O problema da consistência de dados de gravação dupla em bancos de dados e caches (como redis) é um problema público que não tem nada a ver com a linguagem de desenvolvimento. Especialmente em cenários de alta simultaneidade, esse problema se torna mais sério. No artigo de hoje, irei do superficial ao profundo e falarei com você sobre soluções comuns para problemas de consistência de dados de gravação dupla em banco de dados e cache, possíveis armadilhas nessas soluções e qual é a solução ideal.
Em teoria, definir um tempo de expiração para o cache é uma solução para garantir consistência eventual. Nesse esquema, podemos definir um tempo de expiração para os dados armazenados no cache, todas as operações de gravação estão sujeitas ao banco de dados e fazemos o possível apenas para a operação do cache. Ou seja, se o banco de dados for gravado com sucesso e a atualização do cache falhar, desde que o tempo de expiração seja atingido, as solicitações de leitura subsequentes lerão naturalmente novos valores do banco de dados e, em seguida, preencherão o cache. Portanto, as ideias discutidas a seguir não dependem do esquema de definição de um tempo de expiração para o cache.
Aqui, discutimos quatro estratégias de atualização:
Atualize primeiro o cache e depois atualize o banco de dados
Atualize primeiro o banco de dados e depois atualize o cache
Exclua o cache primeiro e depois atualize o banco de dados
Atualize o banco de dados primeiro e, em seguida, exclua o cache
1. Atualize primeiro o cache e, em seguida, atualize o banco de dados
Esta estratégia de atualização não deve ser usada no projeto, os problemas existentes são óbvios:

Conforme mostrado na figura acima, para cada operação de escrita de um determinado usuário, se o cache acabou de ser escrito, ocorre uma anormalidade na rede repentinamente, fazendo com que a escrita no banco de dados falhe.
O resultado é que o cache é atualizado com os dados mais recentes, mas o banco de dados não. Os dados no cache não se tornam dados sujos ? Se a solicitação de consulta do usuário apenas ler os dados neste momento, haverá um problema, porque os dados não existem no banco de dados, e esse problema é muito sério.
Todos sabemos que o principal objetivo do cache é armazenar temporariamente os dados no banco de dados na memória, o que é conveniente para consultas subsequentes e melhora a velocidade da consulta.
Mas se um dado não existe no banco de dados , qual é o sentido de armazenar em cache esse tipo de dados falsos?
Portanto, não é aconselhável atualizar o cache primeiro e depois atualizar o banco de dados e não é muito usado no trabalho real.
2. Atualize primeiro o banco de dados e, em seguida, atualize o cache
Este plano é geralmente contestado por todos. Há duas razões principais:
Causa 1:
Do ponto de vista da segurança do thread, se houver solicitação A e solicitação B para operações de atualização ao mesmo tempo, haverá:
(1) Thread A atualiza o banco de dados
(2) Thread B atualiza o banco de dados
(3) Thread B atualiza o cache
(4) Thread A atualiza o cache
Isso significa que solicitar que A atualize o cache deve ser feito antes de solicitar que B atualize o cache, mas devido à rede e outros motivos, B atualizou o cache antes de A. Isso resulta em dados sujos e, portanto, não é considerado!
Motivo dois:
Do ponto de vista dos cenários de negócios, existem dois problemas:
(1) Se for um cenário de negócios em que o banco de dados grava mais e lê menos, adotar essa solução fará com que o cache seja atualizado frequentemente antes mesmo de os dados serem lidos, desperdiçando desempenho.
(2) Se o valor que você gravar no banco de dados não for gravado diretamente no cache, mas for gravado no cache após uma série de cálculos complexos. Então, após cada gravação no banco de dados, o valor gravado no cache é recalculado, o que sem dúvida é um desperdício de desempenho.
Obviamente, excluir o cache é mais adequado. A próxima discussão é a mais controversa, exclua o cache primeiro e depois atualize o banco de dados; ou atualize o banco de dados primeiro e depois exclua o cache.
3. Exclua o cache primeiro e, em seguida, atualize o banco de dados:
A razão pela qual esse esquema causará inconsistência é: ao mesmo tempo, há uma solicitação A para operação de atualização e outra solicitação B para operação de consulta. Então aparecerá a seguinte situação:
(1) Excluir o cache antes de solicitar a A para executar uma operação de gravação
(2) Solicitar B para consultar e descobrir que o cache não existe
(3) Solicitar B para consultar o banco de dados para obter o valor antigo
(4) Solicitar B para gravar o valor antigo no cache
(5) Solicitação A grava o novo valor no banco de dados
Se a política de definir um tempo de expiração para o cache não for adotada aqui, os dados sempre serão dados sujos! ! !
Solução: estratégia de exclusão dupla atrasada:
(1) exclua o cache primeiro
(2) grave no banco de dados novamente
(3) durma por um período de tempo (como um segundo) e exclua o cache novamente
O objetivo de fazer isso é excluir os dados de cache sujos gerados durante o tempo de suspensão (esse tempo de suspensão precisa ser especificado de acordo com a lógica de negócios demorada do projeto).
E se for a arquitetura de separação de leitura e gravação do MySQL?
Nesse caso, o motivo da inconsistência de dados é o seguinte, ainda existem duas solicitações, uma solicita que A execute uma operação de atualização e a outra solicita que B execute uma operação de consulta.
(1) Solicitar A para executar uma operação de gravação e excluir o cache;
(2) Solicitar A para gravar dados no banco de dados;
(3) Solicitar B para consultar o cache e descobrir que o cache não tem valor;
(4) Solicitar B para consultar o banco de dados, neste momento, A sincronização mestre-escravo não foi concluída, portanto, o valor antigo é consultado;
(5) Solicitação B para gravar o valor antigo no cache;
(6) O banco de dados conclui o mestre- sincronização escrava e a biblioteca escrava torna-se o novo valor;
A situação acima é o motivo da inconsistência de dados. Ainda use a estratégia de atraso de exclusão dupla. No entanto, o tempo de espera é modificado para adicionar várias centenas de ms ao tempo de atraso da sincronização mestre-escravo.
O que devo fazer se a taxa de transferência diminuir devido à estratégia de exclusão dupla atrasada?
Outro thread pode ser iniciado para executar a segunda operação de exclusão de forma assíncrona, de modo que a solicitação de gravação não precise ser suspensa por um período de tempo antes de retornar, aumentando assim a taxa de transferência.
Em seguida, há outra pergunta: o que devo fazer se a exclusão falhar ao excluir o cache pela segunda vez?
4. Atualize o banco de dados primeiro e, em seguida, exclua o cache
Esta estratégia não é isenta de problemas de simultaneidade.Se ocorrerem as seguintes situações, dados sujos ainda serão gerados. Supondo que haverá duas requisições, uma requisição A para operação de consulta e uma requisição B para operação de atualização, então ocorrerá a seguinte situação:
(1) O cache simplesmente falha
(2) Solicitação A para consultar o banco de dados e obter um valor antigo
(3) Solicitação B para gravar o novo valor no banco de dados
(4) Solicitação B para excluir o cache
(5) Solicitação A para gravar o valor antigo encontrado no cache
No entanto, esta situação ainda é relativamente rara, e as seguintes condições devem ser atendidas ao mesmo tempo:
1. O cache expira automaticamente.
2. Solicitar a A que descubra o valor antigo do banco de dados e atualizar o cache leva mais tempo do que solicitar a B que grave no banco de dados e exclua o cache.
Todos nós sabemos que a velocidade de consultar o banco de dados é geralmente mais rápida do que escrever o banco de dados, sem mencionar a exclusão do cache após a gravação do banco de dados. Portanto, na maioria dos casos, escrever solicitações de dados leva mais tempo do que ler dados.
Pode-se ver que a probabilidade de que o sistema satisfaça as duas condições acima ao mesmo tempo é muito pequena.
É recomendável usar a solução de primeiro gravar no banco de dados e depois excluir o cache. Embora o problema de inconsistência de dados não possa ser 100% evitado, a probabilidade desse problema é a menor em comparação com outras soluções.
Mas, nesse cenário, e se a exclusão do cache falhar?
Resposta: O mecanismo de repetição precisa ser adicionado.
Na interface, se a atualização do banco de dados for bem-sucedida, mas a atualização do cache falhar, você poderá tentar novamente 3 vezes imediatamente. Se algum deles for bem-sucedido, o sucesso será retornado diretamente. Se falhar nas três vezes, será gravado no banco de dados para processamento subsequente.
Obviamente, se você tentar novamente de forma síncrona diretamente na interface, quando a simultaneidade da interface for relativamente alta, o desempenho da interface poderá ser ligeiramente afetado.
Neste momento, você precisa alterar para repetição assíncrona.
Há muitas maneiras de tentar novamente de forma assíncrona, como:
1. Um encadeamento separado é iniciado a cada vez e esse encadeamento é dedicado a novas tentativas. No entanto, se em um cenário de alta simultaneidade, muitos encadeamentos podem ser criados, causando problemas de OOM do sistema, portanto, isso não é recomendado.
2. Entregue as tarefas repetidas ao pool de encadeamentos, mas se o servidor for reiniciado, alguns dados poderão ser perdidos.
3. Grave os dados de nova tentativa na tabela e, em seguida, use elastic-job e outras tarefas agendadas para tentar novamente.
4. Grave a solicitação repetida no middleware de mensagem, como mq, e processe-a no consumidor de mq.
No entanto, todos os métodos acima têm uma desvantagem, causando muita intrusão no código da linha de negócios. Portanto, existe o método 5:
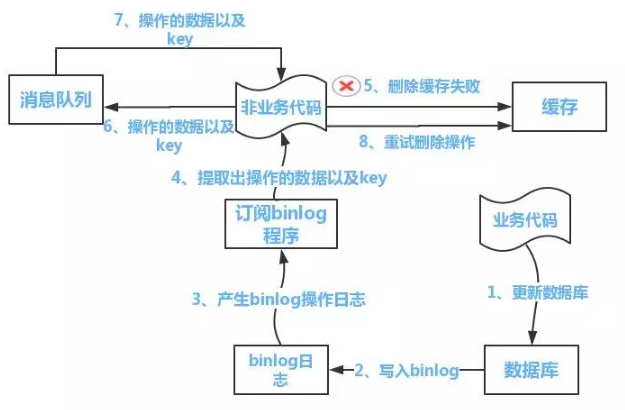
Inscreva-se no binlog do mysql .Entre os assinantes, se uma solicitação de atualização de dados for encontrada, o cache correspondente será excluído.
Ali já tem um canal de middleware pronto, se você estiver interessado, pode aprender sozinho~
Da mesma forma, mesmo que canel seja usado, ainda haverá o problema de falha na exclusão, que requer a adição do mecanismo de repetição discutido anteriormente.
Se o cliente do canal (ou seja, o assinante) falhar ao excluir o cache novamente, é recomendável gravar no mq e permitir que o mq repita automaticamente.
Como mostrado abaixo: