Um, Flume
1.1 Visão Geral
O Flume é um sistema de coleta, agregação e transmissão em massa distribuída, altamente disponível e confiável, fornecido pela Cloudera. O Flume suporta a coleta de dados de várias fontes de dados (como arquivos, pastas, pacotes Socket, Kafka, etc.); ao mesmo tempo, o Flume fornece processamento de dados simples e grava os dados processados em HDFS, hbase, hive, Kafka e muitos outros sistemas de armazenamento externo.
1.2 Princípio de operação
Vários conceitos importantes no Flume:
- Agente: É a função central do Flume, e o sistema de coleta do Flume é conectado por Agentes individuais. Um agente contém os componentes Source, Sink e Channel;
- Fonte: componente de coleta, responsável por obter os dados coletados da fonte de dados;
- Sink: componente sinking, responsável por transferir dados para o próximo nível do Agente, ou armazená-los em um dispositivo de armazenamento (como HDFS);
- Canal: componente do canal, responsável por transferir os dados da Fonte para o Sink;
A relação entre os componentes Source, Sink e Channel é mostrada na figura a seguir:

1.3 Instalação do Flume
Dica: Antes de instalar o Flume, você deve primeiro preparar o ambiente Hadoop.
A última versão do Flume é 1.9.0. Link para download: http://archive.apache.org/dist/flume/1.9.0/.
Após a conclusão do download, carregue o pacote compactado no /export/softwaresdiretório do servidor e descompacte /export/servers-o.
Depois que a descompactação for concluída, entre no cd /export/servers/apache-flume-1.8.0-bin/confdiretório, edite o arquivo flume-env.sh e defina a variável de ambiente JAVA_HOME.
cd /export/servers/apache-flume-1.8.0-bin/conf
cp flume-env.sh.template flume-env.sh
vi flume-env.sh
export JAVA_HOME=/export/servers/jdk1.8.0_141
1.4 Aplicação Flume
1.4.1 Colete dados do equipamento terminal
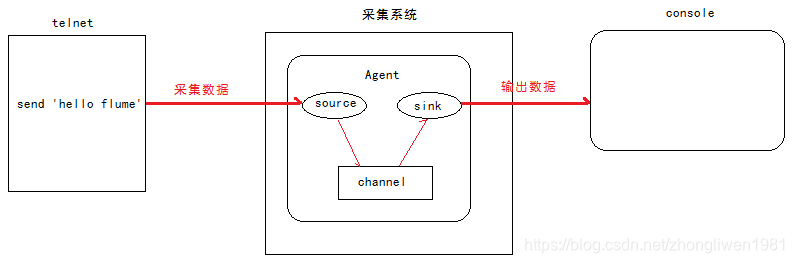
-
Análise de requisitos:
1) Inicie o Flume e vincule o IP e a porta;
2) Inicie o terminal e use telnet para enviar dados para o Flume;
3) O Flume envia os dados coletados para o console; -
Etapas de implementação:
Etapa 1: Crie um novo arquivo de configuração /export/servers/apache-flume-1.8.0-bin/conf/netcat-logger.confe defina o plano de coleta de dados no arquivo de configuração;
# 定义agent中各组件的名字
a1.sources = r1
a1.sinks = k1
a1.channels = c1
# 描述和配置source组件:r1
a1.sources.r1.type = netcat
# 绑定数据源提供方的地址
a1.sources.r1.bind = 192.168.31.9
# 绑定数据源提供方的端口
a1.sources.r1.port = 44444
# 描述和配置sink组件:k1
a1.sinks.k1.type = logger
# 描述和配置channel组件,此处使用是内存缓存的方式
a1.channels.c1.type = memory
a1.channels.c1.capacity = 1000
a1.channels.c1.transactionCapacity = 100
# 建立连接关系
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1
O a1 na configuração acima representa o nome do agente, que é especificado quando você inicia o Flume.
Etapa 2: iniciar o Flume;
cd /export/servers/apache-flume-1.8.0-bin/bin
flume-ng agent -c ../conf -f ../conf/netcat-logger.conf -n a1 -Dflume.root.logger=INFO,console
-c: especifica o diretório onde o arquivo de configuração está localizado;
-f: especifica o caminho do arquivo de configuração;
-n: especifica o nome do agente;
Etapa 3: inicie o terminal e use o telnet para testar;
telnet 192.168.31.9 44444
1.3.2 Coletar dados do arquivo
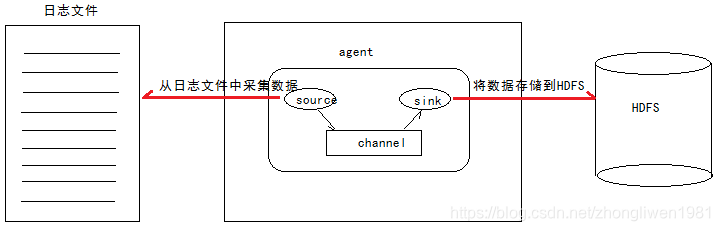
-
Análise de requisitos: por
exemplo, há um arquivo de log usado para uso comercial e o conteúdo do arquivo de log continuará a mudar. Agora precisamos coletar os dados do arquivo de log em tempo real e armazená-los no HDFS. -
Idéias de implementação:
1) Fonte: monitorar a atualização do conteúdo do arquivo, o formato do comando éexec ‘tail -F file’;
2) Sink: usar HDFS;
3) Canal: pode ser do tipo arquivo ou memória; -
Etapas de implementação:
Etapa 1: Crie um novo arquivo de configuração /export/servers/apache-flume-1.8.0-bin/conf/tail-file.confe defina o plano de coleta de dados no arquivo de configuração;
# 设置agent中各组件的名字
a1.sources = source1
a1.sinks = sink1
a1.channels = channel1
# 描述source组件
a1.sources.source1.type = exec
a1.sources.source1.command = tail -F /export/servers/taillogs/access_log
# 描述Sink组件
a1.sinks.sink1.type = hdfs
a1.sinks.sink1.hdfs.path = hdfs://node01:8020/weblog/flume-collection/%y-%m-%d/%H%M/
a1.sinks.sink1.hdfs.filePrefix = access_log
a1.sinks.sink1.hdfs.maxOpenFiles = 5000
a1.sinks.sink1.hdfs.batchSize= 100
a1.sinks.sink1.hdfs.fileType = DataStream
a1.sinks.sink1.hdfs.writeFormat =Text
a1.sinks.sink1.hdfs.round = true
a1.sinks.sink1.hdfs.roundValue = 10
a1.sinks.sink1.hdfs.roundUnit = minute
a1.sinks.sink1.hdfs.useLocalTimeStamp = true
# 描述channel组件
a1.channels.channel1.type = memory
a1.channels.channel1.keep-alive = 120
a1.channels.channel1.capacity = 500000
a1.channels.channel1.transactionCapacity = 600
# 建立连接
a1.sources.source1.channels = channel1
a1.sinks.sink1.channel = channel1
Etapa 2: iniciar o Flume;
cd /export/servers/apache-flume-1.6.0-cdh5.14.0-bin/bin
flume-ng agent -c ../conf -f ../conf/tail-file.conf -n a1 -Dflume.root.logger=INFO,console
A terceira etapa: escrever um script para gravar dados continuamente no arquivo de log;
# 新建shells文件夹,用于存放脚本文件
mkdir -p /export/servers/shells/
cd /export/servers/shells/
vi tail-file.sh
#!/bin/bash
while true
do
date >> /export/servers/taillogs/access_log;
sleep 0.5;
done
Etapa 4: inicie o script;
mkdir -p /export/servers/taillogs
sh /export/servers/shells/tail-file.sh
1.3.3 Pasta de coleção
-
Análise de demanda:
por exemplo, colete o diretório de log do servidor de aplicativos. Sempre que um novo arquivo de log é gerado, o arquivo de log precisa ser coletado no HDFS. -
Idéias de implementação:
1) Fonte: diretório do arquivo do monitor, o formato do comando éspooldir’;
2) Sink: use HDFS;
3) Canal: pode ser do tipo arquivo ou memória; -
Etapas de implementação:
Etapa 1: Crie um novo arquivo de configuração /export/servers/apache-flume-1.8.0-bin/conf/spooldir.confe defina o plano de coleta de dados no arquivo de configuração;
# 设置Agent中各个组件的名字
a1.sources = source1
a1.sinks = sink1
a1.channels = channel1
# 描述和配置Source组件
# 注意:监控目录不能够出现同名文件
a1.sources.source1.type = spooldir
a1.sources.source1.spoolDir = /export/servers/dirfile
a1.sources.source1.fileHeader = true
# 描述和配置Sink组件
a1.sinks.sink1.type = hdfs
a1.sinks.sink1.hdfs.path = hdfs://node01:8020/spooldir/files/%y-%m-%d/%H%M/
a1.sinks.sink1.hdfs.filePrefix = events-
a1.sinks.sink1.hdfs.round = true
a1.sinks.sink1.hdfs.roundValue = 10
a1.sinks.sink1.hdfs.roundUnit = minute
a1.sinks.sink1.hdfs.rollInterval = 3
a1.sinks.sink1.hdfs.rollSize = 20
a1.sinks.sink1.hdfs.rollCount = 5
a1.sinks.sink1.hdfs.batchSize = 1
a1.sinks.sink1.hdfs.useLocalTimeStamp = true
# 生成的文件类型,默认是Sequencefile,DataStream代表普通文本类型
a1.sinks.sink1.hdfs.fileType = DataStream
# 描述和配置通道
a1.channels.channel1.type = memory
a1.channels.channel1.capacity = 1000
a1.channels.channel1.transactionCapacity = 100
# 建立连接
a1.sources.source1.channels = channel1
a1.sinks.sink1.channel = channel1
Etapa 2: iniciar o Flume;
cd /export/servers/apache-flume-1.6.0-cdh5.14.0-bin/bin
flume-ng agent -c ../conf -f ../conf/spooldir.conf -n a1 -Dflume.root.logger=INFO,console
Após a conclusão da inicialização, você pode /export/servers/dirfileadicionar arquivos continuamente ao diretório e, em seguida, ver os arquivos de log coletados no caminho / spooldir do HDFS.
1.3.4 Cascata de Agente
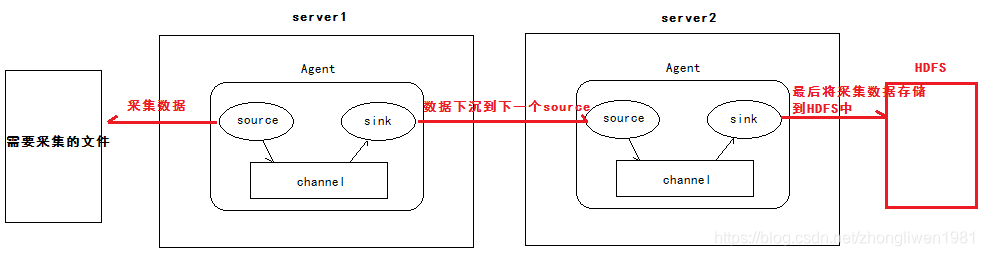
-
Análise de demanda:
1) O primeiro agente é responsável por coletar dados do arquivo especificado e, em seguida, enviá-los para o próximo agente através da rede;
2) O segundo agente é responsável por receber os dados enviados do primeiro agente e salvar os dados para HDFS; -
Etapas de implementação:
A primeira etapa: preparar dois hosts para instalar o ambiente hadoop e flume, eles são node01 e node02 respectivamente;
Etapa 2: Defina node01 e node02 para usar o protocolo avro para transmitir dados, respectivamente;
cd /export/servers/ apache-flume-1.8.0-bin/conf
vi tail-avro-avro-logger.conf
A configuração do node01:
# 设置agent中各个组件的名字
a1.sources = source1
a1.sinks = sink1
a1.channels = channel1
a1.sources.source1.type = exec
a1.sources.source1.command = tail -F /export/servers/taillogs/access_log
a1.sources.source1.channels = channel1
# 设置Sink的类型为avro
a1.sinks.sink1.type = avro
# 指定下沉到下一个agent的主机地址
a1.sinks.sink1.hostname = node02
a1.sinks.sink1.port = 4141
a1.sinks.sink1.batch-size = 10
# 配置channel
a1.channels.channel1.type = memory
a1.channels.channel1.capacity = 1000
a1.channels.channel1.transactionCapacity = 100
# 建立连接
a1.sources.source1.channels = channel1
a1.sinks.sink1.channel = channel1
A configuração do node02:
a1.sources = source1
a1.sinks = sink1
a1.channels = channel1
# 设置source的类型为avro
a1.sources.source1.type = avro
# 指定从哪个source获取数据
a1.sources.source1.bind = node01
a1.sources.source1.port = 4141
a1.sinks.sink1.type = hdfs
a1.sinks.sink1.hdfs.path = hdfs://node01:8020/av/%y-%m-%d/%H%M/
a1.sinks.sink1.hdfs.filePrefix = events-
a1.sinks.sink1.hdfs.round = true
a1.sinks.sink1.hdfs.roundValue = 10
a1.sinks.sink1.hdfs.roundUnit = minute
a1.sinks.sink1.hdfs.rollInterval = 3
a1.sinks.sink1.hdfs.rollSize = 20
a1.sinks.sink1.hdfs.rollCount = 5
a1.sinks.sink1.hdfs.batchSize = 1
a1.sinks.sink1.hdfs.useLocalTimeStamp = true
#生成的文件类型,默认是Sequencefile,可用DataStream,则为普通文本
a1.sinks.sink1.hdfs.fileType = DataStream
a1.channels.channel1.type = memory
a1.channels.channel1.capacity = 1000
a1.channels.channel1.transactionCapacity = 100
a1.sources.source1.channels = channel1
a1.sinks.sink1.channel = channel1
Etapa 3: iniciar o canal de node01 e node2 respectivamente;
cd /export/servers/apache-flume-1.8.0-bin/bin
flume-ng agent -c ../conf -f ../conf/avro-hdfs.conf -n a1 -Dflume.root.logger=INFO,console
Depois que a inicialização for concluída, execute o teste de script escrito acima.
mkdir -p /export/servers/taillogs
sh /export/servers/shells/tail-file.sh
1.3.5 Alta Disponibilidade
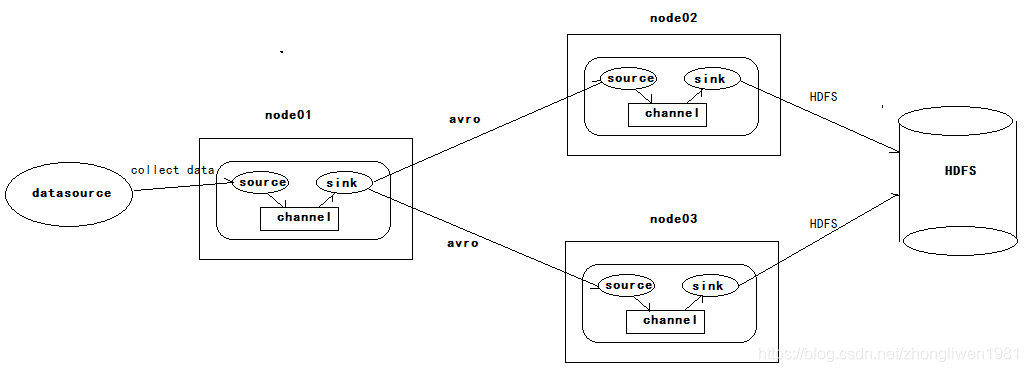
Existem três hosts nele, node01, node02 e node03. node01 é responsável por coletar dados externos e, em seguida, enviar os dados coletados para node02 ou node03. O próprio Flume NG fornece um mecanismo de fusível para alcançar alta disponibilidade. Portanto, mesmo se node02 ou node03 for fusível, Flume NG pode alternar ou retomar as operações automaticamente.
A versão do Flume no momento de seu lançamento é conhecida coletivamente como Flume OG. No entanto, com a expansão contínua das funções do Flume, deficiências como engenharia de código Flume OG inchada, design de componente de núcleo irracional e configuração de núcleo não padrão foram expostos. Em outubro de 2011, a equipe de desenvolvimento do Flume refatorou o Flume NG, e a versão refatorada é coletivamente conhecida como Flume NG. Após a reestruturação, o Flume NG se tornou uma ferramenta leve de coleta de logs que suporta fusão e balanceamento de carga.
Para configurar a alta disponibilidade, você só precisa definir dois coletores no esquema de coleta node01, apontando para node02 e node03 respectivamente.

configuração do coletor:
# sink1
agent1.sinks.k1.channel = c1
agent1.sinks.k1.type = avro
agent1.sinks.k1.hostname = node02
agent1.sinks.k1.port = 52020
# sink2
agent1.sinks.k2.channel = c1
agent1.sinks.k2.type = avro
agent1.sinks.k2.hostname = node03
agent1.sinks.k2.port = 52020
# 将sink添加到sink group里面
agent1.sinkgroups.g1.sinks = k1 k2
Para ativar a fusão, você precisa definir o tipo de processamento do coletor para failover.
agent1.sinkgroups.g1.processor.type = failover
# 设置权重,权重越高,优先级也就越高
agent1.sinkgroups.g1.processor.priority.k1 = 10
agent1.sinkgroups.g1.processor.priority.k2 = 1
# 设置failover time的上限,单位是毫秒,如果没有设置,默认为30秒
agent1.sinkgroups.g1.processor.maxpenalty = 10000
- Trabalho de teste:
Primeiro, carregamos os arquivos no Node01, e o Node01 é responsável por coletar dados do diretório de log especificado. Como o peso do sink1 é mais pesado do que o do sink2, o agente do Node02 é coletado e carregado primeiro no sistema de armazenamento. Em seguida, eliminamos o node02. Neste momento, o Node03 é responsável pela coleta e upload dos logs. Em seguida, restauramos manualmente o serviço Flume do nó Node02 e, em seguida, carregamos os arquivos no Node01 novamente e descobrimos que o Node02 retoma a coleta de níveis de prioridade.
1.3.6 Balanceamento de carga
Se o Agente1 for um nó de roteamento, ele é responsável por balancear o Evento armazenado temporariamente no Canal para vários componentes Sink correspondentes, e cada componente Sink é conectado a um Agente independente. Da seguinte forma:
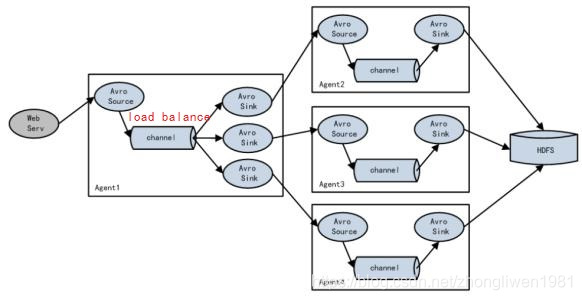
Função de balanceamento automático de carga Flume NG. Se você deseja iniciar o balanceamento de carga, você só precisa definir o tipo de processamento do grupo de coletores como load_balance.
agent1.sinkgroups.g1.processor.type = load_balance
agent1.sinkgroups.g1.processor.backoff = true
agent1.sinkgroups.g1.processor.selector = round_robin
agent1.sinkgroups.g1.processor.selector.maxTimeOut = 10000
1.3.7 Interceptador
Suponha que haja dois hosts A e B que coletam dados do arquivo de log em tempo real. Por fim, faça um resumo no host C e salve-o no HDFS.
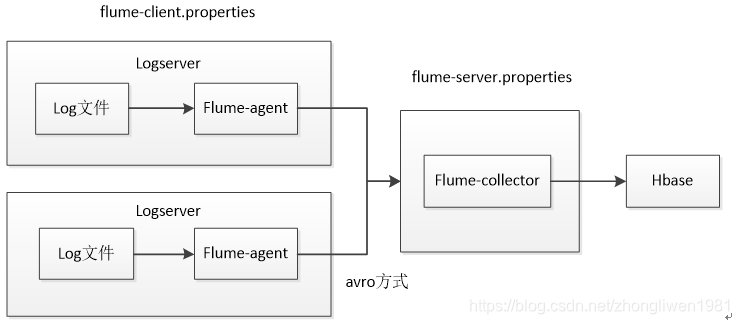
Dois servidores de log são implantados acima para coletar dados de log. Eles enviam os dados coletados para o coletor Flume para agregação e, em seguida, armazenam os dados agregados em Hbase ou HDFS.
Pergunta: Como os dados do arquivo de log são coletados quando há dois hosts, como o Flume-Collector sabe de qual arquivo de log os dados coletados vêm? ? ? ? ? A resposta é usar interceptores.
1.3.7.1 O que é um interceptor
O interceptor é um componente definido entre a fonte e o canal. O interceptor pode converter ou excluir esses eventos antes de gravar a hora recebida pela fonte no canal. Cada interceptor processa apenas eventos recebidos pela mesma fonte.
- Interceptador embutido:
1) Interceptor de carimbo de data / hora: Usando este interceptor, o Agente irá inserir o carimbo de data / horaevent headernele. Se você não usar nenhum interceptador, o Flume receberá apenas mensagens.
2) Interceptador de host: Este interceptor irá inserir o endereço IP do host ou o nome do hostevent headernele;
3) Interceptor estático: Este interceptor irá inserir k / vevent headernele;
4) Interceptor de filtragem Regex: Este interceptor pode inserir Alguns logs desnecessários são filtrados , e os dados de registro que atendem às condições regulares podem ser coletados conforme necessário;
5) Interceptador do extrator Regex:event headeradicione o k / v especificado para atender ao conteúdo regular;
6) Interceptor UUID:events headergera em cada string A UUID, o UUID gerado pode ser ler no coletor;
7) Interceptor Morphline: Este interceptor usa Morphline para converter os dados de cada evento de acordo;
8) Interceptador de Pesquisa e Substituição: Este interceptor é baseado em expressões regulares Java Fornece funções de pesquisa e substituição simples baseadas em string;
1.3.7.2 Uso de interceptores
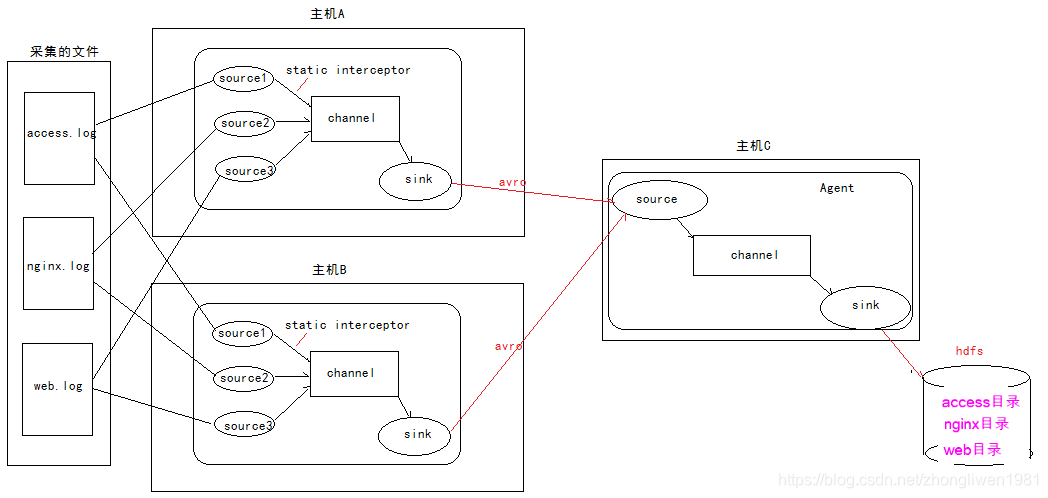
Defina três origens no host a e host b para coletar dados de arquivos de log diferentes. Como o static interceptorinterceptor é definido no host ae host b , o interceptor adicionará o k / v especificado (como type = access, type = nginx, type = web) a event headerele. Em seguida, coloque os dados coletados no host c para obter um resumo. Após o resumo, c do host event headeradquire o valor do tipo dos arquivos de diretório armazenados em hdfs como o tipo, o último armazenamento de dados agregado (um formato de armazenamento de dados) para o diretório especificado em hdfs.

1.3.7.3 Configuração do interceptor
- A configuração de node01 e node02:
# 定义3个source
a1.sources = r1 r2 r3
a1.sinks = k1
a1.channels = c1
# 第一个source采集access.log文件数据
a1.sources.r1.type = exec
a1.sources.r1.command = tail -F /export/servers/taillogs/access.log
# 定义静态拦截器,每一个source定义一个拦截器
a1.sources.r1.interceptors = i1
a1.sources.r1.interceptors.i1.type = static
a1.sources.r1.interceptors.i1.key = type
a1.sources.r1.interceptors.i1.value = access
# 第二个source采集nginx.log文件数据
a1.sources.r2.type = exec
a1.sources.r2.command = tail -F /export/servers/taillogs/nginx.log
a1.sources.r2.interceptors = i2
a1.sources.r2.interceptors.i2.type = static
a1.sources.r2.interceptors.i2.key = type
a1.sources.r2.interceptors.i2.value = nginx
# 第三个source采集web.log文件数据
a1.sources.r3.type = exec
a1.sources.r3.command = tail -F /export/servers/taillogs/web.log
a1.sources.r3.interceptors = i3
a1.sources.r3.interceptors.i3.type = static
a1.sources.r3.interceptors.i3.key = type
a1.sources.r3.interceptors.i3.value = web
# 定义Sink
a1.sinks.k1.type = avro
a1.sinks.k1.hostname = node03
a1.sinks.k1.port = 41414
# 定义channel
a1.channels.c1.type = memory
a1.channels.c1.capacity = 20000
a1.channels.c1.transactionCapacity = 10000
# 与channel建立连接
a1.sources.r1.channels = c1
a1.sources.r2.channels = c1
a1.sources.r3.channels = c1
a1.sinks.k1.channel = c1
- A configuração do node03:
a1.sources = r1
a1.sinks = k1
a1.channels = c1
# 定义source
a1.sources.r1.type = avro
a1.sources.r1.bind = node03
a1.sources.r1.port =41414
# 添加时间拦截器
a1.sources.r1.interceptors = i1
a1.sources.r1.interceptors.i1.type = org.apache.flume.interceptor.TimestampInterceptor$Builder
# 定义channel
a1.channels.c1.type = memory
a1.channels.c1.capacity = 20000
a1.channels.c1.transactionCapacity = 10000
# 定义sink
a1.sinks.k1.type = hdfs
a1.sinks.k1.hdfs.path=hdfs://node01:8020/source/logs/%{type}/%Y%m%d
a1.sinks.k1.hdfs.filePrefix =events
a1.sinks.k1.hdfs.fileType = DataStream
a1.sinks.k1.hdfs.writeFormat = Text
# 时间类型
a1.sinks.k1.hdfs.useLocalTimeStamp = true
# 不按条数生成
a1.sinks.k1.hdfs.rollCount = 0
# 按时间生成,单位为秒
a1.sinks.k1.hdfs.rollInterval = 30
# 按大小生成
a1.sinks.k1.hdfs.rollSize = 10485760
# 批量写入hdfs的个数
a1.sinks.k1.hdfs.batchSize = 10000
# 操作hdfs的线程数
a1.sinks.k1.hdfs.threadsPoolSize=10
# 操作hdfs超时时间,单位为毫秒
a1.sinks.k1.hdfs.callTimeout=30000
# 与channel建立连接
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1
- Roteiro de coleta de dados:
# !/bin/bash
while true
do
date >> /export/servers/taillogs/access.log;
date >> /export/servers/taillogs/web.log;
date >> /export/servers/taillogs/nginx.log;
sleep 0.5;
done