Arquitetura de duas máquinas
A essência das soluções de armazenamento de alta disponibilidade é replicar dados para vários dispositivos de armazenamento e obter alta disponibilidade por meio da redundância de dados. A complexidade se reflete principalmente em como lidar com a inconsistência de dados causada por atrasos e interrupções na replicação. Portanto, para qualquer solução de armazenamento de alta disponibilidade, precisamos pensar e analisar a partir dos seguintes aspectos:
Como replicar dados?
Quais são as responsabilidades de cada nó?
Como lidar com o atraso de replicação?
Como lidar com interrupções de replicação?
Arquiteturas comuns de armazenamento de alta disponibilidade incluem mestre-escravo, mestre-escravo, mestre-mestre, cluster e partição.
Replicação mestre/em espera
A replicação de backup mestre é a solução de armazenamento de alta disponibilidade mais comum e simples.Quase todos os sistemas de armazenamento fornecem a função de replicação de backup mestre, como MySQL, Redis e MongoDB.
- Implementação básica
O seguinte é um diagrama de estrutura de esquema mestre-backup padrão:
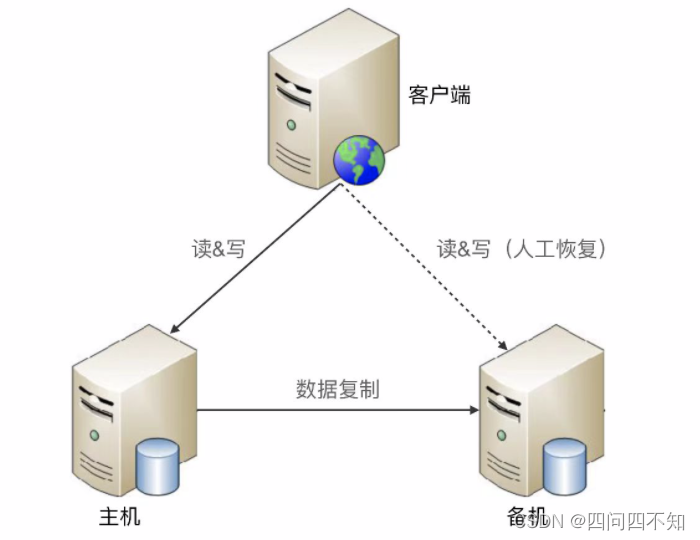
- Análise de vantagens e desvantagens
-
Vantagens:
1. Não há necessidade de perceber a existência da máquina de backup
; -
Desvantagens:
1. A máquina em espera é apenas para backup e não fornece operações de leitura e gravação;
2. A intervenção manual é necessária após uma falha e não pode ser restaurada automaticamente; -
Cenário de uso:
O sistema interno de gerenciamento de back-end geralmente usa a arquitetura de replicação mestre-escravo, como sistema de gerenciamento de alunos, sistema de gerenciamento de funcionários, sistema de gerenciamento de férias etc., porque a frequência de alterações de dados nesses sistemas é baixa, mesmo se éperdido em alguns cenários Os dados também podem ser preenchidos manualmente
replicação mestre-escravo
O mestre é responsável pelas operações de leitura e gravação, e o escravo é responsável apenas pelas operações de leitura, não pelas operações de gravação.
- Implementação básica
A seguir está a arquitetura padrão de replicação mestre-escravo:
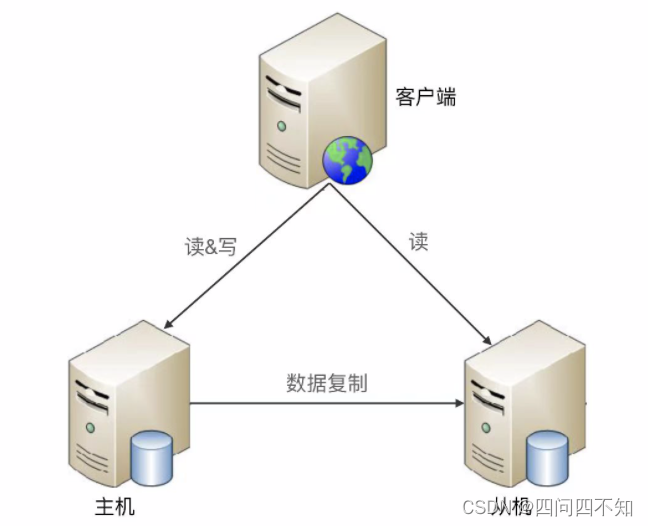
- Análise de vantagens e desvantagens
-
Vantagens:
1. Quando a replicação mestre-escravo falha no host, os negócios relacionados à operação de leitura podem continuar em execução;
2. O escravo da arquitetura de replicação mestre-escravo fornece operações de leitura, o que faz pleno uso do desempenho de o hardware; -
Desvantagens:
1. O cliente precisa perceber a relação mestre-escravo e enviar diferentes operações para diferentes máquinas para processamento;
2. Se o atraso de replicação mestre-escravo for relativamente grande, problemas de negócios ocorrerão devido à inconsistência de dados;
3. Intervenção manual é necessário em caso de falha; -
Cenários de uso:
Cenários de negócios com menos gravações e mais leituras usam mais arquiteturas de replicação mestre-escravo. Por exemplo, em fóruns, BBS, sites de notícias, etc., o número de operações de leitura é 10 vezes ou até 100 vezes maior que o número de operações de gravação.
transição
Existem dois problemas comuns nos esquemas de replicação mestre-escravo e mestre-escravo:
- 1. Após a falha do host, a operação de gravação não pode ser executada;
- 2. Se o host não puder ser restaurado, uma nova função de host precisará ser atribuída manualmente;
A alternância de máquina dupla foi criada para resolver esses dois problemas, incluindo esquemas de alternância mestre-espera e mestre-escravo. Simplificando, essas duas soluções são adicionar a função de "troca" com base na solução original, ou seja, o sistema determina automaticamente a função do host e conclui a troca de função.
Para obter uma solução de comutação completa, vários pontos-chave do projeto devem ser considerados:
Julgando o status das salas master e backup
- Canais para transferência de estado: eles estão conectados entre si ou arbitragem de terceiros?
- O conteúdo da detecção de status: como se a máquina está desligada, se o processo existe, se a resposta é lenta, etc.
mudar de decisão
- Tempo de comutação: Em que circunstâncias a máquina em espera deve ser atualizada para a máquina principal? A máquina de backup é atualizada após a falha de energia da máquina ou o processo no host não existe.
- Estratégia de troca: depois que o host original se recupera da falha, ele precisa ser trocado novamente para garantir que o host original continue sendo o mestre ou o host original se tornará automaticamente a nova máquina de backup após a recuperação da falha?
- Grau de automação: A chave é totalmente automática ou semiautomática?
Resolução de conflitos de dados
Quando o host com falha original é restaurado, pode haver conflitos de dados entre os hosts antigos e novos. Por exemplo, o usuário adiciona um pedaço de dados com um ID de 100 no host antigo, mas esses dados não foram copiados para o antigo modo de espera. Após a recuperação do antigo host defeituoso, como lidar com os dados com IDs duplicados.
De acordo com os diferentes canais de transferência de estado, existem três formas comuns de arquitetura de comutação ativo-espera: interconexão, intermediário e simulação.
interligado
Interconexão significa que as máquinas mestre e standby estabelecem diretamente um canal para transferência de status. Há um problema de falha no canal de transferência de status. Pode ser
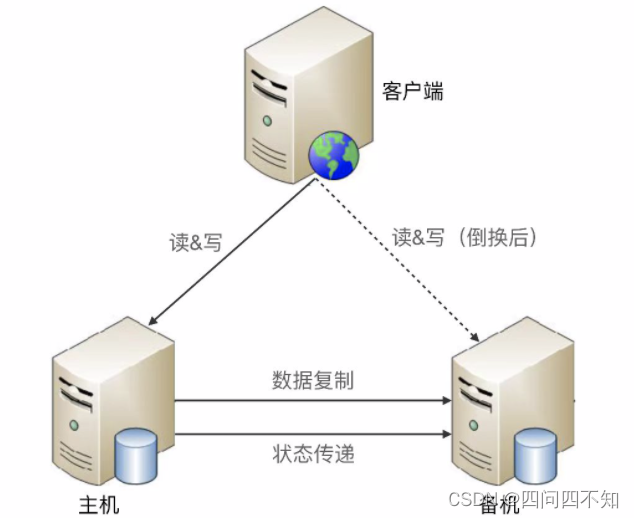
que o mestre envie o status para o backup ou o backup chegue ao mestre para obter informações de status .
Ele pode ser compartilhado com o canal de replicação de dados ou pode ser um canal independente. Para aproveitar ao máximo a vantagem de que o esquema de comutação pode determinar automaticamente o host, o cliente também
terá algumas alterações correspondentes
Por exemplo, IP virtual, o host precisa vincular esse IP virtual.
2. O cliente registra os endereços das máquinas principal e standby ao mesmo tempo;
3. Embora a máquina standby possa receber a solicitação de operação do cliente, ela a rejeitará diretamente. O motivo da rejeição é "a máquina standby não não prestar serviços externos";
Desvantagens da interconexão:
1. Quando o canal de transferência de estado falha, a máquina em espera também pode pensar que o mestre está com defeito e atualizar para o mestre, resultando em dois mestres; 2.
Se mais canais forem adicionados para aumentar a confiabilidade da transferência de estado, apenas reduzirá A probabilidade de falha do canal não pode resolver fundamentalmente essa deficiência e, quanto mais canais houver, mais complexa será a tomada de decisão do estado.
Intermediário
O tipo intermediário refere-se à introdução de um intermediário terceirizado além das máquinas principais e de espera.As máquinas principais e de espera não estão conectadas diretamente, mas estão conectadas ao intermediário, e as informações de status são transmitidas por meio do intermediário.
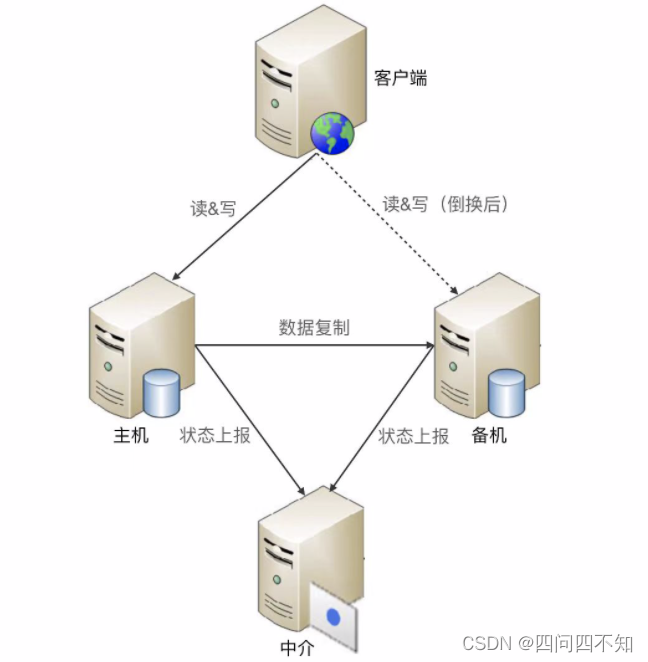
Embora o método intermediário seja mais simples em termos de transferência de estado e tomada de decisão do estado, há um problema de como garantir a alta disponibilidade do próprio intermediário. Se o próprio intermediário cair, todo o sistema entrará em um estado de espera dupla e os serviços relacionados às operações de gravação ficarão indisponíveis.
O Replica Set do MongoDB adota o método intermediário, e o diagrama de arquitetura é o seguinte,
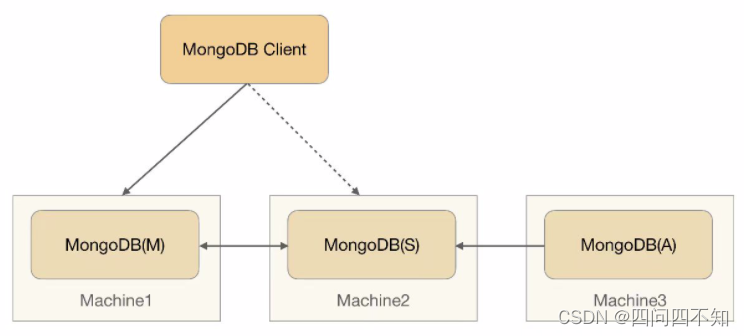
- MongoDB(M), nó mestre: armazena dados
- MongoDB(S): nó de espera: armazena dados
- MongoDB (A): nó Quorum: não armazena dados.O
cliente se conecta aos nós ativo e standby.
As soluções de código aberto já possuem soluções intermediárias relativamente maduras, como ZooKeeper e Keepalived. O próprio ZooKeeper implementou uma arquitetura de cluster de alta disponibilidade, o que nos ajudou a resolver o problema de confiabilidade do próprio intermediário.Na prática de engenharia, é recomendável construir uma arquitetura de comutação intermediária baseada no ZooKeeper.
analógico
O modo de simulação significa que nenhum dado de estado é transmitido entre as máquinas mestre e standby, mas a máquina standby é simulada como um cliente, inicia operações simuladas de leitura e gravação para o mestre e julga o status do mestre de acordo com a resposta do operações de leitura e gravação.
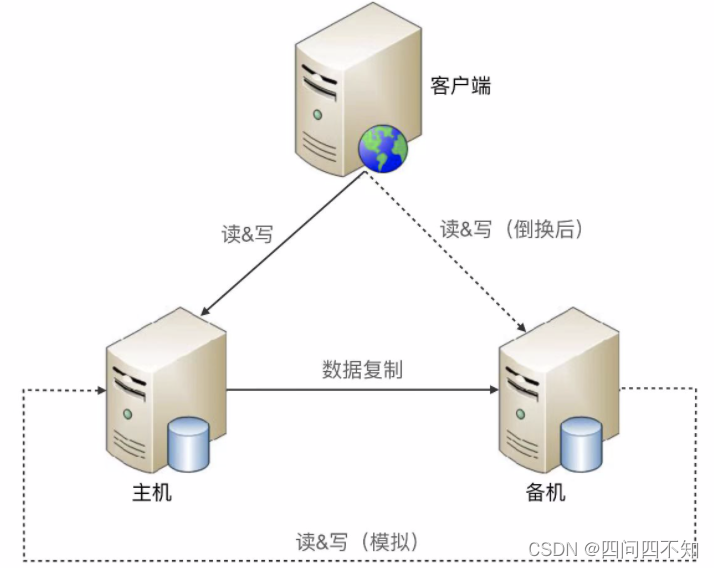
Em comparação com a comutação interconectada, a comutação analógica tem a vantagem de uma implementação mais simples, porque o estabelecimento e o gerenciamento de canais de transferência de estado são omitidos.
A simplicidade é uma vantagem e uma desvantagem. Como as informações de status obtidas por operações analógicas de leitura e gravação são apenas informações de resposta (por exemplo, HTTP 404, tempo limite, tempo de resposta superior a 3 segundos etc.), não são tão diversas quanto o tipo interconectado (além das informações de resposta, também pode incluir carga de CPU, carga de E/S, taxa de transferência, tempo de resposta, etc.), tomando decisões de estado com base em estados finitos, pode haver desvios.
replicação mestre-mestre
A replicação mestre-mestre significa que ambas as máquinas são hosts e copiam dados uma para a outra, e o cliente pode selecionar arbitrariamente uma das máquinas para operações de leitura e gravação.
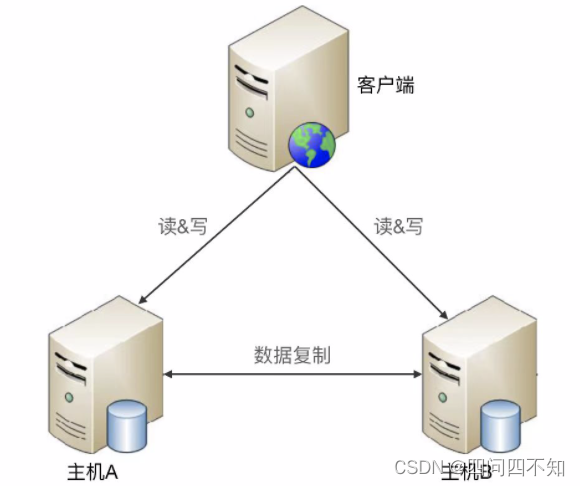
A replicação mestre-mestre é geralmente muito mais simples. Não requer transmissão de informações de estado, tomada de decisão de estado e troca de estado, mas tem restrições nos cenários de uso. Se a arquitetura de replicação mestre-mestre for adotada, os dados devem ser replicados bidirecionalmente e muitos dados não podem ser copiados em ambas as direções. Por exemplo:
- 1. Se o ID do usuário gerado após o registro do usuário aumentar de acordo com o número, ele não pode ser copiado em ambas as direções, caso contrário, vários hosts aparecerão com o mesmo ID;
- 2. O inventário não pode ser copiado em ambas as direções.Se um host for reduzido, o outro host também será reduzido e será substituído após a cópia;
Portanto, a arquitetura de replicação mestre-mestre tem requisitos rígidos de design de dados e geralmente é adequada para cenários de dados temporários, passíveis de perda e sobrescritos. Por exemplo, dados de sessão gerados pelo login do usuário (podem ser gerados por novo login), dados de log de comportamento do usuário (podem ser perdidos), dados de rascunho do fórum (podem ser perdidos), etc.
Clusters e partições
agrupamento de dados
As arquiteturas mestre-escravo, mestre-escravo e mestre-mestre têm uma suposição implícita em essência: o host pode armazenar todos os dados e os recursos de armazenamento e processamento do próprio host são limitados. Um único servidor é definitivamente incapaz de armazenar e processar, devemos usar vários servidores para armazenar dados, esta é a arquitetura de cluster de dados.
Um cluster é uma combinação de várias máquinas para formar um sistema unificado. As "máquinas múltiplas" aqui são pelo menos 3 em número; em comparação, existem 2 máquinas para o mestre e o escravo e o mestre e o escravo. De acordo com os diferentes papéis assumidos pelas máquinas no cluster, os clusters podem ser divididos em dois tipos: clusters centralizados de dados e clusters descentralizados de dados.
agrupamento de dados
1 mestre com vários backups ou 1 mestre com vários escravos. Seja 1 mestre e 1 escravo, 1 mestre e 1 backup ou 1 mestre e vários backups e 1 mestre e vários escravos, os dados só podem ser gravados no host e a operação de leitura pode ser flexível e alterável referindo-se arquitetura mestre-escravo e mestre-escravo. A figura a seguir mostra uma arquitetura que lê e grava todos os dados no host:
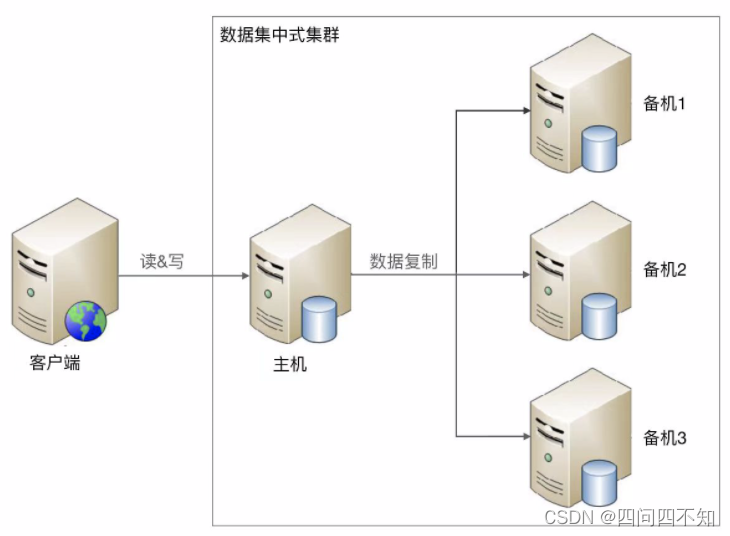
Embora a arquitetura seja semelhante, devido ao grande número de servidores no cluster, a complexidade geral é maior, o que se reflete especificamente em:
- 1. Como o host copia dados para a máquina em espera?
Nas arquiteturas mestre-escravo e mestre-escravo, há apenas um canal de replicação, enquanto na arquitetura de cluster de conjunto de dados, há vários canais de replicação. Vários canais de replicação aumentarão primeiro a pressão da replicação do host. Em alguns cenários, precisamos considerar como reduzir a pressão da replicação do host ou reduzir a pressão da replicação do host na leitura e gravação normais.
Em segundo lugar, vários canais de replicação podem causar inconsistência de dados entre várias máquinas de backup. Em alguns cenários, precisamos verificar e corrigir a consistência de dados entre as máquinas de backup.
- 2. Como a máquina em espera detecta o status da máquina principal?
Na arquitetura mestre-escravo e mestre-escravo, apenas uma máquina em espera precisa julgar o status do mestre. Na arquitetura de cluster de concentração de dados, várias máquinas de backup precisam julgar o status do host, e os resultados do julgamento de diferentes máquinas de backup podem ser diferentes. Como lidar com diferentes julgamentos do status do host por diferentes máquinas de backup é um problema complicado?
- 3. Após a falha do host, como determinar um novo host
Na arquitetura mestre-escravo, se o mestre falhar, a máquina de backup pode ser atualizada para o mestre; enquanto na arquitetura de cluster centralizada de dados, várias máquinas de backup podem ser atualizadas para o mestre, mas na verdade apenas uma máquina de backup é permitida ser atualizado para o mestre, então qual máquina de backup escolher como a nova mestre e como coordenar entre as máquinas de backup?
O cluster de conjunto de dados de software livre atual é normalmente o ZooKeeper. O ZooKeeper resolve os problemas mencionados acima por meio do algoritmo ZAB, mas a complexidade do algoritmo ZAB é muito alta.
Cluster disperso de dados
Cluster disperso de dados refere-se a vários servidores formando um cluster, e cada servidor é responsável por armazenar parte dos dados; ao mesmo tempo, para melhorar a utilização do hardware, cada servidor faz backup de parte dos dados.
A complexidade dos clusters descentralizados de dados reside em como distribuir dados para diferentes servidores. O algoritmo precisa considerar estes pontos de design:
-
Equilíbrio
O algoritmo precisa garantir que as partições de dados no servidor sejam basicamente equilibradas e que o número de partições em um servidor não possa ser várias vezes o de outro servidor. -
Tolerância a falhas
Quando ocorre uma falha parcial do servidor, o algoritmo precisa alocar a partição de dados originalmente atribuída ao servidor com falha para outros servidores. -
Escalabilidade
Quando a capacidade do cluster é insuficiente e novos servidores são expandidos, o algoritmo pode migrar automaticamente algumas partições de dados para os novos servidores e garantir o balanceamento de todos os servidores após a expansão.
A diferença entre um cluster de dados dispersos e um cluster de dados centralizados é que cada servidor em um cluster de dados dispersos pode lidar com solicitações de leitura e gravação, portanto, não há função como um host responsável por gravar em um cluster de dados centralizados. Entretanto, em um cluster de dados distribuídos, deve haver um papel responsável por executar o algoritmo de alocação de dados, que pode ser um servidor independente ou um servidor eleito pelo próprio cluster. Se uma máquina for escolhida pelo servidor do cluster para assumir a responsabilidade da alocação da partição de dados, esse servidor geralmente também é chamado de host, mas precisamos saber o "host" aqui e o "host" no cluster de dados.
A implementação do Hadoop é que um servidor independente é responsável pela alocação das partições de dados, e esse servidor é chamado de Namenode. A arquitetura de gerenciamento de partição de dados do Hadoop é a seguinte:
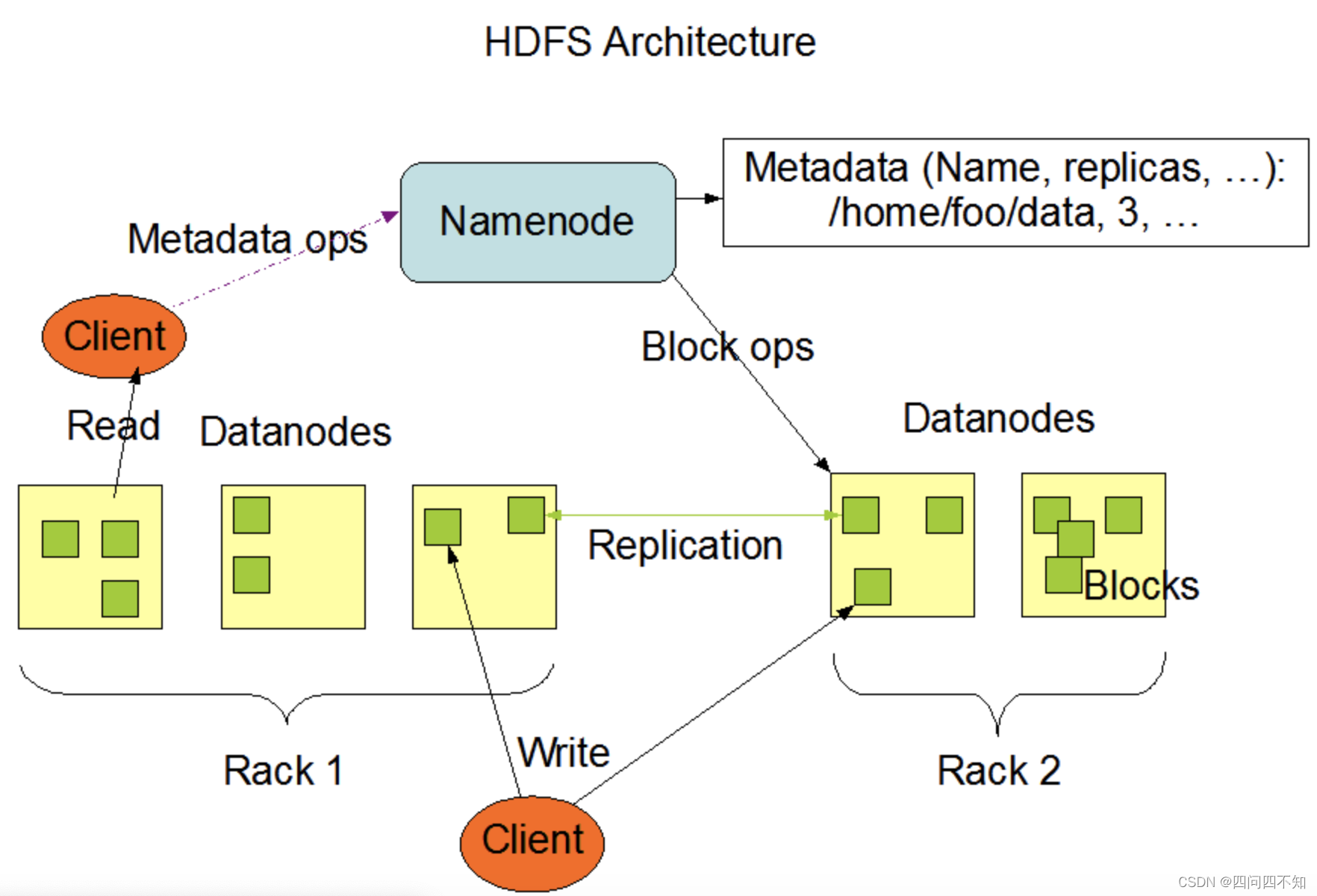
A seguir está a explicação oficial do Hadoop, que pode explicar a forma básica de gerenciamento de partição de dados centralizada.
- HDFS adota arquitetura mestre/escravo. Um cluster HDFS consiste em um Namenode e um certo número de Datanodes.
- Namenode é um servidor central responsável por gerenciar o namespace do sistema de arquivos e o acesso do cliente aos arquivos.
- O Datanode no cluster geralmente é um nó, que é responsável por gerenciar o armazenamento no nó onde está localizado. O HDFS expõe o namespace do sistema de arquivos e os usuários podem armazenar dados na forma de arquivos. Internamente, um arquivo é realmente dividido em um ou mais blocos de dados, e esses blocos são armazenados em um conjunto de Datanodes.
- O Namenode executa operações de namespace do sistema de arquivos, como abrir, fechar e renomear arquivos ou diretórios. Também é responsável por determinar o mapeamento de blocos de dados para nós Datanode específicos.
- Os datanodes são responsáveis por lidar com as solicitações de leitura e gravação dos clientes do sistema de arquivos. Crie, exclua e copie blocos de dados sob o agendamento unificado do Namenode.
Diferentemente do Hadoop, o cluster Elasticsearch aloca partições de dados elegendo um servidor, que é chamado de master node. Sua arquitetura de gerenciamento de partições de dados é a seguinte: As responsabilidades
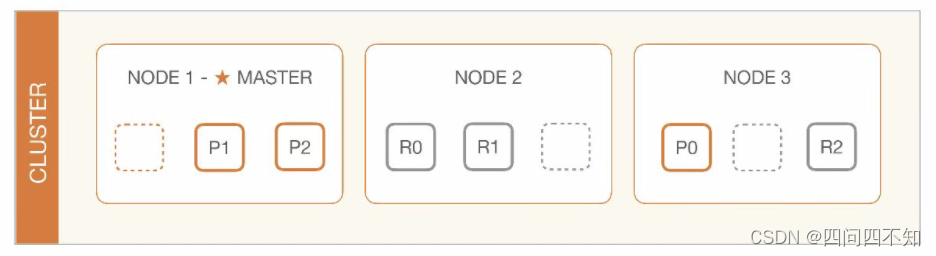
do master node são as seguintes:
O nó mestre é responsável por ações leves em todo o cluster, como criar ou excluir um índice, rastrear quais nós fazem parte do cluster e decidir quais shards alocar para quais nós. É importante para a integridade do cluster ter um nó principal estável.
elasticsearch官方文档——modules-node
Na arquitetura de cluster de dados centralizados, o cliente só pode gravar dados no host; na arquitetura de cluster de dados dispersos, o cliente pode ler e gravar dados em qualquer servidor. É precisamente por causa dessa diferença fundamental que os cenários de aplicação dos dois clusters são diferentes. De um modo geral, clusters de dados centralizados são adequados para cenários em que a quantidade de dados é pequena e o número de máquinas de cluster é pequeno. Por exemplo, um cluster ZooKeeper geralmente recomenda cerca de 5 máquinas e a quantidade de dados pode ser suportada por um único servidor; e um cluster de dados distribuídos, devido à sua boa escalabilidade, é adequado para cenários de negócios com uma grande quantidade de dados de negócios e um grande número de máquinas de cluster. Por exemplo, clusters Hadoop, clusters HBase e clusters de grande escala podem atingir centenas ou até milhares de servidores.
partição de dados
As arquiteturas de armazenamento de alta disponibilidade que discutimos acima são todas consideradas e projetadas com base em cenários de falha de hardware. A principal consideração é como o sistema deve lidar quando algum hardware pode ser danificado. No entanto, para alguns desastres ou acidentes de grande impacto, existem Possivelmente todo o hardware falha. Por exemplo, desastres extremos ou acidentes como enchentes em Nova Orleans, apagões nos Estados Unidos e no Canadá e o terremoto de Los Angeles podem causar a paralisação de toda a infraestrutura de uma cidade ou mesmo de uma área. arquitetura projetada com base em falhas de hardware não é mais aplicável. , precisamos projetar uma arquitetura de alta disponibilidade com base em falhas de nível geográfico, que é o pano de fundo da arquitetura de partição de dados.
Diferentes partições são distribuídas em diferentes localizações geográficas, e cada partição armazena uma parte dos dados, evitando assim o grande impacto causado por falhas em nível geográfico.
A quantidade de dados
O tamanho do volume de dados determina diretamente a complexidade das regras de partição. Por exemplo, se o MySQL for usado para armazenar dados, supondo que a capacidade de armazenamento do MySQL seja de 500 GB, então 2 TB de dados requer pelo menos 4 servidores MySQL; e se os dados forem de 200 TB, não é tão simples quanto aumentar para 800 servidores MySQL. Se 800 servidores forem gerenciados em paralelo da mesma forma que 4 servidores, a complexidade mudará substancialmente, conforme a seguir:
Entre os 800 servidores, pode haver uma ou duas falhas de servidor a cada semana.Localizar duas falhas de servidor dos 800 servidores não é uma tarefa fácil em muitos casos, e a complexidade de operação e manutenção é alta.
A adição de novos servidores, configurações relacionadas à partição e até regras precisam ser modificadas, e cada modificação pode teoricamente afetar a operação dos 800 servidores existentes, sendo muito comum alterar acidentalmente a configuração errada na prática.
Se uma quantidade tão grande de dados estiver concentrada geograficamente em uma determinada cidade, o risco é muito alto. No caso de falhas catastróficas, como enchentes e blecautes, todos os dados podem ser perdidos. Portanto, as regras de partição precisam considerar a recuperação geográfica de desastres .
regras de zoneamento
As partições intercontinentais são usadas principalmente para fornecer serviços para diferentes continentes. Como o atraso da rede de comunicação intercontinental é muito grande para fornecer serviços online, os data centers intercontinentais podem não se comunicar entre si ou servir apenas como backups; as partições de país são usadas principalmente para diferentes países . Diferentes países têm diferentes idiomas, leis, serviços, etc., e as partições entre os países geralmente são usadas apenas como backup; como as partições da cidade estão todas no mesmo país ou região, o atraso da rede é baixo e o negócio é semelhante , e as partições são fornecidas ao mesmo tempo.Serviços, que podem atender às necessidades de negócios em diferentes lugares e viver mais.
copiar regra
Os dados estão espalhados em várias regiões e a arquitetura da partição também precisa considerar o esquema de replicação.
Existem três tipos de regras de replicação: centralizada, espera mútua e independente.
- centralizado
Backup centralizado significa que existe um centro de backup geral, e todas as partições fazem backup de dados no centro de backup. Sua estrutura básica é a seguinte: as vantagens e desvantagens são
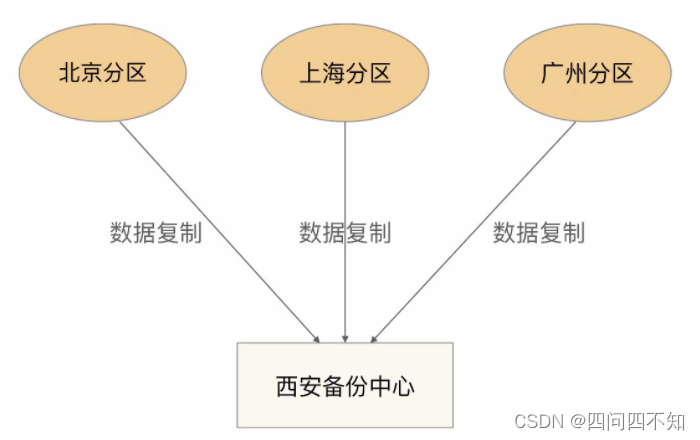
:
O design é simples e não há conexão direta entre as partições, portanto, elas não afetam umas às outras.
É fácil de expandir. Se você deseja adicionar uma quarta partição (por exemplo, partição Wuhan), você só precisa copiar os dados da partição Wuhan para o centro de backup de Xi'an e outras partições não serão afetadas.
O custo é alto e um centro de backup independente precisa ser construído.
- Espera mútua
Backup mútuo significa que cada partição faz backup dos dados de outra partição. Sua estrutura básica é a seguinte:
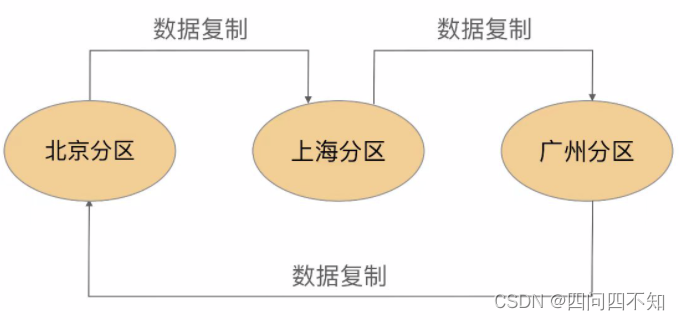
as vantagens e desvantagens são:
O design é relativamente complicado. Além de realizar o armazenamento de dados de negócios, cada partição também precisa realizar funções de backup, e elas estão relacionadas e são afetadas umas pelas outras.
A expansão é problemática. Se você adicionar uma partição Wuhan, precisará modificar a replicação da partição Guangzhou para apontar para a partição Wuhan e, em seguida, apontar a replicação da partição Wuhan para a partição Beijing. No entanto, como lidar com os dados da partição Guangzhou que foram copiados na partição original de Pequim também é um problema. Seja migração de dados ou dados históricos da partição Guangzhou mantidos na partição Pequim, e novos dados são copiados para a partição Wuhan, de qualquer forma é muito problemático.
Baixo custo, uso direto de equipamentos existentes.
- independente
Backup independente significa que cada partição possui seu próprio centro de backup independente e sua estrutura básica é a seguinte:
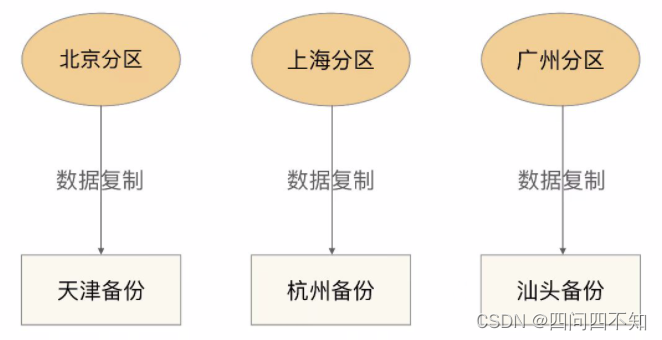
As vantagens e desvantagens de uma arquitetura de backup independente são:
O design é simples e cada partição não afeta uma à outra.
Fácil de expandir, as partições recém-adicionadas só precisam criar seu próprio centro de backup.
O custo é alto, cada partição precisa de um centro de backup independente e o custo do local do centro de backup é o custo principal, portanto, o custo do tipo independente é muito maior do que o do tipo centralizado.