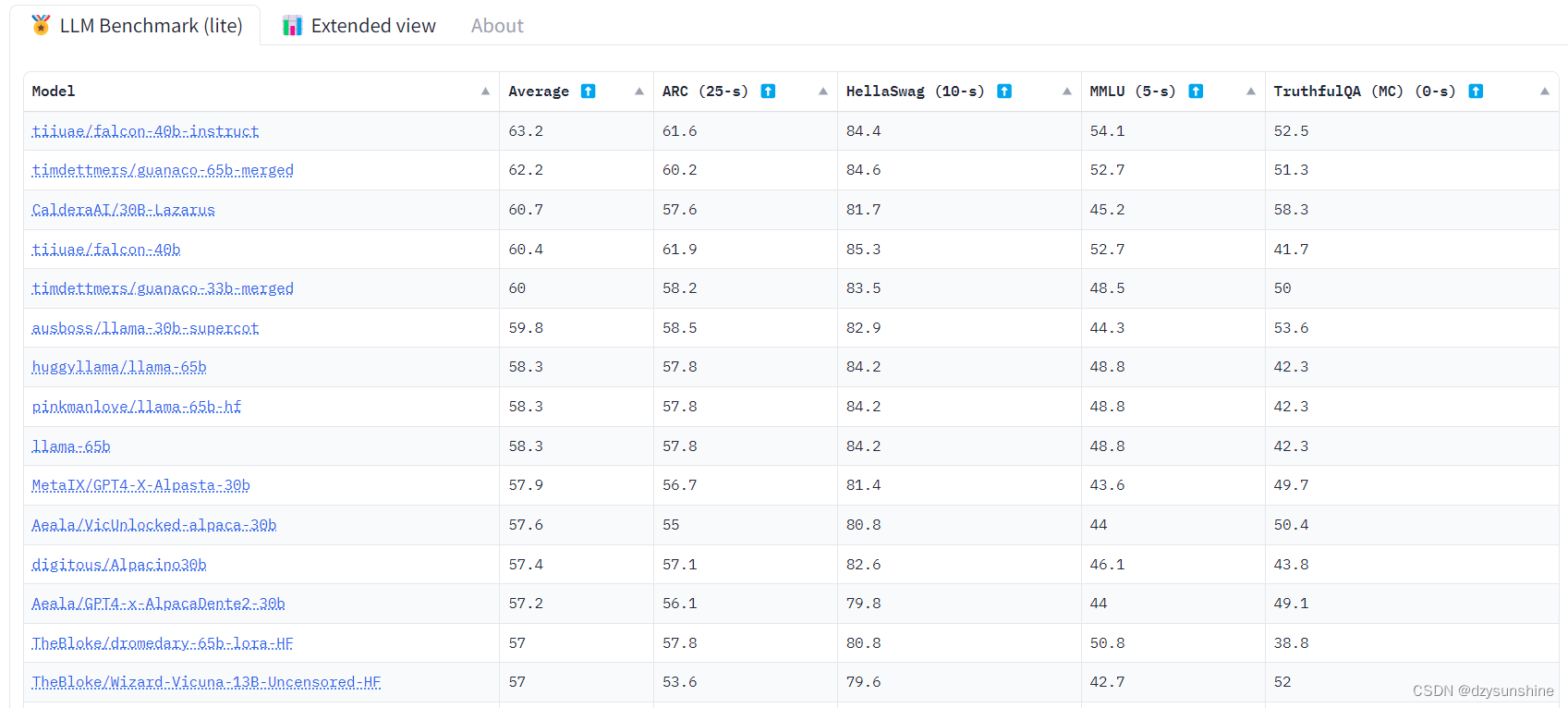
Tabela de classificação LLM aberta
Open LLM Leaderboard é uma lista de avaliação LLM organizada pela HuggingFace, que avaliou modelos LLM de código aberto mais convencionais. A avaliação inclui principalmente o desempenho em quatro conjuntos de dados do AI2 Reasoning Challenge, HellaSwag, MMLU e TruthfulQA, principalmente em inglês.
Endereço da lista: https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard