Artigo Diretório
Redis
Prefácio
Devido ao teste de estresse anterior, a taxa de transferência de análise e obtenção de informações da página inicial é muito baixa. Para isso, otimizamos a lógica, alteramos várias consultas ao banco de dados para uma consulta e, em seguida, reunimos os dados que queremos na lógica java , E conduziu um teste de estresse. Embora o rendimento tenha melhorado, ainda é insatisfatório. Mais tarde, um índice foi adicionado ao campo do banco de dados. O rendimento também melhorou, mas a mudança não é grande. Se você quiser otimizá-lo, pode Otimize o cache. Basicamente, as coisas na página inicial são lidas mais e menos escritas. Para atender a este cenário de negócios, você pode usar uma solução de cache.
Colocar parte dos dados no cache para agilizar o acesso, enquanto o DB é responsável pela colocação dos dados
Primeiro, precisamos considerar quais dados precisam ser colocados no cache:
- Os requisitos de imediatismo e consistência de dados não são altos, como logística, classificação de produtos, lista de produtos, etc., que são adequados para armazenamento em cache e um tempo de expiração (de acordo com a frequência de atualização de dados)
- Dados com grande quantidade de visitas e baixa frequência de atualização, que é o que costumamos chamar de cenário de mais leitura e menos escrita. Por exemplo, é aceitável que o comprador veja a notícia em 5 minutos quando o produto for lançado em segundo plano.
Para aqueles dados que requerem alta rapidez, consistência de dados ou dados atualizados frequentemente, vá para o banco de dados para verificar!
Adicionar lógica de cache
Vamos primeiro resolver a lógica de adicionar cache
- Em primeiro lugar, o que estamos adicionando ao cache? Se todo o projeto for implementado em java, então podemos usar diretamente a serialização jdk e armazená-lo no redis, mas em um projeto grande, temos que considerar vários problemas, como compatibilidade de plataforma cruzada e linguagem cruzada, então usamos string json Armazenado na forma de, porque json é compatível com várias linguagens e plataformas
- A lógica de salvar é primeiro converter o objeto em uma string json e armazená-lo em redis. A lógica de buscar é reverter as informações obtidas de redis. Este é o processo de serialização e desserialização.
Há um episódio ao usar o redis
Ao concluir a lógica básica, realizei um teste de estresse e ocorreu uma exceção de estouro de memória fora do heap. Os motivos específicos são os seguintes:
- Depois do SpringBoot 2.0, o lettuce é usado como o cliente redis por padrão e usa o netty para comunicação de rede na parte inferior.
- O bug da alface causou estouro de memória off-heap. Quando aumentei o parâmetro de inicialização jvm -Xmx, descobri que o problema ainda não foi resolvido. Mais cedo ou mais tarde, uma exceção ainda ocorreria porque o estouro de memória off-heap não era memória in-heap, mas memória off-heap. Isso pode ser configurado através de -Dio.netty.maxDirectMemory, mas você verá que as exceções ainda aparecerão, sua função é aumentar a memória, não a partir da raiz.
- Solução: (1), atualizar o cliente Lettuce (2) mudar para Jedis; usei a segunda solução
Até agora, você acha que o cache é suficiente? A resposta é claro que não, no caso de alta simultaneidade, se apenas tal operação for realizada, haverá uma série de problemas!
Por exemplo: penetração de cache, avalanche de cache, quebra de cache, deixe-me falar sobre como resolvi isso no projeto
Problemas comuns de cache e minhas soluções no projeto
Deixe-me explicar o conceito primeiro:
- Penetração do cache: É para consultar um dado que não está no cache e que não está no banco de dados. É atacado de forma maliciosa por criminosos. É para consultar um dado que não existe. De repente, ele enviará centenas de milhares de solicitações para o banco de dados. Desabou
- Avalanche de cache: trata-se de um lote de chaves no cache que expiram ao mesmo tempo, e centenas de milhares de solicitações simultâneas chegam para solicitar esses dados, então a solicitação será enviada para o banco de dados, causando o travamento do banco de dados, o que é Efeito avalanche
- Quebra do cache: a chave para um determinado ponto de acesso extremo no cache expira em um determinado momento. Esta é uma solicitação simultânea de centenas de milhares de chamadas para o banco de dados, resultando em tempo de inatividade do banco de dados
solução:
- Penetração do cache: (A solução que tomei é armazenar em cache um valor nulo e definir um curto tempo de expiração)
- Ao armazenar em cache um valor nulo e adicionar um tempo de expiração
- Através do filtro Bloom, os dados que não existem são bloqueados, mas este esquema terá alguns erros de julgamento
- Avalanche de cache:
- Para lidar com um grande número de chaves expirando ao mesmo tempo, podemos adicionar um valor aleatório ao definir o tempo de expiração para lidar com
- Quebra de cache:
- Isso é obtido por meio de bloqueio. Quando um grande número de solicitações chega, o método de bloqueio é usado para permitir que um determinado thread vá para o banco de dados para verificar e, em seguida, coloque os dados detectados no cache
Dê uma olhada no meu código:
//去数据库中查的业务逻辑
private Map<String, List<Catelog2Vo>> getDataFromDb() {
//得到锁以后,我们应该再去缓存中确定一次,如果没有才需要继续查询
String catalogJson = stringRedisTemplate.opsForValue().get("catalogJson");
if (!StringUtils.isEmpty(catalogJson)) {
//缓存不为空直接返回
Map<String, List<Catelog2Vo>> result = JSON.parseObject(catalogJson, new TypeReference<Map<String, List<Catelog2Vo>>>() {
});
return result;
}
System.out.println("查询了数据库");
/**
* 将数据库的多次查询变为一次
*/
List<CategoryEntity> selectList = this.baseMapper.selectList(null);
//1、查出所有分类
//1、1)查出所有一级分类
List<CategoryEntity> level1Categorys = getParent_cid(selectList, 0L);
//封装数据
Map<String, List<Catelog2Vo>> parentCid = level1Categorys.stream().collect(Collectors.toMap(k -> k.getCatId().toString(), v -> {
//1、每一个的一级分类,查到这个一级分类的二级分类
List<CategoryEntity> categoryEntities = getParent_cid(selectList, v.getCatId());
//2、封装上面的结果
List<Catelog2Vo> catelog2Vos = null;
if (categoryEntities != null) {
catelog2Vos = categoryEntities.stream().map(l2 -> {
Catelog2Vo catelog2Vo = new Catelog2Vo(v.getCatId().toString(), null, l2.getCatId().toString(), l2.getName().toString());
//1、找当前二级分类的三级分类封装成vo
List<CategoryEntity> level3Catelog = getParent_cid(selectList, l2.getCatId());
if (level3Catelog != null) {
List<Catelog2Vo.Category3Vo> category3Vos = level3Catelog.stream().map(l3 -> {
//2、封装成指定格式
Catelog2Vo.Category3Vo category3Vo = new Catelog2Vo.Category3Vo(l2.getCatId().toString(), l3.getCatId().toString(), l3.getName());
return category3Vo;
}).collect(Collectors.toList());
catelog2Vo.setCatalog3List(category3Vos);
}
return catelog2Vo;
}).collect(Collectors.toList());
}
return catelog2Vos;
}));
//3、将查到的数据放入缓存,将对象转为json
String valueJson = JSON.toJSONString(parentCid);
stringRedisTemplate.opsForValue().set("catalogJson", valueJson, 1, TimeUnit.DAYS);
return parentCid;
}
/**
* 从数据库查询并封装数据::本地锁
* @return
*/
public Map<String, List<Catelog2Vo>> getCatalogJsonFromDbWithLocalLock() {
// //如果缓存中有就用缓存的
// Map<String, List<Catelog2Vo>> catalogJson = (Map<String, List<Catelog2Vo>>) cache.get("catalogJson");
// if (cache.get("catalogJson") == null) {
// //调用业务
// //返回数据又放入缓存
// }
//只要是同一把锁,就能锁住这个锁的所有线程
//1、synchronized (this):SpringBoot所有的组件在容器中都是单例的。
//TODO 本地锁:synchronized,JUC(Lock),在分布式情况下,想要锁住所有,必须使用分布式锁
synchronized (this) {
//得到锁以后,我们应该再去缓存中确定一次,如果没有才需要继续查询
return getDataFromDb();
}
}
Vendo o código acima, você acha que definir um bloqueio local não é problema? Se for um aplicativo único, está tudo bem, mas para projetos distribuídos ainda existem alguns problemas, deixe-me mostrar uma imagem:
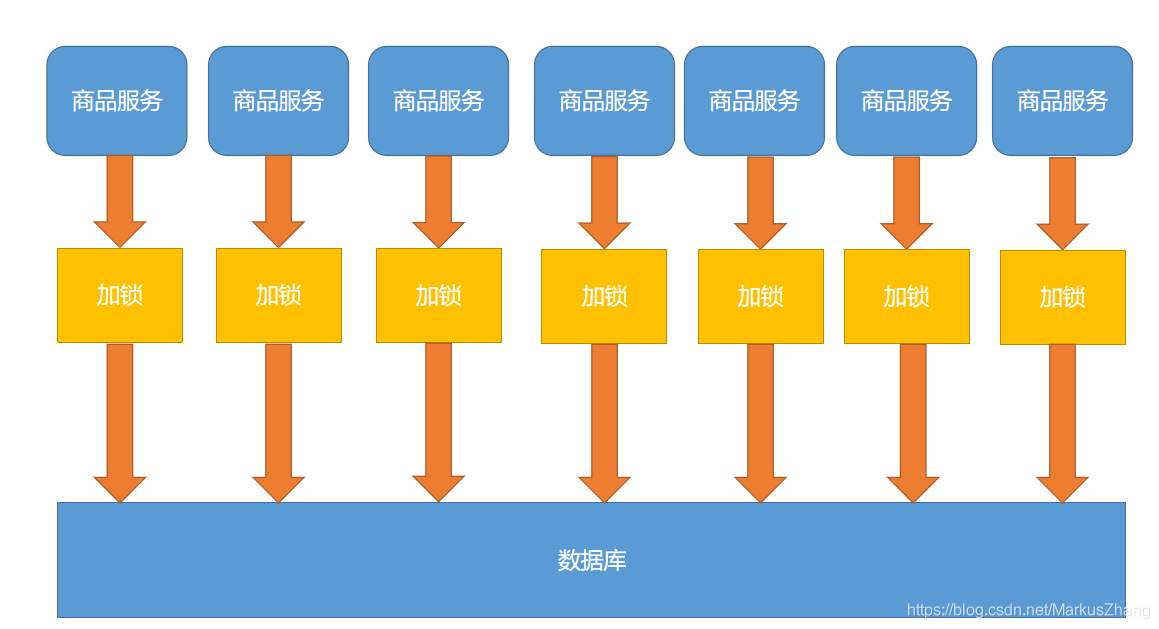
Nosso projeto é um projeto de cluster distribuído. Claro, um serviço deve ter muitos servidores. Suponha que chamemos 100.000 solicitações e as solicitações para cada servidor após o balanceamento de carga sejam 10.000 solicitações. Ao mesmo tempo, considera-se que não há nenhum no cache, então Cada servidor enviará uma solicitação ao banco de dados. Se houver poucos servidores, ainda está ok, mas não está de acordo com a nossa intenção original. Queremos verificar o banco de dados apenas uma vez, e as solicitações subsequentes serão transferidas para o redis. Então podemos usar bloqueios distribuídos para resolver!
Como o bloqueio distribuído é projetado? Vamos fazer um desenho para um melhor entendimento
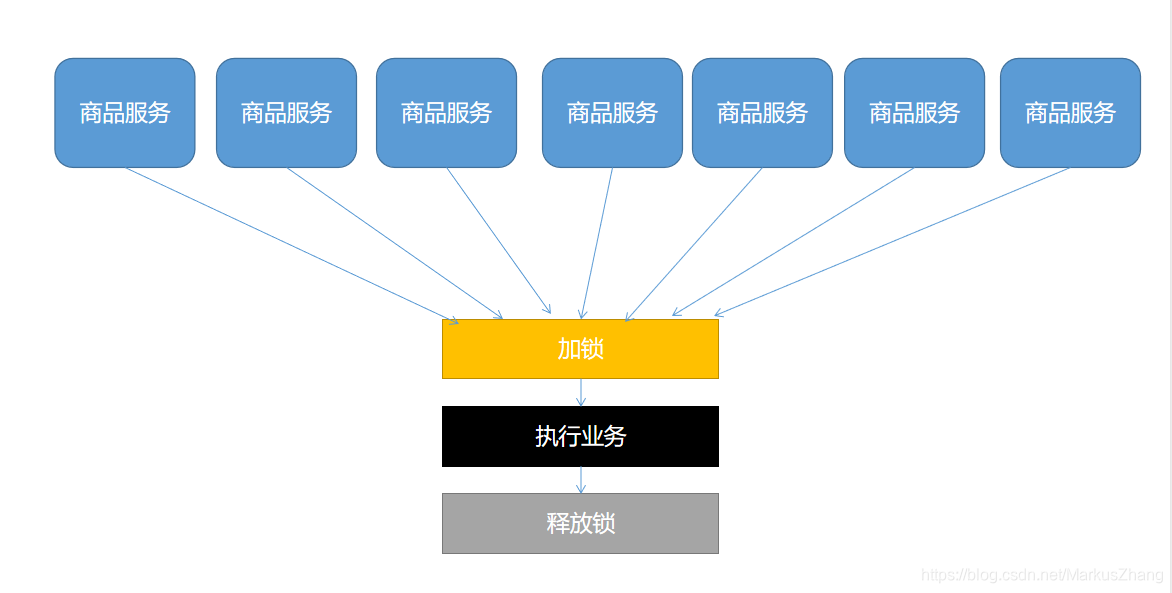
Em termos leigos, podemos ir ao mesmo lugar para "ocupar o buraco", e se o fizermos, executaremos a lógica. Caso contrário, você deve esperar até que o bloqueio seja liberado. O Occupy the lock pode ir para o redis, você pode ir para o banco de dados, você pode ir para qualquer lugar que todos possam acessar, esperando para poder usar o método spin.
Meu plano é levar a fechadura no redis, é um produto que realiza fechaduras distribuídas naturalmente, com suas instruções é possível realizar fechaduras distribuídas.
set key value ex|px nx|xx;
// 我们可以采用这个指令:
set key value ex nx;
// 也就是当这个键不存在的是设置锁
Como realizar esse bloqueio distribuído?
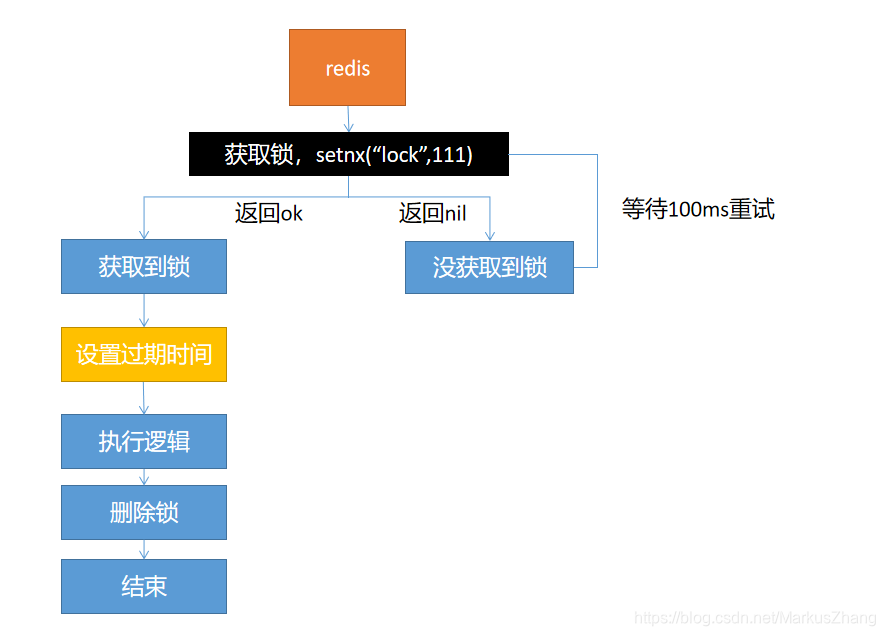
Opção um:

Com este esquema de design, haverá um problema: quando o encadeamento adquire o bloqueio e, em seguida, executa a lógica de negócios e se prepara para excluir o bloqueio, de repente o servidor cai, o que fará com que o bloqueio sempre exista e causará morte se não puder ser liberado. A situação de bloqueio.
A solução é: definir um prazo de validade, mesmo que o servidor esteja fora do ar e não possa ser liberado manualmente, ele pode ser liberado automaticamente após a data de vencimento
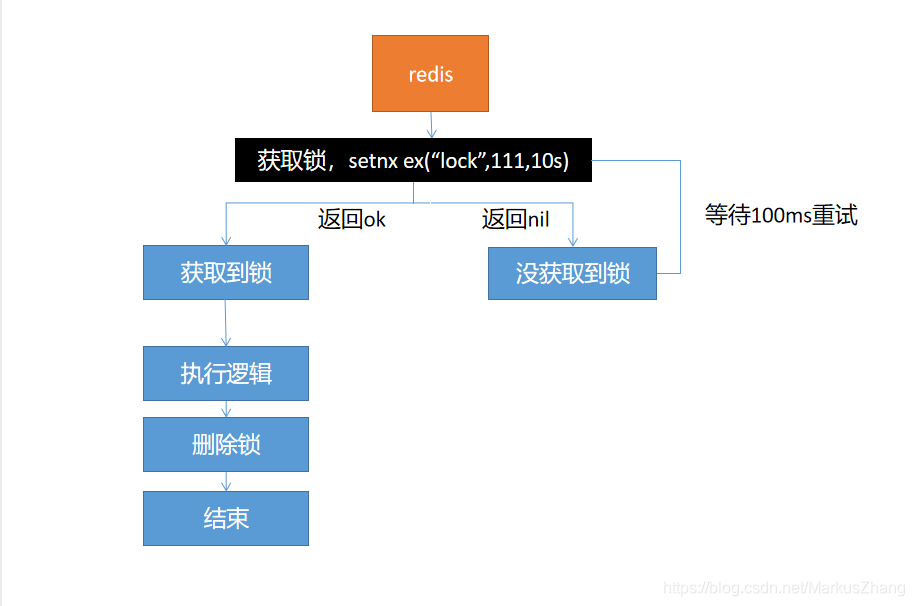
Opção II:
O problema da solução um está resolvido, mas haverá problemas.Se vamos definir o tempo de expiração após adquirir o bloqueio, o servidor está fora do ar neste momento, o que também causará um deadlock.
Solução: certifique-se de que a aquisição de bloqueios e a configuração do tempo de expiração são atômicos e o comando setnx ex pode garantir a atomicidade
terceira solução:
Esta solução resolve a atomicidade de definir bloqueios, mas ao excluir bloqueios, eles devem ser excluídos diretamente? Quando o tempo de execução do nosso negócio é muito longo, presume-se que o bloqueio expirou e outros threads adquiriram o bloqueio. Após o thread anterior ter executado o negócio, para excluir o bloqueio, ele excluirá o bloqueio de outros
Solução: Especifique seu próprio UUID ao configurar o bloqueio. Após executar o negócio, obtenha o bloqueio e verifique se ele foi configurado por você antes. Se for configurado por você mesmo, apague-o, caso contrário, ignore-o e certifique-se ao excluir o bloqueio. Atomicidade, por quê? Se obtivermos o bloqueio que definimos antes, mas ainda houver um período de tempo entre a obtenção do valor e a exclusão do bloqueio. Se o bloqueio falhar durante esse período e outra pessoa obtiver o bloqueio, ainda pensaremos que o bloqueio somos nós mesmos. , Levará à exclusão acidental.
Opção quatro:
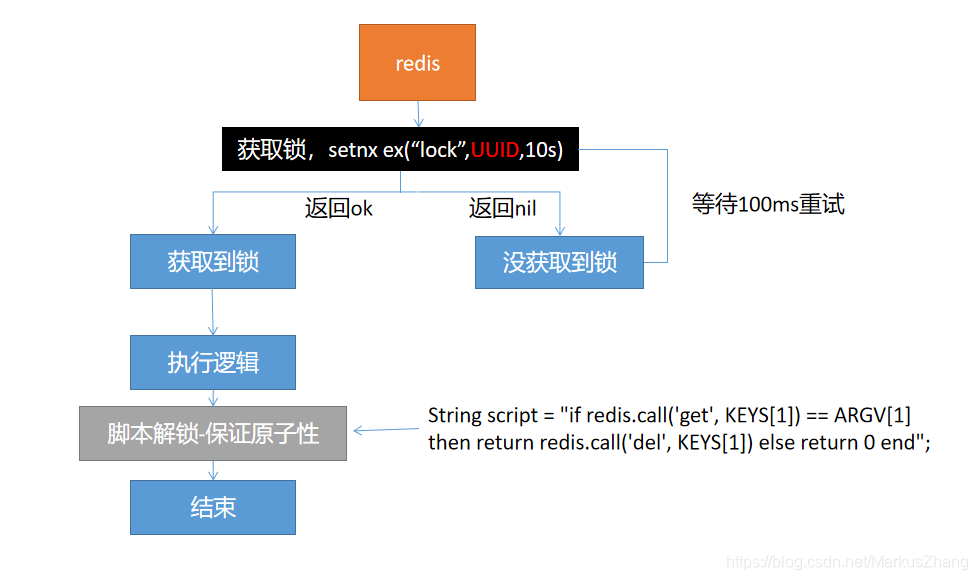
A opção quatro é a solução definitiva.Em resumo, é necessário garantir a atomicidade ao adquirir e excluir bloqueios!
Em seguida, vem um link importante: como resolver a consistência dos dados do cache?
Existem duas opções:
- Modo de escrita dupla
- Modo de falha
Vamos desenhar e analisar o fluxo de trabalho do modo de escrita dupla:

Vamos fazer um desenho para analisar o fluxo de trabalho do modo de falha:

Na verdade, esses dois esquemas causarão inconsistência de dados; por exemplo, no modo de gravação dupla, duas solicitações de gravação vêm uma após a outra. Após o processamento, o cache de gravação é devido a atrasos na rede e outros motivos. A primeira solicitação de gravação é gravada no cache, o que resulta em inconsistência de dados, e os dados no cache não são os dados mais recentes; por exemplo, no modo de falha, olhe para a imagem para saber quando eu não concluí a segunda solicitação de gravação , Fui ler o cache, mas não li e verifiquei no banco de dados. Quando li, supondo que a segunda solicitação não foi concluída, quando a segunda solicitação for concluída, exclua o cache e irei atualizá-lo novamente. Causa problemas de inconsistência de dados.
Como podemos resolver os problemas acima?
solução:
- Se forem dados de latitude do usuário (dados do pedido, dados do usuário), a chance dessa simultaneidade é muito pequena, então não há necessidade de considerar o problema de inconsistência de dados. Os dados em cache mais o tempo de expiração podem ser acionados a cada vez para ler e atualizar ativamente.
- Se forem dados básicos, como menus e introduções de produtos, você também pode usar o canal para assinar o binlog.As informações no banco de dados são alteradas e o canal coleta as informações, faz algum processamento e depois sincroniza com o redis.
- Dados em cache + tempo de expiração são suficientes para resolver a maioria dos requisitos de negócios para armazenamento em cache
- Se houver um pouco mais de operações de gravação, podemos garantir leituras e gravações simultâneas bloqueando, alinhando ao escrever e gravando, garantindo a ordem e sem bloqueio durante a leitura, então bloqueios de leitura e gravação são usados (negócios não estão relacionados aos dados de coração , Permitindo que dados sujos temporários sejam ignorados)
Aqui está um resumo
Dito isso, vamos resumir!
Os dados que podemos colocar no cache não devem exigir alta consistência de dados e tempo real. Portanto, adicione o tempo de expiração ao armazenar dados em cache para garantir que você obtenha os dados mais recentes todos os dias. Não devemos projetar excessivamente e aumentar a complexidade do sistema. Ao encontrar dados com altos requisitos de tempo real e consistência, devemos consultar o banco de dados, mais lentamente do que mais lento.