conceito de cache
O cache serve para ajustar a velocidade de duas ou mais substâncias diferentes com velocidades inconsistentes e acelerar a mais lenta no meio. Por exemplo, os caches de primeiro nível e segundo nível da CPU armazenam os dados que a CPU acessou recentemente frequentemente. A memoria é usada para guardar os dados que a CPU acessa com frequencia o disco rigido, e o disco rigido tambem possui caches de diversos tamanhos, ate mesmo o raid card do servidor fisico possui caches, tudo com a finalidade de agilizar os CPU's acesso aos dados do disco rígido, porque a velocidade da CPU é muito rápida, os dados necessários para a CPU muitas vezes não conseguem atender às necessidades da CPU em um curto período de tempo devido ao disco rígido, portanto, o cache da CPU, a memória , O cache do cartão Raid e o cache do disco rígido podem atender aos requisitos de dados da CPU até certo ponto, ou seja, a CPU pode ler dados do cache. Melhora consideravelmente a eficiência da CPU
cache do sistema
buffer e cache:
-
Buffer: Buffer também é chamado de buffer de gravação. Geralmente é usado para operações de gravação. Os dados podem ser gravados primeiro na memória e depois gravados no disco. O buffer geralmente é usado para buffer de gravação para resolver o buffer de velocidades inconsistentes de diferentes mídias. Os dados são escrito temporariamente primeiro. Para o local mais próximo, para aumentar a velocidade de gravação, a CPU primeiro gravará os dados no buffer de disco da memória e, em seguida, pensará que os dados foram gravados e, em seguida, o kernel gravará no disco em mais tarde, então o servidor perderá parte dos dados na memória.
-
Cache: Cache também é chamado de cache de leitura. Geralmente é usado para operações de leitura. A CPU lê arquivos da memória. Se não houver memória, lê do disco rígido para a memória e depois para a CPU. Coloque os dados que precisam ser lidos com frequência em sua área de cache mais próxima, você pode lê-lo rapidamente na próxima vez que o ler
Hierarquia e local de armazenamento em cache
- Camada do usuário: cache DNS do navegador, cache DNS do aplicativo, cliente de cache DNS do sistema operacional
- Camada de proxy: CDN, cache de proxy reverso
- Camada da Web: cache do servidor da Web
- Camada de aplicação: página estática
- Camada de dados: cache distribuído de dados, biblioteca
- Camada do sistema: cache do sistema operacional
- Camada física: cache de disco, Raid Cache
Cache DNS
O cache DNS do navegador tem como padrão 60 segundos, ou seja, a resolução DNS não será executada se o mesmo nome de domínio for acessado em 60 segundos.
cache da camada de aplicativo
Os serviços da Web, como Nginx e PHP, podem definir caches de aplicativos para acelerar a resposta às solicitações do usuário. Além disso, algumas linguagens interpretadas, como PHP/Python/Java, não podem ser executadas diretamente e precisam ser compiladas em bytecode primeiro, mas o bytecode precisa ser interpretado por um intérprete como O código de máquina só pode ser executado posteriormente, portanto o bytecode também é uma espécie de cache e, às vezes, haverá um fenômeno de que o bytecode não é atualizado após o lançamento do código do programa. Portanto, antes de iniciar a nova versão, você precisa primeiro limpar o cache do aplicativo e, em seguida, iniciar a nova versão.
Além disso, a tecnologia estática de página dinâmica pode ser usada para acelerar o acesso, por exemplo: para acessar a página dinâmica de dados do banco de dados, use o programa para gerar o arquivo de página estática html com antecedência, introdução do produto do site de comércio eletrônico, informações de comentários, dados não em tempo real, etc. podem ser realizados usando esta tecnologia.
cache da camada de dados
Serviço de cache distribuído:
- Redis
- Memcached
base de dados:
- Cache de consultas do MySQL
- cache innodb, cache MYISAM
cache de hardware
- Cache da CPU (cache de dados L1 e cache de instruções L1), cache L2, cache L3
- Cache de disco: Cache de disco
- Cache de matriz de disco: Raid Cache, que pode usar baterias para evitar perda de dados devido a falha de energia
Bancos de dados relacionais e não relacionais
banco de dados relacional
- Um banco de dados relacional é um banco de dados estruturado, construído com base em um modelo relacional (modelo de tabela bidimensional), geralmente orientado a registros.
- A instrução SQL (Standard Data Query Language) é uma linguagem baseada em banco de dados relacional, que é usada para realizar a recuperação e operação de dados no banco de dados relacional.
- Os principais bancos de dados relacionais incluem Oracle, MySQL, SQL Server, Microsoft Access, DB2, PostgreSQL, etc.
Ao usar os bancos de dados acima, você deve primeiro construir um banco de dados, construir uma tabela e projetar uma estrutura de tabela e, em seguida, armazenar os dados de acordo com a estrutura da tabela.Se os dados não corresponderem à estrutura da tabela, o armazenamento falhará.
banco de dados não relacional
- NoSQL (NoSQL=NotonlysQL), que significa "não apenas SQL", é o termo geral para bancos de dados não relacionais.
- Bancos de dados que não sejam bancos de dados relacionais convencionais são considerados não relacionais.
- Não há necessidade de pré-criar bancos de dados e tabelas para definir a estrutura da tabela de armazenamento de dados. Cada registro pode ter diferentes tipos de dados e número de campos (como texto, imagens, vídeos, música, etc. em bate-papos em grupo do WeChat).
- Os principais bancos de dados NOSQL incluem Redis, MongBD, Hbase (banco de dados não relacional distribuído, usado para big data), Memcached, ElasticSearch (referido como ES, banco de dados indexado), TSDB (banco de dados contínuo no tempo) etc.
A diferença entre banco de dados relacional e banco de dados não relacional:
(1) Diferentes métodos de armazenamento de dados
A principal diferença entre bancos de dados relacionais e não relacionais é a forma como os dados são armazenados.
- Os dados relacionais são inerentemente tabulares e, portanto, armazenados em linhas e colunas de uma tabela de dados. As tabelas de dados podem ser associadas entre si e armazenadas de forma colaborativa, e também é fácil extrair dados.
- Por outro lado, os dados não relacionais não cabem em linhas e colunas de tabelas, mas são agrupados em grandes blocos. Os dados não relacionais geralmente são armazenados em conjuntos de dados, como documentos, pares chave-valor ou estruturas gráficas. Seus dados e suas características são o fator de influência número um na escolha de como armazenar e extrair seus dados. (É fácil alternar os tipos de dados, existem vários tipos de dados em um conjunto de dados)
(2) Diferentes métodos de expansão
A maior diferença entre os bancos de dados SQL e NoSQL pode estar na forma de expansão.Para atender a demanda crescente, é claro, a expansão é necessária.
- Para suportar mais concorrência, o banco de dados SQL é dimensionado , ou seja, para aumentar o poder de processamento e usar um computador mais rápido, para que o mesmo conjunto de dados possa ser processado mais rapidamente. Como os dados são armazenados em tabelas relacionais, os gargalos de desempenho para operações que podem envolver muitas tabelas precisam ser superados aumentando o desempenho do computador. Embora o banco de dados SQI tenha muito espaço para desenvolvimento, ele definitivamente atingirá o limite superior de expansão vertical no final. (Os dados geralmente são armazenados no sistema de arquivos local. A leitura pode compartilhar o desempenho por meio da separação leitura-gravação e balanceamento de carga, mas a leitura e a gravação ainda consomem o desempenho de E/S)
- Os bancos de dados NoSQL, por outro lado, escalam horizontalmente . Como o armazenamento de dados não relacionais é distribuído naturalmente, a expansão dos bancos de dados NoSQL pode compartilhar a carga adicionando mais servidores de banco de dados comuns (nós) ao pool de recursos. (A distribuição de dados é armazenada em servidores diferentes, que podem ser lidos e gravados simultaneamente para acelerar a eficiência)
Pontas:
- Expansão horizontal: adicione servidores. (mais barato)
- Expansão vertical: Melhore a configuração de hardware, como mudar para uma CPU de maior desempenho, aumentando o número de núcleos de CPU, discos rígidos, E/S de disco e cartões de memória. (exceto para o disco rígido, outros precisam ser desligados para adicionar)
(3) Suporte diferente para transações
- Se as operações de dados exigirem alta transacionalidade ou consultas de dados complexas precisarem controlar o plano de execução, o banco de dados SQL tradicional é sua melhor escolha em termos de desempenho e estabilidade. O banco de dados SQL oferece suporte ao controle refinado sobre a atomicidade da transação e é fácil reverter as transações.
- Embora os bancos de dados NoSQL também possam usar operações de transação, eles não podem ser comparados aos bancos de dados relacionais em termos de estabilidade; portanto, seu valor real está na escalabilidade das operações e no processamento de grandes quantidades de dados.
- Bancos de dados não relacionais são inferiores aos bancos de dados relacionais em termos de processamento de transações e estabilidade. No entanto, possui bom desempenho de leitura e gravação, é fácil de expandir e tem vantagem no processamento de dados grandes.
Banco de dados relacional: especialmente adequado para altos requisitos transacionais e tarefas que precisam controlar o plano de execução, e o controle refinado das transações é melhor.
Banco de dados não relacional: o controle de transações será um pouco mais fraco e seu valor está na alta escalabilidade e no processamento de grande volume de dados
Plano de fundo do banco de dados não relacional
Ele pode ser usado para lidar com os três principais problemas do tipo de site dinâmico puro da Web 2.0.
(1) Alto desempenho - altos requisitos simultâneos de leitura e gravação para o banco de dados.
(2) Enorme armazenamento - a necessidade de armazenamento eficiente e acesso a dados massivos.
(3) HighScalability&&HighAvailability——Requisitos para alta escalabilidade e alta disponibilidade do banco de dados.
Bancos de dados relacionais e bancos de dados não relacionais têm suas próprias características e cenários de aplicação.A estreita combinação dos dois trará novas ideias para o desenvolvimento de bancos de dados web 2.0. Deixe que os bancos de dados relacionais se concentrem em relacionamentos e garantias de consistência de dados, e os bancos de dados não relacionais se concentrem em armazenamento e alta eficiência . Por exemplo, em um ambiente de banco de dados MySQI onde as leituras e gravações são separadas, os dados acessados com frequência (ou seja, dados de alto calor) podem ser armazenados em um banco de dados não relacional para melhorar a velocidade de acesso
2.5 Resumo
Banco de dados relacional:
- Exemplo --> banco de dados --> tabela (tabela) --> linha de registro (linha), campo de dados (coluna)
Banco de dados não relacional:
-
Instância --> banco de dados --> coleção (coleção) --> par chave-valor (chave-valor)
-
Bancos de dados não relacionais não requerem criação manual de bancos de dados e coleções (tabelas).
Introdução ao Redis
Redis (Remote Dictionary Server) é um banco de dados NoSQL de código aberto escrito em C.
O Redis é executado com base na memória e oferece suporte à persistência . Ele adota a forma de armazenamento chave-valor (par chave-valor), que é uma parte indispensável da atual arquitetura distribuída.
O programa do servidor Redis é um modelo de processo único, ou seja, vários processos Redis podem ser iniciados em um servidor ao mesmo tempo, e a velocidade real de processamento do Redis depende inteiramente da eficiência de execução do processo principal.
- Se apenas um processo Redis estiver em execução no servidor, quando vários clientes acessarem ao mesmo tempo, a capacidade de processamento do servidor diminuirá até certo ponto;
- Se vários processos Redis forem iniciados no mesmo servidor, o Redis colocará muita pressão na CPU do servidor enquanto melhora os recursos de processamento simultâneo.
Ou seja: no ambiente de produção real, é necessário decidir quantos processos Redis abrir de acordo com as reais necessidades. Se você tiver requisitos mais altos para alta simultaneidade, considere abrir vários processos no mesmo servidor. Se os recursos da CPU forem relativamente limitados, um único processo pode ser usado
Redis tem as seguintes vantagens:
(1) Alta velocidade de leitura e gravação de dados: a velocidade de leitura de dados pode atingir até 110.000 vezes/s, e a velocidade de gravação de dados pode atingir até 81.000 vezes/s.
(2) Estrutura de dados suportada: valor-chave, suporta tipos de dados ricos: Strings, Listas, Hashes, Conjuntos e Conjuntos Classificados e outras operações de tipo de dados.
- Strings tipo de string
- Tipo de lista de listas
- Hashes hash (hash)
- Define a coleção não ordenada
- Sorted Sets coleções ordenadas (ou zsets)
(o redis também pode ser usado como uma fila de mensagens, que pode ser realizada por meio de conjuntos classificados)
(3) Persistência de dados de suporte: os dados na memória podem ser salvos no disco e podem ser carregados novamente para uso ao reiniciar.
(4) Atomicidade: todas as operações do Redis são atômicas. (Transações de suporte, todas as operações são tratadas como transações)
(5) Backup de dados de suporte: backup de dados no modo master-salve. (Suporte a replicação mestre-escravo)
Desvantagens do Redis
- Problema de consistência de gravação dupla de cache e banco de dados
- Problema de avalanche de cache
- problema de quebra de cache
- Cache ## Cenários aplicáveis do Redis
- Como um banco de dados baseado em memória, o Redis é um cache de alto desempenho geralmente usado em caches de sessão, filas, tabelas de classificação, contadores, artigos mais recentes, comentários mais recentes, assinaturas de publicação, etc.
- O Redis é adequado para cenários com altos requisitos de dados em tempo real, armazenamento de dados com características de expiração e eliminação, sem necessidade de persistência ou apenas consistência fraca e lógica simples.
Por que o Redis é tão rápido?
-
1. Redis é uma estrutura de memória pura, que evita operações demoradas, como E/S de disco. (executa com base na memória)
-
2. O módulo principal do processamento de comandos Redis é de thread único, o que reduz o custo da competição de bloqueio, criação e destruição frequentes de threads e reduz o consumo de troca de contexto de thread. (modelo de rosca simples)
-
3. O mecanismo de multiplexação de E/S é adotado, o que melhora muito a eficiência da simultaneidade. (modo epoll)
Observação:
Existem dois tipos de E/S no sistema Linux: E/S de disco e E/S de solicitação de rede.
O recém-adicionado multithreading no Redis 6.0 usa apenas multilinearidade para processar solicitações de rede, enquanto os comandos de leitura e gravação de dados ainda são processados por um único thread.
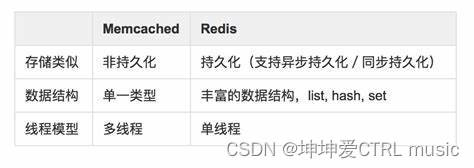
Comparação entre Redis e memcached
Instalação e implantação do Redis
关闭防火墙
systemctl stop firewalld
setenforce 0
#安装依赖环境
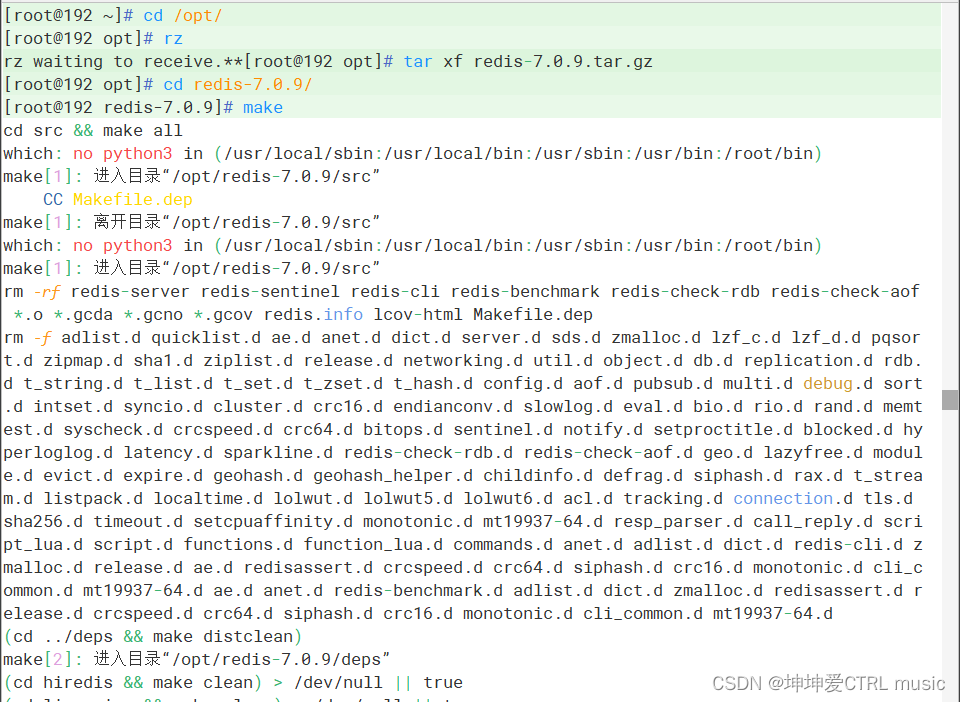
yum install -y gcc gcc-c++ make
#解压文件到指定文件夹 opt
tar zxvf redis-5.0.7.tar.gz -C /opt/
cd /opt/redis-5.0.7/
#安装
make
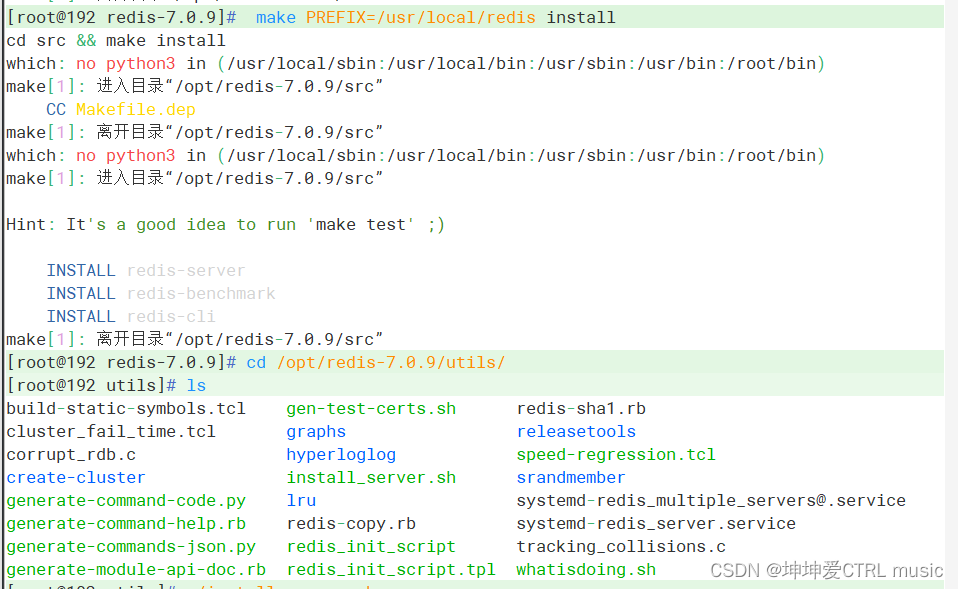
make PREFIX=/usr/local/redis install
#执行软件包提供的install_server.sh 脚本文件,设置Redis服务所需要的相关配置文件
cd /opt/redis-5.0.7/utils
./install_server.sh
……
慢慢回车
Please select the redis executable path []
手动输入
/usr/local/redis/bin/redis-server
#创建软链接
ln -s /usr/local/redis/bin/* /usr/local/bin/
/etc/init.d/redis_6379 stop #停止
/etc/init.d/redis_6379 start #启动
/etc/init.d/redis_6379 restart #重启
/etc/init.d/redis_6379 status
vim /etc/redis/6379.conf
70行,添加 监听的主机地址
bind 127.0.0.1 192.168.137.10
93行,Redis默认的监听端口
port 6379
137行,启用守护进程
daemonize yes
159行,指定 PID 文件
pidfile /var/run/redis_6379.pid
167行,日志级别
loglevel notice
172行,指定日志文件
logfile /var/log/redis_6379.log
------------------------------------------
#重启服务
/etc/init.d/redis_6379 restartDescompacte o pacote e compile-o
Instalar no diretório especificado
Execute o arquivo de script fornecido pelo pacote e faça uma conexão suave
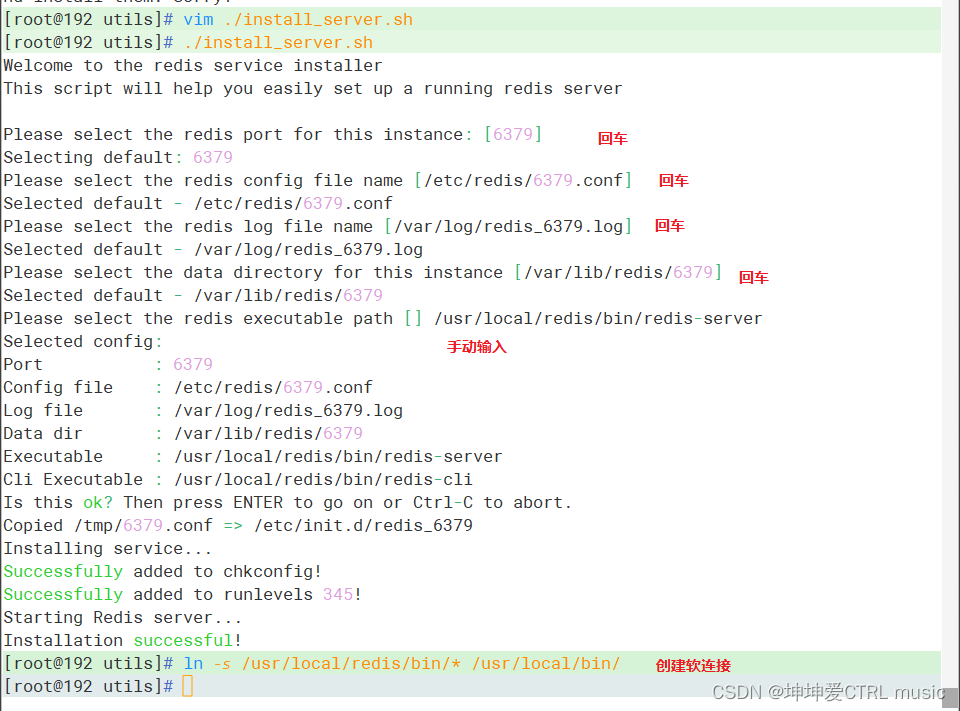
Inicie o serviço redis e verifique

Digite o arquivo de configuração para adicionar o host de escuta
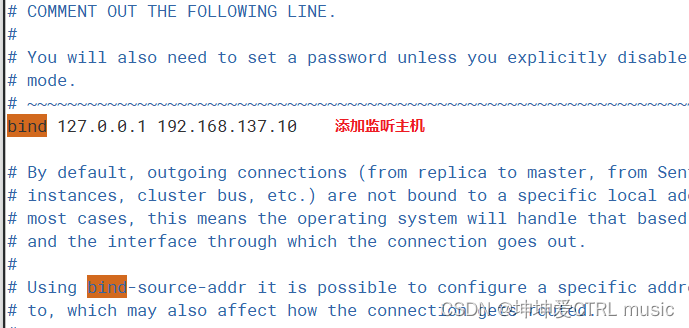
reinicie o serviço

Ferramenta de comando Redis
- redis-server: ferramenta para iniciar o Redis
- redis-benchmark: usado para detectar a eficiência operacional do Redis na máquina
- redis-check-aof: repara arquivo persistente AOF
- redis-check-rdb: repara arquivos persistentes RDB
- redis-cli: ferramenta de linha de comando do Redis
ferramenta de linha de comando redis-cli
语法:redis-cli -h host -p port -a password
-h:指定远程主机
-p:指定Redis服务的端口号
-a:指定密码,未设置数据库密码可以省略-a选项若不添加任何选项表示,则使用127.0.0.1:6379连接本机上的Redis数据库 redis-cli -h 192.168.137.10 -p 6379 #登录指定主机redis
redis-cli #登录本机redis

ferramenta de teste redis -benchmark
redis-benchmark é a ferramenta oficial de teste de desempenho do Redis que pode testar efetivamente o desempenho dos serviços do Redis
基本的测试语法:redis-benchmark [选项] [选项值]| opções | efeito |
|---|---|
| -h | Especifique o nome do host do servidor |
| p | especifique a porta do servidor |
| -s | Especifique o soquete do servidor |
| -n | Especifique o número de solicitações |
| -d | Especifique o tamanho dos dados do valor SET/GET em bytes |
| -k | 1=manter vivo 0=reconectar |
| -r | SET/GET/INCR usa chave aleatória, sADD usa valor aleatório |
| -P | Encaminhar <numerq> solicitações |
| --csv | Saída em formato csv. |
| -l (pequeno L) | Gerar loop, executar testes para sempre |
| -t | Execute apenas uma lista separada por vírgulas de comandos de teste |
| -eu (grande eu) | Modo ocioso. Abra apenas N conexões ociosas e aguarde |
Envie 100 conexões simultâneas e 100.000 solicitações para o servidor Redis com endereço IP 192.168.137.10 e porta 6379 para testar o desempenho
redis-benchmark -h 192.168.137.10 -p 6379 -c 100 -n 100000#测试存取大小为100字节的数据包的性能
redis-benchmark -h 192.168.137.10 -p 6379 -q -d 100
#测试本机上Redis服务在进行 set与1push操作时的性能
redis-benchmark -t set,lpush -n 100000 -q
Comandos comuns do banco de dados Redis
não diferencia maiúsculas de minúsculas
set 存放数据,命令格式为 set key value
get 获取数据,命令格式为 get keyredis-cli
127.0.0.1:6379> set name my #设置name值为my
OK
127.0.0.1:6379> get name #查看name的值
"my"
Verifique o status das chaves no banco de dados
keys 命令可以取符合规则的键值列表,通常情况可以结合*、?等选项来使用。
exists 命令可以判断键值是否存在。
del 命令可以删除当前数据库的指定 key。
type 命令可以获取 key 对应的 value 值类型。keys ver as chaves no banco de dados

chaves ? 与 chaves *
set qq 1
set qq1 2
set q2 3
set q4 4
keys q?
keys q*
chaves ??

O comando exists pode determinar se existe um valor de chave.
exists qq#判断 qq键是否存在
#1表示 qq键是存在
exists q
#0表示q键不存在
O comando del pode excluir a chave especificada do banco de dados atual.
del 键名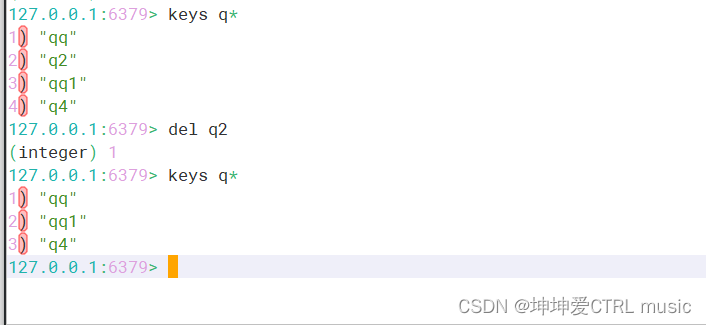
O comando type pode obter o tipo de valor correspondente à chave.
type 键名
O comando rename é para renomear uma chave existente.
(覆盖)命令格式:rename 源key 目标keyAo usar o comando rename para renomear, a renomeação será executada independentemente da existência da chave de destino, e o valor da chave de origem substituirá o valor da chave de destino. No uso real, é recomendável usar o comando exists para verificar se a chave de destino existe e, em seguida, decidir se deve executar o comando renomear para evitar a substituição de dados importantes
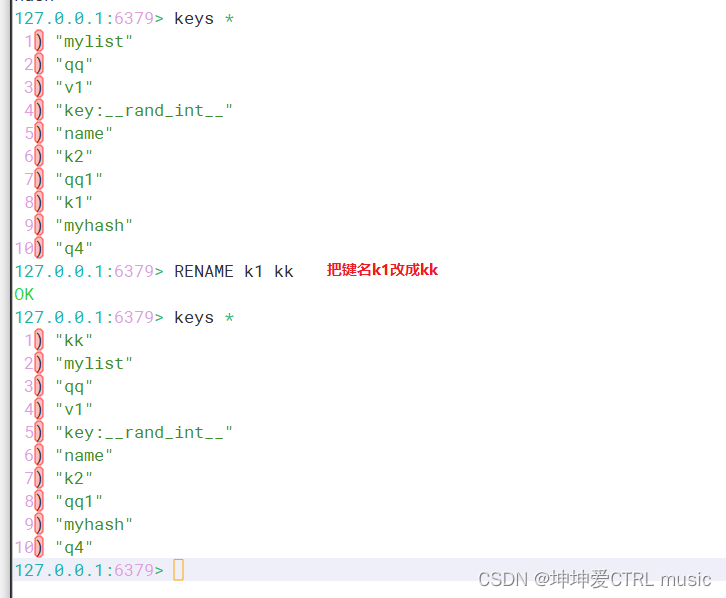
comando renomear
O comando renamenx serve para renomear uma chave existente e detectar se o novo nome existe.Se a chave de destino existir, ela não será renomeada.
(不覆盖)命令格式:renamenx 源key 目标key
O comando dbsize verifica o número de chaves no banco de dados atual.
dbsize
Defina uma senha usando o comando config set requirepass password
config set requirepass 密码Use o comando config get requirepass para visualizar a senha (depois que a senha for definida, a senha deve ser verificada primeiro, caso contrário, todas as operações estarão indisponíveis )
config get requirepassexcluir senha
config set requirepass ''Comandos comuns de vários bancos de dados do Redis
- O Redis oferece suporte a vários bancos de dados. O Redis contém 16 bancos de dados por padrão e os nomes dos bancos de dados são nomeados sequencialmente com números de 0 a 15.
- Vários bancos de dados são independentes uns dos outros e não interferem entre si
Alternar entre vários bancos de dados
命令格式:select 序号Depois de usar redis-cli para se conectar ao banco de dados Redis, o banco de dados com número de série 0 é usado por padrão
Movendo dados entre vários bancos de dados
格式:move 键值 序号Limpar os dados no banco de dados
FLUSHDB :清空当前数据库数据
FLUSHALL :清空所有数据库的数据,慎用!