Um, Hive
1.1 Data Warehouse
1.1.1 Banco de dados e data warehouse
1) O banco de dados é orientado a transações e o data warehouse é orientado ao assunto;
2) O banco de dados geralmente armazena dados de negócios, e o data warehouse geralmente armazena dados históricos;
3) O design do banco de dados deve evitar redundância tanto quanto possível, geralmente para um determinado projeto de aplicativo de negócios; o data warehouse deliberadamente introduz redundância ao projetar e projetar de acordo com os requisitos de análise, dimensões de análise e indicadores de análise;
4) O banco de dados é projetado para capturar dados, e o data warehouse é projetado para analisar dados;
O data warehouse é gerado para extrair mais recursos de dados para que os usuários de dados tomem decisões quando já houver um grande número de bancos de dados.
1.1.2 A arquitetura em camadas do data warehouse
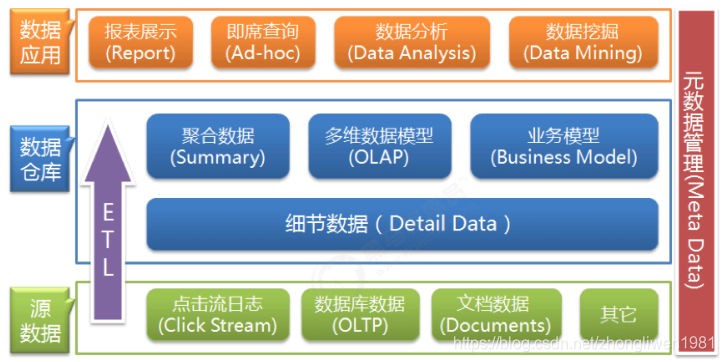
Pode-se ver no diagrama de arquitetura que a camada inferior é a fonte de dados. Os dados no data warehouse geralmente vêm de diferentes fontes de dados. Pode ser um arquivo de documento ou um banco de dados. A camada intermediária é nosso data warehouse e a camada superior é a camada de aplicativo de dados. Pode-se ver que, depois que os dados fluem para o data warehouse de baixo para cima, ele fornece suporte de dados para aplicativos de nível superior. Pode-se entender que o data warehouse é apenas uma plataforma intermediária de gerenciamento de dados integrado.
O data warehouse obtém dados de várias fontes de dados, assim como a conversão e o fluxo de dados no data warehouse podem ser considerados como o processo de ETL (Extrair Extra, Converter, Transferir Carregar). ETL é o pipeline do data warehouse e também pode ser considerado o sangue do data warehouse. Ele mantém o metabolismo dos dados no data warehouse e a maior parte da energia no gerenciamento e manutenção diários do data warehouse é manter o ETL normal e estável.
1.1.3 Gestão de Metadados de Data Warehouse
Os metadados registram principalmente a definição do modelo no data warehouse, o relacionamento de mapeamento entre vários níveis, o status dos dados do data warehouse de monitoramento e o status de execução da tarefa do ETL. Geralmente, ele será armazenado e gerenciado uniformemente por meio de um banco de dados de metadados.
Os metadados são uma parte importante do sistema de gerenciamento de data warehouse, que percorre todo o processo de construção do data warehouse e afeta diretamente a construção, o uso e a manutenção do data warehouse.
Sua principal função:
- Ele define o mapeamento do sistema de dados de origem para o data warehouse, as regras de conversão de dados, a estrutura lógica do data warehouse, as regras de atualização de dados, o histórico de importação de dados e o ciclo de carregamento e outros conteúdos relacionados;
- Ao usar o data warehouse, os usuários acessam os dados por meio de metadados, esclarecem o significado dos itens de dados e personalizam os relatórios;
- A escala e a complexidade do data warehouse são inseparáveis do gerenciamento correto de metadados, incluindo adicionar ou remover fontes de dados externas, alterar métodos de limpeza de dados, controlar consultas de erro e organizar backups; os
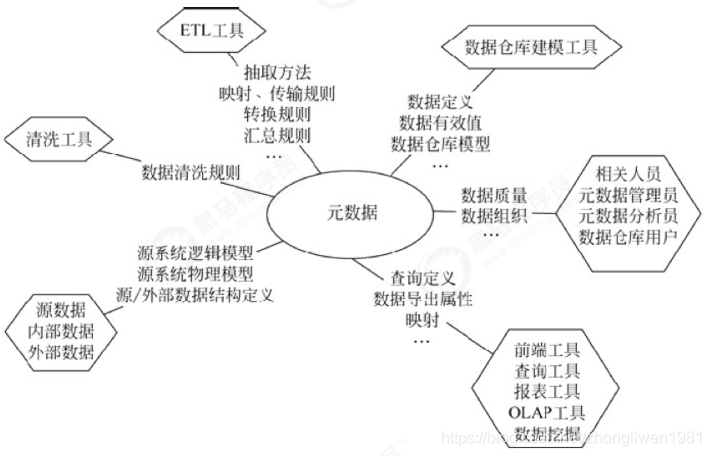
metadados podem ser divididos em metadados técnicos e metadados de negócios. Metadados técnicos são usados pelo pessoal de TI que desenvolve e gerencia data warehouses. Descreve dados relacionados ao desenvolvimento, gerenciamento e manutenção de data warehouse, incluindo informações de fonte de dados, descrição de conversão de dados, modelo de data warehouse, limpeza de dados e regras de atualização e mapeamento de dados. direitos de acesso, etc. Os metadados de negócios servem para gerenciamento e analistas de negócios. Eles descrevem dados de uma perspectiva de negócios, incluindo termos de negócios, quais dados estão no data warehouse, a localização dos dados e a disponibilidade de dados, etc., ajudando os usuários de dados a entender melhor o que está no armazém de dados Os dados estão disponíveis e como usá-los.
Pode-se ver que os metadados não apenas definem o modo, fonte, extração e regras de conversão dos dados no data warehouse, mas também são a base para a operação de todo o sistema de data warehouse. Os metadados conectam os componentes soltos no data warehouse sistema para formar um todo orgânico.
1.2 Introdução ao Hive
1.2.1 Conceitos básicos do Hive
Hive é uma ferramenta de data warehouse baseada em Hadoop, usada principalmente para extração, conversão e carregamento de dados. O Hive pode mapear arquivos de dados estruturados em uma tabela de dados e fornecer funções de consulta SQL. Ele pode converter instruções SQL em tarefas MapReduce para cálculos. A camada subjacente é o HDFS para fornecer armazenamento de dados.
1.2.2 Arquitetura básica do Hive
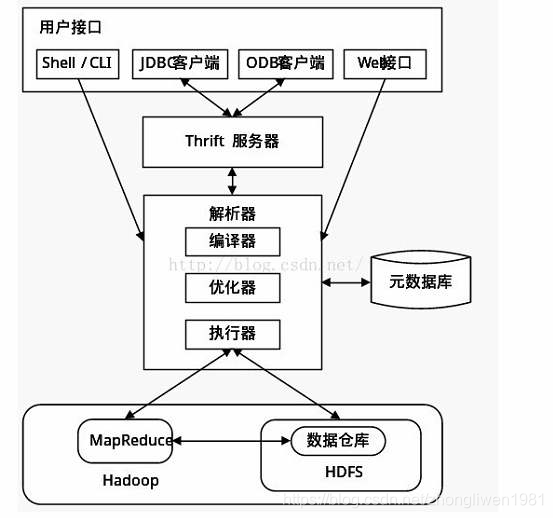
- Interface do usuário : incluindo CLI, JDBC / ODBC, WebGUI. Entre eles, CLI é uma linha de comando shell, JDBC / ODBC é a implementação JAVA do Hive e WebGUI é para acessar o Hive por meio de um navegador.
- Armazenamento de metadados : geralmente armazenado em bancos de dados relacionais como mysql / derby. O Hive armazena metadados no banco de dados. Os metadados no Hive incluem informações da tabela, informações da coluna, informações da partição e o diretório onde os dados da tabela estão localizados.
- Intérprete, compilador, otimizador, executor : declaração de consulta HQL completa de análise lexical, análise de sintaxe, compilação, otimização e geração de plano de consulta. O plano de consulta gerado é armazenado no HDFS e invocado e executado pelo MapReduce.
1.2.3 A relação entre o Hive e os bancos de dados tradicionais
| Colmeia | RDBMS | |
|---|---|---|
| Linguagem de consulta | HQL | SQL |
| armazenamento de dados | HDFS | Dispositivo bruto ou FS local |
| realizado | MapReduce | Executor |
| Atraso de dados | Alto | baixo |
| Tamanho dos dados | Grande | pequena |
| Cenários de aplicação | Análise estatística de dados | Armazenamento persistente de dados |
1.3 Instalação do Hive
- Etapa 1: Baixe o pacote compactado e descompacte-o;
cd /export/softwares/
tar -zxvf apache-hive-3.1.0-bin.tar.gz -C ../servers/
- Etapa 2: modificar o arquivo de configuração do hive;
cd /export/servers/apache-hive-3.1.0-bin/conf
cp hive-env.sh.template hive-env.sh
# 配置HADOOP_HOME
HADOOP_HOME=/export/servers/hadoop-3.1.1
# Hive配置文件路径
export HIVE_CONF_DIR=/export/servers/apache-hive-3.1.0-bin/conf
hive-site.xml :
cd /export/servers/apache-hive-3.1.0-bin/conf
vim hive-site.xml
Conteúdo do arquivo de configuração:
<?xml version="1.0" encoding="UTF-8" standalone="no"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<property>
<name>javax.jdo.option.ConnectionUserName</name>
<value>root</value>
</property>
<property>
<name>javax.jdo.option.ConnectionPassword</name>
<value>123456</value>
</property>
<property>
<name>javax.jdo.option.ConnectionURL</name>
<value>jdbc:mysql://node03:3306/hive?createDatabaseIfNotExist=true&useSSL=false</value>
</property>
<property>
<name>javax.jdo.option.ConnectionDriverName</name>
<value>com.mysql.jdbc.Driver</value>
</property>
<property>
<name>hive.metastore.schema.verification</name>
<value>false</value>
</property>
<property>
<name>datanucleus.schema.autoCreateAll</name>
<value>true</value>
</property>
<property>
<name>hive.server2.thrift.bind.host</name>
<value>node03.hadoop.com</value>
</property>
</configuration>
- Etapa 3: Configurar as variáveis de ambiente do hive;
# 修改配置文件
sudo vim /etc/profile
export HIVE_HOME=/export/servers/apache-hive-3.1.0-bin
export PATH=:$HIVE_HOME/bin:$PATH
- Etapa 4: Instale o mysql no node03 e inicie o serviço mysql;
# 安装mysql相关包
yum install mariadb mariadb-server
# 启动mysql服务
systemctl start mariadb
# 设置用户名和密码
mysql_secure_installation
# 给用户授权
grant all privileges on *.* to 'root'@'%' identified by 'root' with grant option;
flush privileges;
-
Etapa 5: Adicione o pacote de driver mysql ao diretório lib do hive;
-
Etapa 6: inicie o serviço hadoop e execute o
hivecomando. Se aparecer umhive>prompt, significa que a instalação foi bem-sucedida (conforme mostrado abaixo);
1.4 Operação básica do Hive
1.4.1 Operações de banco de dados
- Criar banco de dados
create database [if not exists] 数据库名;
- Crie um banco de dados e especifique o local de armazenamento
create database 数据库名 location 存储路径;
例如:
create database myhive location '/myhive';
O local de armazenamento padrão do hive hive.metastore.warehouse.diré especificado pelos parâmetros do arquivo de configuração hive-site.xmlp .

- Modifique o banco de dados
O Hive pode modificar apenas algumas propriedades básicas do banco de dados, mas não pode modificar informações de metadados (como nome do banco de dados, localização do banco de dados, etc.).
alter database 数据库名 set dbproperties('参数名'='属性值');
- Veja os detalhes do banco de dados
desc database [extended] 数据库名;
Se o parâmetro estendido for especificado, as informações detalhadas do banco de dados serão exibidas.
- Excluir banco de dados
drop database 数据库名 [cascade];
Se o banco de dados não estiver vazio, você precisará especificar o parâmetro cascade.
1.4.2 Operações de mesa
1.4.2.1 A sintaxe básica da criação de uma tabela
A sintaxe básica para criar uma tabela:
CREATE [EXTERNAL] TABLE [IF NOT EXISTS] table_name
[(col_name data_type [COMMENT col_comment], ...)]
[COMMENT table_comment]
[PARTITIONED BY (col_name data_type [COMMENT col_comment], ...)]
[CLUSTERED BY (col_name, col_name, ...)
[SORTED BY (col_name [ASC|DESC], ...)] INTO num_buckets BUCKETS]
[ROW FORMAT row_format]
[STORED AS file_format]
[LOCATION hdfs_path]
- EXTERNAL: representa a criação de uma tabela externa. Ao criar uma tabela externa, você precisa especificar o caminho real de armazenamento dos dados por meio de LOCATION. Portanto, ao excluir uma tabela externa, apenas os metadados da tabela são excluídos, não os dados. Se EXTERNAL não for especificado, o padrão é a tabela interna. Quando uma tabela interna é excluída, os metadados e os dados da tabela interna são excluídos juntos.
- FORMATO DA LINHA: Defina o formato dos dados. O usuário pode personalizar o SerDe ou usar o SerDe embutido ao construir a mesa. Se ROW FORMAT ou ROW FORMAT DELIMITED não for especificado, o SerDe embutido será usado. Ao criar a tabela, o usuário também precisa especificar a coluna para a tabela.Ao especificar a coluna, o usuário também pode personalizar o SerDe.O Hive determina os dados da coluna através do SerDe;
SerDe é a abreviatura em inglês de Serialize e Deserilize. O Hive conclui as operações de leitura e gravação de tabelas por meio de serialização e desserialização. A operação de serialização é converter o objeto java usado pelo hive em uma sequência de bytes que pode ser gravada em hdfs ou um arquivo de fluxo que pode ser reconhecido por outros sistemas. A operação de desserialização consiste em converter uma string ou fluxo binário em um objeto java que o hive possa reconhecer. Por exemplo: a instrução select usará o objeto Serialize para analisar os dados hdfs; a instrução insert usará Deserilize, os dados são gravados no sistema hdfs e os dados precisam ser serializados.
- STORED AS: O formato de armazenamento do arquivo. Se for texto simples, você pode usá-lo
STORED AS TEXTFILE; se os dados precisam ser compactados, use-oSTORED AS SEQUENCEFILE. formato de armazenamento de arquivo hive para o padrãoTEXTFILE, a configuração podehive.default.fileformatser modificada; - CLUSTERED BY: Organização de buckets para uma determinada coluna. Os intervalos são uma divisão de intervalo de dados mais refinada. O Hive usa o hash do valor da coluna, divide pelo número de depósitos e calcula o restante para determinar em qual depósito o registro está armazenado;
- PARTICIONADO POR: Crie uma tabela particionada. O nome do campo de partição especificado não pode ser igual ao nome do campo da tabela, caso contrário, um erro será relatado;
1.4.2.2 Tipo de Campo
| Tipos de | Descrição | Exemplo | Restrições de versão |
|---|---|---|---|
| BOLEANO | verdadeiro falso | 1Y | |
| TINYINT | Inteiro assinado de 1 byte, -128 ~ 127 | 1S | |
| PEQUENO | Inteiro assinado de 2 bytes, -32768 ~ 32767 | 1S | |
| INT | Inteiro assinado de 4 bytes | 1 | |
| BIGINT | Inteiro assinado de 8 bytes | 1L | |
| FLUTUADOR | Número de ponto flutuante de precisão única de 4 bytes | 1.0 | |
| EM DOBRO | Número de ponto flutuante de precisão dupla de 8 bytes | 1.0 | Hive 2.2.0+ |
| DECIMAL | Decimal com sinal de precisão arbitrária | 1.0 | O Hive 0.11.0+ começa a introduzir 38 casas decimais e o Hive 0.13.0+ começa a personalizar as casas decimais |
| Numérico | Decimal com sinal de precisão arbitrária | 1.0 | Hive 3.0.0+ |
| FRAGMENTO | String de comprimento variável | "a" 或 'a' | |
| VARCHAR | String de comprimento variável | "a" 或 'a' | Hive 0.12.0+ |
| CARACTERES | String de comprimento fixo | "a" 或 'a' | Hive 0.13.0+ |
| BINÁRIO | Matriz de bytes | Hive 0.8.0+ | |
| TIMESTAMP | Timestamp, em milissegundos | 1287897987312 | Hive 0.8.0+ |
| DATA | data | '2020-06-06' | Hive 0.12.0+ |
| INTERVALO | Intervalo de freqüência de tempo | Hive 1.2.0+ | |
| VARIEDADE | Array, só pode armazenar o mesmo tipo de dados | matriz (1,2,3,4,5) | Hive 0.14+ |
| MAPA | Armazene uma coleção de pares de valores-chave | mapa ('a', 1, 'b', 2) | Hive 0.14+ |
| ESTRUTURA | Estrutura, pode armazenar diferentes tipos de dados | person_struct (1, 'Xiaobai', 18) | |
| UNIÃO | Um valor em um intervalo limitado | colmeia 0.7.0+ |
Para tipos específicos, consulte: https://cwiki.apache.org/confluence/display/Hive/LanguageManual+Types
1.4.2.3 Criar Operação de Tabela
use myhive;
# 创建简单表
create table company(id int, name string);
# 创建表并指定分隔符
create table if not exists company (id, name)
row format delimited fields terminated by '\t';
# 根据查询结果创建表
create table t2 as select * from t1; # 复制表结构和数据
create table t2 like t1; # 复制表结构
1.4.4.4 Tabela de Partição
Quando a quantidade de dados na tabela é muito grande, podemos particionar os dados de uma tabela, por exemplo: data. Isso pode melhorar a eficiência da consulta de dados.
- Crie uma tabela de partição:
# 创建分区表
create table score(s_id string,c_id string, s_score int) partitioned by (year string, month string) row format delimited fields terminated by '\t' location '/score';
Acima criamos uma pontuação da tabela de partição, que é particionada de acordo com os campos ano e mês. Dados com o mesmo valor de mês serão armazenados na mesma partição.
O que precisa ser enfatizado aqui é que as colunas de partição ano e mês não existem realmente na tabela do banco de dados, são apenas nossas provisões artificiais. O Hive não oferece suporte a certas colunas da tabela como colunas de partição.
- Veja o diretório da tabela de partição:
hdfs dfs -ls /score/year=2020&month=6/
- Exibir partição:
show partitions score;
- Carregue dados para a tabela de partição:
load data local inpath '/export/data/score.csv' into table score partition (year='2020',month='6');
-
- Ver dados da partição:
select * from score where year = '2020' and month = '6';
O método de consulta de dados de partição especifica o campo de partição como a condição de consulta. Depois que o nome da partição é especificado, a varredura completa da tabela não é mais executada e a consulta é realizada diretamente a partir da partição especificada, melhorando assim a eficiência da consulta de dados.
- Adicionar partição:
alter table score add partition(year='2020', month='5');
- Excluir partição:
alter table score drop partition(year='2020', month='5');
1.4.4.5 Tabela de balde
A diferença com o particionamento é que o particionamento não se baseia nas colunas reais da tabela, mas o agrupamento é baseado nas colunas reais da tabela e os dados são divididos em diferentes depósitos de acordo com os campos especificados.
- Como o Hive determina para qual intervalo os dados são alocados?
O Hive determina em qual depósito os dados são armazenados por módulo o número de depósitos do hash de um determinado valor de coluna. Por exemplo, se o atributo de nome for dividido em 3 depósitos, o hash do valor do atributo de nome é módulo 3 e os dados são divididos em grupos de acordo com o resultado do módulo. Se o resultado for 0, ele será registrado no primeiro arquivo, o resultado será 1 será registrado no segundo arquivo, o resultado será 2 será registrado no terceiro arquivo, e assim por diante.
Se quiser usar a função de intervalo, você deve primeiro habilitar o intervalo:
set hive.enforce.bucketing=true;
Em seguida, defina o número de Reduzir:
set mapreduce.job.reduces = 3;
Ao criar uma tabela, especifique o número de depósitos:
# 创建表时指定按照c_id列进行分桶,并且将数据放入到3个分桶中
create table ... clustered by(c_id) into 3 buckets row format delimited fields terminated by '\t';
Insira dados na tabela de balde:
insert overwrite table course select * from course_two cluster by (c_id);
Ver dados do intervalo:
# 查看第一个分桶的数据
select * from course tablesample(bucket 1 out of 3 on c_id);
1.4.4.5 Outras operações modificadas
- Modifique a tabela:
# 重命名
alter table old_table_name rename to new_table_name;
# 查询表结构
desc tablename;
# 添加列
alter table tablename add columns (column_name column_type, ...);
# 删除表
drop table tablename;