O princípio é explicado em detalhes
A replicação mestre-escravo do MySQL envolve três threads, uma em execução no nó mestre (thread de despejo de log) e as outras duas (thread de E / S, thread SQL) em execução no nó escravo, conforme mostrado na figura a seguir:
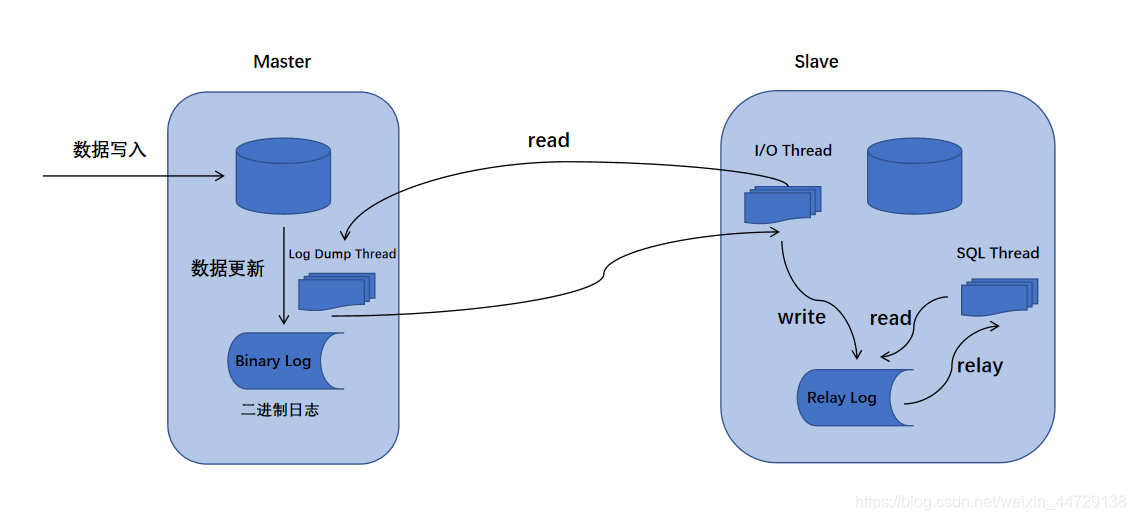
- Encadeamento de despejo de log binário do nó mestre
Quando o nó escravo se conecta ao nó mestre, o nó mestre criará um encadeamento de despejo de log para enviar o conteúdo do bin-log. Ao ler a operação no bin-log, este thread irá bloquear o bin-log no nó mestre.Quando a leitura for concluída, o bloqueio será liberado antes mesmo de ser enviado para o nó escravo. - Encadeamento de E / S do nó escravo
Quando o comando iniciar escravo é executado no nó escravo, o nó escravo criará um encadeamento de E / S para se conectar ao nó mestre e solicitar o bin-log atualizado na biblioteca mestre. Depois que o thread de E / S recebe a atualização enviada pelo processo de despejo do log bin do nó mestre, ele a salva no relay-log local. - O encadeamento SQL do encadeamento SQL do nó escravo
é responsável por ler o conteúdo no relay log, analisá-lo em operações específicas e executá-las e, por fim, garantir a consistência dos dados mestre-escravo.
Descrição:
- Para cada conexão mestre-escravo, três processos são necessários para concluir. Quando o nó mestre tem vários nós escravos, o nó mestre criará um
processo de despejo de log binário para cada nó escravo conectado atualmente , e cada nó escravo tem seu próprio processo de E / S e processo SQL. - O nó escravo usa o processo de E / S e o processo SQL para extrair logs atualizados da biblioteca principal e reproduzir e executar instruções SQL localmente, de modo que o desempenho da operação de leitura não seja reduzido quando a tarefa de sincronização de dados for executada.
- Para implementar a replicação, a função de log binário (bin-log) no mestre deve ser ativada, caso contrário, ela não pode ser implementada.
Ilustração do log de execução de replicação:
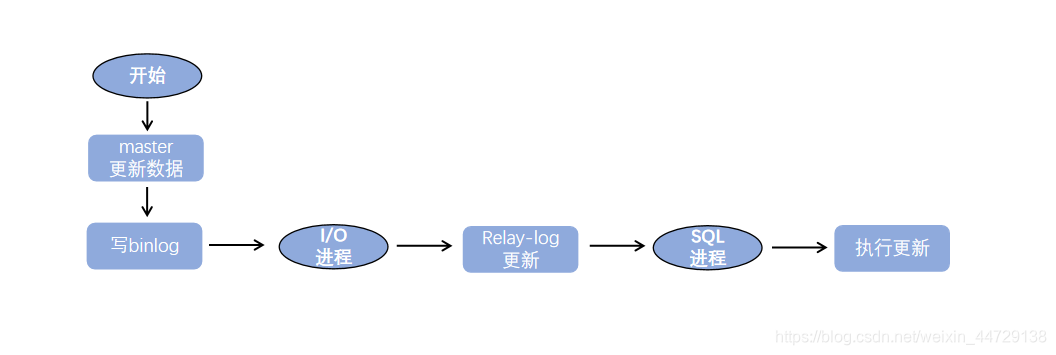
o processo básico de replicação é o seguinte:
- O processo de E / S no nó escravo se conecta ao nó mestre e solicita o conteúdo do log após o local especificado do arquivo de log especificado (ou desde o início do log);
- Depois que o nó mestre recebe a solicitação de I / O do nó escravo, o processo de I / O responsável pela replicação lê as informações de log após o local especificado do log especificado de acordo com as informações de solicitação e as retorna para o nó escravo. As informações retornadas incluem o arquivo bin-log e a posição bin-log das informações retornadas desta vez; após receber o conteúdo do processo de E / S do nó, o conteúdo do log recebido é atualizado para o relay log local e lê o binário obtido o nome e a localização do arquivo de log são salvos no arquivo master-info (
此文件好像没有了,有可能被别的文件代替了), de modo que da próxima vez que for lido, possa ser claramente informado ao Master que o conteúdo do log precisa ser lido novamente de qual local em um determinado compartimento registro; - Após o encadeamento SQL do Slave detectar
que o novo conteúdo foi adicionado ao relay-log , ele analisará o conteúdo do relay-log na operação realmente realizada no nó Zhu e a executará no banco de dados.
Método de cópia
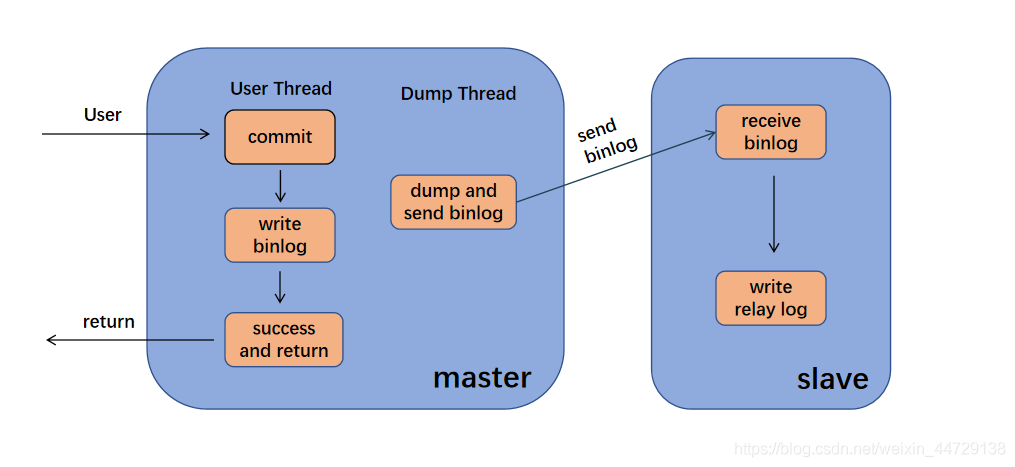
A replicação mestre-escravo do MySQL é assíncrona por padrão. As operações de adição, exclusão e modificação do MySQL serão todas gravadas no log binário. Quando o nó escravo se conectar ao mestre, ele obterá ativamente o arquivo de log bin mais recente do mestre e retransmitirá o sql no log bin para o local por meio Relé de E / S.
- Modo assíncrono (modo assíncrono mysql)
Neste modo, o nó mestre não irá empurrar ativamente o log bin para o nó escravo.Isso pode causar um failover, e o nó escravo pode não sincronizar o último log bin para o local a tempo.
- Modo semi-síncrono (mysql semi-sync)
Neste modo, o nó mestre só precisa receber a informação de retorno de um dos nós escravos, e vai se comprometer; caso contrário, ele precisa esperar até o período de tempo limite e então mudar para modo assíncrono e enviar; a finalidade disso O atraso de dados do banco de dados mestre-escravo pode ser reduzido e a segurança dos dados pode ser melhorada. Depois que a transação é enviada, o log bin é transmitido para pelo menos um nó escravo. Não há garantir que o nó escravo atualizará a transação para o banco de dados. Haverá uma certa redução no desempenho e o tempo de resposta será mais longo. Conforme mostrado na figura abaixo: O
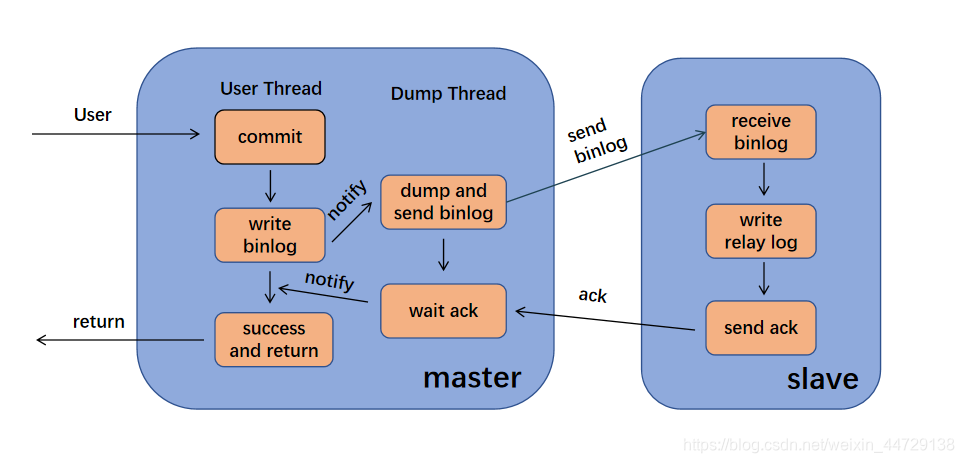
modo semissíncrono não é o mysql embutido. A partir do mysql 5.5, o mestre e o escravo precisam instalar plug-ins para habilitar o modo semissíncrono. - Modo de sincronização total O modo de sincronização
total significa que o nó mestre e o nó escravo executam o commit e confirmam antes de retornar o sucesso para o cliente. O princípio é o mesmo da semissincronização.
formato de registro binlog
Existem três maneiras de replicação mestre-escravo do MySQL:
- Replicação baseada em instrução SQL (replicação baseada em instrução, SBR)
- Replicação baseada em linha (RBR)
- Replicação de base mista (MBR)
Existem também três formatos de arquivo binlog correspondentes:
- DEMONSTRAÇÃO
- FILEIRA
- MISTURADO
Replicação baseada em instrução SQL
A Replicação baseada em instruções (SBR) é para registrar as instruções sql no log bin. Este formato de replicação é usado no Mysql 5.1.4 e em versões anteriores.
Vantagens: só precisa registrar a instrução sql que irá modificar os dados para o binlog, o que reduz a qualidade diária do binlog, economiza I / O e melhora o desempenho.
Desvantagens: Em alguns casos, os dados nos nós mestre e escravo serão inconsistentes (como sleep (), now (), etc.).
Replicação baseada em linha
Relicação baseada em linha (RBR) é que mysql master decompõe instruções SQL em instruções baseadas em mudanças de linha e as registra no log bin, o que significa registrar quais dados foram modificados e quais foram modificados.
Vantagens: Não haverá problema de que procedimentos armazenados, funções ou chamadas de gatilhos ou gatilhos não possam ser copiados corretamente em certas circunstâncias específicas.
Desvantagens: Um grande número de logs será gerado, especialmente quando a tabela for modificada, os logs aumentarão drasticamente e o tempo de sincronização do log bin aumentará. Também não é possível obter as instruções SQL executadas por meio da análise de log bin, e apenas as alterações de dados que ocorreram podem ser vistas.
Replicação de modo misto
Replicação de formato misto (MBR), o MBR usado pelo cluster NDB MySQL 7.3 e 7.4. É uma mistura dos dois modos acima. Para replicação geral, use o modo STATEMENT para salvar no log bin. Para operações que não podem ser replicadas no modo STATEMENT, use o modo ROW para salvar. O MySQL selecionará o método de salvamento do log de acordo com o SQL executado demonstração.
Modo de replicação GTID
Na replicação tradicional, quando ocorre uma falha, uma chave mestre-escravo é necessária.É necessário encontrar o binlog e os pontos pos e, em seguida, apontar o nó mestre para o novo nó mestre, que é relativamente problemático e sujeito a erros. No MySQL 5.6, não há necessidade de pesquisar binlog e pos points. Precisamos apenas saber o ip, a porta e a senha da conta do nó mestre. Como a replicação é automática, o MySQL encontrará automaticamente pontos para sincronização por meio do mecanismo interno GTID.
Em versões anteriores ao MySQL 5.6, a replicação do escravo era de thread único. Um evento lê o aplicativo e o mestre grava simultaneamente, portanto, o atraso é inevitável. A única maneira eficaz é colocar várias bibliotecas em vários escravos, o que é um desperdício de servidores. No MySQL 5.6, podemos colocar várias tabelas em várias bibliotecas, para que possamos usar a replicação multithread.
- Princípio de funcionamento baseado na replicação GTID
- Quando o nó mestre atualiza os dados, ele irá gerar o GTID antes da transação e registrá-lo no log binlog junto;
- O thread de E / S do nó escravo grava o log bin alterado no relay log local;
- O encadeamento SQL obtém o GTID do relay log e, em seguida, compara se há um registro no binlog local (portanto, o nó escravo do MySQL deve abrir o log binário);
- Se houver um registro, significa que a transação GTID foi executada e o nó escravo irá ignorá-la; se não houver registro, o nó escravo executará a transação GTID do relay log e registrará no log bin;
- Durante o processo de análise, será julgado se há uma chave primária, caso contrário, use um índice secundário, se houver uma varredura completa.
Resumindo
A replicação mestre-escravo do Mysql é a base da alta disponibilidade e do alto desempenho do MySQL. Com esta base, a implantação do MySQL se tornará simples, flexível e diversa, para que possa ser ajustada com flexibilidade de acordo com diferentes cenários de negócios.
Está tudo aqui. Para mais artigos, consulte a conta pública pessoal do WeChat ALL No Linux, vamos digitalizá-la!
