Autor original: nuvem de inspiração
Endereço original: Exploração aprofundada do princípio da replicação mestre-escravo MySQL
índice
1. Conceito de replicação mestre-escravo MySQL
2. O objetivo principal da replicação mestre-escravo do MySQL
3. Forma mestre-escravo do MySQL
4. Princípio de replicação mestre-escravo do MySQL
5. Modo de replicação mestre-escravo MySQL
O que é Replicação MySQL (replicação mestre-escravo MySQL )? Por que a replicação mestre-escravo e qual é o seu princípio de realização?
1. Conceito de replicação mestre-escravo MySQL
A replicação mestre-escravo do MySQL significa que os dados podem ser replicados de um nó mestre do servidor de banco de dados MySQL para um ou mais nós escravos. O MySQL usa replicação assíncrona por padrão, de modo que o nó escravo não precise acessar sempre o servidor mestre para atualizar seus próprios dados. A atualização de dados pode ser realizada em uma conexão remota. O nó escravo pode replicar todos os bancos de dados no banco de dados mestre ou um banco de dados específico ou uma tabela específica.
2. O objetivo principal da replicação mestre-escravo do MySQL
- Separação de leitura e gravação: No trabalho de desenvolvimento, às vezes uma determinada instrução SQL precisa bloquear a tabela, resultando em impossibilidade temporária de usar o serviço de leitura, o que afetará o negócio existente, use a replicação mestre-escravo, deixe a biblioteca mestre ser responsável por escrita, e a biblioteca escrava Responsável pela leitura, de forma que mesmo que a biblioteca principal tenha um cenário de tabela de bloqueio, o funcionamento normal do negócio pode ser garantido pela leitura da biblioteca escrava.
- Backup de dados em tempo real: quando um nó do sistema falha, ele pode ser facilmente ativado
- HA altamente disponível
- Expansão da arquitetura: Com o aumento do acesso de negócios no sistema, se o banco de dados for implantado em uma máquina autônoma, isso levará a uma frequência excessiva de acesso de E / S. Com a replicação mestre-escravo, vários nós de armazenamento de dados são adicionados, a carga é distribuída entre vários nós escravos, a frequência de acesso de E / S de disco de uma única máquina é reduzida e o desempenho de E / S de uma única máquina é aprimorado.
3. Forma mestre-escravo do MySQL
Um mestre e um seguidor:

Um-mestre-multi-escravo: Um-mestre-um-escravo e um-mestre-multi-escravo são as arquiteturas mestre-escravo mais comuns, que são simples e eficazes de implementar. Ele pode não apenas realizar HA, mas também separar ler e escrever, melhorando assim a simultaneidade do cluster.
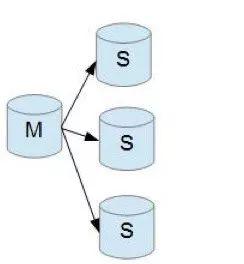
Multi-master e one-slave (suportado desde 5.7): Multi-master e one-slave podem fazer backup de múltiplos bancos de dados mysql para um servidor com melhor desempenho de armazenamento.
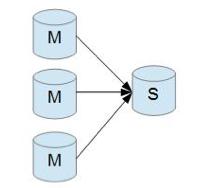
Replicação mestre duplo: isto é, replicação mestre-escravo mútuo, cada mestre é mestre e escravo de outro servidor. Desta forma, as alterações feitas por qualquer uma das partes serão replicadas para o banco de dados da outra parte.
Replicação em cascata: No modo de replicação em cascata, a sincronização de dados de alguns escravos não é conectada ao nó mestre, mas ao nó escravo. Porque se o nó mestre tiver muitos nós escravos, parte do desempenho será perdida para a replicação, então podemos deixar 3 ~ 5 nós escravos se conectarem ao nó mestre, e outros nós escravos são conectados ao nó escravo como o segundo ou terceiro nível, para que não só possa aliviar a pressão no nó mestre e não tenha impacto negativo na consistência dos dados.

4. Princípio de replicação mestre-escravo do MySQL
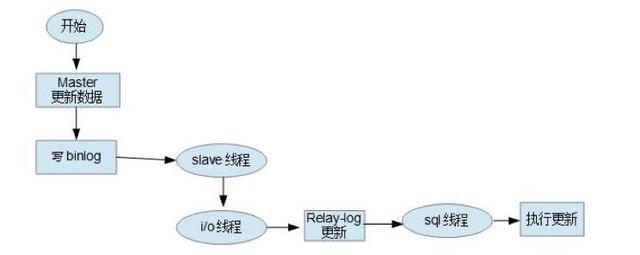
A replicação mestre-escravo do MySQL envolve três threads, uma em execução no nó mestre (thread de despejo de log) e as outras duas (thread de E / S, thread SQL) em execução no nó escravo, conforme mostrado na figura a seguir:

l thread de despejo de log binário do nó mestre
Quando o nó escravo se conecta ao nó mestre, o nó mestre cria um encadeamento de despejo de log para enviar o conteúdo do bin-log. Ao ler a operação no bin-log, este thread irá bloquear o bin-log no nó mestre.Quando a leitura for concluída, o bloqueio será liberado antes mesmo de ser enviado para o nó escravo.
l thread de E / S do nó escravo
Depois de executar o comando `start slave` no nó escravo, o nó escravo criará um thread de E / S para se conectar ao nó mestre e solicitar o bin-log atualizado na biblioteca mestre. Depois que o thread de E / S recebe a atualização enviada pelo processo de despejo do log bin do nó mestre, ele a salva no relay-log local.
l thread SQL do nó escravo
O encadeamento SQL é responsável por ler o conteúdo no relay log, analisá-lo em operações específicas e executá-las e, por fim, garantir a consistência dos dados mestre-escravo.
Para cada conexão mestre-escravo, três processos são necessários para concluir. Quando o nó mestre tem vários nós escravos, o nó mestre construirá um processo de despejo de log binário para cada nó escravo conectado no momento, e cada nó escravo tem seu próprio processo de E / S, o processo SQL. O nó escravo usa dois threads para puxar atualizações e executá-las da biblioteca principal em tarefas independentes, de modo que o desempenho das operações de leitura não seja reduzido quando a tarefa de sincronização de dados for executada . Por exemplo, se o nó escravo não estiver em execução, o processo de E / S pode obter rapidamente atualizações do nó mestre, embora o processo SQL ainda não tenha sido executado. Se o serviço do nó escravo for interrompido antes que o processo SQL seja executado, pelo menos o processo de E / S retirou as alterações mais recentes do nó mestre e salvou-as no relay log local. Quando o serviço estiver ativo novamente, a sincronização de dados pode ser concluído.
Para implementar a replicação, você deve primeiro habilitar a função de log binário (bin-log) no lado mestre, caso contrário, ela não pode ser implementada. Porque todo o processo de replicação é na verdade que o Slave obtém o log do Master e então executa as várias operações registradas no log em ordem completa em si mesmo. Como mostrado abaixo:
O processo básico de cópia é o seguinte:
- O processo de E / S no nó escravo se conecta ao nó mestre e solicita o conteúdo do log após o local especificado do arquivo de log especificado (ou o log desde o início);
- Após o nó mestre receber a solicitação de I / O do nó escravo, o processo de I / O responsável pela replicação lê as informações de log após o local de log especificado de acordo com as informações de solicitação e as retorna para o nó escravo. Além das informações contidas no log, as informações retornadas também incluem o arquivo bin-log e a posição bin-log das informações retornadas; após receber o conteúdo do processo de E / S do nó, o conteúdo do log recebido é atualizado para o relay log local e salve o nome do arquivo de log binário lido e a localização no arquivo master-info, de modo que da próxima vez que você ler, possa dizer claramente ao Master "De qual bin-log eu preciso? Por favor, envie-me o conteúdo do log desde o início da posição.
- Depois que o encadeamento SQL do Slave detecta o novo conteúdo adicionado ao relay-log, ele analisa o conteúdo do relay-log na operação realmente realizada no nó Zhu e a executa no banco de dados.
5. Modo de replicação mestre-escravo MySQL
A replicação mestre-escravo do MySQL é assíncrona por padrão. As operações de adição, exclusão e modificação do MySQL serão todas gravadas no log binário. Quando o nó escravo se conectar ao mestre, ele obterá ativamente o arquivo de log bin mais recente do mestre. E coloque o sql relay no log bin.
l modo assíncrono (modo assíncrono mysql)
O modo assíncrono é mostrado na figura abaixo. Nesse modo, o nó mestre não enviará ativamente o log do compartimento para o nó escravo. Isso pode levar a um failover, e o nó escravo pode não sincronizar imediatamente o registro do compartimento mais recente para o local.

l modo semissíncrono (mysql semi-sync)
Neste modo, o nó mestre só precisa receber as informações de retorno de um dos nós escravos e se compromete ; caso contrário, ele precisa esperar até o período de tempo limite e, em seguida, mudar para o modo assíncrono e enviar; a finalidade disso é para reduzir o atraso de dados do banco de dados mestre-escravo, pode melhorar a segurança dos dados, garantir que após a transação ser confirmada, o log bin é transmitido para pelo menos um nó escravo, e não há garantia de que o nó escravo atualizará esta transação para o db. Haverá uma certa redução no desempenho e um tempo de resposta mais longo. Como mostrado abaixo:

O modo semissíncrono não é construído no mysql. A partir do mysql 5.5, o mestre e o escravo precisam instalar plug-ins para habilitar o modo semissíncrono.
l Modo de sincronização completa
O modo de sincronização completa significa que o nó mestre e o nó escravo executam o commit e confirmam antes de retornar o sucesso para o cliente.
6. Formato de registro Binlog
Existem três maneiras de replicação mestre-escravo do MySQL: replicação baseada em instrução (SBR) com base em instruções SQL, replicação baseada em linha (RBR) e replicação baseada em combinação (MBR). Existem também três formatos do arquivo binlog correspondente: STATEMENT, ROW, MIXED.
l A replicação baseada em instruções (SBR) é para registrar as instruções sql no log bin. Este formato de replicação é usado no Mysql 5.1.4 e em versões anteriores. A vantagem é que apenas as instruções SQL que modificam os dados precisam ser registradas no binlog, o que reduz a qualidade diária do binlog, economiza E / S e melhora o desempenho. A desvantagem é que, em alguns casos, os dados nos nós mestre e escravo serão inconsistentes (como sleep (), now (), etc.).
Relicação baseada em linha (RBR) é que o mestre do MySQL decompõe instruções SQL em instruções baseadas em mudanças de linha e as registra no log bin, ou seja, apenas registra quais dados foram modificados e quais foram modificados. A vantagem é que não haverá problema de que procedimentos armazenados, funções ou chamadas ou gatilhos não possam ser copiados corretamente em certas circunstâncias específicas. A desvantagem é que um grande número de logs será gerado, especialmente quando a tabela for modificada, o log aumentará drasticamente e o tempo de sincronização do log bin aumentará. Também não é possível obter a instrução sql executada por meio da análise de log bin, apenas as alterações de dados que ocorreram podem ser vistas.
l Replicação de formato misto (MBR), o MBR usado pelo cluster NDB MySQL 7.3 e 7.4. É uma mistura dos dois modos acima. Para replicação geral, use o modo STATEMENT para salvar no log bin. Para operações que não podem ser replicadas no modo STATEMENT, use o modo ROW para salvar. O MySQL escolherá o método de salvamento do log de acordo com o SQL executado declaração.
7. Modo de cópia GTID
@ Na replicação tradicional, quando ocorre uma falha, uma chave mestre-escravo é necessária.É necessário encontrar o log bin e os pontos pos, e então apontar o nó mestre para o novo nó mestre, que é relativamente problemático e sujeito a erros. No MySQL 5.6, não há necessidade de procurar pontos binlog e pos. Precisamos apenas saber o ip, a porta e a senha da conta do nó mestre. Como a replicação é automática, o MySQL encontrará automaticamente pontos para sincronização por meio do mecanismo interno GTID.
@ Replicação multi-threaded (baseada na biblioteca), nas versões anteriores ao MySQL 5.6, a replicação do slave era single-threaded. Leia a aplicação de um evento um evento. O mestre grava simultaneamente, então o atraso é inevitável. A única maneira eficaz é colocar várias bibliotecas em vários escravos, o que é um desperdício de servidores. No MySQL 5.6, podemos colocar várias tabelas em várias bibliotecas, para que possamos usar a replicação multithread.
- Princípio de funcionamento baseado na replicação GTID
- Quando o nó mestre atualiza os dados, ele irá gerar o GTID antes da transação e gravá-lo no log binlog juntos.
- O thread de E / S do nó escravo grava o log do compartimento alterado no relay log local.
- O encadeamento SQL obtém o GTID do relay log e, em seguida, compara se há um registro no binlog local (portanto, o nó escravo MySQL deve abrir o log binário).
- Se houver um registro, significa que a transação GTID foi executada e o nó escravo irá ignorá-la.
- Se não houver nenhum registro, o nó escravo executará a transação GTID a partir do relay log e gravará no log bin.
- No processo de análise, será julgado se há uma chave primária, caso contrário, use um índice secundário, se houver uma varredura completa.
Resumindo
A replicação mestre-escravo do Mysql é a base da alta disponibilidade e alto desempenho do MySQL. Com esta base, a implantação do MySQL se tornará simples, flexível e diversa, para que possa ser ajustada com flexibilidade de acordo com os diferentes cenários de negócios.