Um índice
Explicação do site oficial do Index
MySQL: Index é uma estrutura de dados classificada que ajuda o MySQL a obter dados com eficiência
Estrutura de dados do índice:
- árvore binária
- árvore preta vermelha
- Tabela de hash
- Árvore B
Caso: Há uma tabela com duas colunas e sete linhas.
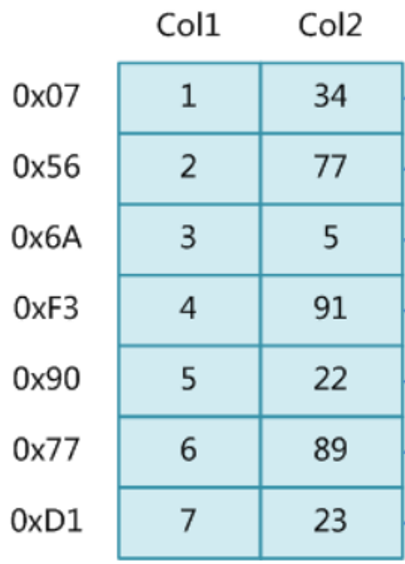
Se nossa instrução sql de consulta for:
select * from t where t.col2=89;
Em circunstâncias normais, o valor de col2 precisa ser retirado linha por linha e então comparado com 89 até que seja encontrado;
Para os dados em uma tabela MySQL, várias linhas de dados não são necessariamente armazenadas lado a lado no disco (porque se uma linha de dados for salva, a segunda linha de dados é salva alguns dias depois, pode haver outros dados em o período intermediário armazenado no disco), ele é armazenado aleatoriamente; executa uma instrução SQL de consulta (se houver muitos dados na tabela), toda vez que um dado é obtido do disco, ele precisa fazer um I /O lê a interação com o disco e compara os dados depois de buscar os dados Para ver se são os dados que precisamos, o desempenho é muito baixo; nosso objetivo é reduzir o número de interações com o disco ao procurar os dados que desejamos necessidade (diminuir o número de buscas), desde que esse número seja controlado dentro de uma determinada faixa, a eficiência será de muita melhora, nesse ponto nasceu o índice;
A seguir, índice col2, como mencionado anteriormente, o índice é uma estrutura de dados, como uma árvore binária
Árvore binária
Em seguida, colocamos os dados da coluna col2 na árvore binária (o nó filho esquerdo é menor que o nó pai e o nó filho direito é maior que o nó pai), da seguinte forma: se você procurar por 89, poderá

encontrar pesquisando apenas duas vezes, na primeira vez você obtém 34. Descobriu-se que os dados que procuramos não são os dados que procuramos e os dados que procuramos são maiores que 34. Deve ser pesquisado no nó filho direito de 34 e 89 pode ser encontrado pela segunda vez;
Na árvore acima, cada nó armazena chave/valor, onde a chave armazena o valor correspondente ao campo col2 (34, 77...89, 23) e o valor armazena o endereço do arquivo em disco da linha onde o índice é localizado;
Na verdade, a camada inferior do índice MySQL não é uma árvore binária, as razões são as seguintes
Se nossa consulta col1 for assim:
select * from t where t.col1=6;
Se for uma árvore binária, então a árvore binária correspondente a col1 é assim:
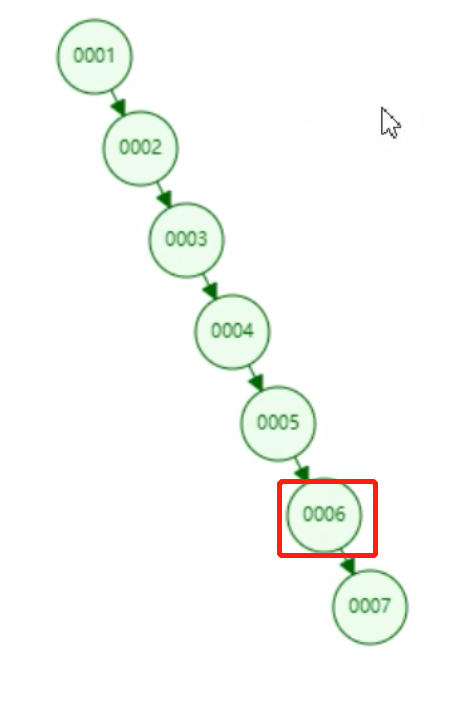
Neste momento, a árvore binária é equivalente a uma lista encadeada, e o número de vezes para procurar por col1=6 ainda é de 6 vezes, o que não melhora a eficiência da consulta; ou seja, se o índice usar uma árvore binária,
o os dados nesta coluna são dados incrementais, e a árvore binária não vai subir. Funciona, então a camada inferior do índice não é feita com uma árvore binária;
Árvore rubro-negra A
árvore rubro-negra também é chamada de árvore balanceada binária, que tem a função de balancear automaticamente a árvore. A árvore rubro-negra correspondente a col1 é a seguinte: Neste momento, o número de
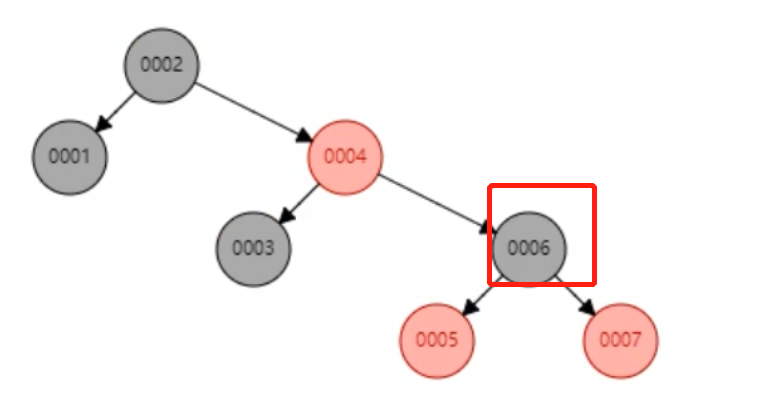
vezes para procurar col1= 6 é 3 vezes;
A camada inferior do índice MySQL não é uma árvore rubro-negra. As razões são as seguintes:
A altura da árvore é limitada: quando a quantidade de dados na tabela é muito grande, como 500w, a altura da árvore é muito alto. Por exemplo, a altura da árvore chega a 20, e você precisa verificar Os dados estão localizados no nó folha inferior, pelo menos 20 pesquisas são necessárias e 20 IOs de disco são necessários; então, o que precisamos fazer é reduzir a altura da árvore, como altura <= 4 ou altura <= 3, etc., somos Aceitáveis - árvore B;
árvore B
- Os nós folha têm a mesma profundidade e o ponteiro do nó folha é nulo
- Todos os elementos de índice não são repetidos
- O índice de dados no nó é organizado em ordem crescente da esquerda para a direita
A árvore rubro-negra anterior tem apenas um nó raiz, e a árvore B tem vários nós raiz (expansão horizontal).

A camada inferior do índice MySQL não usa uma árvore B pura, mas otimiza a árvore B, que é, a árvore B+
B+Tree (variante BTree)
- Os nós não-folha não armazenam dados, mas apenas índices (redundância) e mais índices podem ser colocados (isto é, os nós folha contêm todos os elementos de índice na tabela)
- Os nós não-folha são chamados de índices redundantes. Depois de obter alguns dados dos nós folha, os nós não-folha constroem árvores B+ (isto é, os nós não-folha são para construir árvores B+)
- Os nós folha contêm todos os campos de índice
- Os nós folha são conectados por ponteiros (B-trees não têm ponteiros), que armazenam a localização do nó atual no disco e melhoram o desempenho do acesso de intervalo
Cada linha abaixo chamamos de página

A camada inferior do índice MySQL usa uma árvore B+;
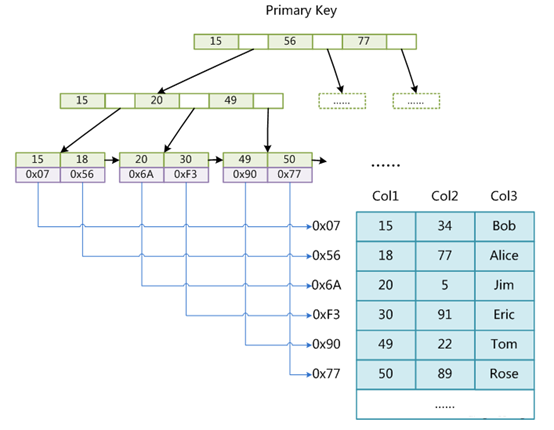
se procurarmos por col1=30, carregaremos primeiro todas as páginas do nó raiz (15, 56, 77) na memória (RAM) (relativamente demorado) , e então carregue o Compare 30 com esses dados na memória (relativamente demorado), se você usar busca binária para localizar rapidamente 30, está entre 15 e 56; então os dados na página 15 (15, 20, 49) também é Carregar na memória e comparar com 30...;
Então, por que não remover outros nós, deixar apenas os nós de folha, colocar todos os dados nos nós de folha e, em seguida, carregar os nós de folha na memória de uma vez e pesquisar diretamente 30 e os dados na memória pela metade? Se a quantidade de dados for muito grande, é fácil estourar a memória;
O tamanho de cada página é de cerca de 16K
#查看mysql页大小:16384字节——16KB
SHOW GLOBAL STATUS LIKE 'Innodb_page_size'
Quantos dados podem ser armazenados depois que a árvore B+ estiver cheia?
Por que 16 KB?
Se for usado o tipo bigInt (8 bits), cada índice ocupa 8 bits e o endereço entre 15 e 16 na figura acima é o endereço da próxima linha (página) (o endereço de 15, 20, 49), e este endereço ocupa 6 bits; Depois que os 16KB de dados da página estiverem cheios, o número de elementos de índice que podem ser colocados: 16kb/(8+6)b=1170; o nó folha é especial, tome o nó folha 15 como exemplo, o índice 15 pode ser armazenado nos dados O endereço do espaço em disco onde está localizado também pode armazenar todas as outras colunas da linha. Os dados podem ser relativamente grandes. Se for uma linha de dados, será 1kb se for estiver cheio (uma linha de registros geralmente não excederá 1kb), então este nó folha A quantidade aproximada de dados que podem ser armazenados é: 1kb/(8+6)b=16 (como geralmente é menor que 1kb, o valor de 16 obtido é um valor hipotético, não calculado aqui);
Resumindo, quando a árvore B+ está cheia, a quantidade de dados de índice que podem ser armazenados é:
1170X1170X16=21.902.400, ou seja, mais de 20 milhões; enquanto a altura da árvore é apenas 3, ou seja, os dados podem ser encontrado após 3 IOs;
O nó raiz do MySQL está, na verdade, diretamente na memória (o nó raiz reside na memória, ou seja, 15, 56 e 77 na figura acima já estão na memória logo no início), ou seja, na verdade não são 3 IOs, mas 2 vezes; após a versão superior do MySQL, todos os nós não-folha são colocados na memória, o que é mais rápido;
Por que a camada inferior do índice MySQL usa a árvore B+ em vez da árvore B?
Como mencionado acima, se a árvore B+ armazena 20 milhões de números, a altura da árvore é de apenas 3; e se for uma árvore B?
A árvore B é a seguinte:

O tamanho máximo de cada pedaço de dados é 1kb, e cada página é 16kb, então cada página (linha) de dados pode conter apenas 16 elementos de índice, ou seja, a enésima potência de 16 deve chegar a 20 milhões, e este n é o altura da árvore, obviamente, n Esta altura é muito maior que a altura 3 da árvore B+;
Tabelas e índices são armazenados em disco. Se a configuração não for alterada, o local padrão é:
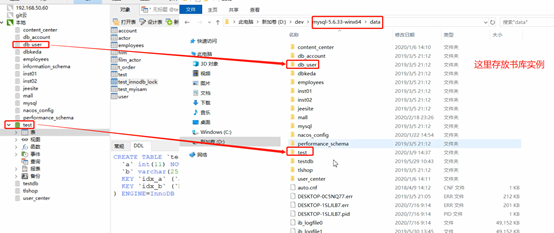
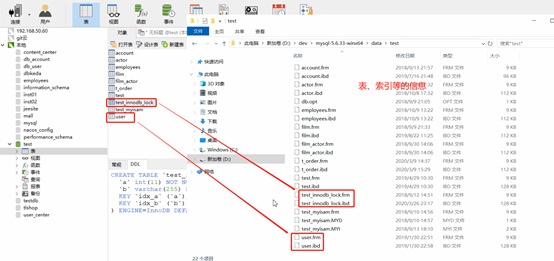
Mecanismo de armazenamento de duas tabelas MySQL
2.1 Introdução ao mecanismo de armazenamento
O mecanismo de armazenamento usa o banco de dados ou a tabela do banco de dados? é uma tabela de banco de dados.
Quando usamos o Navcat do MySQL para construir uma tabela, podemos escolher um mecanismo de armazenamento, da seguinte forma: o
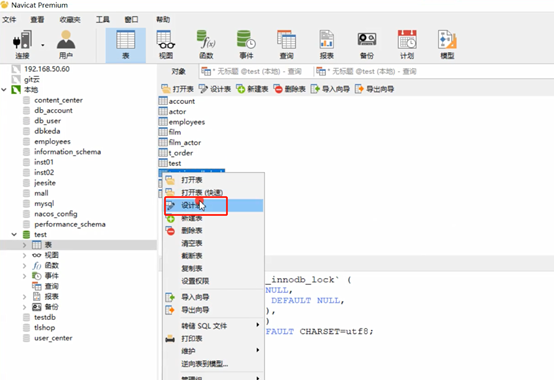
mecanismo de armazenamento geralmente selecionado é o InnorDB e a versão anterior usa o mecanismo de armazenamento MyISAM
2.2 Mecanismo de armazenamento MyISAM (não é mais usado)
Crie uma nova tabela e use o MyISAM como o mecanismo de armazenamento, da seguinte maneira
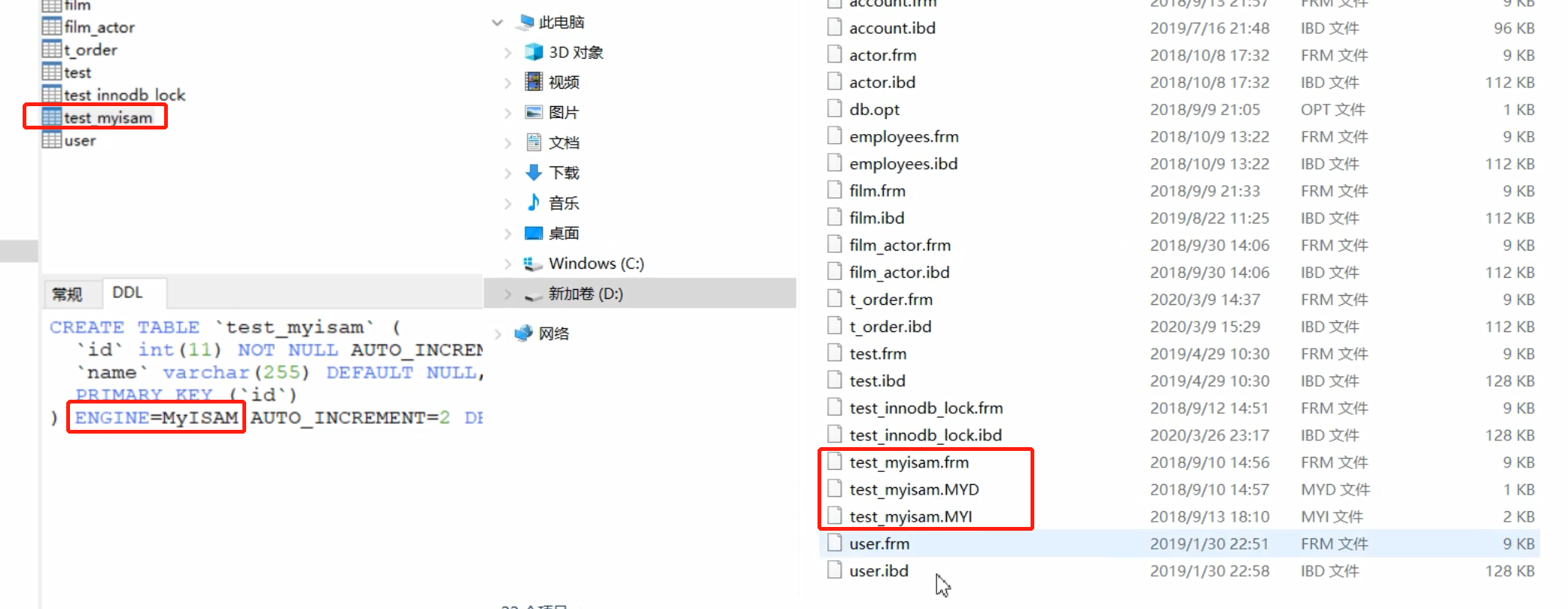
- .frm: Armazena as informações da estrutura da tabela de dados (frame frame para abreviar)
- .MYD: armazena dados (MY é a primeira letra de MyISAM, D é DATA)
- .MYI: armazena o índice (MY é a primeira letra do MyISAM, I é o índice do índice)
Arquivos de índice MyISAM e arquivos de dados são separados (não agrupados)
Se as condições de verificação forem as seguintes
select * from t where t.col1=30;
O MySQL primeiro localizará o elemento de índice na árvore de índice do arquivo MYI 0xF3e, em seguida, 0xF3encontrará uma linha de dados no disco no arquivo MYD de acordo com o endereço do arquivo em disco;
2.3 Mecanismo de armazenamento InnoDB
Crie uma nova tabela e use o InnorDB como mecanismo de armazenamento, da seguinte maneira
- .frm: Armazena as informações da estrutura da tabela de dados (frame frame para abreviar)
- .ibd: armazena dados e index()
Implementação de índice InnoDB (agregação)
- O próprio arquivo de dados da tabela é um arquivo de estrutura de índice organizado por B+Tree
- Índice agrupado - os nós folha contêm registros de dados completos
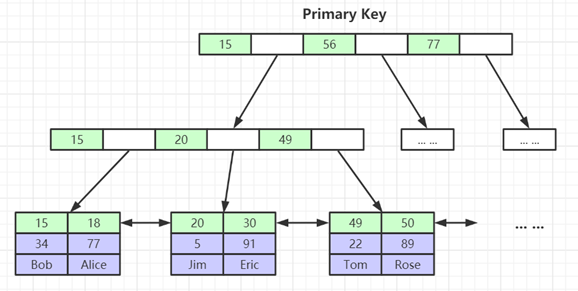
Como pode ser visto na figura acima, o nó folha armazena os dados de outras colunas da linha atual, por exemplo, o nó 15 armazena os dados de todas as outras colunas da linha 15, 34, Bob, etc. (índice clusterizado );
Ou seja, dados e índices InnoDB estão na mesma árvore (mesmo arquivo, índice clusterizado), enquanto MyISAM não está na mesma árvore (índice não clusterizado);
O que é mais rápido, um índice clusterizado ou um índice não clusterizado?
A agregação é rápida, porque o índice clusterizado não precisa pesquisar nos arquivos;
Por que é recomendável criar uma chave primária para tabelas InnoDB e usar chaves primárias de incremento automático inteiro?
O arquivo ibd deve ser organizado com uma árvore B+, então de onde vem essa árvore B+? Se a tabela tiver sua própria chave primária, use diretamente os dados da coluna dessa chave primária para construir os dados de toda a tabela da árvore B+. E sem uma chave primária? Se não houver chave primária, começará na primeira coluna para selecionar uma coluna sem dados repetidos como chave primária e usar esta coluna de dados para organizar uma árvore B+; se nenhuma coluna elegível for selecionada (nenhuma coluna de dados não é igual)? Então o MySQL criará uma nova coluna oculta, que manterá um id único para organizar os dados de toda a tabela;
Resumindo: depois de construirmos a chave primária, não precisamos ser tão problemáticos e não precisamos que o MySQL faça tanto trabalho extra;
Então, por que é recomendado que a chave primária seja plástica e auto-incrementada?
razões de plástico
- Ao procurar por um índice, a operação de comparação de tamanho é realizada na árvore B+, e o uuid é uma string, e a comparação de tamanho precisa ser comparada por meio da sequência de códigos ASSIC e comparada caractere por caractere, portanto, a eficiência da modelagem é alto;
- E o espaço ocupado pela modelagem é relativamente pequeno;
Razões para o auto-incremento
Vamos primeiro entender a estrutura Hash
Ao construir um índice, o padrão é B+Tree, e você também pode escolher a
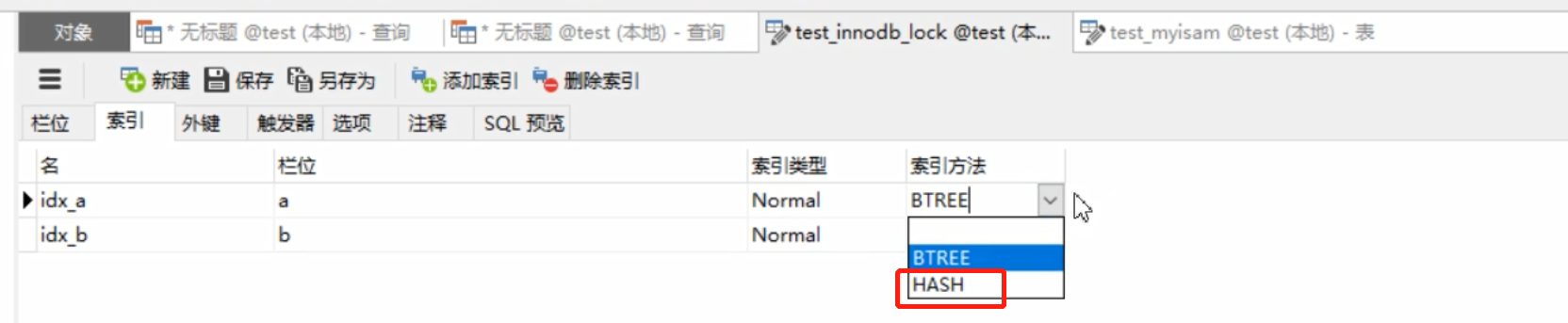
estrutura Hash Estrutura Hash
- Execute um cálculo de hash na chave do índice para localizar o local do armazenamento de dados
- Em muitos casos, o índice Hash é mais eficiente que o índice de árvore B+
- Só pode satisfazer "=", "IN", não suporta consulta de intervalo
- problema de conflito de hash
a tabela é a seguinte
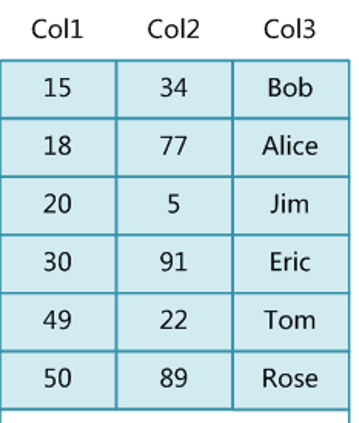
Se col3 for usado como um índice de hash, quando um dado for inserido, um algoritmo de hash (md5 e muitos outros algoritmos) será executado nos dados e o valor de hash obtido será colocado no balde de hash (matriz de hash) . Se o valor de hash obtido for o mesmo Se houver um conflito de hash, uma lista encadeada é gerada para armazenar dados com o mesmo valor de hash; por exemplo, se queremos encontrar uma linha de dados cujo nome = Alice, primeiro executamos uma operação de hash em Alice, obtenha o valor de hash e percorra a lista vinculada correspondente; na lista vinculada Além de armazenar o elemento de índice, cada nó de .com também armazena o endereço do arquivo de disco da linha em que o índice está localizado ;
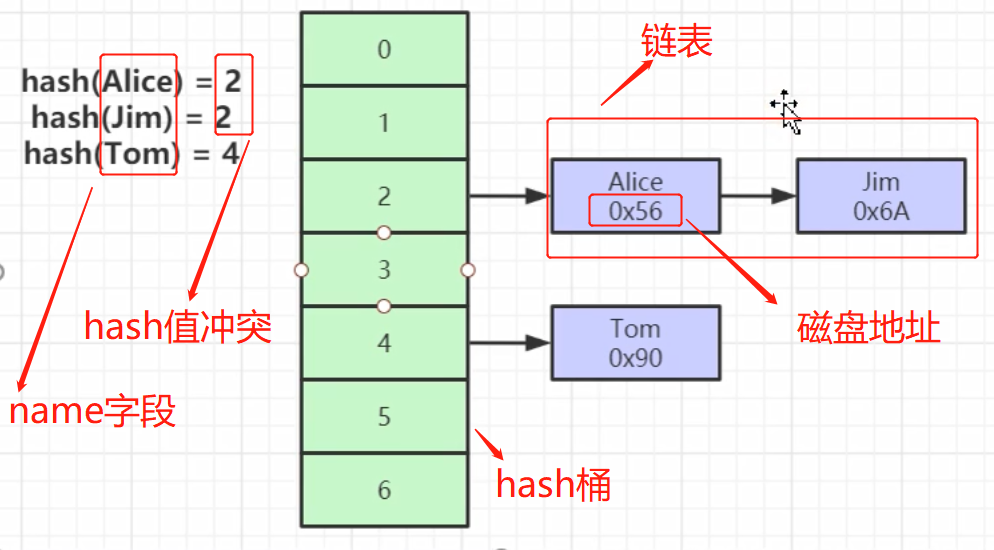
parece que esse tipo de busca de hash é mais rápido; então porque não usar a estrutura Hash, mas usar a árvore B+? O principal motivo é que o hash não oferece suporte a consultas =, in e range; a árvore B+ tem um ponteiro bidirecional no nó folha e a árvore B+ é classificada, portanto suporta consultas range;
Incremento não automático: quando novos dados são adicionados, o nó será dividido e, em seguida, a árvore será balanceada;
Incremento automático: quando novos dados forem adicionados, o nó não será dividido e um novo nó será criado;
Por que o nó folha da estrutura de índice de chave não primária armazena o valor da chave primária? (Consistência e economia de espaço de armazenamento)
Da seguinte forma, após indexar col3, o nó folha Alice armazena o valor da chave primária 18
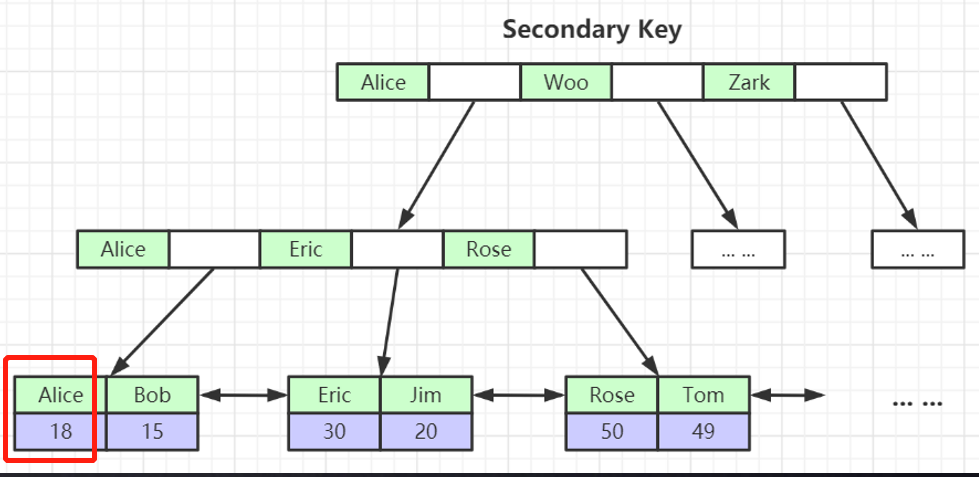
O índice secundário primeiro localiza o índice da chave primária e, em seguida, localiza os dados específicos por meio do índice da chave primária (o índice secundário tem uma operação de tabela de retorno);
Índice de junta tripla (índice composto)
Não é recomendável criar vários índices de valor único para uma tabela; geralmente, ao criar 2 a 3 índices conjuntos, mais de 80% das instruções SQL de consulta são cobertas;
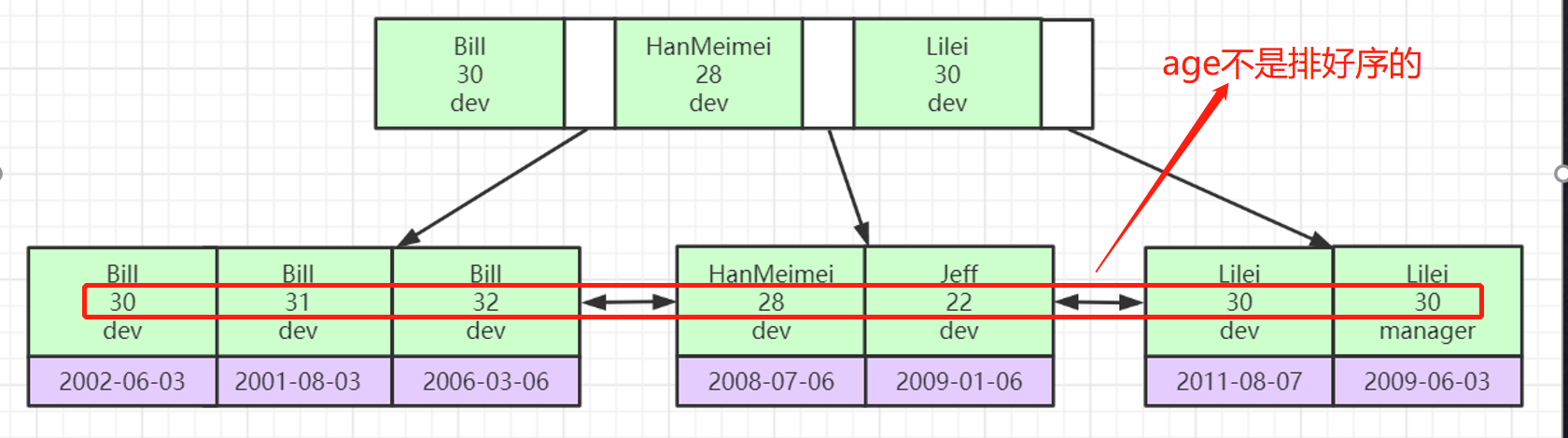
Crie um índice de chave primária conjunta para três campos : nome, idade, posição
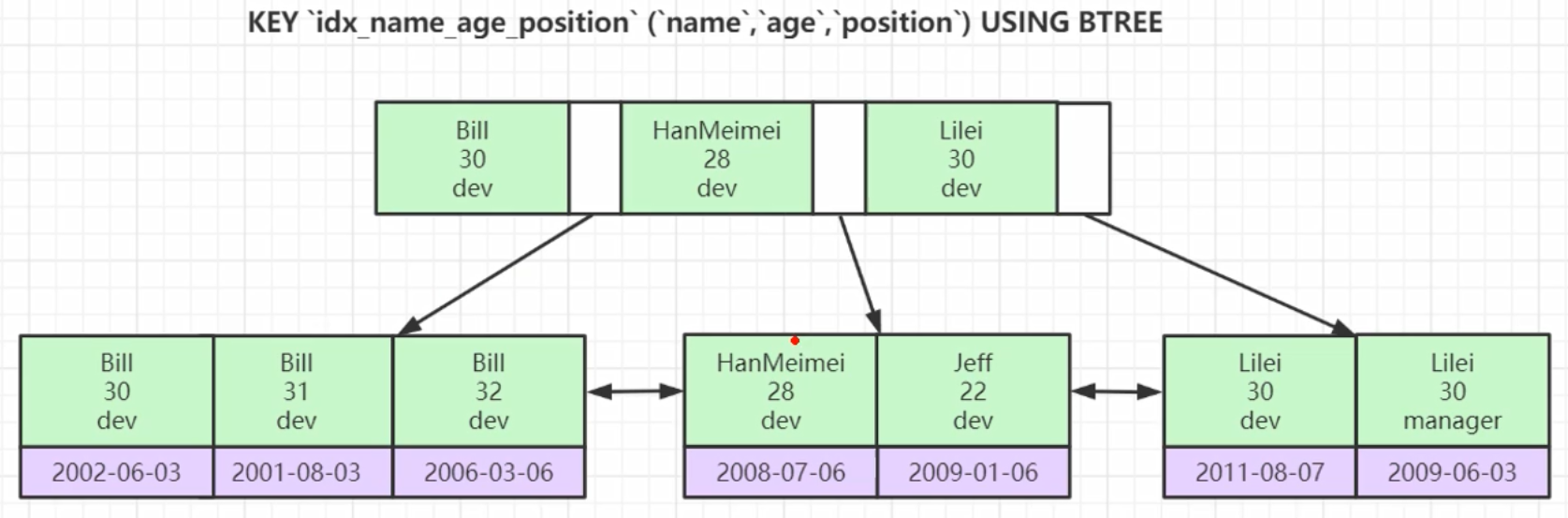
Ele será classificado de acordo com a ordem em que o índice foi estabelecido. Primeiro compare o nome, depois compare a idade e depois compare a posição para determinar a ordem. Após a classificação, ele será colocado na árvore do índice; se o nome é um
tipo de string, então compare cada personagem de acordo com Assic , quando a ordem pode ser classificada por nome, idade e posição não são consideradas; se o nome for o mesmo (ambos se chamam Bill), então compare a idade, se a idade for o mesmo, compare a posição, pois é uma chave primária conjunta, então aqui esses três Campos não podem ser iguais ao mesmo tempo;
índice princípio mais à esquerda
Sob a premissa de estabelecer um índice conjunto acima, qual declaração abaixo usará o índice?
# 走索引
1 SELECT * FROM employees WHERE name = 'Bill' and age = 31;
# 不走索引
2 SELECT * FROM employees WHERE age = 30 AND position = 'dev';
# 不走索引
3 SELECT * FROM employees WHERE position = 'manager';
Para o índice conjunto, ele deve ser usado na ordem em que o índice foi criado; então, por que deveria haver o princípio do índice mais à esquerda, por que o índice deveria ser usado na ordem de consulta de nome, idade e posição?
Os dados inseridos na árvore de índice são classificados e as regras de classificação são baseadas na ordem de nome, idade e posição quando o índice é construído;
Se não estivermos em conformidade com o princípio mais à esquerda, verifique diretamente idade = 30. Na tabela inteira, a idade não é classificada, portanto, o índice não desempenha um papel e a tabela inteira precisa ser verificada;